pandas on Snowflake¶
Mit pandas on Snowflake können Sie Ihren Pandas-Code direkt für Ihre Daten in Snowflake ausführen. Durch eine Änderung der Importanweisung und von ein paar Zeilen Code erhalten Sie die vertraute Pandas-Erfahrung, um robuste Pipelines zu entwickeln, und profitieren gleichzeitig von der Leistung und Skalierbarkeit von Snowflake bei der Skalierung Ihrer Pipelines.
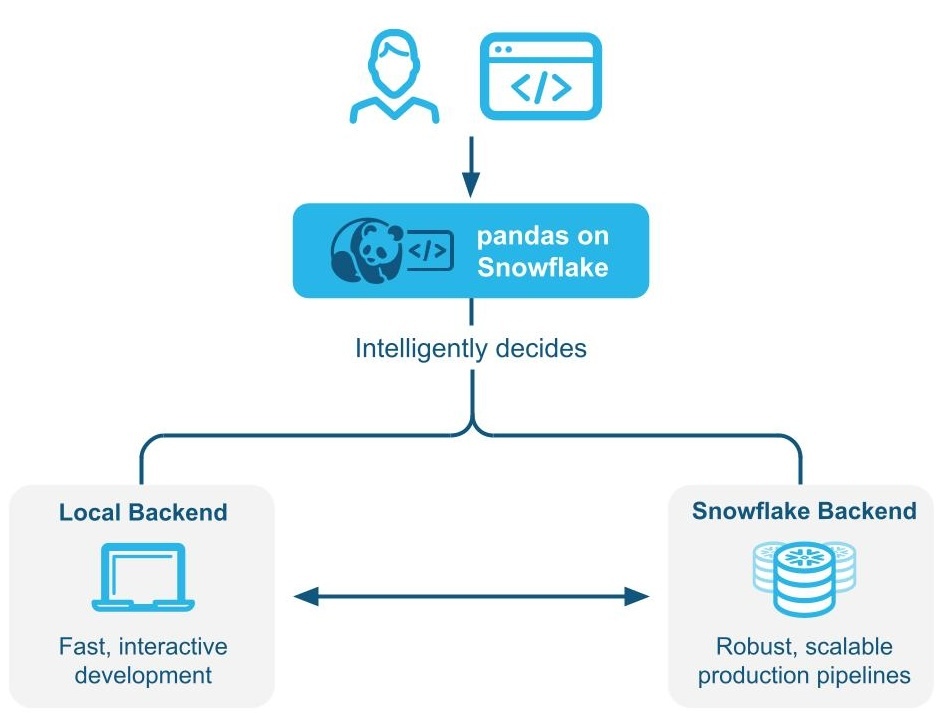
pandas on Snowflake bestimmt intelligent, ob der pandas-Code lokal ausgeführt werden soll oder die Snowflake-Engine verwendet wird, um die Leistung durch hybride Ausführung zu skalieren und zu verbessern. Bei der Arbeit mit großen Datensets in Snowflake, führt Snowpark pandas Workloads nativ in Snowflake durch Transpilierung nach SQL aus und kann so die Vorteile der Parallelisierung und der Data Governance und Sicherheit von Snowflake nutzen.
pandas on Snowflake wird über die Snowpark pandas APIals Teil der Snowpark-Bibliothek für Python bereitgestellt, die eine skalierbare Datenverarbeitung von Python-Code innerhalb der Snowflake-Plattform ermöglicht.
Vorteile der Verwendung von pandas on Snowflake¶
Trifft Python-Entwickler dort, wo sie sind: pandas on Snowflake bietet Python-Entwicklern eine vertraute Schnittstelle, indem sie eine pandas-kompatible Schicht bereitstellt, die nativ in Snowflake ausgeführt werden kann.
Skalierbares verteiltes pandas: pandas on Snowflake verbindet die praktischen Vorteile von pandas mit der Skalierbarkeit von Snowflake, indem vorhandene Abfrageoptimierungstechniken von Snowflake genutzt werden. Es sind nur minimale Änderungen am Code erforderlich, was die Migration vereinfacht, so dass Sie nahtlos vom Prototyp zur Produktion übergehen können.
Keine zusätzliche Compute-Infrastruktur, die verwaltet und optimiert werden muss: pandas on Snowflake nutzt die leistungsstarke Compute-Engine von Snowflake, so dass Sie keine zusätzliche Compute-Infrastruktur einrichten oder verwalten müssen.
Erste Schritte mit pandas on Snowflake¶
Bemerkung
Ein praktisches Beispiel für die Verwendung von pandas on Snowflake finden Sie in diesem Notebook. Sehen Sie sich auf dieses Video an.
Um pandas on Snowflake zu installieren, können Sie conda oder pip verwenden, um das Paket zu installieren. Ausführliche Anweisungen finden Sie unter Installation.
Sobald pandas on Snowflake installiert ist, verwenden Sie statt des Imports von pandas als import pandas as pd die folgenden beiden Zeilen:
Hier sehen Sie ein Beispiel, wie Sie pandas on Snowflake über die pandas auf der Snowpark Python-Bibliothek mit Modin verwenden können.
read_snowflake unterstützt das Lesen von Snowflake-Ansichten, dynamischen Tabellen, Iceberg-Tabellen und mehr. Sie können eine SQL-Abfrage auch direkt übergeben und einen pandas on Snowflake-DataFrame erhalten, sodass Sie nahtlos zwischen SQL und pandas on Snowflake wechseln können.
Funktionsweise der hybriden Ausführung¶
Bemerkung
Ab Snowpark Python Version 1.40.0 ist die Hybridausführung standardmäßig aktiviert, wenn Sie pandas on Snowflake verwenden.
pandas on Snowflake verwendet die hybride Ausführung, um zu bestimmen, ob der pandas-Code lokal ausgeführt werden soll oder die Snowflake-Engine zur Skalierung und Verbesserung der Leistung verwendet wird. So können Sie weiterhin vertrauten pandas-Code schreiben, um robuste Pipelines zu entwickeln, ohne sich Gedanken über die optimalste und effizienteste Art und Weise machen zu müssen, Ihren Code auszuführen, während Sie gleichzeitig von der Leistung und Skalierbarkeit von Snowflake profitieren, wenn Ihre Pipelines skaliert werden.
Beispiel 1 Erstellen Sie ein kleines, 11-Zeilen-DataFrame inline. Bei der Hybridausführung wählt Snowflake das lokale, speicherinterne pandas-Backend für die Ausführung des Vorgangs aus:
Beispiel 2 Startwert für eine Tabelle mit 10 Millionen Zeilen von Transaktionen
Sie sehen, dass die Tabelle Snowflake als Backend nutzt, da es sich um eine große Tabelle handelt, die sich in Snowflake befindet.
Beispiel 3: Daten filtern und eine groupby-Aggregation ausführen, die zu 7 Datenzeilen führt.
Wenn Daten gefiltert werden, erkennt Snowflake implizit die Auswahl des Backends von Engine-Änderungen von Snowflake zu pandas, da die Ausgabe nur 7 Datenzeilen umfasst.
Hinweise und Beschränkungen¶
Der DataFrame-Typ ist immer
modin.pandas.DataFrame/Series/etc, auch wenn sich das Backend ändert, um die Interoperabilität/Kompatibilität mit nachgelagertem Code sicherzustellen.Um zu bestimmen, welches Backend verwendet werden soll, verwendet Snowflake manchmal eine Schätzung der Zeilengröße, anstatt die genaue Länge des DataFrame bei jedem Schritt zu berechnen. Das bedeutet, dass Snowflake nicht immer sofort nach einem Vorgang zum optimalen Backend wechselt, wenn das Datenset größer/kleiner wird (z. B. Filtern, Aggregation).
Wenn bei einem Vorgang zwei oder mehr DataFrames über verschiedene Backends hinweg kombiniert werden, bestimmt Snowflake auf der Grundlage der niedrigsten Datenübertragungskosten, wohin die Daten verschoben werden sollen.
Filtervorgänge führen möglicherweise nicht zu einer Bewegung von Daten, da Snowflake möglicherweise nicht in der Lage ist, die Größe der zugrundeliegenden gefilterten Daten zu schätzen.
DataFrames, die aus speicherinternen Python-Daten bestehen, verwenden das pandas-Backend, wie z. B.:
DataFrames werden bei einer begrenzten Anzahl von Vorgängen automatisch von der Snowflake-Engine zur pandas-Engine verschoben. Zu diesen Vorgängen gehören
df.apply,df.plot,df.iterrows,df.itertuples,series.items, und bei Reduzierungsvorgängen, bei denen die Datenmenge garantiert kleiner ist. Nicht alle Vorgänge sind unterstützte Punkte, an denen eine Datenmigration erfolgen kann.Die Hybridausführung verschiebt einen DataFrame nicht automatisch von der pandas-Engine zurück zu Snowflake, außer in Fällen, in denen ein Vorgang wie
pd.concatauf mehrere DataFrames Auswirkungen hat.Snowflake verschiebt einen DataFrame nicht automatisch von der pandas-Engine zurück zu Snowflake, es sei denn, ein Vorgang wie
pd.concathat Auswirkungen auf DataFrames.
Wann Sie pandas on Snowflake verwenden sollten¶
Sie sollten pandas on Snowflake verwenden, wenn einer der folgenden Punkte zutrifft:
Sie sind mit den pandas-API und dem breiteren PyData-Ökosystem vertraut
Sie arbeiten in einem Team mit anderen, die mit pandas vertraut sind und an der gleichen Codebasis zusammenarbeiten möchten
Sie haben vorhandenen Code, der in pandas geschrieben ist
Sie bevorzugen die genauere Code-Vervollständigung von AI-basierten Copilot-Tools
Weitere Informationen dazu finden Sie unter Snowpark DataFrames vs Snowpark pandas DataFrame: Was sollte ich wählen?
Verwendung von pandas on Snowflake mit Snowpark DataFrames¶
Die pandas on Snowflake und DataFrame API sind in hohem Maße interoperabel, so dass Sie eine Pipeline erstellen können, die beide APIs nutzt. Weitere Informationen dazu finden Sie unter Snowpark DataFrames vs Snowpark pandas DataFrame: Was sollte ich wählen?
Sie können die folgenden Operationen verwenden, um Konvertierungen zwischen Snowpark-DataFrames und Snowpark pandas-DataFrames durchzuführen:
Operation |
Eingabe |
Ausgabe |
|---|---|---|
Snowpark DataFrame |
Snowpark pandas-DataFrame |
|
Snowpark pandas-DataFrame oder Snowpark pandas Series |
Snowpark DataFrame |
Vergleich von pandas on Snowflake mit nativen Pandas¶
pandas on Snowflake und natives pandas haben ähnliche DataFrame-APIs mit übereinstimmenden Signaturen und ähnlicher Semantik. pandas on Snowflake bietet die gleiche API-Signatur wie natives pandas und bietet skalierbare Berechnungen mit Snowflake. pandas on Snowflake respektiert die in der Dokumentation zum nativen pandas beschriebene Semantik so weit wie möglich, verwendet aber das Verarbeitungs- und Typensystem von Snowflake. Wenn natives pandas jedoch auf einem Clientcomputer ausgeführt wird, verwendet es das Verarbeitungs- und Typensystem von Python. Informationen über die Typzuordnung zwischen pandas on Snowflake und Snowflake finden Sie unter Datentypen.
Ab Snowpark Python 1.40.0 wird pandas on Snowflake am besten mit Daten verwendet, die bereits in Snowflake vorhanden sind. Um zwischen nativem pandas und pandas on Snowflake-Typ zu konvertieren, verwenden Sie die folgenden Operationen:
Operation |
Eingabe |
Ausgabe |
|---|---|---|
Snowpark pandas-DataFrame |
Nativer pandas-DataFrame: Materialisiert alle Daten in der lokalen Umgebung. Wenn das Datenset sehr groß ist, kann dies zu einem Fehler wegen unzureichendem Arbeitsspeicher führen. |
|
Native pandas DataFrame, Rohdaten, Snowpark pandas-Objekt |
Snowpark pandas-DataFrame |
Ausführungsumgebung¶
pandas: Arbeitet auf einem einzigen Computer und verarbeitet Daten im Arbeitsspeicher.pandas on Snowflake: Integriert in Snowflake, das verteiltes Computing über einen Cluster von Rechnern für große Datensets ermöglicht, während pandas im Arbeitsspeicher für die Verarbeitung kleiner Datensets genutzt wird. Diese Integration ermöglicht die Verarbeitung viel größerer Datensets, die die Kapazität des Arbeitsspeichers eines einzelnen Rechners übersteigen würden. Beachten Sie, dass die Verwendung der Snowpark pandas-API eine Verbindung zu Snowflake erfordert.
Lazy- vs. Eager-Evaluation¶
pandas: Führt Operationen sofort aus und materialisiert die Ergebnisse nach jeder Operation vollständig im Arbeitsspeicher. Diese Eager-Evaluation von Operationen kann zu einem erhöhten Arbeitsspeicherdruck führen, da Daten innerhalb eines Computers umfangreich verschoben werden müssen.pandas on Snowflake: Bietet die gleiche API-Erfahrung wie pandas. Es ahmt das Eager-Evaluationsmodell von pandas nach, baut aber intern einen Lazy-evaluierten Abfragegraphen auf, um eine Optimierung über alle Operationen hinweg zu ermöglichen.Das Zusammenführen und Transpilieren von Operationen über einen Abfragegraphen ermöglicht zusätzliche Optimierungsmöglichkeiten für die zugrunde liegende verteilte Snowflake-Computing-Engine, was sowohl die Kosten als auch die Laufzeit der End-to-End-Pipeline im Vergleich zur direkten Ausführung von pandas in Snowflake verringert.
Bemerkung
Für E/A-bezogene APIs sowie APIs, deren Rückgabewert kein Snowpark pandas-Objekt ist (d. h.
DataFrame,SeriesoderIndex), erfolgt immer eine Eager-Evaluation. Beispiel:read_snowflaketo_snowflaketo_pandasto_dictto_list__repr__Die Dunder-Methode
__array__, die von einigen Drittanbieter-Bibliotheken wie scikit-learn automatisch aufgerufen werden kann. Aufrufe dieser Methode materialisieren die Ergebnisse auf dem lokalen Computer.
Datenquelle und Datenspeicher¶
pandas: Unterstützt die verschiedenen Reader und Writer, die in der pandas-Dokumentation unter IO Tools (text, CSV, HDF5 …) aufgeführt sind.pandas on Snowflake: Kann aus Snowflake-Tabellen lesen und schreiben und lokale oder im Stagingbereich befindliche CSV-, JSON- oder Parquet-Dateien lesen. Weitere Informationen dazu finden Sie unter IO (Lesen und Schreiben).
Datentypen¶
pandas: Bietet eine Vielzahl von Datentypen, wie z. B. Ganzzahlen, Fließkommazahlen, Zeichenfolgen,datetime-Typen und kategorische Typen. Es unterstützt auch benutzerdefinierte Datentypen. Datentypen in pandas werden in der Regel von den zugrunde liegenden Daten abgeleitet und streng erzwungen.pandas on Snowflake: Ist durch das Snowflake-Typensystem begrenzt, das pandas-Objekte SQL zuordnet, indem es die pandas-Datentypen in die SQL-Typen von Snowflake übersetzt. Die meisten pandas-Typen haben eine natürliche Entsprechung in Snowflake, aber die Zuordnung ist nicht immer eins zu eins. In einigen Fällen werden mehrere pandas-Typen demselben SQL-Typ zugeordnet.
In der folgenden Tabelle sind die Typzuordnungen zwischen pandas und Snowflake SQL aufgeführt:
pandas-Typ |
Snowflake-Typ |
|---|---|
Alle Integer-Typen mit und ohne Vorzeichen, einschließlich der erweiterten Integer-Typen von pandas |
NUMBER(38, 0) |
Alle Float-Typen, einschließlich der erweiterten Float-Datentypen von pandas |
FLOAT |
|
BOOLEAN |
|
STRING |
|
TIME |
|
DATE |
Alle Zeitzonen-unabhängigen |
TIMESTAMP_NTZ |
Alle Zeitzonen-kompatiblen |
TIMESTAMP_TZ |
|
ARRAY |
|
MAP |
Objektspalte mit gemischten Datentypen |
VARIANT |
Timedelta64[ns] |
NUMBER(38, 0) |
Bemerkung
Kategoriale, Perioden-, Intervall-, Sparse- und benutzerdefinierte Datentypen werden nicht unterstützt. Timedelta wird derzeit nur auf dem pandas on Snowpark-Client unterstützt. Wenn Sie Timedelta zurück nach Snowflake schreiben, wird es als Zahlentyp gespeichert.
Die folgende Tabelle enthält die Zuordnung von Snowflake SQL-Typen zurück zu pandas on Snowflake-Typen unter Verwendung von df.dtypes:
Snowflake-Typ |
pandas on Snowflake-Typ ( |
|---|---|
NUMBER ( |
|
NUMBER ( |
|
BOOLEAN |
|
STRING, TEXT |
|
VARIANT, BINARY, GEOMETRY, GEOGRAPHY |
|
ARRAY |
|
OBJECT |
|
TIME |
|
TIMESTAMP, TIMESTAMP_NTZ, TIMESTAMP_LTZ, TIMESTAMP_TZ |
|
DATE |
|
Bei der Konvertierung von Snowpark pandas DataFrame in native pandas DataFrame mit to_pandas() haben die nativen pandas DataFrame verfeinerte Datentypen im Vergleich zu den pandas on Snowflake-Typen, die mit Zuordnung von Datentypen zwischen SQL und Python für Funktionen und Prozeduren kompatibel sind.
Umwandlung und Typ-Inferenz¶
pandas: Verlässt sich auf NumPy und folgt standardmäßig dem NumPy- und dem Python-Typsystem für implizite Typumwandlung und Typinferenz. Beispielsweise werden Boolesche Werte als Integer-Typen behandelt, sodass1 + Trueden Wert2zurückgibt.pandas on Snowflake: Ordnet NumPy und Python-Typen den Snowflake-Typen gemäß der obigen Tabelle zu und verwendet das zugrunde liegende Snowflake-Typsystem für implizite Typumwandlung und Typinferenz. Beispielsweise werden gemäß der Logische Datentypen Boolean-Typen nicht implizit in Integer-Typen konvertiert, sodass1 + Truezu einem Typkonvertierungsfehler führt.
Behandlung von Nullwerten¶
pandas: In den pandas-Versionen 1.x war pandas flexibel bei der Behandlung fehlender Daten, sodass es alle PythonNone,np.nan,pd.NaN,pd.NAundpd.NaTals fehlende Werte behandelte. In späteren Versionen von pandas (2.2.x) werden diese Werte als unterschiedliche Werte behandelt.pandas on Snowflake: Verwendet einen ähnlichen Ansatz wie frühere pandas-Versionen, bei dem alle oben aufgeführten Werte als fehlende Werte behandelt werden. Snowpark verwendet wiederNaN,NAundNaTvon pandas. Beachten Sie jedoch, dass alle diese fehlenden Werte austauschbar behandelt und als SQL NULL in der Snowflake-Tabelle gespeichert werden.
Offset-/Frequenz-Aliasse¶
pandas: Datumsoffsets in pandas wurden in Version 2.2.1 geändert. Aliasse mit einem Buchstaben'M','Q','Y'und andere wurden zugunsten von Offsets mit zwei Buchstaben veraltet.pandas on Snowflake: Verwendet ausschließlich die neuen Offsets, die in der pandas-Dokumentation zu Zeitreihen beschrieben sind.
Installieren der pandas on Snowflake-Bibliothek¶
Voraussetzungen
Die folgenden Paketversionen sind erforderlich:
Python 3.9 (veraltet), 3.10, 3.11, 3.12 oder 3.13
Modin Version 0.32.0
pandas Version 2.2.*
Tipp
Um pandas on Snowflake in Snowflake Notebooks zu verwenden, lesen Sie die Anweisungen zur Einrichtung unter pandas on Snowflake in Notebooks.
Um pandas on Snowflake in Ihrer Entwicklungsumgebung zu installieren, gehen Sie folgendermaßen vor:
Wechseln Sie in Ihr Projektverzeichnis, und aktivieren Sie Ihre virtuelle Python-Umgebung:
Bemerkung
Die API befindet sich in aktiver Entwicklung, daher empfehlen wir, sie in einer virtuellen Python-Umgebung zu installieren statt systemweit. Auf diese Weise kann jedes Projekt, das Sie erstellen, eine bestimmte Version verwenden, sodass Sie von Änderungen in zukünftigen Versionen unberührt bleiben.
Sie können eine virtuelle Python-Umgebung für eine bestimmte Python-Version mit Tools wie Anaconda, Miniconda oder virtualenv erstellen.
Um zum Beispiel mit conda eine virtuelle Umgebung für Python 3.12 zu erstellen, führen Sie folgende Befehle aus:
Bemerkung
Wenn Sie zuvor eine ältere Version von pandas on Snowflake mit Python 3.9 und pandas 1.5.3 installiert haben, müssen Sie Ihre Python- und pandas-Versionen wie oben beschrieben aktualisieren. Führen Sie die Schritte zum Erstellen einer neuen Umgebung mit Python 3.10 oder 3.13 aus.
Installieren Sie die Snowpark Python-Bibliothek mit Modin:
oder
Bemerkung
Stellen Sie sicher, dass
snowflake-snowpark-pythonVersion 1.17.0 oder höher installiert ist.
Authentifizierung mit Snowflake¶
Bevor Sie pandas on Snowflake verwenden, müssen Sie eine Sitzung mit der Snowflake-Datenbank einrichten. Sie können eine Konfigurationsdatei verwenden, um die Verbindungsparameter für Ihre Sitzung auszuwählen, oder Sie können sie in Ihrem Code spezifizieren. Weitere Informationen dazu finden Sie unter Erstellen einer Sitzung für Snowpark Python. Wenn eine eindeutige aktive Snowpark Python-Sitzung existiert, werden pandas on Snowflake diese automatisch verwenden. Beispiel:
pd.session ist eine Snowpark-Sitzung, d. h. Sie können mit ihr alles tun, was Sie auch mit jeder anderen Snowpark-Sitzung tun können. Sie können damit zum Beispiel eine beliebige SQL-Abfrage ausführen, die zu einem Snowpark DataFrame gemäß Sitzungs-API führt. Beachten Sie aber, dass das Ergebnis ein Snowpark DataFrame und kein Snowpark pandas DataFrame sein wird.
Alternativ können Sie Ihre Snowpark-Verbindungsparameter in einer Konfigurationsdatei konfigurieren. Damit entfällt die Notwendigkeit, Verbindungsparameter in Ihrem Code zu spezifizieren, sodass Sie Ihren pandas on Snowflake-Code fast so schreiben können, wie Sie normalerweise pandas-Code schreiben würden.
Erstellen Sie eine Konfigurationsdatei unter
~/.snowflake/connections.toml, die in etwa so aussieht:Um eine Sitzung mit diesen Anmeldeinformationen zu erstellen, verwenden Sie
snowflake.snowpark.Session.builder.create():
Sie können auch mehrere Snowpark-Sitzungen erstellen und dann eine davon pandas on Snowflake zuweisen. pandas on Snowflake verwendet nur eine Sitzung, daher müssen Sie eine der Sitzungen explizit pandas on Snowflake mit pd.session = pandas_session zuweisen:
Das folgende Beispiel zeigt, dass der Versuch, pandas on Snowflake zu verwenden, wenn es keine aktive Snowpark-Sitzung gibt, eine SnowparkSessionException mit einem Fehler wie „pandas on Snowflake requires an active snowpark session, but there is none“ auslöst. Sobald Sie eine Sitzung erstellt haben, können Sie pandas on Snowflake nutzen. Beispiel:
Das folgende Beispiel zeigt, dass der Versuch, pandas on Snowflake zu verwenden, wenn es mehrere aktive Snowpark-Sitzungen gibt, eine SnowparkSessionException mit einer Meldung wie „There are multiple active snowpark sessions, but you need to choose one for pandas on Snowflake“ auslöst.
Bemerkung
Sie müssen die Sitzung festlegen, die für einen neuen pandas on Snowflake-DataFrame oder eine Series über modin.pandas.session verwendet wird. Das Zusammenführen von DataFrames, das mit verschiedenen Sitzungen erstellt wurde, wird jedoch nicht unterstützt. Sie sollten also vermeiden, wiederholt verschiedene Sitzungen festzulegen und DataFrames mit verschiedenen Sitzungen in einem Workflow zu erstellen.
API-Referenz¶
Siehe die pandas on Snowflake API-Referenz für die vollständige Auflistung der derzeit implementierten APIs und verfügbaren Methoden.
Eine vollständige Liste der unterstützten Operationen finden Sie in den folgenden Tabellen in der pandas on Snowflake-Referenz:
APIs und Konfigurationsparameter für die Hybridausführung¶
Die Hybridausführung verwendet eine Kombination aus der Schätzung der Datenset-Größe und den Vorgängen, die auf den DataFrame angewendet werden, um die Wahl des Backends zu bestimmen. Im Allgemeinen wird bei Datensets unter 100.000 Zeilen lokales pandas verwendet. Bei mehr als 100.000 Zeilen wird in der Regel Snowflake verwendet, es sei denn, das Datenset wird aus lokalen Dateien geladen.
Konfigurieren der Transferkosten¶
Um den Standard-Schwellenwert für einen Wechsel in einen anderen Zeilengrenzwert zu ändern, können Sie die Umgebungsvariable vor dem Initialisieren eines DataFrame ändern:
Durch Einstellen dieses Wertes wird das Übertragen von Zeilen aus Snowflake bestraft.
Konfigurieren der lokalen Ausführungslimits¶
Sobald ein DataFrame lokal ist, bleibt er im Allgemeinen lokal, es sei denn, es ist notwendig, ihn für eine Zusammenführung zurück zu Snowflake zu verschieben. Es gibt jedoch eine Obergrenze für die maximale Datengröße, die lokal verarbeitet werden kann. Derzeit beträgt diese Grenze 10 Millionen Zeilen.
Prüfen und Einstellen des Backends¶
Um das aktuelle Backend Ihrer Wahl zu überprüfen, können Sie den Befehl df.getbackend() verwenden, der Pandas für die lokale Ausführung oder Snowflake für die Pushdown-Ausführung zurückgibt.
Um das aktuelle Backend Ihrer Wahl mit entweder set_backend oder seinem Alias move_to festzulegen:
Sie können das Backend auch direkt festlegen:
So können Sie Informationen darüber prüfen und anzeigen, warum Daten verschoben wurden:
Manuelle Überschreibung der Backend-Auswahl durch Pinning des Backends¶
Standardmäßig wählt Snowflake automatisch das beste Backend für einen bestimmten DataFrame und einen Vorgang aus. Wenn Sie die automatische Auswahl der Engine überschreiben möchten, können Sie die automatische Umschaltung für ein Objekt und alle daraus erzeugten Daten mit der Methode pin_backend() deaktivieren:
Um den automatischen Backend-Wechsel wieder zu aktivieren, rufen Sie unpin_backend() auf:
Snowpark pandas in Snowflake-Notebooks verwenden¶
Um pandas on Snowflake in Snowflake-Notebooks zu verwenden, siehe pandas on Snowflake in Notebooks.
Snowpark pandas in Python-Arbeitsblättern verwenden¶
Um Snowpark pandas zu verwenden, müssen Sie Modin installieren, indem Sie modin unter Packages in der Python-Arbeitsblattumgebung auswählen.
Sie können den Rückgabetyp der Python-Funktion unter Settings > Return type auswählen. Standardmäßig ist dies als Snowpark-Tabelle eingestellt. Um den Snowpark pandas-DataFrame als Ergebnis anzuzeigen, können Sie einen Snowpark pandas-DataFrame in einen Snowpark-DataFrame umwandeln, indem Sie to_snowpark() aufrufen. Bei dieser Konvertierung fallen keine E/A-Kosten an.
Hier sehen Sie ein Beispiel für die Verwendung von Snowpark pandas mit Python-Arbeitsblättern:
Verwendung von pandas on Snowflake in gespeicherten Prozeduren¶
Sie können pandas on Snowflake in einer gespeicherten Prozedur verwenden, um eine Datenpipeline aufzubauen und die Ausführung der gespeicherten Prozedur mit Aufgaben zu planen.
Hier sehen Sie, wie Sie eine gespeicherte Prozedur mit SQL erstellen können:
Hier sehen Sie, wie Sie eine gespeicherte Prozedur mit Snowflake Python API erstellen können:
Um die gespeicherte Prozedur aufzurufen, können Sie dt_pipeline_sproc() in Python oder CALL run_data_transformation_pipeline_sp() in SQL ausführen.
Verwendung von pandas on Snowflake mit Bibliotheken von Drittanbietern¶
pandas wird häufig zusammen mit der APIs-Bibliothek von Drittanbietern für Visualisierungs- und Machine Learning-Anwendungen verwendet. pandas on Snowflake ist mit den meisten dieser Bibliotheken interoperabel, so dass sie ohne explizite Konvertierung in pandas DataFrames verwendet werden können. Beachten Sie jedoch, dass die verteilte Ausführung in den meisten Bibliotheken von Drittanbietern nicht unterstützt wird, außer in bestimmten Anwendungsfällen. Dies kann daher zu einer langsameren Leistung bei großen Datensätzen führen.
Unterstützte Bibliotheken von Drittanbietern¶
Die unten aufgeführten Bibliotheken akzeptieren pandas on Snowflake DataFrames als Eingabe, aber nicht alle ihre Methoden wurden getestet. Einen detaillierten Status der Interoperabilität auf der API-Ebene finden Sie unter Interoperabilität mit Bibliotheken von Drittanbietern.
Plotly
Altair
Seaborn
Matplotlib
Numpy
Scikit-learn
XGBoost
NLTK
Streamlit
pandas on Snowflake hat derzeit eine beschränkte Kompatibilität für bestimmte NumPy und Matplotlib APIs, wie die verteilte Implementierung für np.where und die Interoperabilität mit df.plot. Wenn Sie Snowpark pandas DataFrames über to_pandas() konvertieren, wenn Sie mit diesen Bibliotheken von Drittanbietern arbeiten, vermeiden Sie mehrere I/O-Aufrufe.
Hier ist ein Beispiel mit Altair für die Visualisierung und scikit-learn für das maschinelle Lernen.
Sie können das Überleben auch nach Geschlecht analysieren.
Sie können jetzt scikit-learn verwenden, um ein einfaches Modell zu trainieren.
Bemerkung
Für eine bessere Leistung empfehlen wir die Konvertierung in pandas DataFrames über to_pandas(), insbesondere bei der Verwendung von Bibliotheken für maschinelles Lernen wie scikit-learn. Die Funktion to_pandas() sammelt jedoch alle Zeilen, so dass es möglicherweise besser ist, die Größe des Datenrahmens zunächst mit sample(frac=0.1) oder head(10) zu reduzieren.
Nicht unterstützte Bibliotheken¶
Wenn Sie nicht unterstützte Bibliotheken von Drittanbietern mit einem pandas on Snowflake DataFrame verwenden, empfehlen wir, das pandas on Snowflake DataFrame in einen pandas DataFrame zu konvertieren, indem Sie to_pandas() aufrufen, bevor Sie den DataFrame an die Methode der Drittanbieter-Bibliothek übergeben.
Bemerkung
Der Aufruf von to_pandas() zieht Ihre Daten aus Snowflake heraus und in den Speicher, daher sollten Sie dies für große Datensätze und sensible Anwendungsfälle in Betracht ziehen.
Verwendung von Snowflake Cortex LLM-Funktionen mit Snowpark Pandas¶
Sie können Snowflake Cortex LLM Funktionen über die Snowpark pandas apply-Funktion verwenden.
Sie wenden die Funktion mit speziellen Schlüsselwortargumenten an. Derzeit werden die folgenden Cortex-Funktionen unterstützt:
Das folgende Beispiel verwendet die Funktion TRANSLATE über mehrere Datensätze in einem Snowpark pandas DataFrame:
Ausgabe:
Im folgenden Beispiel wird die SENTIMENT (SNOWFLAKE.CORTEX)-Funktion für die Snowflake-Tabelle reviews verwendet:
Das folgende Beispiel verwendet EXTRACT_ANSWER (SNOWFLAKE.CORTEX), um eine Frage zu beantworten:
Ausgabe:
Bemerkung
Das Paket snowflake-ml-python muss installiert sein, um die Funktionen von Cortex LLM nutzen zu können.
Einschränkungen¶
pandas on Snowflake weist folgende Beschränkungen auf:
pandas on Snowflake bietet keine Garantie für die Kompatibilität mit OSS-Bibliotheken von Drittanbietern. Ab Version 1.14.0a1 führt Snowpark pandas jedoch eine begrenzte Kompatibilität für NumPy ein, insbesondere für die Verwendung von
np.where. Weitere Informationen dazu finden Sie unter NumPy-Interoperabilität.Wenn Sie die Bibliotheks-APIs eines Drittanbieters mit einem Snowpark pandas DataFrame aufrufen, empfiehlt Snowflake, dass Sie Snowpark pandas DataFrame in ein pandas DataFrame umwandeln, indem Sie
to_pandas()aufrufen, bevor Sie DataFrame an den Aufruf der Bibliothek des Drittanbieters übergeben. Weitere Informationen dazu finden Sie unter Verwendung von pandas on Snowflake mit Bibliotheken von Drittanbietern.pandas on Snowflake ist nicht in Snowpark ML integriert. Wenn Sie Snowpark ML verwenden, empfehlen wir Ihnen, den Snowpark pandas DataFrame mit to_snowpark() in einen Snowpark DataFrame zu konvertieren, bevor Sie Snowpark ML aufrufen.
Lazy-
MultiIndex-Objekte werden nicht unterstützt. WennMultiIndexverwendet wird, wird ein natives PandasMultiIndex-Objekt zurückgegeben, bei dem alle Daten von der Clientseite abgerufen werden müssen.Nicht alle pandas-APIs haben eine verteilte Implementierung in pandas on Snowflake, obwohl einige hinzugefügt werden. Bei nicht unterstützten APIs wird
NotImplementedErrorausgelöst. Weitere Informationen zur Unterstützung von APIs finden Sie in der API-Referenzdokumentation.pandas on Snowflake bietet Kompatibilität mit jeder Patch-Version von pandas 2.2.
Snowpark pandas kann nicht innerhalb der
apply-Funktion von Snowpark pandas referenziert werden. Sie können native Pandas nur innerhalb vonapplyverwenden.Nachfolgenden sehen Sie ein Beispiel:
Problembehandlung¶
Dieser Abschnitt enthält Tipps zur Fehlerbehebung bei der Verwendung von pandas on Snowflake.
Versuchen Sie bei der Fehlersuche, dieselbe Operation mit einem nativen Pandas DataFrame (oder einem Beispiel) auszuführen, um zu sehen, ob derselbe Fehler weiterhin auftritt. Dieser Ansatz könnte Hinweise darauf liefern, wie Sie Ihre Abfrage korrigieren können. Beispiel:
Wenn Sie ein langlaufendes Notebook geöffnet haben, beachten Sie, dass Snowflake-Sitzungen standardmäßig ein Timeout haben, wenn die Sitzung 240 Minuten (4 Stunden) inaktiv war. Wenn die Sitzung abläuft, erhalten Sie folgende Meldung, wenn Sie weitere Abfragen von pandas on Snowflake ausführen: „Das Token für die Authentifizierung ist abgelaufen. Der Benutzer muss sich erneut authentifizieren.“ An diesem Punkt müssen Sie die Verbindung zu Snowflake erneut herstellen. Dies kann dazu führen, dass alle nicht persistenten Sitzungsvariablen verloren gehen. Weitere Informationen zur Konfiguration des Parameters für die Leerlauf-Timeout der Sitzung finden Sie unter Sitzungsrichtlinien.
Best Practices¶
In diesem Abschnitt werden Best Practices beschrieben, die Sie bei der Verwendung von pandas on Snowflake beachten sollten.
Vermeiden Sie die Verwendung von iterativen Codemustern wie
for-Schleifen,iterrowsunditeritems. Iterative Codemuster erhöhen schnell die generierte Abfragekomplexität. Überlassen Sie pandas on Snowflake die Datenverteilung und die Parallelisierung der Berechnungen, nicht dem Clientcode. Versuchen Sie bei iterativen Mustern nach Operationen zu suchen, die auf dem gesamten DataFrame durchgeführt werden können, und verwenden Sie stattdessen die entsprechenden Operationen.
Vermeiden Sie den Aufruf von
apply,applymapodertransform, die schließlich mit UDFs oder UDTFs implementiert werden und möglicherweise nicht so leistungsfähig wie reguläre SQL-Abfragen sind. Wenn die angewandte Funktion über eine gleichwertige DataFrame- oder Series-Operation verfügt, verwenden Sie stattdessen diese Operation. Verwenden Sie also anstelle vondf.groupby('col1').apply('sum')den direkten Aufrufdf.groupby('col1').sum().Rufen Sie
to_pandas()auf, bevor Sie die DataFrame oder Serie an einen Bibliotheksaufruf eines Drittanbieters übergeben. pandas on Snowflake bietet keine Kompatibilitätsgarantie mit Bibliotheken von Drittanbietern.Verwenden Sie eine materialisierte reguläre Snowflake-Tabelle, um zusätzlichen I/O-Overhead zu vermeiden. pandas on Snowflake arbeitet auf einem Daten-Snapshot, der nur für reguläre Tabellen funktioniert. Für andere Typen, einschließlich externer Tabellen, Ansichten und Apache Iceberg™-Tabellen, wird vor dem Erstellen des Snapshots eine temporäre Tabelle erstellt, was zusätzlichen Materialisierungs-Overhead verursacht.
pandas on Snowflake bietet eine schnelle und kopierfreie Klon-Funktion beim Erstellen von DataFrames aus Snowflake-Tabellen und nutzt dazu
read_snowflake.Überprüfen Sie den Ergebnistyp, bevor Sie mit anderen Operationen fortfahren, und führen Sie bei Bedarf eine explizite Typumwandlung mit
astypeaus.Aufgrund der begrenzten Fähigkeit zur Typinferenz gibt
df.applybei fehlendem Typhinweis Ergebnisse vom Typ Objekt (Variant) zurück, auch wenn das Ergebnis nur Integer-Werte enthält. Wenn andere Operationen erfordern, dassdtypeintist, können Sie eine explizite Typumwandlung ausführen, indem Sie die Methodeastypeaufrufen, um den Spaltentyp zu korrigieren, bevor Sie fortfahren.Vermeiden Sie es, APIs aufzurufen, die Evaluation und Materialisierung erfordern, wenn dies nicht notwendig ist.
APIs, die nicht
SeriesoderDataframezurückgeben, erfordern eine Eager-Evaluation und -Materialisierung, um das Ergebnis mit dem korrekten Typ zu erzeugen. Dasselbe gilt für Plot-Methoden. Reduzieren Sie die Anrufe dieser APIs, um unnötige Evaluationen und Materialisierungen zu vermeiden.Vermeiden Sie den Aufruf von
np.where(<cond>, <scalar>, n)bei großen Datensets.<scalar>wird an einen DataFrame in der Größe von<cond>gesendet, was langsam sein kann.Bei der Arbeit mit iterativ aufgebauten Abfragen kann
df.cache_resultverwendet werden, um Zwischenergebnisse zu materialisieren, um die wiederholte Auswertung zu reduzieren, die Latenzzeit zu verbessern und die Komplexität der gesamten Abfrage zu verringern. Beispiel:Im obigen Beispiel ist die Abfrage zum Erstellen von
df2teuer im Computing und wird sowohl beim Erstellen vondf3als auch vondf4wiederverwendet. Die Materialisierung vondf2in eine temporäre Tabelle (sodass nachfolgende Operationen mitdf2ein Tabellenscan anstelle eines Pivots sind) kann die Gesamtlatenz des Codeblocks verringern:
Beispiele¶
Hier ist ein Codebeispiel mit pandas-Operationen. Wir beginnen mit einem Snowpark pandas DataFrame namens pandas_test, der drei Spalten enthält: COL_STR, COL_FLOAT und COL_INT. Das zu diesen Beispielen gehörende Notebook finden Sie unter pandas on Snowflake-Beispiele im Snowflake-Labs-Repository.
Wir speichern den DataFrame als Snowflake-Tabelle mit dem Namen pandas_test, die wir in unseren Beispielen verwenden werden.
Als Nächstes erstellen wir eine DataFrame aus der Snowflake-Tabelle. Wir löschen die Spalte COL_INT und speichern das Ergebnis in Snowflake in einer Spalte namens row_position.
Das Ergebnis ist eine neue Tabelle: pandas_test2, die wie folgt aussieht:
IO (Lesen und Schreiben)¶
Weitere Informationen dazu finden Sie unter Eingabe/Ausgabe.
Indizierung¶
Fehlende Werte¶
Typkonvertierung¶
Binäre Operationen¶
Aggregation¶
Merge¶
Groupby¶
Weitere Informationen dazu finden Sie unter GroupBy.