Installieren und Konfigurieren des Spark-Konnektors¶
Es werden mehrere Versionen des Konnektors unterstützt. Snowflake empfiehlt jedoch dringend die Verwendung der neuesten Version des Konnektors. Hinweise zur Anzeige von Release-Informationen zur neueste Version finden Sie unter Versionshinweise zum Spark-Konnektor (Link in der Seitenleiste).
Die Anweisungen unter diesem Thema können zur Installation und Konfiguration aller unterstützten Versionen des Konnektors verwendet werden.
Unterstützte Versionen¶
Snowflake unterstützt mehrere Versionen des Konnektors:
Snowflake Spark Connector Versionen: |
3.x, 2.x |
Unterstützte Spark-Versionen: |
Connector Version 3.x: Spark 3.5, 3.4, 3.3, 3.2 . Connector Version 2.x: Spark 3.4, 3.3, 3.2 |
Unterstützte Scala-Versionen: |
Scala 2.13 . Scala 2.12 |
Name der Datenquelle: |
Connector Version 3.x und 2.x: |
Paketname (für importierte Klassen): |
|
Paketverteilung: |
Scala 2.13 im zentralen Maven-Repository . Scala 2.12 im zentralen Maven-Repository |
Quellcode: |
spark-snowflake (GitHub) . |
Die Entwicklerhinweise für die verschiedenen Versionen werden zusammen mit dem Quellcode gehostet.
Bemerkung
3.x: Eine einzige Version des Snowflake Spark Connectors Version 3.0.0 und höher unterstützt mehrere Versionen von Spark.
2.x: Der Snowflake Spark Connector für 2.x unterstützt generell die drei neuesten Versionen von Spark. Laden Sie eine Version des Konnektors herunter, die für Ihre Spark-Version entwickelt wurde. Laden Sie beispielsweise die
2.16.0-spark_3.4Version des Konnektors herunter, um Version 2.16.0 des Konnektors mit der Spark-Version 3.4 zu verwenden.Um die Datenschutzrichtlinien bei der Abfrage von Apache Iceberg™-Tabellen aus Apache Spark™ durchzusetzen, müssen Sie 3.1.6 oder eine neuere Version installieren.
Anforderungen¶
Um Snowflake mit Spark zu installieren und zu verwenden, benötigen Sie Folgendes:
Ein unterstütztes Betriebssystem. Eine Liste der unterstützten Betriebssysteme finden Sie unter Betriebssystemunterstützung.
Snowflake-Konnektor für Spark
Snowflake-JDBC-Treiber (die mit der Version des Konnektors kompatible Version).
Apache Spark-Umgebung, entweder selbst gehostet oder in einer der folgenden Umgebungen gehostet:
Darüber hinaus können Sie einen dedizierten Amazon S3-Bucket oder einen Azure Blob-Speichercontainer als Stagingzone zwischen den beiden Systemen verwenden. Dies ist jedoch ab Version 2.2.0 des Konnektors nicht mehr erforderlich, da dieser (standardmäßig) einen temporären internen Snowflake-Stagingbereich für den gesamten Datenaustausch verwendet.
Die für die Verbindung verwendete Rolle benötigt USAGE- und CREATE STAGE-Berechtigungen für das Schema, das die Tabelle enthält, aus der Sie lesen bzw. in die Sie schreiben werden.
Bemerkung
Wenn Sie Databricks oder Qubole für das Hosting von Spark verwenden, müssen Sie den Snowflake-Konnektor für Spark (oder eine seiner anderen Voraussetzungen) nicht herunterladen oder installieren. Sowohl bei Databricks als auch Qubole ist der Konnektor integriert, um eine native Konnektivität sicherzustellen.
Weitere Details dazu finden Sie unter:
Überprüfen der OCSP-Konnektor- oder Treiber-Version¶
Snowflake verwendet OCSP, um die Zertifikatkette beim Herstellen einer Verbindung zu Snowflake auszuwerten. Die Version von Treiber oder Konnektor bestimmt zusammen mit deren Konfiguration das OCSP-Verhalten. Weitere Informationen zur Treiber- oder Konnektor-Version, ihrer Konfiguration und zum OCSP-Verhalten finden Sie unter OCSP-Konfiguration.
Herunterladen und Installieren des Konnektors¶
Die Anweisungen in diesem Abschnitt beziehen sich auf die Version 2.x und höher des Snowflake-Konnektors für Spark.
Wichtig
Snowflake veröffentlicht regelmäßig neue Versionen des Konnektors. Die folgenden Installationsaufgaben müssen bei jeder Installation einer neuen Version durchgeführt werden. Dies gilt auch für den Snowflake-JDBC-Treiber, der eine Voraussetzung für den Spark-Konnektor ist.
Schritt 1: Neueste Version des Snowflake Connector für Spark herunterladen¶
Snowflake bietet mehrere Versionen des Konnektors an. Sie müssen die entsprechende Version auf Basis folgender Aspekte herunterladen:
Die Version des Snowflake-Konnektors für Spark, die Sie verwenden möchten.
Die Spark-Version, die Sie verwenden.
Die Scala-Version, die Sie verwenden.
Sie können den Snowflake-Konnektor für Spark von Maven herunterladen. Wenn Sie den Treiber bauen möchten, können Sie den Quellcode unter GitHub abrufen.
Zentrales Maven-Repository¶
Snowflake stellt für jede unterstützte Scala-Version (2.12 und 2.13) separate Paketartefakte bereit. Für jede dieser Scala-Versionen bietet Snowflake verschiedene Versionen des Spark-Konnektors sowie separate Artefakte, die verschiedene Versionen von Spark unterstützen.
So laden Sie den Spark-Konnektor herunter:
Suchen Sie im Maven-Repository nach der gewünschten Version des Snowflake Spark Connectors:
Der folgende Screenshot zeigt ein Beispiel für die Suchergebnisseite:

Das Etikett Latest version zeigt die aktuellste Version des Treibers an. Wenn Sie eine frühere Version herunterladen möchten, klicken Sie auf den Link View all neben der neuesten Version, um alle verfügbaren Pakete anzuzeigen. Der folgende Screenshot zeigt ein Beispiel für alle verfügbaren Pakete für spark-snowflake_2.12.
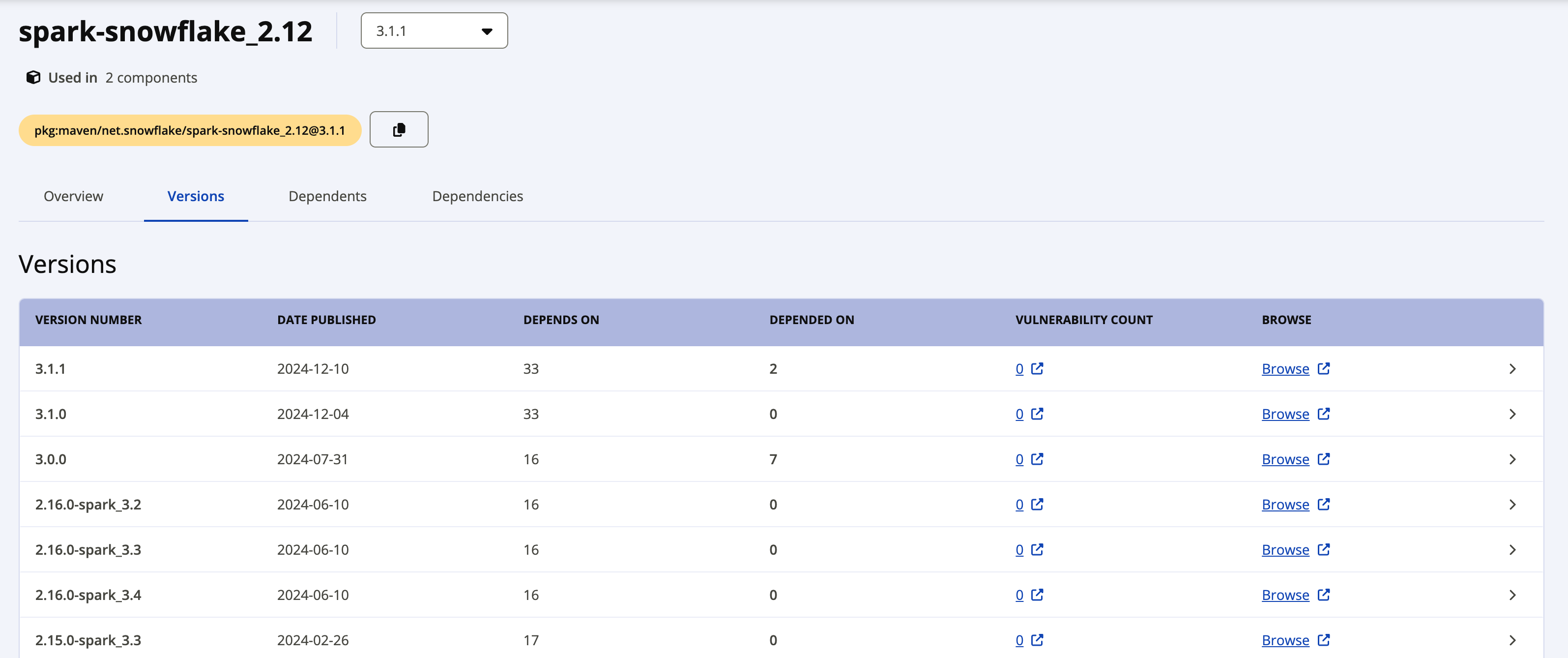
Die einzelnen Pakete für Snowflake Spark Connector Version 2.x verwenden die folgende Namenskonvention:
Wobei:
C.Cist die Scala-Version (z. B. 2.12).N.N.Nist die Snowflake-Version (z. B. 2.16.0).P.Pist die Spark-Version (z. B. 3.4).
Beispiel:
Die einzelnen Pakete für Snowflake Spark Connector Version 3.x verwenden die folgende Namenskonvention:
Wobei:
C.Cist die Scala-Version (z. B. 2.13).N.N.Nist die Snowflake-Version (z. B. 3.1.1).
Beispiel:
Klicken Sie auf den Link Browse neben der Version, die Sie herunterladen möchten, wählen Sie dann die JAR-Datei aus und laden Sie sie herunter.

Wenn Sie die Paketsignatur überprüfen möchten, müssen Sie die Signaturdatei ebenfalls herunterladen. Klicken Sie auf den Dateinamen mit der Dateinamenerweiterung
.jar.asc(z. B. net.snowflake:spark-snowflake_2.13:3.1.1.jar.asc oder net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4.jar.asc).
GitHub¶
Der Quellcode für den Snowflake-Konnektor für Spark ist auf GitHub verfügbar. Die kompilierten Pakete sind jedoch nicht auf GitHub verfügbar. Sie können die kompilierten Pakete von Maven herunterladen.
Schritt 2: Kompatible Version des Snowflake-JDBC-Treibers herunterladen¶
Als Nächstes müssen Sie die Version des Snowflake-JDBC-Treibers herunterladen, die mit der von Ihnen verwendeten Version des Snowflake Spark Connectors kompatibel ist.
Der Snowflake-JDBC-Treiber wird als Standard-Java-Paket über die Seite für den JDBC-Treiber im Maven Central Repository bereitgestellt. Sie können das Paket entweder als .jar-Datei herunterladen oder direkt das Paket referenzieren. Bei dieser Anleitung wird davon ausgegangen, dass Sie das Paket referenzieren.
Informationen zu der für Ihre Version des Snowflake-Spark-Konnektors unterstützte Version des Snowflake-JDBC-Treibers finden Sie unter Snowflake Connector for Spark-Versionshinweise.
Weitere Informationen zum Herunterladen und Installieren des Snowflake-JDBC-Treibers finden Sie unter Herunterladen und Integrieren des JDBC-Treibers.
Schritt 3 (optional): Überprüfen der Paketsignatur des Snowflake-Konnektors für Spark¶
So überprüfen Sie die Paketsignatur des Snowflake-Konnektors für Spark:
Laden Sie vom öffentlichen Keyserver den öffentlichen Snowflake-GPG-Schlüssel in der von Ihnen verwendeten Version des Snowflake-Konnektors für Spark herunter, und importieren Sie diesen:
Für Version 3.1.2 und höher:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 2A3149C82551A34A
Für Version 3.1.0 bis 3.1.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 5A125630709DD64B
Für die Versionen 2.11.1 bis 3.0.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 630D9F3CAB551AF3
Für die Versionen 2.8.2 bis 2.11.0:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 37C7086698CB005C
Für Version 2.4.13 bis 2.8.1:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys EC218558EABB25A1
Für Version 2.4.12 und niedriger:
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 93DB296A69BE019A
Bemerkung
Wenn dieser Befehl mit der folgenden Fehlermeldung fehlschlägt:
Geben Sie an, dass Sie für den Keyserver Port 80 verwenden möchten:
Führen Sie den Befehl
gpg --verifyaus, um die Signatur des Pakets zu überprüfen.Geben Sie für das Kommandozeilenflag
--verifydie.asc-Datei, die sie zuvor heruntergeladen haben, als Signaturdatei an, und die JAR-Datei als Datei mit den signierten Daten.Wobei:
x.xxist die Scala-Version (z. B. 2.12).N.N.Nist die Version des Snowflake Connectors für Spark (z. B. 2.16.0).P.Pist die Spark-Version (z. B. 3.4).
Bemerkung
Die Überprüfung der Signatur führt zu einer Warnung ähnlich der folgenden:
Um die Warnung zu vermeiden, können Sie dem öffentlichen Snowflake-GPG-Schlüssel implizites Vertrauen gewähren.
Ihre lokale Umgebung kann mehrere GPG-Schlüssel enthalten. Aus Sicherheitsgründen rotiert Snowflake jedoch regelmäßig den öffentlichen GPG-Schlüssel. Als Best Practice empfehlen wir, den vorhandenen öffentlichen Schlüssel zu löschen, nachdem wir bestätigt haben, dass der letzte Schlüssel mit dem zuletzt signierten Paket funktioniert. Beispiel:
Schritt 4: Lokales Spark-Cluster oder die von Amazon EMR gehostete Spark-Umgebung konfigurieren¶
Wenn Sie eine lokale Spark-Installation oder eine Spark-Installation in Amazon EMR verwenden, müssen Sie das spark-shell-Programm so konfigurieren, dass es sowohl den Snowflake-JDBC-Treiber als auch den Spark-Konnektor enthält:
Zum Einbinden des Snowflake-JDBC-Treibers verwenden Sie die Option
--packagemit der Referenz zum JDBC-Paket auf der Seite für den JDBC-Treiber im Maven Central Repository, das die passende Version des gewünschten Treibers bereitstellt (z. B.net.snowflake:snowflake-jdbc:3.13.30).Zum Einbinden des Spark-Konnektors verwenden Sie die Option
--packagemit der Referenz zum entsprechenden Paket (Scala 2.12 oder Scala 2.13), das im Maven Central Repository gehostet wird und die passende Version des gewünschten Treibers enthält (z. B.net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4).
Beispiel:
Installieren zusätzlicher Pakete (falls erforderlich)¶
Abhängig von Ihrer Spark-Installation fehlen möglicherweise einige vom Konnektor benötigte Pakete. Sie können Pakete, die Ihrer Installation fehlen, hinzufügen, indem Sie das entsprechende Flag für spark-shell verwenden:
--packages--jars(wenn die Pakete als.jar-Dateien heruntergeladen wurden)
Die erforderlichen Pakete sind unten mit der Syntax (einschließlich Versionsnummer) für die Verwendung des --packages-Flags zum Verweisen auf die Pakete aufgeführt:
org.apache.hadoop:hadoop-aws:2.7.1org.apache.httpcomponents:httpclient:4.3.6org.apache.httpcomponents:httpcore:4.3.3com.amazonaws:aws-java-sdk-core:1.10.27com.amazonaws:aws-java-sdk-s3:1.10.27com.amazonaws:aws-java-sdk-sts:1.10.27
Wenn beispielsweise die Apache-Pakete fehlen, können Sie die Pakete per Referenz hinzufügen:
Vorbereiten eines externen Speicherorts für Dateien¶
Möglicherweise müssen Sie einen externen Speicherort für Dateien vorbereiten, die Sie zwischen Snowflake und Spark übertragen möchten.
Die Ausführung dieser Aufgabe ist erforderlich, wenn eine der folgenden Situationen zutrifft:
Sie möchten Jobs ausführen, die länger als 36 Stunden dauern. Dies ist die maximale Dauer für das Token, das der Konnektor verwendet, um auf den internen Stagingbereich für den Datenaustausch zuzugreifen.
Die Snowflake-Konnektor für Spark-Version ist 2.1.x oder niedriger (auch wenn Ihre Jobs weniger als 36 Stunden benötigen).
Bemerkung
Wenn Sie derzeit nicht die Version 2.2.0 (oder höher) des Konnektors verwenden, empfiehlt Snowflake dringend ein Upgrade auf die neueste Version.
Vorbereiten eines externen AWS S3-Buckets¶
Bereiten Sie einen externen S3-Bucket vor, mit dem der Konnektor Daten zwischen Snowflake und Spark austauschen kann. Anschließend stellen Sie dem Konnektor die Speicherortinformationen sowie die für den AWS-Zugang am Speicherort erforderlichen Anmeldeinformationen zur Verfügung. Weitere Details dazu finden Sie unter dem nächsten Thema unter Authentifizierung von S3 für den Datenaustausch.
Wichtig
Wenn Sie einen externen S3-Bucket verwenden, entfernt der Konnektor nicht automatisch die zwischengespeicherten/temporären Daten von diesem Speicherort. Daher ist es am besten, einen bestimmten Bucket oder Pfad (Präfix) zu verwenden und eine Lebenszyklusrichtlinie für den Bucket/Pfad festzulegen, um ältere Dateien automatisch zu bereinigen. Weitere Informationen zur Konfiguration einer Lebenszyklusrichtlinie finden Sie in der Amazon S3-Dokumentation.
Vorbereiten eines Azure Blob-Speichercontainers¶
Bereiten Sie einen externen Azure Blob-Speichercontainer vor, über den der Konnektor Daten zwischen Snowflake und Spark austauschen kann. Stellen Sie anschließend dem Konnektor die Speicherortinformationen sowie die für den Azure-Zugang am Speicherort erforderlichen Anmeldeinformationen zur Verfügung. Weitere Details dazu finden Sie unter dem nächsten Thema unter Authentifizieren von Azure für den Datenaustausch.