Tabelas dinâmicas¶
As tabelas dinâmicas são tabelas que se atualizam automaticamente com base em uma consulta definida e na atualização do destino, simplificando a transformação de dados e o gerenciamento de pipeline sem exigir atualizações manuais ou agendamento personalizado.
Ao criar uma tabela dinâmica, você define uma consulta que especifica como os dados devem ser transformados a partir de objetos base. O Snowflake manipula o cronograma de atualização da tabela dinâmica e atualiza a tabela automaticamente para refletir as alterações feitas nos objetos base de acordo com a consulta.
Principais considerações e práticas recomendadas gerais¶
Restrições de imutabilidade: Use restrições de imutabilidade para poder controlar as atualizações de tabelas dinâmicas. As restrições mantêm linhas específicas estáticas enquanto permitem atualizar o restante da tabela de forma incremental. Elas impedem alterações indesejadas nos dados marcados enquanto permitem atualizações normais em outras partes da tabela. Para obter mais informações, consulte Explicando as restrições de imutabilidade.
Chaves primárias: o Snowflake usa chaves primárias confiáveis para rastrear alterações de forma mais eficiente em pipelines de tabelas dinâmicas. Quando uma tabela dinâmica tem uma chave primária derivada do sistema, as tabelas downstream podem usar a atualização incremental, mesmo que a tabela upstream use o modo de atualização completa. Para obter mais informações, consulte Explicando as chaves primárias em tabelas dinâmicas.
Considerações de desempenho: as tabelas dinâmicas usam um processamento incremental para cargas de trabalho compatíveis, o que pode melhorar o desempenho ao processar apenas os dados alterados em vez de computar tabelas inteiras novamente. O desempenho depende dos seus padrões de consulta e da organização dos dados. Para obter orientação sobre como otimizar o desempenho da tabela dinâmica, consulte Desempenho e otimização de tabelas dinâmicas.
Divida tabelas dinâmicas complexas: divida seu pipeline em tabelas dinâmicas menores e focadas para melhorar o desempenho e simplificar a solução de problemas. Para obter mais informações, consulte Práticas recomendadas para criar tabelas dinâmicas.
Como funcionam as tabelas dinâmicas¶
O Snowflake executa a consulta de definição especificada na instrução CREATE DYNAMIC TABLE e suas tabelas dinâmicas são atualizadas por meio de um processo automatizado.
O diagrama a seguir mostra como esse processo calcula as alterações feitas nos objetos base e os mescla na tabela dinâmica usando recursos de computação associados a ela.
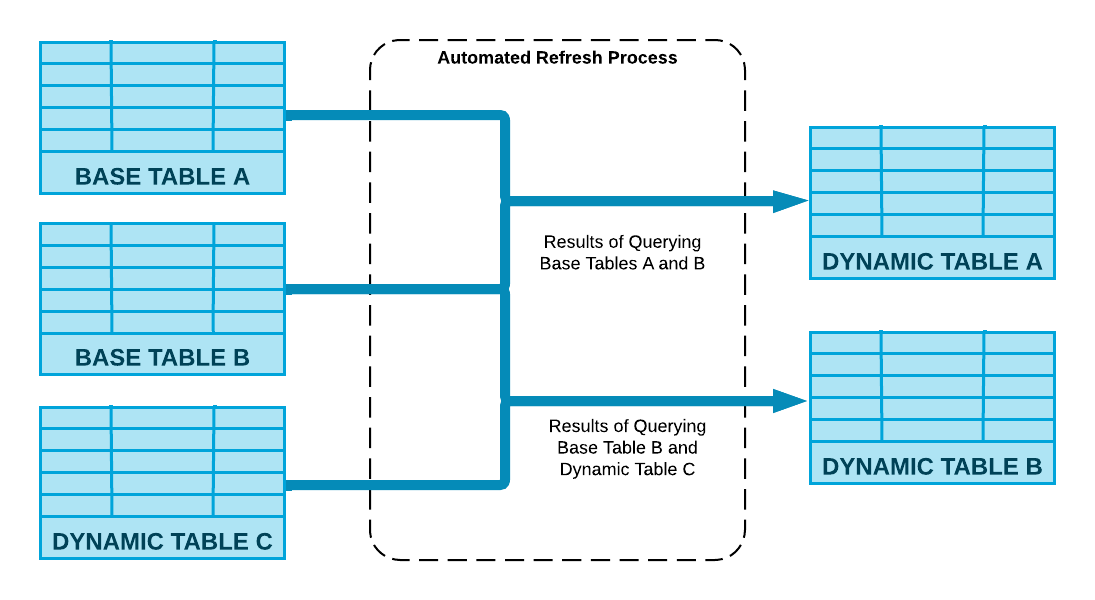
Atraso no destino¶
Use o atraso no destino para definir o nível de atualização dos seus dados. Normalmente, a atualização dos dados da tabela não fica muito atrás disso em relação à atualização dos dados da tabela base. Com a meta de atraso, você controla a frequência de atualização da tabela e o nível de atualização dos dados. A meta de atraso afeta a frequência de atualização e os custos de computação.
Para obter mais informações, consulte Entendendo o atraso de destino da tabela dinâmica. Para obter orientação sobre como equilibrar a atualização dos dados com o desempenho, consulte Otimização do desempenho da tabela dinâmica.
Atualização de tabelas dinâmicas¶
As tabelas dinâmicas tentam atualizar dentro da meta de atraso especificada por você. Por exemplo, um atraso no destino de cinco minutos garante que os dados na tabela dinâmica não fiquem mais de cinco minutos atrasados em relação às atualizações de dados na tabela base. Você define o modo de atualização ao criar a tabela e, depois, as atualizações podem ocorrer em um cronograma ou de forma manual.
Para obter mais informações, consulte Compreensão da inicialização e atualização de tabelas dinâmicas e Atualize manualmente as tabelas dinâmicas.
Quando usar tabelas dinâmicas¶
As tabelas dinâmicas são ideais para os seguintes cenários:
Você quer materializar os resultados da consulta sem escrever um código personalizado.
Você quer evitar o rastreamento manual de dependências de dados e o gerenciamento de cronogramas de atualização. As tabelas dinâmicas permitem que você defina os resultados do pipeline de forma declarativa, sem gerenciar manualmente as etapas de transformação.
Você quer encadear várias tabelas para transformações de dados em um pipeline.
Você não precisa de um controle minucioso dos cronogramas de atualização, basta especificar uma atualização de destino para o pipeline. O Snowflake processa a orquestração das atualizações de dados, incluindo cronograma e execução, com base nos seus requisitos de atualização de destino.
Exemplos de casos de uso¶
Dimensões de alteração lenta (SCDs): as tabelas dinâmicas podem ser usadas para implementar SCDs de tipo 1 e tipo 2 lendo a partir de um fluxo de alterações e usando funções de janela sobre chaves por registro ordenadas por um carimbo de data/hora de alteração. Esse método lida com inserções, exclusões e atualizações que ocorrem fora de ordem, simplificando a criação das SCDs. Para mais informações, consulte Dimensões de alteração lenta com tabelas dinâmicas.
Junções e agregações: para agilizar as consultas, você pode usar as tabelas dinâmicas para pré-computar incrementalmente junções e agregações lentas. Para obter orientação sobre como otimizar esses operadores para atualização incremental, consulte Otimizar consultas para atualização incremental.
Transições de lote para fluxos: as tabelas dinâmicas oferecem suporte a transições contínuas de lote para fluxos com um único comando ALTER DYNAMIC TABLE. Você pode controlar a frequência de atualização em seu pipeline para equilibrar o custo e a atualização dos dados.