Unload into Amazon S3¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths when unloading data from Snowflake tables. This topic describes how to use the COPY command to unload data from a table into an Amazon S3 bucket. You can then download the unloaded data files to your local file system.
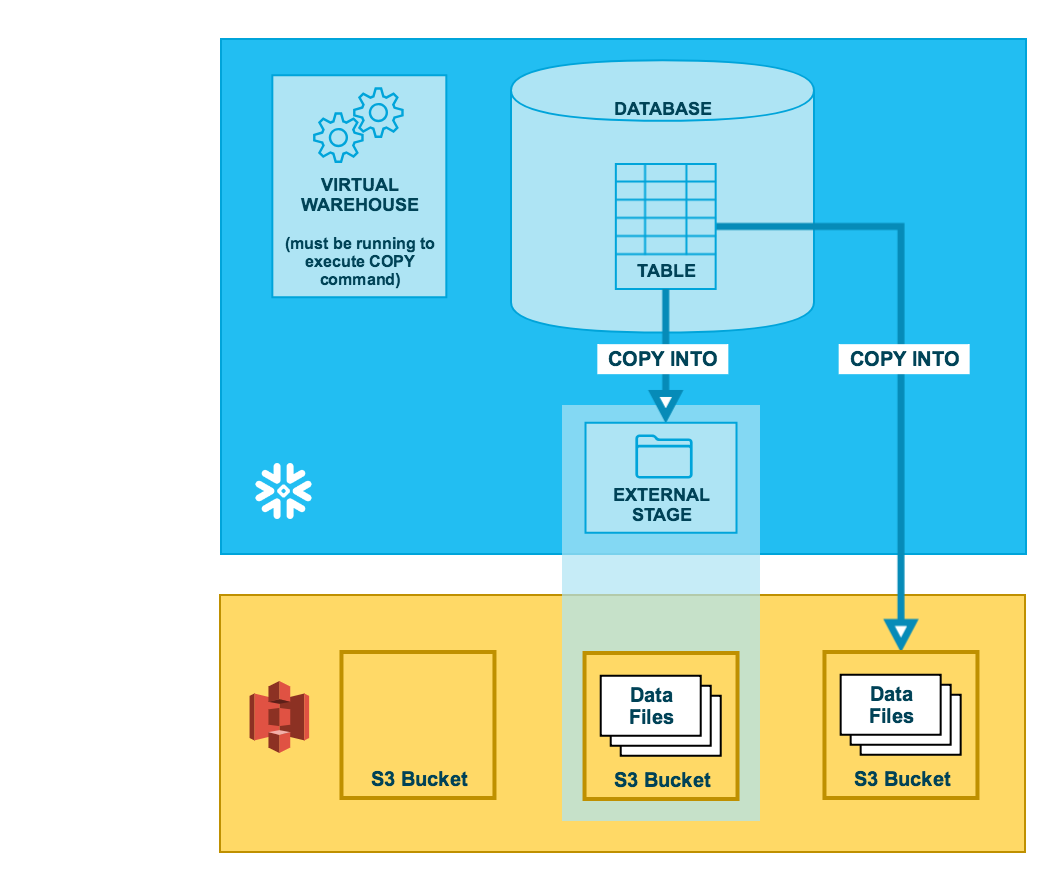
Comme l’illustre le schéma ci-dessous, le déchargement de données dans un compartiment S3 se fait en deux étapes :
- Étape 1:
Utilisez la commande COPY INTO <emplacement> pour copier les données de la table de base de données Snowflake dans un ou plusieurs fichiers d’un compartiment S3. Dans la commande, vous spécifiez un objet de zone de préparation externe nommée qui fait référence au compartiment S3 (recommandé), ou vous pouvez choisir de décharger directement vers le compartiment en spécifiant l’URI et soit les identifiants de sécurité soit le nom d’une intégration de stockage (si nécessaire) du compartiment.
Quelle que soit la méthode que vous utilisez, cette étape nécessite l’exécution d’un entrepôt virtuel en cours d’exécution pour la session si vous exécutez la commande manuellement ou dans un script. L’entrepôt fournit les ressources de calcul pour écrire des lignes à partir de la table.
- Étape 2:
Utilisez les interfaces/outils fournis par Amazon pour télécharger les fichiers du compartiment S3.
Astuce
Les instructions de cet ensemble de chapitres supposent que vous avez lu File formats to unload data et que vous avez créé un format de fichier nommé, le cas échéant.
Avant de commencer, vous pouvez également lire Considérations relatives au déchargement de données pour connaître les bonnes pratiques, les conseils et autres instructions.
Allow the Amazon Virtual Private Cloud IDs¶
Si un administrateur AWS de votre organisation n’a pas explicitement accordé à Snowflake l’accès à votre compte de stockage AWS S3, vous pouvez le faire maintenant. Suivez les étapes décrites dans Autorisation des IDs du Cloud privé virtuel dans les instructions de configuration du chargement des données.
Configure an S3 bucket for unloading data¶
Snowflake requiert les permissions suivantes sur un compartiment S3 et un fichier pour créer de nouveaux fichiers dans le dossier (et tout sous-dossier) :
s3:DeleteObjects3:PutObject
Snowflake recommande de configurer un objet d’intégration de stockage afin de déléguer la responsabilité de l’authentification pour le stockage dans un Cloud externe à une entité de gestion des identités et des accès Snowflake (IAM).
Pour des instructions de configuration, voir Configuration de l’accès sécurisé à Amazon S3.
(Optional) Configure support for Amazon S3 access control lists¶
Les intégrations de stockage de Snowflake prennent en charge les listes de contrôle d’accès AWS (ACLs) pour accorder au propriétaire du compartiment un contrôle total. Les fichiers créés dans les compartiments Amazon S3 à partir de données de table déchargées sont la propriété d’un rôle de gestion des identités et des accès AWS (IAM). Les ACLs prennent en charge le cas d’utilisation où les rôles IAM d’un compte AWS sont configurés pour accéder à des compartiments S3 d’un ou plusieurs autres comptes AWS. Sans la prise en charge ACL, les utilisateurs des comptes propriétaires de compartiments ne pourraient pas accéder aux fichiers de données déchargés vers une zone de préparation externe (S3) en utilisant une intégration de stockage. Lorsque les utilisateurs déchargent les données de la table Snowflake dans des fichiers de données d’une zone de préparation externe (S3) en utilisant COPY INTO <emplacement>, l’opération de déchargement applique une ACL aux fichiers de données déchargés. Les fichiers de données appliquent le privilège "s3:x-amz-acl":"bucket-owner-full-control" aux fichiers, accordant au propriétaire du compartiment S3 un contrôle total sur ces derniers.
Activez la prise en charge des ACL dans l’intégration du stockage pour une zone de préparation S3 via le paramètre optionnel STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control'. Une intégration de stockage est un objet Snowflake qui stocke un utilisateur généré pour la gestion d’identité et d’accès (IAM) pour votre stockage Cloud S3, ainsi qu’un ensemble facultatif d’emplacements de stockage autorisés ou bloqués (c.-à-d. des compartiments S3). Un administrateur AWS de votre organisation ajoute l’utilisateur IAM généré au rôle pour accorder des autorisations Snowflake pour l’accès à des compartiments S3 spécifiés. Cette fonction permet aux utilisateurs d’éviter de fournir des identifiants de connexion lors de la création de zones de préparation ou du chargement de données. Un administrateur peut définir le paramètre STORAGE_AWS_OBJECT_ACL lors de la création d’une intégration de stockage (en utilisant CREATE STORAGE INTEGRATION) ou plus tard (en utilisant ALTER STORAGE INTEGRATION).
Unload data into an external stage¶
Les zones de préparation externes sont des objets de base de données nommés fournissant une grande flexibilité pour le déchargement de données. Étant donné qu’il s’agit d’objets de base de données, des privilèges peuvent être attribués à tout rôle pour les zones de préparation nommées.
Vous pouvez créer une zone de préparation nommée externe en utilisant Snowsight ou SQL :
- Snowsight:
Dans le menu de navigation, sélectionnez Catalog » Database Explorer » <db_name> » Stages » Create
- SQL:
Create a named stage¶
Snowflake utilise des chargements en plusieurs parties lors du chargement vers Amazon S3 et Google Cloud Storage. Ce processus peut entraîner des chargements incomplets dans l’emplacement de stockage de votre zone de préparation externe.
Pour empêcher une accumulation de chargements incomplets, nous vous recommandons de définir une règle de cycle de vie. Pour obtenir des instructions, consultez la documentation Amazon S3 ou Google Cloud Storage.
L’exemple suivant crée une zone de préparation externe nommée my_ext_unload_stage à l’aide d’un compartiment S3 nommé unload avec un chemin de dossier nommé files. La zone de préparation accède au compartiment S3 à l’aide d’une intégration de stockage existante nommée s3_int.
La zone de préparation fait référence à un objet de format de fichier nommé appelé my_csv_unload_format. Pour obtenir des instructions, consultez File formats to unload data.
Unload data to the named stage¶
Utilisez la commande COPY INTO <emplacement> pour décharger les données d’une table vers un compartiment S3 en utilisant la zone de préparation externe.
L’exemple suivant utilise la zone de préparation
my_ext_unload_stagepour décharger toutes les lignes de la tablemytabledans un ou plusieurs fichiers vers le compartiment S3. Un préfixe de nom de fichierd1s’applique aux fichiers :Utilisez la console S3 (ou une application client équivalente) pour récupérer les objets du compartiment (c’est-à-dire les fichiers générés par la commande).
Unload data directly into an S3 bucket¶
Utilisez la commande COPY INTO <emplacement> pour décharger les données d’une table directement vers un compartiment S3 spécifié. Cette option fonctionne bien pour le déchargement ad hoc, lorsque vous ne planifiez pas un déchargement de données régulier avec les mêmes paramètres de table et de compartiment.
Vous devez spécifier l’URI pour le compartiment S3 et les identifiants d’intégration de stockage ou pour accéder au compartiment dans la commande COPY.
L’exemple suivant décharge toutes les lignes de la table
mytabledans un ou plusieurs fichiers avec le préfixe de chemin de dossierunload/vers le compartiment S3mybucket:Note
Dans cet exemple, l’accès au compartiment S3 référencé est effectué à l’aide d’une intégration de stockage référencée nommée
s3_int.Utilisez la console S3 (ou une application client équivalente) pour récupérer les objets du compartiment (c’est-à-dire les fichiers générés par la commande).