Cas d’utilisation en entreprise pour DCM Projects¶
Cette rubrique explique comment utiliser DCM Projects dans des environnements d’entreprise, par exemple pour la gestion de plusieurs projets, le travail avec plusieurs environnements et la collaboration sur des projets.
Quand utiliser plusieurs projets DCM¶
Lorsque vous décidez s’il convient de diviser un DCM project en plusieurs projets et comment procéder, tenez compte de la propriété et de l’utilisation de modèles.
Propriété¶
Chaque projet dispose d’un rôle de propriétaire qui peut déployer tous les objets définis. Les autorisations permettent une gestion granulaire des accès pour chaque objet au sein du projet. Toutefois, si différents groupes d’utilisateurs sont responsables du déploiement de modifications dans un projet, il est généralement utile de diviser un DCM project en conséquence.
Voici un exemple de scénario :
L’administrateur de plateforme déploie une base de données et un entrepôt, crée le rôle d’administrateur d’équipe et accorde les privilèges CREATE à l’administrateur de l’équipe pour un ensemble défini de types d’objets dans cette base de données, ainsi que l’accès à un ensemble défini d’intégrations au niveau du compte.
L’administrateur de l’équipe peut désormais décider comment organiser les schémas et les tables dynamiques dans cette base de données, affiner les fréquences d’actualisation et accorder un accès en lecture plus granulaire aux différents membres de l’équipe.
Voici une solution :
L’administrateur de plateforme déploie l’infrastructure de haut niveau pour l’équipe et accorde à l’administrateur de l’équipe le privilège de créer des projets DCM project au sein de leur base de données.
L’administrateur de l’équipe peut désormais lui aussi tirer parti de DCM Projects en créant un ou plusieurs projets au sein de la base de données de l’équipe afin de gérer les tables et les autorisations accordées aux membres de l’équipe.
Variables de modèles¶
Si un DCM project définit une plage d’objets qui sont et doivent rester dans la plupart des cas similaires, il est généralement plus pratique de les définir une fois en tant que modèle paramétré.
Voici un exemple de scénario :
L’équipe chargée des plateformes déploie une base de données pour chaque équipe régionale de l’organisation.
De nouvelles régions devraient être ajoutées au fil du temps.
Toutes les régions nécessitent globalement la même configuration en termes de schéma, de tables de destination, de rôles et d’entrepôt.
Les modifications de ce modèle de base de données doivent être appliquées à toutes les équipes, par exemple l’ajout d’un rôle en lecture seule.
Voici une solution :
Vous pouvez exécuter un seul ensemble de définitions dans une boucle pour chaque équipe régionale répertoriée dans le profil du manifeste.
Lorsque de plus en plus d’éléments de ce modèle commencent à diverger et que le nombre de conditions de modélisation augmente, il peut s’avérer plus facile de lire et de gérer des projets DCM distincts, chacun avec ses propres définitions d’objets.
Utiliser DCM Projects avec plusieurs environnements¶
Le schéma suivant montre un workflow typique pour le déploiement d’un DCM project vers plusieurs environnements.
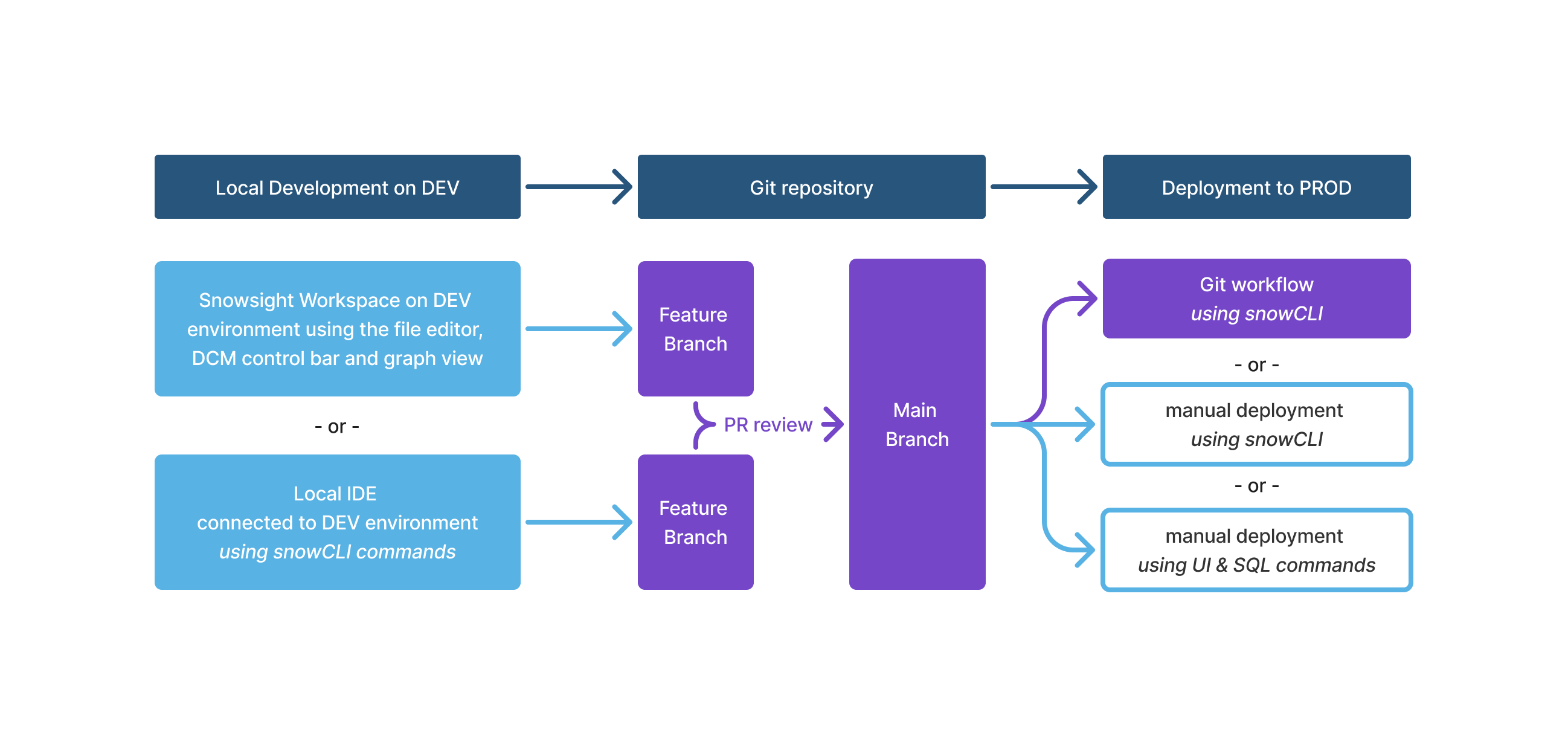
Comptes distincts vs bases de données distinctes¶
Snowflake recommande généralement de configurer chaque environnement comme un compte Snowflake distinct. Cela permet d’assurer une séparation totale entre l’infrastructure de production et tout développement expérimental, et garantit que l’accès des développeurs aux données de production est restreint.
Cependant, avec une gestion des accès prudente, vous pouvez gérer avec succès plusieurs environnements sur un seul compte Snowflake. Cela est plus facile lorsque les bases de données sont clairement séparées, mais peut s’avérer plus complexe lorsque des objets et des intégrations au niveau du compte entrent en jeu.
L’avantage d’une configuration à compte unique est la possibilité de cloner facilement l’infrastructure de production et les données pour tester les modifications avant de déployer ces modifications en production. Cependant, la copie de certaines données de production et d’éléments d’infrastructure vers un autre compte, par exemple via des partages de données au sein de l’organisation, peut s’avérer plus coûteuse.
Conséquences sur la modélisation DCM project¶
Des noms d’objets distincts pour chaque environnement sont nécessaires pour les configurations à compte unique, par exemple pour conserver EMEA_DB et EMEA_ADMIN distincts de EMEA_DB_DEV et EMEA_ADMIN_DEV. Snowflake recommande également cette pratique pour les configurations à plusieurs comptes. Les noms basés sur des modèles permettent à plusieurs instances d’entités telles que EMEA_DB_DEV_JOHN et EMEA_DB_DEV_MARY de coexister, ce qui facilite le développement indépendant et permet de créer et de supprimer rapidement des environnements sandbox pour évaluer différentes solutions.
Cela s’applique à tous les objets au niveau du compte, tels que les bases de données, les rôles et les entrepôts. Vous devez ensuite appliquer ces noms basés sur des modèles à tous les noms complets des objets imbriqués.