Instalação e configuração do conector Spark¶
São com suporte várias versões do conector; no entanto, a Snowflake recomenda fortemente o uso da versão mais recente do conector. Para as informações de lançamento da última versão, consulte as Notas sobre o lançamento do conector Spark (link na barra lateral).
As instruções neste tópico podem ser usadas para instalar e configurar todas as versões com suporte do conector.
Versões com suporte¶
O Snowflake suporta múltiplas versões do conector:
Versões do Snowflake Spark Connector: |
3.x, 2.x |
Versões Spark com suporte: |
Connector versão 3.x: Spark 3.5, 3.4, 3.3, 3.2 . Conector versão 2.x: Spark 3.4, 3.3, 3.2 |
Versões Scala com suporte: |
Scala 2.13 . Scala 2.12 |
Nome da fonte de dados: |
Versão do conector 3.x e 2.x: |
Nome do pacote (para classes importadas): |
|
Distribuição de pacotes: |
Scala 2.13 no Repositório Central Maven . Scala 2.12 no Repositório Central Maven |
Código fonte: |
spark-snowflake (GitHub) . |
As notas do desenvolvedor para as diferentes versões são hospedadas com o código fonte.
Nota
3.x: uma única versão do Snowflake Spark Connector versão 3.0.0 e superior oferece suporte a várias versões do Spark.
2.x: o Snowflake Spark Connector para 2.x geralmente é compatível com as três versões mais recentes do Spark. Baixe uma versão do conector que seja específica para sua versão do Spark. Por exemplo, para usar a versão 2.16.0 do conector com a versão Spark 3.4, baixe a versão
2.16.0-spark_3.4do conector.Para aplicar políticas de proteção de dados ao consultar tabelas Apache Iceberg™ pelo Apache Spark™, você deve instalar a versão 3.1.6 ou posterior.
Requisitos¶
Para instalar e usar o Snowflake com o Spark, você precisa do seguinte:
Um sistema operacional com suporte. Para uma lista dos sistemas operacionais com suporte, consulte Suporte ao sistema operacional.
Conector do Snowflake para Spark
Driver Snowflake JDBC (a versão compatível com a versão do conector).
Ambiente Apache Spark, seja auto-hospedado ou hospedado em qualquer um de:
Além disso, é possível usar um bucket Amazon S3 dedicado ou um contêiner de armazenamento de blobs do Azure como zona de preparação entre os dois sistemas; entretanto, isto não é necessário com a versão 2.2.0 (e superior) do conector, que usa um estágio interno temporário do Snowflake (por padrão) para toda a troca de dados.
A função usada na conexão precisa de privilégios USAGE e CREATE STAGE no esquema que contém a tabela que você lerá ou gravará.
Nota
Se você estiver usando o Databricks ou Qubole para hospedar o Spark, não será necessário baixar ou instalar o conector do Snowflake para Spark (ou qualquer um dos outros requisitos). Tanto o Databricks como o Qubole integraram o conector para fornecer conectividade nativa.
Para obter mais detalhes, consulte:
Verificação da versão do driver ou conector OCSP¶
O Snowflake usa OCSP para avaliar a cadeia de certificados ao fazer uma conexão com o Snowflake. A versão do driver ou conector e sua configuração determinam o comportamento OCSP. Para obter mais informações sobre a versão do driver ou conector, sua configuração e comportamento OCSP, consulte Configuração do OCSP.
Download e instalação do conector¶
As instruções nesta seção pertencem à versão 2.x e superior do Conector do Snowflake para Spark.
Importante
O Snowflake lança periodicamente novas versões do conector. As seguintes tarefas de instalação devem ser realizadas cada vez que você instala uma nova versão. Isto também se aplica ao driver Snowflake JDBC, que é um pré-requisito para o conector Spark.
Etapa 1: Baixar a versão mais recente do conector Snowflake para Spark¶
O Snowflake fornece múltiplas versões do conector. Baixe a versão apropriada, com base no seguinte:
A versão do Conector do Snowflake para Spark que você deseja usar.
A versão do Spark que você está usando.
A versão do Scala que você está usando.
Você pode baixar o Conector do Snowflake para Spark do Maven. Se quiser criar o driver, você pode acessar o código-fonte no GitHub.
Repositório central Maven¶
O Snowflake fornece artefatos em pacotes separados para cada versão do Scala com suporte (2.12 e 2.13). Para cada uma destas versões do Scala, o Snowflake fornece diferentes versões do conector Spark, bem como artefatos separados que suportam diferentes versões do Spark.
Para baixar o conector do Spark:
Procure no repositório Maven a versão desejada do Snowflake Spark Connector:
A seguinte captura de tela fornece um exemplo da página de resultados da pesquisa:

A etiqueta Latest version mostra a versão mais atual do driver. Se quiser fazer o download de uma versão anterior, clique no link View all ao lado da versão mais recente para ver todos os pacotes disponíveis. A captura de tela a seguir mostra um exemplo de todos os pacotes disponíveis para o spark-snowflake_2.12.
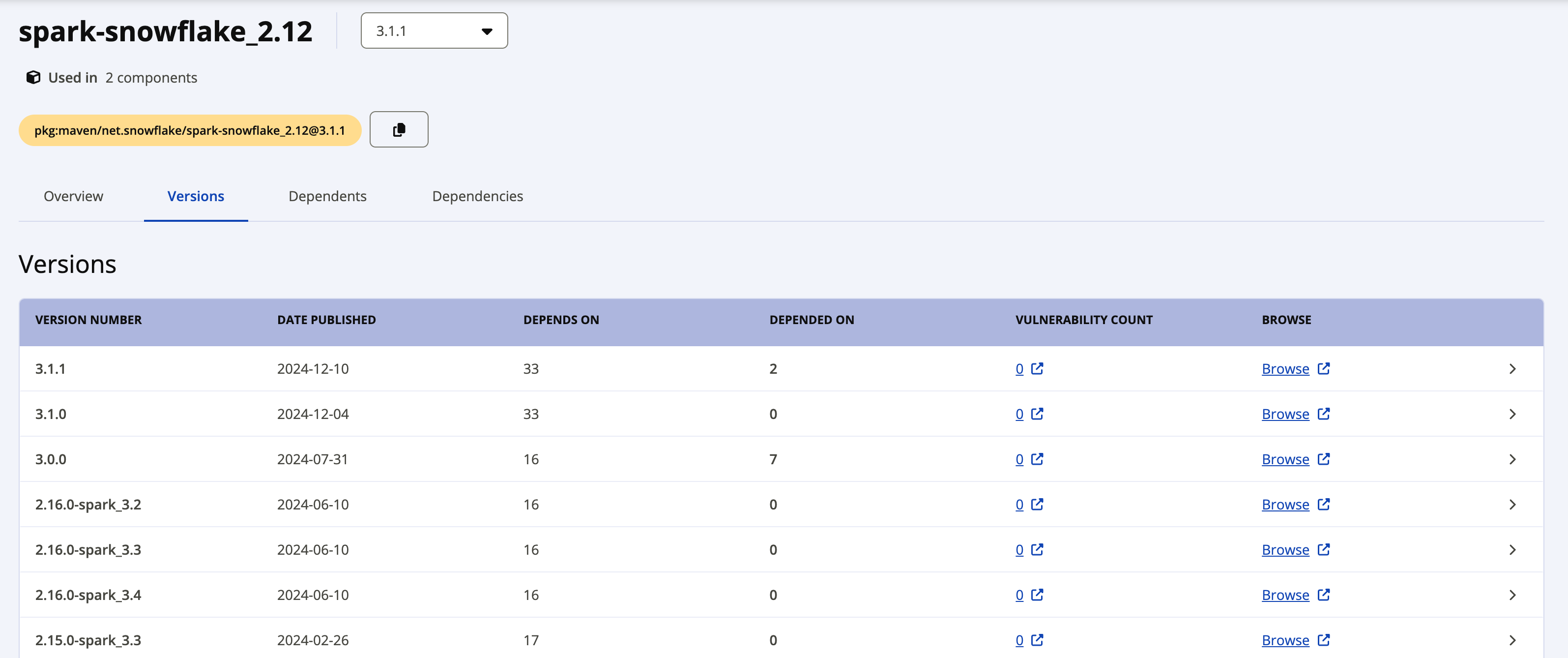
Os pacotes individuais do Snowflake Spark Connector versão 2.x usam a seguinte convenção de nomenclatura:
onde:
C.Cé a versão do Scala (por exemplo, 2.12).N.N.Né a versão do Snowflake (por exemplo, 2.16.0).P.Pé a versão do Spark (por exemplo, 3.4).
Por exemplo:
Os pacotes individuais do Snowflake Spark Connector versão 3.x usam a seguinte convenção de nomenclatura:
onde:
C.Cé a versão do Scala (por exemplo, 2.13).N.N.Né a versão do Snowflake (por exemplo, 3.1.1).
Por exemplo:
Clique no link Browse ao lado da versão que deseja baixar e, em seguida, selecione e baixe o arquivo JAR.

Se você planeja verificar a assinatura do pacote, precisa baixar o arquivo de assinatura também. Clique no nome do arquivo com a extensão de nome de arquivo
. jar.asc(por exemplo, net.snowflake:spark-snowflake_2.13:3.1.1.jar.asc ou net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4.jar.asc).
GitHub¶
O código-fonte do Conector do Snowflake para Spark está disponível no GitHub. Entretanto, os pacotes compilados não estão disponíveis no GitHub. Você pode baixar os pacotes compilados do Maven.
Etapa 2: Baixar a versão compatível do driver Snowflake JDBC¶
Em seguida, você precisa baixar a versão do driver Snowflake JDBC que seja compatível com a versão do Conector Snowflake Spark que você está usando.
O driver Snowflake JDBC é fornecido como um pacote Java padrão através da página do driver JDBC no repositório central Maven. Você pode baixar o pacote como um arquivo .jar ou pode fazer referência direta ao pacote. Estas instruções consideram que você está fazendo referência ao pacote.
Para encontrar a versão com suporte do driver Snowflake JDBC para a versão do Conector do Snowflake para Spark que você está usando, consulte Notas de lançamento de Snowflake Connector for Spark.
Para obter mais detalhes sobre como baixar e instalar o driver Snowflake JDBC, consulte Download/integração do driver JDBC.
Etapa 3 (opcional): Verificar a assinatura do pacote do Conector do Snowflake para Spark¶
Para verificar a assinatura do pacote do Conector do Snowflake para Spark:
A partir do servidor de chaves públicas, baixe e importe a chave pública do Snowflake GPG para a versão do Conector do Snowflake para Spark que você está usando:
Para a versão 3.1.2 e superior:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 2A3149C82551A34A
Para a versão 3.1.0 até 3.1.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 5A125630709DD64B
Para a versão 2.11.1 a 3.0.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 630D9F3CAB551AF3
Para a versão 2.8.2 a 2.11.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 37C7086698CB005C
Para a versão 2.4.13 até 2.8.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys EC218558EABB25A1
Para a versão 2.4.12 e inferior:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 93DB296A69BE019A
Nota
Se esse comando falhar com o seguinte erro:
depois especifique que você deseja usar a porta 80 para o servidor de chaves:
Execute o comando
gpg --verifypara verificar a assinatura do pacote.Para o sinalizador de linha de comando
--verify, especifique o arquivo.ascque você baixou anteriormente como o arquivo de assinatura e o arquivo JAR como o arquivo contendo os dados assinados.onde:
x.xxé a versão do Scala (por exemplo, 2.12).N.N.Né a versão do Snowflake Connector para Spark (por exemplo, 2.16.0).P.Pé a versão do Spark (por exemplo, 3.4).
Nota
A verificação da assinatura produz um aviso semelhante ao seguinte:
Para evitar o aviso, você pode conceder confiança implícita à chave pública GPG do Snowflake.
Seu ambiente local pode conter múltiplas chaves GPG. Entretanto, por razões de segurança, o Snowflake alterna periodicamente a chave pública GPG. Nossa prática recomendada é excluir a chave pública existente depois de confirmar que a última chave funciona com o último pacote assinado. Por exemplo:
Etapa 4: Configurar o cluster Spark local ou ambiente Spark hospedado no Amazon EMR¶
Se você tiver uma instalação do Spark local, ou uma instalação do Spark no Amazon EMR, precisa configurar o programa spark-shell para incluir tanto o driver Snowflake JDBC quanto o Conector Spark:
Para incluir o driver Snowflake JDBC, use a opção
--packagepara fazer referência ao pacote JDBC da página do driver JDBC no Repositório central Maven, fornecendo a versão exata do driver que deseja usar (por exemplo,net.snowflake:snowflake-jdbc:3.13.30).Para incluir o Conector Spark, use a opção
--packagepara fazer referência ao pacote apropriado (Scala 2.12 ou `Scala 2.13`__) hospedado no Repositório central Maven, fornecendo a versão exata do driver que você deseja usar (por exemplo,net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4).
Por exemplo:
Instalação de pacotes adicionais (se necessário)¶
Dependendo de sua instalação do Spark, alguns pacotes requeridos pelo conector podem estar faltando. Você pode adicionar pacotes ausentes à sua instalação usando o sinalizador apropriado para spark-shell:
--packages--jars(se os pacotes foram baixados como arquivos.jar)
Os pacotes necessários estão listados abaixo, com a sintaxe (incluindo o número da versão) para usar o sinalizador --packages para fazer referência aos pacotes:
org.apache.hadoop:hadoop-aws:2.7.1org.apache.httpcomponents:httpclient:4.3.6org.apache.httpcomponents:httpcore:4.3.3com.amazonaws:aws-java-sdk-core:1.10.27com.amazonaws:aws-java-sdk-s3:1.10.27com.amazonaws:aws-java-sdk-sts:1.10.27
Por exemplo, se os pacotes Apache estiverem faltando, para adicionar os pacotes por referência:
Preparação de um local externo para arquivos¶
Talvez seja necessário preparar um local externo para os arquivos que você deseja transferir entre o Snowflake e o Spark.
Esta tarefa é necessária se uma das seguintes situações for verdadeira:
Você executará trabalhos que levam mais de 36 horas, que é a duração máxima do token utilizado pelo conector para acessar o estágio interno para troca de dados.
A versão do Conector do Snowflake para Spark é 2.1.x ou anterior (mesmo se seus trabalhos exigirem menos de 36 horas).
Nota
Se você não estiver usando a versão v2.2.0 (ou superior) do conector, a Snowflake recomenda fortemente a atualização para a versão mais recente.
Preparação de um bucket AWS S3 externo¶
Prepare um bucket S3 externo que o conector possa usar para trocar dados entre o Snowflake e o Spark. Você então fornece ao conector as informações de localização, juntamente com as credenciais necessárias da AWS para a localização. Para obter mais detalhes, consulte Autenticação do S3 para troca de dados no próximo tópico.
Importante
Se você usar um bucket S3 externo, o conector não remove automaticamente nenhum dado intermediário/temporário deste local. Como resultado, é melhor usar um bucket ou caminho específico (prefixo) e definir uma política de ciclo de vida para o bucket/caminho para limpar automaticamente os arquivos mais antigos. Para obter mais detalhes sobre a configuração de uma política de ciclo de vida, consulte a documentação do Amazon S3.
Preparação de um contêiner de armazenamento de blobs do Azure¶
Prepare um contêiner de armazenamento de blobs do Azure externo que o conector possa usar para trocar dados entre o Snowflake e o Spark. Você então fornece ao conector as informações de localização, juntamente com as credenciais do Azure necessárias para a localização. Para obter mais detalhes, consulte Autenticação do Azure para troca de dados no próximo tópico.