Parâmetros¶
O Snowflake fornece parâmetros que lhe permitem controlar o comportamento de sua conta, sessões individuais de usuários e objetos. Todos os parâmetros têm valores padrão. É possível definir esses parâmetros e substituí-los em diferentes níveis, dependendo do tipo de parâmetro (conta, sessão ou objeto).
Hierarquia de parâmetros e tipos¶
Esta seção descreve os diferentes tipos de parâmetros e os níveis em que cada tipo pode ser definido. Existem três tipos de parâmetros:
O diagrama a seguir ilustra a relação hierárquica entre os diferentes tipos de parâmetros e como parâmetros individuais podem ser substituídos em cada nível:
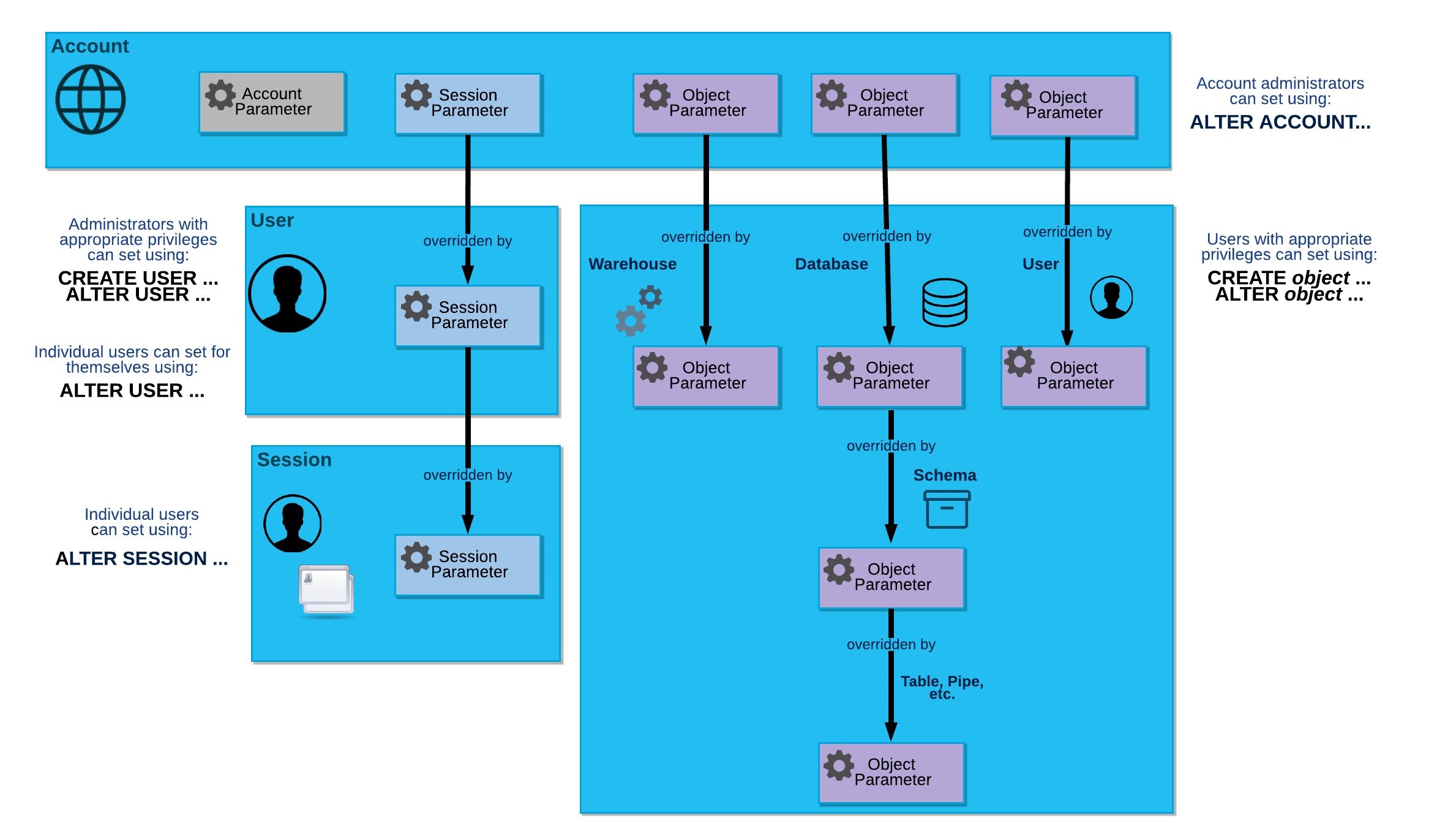
Parâmetros de conta¶
Você só poderá definir parâmetros da conta, no nível da conta, se usar uma função que tenha recebido o privilégio para definir o parâmetro. Para definir o parâmetro da conta, execute o comando ALTER ACCOUNT.
O Snowflake fornece os seguintes parâmetros de conta:
Parâmetro |
Notas |
|---|---|
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES |
Utilizado para especificar as extensões de arquivo permitidas em espaços de trabalho privados para a conta. |
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_SHARED_WORKSPACES |
Utilizado para especificar as extensões de arquivo permitidas em espaços de trabalho compartilhados para a conta. |
Utilizado para permitir que clientes acessem valores de variáveis de vinculação. |
|
Utilizado para ativar o cache de conexão em navegador com um login único (SSO) para clientes fornecidos pelo Snowflake. |
|
Usado para especificar os tipos de carga de trabalho permitidos em sua conta para implantação no Snowpark Container Services. |
|
Usado para criptografar arquivos preparados para carregamento ou descarregamento de dados; pode exigir instalação e configuração adicionais (para obter mais detalhes, consulte a descrição). |
|
Usado para habilitar o processamento entre regiões de chamadas do Snowflake Cortex em uma região diferente se a chamada não puder ser processada na região de sua conta. |
|
Utilizado para definir a versão padrão para todos os objetos de projeto dbt futuros criados em uma conta. |
|
Usado para desativar a concessão de privilégios diretamente aos usuários. Para obter mais informações, consulte privilégios GRANT para notas de uso de USERS. |
|
Usado para especificar os tipos de carga de trabalho que não são permitidos em sua conta para implantação no Snowpark Container Services. |
|
Controla se os eventos da classificação de dados confidenciais são registrados na tabela de eventos do usuário. |
|
Controla se os eventos dos orçamentos são registrados na tabela de eventos. |
|
Usado para ativar ou desativar a otimização de saída de custo de saída de listagem automática. |
|
Permite que a função SYSTEM$GET_PRIVATELINK_CONFIG retorne a chave |
|
Permite que a função SYSTEM$GET_PRIVATELINK_CONFIG retorne as chaves |
|
Usado para ativar ou desativar notebooks privados em uma conta Snowflake. |
|
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT |
Usado para permitir a aplicação da criptografia SNOWFLAKE_FULL para volumes de armazenamento em bloco e instantâneos do Snowpark Container Services. |
Controla se o Snowflake coleta dados de telemetria para propagação de tag. |
|
Usado para especificar a escolha de um repositório de imagens para cancelar Tri-Secret Secure e Periodic Rekeying. |
|
Usado para definir o cronograma de atualização de todas as listagens em uma conta. |
|
Usado para definir o período mínimo de retenção de dados para reter dados históricos para operações de Time Travel. |
|
Esse é o único parâmetro no nível da conta que pode ser definido por administradores tanto de conta (ou seja, usuários com a função do sistema ACCOUNTADMIN) quanto de segurança (ou seja, usuários com a função do sistema SECURITYADMIN). . Para obter mais informações, consulte Parâmetros de objeto. |
|
Usado para especificar se deve capturar o texto SQL de uma instrução SQL rastreada. |
|
Utilizado para ativar ou desativar Workspaces como o editor SQL padrão para a conta. |
Nota
Por padrão, parâmetros da conta não são exibidos na saída de SHOW PARAMETERS. Para obter informações sobre a visualização de parâmetros de conta, consulte Visualizando os parâmetros e seus valores (neste tópico).
Parâmetros de sessão¶
A maioria dos parâmetros é de sessão, que você pode definir nos seguintes níveis:
- Conta:
Os administradores de conta podem executar o comando ALTER ACCOUNT para definir parâmetros de sessão para a conta.
Os valores definidos nesse nível tornam-se os valores padrão para usuários individuais e suas sessões.
- Usuário:
Administradores com os privilégios adequados (normalmente, um usuário a quem foi concedido a função SECURITYADMIN) podem executar o comando ALTER USER para substituir os parâmetros de sessão de usuários individuais. Além disso, os usuários individuais podem executar o comando ALTER USER para substituir os próprios parâmetros de sessão padrão.
Os valores definidos para um usuário tornam-se os valores padrão em qualquer sessão iniciada por esse usuário.
- Sessão:
Os usuários podem executar o comando ALTER SESSION para substituir os parâmetros da sessão atual.
Nota
Por padrão, somente parâmetros de sessão são exibidos na saída de SHOW PARAMETERS. Para obter informações sobre a visualização de parâmetros de conta e objeto, consulte Visualizando os parâmetros e seus valores (neste tópico).
Parâmetros de objeto¶
É possível definir parâmetros de objeto nos seguintes níveis:
- Conta:
Administradores de conta podem executar o comando ALTER ACCOUNT para definir parâmetros para os objetos na conta.
Os valores definidos nesse nível tornam-se os valores padrão dos objetos individuais criados na conta.
- Objeto:
Usuários com os privilégios adequados podem executar o comando CREATE <objeto> ou ALTER <objeto> para substituir os parâmetros de um objeto individual.
O Snowflake fornece os seguintes parâmetros de objeto:
Parâmetro |
Tipo de objeto |
Notas |
|---|---|---|
Procedimento armazenado do Snowflake Scripting |
||
Banco de dados, esquema |
Especifica um prefixo a ser usado no caminho de gravação dos arquivos de tabela do Apache Iceberg™. |
|
Banco de dados, esquema, tabela Apache Iceberg™ |
||
Conta, banco de dados, esquema, tabela Apache Iceberg™ |
Este parâmetro é compatível apenas com as tabelas Iceberg gerenciadas pelo Snowflake que você sincroniza com o Open Catalog. |
|
Funções e modelos da Cortex AI |
Nomes separados por vírgula dos modelos de linguagem Cortex permitidos, |
|
Tabela |
Especifica o agendamento para executar as funções de métricas de dados associadas à tabela. Todas as funções de métricas de dados na tabela ou exibição seguem o mesmo cronograma. |
|
Banco de dados, esquema, tabela |
||
Banco de dados, esquema, tabela |
||
Banco de dados, esquema |
||
Banco de dados, esquema |
||
Conta |
Configurando os próprios pools de computação preferidos para apps Streamlit |
|
Conta, banco de dados, esquema |
||
Conta, usuário |
||
Conta, banco de dados, esquema, tabela Apache Iceberg™ |
Esse parâmetro só é compatível com tabelas Iceberg gerenciadas pelo Snowflake. |
|
Conta, banco de dados, esquema, tabela Apache Iceberg™ |
||
Usuário |
Afeta o histórico de consultas para consultas que falham devido a erros de sintaxe ou análise. |
|
Usuário |
Afeta a censura de mensagens de erro relacionadas a objetos seguros em metadados. |
|
Banco de dados, conta |
||
Banco de dados, esquema, tabela Apache Iceberg™ |
||
Tabela Apache Iceberg™ |
||
Conta, banco de dados, esquema |
||
Conta, banco de dados, esquema, projeto DCM, procedimento armazenado, função, tabela dinâmica, tabela Iceberg, tarefa, serviço. |
Mensagens de log de APIs de registro. |
|
Conta, banco de dados, esquema, projeto DCM, procedimento armazenado, função, tabela dinâmica, tabela Iceberg, tarefa, serviço. |
Eventos de log (tipo de registro EVENT) gravados na tabela de eventos. |
|
Warehouse |
||
Banco de dados, esquema, tabela |
||
Conta, banco de dados, esquema, procedimento armazenado, função |
||
Usuário |
Esse é o único parâmetro de usuário que pode ser definido tanto por administradores de conta (usuários com a função ACCOUNTADMIN do sistema) quanto por administradores de segurança (usuários com a função SECURITYADMIN do sistema). Se esse parâmetro for definido na conta e em um usuário na mesma conta, a política de redes em nível de usuário substituirá a política de redes em nível de conta. |
|
Tabela Apache Iceberg™ |
Especifica o layout do caminho para arquivos de dados Parquet gravados em tabelas Iceberg particionadas. |
|
Esquema, canal |
||
Usuário |
||
Usuário |
||
Banco de dados, esquema, formato de arquivo, tabela Apache Iceberg™ |
Só pode ser definido para tabelas Iceberg que usam um catálogo Iceberg externo. |
|
|
Banco de dados, esquema, tabela |
Use este parâmetro para habilitar carimbos de data/hora de linha em suas tabelas. Para obter mais informações, consulte Usar carimbos de data/hora de linha para medir a latência em seus pipelines. |
CSV_TIMESTAMP_FORMATROW_TIMESTAMP_DEFAULT`` |
Banco de dados, esquema, tabela |
Use este parâmetro para definir carimbos de data/hora de linha por padrão para novas tabelas em um contêiner. Para obter mais informações, consulte Usar carimbos de data/hora de linha para medir a latência em seus pipelines. |
Banco de dados, esquema, tarefa, conta |
||
Banco de dados, esquema, tarefa, conta |
||
Warehouse |
Também é um parâmetro de sessão (pode ser definido nos níveis do objeto e da sessão). Para obter mais detalhes sobre herança e substituição, veja a descrição do parâmetro. |
|
Warehouse |
Também é um parâmetro de sessão (pode ser definido nos níveis do objeto e da sessão). Para obter mais detalhes sobre herança e substituição, veja a descrição do parâmetro. |
|
Banco de dados, esquema, tabela Apache Iceberg™ |
Este parâmetro só é suportado para tabelas Iceberg que usam Snowflake como catálogo. |
|
Banco de dados, esquema, tarefa |
||
Banco de dados, esquema, tarefa |
||
Conta, banco de dados, esquema, procedimento armazenado, função |
||
Banco de dados, esquema, tarefa |
||
Banco de dados, esquema, tarefa |
||
Banco de dados, esquema, tarefa |
Nota
Por padrão, parâmetros do objeto não são exibidos na saída de SHOW PARAMETERS. Para obter informações sobre a visualização de parâmetros de objeto, consulte Visualizando os parâmetros e seus valores (neste tópico).
Visualização dos parâmetros e de seus valores¶
Para visualizar os parâmetros definidos e os respectivos valores padrão, execute o comando SHOW PARAMETERS. Você pode executar o comando com outros parâmetros para exibir tipos de parâmetro diferentes:
Visualizando os parâmetros de sessão¶
Por padrão, o comando exibe somente parâmetros de sessão:
Visualizando os parâmetros de objeto¶
Para exibir os parâmetros de um objeto específico, inclua uma cláusula IN com o tipo e nome do objeto. Por exemplo:
Visualizando todos os parâmetros (inclusive os parâmetros de conta e objeto)¶
Para exibir todos os parâmetros, inclusive os parâmetros de conta e objeto, inclua a cláusula IN ACCOUNT:
Limitação da lista de parâmetros por nome¶
Você pode especificar a cláusula LIKE para limitar a lista de parâmetros por nome. Por exemplo:
Para exibir os parâmetros de sessão com nomes contendo «time»:
Para exibir todos os parâmetros com nomes que começam com «time»:
Nota
Você deve especificar a cláusula LIKE antes da cláusula IN.
ABORT_DETACHED_QUERY¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica a ação que o Snowflake executa para consultas em andamento se a conectividade for perdida devido à interrupção abrupta de uma sessão (por exemplo, interrupção da rede, interrupção do navegador ou interrupção do serviço).
- Valores:
TRUE: Consultas em andamento são abortadas 5 minutos depois que a conectividade é perdida.FALSE: Consultas em andamento são concluídas.- Padrão:
FALSE
Nota
Para drivers de cliente, fechar a conexão do lado do cliente (por exemplo, chamar
connection.close()) é diferente de sair de fato da sessão do Snowflake. Fechar a conexão pode ser associado a limpar os recursos de propriedade da conexão, incluindo, mas sem limitação, fazer logout da sessão. Fazer logout da sessão também significa que as consultas que ainda estiverem em execução na mesma sessão (por exemplo, consultas enviadas de forma assíncrona) serão canceladas após alguns minutos quando a sessão for desconectada, mesmo que o parâmetro ABORT_DETACHED_QUERY seja definido comofalse(valor padrão).Portanto, alguns drivers do Snowflake implementam a própria lógica comercial para decidir se o logout da sessão é feito quando a conexão é fechada.
Atualmente, essa funcionalidade foi implementada nos seguintes drivers:
A execução da maioria das consultas requer recursos de computação. Esses recursos são fornecidos por warehouses virtuais, que consomem créditos ao funcionar. Se a sessão do Snowflake não for encerrada com o fechamento da conexão, os warehouses talvez continuem operando e consumindo créditos para concluir quaisquer consultas que estavam em andamento quando a conexão foi fechada, até o valor do parâmetro STATEMENT_TIMEOUT_IN_SECONDS, que tem um padrão de dois dias.
ACTIVE_PYTHON_PROFILER¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Define o criador de perfil a ser usado para a sessão ao criar o perfil do código do manipulador Python.
- Valores:
'LINE': para que o perfil se concentre na atividade de uso de linha.'MEMORY': para que o perfil se concentre na atividade de uso da memória.- Padrão:
Nenhum.
ACCOUNT_LEVEL_FILE_EXTENSIONS_ALLOW_LIST_FOR_PRIVATE_WORKSPACES¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica as extensões de arquivo permitidas em espaços de trabalho privados para a conta. O valor é uma lista de extensões separadas por vírgulas, por exemplo:
.ipynb,.sql,.txt. Se o parâmetro estiver vazio (padrão), todas as extensões de arquivo serão permitidas.Quando a lista de permissões não estiver vazia:
Somente as extensões listadas serão permitidas; todas as outras serão bloqueadas.
Arquivos carregados por meio do Workspaces com uma extensão não permitida falharão imediatamente no carregamento.
Se um arquivo for renomeado para usar uma extensão não permitida, o arquivo ficará inacessível no espaço de trabalho.
Arquivos preexistentes com extensões não permitidas não aparecerão no Workspaces.
Os usuários ainda podem usar o comando CLI
PUTdop Snowflake para carregar arquivos com extensões não permitidas para a área de preparação virtual de um espaço de trabalho ou para a área de preparação virtual de um objeto de projeto de notebook. No entanto, esses arquivos ficam inacessíveis e não podem ser utilizados, visualizados, baixados (viaGET) ou listados (viaLIST) dentro do ambiente do espaço de trabalho ou de objeto de projeto de notebook.Para manter a funcionalidade principal do espaço de trabalho, inclua
.ipynbe.sqlna lista de permissões.Arquivos sem extensão (por exemplo,
Makefile) não são permitidos quando a lista não estiver vazia.Arquivos iniciados por ponto (por exemplo,
.gitignoreou.venv) devem ser adicionados explicitamente à lista.A correspondência de extensões diferencia maiúsculas de minúsculas. Por exemplo, se
.txtestiver na lista,.TXTnão será permitido.
- Padrão:
Cadeia de caracteres vazia (todas as extensões permitidas)
ALLOW_BIND_VALUES_ACCESS¶
- Tipo:
Conta — Só pode ser definido para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se os clientes podem acessar valores de variável de vinculação usando a função de tabela BIND_VALUES, a visualização do uso da conta QUERY_HISTORY, a visualização do uso da organização QUERY_HISTORY ou a função QUERY_HISTORY. Para obter mais informações, consulte Recuperar valores de variáveis de vinculação.
- Valores:
TRUE: permite a recuperação de valores de variáveis de vinculação.FALSE: não permite a recuperação de valores de variáveis de vinculação.- Padrão:
TRUE
ALLOW_CLIENT_MFA_CACHING¶
- Tipo:
Conta — Só pode ser definido para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se um token MFA pode ser salvo na keystore do sistema operacional do lado do cliente para promover conectividade contínua e segura sem que os usuários precisem responder a uma solicitação de MFA no início de cada tentativa de conexão ao Snowflake. Para obter mais detalhes e a lista de clientes suportados pelo Snowflake, consulte Uso do armazenamento em cache de tokens MFA para minimizar o número de tentativas durante a autenticação — opcional.
- Valores:
TRUE: Armazena um token MFA na keystore do sistema operacional do lado do cliente para permitir que o aplicativo do cliente utilize o token MFA sempre que uma nova conexão for estabelecida. Enquanto for verdadeiro, os usuários não serão solicitados a responder a solicitações de MFA adicionais.FALSE: Não armazena um token MFA. Os usuários devem responder a uma solicitação de MFA sempre que o aplicativo do cliente estabelecer uma nova conexão com o Snowflake.- Padrão:
FALSE
ALLOW_ID_TOKEN¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se um token de conexão pode ser salvo na chave do sistema operacional do lado do cliente para promover conectividade contínua e segura sem que os usuários precisem entrar com as credenciais de login no início de cada tentativa de conexão ao Snowflake. Para obter mais detalhes e a lista de clientes suportados pelo Snowflake, consulte Uso do cache de conexão para minimizar o número de tentativas de autenticação — Opcional.
- Valores:
TRUE: Armazena um token de conexão na keystore do sistema operacional do lado do cliente para permitir que o aplicativo do cliente execute um SSO baseado em navegador sem que os usuários sejam solicitados a autenticar sempre que uma nova conexão for estabelecida.FALSE: Não armazena uma ficha de conexão. Os usuários são solicitados a autenticar sempre que o aplicativo do cliente estabelece uma nova conexão com o Snowflake. Um SSO ao Snowflake ainda é possível se esse parâmetro for definido como falso.- Padrão:
FALSE
ALLOWED_SPCS_WORKLOAD_TYPES¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica os tipos de carga de trabalho que são permitidos em sua conta para implantação no Snowpark Container Services. Consulte também DISALLOWED_SPCS_WORKLOAD_TYPES.
- Valores:
O valor é uma lista separada por vírgulas dos seguintes tipos de carga de trabalho compatíveis:
USER: Qualquer carga de trabalho implantada diretamente pelos usuários.NOTEBOOK: notebooks Snowflake.STREAMLIT: Streamlit no Snowflake.MODEL_SERVING: serviço de modelo ML.ML_JOB: trabalhos ML do Snowflake.ALL: todas as cargas de trabalho.
- Padrão:
ALL
Nota
Se você configurar ambos ALLOWED_SPCS_WORKLOAD_TYPES e DISALLOWED_SPCS_WORKLOAD_TYPES, DISALLOWED_SPCS_WORKLOAD_TYPES terá precedência. Por exemplo, se você configurar esses dois parâmetros e especificar a carga de trabalho de NOTEBOOK, as cargas de trabalho de NOTEBOOK não poderão ser executadas no Snowpark Container Services.
AUTO_EVENT_LOGGING¶
- Tipo:
Objeto (para procedimentos armazenados do Snowflake Scripting)
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Controla se as mensagens de log e os eventos de rastreamento do Snowflake Scripting são ingeridos automaticamente na tabela de evento. Para definir este parâmetro, execute o comando ALTER PROCEDURE.
- Valores:
LOGGING: adiciona automaticamente as seguintes informações de registro à tabela de evento quando um procedimento é executado:BEGIN/END de um bloco Snowflake Scripting.
BEGIN/END de uma solicitação de trabalho secundário.
Estas informações são adicionadas à tabela de evento somente se o LOG_LEVEL efetivo estiver definido como
TRACEpara o procedimento armazenado.TRACING: adiciona automaticamente as seguintes informações de rastreamento à tabela de evento quando um procedimento armazenado é executado:Captura de exceções.
Informações sobre a execução do trabalho filho.
Estatísticas do trabalho filho.
Estatísticas de procedimento armazenado, incluindo tempo de execução e valores de entrada.
Essas informações serão adicionadas à tabela de evento somente se TRACE_LEVEL efetivo estiver definido como
ALWAYSouON_EVENTpara o procedimento armazenado.ALL: inclui automaticamente as informações de registro adicionadas ao valorLOGGINGe as informações de rastreamento adicionadas ao valorTRACING.OFF: não adiciona automaticamente informações de registro ou de rastreamento à tabela de evento.
- Padrão:
OFF
Para obter mais informações sobre o uso deste parâmetro, consulte Definição de níveis para registro, métricas e rastreamento, Como adicionar automaticamente mensagens de log sobre blocos e trabalhos secundários e Emissão automática de eventos de rastreamento para trabalhos secundários e exceções.
AUTOCOMMIT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a confirmação automática está habilitada para a sessão. A confirmação automática determina se uma instrução DML, quando executada sem uma transação ativa, é automaticamente comprometida depois que a instrução for concluída com sucesso. Para obter mais informações, consulte Transações.
Nota
A definição deste parâmetro como
FALSEimpede que os dados de uso sejam salvos no esquema ORGANIZATION_USAGE de uma conta da organização.- Valores:
TRUE: A confirmação automática está habilitada.FALSE: A confirmação automática está desativada, o que significa que instruções DML devem ser explicitamente confirmadas ou revertidas.- Padrão:
TRUE
Nota
O valor FALSE não é compatível com tarefas.
AUTOCOMMIT_API_SUPPORTED (somente exibição)¶
- Tipo:
N/A
- Tipo de dados:
Booliano
- Descrição:
Somente para uso interno do Snowflake. Parâmetro somente de exibição que indica se o suporte da API para confirmação automática está habilitado para sua conta. Se o valor for
TRUE, você pode ativar ou desativar a confirmação automática através das APIs para os seguintes drivers/conectores:
BASE_LOCATION_PREFIX¶
- Tipo:
Objeto (para bancos de dados e esquemas) — Pode ser definido como Conta » Banco de dados » Esquema
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica um prefixo para o Snowflake usar no caminho de gravação das tabelas Apache Iceberg™ gerenciadas pelo Snowflake. Para obter mais informações, consulte Diretórios de dados e metadados para tabelas Iceberg.
- Valores:
Qualquer prefixo de cadeia de caracteres válido que esteja em conformidade com as convenções de nomenclatura de armazenamento do seu provedor de nuvem.
- Padrão:
Nenhum
BINARY_INPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
O formato de valores VARCHAR passados como entrada para funções de conversão deVARCHAR para BINARY. Para obter mais informações, consulte Entrada e saída de binários.
- Valores:
HEX,BASE64ouUTF8/UTF-8- Padrão:
HEX
BINARY_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
O formato para valores VARCHAR retornados como saída por funções de conversão de BINARYparaVARCHAR. Para obter mais informações, consulte Entrada e saída de binários.
- Valores:
HEXouBASE64- Padrão:
HEX
CATALOG¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas Apache Iceberg™) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o catálogo para as tabelas Apache Iceberg™. Para obter mais informações, consulte a documentação da tabela Iceberg.
- Valores:
SNOWFLAKEou qualquer identificador de integração de catálogo válido.- Padrão:
Nenhum
CATALOG_SYNC¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas Iceberg) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome da integração de catálogo para Snowflake Open Catalog. O Snowflake sincroniza tabelas que usam a integração de catálogo especificada com sua conta Snowflake Open Catalog. Para obter mais informações, consulte Sincronizar uma tabela gerenciada pelo Snowflake com Snowflake Open Catalog.
- Valores:
O nome de qualquer integração de catálogo existente para o Open Catalog.
- Padrão:
Nenhum
CLIENT_ENABLE_LOG_INFO_STATEMENT_PARAMETERS¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Clientes:
JDBC
- Descrição:
Permite que os usuários registrem os valores de dados vinculados a PreparedStatements.
Para ver os valores, você deve não só definir esse parâmetro de nível de sessão para
TRUE, mas também definir o parâmetro de conexão chamadoTRACINGparaINFOouALL.Defina
TRACINGcomoALLpara ver todas as informações de depuração e todas as informações obrigatórias.Defina
TRACINGcomoINFOpara ver os valores de parâmetros vinculados e menos outras informações de depuração.
Cuidado
Se você vincular informações confidenciais, tais como diagnósticos médicos ou senhas, essas informações serão registradas. O Snowflake recomenda certificar-se de que o arquivo de log seja seguro, ou somente usar dados de teste, quando você definir esse parâmetro como
TRUE.- Valores:
TRUEouFALSE.- Padrão:
FALSE
CLIENT_ENCRYPTION_KEY_SIZE¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Inteiro
- Clientes:
Qualquer
- Descrição:
Especifica o tamanho da chave de criptografia AES, em bits, utilizada pelo Snowflake para criptografar/descriptografar arquivos armazenados em estágios internos (para carregamento/descarregamento de dados) quando você usa o tipo de criptografia
SNOWFLAKE_FULL.- Valores:
128ou256- Padrão:
128
Nota
Esse parâmetro não é usado para criptografar/descriptografar arquivos armazenados em estágios externos (ou seja, buckets S3 ou contêineres do Azure). A criptografia/descriptografia desses arquivos é realizada usando uma chave de criptografia externa explicitamente especificada no comando COPY ou no estágio externo nomeado referenciado no comando.
Se você estiver usando o driver JDBC e quiser definir esse parâmetro como 256 (para criptografia forte), arquivos adicionais de política JCE devem ser instalados em cada máquina cliente da qual os dados são carregados/descarregados. Para obter mais informações sobre a instalação dos arquivos necessários, consulte Requisitos Java para o driver JDBC.
Se você estiver usando o conector Python (ou SnowSQL) e quiser definir este parâmetro como 256 (para criptografia forte), não são necessárias tarefas adicionais de instalação ou configuração.
CLIENT_MEMORY_LIMIT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Clientes:
JDBC, ODBC
- Descrição:
Parâmetro que especifica a quantidade máxima de memória que o driver JDBC ou ODBC deve usar para o conjunto de resultados de consultas (em MB).
Para o driver JDBC:
Para simplificar o gerenciamento da memória da JVM, o parâmetro define um limite máximo de utilização de memória global para todas as consultas.
CLIENT_RESULT_CHUNK_SIZE especifica o tamanho máximo de cada conjunto (ou parte) de resultados de consulta para download (em MB). O driver pode exigir memória adicional para processar uma parte; se isso ocorrer, ele ajustará o uso da memória durante a execução para processar pelo menos um thread/consulta. Verifique se o CLIENT_MEMORY_LIMIT está definido num valor consideravelmente mais alto do que o CLIENT_RESULT_CHUNK_SIZE para garantir que há uma disponibilidade de memória suficiente.
Para o driver ODBC:
Esse parâmetro é suportado na versão 2.22.0 e superior.
CLIENT_RESULT_CHUNK_SIZEnão é suportado.
Nota
O driver tentará honrar o valor do parâmetro, mas limitará o uso a 80% da memória do seu sistema.
O limite de uso de memória definido neste parâmetro não se aplica a qualquer outra operação de driver JDBC ou ODBC (por exemplo, conectar ao banco de dados, preparar uma consulta ou instruções PUT e GET).
- Valores:
Qualquer número válido de megabytes.
- Padrão:
1536(efetivamente 1,5 GB)A maioria dos usuários não deve precisar definir este parâmetro. Se este parâmetro não for definido pelo usuário, o driver começa com o padrão especificado acima.
Além disso, o driver JDBC gerencia ativamente sua memória de forma conservadora para evitar o uso de toda a memória disponível.
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Clientes:
JDBC, ODBC
- Descrição:
Para funções ODBC e métodos JDBC específicos, esse parâmetro pode alterar o escopo de busca padrão de todos os bancos de dados/esquemas para o banco de dados/esquema atual. Normalmente, a busca mais específica retorna menos linhas e é executada mais rapidamente.
Por exemplo, o método
getTables()do JDBC aceita um nome de banco de dados e um nome de esquema como argumentos, e retorna os nomes das tabelas do banco de dados e do esquema. Se os argumentos do banco de dados e esquemas foremnull, por padrão, o método pesquisará todos os bancos de dados e todos os esquemas na conta. A definição CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX paraTRUErestringe a busca ao banco de dados e esquema atual especificado pelo contexto de conexão.Em essência, a definição desse parâmetro para
TRUEcria a seguinte precedência para o banco de dados e esquema:Valores passados como argumentos para as funções/métodos.
Valores especificados no contexto de conexão (se houver).
Padrão (todos os bancos de dados e todos os esquemas).
Para obter mais detalhes, consulte as informações abaixo.
Esse parâmetro se aplica ao seguinte:
Métodos de driver JDBC (para a classe
DatabaseMetaData):getColumnsgetCrossReferencegetExportedKeysgetForeignKeysgetFunctionsgetImportedKeysgetPrimaryKeysgetSchemasgetTables
Funções do driver ODBC:
SQLTablesSQLColumnsSQLPrimaryKeysSQLForeignKeysSQLGetFunctionsSQLProcedures
- Valores:
TRUE: Se os argumentos do banco de dados e esquema sãonull, o driver recupera metadados apenas para o banco de dados e esquema especificado pelo contexto de conexão.A interação é descrita com mais detalhes na tabela abaixo.
FALSE: Se os argumentos do banco de dados e esquemas foremnull, o driver recupera metadados para todos os bancos de dados e esquemas da conta.- Padrão:
FALSE- Notas adicionais:
O contexto de conexão se refere ao banco de dados e esquema atual da sessão, que pode ser definido usando qualquer uma das seguintes opções:
Especificar o namespace padrão para o usuário que se conecta ao Snowflake (e inicia a sessão). Isso pode ser definido para o usuário através do comando CREATE USER ou ALTER USER, mas deve ser definido antes que o usuário se conecte.
Especificar o banco de dados e o esquema ao se conectar ao Snowflake através do driver.
Emitir um comando USE DATABASE ou USE SCHEMA dentro da sessão.
Se o banco de dados ou esquema tiver sido especificado por mais de um destes, o mais recente se aplica.
Quando CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX está definido para
TRUE:database argument
schema argument
Base de dados utilizada
Esquema utilizado
Não-nulo
Não-nulo
Argumento
Argumento
Não-nulo
Nulo
Argumento
Todos os esquemas
Nulo
Não-nulo
Contexto de conexão
Argumento
Nulo
Nulo
Contexto de conexão
Contexto de sessão
Nota
Para o driver JDBC, esse comportamento se aplica à versão 3.6.27 (e superior). Para o driver ODBC, esse comportamento se aplica à versão 2.12.96 (e superior).
Se você quiser pesquisar somente o banco de dados do contexto de conexão, mas quiser pesquisar todos os esquemas dentro desse banco de dados, veja CLIENT_METADATA_USE_SESSION_DATABASE.
CLIENT_METADATA_USE_SESSION_DATABASE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Clientes:
JDBC
- Descrição:
Esse parâmetro se aplica somente aos métodos afetados por CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX.
Esse parâmetro se aplica somente quando ambas as condições a seguir são cumpridas:
CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX é
FALSEou não definido.Nenhum banco de dados ou esquema é passado para a função ODBC ou método JDBC relevante.
Para funções ODBC e métodos JDBC específicos, esse parâmetro pode alterar o escopo padrão de busca de todos os bancos de dados para o banco de dados atual. Normalmente, a busca mais específica retorna menos linhas e é executada mais rapidamente.
Para obter mais detalhes, consulte as informações abaixo.
- Valores:
TRUE:O driver pesquisa todos os esquemas no banco de dados do contexto de conexão. (Para obter mais detalhes sobre o contexto de conexão, veja a documentação para CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX).
FALSE:O driver pesquisa todos os esquemas em todos os bancos de dados.
- Padrão:
FALSE- Notas adicionais:
Quando o banco de dados é null e o esquema é null e CLIENT_METADATA_REQUEST_USE_CONNECTION_CTX é FALSE:
CLIENT_METADATA_USE_SESSION_DATABASE
Comportamento
FALSE
Todos os esquemas em todos os bancos de dados são pesquisados.
TRUE
Todos os esquemas no banco de dados atual são pesquisados.
CLIENT_PREFETCH_THREADS¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Clientes:
JDBC, ODBC, Python, .NET
- Descrição:
Parâmetro que especifica o número de threads usados pelo cliente para pré-preencher grandes conjuntos de resultados. O driver tentará honrar o valor do parâmetro, mas define os valores mínimo e máximo (dependendo dos recursos do seu sistema) para melhorar o desempenho.
- Valores:
1a10- Padrão:
4A maioria dos usuários não deve precisar definir este parâmetro. Se esse parâmetro não for definido pelo usuário, o driver começará com o padrão especificado acima, mas também gerenciará ativamente sua contagem de threads de forma conservadora para evitar o uso de toda a memória disponível.
CLIENT_RESULT_CHUNK_SIZE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Clientes:
JDBC, Node.js, SQL API, Go
- Descrição:
Parâmetro que especifica o tamanho máximo de cada conjunto (ou parte) de resultados de consulta para download (em MB). O driver JDBC baixa os resultados de consultas em partes.
Consulte também CLIENT_MEMORY_LIMIT.
- Valores:
16a160- Padrão:
160A maioria dos usuários não deve precisar definir este parâmetro. Se esse parâmetro não for definido pelo usuário, o driver começará com o padrão especificado acima, mas também gerenciará ativamente sua memória de forma conservadora para evitar o uso de toda a memória disponível.
CLIENT_RESULT_COLUMN_CASE_INSENSITIVE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Clientes:
JDBC
- Descrição:
Parâmetro que indica se o nome da coluna deve ser buscado sem diferenciar maiúsculas e minúsculas em métodos
ResultSet.get*no JDBC.- Valores:
TRUE: busca os nomes das colunas sem diferenciar maiúsculas e minúsculas.FALSE: busca os nomes das colunas diferenciando maiúsculas e minúsculas.- Padrão:
FALSE
CLIENT_SESSION_KEEP_ALIVE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Clientes:
.NET, Golang, JDBC, Node.js, ODBC, Python,
- Descrição:
Parâmetro que indica se o usuário deve ser forçado a fazer o login novamente após um período de inatividade na sessão.
- Valores:
TRUE: O Snowflake mantém a sessão ativa indefinidamente enquanto a conexão estiver ativa, mesmo que não haja atividade do usuário.FALSE: O usuário deve fazer login novamente após quatro horas de inatividade.- Padrão:
FALSE
Nota
Atualmente, o parâmetro só entra em vigor ao iniciar a sessão. Você pode modificar o valor do parâmetro no nível da sessão executando um comando ALTER SESSION, mas isso não afeta a funcionalidade de manutenção de atividade da sessão, como estender a sessão. Para obter mais informações sobre como definir o parâmetro no nível da sessão, consulte a documentação do cliente:
CLIENT_SESSION_KEEP_ALIVE_HEARTBEAT_FREQUENCY¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Clientes:
SnowSQL, JDBC, Python, Node.js
- Descrição:
Número de segundos entre as tentativas do cliente para atualizar o token para a sessão.
- Valores:
900a3600- Padrão:
3600
CLIENT_TIMESTAMP_TYPE_MAPPING¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Clientes:
Qualquer
- Descrição:
Especifica a variação TIMESTAMP_* a ser usada ao vincular variáveis de carimbo de data/hora para aplicativos JDBC ou ODBC que usam a API de vinculação para carregar dados.
- Valores:
TIMESTAMP_LTZouTIMESTAMP_NTZ- Padrão:
TIMESTAMP_LTZ
CORTEX_MODELS_ALLOWLIST¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica os modelos que os usuários da conta podem acessar. Use esse parâmetro para permitir modelos de lista para todos os usuários da conta. Se precisar fornecer acesso a usuários específicos além do que foi especificado na lista de permissões, use o controle de acesso baseado em função. Para obter mais informações, consulte Parâmetro de lista de permissões no nível da conta.
Quando os usuários fazem uma solicitação, o Snowflake Cortex avalia o parâmetro para determinar se o usuário pode acessar o modelo.
- Valores:
'All': fornece acesso a todos os modelos, incluindo modelos ajustados.Exemplo:
'model1,model2,...': fornece acesso aos modelos especificados em uma lista separada por vírgulas.Exemplo:
'None': impede o acesso a qualquer modelo.Exemplo:
- Padrão:
'All'
CORTEX_ENABLED_CROSS_REGION¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica as regiões onde uma solicitação de inferência pode ser processada caso a solicitação não possa ser processada na região onde a solicitação foi originalmente feita. Especificar
DISABLEDdesabilita a inferência entre regiões. Para exemplos e detalhes, consulte Inferência entre regiões.- Valores:
Este parâmetro pode ser definido como um dos seguintes:
DISABLEDANY_REGIONLista separada por vírgulas incluindo um ou mais dos seguintes valores:
AWS_APJAWS_AUAWS_EUAWS_USAWS_GLOBALAZURE_EUAZURE_USAZURE_GLOBALGCP_USGCP_GLOBAL
Explicação de cada valor de parâmetro¶ Valor
Comportamento
DISABLEDAs solicitações de inferência serão tratadas em:
A região onde a solicitação é feita.
ANY_REGIONAs solicitações de inferência podem ser encaminhadas para:
Qualquer região que ofereça suporte à inferência entre regiões (listada nesta tabela) e que tenha disponibilidade, incluindo a região onde a solicitação é feita.
AWS_APJAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nos seguintes AWS Regiões
AWS Ásia Pacífico (Tokyo) ap-northeast-1
AWS Ásia Pacífico (Seul) ap-northeast-2
AWS Ásia Pacífico (Osaka) ap-northeast-3
AWS Ásia Pacífico (Mumbai) ap-south-1
AWS Ásia Pacífico (Hyderabad) ap-south-2
AWS Ásia Pacífico (Singapura) ap-southeast-1
AWS Ásia Pacífico (Sydney) ap-southeast-2
AWS Ásia Pacífico (Melbornne) ap-southeast-4
AWS_AUAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nos seguintes AWS Regiões
AWS Ásia-Pacífico (Sydney) ap-southeast-2
AWS Ásia Pacífico (Melbornne) ap-southeast-4
AWS_EUAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nos seguintes AWS Regiões, que estão (e estarão) localizadas dentro da União Europeia:
AWS Europa (Frankfurt) eu-central-1
AWS Europa (Estocolmo) eu-north-1
AWS Europa (Milão) eu-south-1
AWS Europa (Espanha) eu-south-2
AWS Europa (Irlanda) eu-west-1
AWS Europa (Paris) eu-west-3
AWS_USAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nos seguintes AWS Regiões, que estão (e estarão) localizadas nos Estados Unidos:
AWS US Leste (Virgínia do Norte) us-east-1
AWS US Leste (Ohio) us-east-2
AWS US Oeste (Oregon) us-west-2
AWS_GlobalAs solicitações de inferência serão tratadas na região onde a solicitação for feita e em qualquer região comercial da AWS.
AZURE_EUAs solicitações de inferência serão tratadas na região onde a solicitação é feita e nas seguintes regiões do Azure, que estão (e estarão) localizadas na União Europeia:
Azure Europa (Países Baixos) westeurope
Azure Europa (França) francecentral
Azure Europa (Alemanha) germanywestcentral
Azure Europa (Itália) italynorth
Azure Europa (Polônia) polandcentral
Azure Europa (Espanha) spaincentral
Azure Europa (Suécia) swedencentral
AZURE_USAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nas seguintes regiões do Azure, que estão (e estarão) localizadas nos Estados Unidos:
Azure US (Virgínia) eastus2
Azure US (Virgínia) eastus
Azure US (Califórnia) westus
Azure US (Phoenix) westus3
Azure US (Illinois) northcentralus
Azure US (Texas) southcentralus
AZURE_GlobalAs solicitações de inferência serão tratadas na região onde a solicitação for feita e em qualquer região comercial do Azure.
GCP_USAs solicitações de inferência serão tratadas na região onde a solicitação for feita e nos seguintes GCP Regiões, que estão (e estarão) localizadas nos Estados Unidos:
GCP US (Iowa) us-central1
GCP US (Oregon) us-west1
GCP US (Las Vegas) us-west4
GCP US (N. Virginia) us-east4
GCP_GlobalAs solicitações de inferência serão tratadas na região onde a solicitação for feita e em qualquer região comercial da GCP.
- Padrão:
O valor padrão depende de quando e onde a conta foi criada:
ANY_REGIONpara novas contas em novas organizações em regiões comerciais criadas após 9 de março de 2026.DISABLEDpara todas as outras contas, incluindo regiões governamentais.
CSV_TIMESTAMP_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato para valores TIMESTAMP em arquivos CSV baixados do Snowsight.
Se este parâmetro não for definido, TIMESTAMP_LTZ_OUTPUT_FORMAT será usado para valores TIMESTAMP_LTZ, TIMESTAMP_TZ_OUTPUT_FORMAT será usado para TIMESTAMP_TZ e TIMESTAMP_NTZ_OUTPUT_FORMAT para valores TIMESTAMP_NTZ.
Para obter mais informações, consulte Formatos de entrada e saída de data e hora ou Como baixar os resultados de sua consulta.
- Valores:
Qualquer formato de carimbo de data/hora válido e compatível.
- Padrão:
Sem valor.
DATA_METRIC_SCHEDULE¶
- Tipo:
Objeto (para tabelas)
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o agendamento para executar as funções de métricas de dados associadas à tabela.
- Valores:
O agendamento pode ser baseado em um número definido de minutos, uma expressão cron ou um evento DML na tabela que não envolve reclustering. Para obter mais detalhes, consulte:
- Padrão:
60 MINUTE
DATA_RETENTION_TIME_IN_DAYS¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido para Conta » Base de dados » Esquema » Tabela
- Tipo de dados:
Inteiro
- Descrição:
Número de dias para os quais o Snowflake retém dados históricos para realizar ações de Time Travel (SELECT, CLONE, UNDROP) no objeto. Um valor de
0desabilita efetivamente o Time Travel para o banco de dados, esquema ou tabela especificado. Para obter mais informações, consulte Compreensão e uso do Time Travel.- Valores:
0ou1(para Standard Edition)0para90(para Enterprise Edition ou superior)- Padrão:
1
DATE_INPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de entrada para o tipo de dados DATE. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de data válido e suportado ou
AUTO(
AUTOespecifica que o Snowflake tenta detectar automaticamente o formato das datas armazenadas no sistema durante a sessão)- Padrão:
AUTO
DATE_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados DATE. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de data válido e suportado
- Padrão:
YYYY-MM-DD
DEFAULT_DBT_VERSION¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Specifies the default version for all future dbt project objects created in an account. Setting this value on the account enables organization administrators to opt-in to newer versions (for example, changing the default to
1.10.15) without requiring users to manually update CREATE DBT PROJECT DDL statements for every individual project. For more information, see Definir a versão padrão no nível da conta.- Valores:
1.9.4ou1.10.15- Padrão:
1.9.4
DEFAULT_DDL_COLLATION¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido para Conta » Base de dados » Esquema » Tabela
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Define o agrupamento padrão utilizado para as seguintes operações DDL:
ALTER TABLE … ADD COLUMN
A definição desse parâmetro força todas as colunas criadas posteriormente nos objetos afetados (tabela, esquema, banco de dados ou conta) a ter o agrupamento especificado como padrão, a menos que o agrupamento da coluna esteja explicitamente definido no DDL.
Por exemplo, se
DEFAULT_DDL_COLLATION = 'en-ci', as duas instruções a seguir são equivalentes:Nota
Este parâmetro não é suportado para tabelas dinâmicas e Tabelas Apache Iceberg™. Este parâmetro não é compatível com colunas indexadas para tabelas híbridas.
- Valores:
Qualquer especificação de agrupamento válido e suportado.
- Padrão:
Cadeia de caracteres vazia
Nota
Para definir o agrupamento padrão para a conta, use o seguinte comando:
O agrupamento padrão das colunas da tabela pode ser definido no nível da tabela, esquema ou banco de dados durante a criação ou a qualquer momento posteriormente:
DEFAULT_NOTEBOOK_COMPUTE_POOL_CPU¶
- Tipo:
Objeto (para bancos de dados e esquemas) — Pode ser definido como Conta » Banco de dados » Esquema
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Define o pool de computação preferencial de CPU usado para Notebooks no CPU Container Runtime.
- Valores:
Nome de um pool de computação em sua conta.
- Padrão:
SYSTEM_COMPUTE_POOL_CPU (consulte Pools de computação do sistema).
DEFAULT_NOTEBOOK_COMPUTE_POOL_GPU¶
- Tipo:
Objeto (para bancos de dados e esquemas) — Pode ser definido como Conta » Banco de dados » Esquema
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Define o pool de computação preferencial de GPU usado para Notebooks no GPU Container Runtime.
- Valores:
Nome de um pool de computação em sua conta.
- Padrão:
SYSTEM_COMPUTE_POOL_GPU (consulte Pools de computação do sistema).
DEFAULT_NULL_ORDERING¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica a ordenação padrão dos valores NULL em um conjunto de resultados.
A ordem dos valores NULL nas linhas depende da cláusula ORDER BY:
Quando a ordem de classificação é ASC (o padrão) e esse parâmetro é definido como
LAST(o padrão), os valores NULL são retornados por último. Portanto, a menos que especificado de outra forma, os valores NULL são considerados mais altos do que quaisquer valores diferentes de NULL.Quando a ordem de classificação é ASC e esse parâmetro é definido como
FIRST, os valores NULL são retornados primeiro.Quando a ordem de classificação é DESC e esse parâmetro é definido como
FIRST, os valores NULL são retornados por último.Quando a ordem de classificação é DESC e esse parâmetro é definido como
LAST, os valores NULL são retornados primeiro.
Se uma ordem NULL for especificada na cláusula ORDER BY com NULLS FIRST ou NULLS LAST, a ordem especificada terá precedência sobre qualquer valor de DEFAULT_NULL_ORDERING.
- Valores:
FIRST: os valores NULL são inferiores a qualquer valor diferente de NULL.LAST: os valores NULL são superiores a qualquer valor diferente de NULL.- Padrão:
LAST
DEFAULT_STREAMLIT_COMPUTE_POOL¶
- Tipo:
Conta — Só pode ser definido para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o pool de computação padrão a ser utilizado para apps Streamlit com tempo de execução de contêiner.
Quando você executa CREATE STREAMLIT, se você especifica um tempo de execução de contêiner na propriedade RUNTIME_NAME e não especifica a propriedade COMPUTE_POOL, o Snowflake usa o pool de computação especificado no parâmetro DEFAULT_STREAMLIT_COMPUTE_POOL. Esse pool de computação padrão é resolvido no momento da criação. A atualização de DEFAULT_STREAMLIT_COMPUTE_POOL não atualizará a propriedade COMPUTE_POOL em apps Streamlit existentes. Para obter mais informações, consulte Configurando os próprios pools de computação preferidos para apps Streamlit.
- Valores:
Nome de um pool de computação em sua conta.
- Padrão:
SYSTEM_COMPUTE_POOL_CPU
DEFAULT_STREAMLIT_NOTEBOOK_WAREHOUSE¶
- Tipo:
Objeto (para bancos de dados e esquemas) — Pode ser definido como Conta » Banco de dados » Esquema
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome do warehouse padrão a ser usado ao criar um notebook.
Para obter mais informações, consulte ALTER ACCOUNT, ALTER DATABASE e ALTER SCHEMA.
- Valores:
O nome de qualquer warehouse existente.
- Padrão:
SYSTEM$STREAMLIT_NOTEBOOK_WH
DISABLE_USER_PRIVILEGE_GRANTS¶
- Tipo:
Objeto (para usuários) — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Controla se os usuários de uma conta podem conceder privilégios diretamente a outros usuários.
Desabilitar as concessões de privilégios de usuário (ou seja, definir DISABLE_USER_PRIVILEGE_GRANTS como
TRUE) não afeta as concessões existentes aos usuários. As concessões existentes aos usuários continuam dando privilégios a eles. Para obter mais informações, consulte GRANT <privilégios> … TO USER.- Valores:
TRUE: os usuários da conta não podem conceder privilégios a outro usuário.FALSE: os usuários da conta podem conceder privilégios a outro usuário.- Padrão:
FALSE
DISALLOWED_SPCS_WORKLOAD_TYPES¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica os tipos de carga de trabalho que não são permitidos em sua conta para implantação no Snowpark Container Services. Consulte também ALLOWED_SPCS_WORKLOAD_TYPES.
- Valores:
O valor é uma lista separada por vírgulas dos seguintes tipos de carga de trabalho compatíveis:
USER: Qualquer carga de trabalho implantada diretamente pelos usuários.NOTEBOOK: notebooks Snowflake.STREAMLIT: Streamlit no Snowflake.MODEL_SERVING: serviço de modelo ML.ML_JOB: trabalhos ML do Snowflake.ALL: todas as cargas de trabalho.
- Padrão:
Cadeia de caracteres vazia
Nota
Se você configurar ambos os parâmetros DISALLOWED_SPCS_WORKLOAD_TYPES e ALLOWED_SPCS_WORKLOAD_TYPES, o Snowflake aplicará primeiro DISALLOWED_SPCS_WORKLOAD_TYPES. Por exemplo, se você configurar esses dois parâmetros e especificar a carga de trabalho de NOTEBOOK, as cargas de trabalho de NOTEBOOK não poderão ser executadas no Snowpark Container Services.
ENABLE_AUTOMATIC_SENSITIVE_DATA_CLASSIFICATION_LOG¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Controla se os eventos de classificação de dados confidenciais são registrados na tabela de eventos do usuário.
- Valores:
TRUE: o Snowflake registra os eventos de classificação de dados confidenciais na tabela de eventos do usuário.FALSE: os eventos de classificação de dados confidenciais não são registrados.- Padrão:
TRUE
ENABLE_BUDGET_EVENT_LOGGING¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Controla se os dados de telemetria são coletados para orçamentos.
- Valores:
TRUE: o Snowflake registra os dados de telemetria relacionados aos orçamentos em uma tabela de eventos.FALSE: o Snowflake não registra os dados de telemetria relacionados a orçamentos.- Padrão:
TRUE
ENABLE_DATA_COMPACTION¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas Iceberg) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Booliano
- Descrição:
Especifica se o Snowflake deve ativar a compactação de dados em Tabelas Apache Iceberg™ gerenciadas pelo Snowflake.
- Valores:
TRUE: o Snowflake realiza a compactação de dados nas tabelas.FALSE: o Snowflake não realiza a compactação de dados nas tabelas.- Padrão:
TRUE
ENABLE_EGRESS_COST_OPTIMIZER¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Ativa ou desativa o otimizador de custo de saída do preenchimento automático entre nuvens da listagem.
- Valores:
TRUE: ativar o otimizador de custo de saída.FALSE: desativar o otimizador de custo de saída.- Padrão:
FALSE
Para obter mais informações, consulte Preenchimento automático de listagens.
ENABLE_GET_DDL_USE_DATA_TYPE_ALIAS¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a saída retornada pela função GET_DDL contém sinônimos de tipo de dados especificados na instrução DDL original. Os sinônimos de tipos de dados também são chamados de aliases de tipos de dados.
- Valores:
TRUE: Exibição dos aliases de tipo de dados especificados no original DDL Instrução.FALSE: Substitua os aliases dos tipos de dados especificados no original DDL Instrução com nomes de tipos de dados padrão do Snowflake.
Você pode definir este parâmetro como TRUE para gerar DDL Instruções usando o GET_DDL Função que especifica aliases de tipos de dados, conforme definido no original SQL Instruções, que podem ser necessárias para preservar a integridade do modelo de dados durante as migrações.
A seguir estão alguns exemplos de aliases de tipos de dados:
CHAR é um alias para o VARCHAR tipo de dados.
BIGINT é um alias para o NUMBER tipo de dados.
DATETIME é um alias para o TIMESTAMP_NTZ tipo de dados.
A instrução a seguir cria uma tabela usando os aliases para os tipos de dados:
Quando este parâmetro é definido como FALSE, o GET_DDL A função retorna a seguinte saída:
Quando este parâmetro é definido como TRUE, o GET_DDL A função retorna a seguinte saída:
- Padrão:
FALSE
ENABLE_ICEBERG_MERGE_ON_READ¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas Apache Iceberg™) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Booliano
- Descrição:
Especifica se o comportamento de mesclagem na leitura deve ser ativado para Tabelas Apache Iceberg™ gerenciadas pelo Snowflake. Para obter mais informações, consulte Use as exclusões em nível de linha.
- Valores:
TRUE: ative o comportamento de mesclagem na leitura:Se você usar o formato Iceberg v2 com tabelas Iceberg, habilitará o uso de exclusões em nível de linha por meio de arquivos de exclusão posicional.
Se você usar o formato Iceberg v3 com tabelas Iceberg, habilitará o uso de exclusões em nível de linha por meio de vetores de exclusão.
Para obter mais informações sobre o comportamento de mesclagem na leitura e de cópia na gravação, consulte Use as exclusões em nível de linha.
Nota
Para especificar a versão do Iceberg para tabelas, use o parâmetro ICEBERG_VERSION_DEFAULT ou o ICEBERG_VERSION.
FALSE: Habilita o comportamento de cópia na gravação para operações DML.- Padrão:
TRUE
ENABLE_IDENTIFIER_FIRST_LOGIN¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Determina o fluxo de login dos usuários. Quando ativado, o Snowflake solicita aos usuários seu nome de usuário ou endereço de e-mail antes de apresentar métodos de autenticação. Para obter mais detalhes, consulte Login com primeiro identificador.
- Valores:
TRUE: Snowflake usa um fluxo de login com primeiro identificador para autenticar usuários.FALSE: Snowflake apresenta todas as opções de login possíveis, mesmo que essas opções não se apliquem a um usuário específico.- Padrão:
FALSE
ENABLE_INTERNAL_STAGES_PRIVATELINK¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a função SYSTEM$GET_PRIVATELINK_CONFIG retorna a chave
private-internal-stagesno resultado da consulta. O valor correspondente no resultado da consulta é usado durante o processo de configuração da conectividade privada para estágios internos. O valor desse parâmetro também afeta o comportamento das funções do sistema relacionadas à conectividade privada. Por exemplo,TRUEativa SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS eFALSEdesativa SYSTEM$REVOKE_STAGE_PRIVATELINK_ACCESS.- Valores:
TRUE: Retorna a chaveprivate-internal-stagese o valor no resultado da consulta.FALSE: não retorna a chaveprivate-internal-stagese o valor no resultado da consulta.- Padrão:
FALSE
ENABLE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a função SYSTEM$GET_PRIVATELINK_CONFIG retorna as chaves
privatelink-snowflake-managed-storage-volume-nfseprivatelink-snowflake-managed-storage-volume-fsno resultado da consulta em implantações do Azure. Os valores correspondentes no resultado da consulta são utilizados durante o processo de configuração para conectividade privada com volumes de armazenamento gerenciados pelo Snowflake. O valor desse parâmetro também afeta o comportamento das funções do sistema relacionadas à conectividade privada. Por exemplo,TRUEhabilita SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS, eFALSEdesabilita SYSTEM$REVOKE_SNOWFLAKE_MANAGED_STORAGE_VOLUME_PRIVATELINK_ACCESS.- Valores:
TRUE: retorna os valores e as chavesprivatelink-snowflake-managed-storage-volume-nfseprivatelink-snowflake-managed-storage-volume-fsno resultado da consulta para implantações do Azure.FALSE: não retorna essas chaves e valores no resultado da consulta.- Padrão:
FALSE
ENABLE_NOTEBOOK_CREATION_IN_PERSONAL_DB¶
- Tipo:
Usuário – Pode ser definido para Conta > Usuário
- Tipo de dados:
Booliano
- Descrição:
Especifica se os usuários podem criar notebooks privados (armazenados em seus bancos de dados pessoais). Quando TRUE, os usuários da conta poderão criar notebooks privados (supondo que outros privilégios necessários sejam concedidos).
- Valores:
TRUE: permite que os usuários criem notebooks privados.FALSE: impede que os usuários criem notebooks privados.- Padrão:
FALSE
ENABLE_SPCS_BLOCK_STORAGE_SNOWFLAKE_FULL_ENCRYPTION_ENFORCEMENT¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Habilita a aplicação do tipo de criptografia SNOWFLAKE_FULL para volumes de armazenamento em bloco e instantâneos do Snowpark Container Services.
- Valores:
TRUE: Aplica a criação de volumes de armazenamento em bloco e instantâneos do SPCS somente com o tipo de criptografia SNOWFLAKE_FULL. O tipo de criptografia SNOWFLAKE_SSE não é permitido. Todos os volumes de armazenamento em bloco e snapshots existentes com o tipo de criptografia SNOWFLAKE_SSE devem ser migrados para SNOWFLAKE_FULL antes de habilitar esse parâmetro. A definição do valor do parâmetro como TRUE com volumes ou instantâneos criptografados com SNOWFLAKE_FULL resulta em erro.FALSE: ambos os tipos de criptografia SNOWFLAKE_SSE e SNOWFLAKE_FULL são permitidos para volumes de armazenamento em bloco e instantâneos do SPCS na conta.- Padrão:
FALSE
ENABLE_TAG_PROPAGATION_EVENT_LOGGING¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Controla se os dados de telemetria são coletados para propagação automática de tag.
- Valores:
TRUE: o Snowflake registra os dados de telemetria relacionados à propagação de tags em uma tabela de eventos.FALSE: o Snowflake não registra os dados de telemetria relacionados à propagação de tags.- Padrão:
FALSE
ENABLE_TRI_SECRET_AND_REKEY_OPT_OUT_FOR_IMAGE_REPOSITORY¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica a opção do repositório de imagens para desativar Tri-Secret Secure e Periodic Rekeying.
- Valores:
TRUE: desativa o rechaveamento periódico e o Tri-Secret Secure no repositório de imagens.FALSE: não permite a criação de um repositório de imagens para Tri-Secret Secure e rechaveamento periódico nas contas. Da mesma forma, não permite habilitar Tri-Secret Secure e rechaveamento periódico em contas com o repositório de imagens habilitado.- Padrão:
FALSE
ENABLE_UNHANDLED_EXCEPTIONS_REPORTING¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se o Snowflake pode capturar – em uma tabela de eventos – mensagens de log ou rastrear dados de eventos para exceções não tratadas no código do manipulador da UDF ou procedimento. Para obter mais informações, consulte Captura de mensagens de exceções não tratadas.
- Valores:
TRUE: os dados sobre exceções não tratadas serão capturados como dados de log ou de rastreamento se a criação de log e o rastreamento estiverem ativados.FALSE: os dados sobre exceções não tratadas não são capturados.- Padrão:
TRUE
ENABLE_UNLOAD_PHYSICAL_TYPE_OPTIMIZATION¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se o esquema deve ser definido para arquivos Parquet descarregados com base nos tipos de dados de coluna lógica (ou seja, os tipos na consulta SQL ou na tabela de origem) ou nos valores de coluna descarregados (ou seja, os menores tipos de dados e precisão que suportam os valores nas colunas de saída da instrução SQL ou da tabela de origem).
- Valores:
TRUE: O esquema dos arquivos de dados de Parquet descarregados é determinado pelos valores da coluna na consulta de descarregamentoSQL ou tabela de origem. O Snowflake otimiza as colunas da tabela ao definir a menor precisão que aceita todos os valores. O descarregador segue esse padrão ao escrever valores em arquivos Parquet. O tipo de dados e a precisão de uma coluna de saída são definidos para o menor tipo de dados e precisão que oferecem suporte para seus valores na instrução de descarregamento SQL ou tabela de origem. Aceite essa configuração para obter um melhor desempenho e arquivos de dados menores.FALSE: O esquema é determinado pelos tipos de dados da coluna lógica. Defina este valor para um esquema de arquivo de saída consistente.- Padrão:
TRUE
ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR¶
- Tipo:
Usuário — Pode ser definido para Conta » Usuário
- Tipo de dados:
Booliano
- Descrição:
Controla se o texto da consulta é excluído se uma consulta SQL falhar devido a um erro de sintaxe ou de análise. Se
FALSE, o conteúdo de uma consulta com falha é editado nas exibições, páginas e funções que fornecem um histórico de consulta.Somente os usuários com uma função que recebeu ou herdou o privilégio AUDIT podem definir o parâmetro ENABLE_UNREDACTED_QUERY_SYNTAX_ERROR.
Ao usar o comando ALTER USER para definir o parâmetro como
TRUEpara um determinado usuário, modifique o usuário que deseja ver o texto da consulta, não o usuário que executou a consulta (se forem usuários diferentes).- Valores:
TRUE: desabilita a exclusão do texto da consulta para consultas que falham devido a um erro de sintaxe ou análise.FALSE: exclui o conteúdo de uma consulta das exibições, páginas e funções que fornecem um histórico de consulta quando uma consulta falha devido a um erro de sintaxe ou análise.- Padrão:
FALSE
ENABLE_UNREDACTED_SECURE_OBJECT_ERROR¶
- Tipo:
Usuário — Pode ser definido para Conta » Usuário
- Tipo de dados:
Booliano
- Descrição:
Controla se as mensagens de erro relacionadas a objetos seguros são editadas nos metadados. Para obter mais informações, consulte Objetos seguros: edição de informações em mensagem de erro.
Somente os usuários com uma função que recebeu ou herdou o privilégio AUDIT podem definir o parâmetro ENABLE_UNREDACTED_SECURE_OBJECT_ERROR.
Ao usar o comando ALTER USER para definir o parâmetro
TRUEpara um usuário específico, modifique o usuário que deseja ver as mensagens de erro redigidas nos metadados, não o usuário que causou o erro.- Valores:
TRUE: desativa a censura de mensagens de erro relacionadas a objetos seguros em metadados.FALSE: censura o conteúdo de mensagens de erro relacionadas a objetos seguros em metadados.- Padrão:
FALSE
ENFORCE_NETWORK_RULES_FOR_INTERNAL_STAGES¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se uma política de redes que usa regras de rede pode restringir o acesso a estágios internos de AWS.
Este parâmetro não tem efeito nas políticas de redes que não utilizam regras de rede.
Esse parâmetro no nível da conta afeta as políticas de rede no nível da conta e no nível do usuário.
Para obter detalhes sobre o uso de políticas e regras de rede para restringir o acesso a estágios internos de AWS, incluindo o uso deste parâmetro, consulte Proteção de estágios internos no AWS.
- Valores:
TRUE: permite que as políticas de redes que usam regras de rede restrinjam o acesso aos estágios internos do AWS. A regra de rede também deve usarMODEeTYPEapropriados para restringir o acesso ao estágio interno.FALSE: as políticas de redes nunca restringem o acesso a estágios internos.- Padrão:
FALSE
ENFORCE_NETWORK_RULES_FOR_SNOWFLAKE_MANAGED_STORAGE_VOLUME¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se uma política de redes que usa regras de rede pode restringir o acesso a volumes de armazenamento gerenciados pelo AWS Snowflake.
Este parâmetro não tem efeito nas políticas de redes que não utilizam regras de rede.
Esse parâmetro em nível de conta afeta apenas as políticas de redes em nível de conta.
Para obter detalhes sobre como usar políticas e regras de rede para restringir o acesso a volumes de armazenamento gerenciados pelo Snowflake, consulte Protegendo volumes de armazenamento gerenciados pelo Snowflake na AWS.
- Valores:
TRUE: permite que políticas de redes que usam regras de rede restrinjam o acesso a volumes de armazenamento gerenciados pelo Snowflake. A regra de rede também deve usar os valoresMODEeTYPEapropriados para restringir o acesso ao volume.FALSE: as políticas de redes nunca restringem o acesso a volumes de armazenamento gerenciados pelo Snowflake.- Padrão:
FALSE
ERROR_ON_NONDETERMINISTIC_MERGE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se um erro deve ser retornado quando o comando MERGE é usado para atualizar ou excluir uma linha de destino que une várias linhas de origem e o sistema não pode determinar a ação a ser executada na linha de destino.
- Valores:
TRUE: É retornado um erro que inclui valores de uma das linhas de destino que causaram o erro.FALSE: Nenhum erro é retornado e a fusão é concluída com sucesso, mas os resultados da fusão não são determinísticos.- Padrão:
TRUE
ERROR_ON_NONDETERMINISTIC_UPDATE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se um erro deve ser retornado quando o comando UPDATE é usado para atualizar uma linha de destino que une várias linhas de origem e o sistema não pode determinar a ação a ser executada na linha de destino.
- Valores:
TRUE: É retornado um erro que inclui valores de uma das linhas de destino que causaram o erro.FALSE: Nenhum erro é retornado e a atualização é concluída, mas os resultados da atualização não são determinísticos.- Padrão:
FALSE
EVENT_TABLE¶
- Tipo:
Objeto — Pode ser definido para Conta » Banco de dados
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome da tabela de eventos para registrar mensagens de procedimentos armazenados e UDFs contidos no objeto ao qual a tabela de eventos está associada.
A associação de uma tabela de eventos a um banco de dados está disponível em Enterprise Edition ou superior.
- Valores:
Qualquer tabela de eventos existente criada com a execução do comando CREATE EVENT TABLE.
- Padrão:
Nenhum
EXTERNAL_OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Determina se as funções ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN podem ser usadas como função principal ao criar uma sessão do Snowflake com base no token de acesso do servidor de autorização externa OAuth.
- Valores:
TRUE: adiciona as funções ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN à propriedadeEXTERNAL_OAUTH_BLOCKED_ROLES_LISTda integração de segurança externa OAuth, o que significa que estas funções não podem ser usadas como a função principal ao criar uma sessão do Snowflake usando uma autenticação externa OAuth.FALSE: remove os ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN da lista de funções bloqueadas definidas pela propriedadeEXTERNAL_OAUTH_BLOCKED_ROLES_LISTda integração de segurança externa OAuth.- Padrão:
TRUE
EXTERNAL_VOLUME¶
Objeto (para bancos de dados, esquemas e tabelas Apache Iceberg™) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o volume externo para tabelas Apache Iceberg™. Para obter mais informações, consulte a documentação da tabela Iceberg.
- Valores:
Qualquer identificador de volume externo válido.
- Padrão:
Nenhum
GEOGRAPHY_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Formato de exibição de valores GEOGRAPHY.
Para EWKT e EWKB, o SRID é sempre 4326 na saída. Consulte a nota sobre como lidar com EWKT e EWKB.
- Valores:
GeoJSONWKT,WKB,EWKTouEWKB- Padrão:
GeoJSON
GEOMETRY_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Formato de exibição de valores GEOMETRY.
- Valores:
GeoJSONWKT,WKB,EWKTouEWKB- Padrão:
GeoJSON
HYBRID_TABLE_LOCK_TIMEOUT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Descrição:
Número de segundos a aguardar ao tentar adquirir bloqueios em nível de linha em uma tabela híbrida, antes de atingir o tempo limite e abortar a instrução.
- Valores:
0para qualquer inteiro (sem limite). Um valor de0desabilita a espera de bloqueio (ou seja, a instrução deve adquirir o bloqueio imediatamente ou será abortada). Este valor especifica quanto tempo a instrução aguardará por todos os bloqueios em nível de linha que ela precisa adquirir após cada tentativa de execução (1 hora por padrão). Se a instrução não puder adquirir todos os bloqueios, ela poderá ser tentada novamente, e o mesmo período de espera será aplicado.- Padrão:
3600(1 hora)
Consulte também LOCK_TIMEOUT.
ICEBERG_VERSION¶
- Tipo:
Objeto (para tabelas Apache Iceberg™) – pode ser definido apenas para tabelas Apache Iceberg™
- Tipo de dados:
Inteiro
- Descrição:
Especifica a versão da especificação Apache Iceberg™ à qual a tabela está em conformidade. Se você usar o parâmetro ICEBERG_VERSION_DEFAULT para especificar a versão padrão do Iceberg em um nível superior, esse parâmetro substituirá o padrão. Você pode especificar uma versão do Iceberg para tabelas Iceberg gerenciadas pelo Snowflake e tabelas Iceberg gerenciadas externamente que você cria em um banco de dados vinculado a catálogo.
Cuidado
Antes de usar outros mecanismos para atualizar a versão de formato de uma tabela Iceberg nas propriedades da tabela para a v3, certifique-se de que a tabela não esteja sendo utilizada por mecanismos ou aplicativos que ainda não são compatíveis com a v3. O downgrade de versões de formato não é compatível com a especificação Apache Iceberg. Portanto, todos os leitores e gravadores devem ser compatíveis com a v3. A versão padrão para tabelas Iceberg no Snowflake é a v2, que pode ser configurada para a v3, se necessário. No momento, não é possível usar o Snowflake para realizar atualizações de versão no local.
Nota
Você pode definir esse parâmetro durante a criação de uma tabela Iceberg usando o comando CREATE ICEBERG TABLE (Snowflake como o catálogo Iceberg) ou CREATE ICEBERG TABLE (catálogo REST Iceberg). Você não pode usar o comando ALTER ICEBERG TABLE para alterar essa configuração para uma tabela existente.
- Valores:
2: a tabela está em conformidade com a versão 2 do Iceberg.3: a tabela está em conformidade com a versão 3 do Iceberg.- Padrão:
2
ICEBERG_VERSION_DEFAULT¶
- Tipo:
Objeto (para bancos de dados e esquemas) — Pode ser definido como Conta » Banco de dados » Esquema
- Tipo de dados:
Inteiro
- Descrição:
Especifica a versão da especificação do Apache Iceberg™ a ser seguida ao criar novas tabelas Iceberg gerenciadas pelo Snowflake.
Cuidado
Antes de usar outros mecanismos para atualizar a versão de formato de uma tabela Iceberg nas propriedades da tabela para a v3, certifique-se de que a tabela não esteja sendo utilizada por mecanismos ou aplicativos que ainda não são compatíveis com a v3. O downgrade de versões de formato não é compatível com a especificação Apache Iceberg. Portanto, todos os leitores e gravadores devem ser compatíveis com a v3. A versão padrão para tabelas Iceberg no Snowflake é a v2, que pode ser configurada para a v3, se necessário. No momento, não é possível usar o Snowflake para realizar atualizações de versão no local.
Nota
Para definir a versão para uma tabela específica, defina o parâmetro ICEBERG_VERSION. Consulte ICEBERG_VERSION.
- Valores:
2: a tabela está em conformidade com a versão 2 do Iceberg.3: a tabela está em conformidade com a versão 3 do Iceberg.- Padrão:
2
INITIAL_REPLICATION_SIZE_LIMIT_IN_TB¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Número.
- Descrição:
Define o tamanho máximo estimado para a replicação inicial de um banco de dados primário para um banco de dados secundário (em TB). Define este parâmetro em qualquer conta que armazene um banco de dados secundário. Esse limite de tamanho ajuda a evitar que contas incorram acidentalmente em grandes taxas de replicação de banco de dados.
Para remover o limite de tamanho, defina o valor para
0.0.Observe que atualmente não há um limite de tamanho padrão aplicado a atualizações posteriores de um banco de dados secundário.
- Valores:
0.0e acima com uma escala de pelo menos 1 (por exemplo,20.5,32.25,33.333, etc.).- Padrão:
10.0
JDBC_ENABLE_PUT_GET¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se é permitido permitir o acesso dos comandos PUT e GET aos sistemas de arquivos locais.
- Valores:
TRUE: JDBC ativa os comandos PUT e GET.FALSE: JDBC desativa os comandos PUT e GET.- Padrão:
TRUE
JDBC_TREAT_DECIMAL_AS_INT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica como o JDBC processa colunas que têm uma escala de zero (
0).- Valores:
TRUE: O JDBC processa uma coluna cuja escala é zero como BIGINT.FALSE: O JDBC processa uma coluna cuja escala é zero como DECIMAL.- Padrão:
TRUE
JDBC_TREAT_TIMESTAMP_NTZ_AS_UTC¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica como o JDBC processa valores TIMESTAMP_NTZ.
Por padrão, quando o driver JDBC busca um valor do tipo TIMESTAMP_NTZ do Snowflake, ele converte o valor para o horário «wallclock» usando o fuso horário JVM do cliente.
Os usuários que desejam manter o fuso horário UTC para a conversão podem definir esse parâmetro como
TRUE.Esse parâmetro se aplica somente ao driver JDBC.
- Valores:
TRUE: o driver usa UTC para obter o valor TIMESTAMP_NTZ no horário «wallclock».FALSE: o driver usa o fuso horário atual do cliente JVM para obter o valor TIMESTAMP_NTZ no horário «wallclock».- Padrão:
FALSE
JDBC_USE_SESSION_TIMEZONE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se o driver JDBC usa o fuso horário da classe da JVM ou o fuso horário da sessão (especificado pelo parâmetro TIMEZONE) para os métodos
getDate(),getTime()egetTimestamp()da classeResultSet.- Valores:
TRUE: O driver JDBC usa o fuso horário da sessão.FALSE: O driver JDBC utiliza o fuso horário da JVM.- Padrão:
TRUE
JSON_INDENT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Descrição:
Especifica o número de espaços em branco para recuar cada novo elemento na saída JSON na sessão. Especifica também se caracteres de nova linha devem ser inseridos após cada elemento.
- Valores:
0a16(um valor de
0retorna uma saída compacta removendo todos os espaços em branco e caracteres de nova linha da saída)- Padrão:
2
Nota
Esse parâmetro não afeta o JSON descarregado de uma tabela para um arquivo usando o comando COPY INTO <local>. O comando sempre descarrega dados de JSON no formato NDJSON:
Cada registro da tabela separado por um caractere de nova linha.
Em cada registro, formatação compacta (ou seja, sem espaços ou caracteres de nova linha).
JS_TREAT_INTEGER_AS_BIGINT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica como o driver Node.js do Snowflake processa colunas numéricas que têm uma escala de zero (
0), por exemplo INTEGER ou NUMBER(p, 0).- Valores:
TRUE: JavaScript processa uma coluna cuja escala é zero como Bigint.FALSE: JavaScript processa uma coluna cuja escala é zero como Number.- Padrão:
FALSE
Nota
Por padrão, colunas INTEGER do Snowflake (incluindo BIGINT, NUMBER(p, 0), etc.) são convertidas para o tipo de dados Número do JavaScript. No entanto, os maiores valores inteiros legais do Snowflake são maiores do que os maiores valores numéricos legais JavaScript. Para converter as colunas INTEGER do Snowflake em Bigint JavaScript, que pode armazenar valores maiores que Número JavaScript, defina o parâmetro de sessão JS_TREAT_INTEGER_AS_BIGINT.
Para obter exemplos de como utilizar esse parâmetro, consulte Busca de tipos de dados inteiros como Bigint.
LISTING_AUTO_FULFILLMENT_REPLICATION_REFRESH_SCHEDULE¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Define o intervalo de tempo usado para atualizar os produtos de dados baseados baseado no pacote de aplicativos para outras regiões.
- Valores:
num MINUTES:Um valor entre
1e11520. Deve incluir a unidade MINUTES.USING CRON expr time_zone:Especifica uma expressão cron e um fuso horário para a atualização. Oferece suporte a um subconjunto de sintaxe de utilitário cron padrão.
Para obter uma lista de fusos horários, consulte o tópico da Wikipédia Lista de fusos horários do banco de dados tz. A expressão cron consiste nos seguintes campos:
Os seguintes caracteres especiais são suportados:
*Curinga. Especifica qualquer ocorrência do campo.
LSignifica “último”. Quando usado no campo do dia da semana, permite especificar construções como “a última sexta-feira” (“5L”) de um determinado mês. No campo do dia do mês, ele especifica o último dia do mês.
/nIndica a enésima instância de uma determinada unidade de tempo. Cada quanta de tempo é computada independentemente. Por exemplo, se
4/3for especificado no campo mês, a atualização será agendada para abril, julho e outubro. Por exemplo, a cada três meses, a partir do quarto mês do ano. O mesmo cronograma é mantido nos anos seguintes. Ou seja, a atualização não está programada para ser executada em janeiro (3 meses após a execução de outubro).
Nota
Atualmente, a expressão cron avalia apenas em relação ao fuso horário especificado. Alterar o valor do parâmetro TIMEZONE para a conta (ou definir o valor no nível do usuário ou da sessão) não altera o fuso horário para a atualização.
A expressão cron define todos os tempos de execução válidos para a atualização. O Snowflake tenta atualizar as listagens com base neste cronograma; no entanto, qualquer tempo de execução válido é ignorado se uma execução anterior não tiver sido concluída antes do início do próximo tempo de execução válido.
Quando um dia específico do mês e um dia da semana são inclusos na expressão cron, a atualização é agendada nos dias que satisfazem o dia do mês ou o dia da semana. Por exemplo,
SCHEDULE = 'USING CRON 0 0 10-20 * TUE,THU UTC'agenda uma atualização à 0h do décimo ao vigésimo dia de qualquer mês e também em qualquer terça-feira ou quinta-feira fora dessas datas.
- Padrão:
Nenhum
LOCK_TIMEOUT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Inteiro
- Descrição:
Número de segundos a esperar enquanto se tenta bloquear um recurso antes de dar o time out e abortar a instrução.
- Valores:
0para qualquer inteiro (sem limite). Um valor de0desabilita a espera de bloqueio (a instrução deve adquirir o bloqueio imediatamente ou será abortada). Se vários recursos precisarem ser bloqueados pela instrução, o tempo limite se aplica separadamente a cada tentativa de bloqueio.- Padrão:
43200(12 horas)
Consulte também HYBRID_TABLE_LOCK_TIMEOUT.
LOG_LEVEL¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
Objeto (para bancos de dados, esquemas, projetos DCM, procedimentos armazenados, UDFs, tabelas dinâmicas, tabelas Iceberg, tarefas, serviços) – pode ser definido para:
Conta » Banco de dados » Esquema » Projeto DCM
Conta » Banco de dados » Esquema » Procedimento
Conta » Banco de dados » Esquema » Função
Conta » Banco de dados » Esquema » Tabela dinâmica
Conta » Banco de dados » Esquema » Tabela Iceberg (gerenciada externamente)
Conta » Banco de dados » Esquema » Tarefa
Conta » Banco de dados » Esquema » Serviço
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica o nível de gravidade das mensagens de log produzidas por APIs de registro que devem ser ingeridas e disponibilizadas na tabela de eventos ativa. As mensagens de log no nível especificado (e em níveis mais graves) são ingeridas. Para obter mais informações sobre os níveis de registro, consulte Definição de níveis para registro, métricas e rastreamento.
- Valores:
TRACEDEBUGINFOWARNERRORFATALOFF
- Padrão:
OFF- Notas adicionais:
A tabela a seguir lista os níveis de mensagens de log ingeridas quando você define o parâmetro
LOG_LEVELpara um nível.Configuração do parâmetro LOG_LEVEL
Níveis de mensagens de log ingeridas
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERROR(Somente para UDFs de Java, UDTFs de Java e procedimentos armazenados em Java e Scala. Para obter mais informações, consulte Definição de níveis para registro, métricas e rastreamento).FATAL
Se esse parâmetro for definido tanto na sessão quanto no objeto (ou esquema, banco de dados ou conta), será usado o valor mais detalhado. Consulte Como o Snowflake determina o nível de efeito.
LOG_EVENT_LEVEL¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
Objeto (para bancos de dados, esquemas, projetos DCM, procedimentos armazenados, UDFs, tabelas dinâmicas, tabelas Iceberg, tarefas, serviços) – pode ser definido para:
Conta » Banco de dados » Esquema » Projeto DCM
Conta » Banco de dados » Esquema » Procedimento
Conta » Banco de dados » Esquema » Função
Conta » Banco de dados » Esquema » Tabela dinâmica
Conta » Banco de dados » Esquema » Tabela Iceberg (gerenciada externamente)
Conta » Banco de dados » Esquema » Tarefa
Conta » Banco de dados » Esquema » Serviço
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica o nível de gravidade dos eventos de log (linhas com tipo de registro EVENT) que devem ser ingeridos e disponibilizados na tabela de eventos ativa. Os eventos de log no nível especificado (e em níveis mais graves) são ingeridos. Para obter os valores de gravidade compatíveis e como os níveis se combinam, consulte Definição de níveis para registro, métricas e rastreamento.
- Valores:
TRACEDEBUGINFOWARNERRORFATALOFF
- Padrão:
OFF- Notas adicionais:
A tabela a seguir lista os níveis de eventos de log ingeridos quando você define o parâmetro
LOG_EVENT_LEVELpara um nível.Configuração do parâmetro LOG_EVENT_LEVEL
Níveis de eventos de log ingeridos
TRACETRACEDEBUGINFOWARNERRORFATAL
DEBUGDEBUGINFOWARNERRORFATAL
INFOINFOWARNERRORFATAL
WARNWARNERRORFATAL
ERRORERRORFATAL
FATALERRORFATAL
Se esse parâmetro for definido tanto na sessão quanto no objeto (ou esquema, banco de dados ou conta), será usado o valor mais detalhado. Consulte Como o Snowflake determina o nível de efeito.
LOGIN_IDP_REDIRECT (somente exibição)¶
- Tipo:
Conta
- Tipo de dados:
VARCHAR
- Descrição:
Parâmetro somente exibição com um objeto JSON que resume os valores que alguém definiu na propriedade de conta
LOGIN_IDP_REDIRECT.O objeto JSON contém um mapeamento entre as interfaces do Snowflake e as integrações de segurança SAML. As integrações de segurança SAML são usadas para implementar a autenticação de login único (Single Sign-On, SSO). Se uma interface for mapeada para uma integração de segurança SAML, os usuários que acessam a interface serão redirecionados ao provedor de identidade de terceiros (Identity Provider, IdP) para autenticação. Eles nunca veem a tela de login do Snowflake.
For a conceptual overview and configuration examples, see Redirecionando usuários automaticamente para seu provedor de identidade. For the syntax used to set the property, see ALTER ACCOUNT.
MAX_CONCURRENCY_LEVEL¶
- Tipo:
Objeto (para warehouses) — Pode ser definido para Conta » Warehouse
- Tipo de dados:
Número
- Descrição:
Especifica o nível de simultaneidade das instruções SQL (ou seja, consultas e DML) executadas por um warehouse. Quando o nível é atingido, a operação realizada depende de se o warehouse é de um único ou de múltiplos clusters:
cluster único ou multicluster (no modo Maximizado): As instruções são enfileiradas até que os recursos já alocados sejam liberados ou recursos adicionais sejam provisionados, o que pode ser realizado aumentando o tamanho do warehouse.
Multicluster (em modo de dimensionamento automático): Clusters adicionais são iniciados.
MAX_CONCURRENCY_LEVEL pode ser usado em conjunto com o parâmetro STATEMENT_QUEUED_TIMEOUT_IN_SECONDS para garantir que um warehouse nunca fique em atraso.
Em geral, ele limita o número de instruções que podem ser executadas simultaneamente por um cluster de warehouse, mas há exceções. Nos casos a seguir, o número real de instruções executadas simultaneamente por um warehouse pode ser maior ou menor do que o nível especificado:
Instruções menores, mais básicas: Mais instruções podem ser executadas simultaneamente porque instruções pequenas geralmente são executadas em um subconjunto dos recursos computacionais disponíveis em um warehouse. Isso significa que eles contam apenas como uma fração para o nível de concorrência.
Instruções maiores e mais complexas: Menos instruções podem ser executadas simultaneamente.
- Padrão:
8
Dica
Esse valor é apenas padrão e pode ser alterado a qualquer momento:
Reduzir o nível de simultaneidade de um warehouse pode limitar o número de consultas simultâneas em execução em um warehouse. Quando menos consultas estão competindo pelos recursos do warehouse em um determinado momento, uma consulta pode receber mais recursos, o que pode resultar em um desempenho mais rápido da consulta, especialmente para uma consulta grande/complexa e com várias instruções.
Aumentar o nível de concorrência para um warehouse pode diminuir a alocação de recursos computados disponíveis para a instrução; contudo, isso não necessariamente limita o número total de consultas simultâneas que podem ser executadas pelo warehouse, nem necessariamente afeta o desempenho total do warehouse, que depende da natureza das consultas que estão sendo executadas.
Observe que, como descrito anteriormente, esse parâmetro afeta os warehouses multicluster (em modo de dimensionamento automático) porque o Snowflake inicia automaticamente um novo cluster dentro do depósito multicluster para evitar filas. Assim, a redução do nível de concorrência para um warehouse de vários clusters (no modo de dimensionamento automático) pode aumentar o número de clusters ativos a qualquer momento.
Lembre também que o Snowflake aloca automaticamente recursos para cada instrução quando ela é submetida, e o montante alocado é ditado pelas exigências individuais da instrução. Com base nisso e em observações de padrões de consulta do usuário ao longo do tempo, selecionamos um padrão que equilibra o desempenho e o uso de recursos.
Como tal, antes de alterar o padrão, recomendamos que você teste a alteração ajustando o parâmetro em pequenos incrementos e observando o impacto em relação a um conjunto representativo de suas consultas.
MAX_DATA_EXTENSION_TIME_IN_DAYS¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido para Conta » Base de dados » Esquema » Tabela
- Tipo de dados:
Inteiro
- Descrição:
Número máximo de dias que o Snowflake pode estender o período de retenção de dados para tabelas para evitar que os fluxos nas tabelas fiquem obsoletos. Por padrão, se a configuração DATA_RETENTION_TIME_IN_DAYS para uma tabela de fontes for inferior a 14 dias e um fluxo não tiver sido consumido, o Snowflake estende temporariamente esse período para a compensação do fluxo, até um máximo de 14 dias, independentemente da Edição do Snowflake para sua conta. O parâmetro MAX_DATA_EXTENSION_TIME_IN_DAYS permite limitar esse período de extensão automática para controlar os custos de armazenamento para retenção de dados ou por razões de compliance.
Esse parâmetro pode ser definido nos níveis de conta, banco de dados, esquema e tabela. Observe que a definição do parâmetro no nível de conta ou esquema só afeta as tabelas para as quais o parâmetro ainda não foi explicitamente definido em um nível inferior (por exemplo, no nível da tabela pelo proprietário da tabela). Um valor de 0 desabilita efetivamente a extensão automática para o banco de dados, esquema ou tabela especificado. Para obter mais informações sobre fluxos e desatualização, consulte Introduction to streams.
- Valores:
0para90(90 dias) — um valor de0desativa a extensão automática do período de retenção de dados. Para aumentar o valor máximo de tabelas em sua conta, entre em contato com o suporte Snowflake.- Padrão:
14
Nota
Esse parâmetro pode fazer com que os dados sejam retidos por mais tempo do que a retenção de dados padrão. Antes de aumentá-lo, confirme que o novo valor está de acordo com suas exigências de compliance.
A retenção de tabela não é estendida para fluxos em tabelas compartilhadas. Se você compartilhar uma tabela, certifique-se de definir um tempo de retenção da tabela longo o suficiente para que o consumidor de dados consuma o fluxo. Se um provedor compartilhar uma tabela com, por exemplo, 7 dias de retenção e mantiver a extensão padrão de 14 dias, o fluxo ficará obsoleto após 14 dias na conta do provedor e após 7 dias na conta do consumidor.
METRIC_LEVEL¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
Objeto (para bancos de dados, esquemas, procedimentos armazenados e UDFs) — Pode ser definido para a conta » Banco de dados » Esquema » Procedimento e conta » Banco de dados » Esquema » Função
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Controla como os dados de métricas são ingeridos na tabela de evento. Para obter mais informações sobre níveis métricos, consulte Definição de níveis para registro, métricas e rastreamento.
- Valores:
ALL: Todos os dados de métricas serão registrados na tabela de evento.NONE: Nenhum dado de métrica será registrado na tabela de evento.- Padrão:
NONE
MULTI_STATEMENT_COUNT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Integer (constante)
- Clientes:
SQL API, JDBC, .NET, ODBC
- Descrição:
Número de instruções a serem executadas ao usar a capacidade de instruções múltiplas.
- Valores:
0: Número variável de instruções.1: Uma instrução.Mais do que
1: Quando MULTI_STATEMENT_COUNT é definido como parâmetro de sessão, é possível especificar o número exato de instruções a serem executadas.Números negativos não são permitidos.
- Padrão:
1
MIN_DATA_RETENTION_TIME_IN_DAYS¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Inteiro
- Descrição:
Número mínimo de dias para os quais o Snowflake retém dados históricos para realizar ações de Time Travel (SELECT, CLONE, UNDROP) sobre um objeto. Se um número mínimo de dias para retenção de dados for definido em uma conta, o período de retenção de dados para um objeto é determinado por MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
Para obter mais informações, consulte Compreensão e uso do Time Travel.
- Valores:
0ou1(para Standard Edition)0para90(para Enterprise Edition ou superior)- Padrão:
0
Nota
Esse parâmetro só se aplica a tabelas permanentes e não se aplica aos seguintes objetos:
Tabelas transitórias
Tabelas temporárias
Tabelas externas
Exibições materializadas
Fluxos
Esse parâmetro só pode ser definido e desinstalado por administradores de conta (ou seja, usuários com a função ACCOUNTADMIN ou outra função à qual é concedida a função ACCOUNTADMIN).
A definição do tempo mínimo de retenção de dados não altera nenhum valor de parâmetro DATA_RETENTION_TIME_IN_DAYS existente definido em bancos de dados, esquemas ou tabelas. O tempo de retenção efetivo de um banco de dados, esquema ou tabela é MAX(DATA_RETENTION_TIME_IN_DAYS, MIN_DATA_RETENTION_TIME_IN_DAYS).
NETWORK_POLICY¶
- Tipo:
Conta — Pode ser definido apenas para Conta (pode ser definido por administradores de conta e administradores de segurança)
- Tipo:
Objeto (para usuários) — Pode ser definido para Conta » Usuário
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica a política de redes a ser aplicada para sua conta. As políticas de redes permitem restringir o acesso à sua conta com base no endereço IP dos usuários. Para obter mais detalhes, consulte Controle do tráfego de rede com políticas de rede.
- Valores:
Qualquer política de redes existente (criada usando CREATE NETWORK POLICY)
- Padrão:
Nenhum
Nota
Este é o único parâmetro de conta que pode ser definido por administradores de segurança (ou seja, usuários com a função SECURITYADMIN do sistema) ou superior.
NOORDER_SEQUENCE_AS_DEFAULT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a propriedade ORDER ou NOORDER é definida por padrão quando você cria uma nova sequência ou adiciona uma nova coluna de tabela.
As propriedades ORDER e NOORDER determinam se os valores são ou não gerados para a sequência ou coluna incrementada automaticamente em ordem crescente ou decrescente.
- Valores:
TRUE: quando você cria uma nova sequência ou adiciona uma nova coluna de tabela, a propriedade NOORDER é definida por padrão.NOORDER especifica que não é garantido que os valores estejam em ordem crescente.
Por exemplo, se uma sequência tiver
START 1 INCREMENT 2, os valores gerados podem ser1,3,101,5,103etc.NOORDER pode melhorar o desempenho quando várias operações INSERT são executadas simultaneamente (por exemplo, quando vários clientes estão executando várias instruções INSERT).
FALSE: quando você cria uma nova sequência ou adiciona uma nova coluna de tabela, a propriedade ORDER é definida por padrão.ORDER especifica que os valores gerados para uma sequência ou coluna incrementada automaticamente estão em ordem crescente (ou, se o intervalor for um valor negativo, em ordem decrescente).
Por exemplo, se uma sequência ou coluna incrementada automaticamente tiver
START 1 INCREMENT 2, os valores gerados podem ser1,3,5,7,9etc.
Se você definir esse parâmetro, o valor definido substituirá o valor no pacote de mudança de comportamento 2024_01.
- Padrão:
TRUE
ODBC_TREAT_DECIMAL_AS_INT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica como o ODBC processa colunas que têm uma escala de zero (
0).- Valores:
TRUE: O ODBC processa uma coluna cuja escala é zero como BIGINT.FALSE: O ODBC processa uma coluna cuja escala é zero como DECIMAL.- Padrão:
FALSE
OAUTH_ADD_PRIVILEGED_ROLES_TO_BLOCKED_LIST¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Determina se as funções ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN podem ser usadas como função principal ao criar uma sessão do Snowflake com base no token de acesso do servidor de autorização do Snowflake.
- Valores:
TRUE: adiciona as funções ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN à propriedadeBLOCKED_ROLES_LISTda integração de segurança OAuth do Snowflake, o que significa que estas funções não podem ser usadas como a função principal ao criar uma sessão do Snowflake usando o OAuth do Snowflake.FALSE: remove o ACCOUNTADMIN, ORGADMIN, GLOBALORGADMIN e SECURITYADMIN da lista de funções bloqueadas definidas pela propriedadeBLOCKED_ROLES_LISTda integração de segurança OAuth do Snowflake.- Padrão:
TRUE
OPT_OUT_ERROR_LOGGING¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se o registro de erros de DML é permitido.
- Valores:
TRUE: o registro de erros de DML não está ativado, independentemente de estar ativado em tabelas específicas.FALSE: o registro de erros de DML se comporta normalmente:O registro de erros de DML é ativado em tabelas que têm o parâmetro ERROR_LOGGING no nível da tabela definido como
TRUE.O registro de erros de DML é desativado em tabelas que têm o parâmetro ERROR_LOGGING no nível da tabela definido como
FALSE.
- Padrão:
FALSE
Para obter mais informações, consulte Registro de erros de DML.
PERIODIC_DATA_REKEYING¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Esse parâmetro só se aplica à Enterprise Edition (ou superior). Ele permite/desativa a recriptografia de dados de tabela com novas chaves anualmente para fornecer níveis adicionais de proteção de dados.
Você pode habilitar e desabilitar a recodificação a qualquer momento. Habilitar/desabilitar a recodificação não resulta em lacunas em seus dados criptografados:
Se a recodificação for ativada por um período e depois desativada, todos os dados já marcados para recodificação serão recodificados, mas nenhum outro dado será recodificado novamente até que você reative a opção.
Se a recodificação for reativada, o Snowflake recodificará automaticamente todos os dados que têm chaves que atendem aos critérios (ou seja, chaves com mais de um ano).
Para obter mais informações sobre a recodificação de dados criptografados, consulte Explicação do gerenciamento de chaves de criptografia no Snowflake.
- Valores:
TRUE: Os dados são recodificados novamente após um ano após a última criptografia. A recodificação ocorre em segundo plano para que não haja tempo de parada e os dados/tabela afetados estejam sempre disponíveis.FALSE: Os dados não são recodificados.- Padrão:
FALSE
Nota
Há cobranças associadas com a recodificação dos dados porque, após a recodificação dos dados, os dados antigos (com a criptografia da chave anterior) são mantidos em Fail-safe pelo período padrão (7 dias). Por isso, a recodificação periódica é desativada por padrão. Para permitir a recodificação periódica, você deve habilitá-la explicitamente.
Além disso, as cobranças Fail-safe para a recodificação não estão listadas individualmente em seu extrato mensal; elas são incluídas no total Fail-safe para sua conta a cada mês.
Para obter mais informações sobre o Fail-safe, consulte Explicação e visualização do Fail-safe.
PIPE_EXECUTION_PAUSED¶
- Tipo:
Objeto — Pode ser definido para Conta » Esquema » Canal
- Tipo de dados:
Booliano
- Descrição:
Especifica se um canal em funcionamento deve ser pausado, principalmente na preparação para transferir a propriedade do canal para uma função diferente:
Um administrador de conta (usuário com a função ACCOUNTADMIN) pode definir esse parâmetro no nível da conta, efetivamente pausando ou retomando todos os canais da conta.
Um usuário com o privilégio MODIFY sobre um esquema pode pausar ou retomar todos os canais do esquema.
O proprietário do canal pode definir esse parâmetro para um canal.
Observe que a definição do parâmetro no nível de conta ou esquema só afeta canais para os quais o parâmetro ainda não foi explicitamente definido em um nível inferior (por exemplo, no nível do canal pelo proprietário do canal).
Isso permite o caso de uso prático no qual um administrador de conta pode pausar todos os canais no nível da conta, enquanto um proprietário de canal ainda pode ter um tubo individual funcionando.
- Valores:
TRUE: Pausa o canal. Quando o parâmetro está definido para esse valor, a função SYSTEM$PIPE_STATUS mostra oexecutionStatecomoPAUSED. Observe que o proprietário do canal pode continuar a enviar arquivos para um canal pausado; no entanto, os arquivos não são processados até que o canal seja retomado.FALSE: Retoma o canal, mas somente se a propriedade do canal não tiver sido transferida enquanto ele estava pausado. Quando o parâmetro está definido para esse valor, a função SYSTEM$PIPE_STATUS mostra oexecutionStatecomoRUNNING.Se a propriedade do canal tiver sido transferida para outra função após a pausa do canal, esse parâmetro não poderá ser usado para retomar o canal. Em vez disso, use a função SYSTEM$PIPE_FORCE_RESUME para forçar o canal a ser retomado explicitamente.
Isso permite que o novo proprietário use SYSTEM$PIPE_STATUS para avaliar o estado do canal (por exemplo, determinar quantos arquivos estão esperando para serem carregados) antes de retomar o canal.
- Padrão:
FALSE(canais estão funcionando por padrão)
Nota
Em geral, os canais não precisam ser pausados, exceto para a transferência de propriedade.
PATH_LAYOUT¶
- Tipo:
Objeto (para tabelas Apache Iceberg™) – pode ser definido para tabela Iceberg
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica o layout de caminho que o Snowflake usa ao gravar arquivos de dados Parquet em tabelas Iceberg. Você pode especificar este parâmetro ao criar uma tabela, mas não pode especificá-lo ao modificar uma tabela.
Nota
Para tabelas gerenciadas externamente que você cria em um banco de dados Snowflake padrão, o Snowflake infere e respeita o esquema de particionamento especificado pela tabela remota.
- Valores:
FLAT: o Snowflake grava todos os arquivos de dados Parquet no diretóriodata/da tabela.HIERARCHICAL: o Snowflake grava dados particionados no diretóriodata/da tabela usando um layout de caminho hierárquico. Com esse layout, cada coluna de partição é representada como um nível de diretório no caminho. Para definir essas colunas de particionamento, use o parâmetro PARTITION BY. Esse layout também é chamado de particionamento «estilo Hive».Se você especificar o layout hierárquico, mas não especificar uma cláusula PARTITION BY com o comando, o Snowflake armazenará os arquivos de dados Parquet usando um caminho de layout simples. Você não pode usar o comando ALTER ICEBERG TABLE para habilitar posteriormente um layout de caminho hierárquico para a tabela. Você pode definir esse parâmetro como HIERARCHICAL sem especificar uma cláusula PARTITION BY se não quiser usar particionamento com caminhos hierárquicos agora, mas poderá usá-lo no futuro.
- Padrão:
FLAT
Para obter mais informações, consulte Diretórios de dados e metadados.
PREVENT_UNLOAD_TO_INLINE_URL¶
- Tipo:
Objeto (para usuários) — Pode ser definido para Conta » Usuário
- Tipo de dados:
Booliano
- Descrição:
Especifica se você deve impedir operações ad hoc de descarregamento de dados para locais externos de armazenamento em nuvem (ou seja, instruções COPY INTO <local> que especificam o URL do armazenamento em nuvem e as configurações de acesso diretamente na instrução). Para obter um exemplo, consulte Descarregamento de dados de uma tabela diretamente para arquivos em um local externo.
- Valores:
TRUE: Instruções COPY INTO <location> devem fazer referência a um estágio interno (Snowflake) ou externo nomeado ou a um usuário interno ou estágio de tabela. Um estágio externo nomeado deve armazenar a URL de armazenamento em nuvem e as configurações de acesso em sua definição.FALSE: São permitidas operações ad hoc de descarregamento de dados para locais externos de armazenamento em nuvem.- Padrão:
FALSE
PREVENT_UNLOAD_TO_INTERNAL_STAGES¶
- Tipo:
Usuário — Pode ser definido para Conta » Usuário
- Tipo de dados:
Booliano
- Descrição:
Especifica se devem-se evitar operações de descarga de dados em etapas internas (Snowflake) usando instruções COPY INTO <local>.
- Valores:
TRUE: O descarregamento de dados de tabelas do Snowflake para qualquer estágio interno, incluindo estágios de usuários, estágios de tabelas ou estágios internos nomeados é impedido.FALSE: É permitido o descarregamento de dados em estágios internoss, limitado apenas pelas restrições padrão do tipo de estágio:O usuário atual só pode descarregar dados para seu próprio estágio de usuário.
Usuários só podem descarregar dados para estágios de tabela quando sua função ativa tiver o privilégio OWNERSHIP sobre a tabela.
Usuários só podem descarregar dados para estágios internos nomeados quando sua função ativa tiver o privilégio WRITE no estágio.
- Padrão:
FALSE
PYTHON_PROFILER_TARGET_STAGE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome totalmente qualificado do estágio no qual o relatório será salvo quando você criar o perfil do código do manipulador Python.
- Valores:
Nome totalmente qualificado do estágio no qual o relatório será salvo.
Use um estágio temporário para armazenar a saída somente durante a sessão.
Use um estágio permanente para preservar a saída do criador de perfil fora do escopo de uma sessão.
Para obter mais informações, consulte Especifique o estágio do Snowflake em que a saída do perfil deve ser gravada.
- Padrão:
''
PYTHON_PROFILER_MODULES¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica a lista de módulos Python a serem inclusos em um relatório ao criar o perfil do código do manipulador Python.
Use este parâmetro para especificar módulos contidos em manipuladores preparados ou que contêm dependências que você deseja incluir no perfil.
- Valores:
Uma lista separada por vírgulas de nomes de módulos Python.
Para obter exemplos, consulte Inclusão de módulos com o parâmetro PYTHON_PROFILER_MODULES e Criação de perfil do código do manipulador em estágios.
- Padrão:
''
QUERY_TAG¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (até 2.000 caracteres)
- Descrição:
Cadeia de caracteres opcional que pode ser usada para marcar consultas e outras instruções SQL executadas dentro de uma sessão. As tags são exibidas na saída das funções QUERY_HISTORY , QUERY_HISTORY_BY_*.
- Padrão:
Nenhum
QUOTED_IDENTIFIERS_IGNORE_CASE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
Objeto — Pode ser definido para Conta » Base de dados » Esquema » Tabela
- Tipo de dados:
Booliano
- Descrição:
Especifica se letras em identificadores de objetos com aspas duplas são armazenadas e resolvidas como letras maiúsculas. Por padrão, o Snowflake preserva a caixa de caracteres alfabéticos ao armazenar e resolver identificadores com aspas duplas. (consulte Resolução do identificador). Você pode usar esse parâmetro em situações nas quais aplicativos de terceiros sempre usam aspas duplas em torno de identificadores.
Nota
Alterar este parâmetro do valor padrão pode afetar sua capacidade de encontrar objetos que foram previamente criados com identificadores incluindo maiúsculas e minúsculas com aspas duplas. Consulte Impacto da alteração de parâmetro.
Quando definida em uma tabela, esquema ou banco de dados, a configuração só afeta a avaliação dos nomes das tabelas nos corpos de exibições e funções definidas pelo usuário (UDFs). Se sua conta usa identificadores com aspas duplas que devem ser tratados sem diferenciar maiúsculas de minúsculas e você planeja compartilhar uma exibição ou UDF com uma conta que trata identificadores com aspas duplas diferenciando maiúsculas de minúsculas, você pode definir isso na exibição ou UDF que você planeja compartilhar. Isso permite que a outra conta resolva os nomes das tabelas corretamente na exibição ou na UDF.
- Valores:
TRUE: Letras em identificadores com aspas duplas são armazenadas e resolvidas como letras maiúsculas.FALSE: A caixa das letras em identificadores com aspas duplas é preservado. O Snowflake resolve e armazena os identificadores na caixa especificada.Para obter mais informações, consulte Resolução do identificador.
- Padrão:
FALSE
Por exemplo:
Identificador |
Parâmetro definido como |
Parâmetro definido como |
|
|---|---|---|---|
|
resolve como: |
|
|
|
resolve como: |
|
|
|
resolve como: |
|
|
|
resolve como: |
|
|
READ_CONSISTENCY_MODE¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Define o nível de garantias de consistência necessárias para sessões com alterações quase simultâneas.
- Valores:
SESSION: as alterações ficam imediatamente visíveis para consultas subsequentes dentro da mesma sessão, mas nem sempre imediatamente entre sessões.GLOBAL: as alterações ficam imediatamente visíveis para consultas subsequentes em sessões em execução simultânea, mas com um pequeno impacto nos tempos de resposta da consulta (geralmente de milissegundos).- Padrão:
SESSION
Para obter mais informações, consulte Consistência de leitura entre sessões.
REPLACE_INVALID_CHARACTERS¶
- Tipo:
Objeto — Pode ser definido para Conta » Base de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Booliano
- Descrição:
Especifica se caracteres UTF-8 inválidos devem ser substituídos pelo caractere de substituição Unicode (�) nos resultados de consulta para tabelas Apache Iceberg™ que usam um catálogo externo.
- Valores:
TRUE: o Snowflake substitui os caracteres inválidos UTF-8 pelo caractere de substituição Unicode.FALSE: o Snowflake deixa caracteres UTF-8 inválidos inalterados. O Snowflake retorna uma mensagem de erro do usuário se encontrar um caractere UTF-8 inválido.- Padrão:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se é necessário um objeto de integração de armazenamento como credenciais de nuvem ao criar um estágio externo nomeado (usando CREATE STAGE) para acessar um local privado de armazenamento em nuvem.
- Valores:
TRUE: A criação de um estágio externo para acessar um local privado de armazenamento em nuvem requer fazer referência a um objeto de integração de armazenamento como credenciais de nuvem.FALSE: A criação de um estágio externo não requer fazer referência a um objeto de integração de armazenamento. Em vez disso, os usuários podem fazer referência explícita às credenciais do provedor da nuvem, tais como chaves secretas ou tokens de acesso, caso elas tenham sido configuradas para o local de armazenamento.- Padrão:
FALSE
REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se é necessário utilizar um estágio externo nomeado que referencia um objeto de integração de armazenamento como credenciais de nuvem ao carregar ou descarregar dados para um local privado de armazenamento em nuvem.
- Valores:
TRUE: O carregamento ou descarregamento de dados para um local privado de armazenamento em nuvem requer o uso de um estágio externo nomeado que referencia um objeto de integração de armazenamento; especificar um estágio externo nomeado que referencia credenciais explícitas de provedores de nuvem, tais como chaves secretas ou tokens de acesso, produz um erro do usuário.FALSE: Os usuários podem carregar ou descarregar dados para um local privado de armazenamento em nuvem usando um estágio externo nomeado que faz referência explícita às credenciais do provedor da nuvem.Se PREVENT_UNLOAD_TO_INLINE_URL for FALSE, os usuários podem especificar as credenciais explícitas do provedor da nuvem diretamente na instrução COPY.
- Padrão:
FALSE
ROWS_PER_RESULTSET¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Número
- Clientes:
SQL API
- Descrição:
Especifica o número máximo de linhas retornadas em um conjunto de resultados.
- Valores:
0para qualquer número (sem limite) — um valor de0especifica que não há máximo.- Padrão:
0
S3_STAGE_VPCE_DNS_NAME¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome DNS de um ponto de extremidade de interface do Amazon S3. As solicitações enviadas para o estágio interno de uma conta por meio de AWS PrivateLink para Amazon S3 usam esse ponto de extremidade para se conectar.
Para obter mais informações, consulte Acesso a estágios internos com pontos de extremidade de interface dedicados.
- Valores:
Nome DNS com escopo de região válido de um ponto de extremidade de interface S3.
O formato padrão começa com um asterisco (
*) e termina comvpce.amazonaws.com(por exemplo,*.vpce-sd98fs0d9f8g.s3.us-west-2.vpce.amazonaws.com). Para obter mais detalhes sobre como obter esse valor, consulte Configuração do AWS.Os formatos alternativos incluem
bucket.vpce-xxxxxxxx.s3.<região>.vpce.amazonaws.comevpce-xxxxxxxx.s3.<região>.vpce.amazonaws.com.- Padrão:
Cadeia de caracteres vazia
SAML_IDENTITY_PROVIDER¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
JSON
- Descrição:
Permite a autenticação federada. Este parâmetro obsoleto permite uma autenticação federada. Este parâmetro aceita um objeto JSON entre aspas simples com os seguintes campos:
Onde:
certificateEspecifica o certificado (gerado pelo IdP) que verifica a comunicação entre o IdP e o Snowflake.
issuerIndica o emissor/EntityID do IdP.
Opcional.
Para saber como obter esse valor em Okta e AD FS, consulte Migração para uma integração de segurança SAML2.
ssoUrlEspecifica o ponto de extremidade da URL (fornecido pelo IdP) para onde o Snowflake envia as solicitações SAML.
typeEspecifica o tipo de IdP usado para autenticação federada (
"OKTA","ADFS","Custom").labelEspecifica o texto do botão do IdP na página de login do Snowflake. A etiqueta padrão é
Single Sign On. Se você alterar o rótulo padrão, o rótulo especificado só poderá conter caracteres alfanuméricos (caracteres especiais e espaços em branco não são suportados no momento).Observe que, se o campo
"type"for"Okta", um valor para o campolabelnão precisa ser especificado porque Snowflake exibe o logotipo Okta no botão.
Para obter mais informações, incluindo exemplos de definição do parâmetro, consulte Migração para uma integração de segurança SAML2.
- Padrão:
Nenhum
SEARCH_PATH¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o caminho a ser pesquisado para resolver nomes de objetos não qualificados em consultas. Para obter mais informações, consulte Resolução de nomes em consultas.
- Valores:
Lista de identificadores separados por vírgula. Um identificador pode ser um nome de esquema total ou parcialmente qualificado.
- Padrão:
$current, $publicPara obter mais informações sobre as configurações padrão, consulte o caminho de pesquisa padrão.
Nota
Você não pode definir este parâmetro dentro de uma cadeia de caracteres de conexão do cliente, como uma cadeia de caracteres de conexão JDBC ou ODBC. Você deve estabelecer uma sessão antes de definir um caminho de pesquisa.
Este parâmetro não é compatível com tarefas.
SERVERLESS_TASK_MAX_STATEMENT_SIZE¶
- Tipo:
Objeto — Pode ser definido para Conta » Banco de dados » Esquema » Tarefa
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o tamanho máximo permitido do warehouse para Tarefas sem servidor.
- Valores:
Qualquer tamanho de warehouse tradicional:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. O tamanho máximo éX2LARGE.Também é compatível com a sintaxe:
XXLARGE.- Padrão:
X2LARGE
SERVERLESS_TASK_MIN_STATEMENT_SIZE¶
- Tipo:
Objeto — Pode ser definido para Conta » Banco de dados » Esquema » Tarefa
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o tamanho mínimo permitido do warehouse para Tarefas sem servidor.
- Valores:
Qualquer tamanho de warehouse tradicional:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. O tamanho máximo éX2LARGE.Também é compatível com a sintaxe:
XXLARGE.- Padrão:
XSMALL
SIMULATED_DATA_SHARING_CONSUMER¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nome de uma conta de consumidor para simular para testar/validar dados compartilhados, particularmente exibições seguras compartilhadas. Quando esse parâmetro é definido em uma sessão, as exibições compartilhadas retornarão linhas como se fossem executadas na conta do consumidor especificado e não na conta do provedor.
Nota
As simulações só têm sucesso quando a função atual é a proprietária da exibição. Se a função atual não for a proprietária da exibição, as simulações falharão com o erro:
Para obter mais informações, consulte Sobre o Secure Data Sharing e Criação e configuração de compartilhamentos.
- Padrão:
Nenhum
Importante
Esse é um parâmetro de sessão, o que significa que ele pode ser definido no nível de conta; no entanto, ele se aplica apenas a consultas de teste em exibições compartilhadas. Como o parâmetro afeta todas as consultas em uma sessão, ele nunca deve ser definido no nível da conta.
SQL_TRACE_QUERY_TEXT¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica se vai capturar o texto SQL de uma instrução SQL rastreada.
- Valores:
ON: rastreamentos que seguem uma instrução SQL vão capturar o texto do SQL e armazená-lo na tabela de eventos.OFF: rastreamentos não capturam texto SQL na tabela de eventos.Para obter mais informações, consulte Definição de níveis para registro, métricas e rastreamento e Rastreamento de instruções SQL.
- Padrão:
OFF
SSO_LOGIN_PAGE¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Booliano
- Descrição:
Este parâmetro obsoleto desativa o modo de versão preliminar para testar o SSO (após habilitar a autenticação federada) antes de estendê-la aos usuários:
- Valores:
TRUE: O modo de pré-visualização está desativado e os usuários verão o botão para o SSO iniciado para o Snowflake para seu provedor de identidade (como especificado em SAML_IDENTITY_PROVIDER) na página principal de login do Snowflake.FALSE: O modo de pré-visualização é ativado e o SSO pode ser testado usando a seguinte URL:Se sua conta está na região US West:
https://<account_identifier>.snowflakecomputing.com/console/login?fedpreview=trueSe sua conta estiver em qualquer outra região:
https://<account_identifier>.<region_id>.snowflakecomputing.com/console/login?fedpreview=true
Para obter mais informações, consulte:
- Padrão:
FALSE
STATEMENT_QUEUED_TIMEOUT_IN_SECONDS¶
- Tipo:
Sessão e Objeto (para warehouses)
Pode ser definido para Conta » Usuário » Sessão; também pode ser definido para warehouses individuais
- Tipo de dados:
Número
- Descrição:
Tempo, em segundos, durante o qual uma instrução SQL (consulta, DDL, DML e assim por diante) permanece na fila para um warehouse antes de ser cancelada pelo sistema. Esse parâmetro pode ser usado em conjunto com o parâmetro MAX_CONCURRENCY_LEVEL para garantir que um warehouse nunca fique em atraso.
O parâmetro pode ser definido em diferentes níveis na hierarquia da sessão (na conta, no usuário e na sessão). Se o parâmetro for definido em mais de um nível, as regras descritas em Parâmetros de sessão determinam qual valor será utilizado.
O parâmetro também pode ser definido para um warehouse individual para controlar o tempo de execução de todas as instruções SQL processadas pelo warehouse. Quando o parâmetro é definido na hierarquia da sessão e no warehouse, o tempo limite é o menor valor diferente de zero dos dois parâmetros.
Por exemplo, suponha que o parâmetro esteja definido com os seguintes valores em níveis diferentes:
Usuário – 10
Sessão – 20
Warehouse – 15
Neste caso, o valor do parâmetro definido no warehouse é utilizado (15) porque é menor que o valor definido na hierarquia da sessão (20). O parâmetro definido no usuário (10) não é considerado porque é substituído pelo parâmetro definido na sessão.
Nota
Quando ambos STATEMENT_QUEUED_TIMEOUT_IN_SECONDS e USER_TASK_TIMEOUT_MS são definidos, o valor de USER_TASK_TIMEOUT_MS tem precedência.
Ao comparar os valores desses dois parâmetros, observe que STATEMENT_QUEUED_TIMEOUT_IN_SECONDS é definido em unidades de segundos, enquanto USER_TASK_TIMEOUT_MS utiliza unidades de milissegundos.
- Valores:
0para qualquer número (sem limite) — um valor de0especifica que nenhum tempo limite é aplicado. Uma instrução permanecerá enfileirada enquanto a fila persistir.- Padrão:
0(sem tempo limite)
STATEMENT_TIMEOUT_IN_SECONDS¶
- Tipo:
Sessão e Objeto (para warehouses)
Pode ser definido para Conta » Usuário » Sessão; também pode ser definido para warehouses individuais
- Tipo de dados:
Número
- Descrição:
Quantidade de tempo, em segundos, após a qual uma instrução SQL em execução (consulta, DDL, DML, etc.) é cancelada pelo sistema.
O parâmetro pode ser definido em diferentes níveis na hierarquia da sessão (na conta, no usuário e na sessão). Se o parâmetro for definido em mais de um nível, as regras descritas em Parâmetros de sessão determinam qual valor será utilizado.
O parâmetro também pode ser definido para um warehouse individual para controlar o tempo de execução de todas as instruções SQL processadas pelo warehouse. Quando o parâmetro é definido na hierarquia da sessão e no warehouse, o tempo limite é o menor valor diferente de zero dos dois parâmetros.
Por exemplo, suponha que o parâmetro esteja definido com os seguintes valores em níveis diferentes:
Usuário – 10
Sessão – 20
Warehouse – 15
Neste caso, o valor do parâmetro definido no warehouse é utilizado (15) porque é menor que o valor definido na hierarquia da sessão (20). O parâmetro definido no usuário (10) não é considerado porque é substituído pelo parâmetro definido na sessão.
Quando USER_TASK_TIMEOUT_MS e STATEMENT_TIMEOUT_IN_SECONDS são definidos, o tempo limite é o menor valor diferente de zero dos dois parâmetros. Quando comparar os valores desses dois parâmetros, observe que STATEMENT_TIMEOUT_IN_SECONDS é definido em segundos, enquanto USER_TASK_TIMEOUT_MS usa unidades de milissegundos.
A configuração do parâmetro se aplica a todo o tempo gasto pela instrução, incluindo tempo de fila, tempo de bloqueio, tempo de execução, tempo de compilação e assim por diante. Isso se aplica ao tempo total gasto pela instrução, não apenas ao tempo de execução do warehouse.
- Valores:
0a604800(7 dias) — um valor de0especifica que o valor máximo de tempo limite é aplicado.- Padrão:
172800(2 dias)
STORAGE_SERIALIZATION_POLICY¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas Apache Iceberg™) – Pode ser definido para Conta » Banco de dados » Esquema » Tabela Iceberg
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica a política de serialização de armazenamento para Tabelas Apache Iceberg™ gerenciadas pelo Snowflake.
- Valores:
COMPATIBLE: o Snowflake realiza codificação e compactação que garantem a interoperabilidade com mecanismos de computação de terceiros.OPTIMIZED: o Snowflake realiza a codificação e a compactação que garantem o melhor desempenho de tabela dentro do Snowflake.- Padrão:
OPTIMIZED
STRICT_JSON_OUTPUT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Esse parâmetro especifica se a saída JSON em uma sessão é compatível com o padrão geral (como descrito por http://json.org).
O Snowflake foi projetado de forma a permitir entradas JSON contendo valores não-padronizados; entretanto, esses valores não-padronizados podem fazer com que o Snowflake retorne um JSON incompatível com outras plataformas e linguagens. Esse parâmetro, quando ativado, garante que o Snowflake produza um JSON válido/compatível.
- Valores:
TRUE: Saída JSON estrita habilitada, impondo o seguinte comportamento:Valores ausentes e indefinidos na entrada são mapeados para JSON NULL.
Valores numéricos não finitos na entrada (Infinity, -Infinity, NaN, etc.) são mapeados para cadeias de caracteres com representações JavaScript válidas. Isso permite compatibilidade com JavaScript e também permite a conversão desses valores de volta para valores numéricos.
FALSE: A saída estrita JSON não está habilitada.- Padrão:
FALSE
Por exemplo:
Entrada JSON não-padronizada |
Parâmetro definido como |
Parâmetro definido como |
|
|---|---|---|---|
|
saídas: |
|
|
|
saídas: |
|
|
|
saídas: |
|
|
|
saídas: |
|
|
SUSPEND_TASK_AFTER_NUM_FAILURES¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido como Conta » Base de dados » Esquema » Tarefa
- Tipo de dados:
Inteiro
- Descrição:
Número de tarefas consecutivas falhadas, após as quais uma tarefa autônoma ou gráfico de tarefa tarefa de raiz é suspensa automaticamente. Execuções de tarefas falhadas incluem execuções nas quais o código SQL no corpo da tarefa produz um erro do usuário ou atinge o tempo limite. Execuções de tarefas que são puladas, canceladas ou que falham devido a um erro do sistema são consideradas indeterminadas e não são incluídas na contagem de execuções de tarefas falhadas.
Quando o parâmetro é definido como
0, a tarefa com falha não é suspensa automaticamente.Quando o parâmetro é definido como um valor maior que
0, o seguinte comportamento se aplica a execuções de tarefas autônomas ou tarefas de raiz do gráfico da tarefa:Uma tarefa autônoma é automaticamente suspensa após o número especificado de execuções consecutivas de tarefas falhar ou atingir o tempo limite.
Uma tarefa raiz é automaticamente suspensa após o número especificado de vezes em execuções consecutivas após qualquer tarefa única em um gráfico de tarefa falhar ou atingir o tempo limite, após todas as
TASK_AUTO_RETRY_ATTEMPTSpara essa tarefa.Por exemplo, se uma tarefa raiz tiver
SUSPEND_TASK_AFTER_NUM_FAILURESdefinido como 3 e tiver uma tarefa filho comTASK_AUTO_RETRY_ATTEMPTSdefinido como 3, depois que essa tarefa filho falhar 9 vezes consecutivas, a tarefa raiz será suspensa.
O valor padrão do parâmetro é definido como
10, o que significa que a tarefa é suspensa automaticamente após 10 execuções consecutivas de tarefas com falha.Quando você define explicitamente o valor do parâmetro no nível da conta, do banco de dados ou do esquema, a alteração é aplicada às tarefas contidas no objeto modificado durante sua próxima execução programada (incluindo qualquer tarefa filho em uma execução de gráfico da tarefa em andamento).
A suspensão de uma tarefa autônoma reinicia sua contagem de execuções de tarefas falhadas. Suspender a tarefa raiz de um gráfico da tarefa redefine a contagem de cada tarefa no gráfico da tarefa.
- Valores:
0- Sem limite superior.- Padrão:
10
TASK_AUTO_RETRY_ATTEMPTS¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido como Conta » Base de dados » Esquema » Tarefa
- Tipo de dados:
Inteiro
- Descrição:
Especifica o número de tentativas automáticas de repetição do gráfico de tarefas. Se algum gráfico de tarefas for concluído em um estado
FAILED, o Snowflake poderá tentar novamente automaticamente os gráficos da tarefa da última tarefa no gráfico que falhou. Execuções de tarefas falhadas incluem execuções nas quais o código SQL no corpo da tarefa produz um erro do usuário ou atinge o tempo limite. Execuções de tarefas ignoradas ou canceladas são consideradas indeterminadas e não são inclusas na contagem de execuções de tarefa com falha.A nova tentativa automática do gráfico de tarefas está desabilitada por padrão. Para ativar esse recurso, defina
TASK_AUTO_RETRY_ATTEMPTScomo um valor maior que0.Quando você define o valor do parâmetro ao nível da conta, do banco de dados ou do esquema, a alteração é aplicada às tarefas contidas no objeto modificado durante sua próxima execução agendada.
- Valores:
0- Sem limite superior.- Padrão:
0
TIMESTAMP_DAY_IS_ALWAYS_24H¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se a função DATEADD (e seus pseudônimos) sempre considera um dia como exatamente 24 horas para expressões que abrangem vários dias.
- Valores:
TRUE: Um dia é sempre exatamente 24 horas.FALSE: Um dia nem sempre é 24 horas.- Padrão:
FALSE
Importante
Se definido como TRUE, a hora real do dia pode não ser preservada quando o horário de verão (DST) estiver em vigor. Por exemplo:
TIMESTAMP_INPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de entrada para o tipo de dados alias TIMESTAMP. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de carimbo de data/hora válido e suportado ou
AUTO(
AUTOespecifica que o Snowflake tenta detectar automaticamente o formato dos carimbos de data/hora armazenados no sistema durante a sessão)- Padrão:
AUTO
TIMESTAMP_LTZ_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados TIMESTAMP_LTZ. Se CSV_TIMESTAMP_FORMAT não estiver definido, TIMESTAMP_LTZ_OUTPUT_FORMAT será usado ao baixar arquivos CSV. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de carimbo de data/hora válido e suportado
- Padrão:
Nenhum
TIMESTAMP_NTZ_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados TIMESTAMP_NTZ. Se CSV_TIMESTAMP_FORMAT não estiver definido, TIMESTAMP_NTZ_OUTPUT_FORMAT será usado ao baixar arquivos CSV. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de carimbo de data/hora válido e suportado
- Padrão:
YYYY-MM-DD HH24:MI:SS.FF3
TIMESTAMP_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados alias TIMESTAMP. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de carimbo de data/hora válido e suportado
- Padrão:
YYYY-MM-DD HH24:MI:SS.FF3 TZHTZM
TIMESTAMP_TYPE_MAPPING¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica a variação de TIMESTAMP_* que é mapeada para o tipo de dados alias TIMESTAMP.
- Valores:
TIMESTAMP_LTZ,TIMESTAMP_NTZouTIMESTAMP_TZ- Padrão:
TIMESTAMP_NTZ
TIMESTAMP_TZ_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados TIMESTAMP_TZ. Se CSV_TIMESTAMP_FORMAT não estiver definido, TIMESTAMP_TZ_OUTPUT_FORMAT será usado ao baixar arquivos CSV. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de carimbo de data/hora válido e suportado
- Padrão:
Nenhum
TIMEZONE¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Especifica o fuso horário para a sessão.
- Valores:
Você pode especificar um nome de fuso horário ou um nome de link do lançamento 2025b do Banco de Dados de Fusos Horários IANA (por exemplo,
America/Los_Angeles,Europe/London,UTC,Etc/GMT, etc.).- Padrão:
America/Los_Angeles
Nota
Os nomes de fuso horário diferenciam maiúsculas de minúsculas e precisam ser colocados entre aspas simples (por exemplo,
'UTC').O Snowflake não oferece suporte à maioria das abreviações de fuso horário (por exemplo,
PDT,ESTetc.) porque uma determinada abreviação pode se referir a um dos vários fusos horários diferentes. Por exemplo,CSTpode se referir ao Horário Padrão Central na América do Norte (UTC-6), ao Horário Padrão de Cuba (UTC-5) e ao Horário Padrão da China (UTC8).
TIME_INPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de entrada para o tipo de dados TIME. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de tempo válido e suportado ou
AUTO(
AUTOespecifica que o Snowflake tenta detectar automaticamente o formato dos horários armazenados no sistema durante a sessão)- Padrão:
AUTO
TIME_OUTPUT_FORMAT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o formato de exibição para o tipo de dados TIME. Para obter mais informações, consulte Formatos de entrada e saída de data e hora.
- Valores:
Qualquer formato de tempo válido e suportado
- Padrão:
HH24:MI:SS
TRACE_LEVEL¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
Objeto (para bancos de dados, esquemas, procedimentos armazenados e UDFs) — Pode ser definido para a conta » Banco de dados » Esquema » Procedimento e conta » Banco de dados » Esquema » Função
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Controla como os eventos de rastreamento são ingeridos na tabela de eventos. Para obter mais informações sobre níveis de rastreamento, consulte Definição de níveis para registro, métricas e rastreamento.
- Valores:
ALWAYS: todos os eventos de spans e rastreamento serão registrados na tabela de eventos.ON_EVENT: os eventos de rastreamento serão registrados na tabela de eventos somente quando os procedimentos armazenados ou UDFs adicionarem eventos explicitamente.OFF: nenhum período ou evento de rastreamento será registrado na tabela de eventos.- Padrão:
OFF
Nota
Ao rastrear eventos, você também deve definir o parâmetro LOG_LEVEL como um dos valores compatíveis.
TRANSACTION_ABORT_ON_ERROR¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
BOOLEAN
- Descrição:
Especifica a ação a ser executada quando uma instrução emitida dentro de uma transação sem confirmação automática retorna com um erro.
- Valores:
TRUE: A transação sem confirmação automática é abortada. Todas as instruções emitidas dentro dessa transação falharão até que uma instrução de confirmação ou de reversão seja executada para encerrar essa transação.FALSE: A transação sem confirmação automática não é abortada.- Padrão:
FALSE
TRANSACTION_DEFAULT_ISOLATION_LEVEL¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o nível de isolamento para transações na sessão do usuário.
- Valores:
READ COMMITTED(somente valor suportado atualmente)- Padrão:
READ COMMITTED
TWO_DIGIT_CENTURY_START¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Número
- Descrição:
Especifica o ano de «início do século» para anos de 2 dígitos (ou seja, o ano mais antigo que essas datas podem representar). Esse parâmetro evita datas ambíguas ao importar ou converter dados com o componente de formato de data
YY(anos representados como 2 dígitos).- Valores:
De
1900a2100(qualquer valor fora deste intervalo retorna um erro)- Padrão:
1970
Por exemplo:
Ano |
Parâmetro definido como |
Parâmetro definido como |
Parâmetro definido como |
Parâmetro definido como |
Parâmetro definido como |
|
|---|---|---|---|---|---|---|
|
torna-se: |
|
|
|
|
|
|
torna-se: |
|
|
|
|
|
|
torna-se: |
|
|
|
|
|
|
torna-se: |
|
|
|
|
|
UNSUPPORTED_DDL_ACTION¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Determina se um valor não suportado (não padrão) especificado para uma propriedade de restrição retorna um erro.
- Valores:
IGNORE: O Snowflake não retorna um erro para valores não suportados.FAIL: O Snowflake retorna um erro para valores não suportados.- Padrão:
IGNORE
Importante
Esse parâmetro não determina se a restrição é criada. O Snowflake não cria restrições utilizando valores não suportados, independentemente de como este parâmetro é definido.
Para obter mais informações, consulte Propriedades de restrição.
USE_CACHED_RESULT¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Booliano
- Descrição:
Especifica se é necessário reutilizar os resultados da consulta persistente, se disponíveis, quando uma consulta correspondente é enviada.
- Valores:
TRUE: Quando uma consulta é enviada, o Snowflake verifica os resultados da consulta correspondente para consultas executadas anteriormente e, se existir um resultado correspondente, usa o resultado em vez de executar a consulta. Isso pode ajudar a reduzir o tempo de consulta, pois o Snowflake recupera o resultado diretamente do cache.FALSE: O Snowflake executa cada consulta que é enviada, independentemente da existência de um resultado de consulta correspondente.- Padrão:
TRUE
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido como Conta » Base de dados » Esquema » Tarefa
- Tipo de dados:
Cadeia de caracteres
- Descrição:
Especifica o tamanho dos recursos de computação a serem provisionados para a primeira execução da tarefa, antes que um histórico de tarefas esteja disponível para que o Snowflake determine um tamanho ideal. Quando uma tarefa é concluída com sucesso, o Snowflake ignora esta configuração de parâmetros. Se o histórico de tarefas não estiver disponível para uma determinada tarefa, os recursos de computação voltam para esse tamanho inicial.
Nota
Esse parâmetro se aplica somente a tarefas sem servidor.
O tamanho é equivalente aos recursos computacionais disponíveis ao criar um warehouse. Se o parâmetro for omitido, as primeiras execuções da tarefa são realizadas utilizando um warehouse de tamanho médio (
MEDIUM).Você pode mudar o tamanho inicial para tarefas individuais (usando ALTER TASK) após a criação da tarefa, mas antes de ela já ter sido executada com sucesso uma vez. A alteração do parâmetro após a primeira execução desta tarefa não tem efeito sobre os recursos de computação para execuções de tarefa atuais ou futuras.
Observe que suspender e retomar uma tarefa não remove o histórico de tarefas usado para dimensionar os recursos de computação. O histórico de tarefas só é removido se a tarefa for recriada (usando a sintaxe CREATE OR REPLACE TASK).
- Valores:
Qualquer tamanho de warehouse tradicional:
XSMALL,SMALL,MEDIUM,LARGE,XLARGE,X2LARGE. O tamanho máximo éX2LARGE.Também é compatível com a sintaxe:
XXLARGE.- Padrão:
MEDIUM
USER_TASK_MINIMUM_TRIGGER_INTERVAL_IN_SECONDS¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido como Conta » Base de dados » Esquema » Tarefa
- Tipo de dados:
Número
- Descrição:
Define a frequência com que uma tarefa acionada pode ser executada em segundos. Se uma tarefa for acionada novamente enquanto estiver em execução, o Snowflake aguardará o número especificado de segundos (após a execução anterior ter sido agendada) antes de iniciar a próxima execução.
Se você definir esse parâmetro para mais de 12 horas para uma tarefa, a tarefa será executada a cada 12 horas.
- Valores:
10–604800(1 semana).- Padrão:
30
USER_TASK_TIMEOUT_MS¶
- Tipo:
Objeto (para bancos de dados, esquemas e tabelas) — Pode ser definido como Conta » Base de dados » Esquema » Tarefa
- Tipo de dados:
Número
- Descrição:
Especifica o limite de tempo em uma única execução da tarefa antes que ele se esgote (em milissegundos).
Nota
Antes de aumentar significativamente o prazo para tarefas, considere se as instruções SQL nas definições de tarefas podem ser otimizadas (seja reescrevendo as instruções ou usando procedimentos armazenados) ou se o tamanho do warehouse para tarefas com recursos computacionais gerenciados pelo usuário deve ser aumentado.
Quando ambos STATEMENT_TIMEOUT_IN_SECONDS e USER_TASK_TIMEOUT_MS são definidos, o tempo limite é o valor mais baixo diferente de zero dos dois parâmetros.
Quando ambos STATEMENT_QUEUED_TIMEOUT_IN_SECONDS e USER_TASK_TIMEOUT_MS são definidos, o valor de USER_TASK_TIMEOUT_MS tem precedência.
Para obter mais informações sobre USER_TASK_TIMEOUT_MS, consulte CREATE TASK…USER_TASK_TIMEOUT.
- Valores:
0–604800000(7 dias). Um valor de0especifica que o valor máximo de tempo limite é aplicado.- Padrão:
3600000(1 hora)
USE_WORKSPACES_FOR_SQL¶
- Tipo:
Conta — Pode ser definido apenas para Conta
- Tipo de dados:
Cadeia de caracteres (constante)
- Descrição:
Controla se o editor do Workspaces é a experiência de edição SQL padrão para a conta.
- Valores:
always: Defina o editor padrão para toda a conta como Workspaces para todos os usuários.never: Retorne ao editor anterior e ignore temporariamente qualquer BCR gerenciado pelo Snowflake que torne o Workspaces o padrão.Para obter mais informações, consulte Espaços de trabalho.
WEEK_OF_YEAR_POLICY¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Número
- Descrição:
Especifica como as semanas em um determinado ano são computadas.
- Valores:
0: A semântica utilizada é equivalente à semântica ISO, na qual uma semana pertence a um determinado ano se pelo menos 4 dias dessa semana estiverem nesse ano.1: 1º de janeiro está incluído na primeira semana do ano e 31 de dezembro está incluído na última semana do ano.- Padrão:
0(comportamento semelhante ao ISO)
Dica
1 é o valor mais comum, baseado no feedback que recebemos. Para obter mais informações, incluindo exemplos, consulte Semanas do ano e dias úteis.
WEEK_START¶
- Tipo:
Sessão — Pode ser definido para Sessão do » Usuário » da Conta
- Tipo de dados:
Número
- Descrição:
Especifica o primeiro dia da semana (usado por funções de data relacionadas à semana).
- Valores:
0: o comportamento herdado do Snowflake é usado (semântica semelhante aISO).1(segunda-feira) a7(domingo): todas as funções relacionadas à semana utilizam semanas que começam no dia da semana especificado.- Padrão:
0(comportamento herdado do Snowflake)
Dica
1 é o valor mais comum, baseado no feedback que recebemos. Para obter mais informações, incluindo exemplos, consulte Semanas do ano e dias úteis.