Replicação de bancos de dados em várias contas¶
Este tópico descreve as etapas necessárias para replicar bancos de dados em várias contas Snowflake e para manter os objetos de banco de dados e os dados armazenados sincronizados. A replicação do banco de dados pode ocorrer por meio de contas Snowflake na mesma região ou em regiões diferentes.
Nota
A Snowflake recomenda o uso do recurso de replicação de conta para replicar bancos de dados.
Neste tópico:
Suporte regional para replicação de banco de dados e failover/failback¶
Todas as regiões do Snowflake nos Amazon Web Services, Google Cloud Platform e Microsoft Azure suportam a replicação de banco de dados e failover/failback.
Observe que as contas podem replicar bancos de dados entre Grupos de regiões (por exemplo, entre o Virtual Private Snowflake (VPS) e as regiões multilocatárias) para facilitar o compartilhamento de dados e as migrações de contas entre essas regiões. Esta capacidade está desativada por padrão. Você pode contatar o suporte Snowflake para permitir o acesso.
Interface da Web para replicação de banco de dados e failover/failback¶
Atenção
O gerenciamento e o monitoramento da replicação e do failover/failback em Snowsight e Classic Console estão disponíveis apenas para contas que usam conectividade privada.
Para todas as outras contas, consulte Monitoramento da replicação usando o Snowsight e Replicação de objetos de conta e bancos de dados.
Os administradores de conta (usuários com a função ACCOUNTADMIN) podem gerenciar ações de replicação e failover/failback em Snowsight ou Classic Console
Snowsight¶
- Navegação:
Data » Databases
Gerenciamento de bancos de dados primários¶
Atenção
Disponível apenas para contas que usam conectividade privada. Para todas as outras contas, consulte Monitoramento da replicação usando o Snowsight e Replicação de objetos de conta e bancos de dados.
Entre em Snowsight com uma conta Snowflake que contenha um banco de dados primário.
Selecione o menu suspenso no canto superior esquerdo (ao lado de seu nome de login) » Switch Role »
ACCOUNTADMIN.Selecione Data » Databases no painel de navegação à esquerda. Selecione um banco de dados primário no navegador de objetos de banco de dados. A página de detalhes do banco de dados é aberta.
Como alternativa, para visualizar apenas os bancos de dados que foram habilitados para replicação, use o filtro Replication Status » Primary para listar os bancos de dados primários na conta. Selecione um banco de dados na lista para abrir a página de detalhes.
Nota
O filtro Replication Status só estará disponível se uma conta for de origem ou de destino para replicação de banco de dados.
Selecione
 » Enable Replication. A caixa de diálogo Enable replication é aberta.
» Enable Replication. A caixa de diálogo Enable replication é aberta.Escolha a ação que deseja realizar:
Ativar o failover. Este recurso requer uma Business Critical Edition (ou superior).
Criar um banco de dados secundário em uma ou mais contas de destino.
Se um banco de dados primário em outra conta estiver habilitado para replicação na conta atual, você poderá criar um banco de dados secundário na conta atual. Para adicionar contas de destino adicionais, use o comando ALTER DATABASE na conta de origem para atualizar o banco de dados primário.
Renovar cada banco de dados secundário uma vez, após a sua criação.
Para cada conta de destino deste banco de dados, verifique as opções para criar um banco de dados secundário e atualize o banco de dados.
Entre na conta de destino como um usuário a quem foi previamente concedida a função ACCOUNTADMIN nessa conta.
O Snowflake executa as ações solicitadas e exibe uma caixa de diálogo de sucesso.
Gerencie a replicação para este banco de dados a partir da guia Replication nos detalhes do banco de dados.
Gerenciamento de bancos de dados secundários¶
Atenção
Disponível apenas para contas que usam conectividade privada. Para todas as outras contas, consulte Monitoramento da replicação usando o Snowsight e Replicação de objetos de conta e bancos de dados.
Entre em Snowsight com uma conta Snowflake que contenha um banco de dados secundário.
Selecione o menu suspenso no canto superior esquerdo (ao lado de seu nome de login) » Switch Role »
ACCOUNTADMIN.Selecione Data » Databases no painel de navegação à esquerda.
As seguintes ações estão disponíveis no botão de ações (…) no canto superior direito da página:
Crie um banco de dados secundário.
Nota
Esta opção só estará disponível se uma conta for uma conta de origem ou de destino para replicação de banco de dados.
Se um banco de dados primário em outra conta estiver habilitado para replicação na conta atual, você poderá criar um banco de dados secundário na conta atual. Para adicionar contas de destino adicionais, use o comando ALTER DATABASE na conta de origem para atualizar o banco de dados primário.
Selecione um banco de dados secundário no navegador de objetos do banco de dados. A página de detalhes do banco de dados é aberta.
Selecione a guia Replication.
As seguintes ações estão disponíveis no botão de ações (…) no canto superior direito da página:
Promova o banco de dados secundário para servir como o banco de dados primário. Este recurso requer uma Business Critical Edition (ou superior).
Nota
Para promover um banco de dados secundário para servir como primário, o banco de dados primário deve ter o failover ativado para a conta de destino onde o banco de dados secundário está localizado.
Se esta opção não estiver disponível, você poderá usar o comando ALTER DATABASE na conta de origem para ativar o failover do banco de dados primário para a conta de destino. Para obter mais informações, consulte Etapa 3: habilitar o failover para um banco de dados primário.
Atualize o banco de dados secundário.
Copie um modelo para criar uma tarefa que atualize o banco de dados secundário em um cronograma. Cole o modelo em uma planilha do Snowsight e edite-a para especificar o cronograma desejado.
Console clássico¶
Atenção
Disponível apenas para contas que usam conectividade privada. Para todas as outras contas, consulte Monitoramento da replicação usando o Snowsight e Replicação de objetos de conta e bancos de dados.
Use a área Replication da guia Databases ![]() na Classic Console para executar a maioria das ações relacionadas à configuração e ao gerenciamento da replicação do banco de dados, incluindo as seguintes ações:
na Classic Console para executar a maioria das ações relacionadas à configuração e ao gerenciamento da replicação do banco de dados, incluindo as seguintes ações:
Ativar a replicação para um banco de dados local. Isso promove o banco de dados para servir como banco de dados primário.
Habilitar o failover para um banco de dados primário (contas Business Critical Edition ou superior).
Atualizar um banco de dados secundário, seja uma vez (manualmente) ou repetidamente (em um cronograma, usando uma tarefa).
Promover um banco de dados secundário para servir como banco de dados primário (contas Business Critical Edition ou superior).
Nota
Para poder promover um banco de dados secundário para servir como primário, o banco de dados primário deve ter o failover ativado para a conta de destino onde o banco de dados secundário está localizado.
Se esta opção não estiver disponível:
Entre na conta de origem com o banco de dados primário.
Na área Databases, selecione Replication.
Selecione a guia Primary para listar os bancos de dados primários. Selecione a linha com o banco de dados primário.
Encontre a conta de destino para a qual deseja ativar o failover e selecione Failover.
Desativar a replicação e/ou o failover de um banco de dados primário.
Replicação de um banco de dados para outra conta¶
As instruções nesta seção explicam como preparar suas contas para replicação, promover um banco de dados local para servir como banco de dados primário, realizar a replicação inicial deste banco de dados primário para outra conta e programar a atualização de bancos de dados secundários.
Importante
As contas de destino não têm conectividade Tri-Secret Secure ou conectividade privada ao serviço Snowflake, como AWS PrivateLink, ativada por padrão. Se você precisar de conectividade Tri-Secret Secure ou conectividade privada para o serviço Snowflake para fins de conformidade, segurança ou outros, é sua responsabilidade configurar e habilitar esses recursos na conta de destino.
Pré-requisito: Habilitar a replicação para contas na organização¶
O administrador da organização (funçãoORGADMIN) deve habilitar a replicação para as contas de origem e destino antes de replicar um banco de dados. Para instruções detalhadas, consulte Pré-requisito: Habilitar a replicação para contas na organização.
Habilitação da replicação de banco de dados e failover e atualização dos bancos de dados secundários¶
Nota
Exceto onde indicado, somente administradores de conta (usuários com a função ACCOUNTADMIN) podem executar as instruções SQL nesta seção.
Etapa 1: exibir todas as contas em sua organização¶
Recupere a lista de contas em sua organização nas quais a replicação foi habilitada. Qualquer banco de dados permanente ou transitório existente nestas contas pode ser modificado para servir como um banco de dados primário. As réplicas de um banco de dados primário (ou seja, bancos de dados secundários) só podem ser criadas nessas contas.
Para ver a lista de contas em sua organização, consulte SHOW REPLICATION ACCOUNTS.
SHOW REPLICATION ACCOUNTS;
+------------------+---------------------------------+---------------+------------------+---------+-------------------+
| snowflake_region | created_on | account_name | account_locator | comment | organization_name |
|------------------+---------------------------------+---------------+------------------+---------+-------------------|
| AWS_US_WEST_2 | 2018-11-19 16:11:12.720 -0700 | ACCOUNT1 | MYACCOUNT1 | | MYORG |
| AWS_US_EAST_1 | 2019-06-02 14:12:23.192 -0700 | ACCOUNT2 | MYACCOUNT2 | | MYORG |
+------------------+---------------------------------+---------------+------------------+---------+-------------------+
Consulte a lista completa de IDs de região.
Etapa 2: promover um banco de dados local para servir como um banco de dados primário¶
Modifique um banco de dados permanente ou transitório existente para servir como banco de dados primário usando uma instrução ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS. Forneça uma lista de contas separadas por vírgulas em sua organização que possam armazenar uma réplica deste banco de dados (ou seja, um banco de dados secundário), permitindo que os usuários nessas contas consultem objetos no banco de dados secundário.
Exemplo¶
Promova um banco de dados local mydb1 (na conta account1) para servir como banco de dados primário e especifique que as contas account2 e account3 podem armazenar uma réplica deste banco de dados:
ALTER DATABASE mydb1 ENABLE REPLICATION TO ACCOUNTS myorg.account2, myorg.account3;
Etapa 3: habilitar o failover para um banco de dados primário¶
Nota
O failover/failback requer o Business Critical (ou superior). Para se informar sobre a possibilidade de upgrade, entre em contato com o suporte Snowflake.
Habilite o failover para um banco de dados primário para uma ou mais contas em sua organização usando uma instrução ALTER DATABASE … ENABLE FAILOVER TO ACCOUNTS. A réplica deste banco de dados primário em qualquer uma destas contas (ou seja, um banco de dados secundário) pode ser promovida para servir como banco de dados primário.
Note que a habilitação de failover para um banco de dados primário pode ser feita antes de ou após uma réplica do banco de dados primário ter sido criada em uma conta especificada.
Exemplo¶
Habilite o failover para o banco de dados primário mydb1 para as contas account2 e account3.
-- Executed from primary account
ALTER DATABASE mydb1 ENABLE FAILOVER TO ACCOUNTS myorg.account2, myorg.account3;
Etapa 4: criar um banco de dados secundário¶
Crie uma réplica de um banco de dados primário existente na mesma conta que armazena o banco de dados primário, ou em uma conta diferente (na mesma região ou em uma região diferente). Note que você só pode criar um banco de dados secundário em uma conta especificada na instrução ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS na Etapa 2: Promover um banco de dados local para servir como um banco de dados primário.
Nota
Comandos de replicação (por exemplo, promover um banco de dados para um banco de dados primário em uma conta de origem) tipicamente acionam operações entre regiões e podem levar alguns segundos para surtir efeito. Por exemplo, se você estiver promovendo programaticamente um banco de dados para servir como banco de dados primário em uma conta de origem e criando um banco de dados secundário em uma conta de destino, pode demorar alguns segundos até que você possa criar o banco de dados secundário.
Execute uma instrução CREATE DATABASE … AS REPLICA OF em cada conta de destino para criar uma réplica do banco de dados primário especificado.
Importante
Como prática recomendada, recomendamos dar a cada banco de dados secundário o mesmo nome de seu banco de dados primário. Esta prática oferece suporte a fazer referência a objetos totalmente qualificados (ou seja, '<bd>.<esquema>.<objeto>') por outros objetos no mesmo banco de dados, como a consulta de um nome de tabela totalmente qualificado em uma exibição.
Se um banco de dados secundário tiver um nome diferente do banco de dados primário, então estas referências de objetos seriam desfeitas no banco de dados secundário.
Para visualizar a lista de bancos de dados primários e secundários em sua organização, consulte SHOW REPLICATION DATABASES. Após a criação de um banco de dados secundário, um administrador de contas pode transferir a propriedade do banco de dados para outra função (usando GRANT OWNERSHIP).
Exemplo¶
O exemplo seguinte cria uma réplica do banco de dados primário myorg.account1.mydb1 na conta myorg.account2:
-- Log into the ACCOUNT2 account.
-- Query the set of primary and secondary databases in your organization.
-- In this example, the MYORG.ACCOUNT1 primary database is available to replicate.
SHOW REPLICATION DATABASES;
+------------------+-------------------------------+-----------------+----------+---------+------------+----------------------------+---------------------------------+------------------------------+-------------------+-----------------+
| snowflake_region | created_on | account_name | name | comment | is_primary | primary | replication_allowed_to_accounts | failover_allowed_to_accounts | organization_name | account_locator |
|------------------+-------------------------------+-----------------+----------+---------+------------+----------------------------+---------------------------------+------------------------------+-------------------+-----------------|
| AWS_US_WEST_2 | 2019-11-15 00:51:45.473 -0700 | ACCOUNT1 | MYDB1 | NULL | true | MYORG.ACCOUNT1.MYDB1 | MYORG.ACCOUNT2, MYORG,ACCOUNT1 | MYORG.ACCOUNT1 | MYORG | MYACCOUNT1 |
+------------------+-------------------------------+-----------------+----------+---------+------------+----------------------------+---------------------------------+------------------------------+-------------------+-----------------+
-- Create a replica of the 'mydb1' primary database
-- If the primary database has the DATA_RETENTION_TIME_IN_DAYS parameter set to a value other than the default value,
-- set the same value for the parameter on the secondary database.
CREATE DATABASE mydb1
AS REPLICA OF myorg.account1.mydb1
DATA_RETENTION_TIME_IN_DAYS = 10;
-- Verify the secondary database
SHOW REPLICATION DATABASES;
+------------------+-------------------------------+---------------+----------+---------+------------+-------------------------+---------------------------------+------------------------------+-------------------+-----------------+
| snowflake_region | created_on | account_name | name | comment | is_primary | primary | replication_allowed_to_accounts | failover_allowed_to_accounts | organization_name | account_locator |
|------------------+-------------------------------+---------------+----------+---------+------------+------------------------------------------+----------------+------------------------------+-------------------------------------|
| AWS_US_WEST_2 | 2019-11-15 00:51:45.473 -0700 | ACCOUNT1 | MYDB1 | NULL | true | MYORG.ACCOUNT1.MYDB1 | MYORG.ACCOUNT2, MYORG.ACCOUNT1 | MYORG.ACCOUNT1 | MYORG | MYACCOUNT1 |
| AWS_US_EAST_1 | 2019-08-15 15:51:49.094 -0700 | ACCOUNT2 | MYDB1 | NULL | false | MYORG.ACCOUNT1.MYDB1 | | | MYORG | MYACCOUNT2 |
+------------------+-------------------------------+---------------+----------+---------+------------+-------------------------+---------------------------------+------------------------------+-------------------+-----------------+
Etapa 5. Atualização de cada banco de dados secundário¶
As instruções nesta seção explicam como atualizar um banco de dados secundário a partir de um instantâneo de seu banco de dados primário (usando ALTER DATABASE … REFRESH). Um instantâneo inclui alterações nos objetos e dados. Para a replicação inicial de um banco de dados primário muito grande, recomendamos aumentar o tempo limite da instrução.
Nota
Para atualizar um banco de dados secundário, a função usada para executar a operação deve ter o privilégio OWNERSHIP no banco de dados ou a função deve receber uma função que tenha o privilégio OWNERSHIP no banco de dados.
A função que executa a operação de atualização possui quaisquer novos objetos adicionados como resultado de uma atualização do banco de dados.
Para verificar a região atual após fazer login em uma conta, consulte a função CURRENT_REGION.
ALTER DATABASE mydb1 REFRESH;
Você também pode atualizar um banco de dados secundário interface da Web.
Etapa 6. Atualização de um banco de dados secundário em um cronograma¶
Como melhor prática, recomendamos agendar suas atualizações do banco de dados secundário. Esta seção fornece instruções para iniciar uma atualização automática do banco de dados em um horário especificado.
A frequência com que você atualiza um banco de dados secundário depende do objetivo de ponto de recuperação (RPO) para os dados do banco de dados secundário. Por exemplo, se os aplicativos que dependem dos dados podem tolerar até 1 hora de perda de dados, então você deve atualizar os dados pelo menos a cada hora. Se a tolerância à perda de dados for de 5 minutos, então atualize o banco de dados secundário pelo menos a cada 5 minutos.
Nota
Recomendamos que você execute a replicação inicial de um banco de dados primário manualmente (usando ALTER DATABASE … REFRESH) e programe apenas as atualizações subsequentes.
Há um limite padrão de 60 minutos para uma única execução de uma tarefa. Esta limitação foi implementada como uma proteção contra tarefas não terminadas. Em raras circunstâncias, uma atualização de um banco de dados muito grande poderia exceder o limite padrão de execução de tarefas. Para determinar se isso ocorreu, consulte a função da tabela TASK_HISTORY. Considere aumentar o tempo limite para a tarefa executando ALTER TASK … SET USER_TASK_TIMEOUT_MS = <num>.
Complete as etapas desta seção para iniciar uma atualização automática do banco de dados em um horário especificado.
- Pré-requisitos:
Os seguintes objetos Snowflake são necessários na conta que armazena o banco de dados secundário:
O banco de dados secundário.
Um banco de dados separado para armazenar os novos objetos criados nesta seção. Como os bancos de dados secundários são somente leitura, esse banco de dados deve ser separado do banco de dados secundário. Este banco de dados também deve incluir os seguintes objetos:
Esquema. Use o esquema PUBLIC, ou crie um novo esquema usando CREATE SCHEMA.
Warehouse. Qualquer warehouse pode ser fornecido aqui para atender à exigência de sintaxe, mas não é utilizado para a atualização do banco de dados. Crie um novo warehouse usando CREATE WAREHOUSE.
Tarefa que atualiza o banco de dados secundário em um cronograma.
- Privilégios obrigatórios:
As etapas desta seção exigem uma função com os seguintes privilégios na conta em que o banco de dados secundário é atualizado:
Tipo de objeto
Objeto
Privilégio
Notas
Conta
Conta que armazena o banco de dados secundário
EXECUTE TASK
Necessário para executar a nova tarefa.
Banco de dados
Banco de dados secundário
OWNERSHIP
Necessário para atualizar o banco de dados secundário.
Banco de dados
Banco de dados que armazena a nova tarefa
USAGE
Esquema
Esquema que armazena a nova tarefa
USAGE, CREATE TASK
Tarefa
OWNERSHIP
A função que cria a tarefa é, por padrão, proprietária do objeto. A propriedade pode ser transferida para uma função diferente usando GRANT
privileges… TO ROLE.Warehouse
Warehouse utilizado para configurar a tarefa
USAGE
A especificação de um warehouse é necessária para configurar a tarefa, porém o warehouse não é utilizado para executar a tarefa ou para a operação de atualização.
- Etapas:
Complete as seguintes etapas para cada banco de dados secundário que você deseja atualizar segundo um cronograma:
Crie uma tarefa que inicie a atualização do banco de dados segundo um cronograma (usando CREATE TASK). Observe que embora a sintaxe CREATE TASK para especificar um cronograma de replicação requeira um warehouse, o warehouse não é utilizado para replicação.
Por exemplo, crie uma tarefa chamada
refresh_mydb1_taskque atualiza um banco de dados secundário chamadomydb1a cada 10 minutos com um tempo limite de 4 horas. A tarefa é configurada utilizando o warehouse existentemywh:CREATE TASK refresh_mydb1_task WAREHOUSE = mywh SCHEDULE = '10 minute' USER_TASK_TIMEOUT_MS = 14400000 AS ALTER DATABASE mydb1 REFRESH;
Uma tarefa é suspensa por padrão quando é criada. Retome a tarefa para permitir que ela seja executada com base nos parâmetros especificados na definição da tarefa:
ALTER TASK refresh_mydb1_task RESUME;
Exemplo¶
Execute as seguintes instruções SQL em seu cliente Snowflake preferido para permitir replicação e failover, faça uma atualização inicial do banco de dados e configure as atualizações programadas.
Executar a partir da conta de origem¶
-- The commands below are executed from the source account
-- View replication enabled accounts
SHOW REPLICATION ACCOUNTS;
ALTER DATABASE mydb ENABLE REPLICATION TO ACCOUNTS myorg.account2, myorg.account3;
ALTER DATABASE mydb ENABLE FAILOVER TO ACCOUNTS myorg.account2, myorg.account3;
Executar a partir de cada conta de destino¶
-- The commands below are executed from each target account
-- View replication enabled databases
-- Note the primary column of the source database for the CREATE DATABASE statement below
SHOW REPLICATION DATABASES;
-- If the primary database has the DATA_RETENTION_TIME_IN_DAYS parameter set to a value other than the default value,
-- set the same value for the parameter on the secondary database.
CREATE DATABASE mydb
AS REPLICA OF myorg.account1.mydb
DATA_RETENTION_TIME_IN_DAYS = 10;
-- Increase statement timeout for initial refresh
-- Optional but recommended for initial refresh of a large database
ALTER SESSION SET STATEMENT_TIMEOUT_IN_SECONDS = 604800;
-- If you have an active warehouse in current session, update warehouse statement timeout
SELECT CURRENT_WAREHOUSE();
ALTER WAREHOUSE my_wh SET STATEMENT_TIMEOUT_IN_SECONDS = 604800;
-- Reset warehouse statement timeout after initial refresh
ALTER WAREHOUSE my_wh UNSET STATEMENT_TIMEOUT_IN_SECONDS;
-- Refresh a secondary database
ALTER DATABASE mydb REFRESH;
-- Create task
-- Set up refresh schedule for each secondary database using a separate database
USE DATABASE my_db2;
-- Create a task and RESUME the task for each secondary database
-- Edit the task schedule and timeout for your specific use case
CREATE TASK my_refresh_task
WAREHOUSE = my_wh
SCHEDULE = '10 minute'
USER_TASK_TIMEOUT_MS = 14400000
AS
ALTER DATABASE mydb REFRESH;
-- Start task
ALTER TASK my_refresh_task RESUME;
Uso do localizador de contas herdado¶
Embora o formato herdado snowflake_region.account_locator tenha suporte atualmente para identificar uma conta em comandos de replicação e failover, seu uso não é recomendado, pois pode parar de funcionar no futuro.
Aumento do tempo limite da instrução para a replicação inicial¶
A replicação do banco de dados utiliza recursos computacionais fornecidos pelo Snowflake em vez de seu próprio warehouse virtual para copiar objetos e dados. Entretanto, o parâmetro STATEMENT_TIMEOUT_IN_SECONDS de sessão/objeto ainda controla por quanto tempo uma instrução é executada antes de ser cancelada. O valor padrão é 172800 (2 dias). Como a replicação inicial de um banco de dados primário muito grande pode levar mais do que 2 dias para ser concluída (dependendo da quantidade de metadados no banco de dados, assim como a quantidade de dados nos objetos do banco de dados), recomendamos aumentar o valor de STATEMENT_TIMEOUT_IN_SECONDS para 604800 (7 dias, o valor máximo) para a sessão em que se executa a operação de replicação.
Execute a seguinte instrução ALTER SESSION antes de executar a instrução ALTER DATABASE secondary_db_name REFRESH na mesma sessão:
ALTER SESSION SET STATEMENT_TIMEOUT_IN_SECONDS = 604800;
Observe que o parâmetro STATEMENT_TIMEOUT_IN_SECONDS também se aplica ao warehouse ativo em uma sessão. O parâmetro honra o valor mais baixo definido no nível da sessão ou do warehouse. Se você tiver um warehouse ativo na sessão atual, defina STATEMENT_TIMEOUT_IN_SECONDS como 604800 para este warehouse (usando ALTER WAREHOUSE), também.
Por exemplo:
-- determine the active warehouse in the current session (if any)
SELECT CURRENT_WAREHOUSE();
+---------------------+
| CURRENT_WAREHOUSE() |
|---------------------|
| MY_WH |
+---------------------+
-- change the STATEMENT_TIMEOUT_IN_SECONDS value for the active warehouse
ALTER WAREHOUSE my_wh SET STATEMENT_TIMEOUT_IN_SECONDS = 604800;
Você pode redefinir o valor do parâmetro para o padrão depois que a operação de replicação for concluída:
ALTER WAREHOUSE my_wh UNSET STATEMENT_TIMEOUT_IN_SECONDS;
Monitoramento do progresso de uma atualização de banco de dados¶
Para determinar o status atual da replicação inicial do banco de dados ou uma atualização subsequente do banco de dados secundário, consulte a função da tabela DATABASE_REFRESH_PROGRESS , DATABASE_REFRESH_PROGRESS_BY_JOB (no Snowflake Information Schema).
Uma operação de atualização do banco de dados pode requerer várias horas ou mais para ser concluída, dependendo da quantidade de dados a serem replicados.
Para visualizar o histórico de replicação de um banco de dados especificado dentro de um intervalo de datas especificado, consulte uma das seguintes opções:
Função de tabela DATABASE_REPLICATION_USAGE_HISTORY (no Snowflake Information Schema). Esta função retorna a atividade de uso de replicação dos últimos 14 dias.
Exibição DATABASE_REPLICATION_USAGE_HISTORY (em Account Usage). Esta exibição retorna a atividade de uso de replicação dos últimos 365 dias (1 ano).
Exemplo¶
Monitore o progresso da atualização do banco de dados secundário mydb1:
select *
from table(information_schema.database_refresh_progress(mydb1));
Monitoramento do progresso de uma atualização de banco de dados no console clássico¶
Inicie manualmente uma atualização de banco de dados secundário na Classic Console para visualizar uma barra de progresso dinâmica mostrando o status atual da operação de atualização com estatísticas.
Para iniciar uma operação de atualização de banco de dados secundário:
Em Classic Console, selecione a guia Databases
 » Replication.
» Replication.Selecione o banco de dados secundário para atualizá-lo.
Selecione o botão Refresh now. A caixa de diálogo Refresh Database é aberta.
Selecione o botão Refresh.
A coluna Last Refresh Status exibe o status da operação de atualização atual. A barra de progresso é atualizada de forma dinâmica.
A estatística Refresh History na janela lateral também exibe o status atual de atualização, juntamente com a hora de início da atualização, o número de bytes transferidos e outras estatísticas.
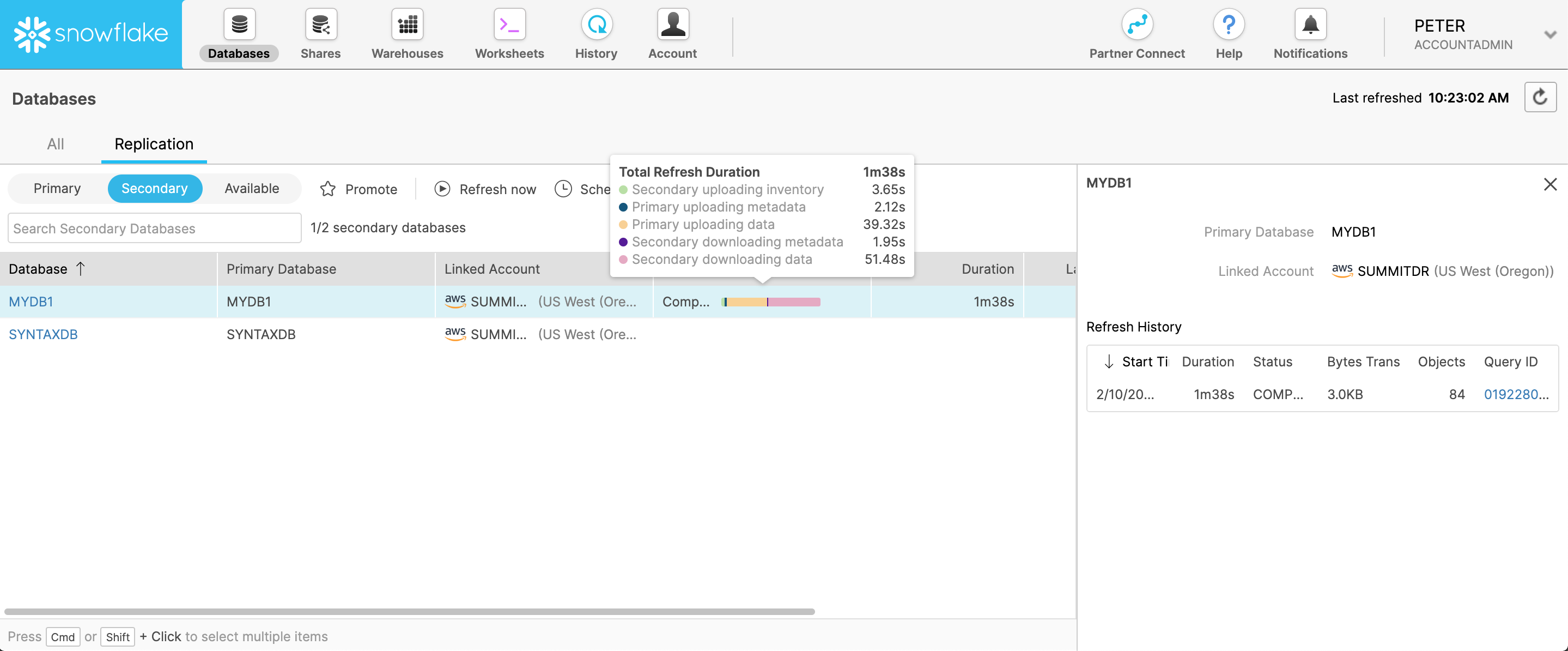
Exibição do histórico de atualização do banco de dados¶
Para visualizar o histórico das operações de atualização do banco de dados secundário, consulte a função da tabela DATABASE_REFRESH_HISTORY (no Snowflake Information Schema). Esta função retorna a atividade de atualização do banco de dados dos últimos 14 dias.
ou
Consulte o Exibição DATABASE_REPLICATION_USAGE_HISTORY (no esquema Account Usage no banco de dados compartilhado do Snowflake). Esta exibição retorna a atividade de uso de replicação de banco de dados dos últimos 365 dias (1 ano).
Exemplo¶
Veja o histórico da operação de atualização do banco de dados secundário mydb1:
select *
from table(information_schema.database_refresh_history(mydb1));
Monitoramento do custo de replicação do banco de dados¶
Para bancos de dados individuais replicados usando a replicação de banco de dados, os usuários com a função ACCOUNTADMIN podem usar Snowsight, Classic Console ou SQL para visualizar a quantidade de dados de replicação transferidos (em bytes) para sua conta Snowflake dentro de um intervalo de datas especificado.
Para visualizar os valores de transferência de dados para sua conta:
- Snowsight:
Selecione Admin » Cost Management.
- Classic Console:
Selecione Account
» Billing & Usage.
A utilização da replicação é mostrada como um warehouse especial fornecido pelo Snowflake chamado
REPLICATION. Selecione Data Transfer para visualizar os custos de transferência de dados. Observe que a interface da Web não detalha os custos de transferência de dados para replicação.
- SQL:
Consulte um dos seguintes:
Função de tabela DATABASE_REPLICATION_USAGE_HISTORY (no Snowflake Information Schema). Esta função retorna a atividade de uso de replicação de banco de dados dos últimos 14 dias.
Exibição Exibição DATABASE_REPLICATION_USAGE_HISTORY (em Account Usage). Esta exibição retorna a atividade de uso de replicação de banco de dados dos últimos 365 dias (1 ano).
As seguintes consultas podem ser executadas na exibição DATABASE_REPLICATION_USAGE_HISTORY:
Consulta: Histórico de custos de replicação (por dia, por objeto)
Esta consulta fornece uma lista completa de bancos de dados replicados e o volume de créditos consumidos através do serviço de replicação nos últimos 30 dias, separados por dia. Qualquer irregularidade no consumo do crédito ou consumo consistentemente alto são sinais para investigações adicionais.
SELECT TO_DATE(start_time) AS date, database_name, SUM(credits_used) AS credits_used FROM snowflake.account_usage.database_replication_usage_history WHERE start_time >= DATEADD(month,-1,CURRENT_TIMESTAMP()) GROUP BY 1,2 ORDER BY 3 DESC;Consulta: Histórico de replicação e média de m dias
Esta consulta mostra a média de créditos diários consumidos pela replicação agrupados por semana durante o último ano. Isto ajuda a identificar quaisquer anomalias na média diária, de maneira que você pode investigar quaisquer picos ou mudanças no consumo.
WITH credits_by_day AS ( SELECT TO_DATE(start_time) AS date, SUM(credits_used) AS credits_used FROM snowflake.account_usage.database_replication_usage_history WHERE start_time >= DATEADD(year,-1,CURRENT_TIMESTAMP()) GROUP BY 1 ORDER BY 2 DESC ) SELECT DATE_TRUNC('week',date), AVG(credits_used) AS avg_daily_credits FROM credits_by_day GROUP BY 1 ORDER BY 1;
Comparação de conjuntos de dados em bancos de dados primários e secundários¶
Opcionalmente, use a função HASH_AGG para comparar as linhas em um conjunto aleatório de tabelas em um banco de dados primário e secundário para verificar a consistência dos dados. A função HASH_AGG retorna um valor agregado de hash de 64 bits assinado para o conjunto (não ordenado) de linhas de entrada. Consulte esta função em todas as tabelas ou em um subconjunto aleatório de tabelas em um banco de dados secundário e no banco de dados primário (a partir do carimbo de data/hora do instantâneo do banco de dados primário) e compare a saída.
Exemplo¶
Executado no banco de dados secundário¶
No banco de dados secundário, consulte a função da tabela DATABASE_REFRESH_PROGRESS (no Snowflake Information Schema). Observe o
snapshot_transaction_timestampna colunaDETAILSpara a fasePRIMARY_UPLOADING_DATA. Este é o carimbo de data/hora para o último instantâneo do banco de dados primário.select parse_json(details)['snapshot_transaction_timestamp'] from table(information_schema.database_refresh_progress(mydb)) where phase_name = 'PRIMARY_UPLOADING_DATA';
Consulte a função HASH_AGG para uma tabela específica. A seguinte consulta retorna um valor de hash para todas as linhas da tabela
mytable:SELECT HASH_AGG( * ) FROM mytable;
Executado no banco de dados primário¶
No banco de dados primário, consulte a função HASH_AGG para a mesma tabela. Usando o Time Travel, especifique o carimbo de data/hora em que o último instantâneo foi tirado para o banco de dados secundário:
SELECT HASH_AGG( * ) FROM mytable AT(TIMESTAMP => '<snapshot_transaction_timestamp>'::TIMESTAMP);
Compare os resultados das duas consultas. A saída deve ser idêntica.
Descarte de um banco de dados secundário¶
Você pode descartar um banco de dados secundário a qualquer momento usando o comando DROP DATABASE. Somente o proprietário do banco de dados (ou seja, a função com o privilégio OWNERSHIP no banco de dados) pode descartar o banco de dados.
Descarte de um banco de dados primário¶
Um banco de dados primário não pode ser descartado se houver uma ou mais réplicas do banco de dados (ou seja, bancos de dados secundários). Para descartar o banco de dados primário, primeiro promova um banco de dados secundário para servir como banco de dados primário e depois descarte o antigo banco de dados primário. Alternativamente, descarte todos os bancos de dados secundários do banco de dados primário e depois descarte o banco de dados primário.
Note que somente o proprietário do banco de dados pode descartar o banco.