Installation et configuration du connecteur Spark¶
Plusieurs versions du connecteur sont prises en charge. Cependant, Snowflake recommande fortement d’utiliser la version la plus récente du connecteur. Pour voir les informations de publication sur la dernière version, voir les notes de version du connecteur Spark (lien dans la barre latérale).
Les instructions de ce chapitre peuvent être utilisées pour installer et configurer toutes les versions du connecteur prises en charge.
Versions prises en charge¶
Snowflake prend en charge plusieurs versions du connecteur :
Versions de Snowflake Connector for Spark : |
3.x, 2.x |
Versions Spark prises en charge : |
Connector version 3.x : Spark 3.5, 3.4, 3.3, 3.2 . Connector version 2.x: Spark 3.4, 3.3, 3.2 |
Versions Scala prises en charge : |
Scala 2.13 . Scala 2.12 |
Nom de source de données : |
Connector versions 3.x et 2.x : |
Nom de pack (pour des classes importées) : |
|
Distribution de pack : |
Scala 2.13 dans le dépôt central Maven . Scala 2.12 dans le Maven Central Repository |
Code source : |
spark-snowflake (GitHub) . |
Les notes du développeur des différentes versions sont hébergées avec le code source.
Note
3.x : une seule version de Snowflake Connector for Spark – la version 3.0.0 ou ultérieure – prend en charge plusieurs versions de Spark.
2.x : la version 2.x de Snowflake Connector for Spark prend généralement en charge les trois versions les plus récentes de Spark. Téléchargez une version du connecteur spécifique à votre version de Spark. Par exemple, pour utiliser la version 2.16.0 du connecteur avec Spark version 3.4, téléchargez la version
2.16.0-spark_3.4du connecteur.Pour appliquer des politiques de protection des données lors de l’interrogation de tables Apache Iceberg™ à partir d’Apache Spark™, vous devez installer 3.1.6 ou une version ultérieure.
Exigences¶
Pour installer et utiliser Snowflake avec Spark, vous avez besoin des éléments suivants :
Un système d’exploitation pris en charge. Pour obtenir la liste des systèmes d’exploitation pris en charge, voir Prise en charge par les systèmes d’exploitation.
Connecteur Snowflake pour Spark.
Pilote JDBC de Snowflake (la version compatible avec la version du connecteur).
Environnement Apache Spark, auto-hébergé ou hébergé dans l’une des formes suivantes :
De plus, vous pouvez utiliser un compartiment Amazon S3 dédié ou un conteneur Azure Blob Storage comme zone de mise en zone de préparation entre les deux systèmes. Cependant, cela n’est pas nécessaire avec la version 2.2.0 (et supérieure) du connecteur qui utilise une zone de préparation interne temporaire Snowflake (par défaut) pour tout échange de données.
Le rôle utilisé dans la connexion nécessite les privilèges USAGE et CREATE STAGE sur le schéma qui contient la table que vous allez lire ou dans laquelle vous allez écrire.
Note
Si vous utilisez Databricks ou Qubole pour héberger Spark, vous n’avez pas besoin de télécharger ou d’installer le connecteur Snowflake pour Spark (ni aucun de ses prérequis). Databricks et Qubole ont tous deux intégré le connecteur pour fournir une connectivité native.
Pour plus de détails, voir :
Vérification de la version du connecteur ou du pilote OCSP¶
Snowflake utilise OCSP pour évaluer la chaîne de certificats lors d’une connexion à Snowflake. La version du pilote ou du connecteur et sa configuration déterminent le comportement OCSP. Pour plus d’informations sur la version du pilote ou du connecteur, leur configuration et le comportement de OCSP, voir Configuration d’OCSP.
Téléchargement et installation du connecteur¶
Les instructions de cette section concernent la version 2.x et les versions supérieures du connecteur Snowflake pour Spark.
Important
Snowflake publie périodiquement de nouvelles versions du connecteur. Les tâches d’installation suivantes doivent être effectuées chaque fois que vous installez une nouvelle version. Ceci s’applique également au pilote JDBC Snowflake qui est une condition préalable pour le connecteur Spark.
Étape 1 : Téléchargement de la dernière version du connecteur Snowflake Connector pour Spark¶
Snowflake fournit plusieurs versions du connecteur. Téléchargez la version appropriée en fonction des éléments suivants :
La version du connecteur Snowflake pour Spark que vous souhaitez utiliser.
La version de Spark que vous utilisez.
La version de Scala que vous utilisez.
Vous pouvez télécharger le connecteur Snowflake Spark à partir de Maven. Si vous souhaitez compiler le pilote, vous pouvez accéder au code source à partir de GitHub.
Maven Central Repository¶
Snowflake fournit des artefacts de paquet distincts pour chaque version de Scala prise en charge (2.12 et 2.13). Pour chacune de ces versions de Scala, Snowflake fournit différentes versions du connecteur Spark ainsi que des artefacts séparés qui prennent en charge différentes versions de Spark.
Pour télécharger le connecteur Spark :
Recherchez dans le référentiel Maven la version souhaitée de Snowflake Connector for Spark :
La capture d’écran suivante fournit un exemple de la page de résultats de recherche :

L’étiquette Latest version indique la version la plus récente du pilote. Si vous souhaitez télécharger une version antérieure, cliquez sur le lien View all à côté de la dernière version pour voir tous les paquets disponibles. La capture d’écran suivante montre un exemple de tous les paquets disponibles pour spark-snowflake_2.12.
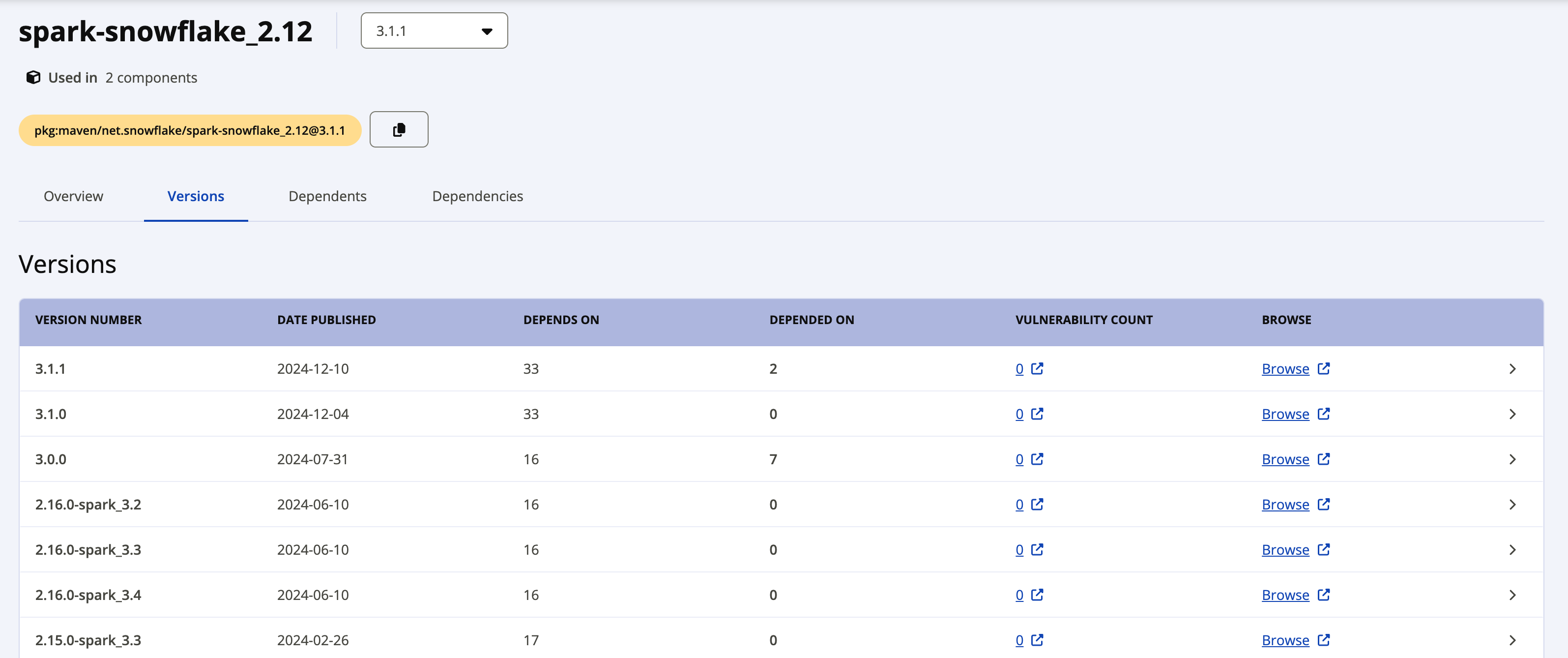
Les paquets individuels pour la version 2.x de Snowflake Connector for Spark utilisent la convention de nommage suivante :
où :
C.Cest la version de Scala (par exemple 2.12).N.N.Nest la version de Snowflake (par ex. 2.16.0).P.Pest la version de Spark (par ex. 3.4).
Par exemple :
Les paquets individuels de la version 3.x de Snowflake Connector for Spark utilisent la convention de nommage suivante :
où :
C.Cest la version de Scala (par ex. 2.13).N.N.Nest la version de Snowflake (par ex. 3.1.1).
Par exemple :
Cliquez sur le lien Browse à côté de la version que vous souhaitez télécharger, puis sélectionnez et téléchargez le fichier JAR.

Si vous prévoyez de vérifier la signature du pack, vous devez également télécharger le fichier de signature. Cliquez sur le nom de fichier portant l’extension
. jar.asc(par exemple, net.snowflake:spark-snowflake_2.13:3.1.1.jar.asc ou net.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4.jar.asc).
GitHub¶
Le code source du connecteur Spark Snowflake est disponible sur GitHub. Cependant, les paquets compilés ne sont pas disponibles sur GitHub. Vous pouvez télécharger les paquets compilés depuis Maven.
Étape 2 : Téléchargement de la version compatible du pilote JDBC Snowflake¶
Ensuite, vous devez télécharger la version du pilote JDBC de Snowflake qui est compatible avec la version du connecteur Snowflake Spark que vous utilisez.
Le pilote JDBC Snowflake est fourni comme pack Java standard via la page Pilote JDBC du dépôt central de Maven. Vous pouvez soit télécharger le pack sous la forme d’un fichier .jar, ou vous pouvez directement faire référence au pack. Ces instructions supposent que vous faites référence au pack.
Pour trouver la version prise en charge par le pilote JDBC de Snowflake pour la version du Snowflake Spark Connector que vous utilisez, voir Notes de version de Snowflake Connector for Spark.
Pour plus de détails sur le téléchargement et l’installation du pilote JDBC Snowflake, voir Téléchargement/intégration du pilote JDBC.
Étape 3 (facultative) : Vérification du connecteur Snowflake pour la signature du pack Spark¶
Pour vérifier le connecteur Snowflake pour la signature du pack Spark :
Depuis le serveur de clés publiques, téléchargez et importez la clé publique Snowflake GPG pour la version du connecteur Snowflake pour Spark que vous utilisez :
Pour la version 3.1.2 et supérieure :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 2A3149C82551A34A
Pour les versions 3.1.0 à 3.1.1 :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 5A125630709DD64B
Pour les versions 2.11.1 à 3.0.0 :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 630D9F3CAB551AF3
Pour les versions 2.8.2 à 2.11.0 :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 37C7086698CB005C
Pour les versions 2.4.13 à 2.8.1 :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys EC218558EABB25A1
Pour les versions 2.4.12 et inférieures :
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 93DB296A69BE019A
Note
Si cette commande échoue avec l’erreur suivante :
alors spécifiez que vous voulez utiliser le port 80 pour le serveur de clés :
Exécutez la commande
gpg --verifypour vérifier la signature du pack.Pour l’indicateur de ligne de commande
--verify, spécifiez le fichier.ascque vous avez téléchargé précédemment comme fichier de signature et le fichier JAR comme fichier contenant les données signées.où :
x.xxest la version de Scala (par exemple 2.12).N.N.Nest la version de Snowflake Connector for Spark (par ex. 2.16.0).P.Pest la version de Spark (par ex. 3.4).
Note
La vérification de la signature crée un avertissement similaire à celui qui suit :
Pour éviter l’avertissement, vous pouvez accorder la confiance implicite à la clé publique GPG Snowflake.
Votre environnement local peut contenir plusieurs clés GPG. Cependant, pour des raisons de sécurité, Snowflake fait tourner périodiquement la clé publique GPG. Nous recommandons de supprimer la clé publique existante après avoir confirmé que la dernière clé fonctionne avec le dernier pack signé. Par exemple :
Étape 4 : Configuration du cluster local Spark ou de l’environnement Spark hébergé sur Amazon EMR¶
Si vous avez une installation Spark locale ou une installation Spark dans Amazon EMR, vous devez configurer le programme spark-shell pour inclure le pilote JDBC Snowflake et le connecteur Spark :
Pour inclure le pilote JDBC Snowflake, utilisez l’option
--packagepour faire référence au pack JDBC provenant de la page Pilote JDBC dans le Maven Central Repository, fournissant la version exacte du pilote que vous souhaitez utiliser (c-à-dnet.snowflake:snowflake-jdbc:3.13.30).Pour inclure le connecteur Spark, utilisez l’option
--packagepour faire référence au pack correspondant (Scala 2.12 ou Scala 2.13) hébergé dans le Maven Central Repository fournissant la version exacte du pilote que vous souhaitez utiliser (c-à-dnet.snowflake:spark-snowflake_2.12:2.16.0-spark_3.4).
Par exemple :
Installation de packs supplémentaires (si nécessaire)¶
En fonction de votre installation Spark, certains packs requis par le connecteur peuvent être manquants. Vous pouvez ajouter des packs manquants à votre installation en utilisant l’indicateur correspondant pour spark-shell :
--packages--jars(si les packs ont été téléchargés en tant que fichiers.jar)
Les packs requis sont répertoriés ci-dessous, avec la syntaxe (y compris le numéro de version) pour utiliser l’indicateur --packages pour faire référence aux packs :
org.apache.hadoop:hadoop-aws:2.7.1org.apache.httpcomponents:httpclient:4.3.6org.apache.httpcomponents:httpcore:4.3.3com.amazonaws:aws-java-sdk-core:1.10.27com.amazonaws:aws-java-sdk-s3:1.10.27com.amazonaws:aws-java-sdk-sts:1.10.27
Par exemple, s’il manque les packs Apache, pour ajouter les packs par référence :
Préparation d’un emplacement externe pour les fichiers¶
Vous devrez peut-être préparer un emplacement externe pour les fichiers que vous voulez transférer entre Snowflake et Spark.
Cette tâche est requise si l’une des situations suivantes est vraie :
Vous exécuterez des tâches qui mettent plus de temps que 36 heures. Il s’agit de la durée maximale du jeton utilisé par le connecteur pour accéder à la zone de préparation interne pour l’échange de données.
La version Snowflake Connector pour Spark est la 2.1.x ou inférieure (même si vos tâches nécessitent moins de 36 heures).
Note
Si vous n’utilisez pas actuellement la version 2.2.0 (ou supérieure) du connecteur, Snowflake recommande vivement la mise à niveau vers la dernière version.
Préparation d’un compartiment S3 AWS externe¶
Préparez un compartiment S3 externe que le connecteur peut utiliser pour échanger des données entre Snowflake et Spark. Vous fournissez ensuite au connecteur les informations d’emplacement, ainsi que les informations d’identification AWS nécessaires pour l’emplacement. Pour plus de détails, voir Authentification S3 pour l’échange de données dans le chapitre suivant.
Important
Si vous utilisez un compartiment S3 externe, le connecteur ne supprime pas automatiquement les données intermédiaires/temporaires de cet emplacement. Par conséquent, il est préférable d’utiliser un compartiment ou un chemin spécifique (préfixe), et de définir une politique de cycle de vie sur le compartiment/chemin pour nettoyer automatiquement les anciens fichiers. Voir la documentation Amazon S3 pour plus de détails sur la configuration d’une politique de cycle de vie.
Préparation d’un conteneur de stockage Azure Blob¶
Préparez un conteneur de stockage externe Azure Blob que le connecteur peut utiliser pour échanger des données entre Snowflake et Spark. Vous fournissez ensuite au connecteur les informations d’emplacement, ainsi que les informations d’identification Azure nécessaires pour l’emplacement. Pour plus de détails, voir Authentification Azure pour l’échange de données dans le chapitre suivant.