Unload into Amazon S3¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths when unloading data from Snowflake tables. This topic describes how to use the COPY command to unload data from a table into an Amazon S3 bucket. You can then download the unloaded data files to your local file system.
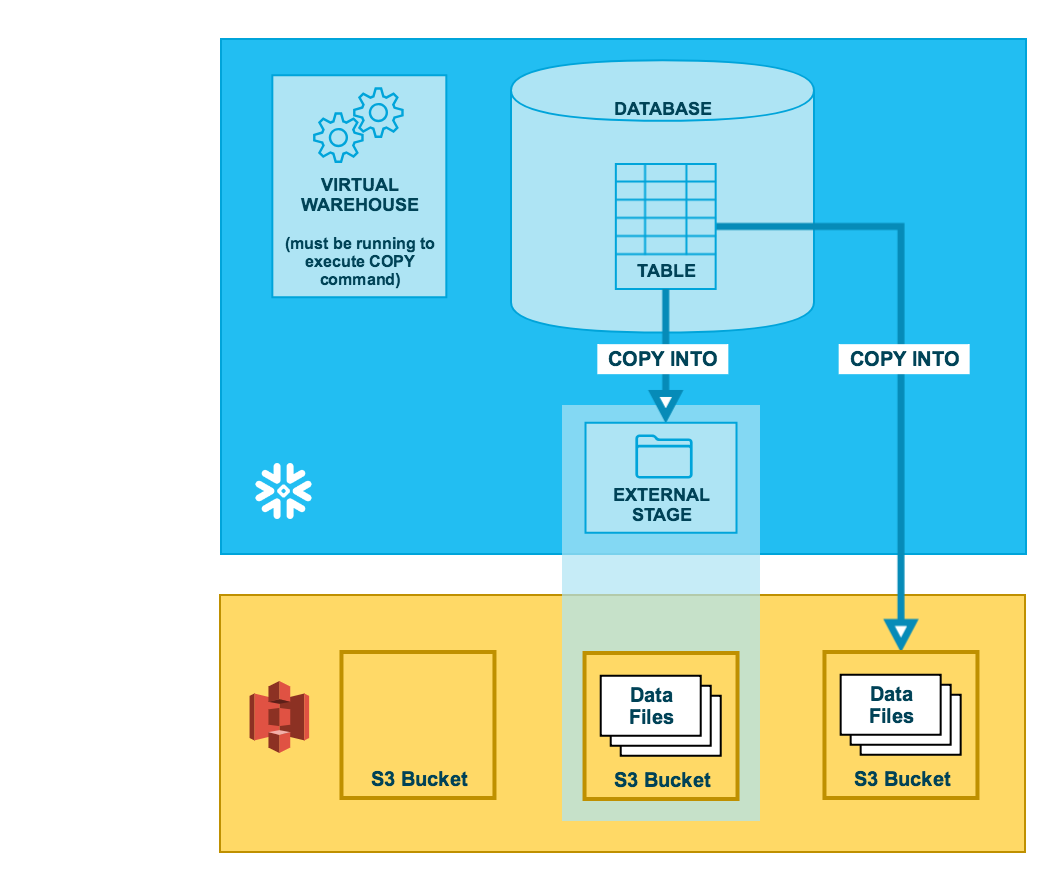
Como ilustrado no diagrama abaixo, a descarregamento de dados para um bucket S3 é realizado em duas etapas:
- Etapa 1:
Use o comando COPY INTO <local> para copiar os dados da tabela do banco de dados Snowflake em um ou mais arquivos em um bucket S3. No comando, você especifica um objeto de estágio externo nomeado que faz referência ao bucket S3 (recomendado) ou você pode optar por descarregar diretamente para o bucket especificando o URI e ou a integração de armazenamento ou as credenciais de segurança (se necessário) para o bucket.
Independentemente do método utilizado, esta etapa requer um warehouse virtual atual e em funcionamento para a sessão se você executar o comando manualmente ou dentro de um script. O warehouse fornece os recursos computacionais para gravar linhas a partir da tabela.
- Etapa 2:
Use as interfaces/ferramentas fornecidas pela Amazon para baixar os arquivos do bucket S3.
Dica
As instruções neste conjunto de tópicos supõem que você tenha lido File formats to unload data e criado um formato de arquivo nomeado, se desejar.
Antes de começar, você também pode ler Considerações sobre o descarregamento de dados para obter práticas recomendadas, dicas e outras orientações.
Allow the Amazon Virtual Private Cloud IDs¶
Se um administrador AWS em sua organização não tiver concedido explicitamente o acesso do Snowflake à sua conta de armazenamento AWS S3, você pode fazê-lo agora. Siga os passos indicados em Permissão para IDs de nuvem privada virtual nas instruções de configuração de carregamento de dados.
Configure an S3 bucket for unloading data¶
O Snowflake requer as seguintes permissões em um bucket e pasta S3 para criar novos arquivos na pasta (e em quaisquer subpastas):
s3:DeleteObjects3:PutObject
Como melhor prática, o Snowflake recomenda configurar um objeto de integração de armazenamento para delegar a responsabilidade de autenticação do armazenamento em nuvem externo a uma entidade de gerenciamento de identidade e acesso (IAM) do Snowflake.
Para instruções de configuração, consulte Configuração de acesso seguro ao Amazon S3.
(Optional) Configure support for Amazon S3 access control lists¶
Integrações de armazenamento do Snowflake suportam listas de controle de acesso (ACLs) do AWS para conceder ao proprietário do bucket o controle total. Os arquivos criados nos buckets S3 da Amazon a partir de dados de tabela descarregados são de propriedade de uma função de Gerenciamento de Identidade e Acesso (IAM) do AWS. ACLs oferecem suporte ao caso de uso em que funções IAM em uma conta AWS são configuradas para acessar buckets S3 em uma ou mais outras contas AWS. Sem suporte para ACL, os usuários nas contas do proprietário do bucket não poderiam acessar os arquivos de dados descarregados para um estágio externo (S3) utilizando uma integração de armazenamento. Quando os usuários descarregam os dados da tabela Snowflake para arquivos de dados em um estágio externo (S3) usando COPY INTO <local>, a operação de descarregamento aplica uma ACL aos arquivos de dados descarregados. Os arquivos de dados aplicam o privilégio "s3:x-amz-acl":"bucket-owner-full-control" aos arquivos, concedendo ao proprietário do bucket S3 total controle sobre eles.
Habilite o suporte para ACL na integração de armazenamento para um estágio S3 através do parâmetro opcional STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control'. Uma integração de armazenamento é um objeto Snowflake que armazena um usuário do gerenciamento de identidade e acesso (IAM) gerado para seu armazenamento em nuvem S3, juntamente com um conjunto opcional de locais de armazenamento permitidos ou bloqueados (ou seja, buckets S3). Um administrador AWS em sua organização adiciona o usuário IAM gerado à função para conceder permissões de acesso do Snowflake aos buckets S3 especificados. Este recurso permite que os usuários evitem fornecer credenciais ao criar estágios ou carregar dados. Um administrador pode definir o parâmetro STORAGE_AWS_OBJECT_ACL ao criar uma integração de armazenamento (usando CREATE STORAGE INTEGRATION) ou mais tarde (usando ALTER STORAGE INTEGRATION).
Unload data into an external stage¶
Os estágios externos são objetos de banco de dados nomeados que proporcionam o maior grau de flexibilidade para o descarregamento de dados. Como eles são objetos de banco de dados, os privilégios para estágios nomeados podem ser concedidos a qualquer função.
Você pode criar uma área de preparação externa nomeada usando o Snowsight ou SQL:
- Snowsight:
No menu de navegação, selecione Catalog » Database Explorer » <nome_bd> » Stages » Create.
- SQL:
Create a named stage¶
O Snowflake utiliza uploads de múltiplas partes ao carregar no Amazon S3 e no Google Cloud Storage. Esse processo pode deixar uploads incompletos no local de armazenamento da sua área de preparação externa.
Para evitar o acúmulo de uploads incompletos, recomendamos que você defina uma regra de ciclo de vida. Para obter instruções, consulte a documentação do Amazon S3 ou do Google Cloud Storage.
O exemplo seguinte cria um estágio externo chamado my_ext_unload_stage usando um bucket S3 chamado unload com um caminho de pasta chamado files. O estágio acessa o bucket S3 utilizando uma integração de armazenamento existente chamada s3_int.
A área faz referência a um objeto de formato de arquivo nomeado chamado my_csv_unload_format. Para obter instruções, consulte File formats to unload data.
Unload data to the named stage¶
Use o comando COPY INTO <local> para descarregar dados de uma tabela para um bucket S3 usando o estágio externo.
O exemplo seguinte usa o estágio
my_ext_unload_stagepara descarregar todas as linhas da tabelamytableem um ou mais arquivos para o bucket S3. Um prefixo de nome de arquivod1é aplicado aos arquivos:Use o console S3 (ou aplicativo cliente equivalente) para recuperar os objetos (ou seja, arquivos gerados pelo comando) do bucket.
Unload data directly into an S3 bucket¶
Use o comando COPY INTO <local> para descarregar dados de uma tabela diretamente em um bucket S3 especificado. Esta opção funciona bem para descarregamento ad hoc, quando você não está planejando descarregar dados regularmente com a mesma tabela e parâmetros de bucket.
Você deve especificar o URI para o bucket S3 e a integração de armazenamento ou credenciais para acessar o bucket no comando COPY.
O exemplo seguinte descarrega todas as linhas da tabela
mytableem um ou mais arquivos com o prefixo do caminho de pastaunload/no S3 bucketmybucket:Nota
Neste exemplo, o bucket S3 referenciado é acessado usando uma integração de armazenamento referenciada chamada
s3_int.Use o console S3 (ou aplicativo cliente equivalente) para recuperar os objetos (ou seja, arquivos gerados pelo comando) do bucket.