Détection des anomalies (fonctions Snowflake ML)¶
Vue d’ensemble¶
La détection des anomalies est le processus d’identification des valeurs aberrantes dans les données. La fonction de détection des anomalies vous permet d’entraîner un modèle pour détecter les valeurs aberrantes dans vos données de séries temporelles. Les valeurs aberrantes, c’est-à-dire les points de données qui s’écartent de la fourchette prévue, peuvent avoir un impact considérable sur les statistiques et les modèles dérivés de vos données. Repérer et supprimer les valeurs aberrantes peut donc contribuer à améliorer la qualité de vos résultats.
Note
La détection des anomalies fait partie de la suite d’outils d’analyse commerciale de Snowflake alimentés par le machine learning.
La détection des valeurs aberrantes peut également s’avérer utile pour déterminer l’origine des problèmes ou des écarts dans les processus lorsqu’il n’y a pas de cause évidente. Par exemple :
Détermination du moment où un problème a commencé à se produire avec votre canal de journalisation.
Identification des jours où vos coûts de calcul Snowflake sont plus élevés que prévu.
La détection des anomalies fonctionne avec des données à série unique ou à séries multiples. Les données à séries multiples représentent plusieurs fils d’événements indépendants. Par exemple, si vous disposez de données de vente pour plusieurs magasins, les ventes de chaque magasin peuvent être vérifiées séparément par un seul modèle basé sur l’identificateur du magasin.
Les données doivent comprendre :
Une colonne d’horodatage.
Une colonne cible représentant une certaine quantité d’intérêt à chaque horodatage.
Note
Idéalement, les données d’entraînement pour un modèle de détection d’anomalies comportent des intervalles de temps espacés de manière régulière (par exemple, quotidiennement). Cependant, l’entraînement du modèle peut gérer des données du monde réel qui comportent des intervalles de temps manquants, dupliqués ou mal alignés. Pour plus d’informations, voir Gestion des données du monde réel dans la prévision des séries temporelles.
Pour détecter les valeurs aberrantes dans les données de séries temporelles, utilisez la classe intégrée de Snowflake ANOMALY_DETECTION (SNOWFLAKE.ML), et suivez ces étapes :
Créez un objet de détection d’anomalie, en lui transmettant une référence aux données d’entraînement.
Cet objet ajuste un modèle aux données d’entraînement que vous lui fournissez. Le modèle est un objet de niveau schéma.
À l’aide de cet objet de modélisation de détection des anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES pour détecter les anomalies, en lui transmettant une référence aux données à analyser.
La méthode utilise le modèle pour identifier les valeurs aberrantes dans les données.
La détection des anomalies est étroitement liée aux Prévisions. Un modèle de détection d’anomalies établit une prévision pour la même période que les données pour lesquelles vous recherchez les anomalies, puis compare les données réelles à la prévision afin d’identifier les valeurs aberrantes.
Important
Avis juridique. Cette fonction ML de Snowflake est alimentée par une technologie de machine learning, dont vous, et non Snowflake, déterminez quand et comment l’utiliser. La technologie de machine learning et les résultats fournis peuvent être inexacts, incorrects ou biaisés. Snowflake vous fournit les modèles de machine learning que vous pouvez utiliser au sein de vos propres workflows. Les décisions basées sur les résultats du machine learning, y compris celles qui sont intégrées dans des pipelines automatiques, devraient être soumises à une supervision humaine et à des processus d’examen pour s’assurer que le contenu généré par le modèle est exact. Snowflake fournit des algorithmes (sans pré-entraînement) et vous êtes responsable des données que vous fournissez à l’algorithme (par exemple, pour l’entraînement et l’inférence) et des décisions que vous prenez en utilisant la sortie du modèle résultant. Les requêtes portant sur cette fonction sont traitées comme toute autre requête SQL et peuvent être considérées comme des métadonnées.
Métadonnées. Lorsque vous utilisez les fonctions ML de Snowflake, Snowflake connecte les messages d’erreur génériques renvoyés par une fonction ML. Ces journaux d’erreurs nous aident à résoudre les problèmes qui surviennent et à améliorer ces fonctions pour mieux répondre à vos demandes.
Pour plus d’informations, voir la FAQ relative à la confiance et à la sécurité concernant l’AI de Snowflake.
À propos de l’algorithme de détection des anomalies¶
L’algorithme de détection des anomalies est alimenté par une machine de renforcement du gradient (GBM). Comme un modèle ARIMA , il utilise une transformation de différenciation pour modéliser les données avec une tendance non stationnaire et utilise des temps de latence auto-régressifs des données cibles historiques comme variables du modèle.
En outre, l’algorithme utilise les moyennes glissantes des données cibles historiques pour aider à prédire les tendances et produit automatiquement des variables de calendrier cyclique (telles que le jour de la semaine et la semaine de l’année) à partir des données d’horodatage.
Vous pouvez ajuster des modèles avec uniquement des données historiques sur la cible et d’horodatage, ou vous pouvez inclure des données exogènes (variables) qui pourraient avoir influencé la valeur cible. Les variables exogènes peuvent être numériques ou catégorielles et peuvent être NULL (les lignes contenant des valeurs NULLs pour les variables exogènes ne sont pas supprimées).
L’algorithme ne repose pas sur l’encodage « one-hot » lors de l’entraînement sur des variables catégorielles, ce qui vous permet d’utiliser des données catégorielles comportant de nombreuses dimensions (cardinalité élevée).
Si votre modèle intègre des variables exogènes, vous devez fournir des valeurs pour ces variables à des horodatages ultérieurs lors de la détection d’anomalies. Les variables exogènes appropriées peuvent inclure des données météorologiques (température, précipitations), des informations spécifiques à l’entreprise (congés historiques et planifiés, campagnes publicitaires, programmes d’événements) ou tout autre facteur externe qui, selon vous, peut aider à prédire votre variable cible.
En option, les lignes historiques individuelles peuvent être balisées comme anormales ou non anormales en utilisant une colonne booléenne séparée.
Un intervalle de prédiction est une plage estimée de valeurs comprises entre une limite supérieure et une limite inférieure dans laquelle un certain pourcentage de données est susceptible de se situer. Par exemple, une valeur de 0,99 signifie que 99 % des données sont susceptibles d’apparaître dans l’intervalle. Le modèle de détection d’anomalies identifie toute donnée qui sort de l’intervalle de prédiction comme une anomalie. Vous pouvez spécifier un intervalle de prédiction ou utiliser la valeur par défaut, qui est de 0,99. Il est possible que cette valeur soit très proche de 1,0 ; 0,9999 ou même plus proche.
Important
De temps à autre, Snowflake peut affiner l’algorithme de détection des anomalies. Ces améliorations sont déployées tout au long du processus de publication régulier de Snowflake. Vous ne pouvez pas revenir à une version antérieure de la fonction, mais les modèles que vous avez créés avec une version antérieure continuent à utiliser cette version pour la détection des anomalies.
Limitations¶
Vous ne pouvez pas choisir ou ajuster l’algorithme de détection des anomalies. L’algorithme ne fournit pas de paramètres permettant de remplacer la tendance, la saisonnalité ou les amplitudes saisonnières ; ces paramètres sont déduits des données.
Le nombre minimum de lignes pour l’algorithme principal de détection des anomalies est de 12 par série temporelle. Pour les séries temporelles comportant entre 2 et 11 observations, la détection des anomalies produit un résultat « naïf » dans lequel toutes les valeurs prédites sont égales à la dernière valeur cible observée. Dans le cas de la détection d’anomalies étiquetées, le nombre d’observations utilisé est le nombre de lignes dont la colonne d’étiquettes est fausse.
La granularité minimale acceptable des données est d’une seconde. (Les horodatages ne doivent pas être espacés de moins d’une seconde.)
La granularité minimale des composantes saisonnières est d’une minute. (La fonction ne peut pas détecter de modèles cycliques à des deltas temporels plus petits.)
La « longueur de la saison » des fonctions autorégressives est liée à la fréquence d’entrée (24 pour des données horaires, 7 pour des données journalières, et ainsi de suite).
Les modèles de détection des anomalies, une fois entraînés, sont immuables. Vous ne pouvez pas mettre à jour les modèles existants avec de nouvelles données ; vous devez entraîner un modèle entièrement nouveau. Les modèles ne prennent pas en charge la gestion des versions. En règle générale, vous devez entraîner les modèles à intervalles réguliers, par exemple une fois par jour, par semaine ou par mois, en fonction de la fréquence à laquelle vous recevez de nouvelles données, afin d’aider le modèle à suivre l’évolution des tendances.
Cette fonctionnalité détecte uniquement les anomalies dans les données de test ; elle ne peut pas détecter les anomalies dans les données d’entraînement. De plus, les horodatages dans les données de test doivent tous être supérieurs aux horodatages dans les données d’entraînement. Assurez-vous que les données d’entraînement couvrent une période typique exempte de valeurs aberrantes réelles, ou étiquetez les valeurs aberrantes connues dans une colonne booléenne.
Vous ne pouvez pas cloner de modèles ni les partager entre rôles ou comptes. Lors du clonage d’un schéma ou d’une base de données, les objets du modèle sont ignorés.
Vous ne pouvez pas répliquer une instance de la classe ANOMALY_DETECTION.
Se préparer à la détection d’anomalies¶
Avant de pouvoir utiliser la détection d’anomalies, vous devez :
Sélectionner un entrepôt virtuel dans lequel vous entraînerez et exécuterez vos modèles.
Attribuer les privilèges nécessaires à la création d’objets de détection d’anomalies.
Vous pourriez également vouloir modifier votre chemin de recherche pour inclure SNOWFLAKE.ML.
Sélection d’un entrepôt virtuel¶
Un entrepôt virtuel Snowflake fournit les ressources calcul pour l’entraînement et l’utilisation de vos modèles de machine learning pour cette fonction. Cette section fournit des conseils généraux sur le choix de la meilleure taille et du meilleur type d’entrepôt à cette fin, en se concentrant sur l’étape d’entraînement (la partie du processus qui prend le plus de temps et qui mobilise le plus de mémoire).
Entraînement sur des données à série unique¶
Pour les modèles formés sur des données à série unique, vous devez choisir le type d’entrepôt en fonction de la taille de vos données d’apprentissage. Les entrepôts standard sont soumis à une limite de mémoire Snowpark inférieure et sont plus appropriés pour les tâches de formation avec moins de lignes ou de caractéristiques exogènes. Si vos données d’apprentissage ne contiennent pas de fonctionnalités exogènes, vous pouvez vous entraîner sur un entrepôt standard si l’ensemble de données comporte 5 millions de lignes ou moins. Si vos données d’entraînement utilisent au moins cinq caractéristiques exogènes, le nombre maximal de lignes est inférieur. Dans le cas contraire, Snowflake suggère d’utiliser un entrepôt optimisé par Snowpark pour les tâches de formation plus importantes.
En général, pour les données à série unique, une taille d’entrepôt plus importante ne se traduit pas par un temps d’apprentissage plus rapide ou des limites de mémoire plus élevées. En règle générale, le temps de formation est proportionnel au nombre de lignes de votre série temporelle. Par exemple, sur un entrepôt standard XS, avec l’évaluation désactivée (CONFIG_OBJECT => {'evaluate': False}), l’entraînement sur un ensemble de données de 100 000 lignes prend environ 60 secondes, tandis que l’entraînement sur un ensemble de données de 1 000 000 de lignes prend environ 125 secondes. Lorsque l’évaluation est activée, le temps d’entraînement augmente de manière à peu près linéaire en fonction du nombre de divisions utilisées.
Pour de meilleures performances, Snowflake recommande d’utiliser un entrepôt dédié sans autres charges de travail simultanées pour entraîner votre modèle.
Entraînement sur des données à séries multiples¶
Comme pour les données à série unique, choisissez le type d’entrepôt en fonction du nombre de lignes de votre série temporelle la plus importante. Si votre plus grande série temporelle contient plus de 5 millions de lignes, la tâche de formation risque de dépasser les limites de mémoire d’un entrepôt standard.
Contrairement aux données à série unique, l’entraînement sur des données à séries multiples est beaucoup plus rapide dans des entrepôts de grande taille. Les points suivants sur les données peuvent vous guider dans votre choix. Encore une fois, tous ces temps sont mesurés avec l’évaluation désactivée.
Type et taille de l’entrepôt |
Nombre de séries temporelles |
Nombre de lignes par série temporelle |
Durée de l’entraînement (secondes) |
|---|---|---|---|
XS standard |
1 |
100,000 |
60 secondes |
XS standard |
10 |
100,000 |
204 secondes |
XS standard |
100 |
100,000 |
720 secondes |
XL standard |
10 |
100,000 |
104 secondes |
XL standard |
100 |
100,000 |
211 secondes |
XL standard |
1000 |
100,000 |
840 secondes |
XL optimisé pour Snowpark |
10 |
100,000 |
65 secondes |
XL optimisé pour Snowpark |
100 |
100,000 |
293 secondes |
XL optimisé pour Snowpark |
1000 |
100,000 |
831 secondes |
Détection des anomalies¶
L’étape d’inférence prend environ une seconde pour traiter 100 lignes de l’ensemble de données d’entrée, quelle que soit la taille de l’entrepôt.
Octroi de privilèges pour la création d’objets de détection d’anomalies¶
L’entraînement d’un modèle de détection d’anomalies aboutit à un objet au niveau du schéma. Par conséquent, le rôle que vous utilisez pour créer des modèles doit avoir le privilège CREATE SNOWFLAKE.ML.ANOMALY_DETECTION sur le schéma où le modèle est créé, ce qui permet au modèle d’y être stocké. Ce privilège est similaire à d’autres privilèges de schéma tels que CREATE TABLE ou CREATE VIEW.
Snowflake vous recommande de créer un rôle nommé analyst qui sera utilisé par les personnes devant détecter des anomalies.
Dans l’exemple suivant, le rôle admin est le propriétaire du schéma admin_db.admin_schema. Le rôle analyst doit créer des modèles dans ce schéma.
Pour utiliser ce schéma, un utilisateur assume le rôle analyst :
Si le rôle analyst dispose des privilèges CREATE SCHEMA dans la base de données analyst_db, il peut créer un nouveau schéma analyst_db.analyst_schema et créer des modèles de détection d’anomalies dans ce schéma :
Pour révoquer le privilège de création de modèle d’un rôle sur le schéma, utilisez REVOKE <privilèges> … FROM ROLE :
Configuration des données pour les exemples¶
Les exemples présentés dans les sections suivantes utilisent un échantillon de données qui contient les ventes quotidiennes d’articles dans différents magasins, ainsi que des données météorologiques quotidiennes (humidité et température). L’ensemble de données contient également une colonne qui indique si le jour est un jour férié.
Exécutez les instructions suivantes pour créer une table nommée
historical_sales_dataqui contient les données d’entraînement du modèle :
Exécutez les instructions suivantes pour créer une table nommée
new_sales_dataqui contient les données à analyser :
Entraînement, utilisation, vue, suppression et mise à jour des modèles¶
Utilisez CREATE SNOWFLAKE.ML.ANOMALY_DETECTION pour créer et entraîner un modèle. Le modèle est entraîné sur l’ensemble de données que vous fournissez.
Voir ANOMALY_DETECTION (SNOWFLAKE.ML) pour plus de détails sur le constructeur SNOWFLAKE.ML.ANOMALY_DETECTION. Pour des exemples de création d’un modèle, consultez Détection des anomalies.
Note
SNOWFLAKE.ML.ANOMALY_DETECTION s’exécute avec des privilèges limités ; par défaut, il n’a donc pas accès à vos données. Vous devez donc transmettre les tables et les vues en tant que références, qui transmettent les privilèges de l’appelant. Vous pouvez également fournir une référence de requête au lieu d’une référence à une table ou à une vue.
Pour créer cette référence, vous pouvez utiliser le mot-clé TABLE avec le nom de la table, de la vue ou de la requête, ou vous pouvez appeler la fonction SYSTEM$REFERENCE ou SYSTEM$QUERY_REFERENCE.
Pour détecter les anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES du modèle :
Pour sélectionner des colonnes dans la sortie tabulaire de la méthode, vous pouvez appeler la méthode dans la clause FROM :
Pour voir la liste de vos modèles, utilisez la commande SHOW SNOWFLAKE.ML.ANOMALY_DETECTION :
Pour supprimer un modèle, utilisez la commande DROP SNOWFLAKE.ML.ANOMALY_DETECTION :
Pour mettre à jour un modèle, supprimez-le et entraînez-en un nouveau. Les modèles sont immuables et ne peuvent pas être mis à jour sur place.
Détection des anomalies¶
Les sections suivantes montrent comment utiliser la détection d’anomalies pour détecter les valeurs aberrantes. Ces sections fournissent des exemples de détection d’anomalies pour une série temporelle unique, pour des séries temporelles multiples, avec et sans variables exogènes, avec un intervalle de prédiction défini par l’utilisateur et avec une approche supervisée (balisée).
Détection d’anomalies pour une série temporelle unique (non supervisée)
Entraînement d’un modèle de détection d’anomalies avec des données balisées
Spécification de l’intervalle de prédiction pour la détection d’anomalies
Détection d’anomalies pour une série temporelle unique (non supervisée)¶
Pour détecter les anomalies dans vos données :
Entraînez un modèle de détection d’anomalies à l’aide de données historiques.
Utilisez le modèle de détection d’anomalies entraîné pour détecter les anomalies dans les données historiques ou projetées. Les horodatages des données de test doivent suivre chronologiquement les horodatages des données d’entraînement. Vous avez besoin d’au moins 2 points de données pour entraîner un modèle, d’au moins 12 pour des résultats non naïfs et d’au moins 60 pour des résultats non linéaires.
Consultez ANOMALY_DETECTION (SNOWFLAKE.ML) pour obtenir des informations sur les paramètres utilisés lors de la création et de l’utilisation d’un modèle.
Entraînement d’un modèle de détection d’anomalies¶
Pour créer un objet modèle de détection d’anomalies, exécutez la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION.
Par exemple, supposons que vous souhaitiez analyser les ventes de vestes dans le magasin dont le store_id est 1 :
Créez une vue ou concevez une requête qui renvoie les données nécessaires à l’entraînement du modèle de détection des anomalies.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_training_dataqui contient les informations relatives à la date et aux ventes :Créez un objet de détection d’anomalies et entraînez son modèle sur les données de cette vue.
Pour cet exemple, exécutez la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION pour créer un objet de détection d’anomalies nommé
basic_model. Transmettez les arguments suivants :Cet exemple transmet une référence à une vue en tant qu’argument INPUT_DATA. L’exemple utilise le mot-clé TABLE pour créer la référence. Vous pouvez également appeler SYSTEM$REFERENCE pour créer la référence.
L’objectif de la colonne « balise » est d’indiquer au modèle quelles lignes correspondent à des anomalies connues. Étant donné que cet exemple utilise un entraînement non supervisé, vous n’avez pas besoin d’utiliser la colonne des balises. Transmettez une chaîne vide comme nom de la colonne balise.
Astuce
Si vous ne souhaitez pas créer de vue pour l’argument INPUT_DATA, vous pouvez transmettre une référence à une requête qui utilise une instruction SELECT qui sert de vue en ligne.
Vous pouvez utiliser le mot-clé TABLE pour créer cette référence de requête. Par exemple :
Les guillemets simples et autres caractères spéciaux sont échappés par une barre oblique inverse.
Au lieu d’utiliser le mot-clé TABLE, vous pouvez appeler SYSTEM$QUERY_REFERENCE pour créer la référence de la requête.
Si la commande est exécutée avec succès, un message indique que votre instance de détection d’anomalies a été créée avec succès :
Utilisation d’un modèle de détection d’anomalies pour détecter les anomalies¶
La création de l’objet de détection des anomalies entraîne le modèle et le stocke dans le schéma. Pour utiliser l’objet de détection d’anomalies afin de détecter des anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES de l’objet. Par exemple :
Créez une vue ou concevez une requête qui renvoie les données à des fins d’analyse.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_data_to_analyzequi contient les informations relatives à la date et aux ventes :En utilisant l’objet du modèle de détection d’anomalies (dans cet exemple,
basic_model, que vous avez créé précédemment), appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES :La méthode renvoie une table qui comprend des lignes pour les données actuellement dans la vue
view_with_data_to_analyzeainsi que la prédiction du détecteur. Pour une description des colonnes de cette table, consultez Renvoie.
Sortie
Les résultats ont été arrondis pour faciliter la lecture.
Pour enregistrer vos résultats directement dans une table, utilisez CREATE TABLE … AS SELECT … et appelez la méthode DETECT_ANOMALIES dans la clause FROM :
Comme le montre l’exemple ci-dessus, lors de l’appel de la méthode, omettez la commande CALL. Au lieu de cela, mettez l’appel entre parenthèses, précédé du mot-clé TABLE.
Entraînement d’un modèle de détection d’anomalies avec des données balisées¶
Dans l’exemple précédent, le résultat du modèle semble inexact. Cela s’explique probablement par le fait que :
Le modèle de détection d’anomalies a été entraîné sur très peu de données d’entrée.
Un plus grand nombre de vestes (30) ont été vendues le 03/01/2020. Cela a eu pour effet de biaiser les prédictions à la hausse et d’augmenter la taille de l’intervalle de prédiction.
Pour améliorer la précision du modèle de détection d’anomalies, vous pouvez soit inclure davantage de données d’entraînement, soit baliser les données d’entraînement (entraînement supervisé). Les données d’entraînement balisées comportent une colonne booléenne supplémentaire qui indique si chaque ligne est une anomalie connue. Le balisage peut aider le modèle de détection d’anomalies à éviter l’adaptation excessive aux anomalies connues dans les données d’entraînement.
Pour inclure des données balisées dans des données d’entraînement, spécifiez la colonne contenant la balise dans l’argument du constructeur LABEL_COLNAME de la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION. Par exemple :
Créez une vue ou concevez une requête qui renvoie les balises avec les données d’entraînement.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_labeled_dataqui contient les balises dans une colonne nomméelabel:Créez un objet pour le modèle de détection d’anomalies et entraînez le modèle sur les données de cette vue.
Pour cet exemple, exécutez la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION pour créer un objet de détection d’anomalies nommé
model_trained_with_labeled_data. L’instruction suivante crée l’objet de détection des anomalies :En utilisant ce nouveau modèle de détection d’anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES en lui transmettant les mêmes arguments que ceux que vous avez utilisés dans Détection d’anomalies pour une série temporelle unique (non supervisée) :
La méthode renvoie une table qui comprend des lignes pour les données actuellement dans la vue
view_with_data_to_analyzeainsi que la prédiction du détecteur. Pour une description des colonnes de cette table, consultez Renvoie.
Sortie
Les résultats ont été arrondis pour faciliter la lecture.
Spécification de l’intervalle de prédiction pour la détection d’anomalies¶
Vous pouvez détecter les anomalies avec différents niveaux de sensibilité. Pour spécifier le pourcentage d’observations à classer comme anomalies, créez un OBJECT qui contient les paramètres de configuration de <nom_du_modèle>!DETECT_ANOMALIES, et attribuez à la clé prediction_interval le pourcentage d’observations à classer comme anomalies.
Pour construire cet objet, vous pouvez utiliser soit une constante d’objet soit la fonction OBJECT_CONSTRUCT.
Ensuite, lorsque vous appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES, transmettez cet objet en tant qu’argument CONFIG_OBJECT.
Par défaut, la valeur associée à la clé prediction_interval est définie sur 0,99, ce qui signifie qu’environ 1 % des données sont marquées comme des anomalies. Vous pouvez spécifier une valeur entre 0 et 1 :
Pour marquer moins d’observations comme des anomalies, spécifiez une valeur plus élevée pour
prediction_interval.Pour marquer plus d’observations comme des anomalies, réduisez la valeur de
prediction_interval.
L’exemple suivant configure la détection des anomalies de manière plus stricte en définissant l”prediction_interval à 0,995. L’exemple utilise également le modèle entraîné sur des données balisées (que vous avez configuré dans Entraînement d’un modèle de détection d’anomalies avec des données balisées) avec la vue contenant les données à analyser (que vous avez configurée dans Détection d’anomalies pour une série temporelle unique (non supervisée)).
Cette instruction produit une table qui comprend des lignes pour les données actuellement dans la vue view_with_data_to_analyze. Chaque ligne comprend une colonne avec la prédiction du détecteur. Vous pouvez constater que le résultat de ce modèle est plus précis que celui de l’exemple non balisé.
Sortie
Les résultats ont été arrondis pour faciliter la lecture.
Ajout de colonnes supplémentaires pour l’analyse¶
Vous pouvez inclure des colonnes supplémentaires dans les données (par exemple temperature, weather, is_black_friday) à des fins d’entraînement et d’analyse, si ces colonnes peuvent vous aider à améliorer l’identification de véritables anomalies.
Pour inclure de nouvelles colonnes pour l’analyse :
Pour les données d’entraînement, créez une vue ou concevez une requête qui inclut les nouvelles colonnes, et créez un nouvel objet de détection d’anomalies, en lui transmettant une référence à cette vue ou à cette requête.
Pour les données à analyser, créez une vue ou concevez une requête qui inclut les nouvelles colonnes et transmettez une référence à cette vue ou requête à la méthode <nom_du_modèle>!DETECT_ANOMALIES.
Le modèle de détection d’anomalies détecte et utilise automatiquement les colonnes supplémentaires.
Note
Vous devez fournir à une vue ou à une requête le même ensemble de colonnes supplémentaires lors de l’exécution de la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION et lors de l’appel de la méthode <nom_du_modèle>!DETECT_ANOMALIES. En cas de non-concordance entre les colonnes des données d’entraînement transmises à la commande et les colonnes des données d’analyse transmises à la fonction, une erreur se produit.
Par exemple, supposons que vous souhaitiez ajouter les colonnes temperature, humidity, et holiday :
Créez une vue ou concevez une requête qui renvoie les données d’entraînement avec ces colonnes supplémentaires.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_training_data_extra_columns:Créez un objet pour le modèle de détection d’anomalies et entraînez le modèle sur les données de cette vue.
Pour cet exemple, exécutez la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION pour créer un objet de détection d’anomalies nommé
model_with_additional_columns, en y ajoutant une référence à la nouvelle vue :Créez une vue ou concevez une requête qui renvoie les données à analyser avec ces colonnes supplémentaires.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_data_for_analysis_extra_columns:À l’aide de ce nouvel objet de détection d’anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES en lui transmettant la nouvelle vue :
Cette instruction produit une table qui comprend des lignes pour les données actuellement dans la vue
view_with_data_for_analysis_extra_columnsainsi que la prédiction du détecteur. Le format de sortie est le même que celui de la sortie affichée pour les commandes que vous avez exécutées précédemment.
Sortie
Les résultats ont été arrondis pour faciliter la lecture.
Détection d’anomalies dans des séries multiples¶
Les sections précédentes ont fourni des exemples de détection d’anomalies pour une série unique. Ces exemples ont mis en évidence des anomalies pour la vente d’un type d’article (vestes) dans un magasin (ID magasin 1). Détecter les anomalies pour plusieurs séries temporelles en même temps (par exemple, pour plusieurs combinaisons d’articles et de magasins) :
Pour les données d’entraînement, créez une vue ou concevez une requête qui inclut une colonne identifiant la série, et créez un nouvel objet de détection d’anomalies, en transmettant une référence à cette vue ou requête et en spécifiant le nom de la colonne de la série pour l’argument SERIES_COLNAME.
Pour les données à analyser, créez une vue ou concevez une requête qui inclut la colonne qui identifie la série. Appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES, en transmettant une référence à cette vue ou requête et en spécifiant le nom de la colonne de la série pour l’argument SERIES_COLNAME.
Supposons par exemple que vous souhaitiez utiliser la combinaison des colonnes store_id et item pour identifier la série :
Créez une vue ou concevez une requête qui renvoie les données d’entraînement avec la colonne correspondant à la série.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_training_data_multiple_seriesqui contient une colonne nomméestore_itemqui identifie la série comme une combinaison d’un ID de magasin et un article :Créez un objet pour la détection d’anomalies et entraînez le modèle sur les données de cette vue.
Pour cet exemple, exécutez la commande CREATE SNOWFLAKE.ML.ANOMALY_DETECTION pour créer un objet de détection d’anomalies nommé
model_for_multiple_series, en transmettant une référence à la nouvelle vue et en spécifiantstore_itempour l’argument SERIES_COLNAME :Créez une vue ou concevez une requête qui renvoie les données à analyser avec la colonne des séries.
Pour cet exemple, exécutez la commande CREATE VIEW pour créer une vue nommée
view_with_data_for_analysis_multiple_seriesqui contient une colonne nomméestore_itempour la série :À l’aide de ce nouvel objet de détection d’anomalies, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES, en lui transmettant la nouvelle vue et en spécifiant
store_itempour l’argument SERIES_COLNAME :Cette instruction produit une table qui comprend des lignes pour les données actuellement dans la vue
view_with_data_for_analysis_multiple_seriesainsi que la prédiction du détecteur. La sortie comprend la colonne qui identifie la série.
Sortie
Les résultats ont été arrondis pour faciliter la lecture.
Visualisation des anomalies et interprétation des résultats¶
Utilisez Snowsight pour examiner et visualiser les résultats de la détection des anomalies. Dans Snowsight, lorsque vous appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES, les résultats sont affichés dans une table sous la feuille de calcul.

Pour visualiser les résultats, vous pouvez utiliser la fonction graphique de Snowsight.
Après avoir appelé la méthode <nom_du_modèle>!DETECT_ANOMALIES, sélectionnez Charts au-dessus de la table des résultats.
Dans la section Data, à droite du graphique :
Sélectionnez la colonne Y et, sous Aggregation, sélectionnez None.
Sélectionnez la colonne TS et, sous Bucketing, sélectionnez None.
Ajoutez les colonnes LOWER_BOUND et UPPER_BOUND, et sous Aggregation, sélectionnez None.
Pour afficher la visualisation initiale, sélectionnez Chart.

Sélectionnez Add Column sur le côté droit de la page, puis sélectionnez les colonnes que vous souhaitez visualiser :
LOWER_BOUND
UPPER_BOUND
IS_ANOMALY
Résultats :
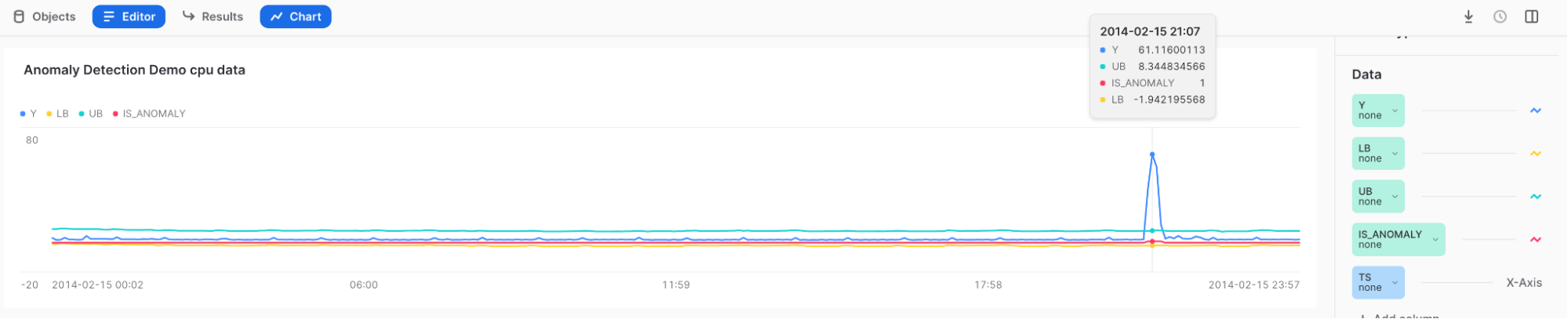
Survolez le pic élevé pour voir que Y se situe en dehors de la limite supérieure et est marqué d’un 1 dans le champ IS_ANOMALY.
Astuce
Pour mieux comprendre vos résultats, consultez Top Insights.
Automatisez la détection des anomalies avec les tâches et les alertes Snowflake¶
Vous pouvez créer un pipeline de détection d’anomalies automatisé, à la fois pour réentraîner le modèle et pour surveiller vos données à la recherche d’anomalies, à l’aide des fonctions de détection d’anomalies au sein des tâches ou des alertes Snowflake.
Entraînement récurrent avec une tâche Snowflake¶
Vous pouvez mettre à jour votre modèle pour refléter les données les plus récentes en utilisant les tâches Snowflake.
Pour créer une tâche qui actualise l’objet de détection des anomalies toutes les heures, exécutez l’instruction suivante, en remplaçant your_warehouse_name par le nom de votre entrepôt :
Par défaut, les tâches venant d’être créées sont suspendues.
Pour reprendre la tâche, exécutez la commande ALTER TASK … RESUME :
Pour mettre la tâche en pause, exécutez la commande ALTER TASK … SUSPEND :
Surveillance à l’aide d’une tâche Snowflake¶
Vous pouvez également utiliser les tâches Snowflake pour surveiller vos données à une fréquence donnée.
Tout d’abord, créez une table qui contiendra les résultats de la détection des anomalies :
Créez une tâche pour stocker les résultats d’une opération récurrente de détection des anomalies dans la table. Cet exemple définit le paramètre WAREHOUSE sur snowhouse. Vous pouvez le remplacer par votre propre entrepôt :
Pour reprendre la tâche, exécutez la commande ALTER TASK … RESUME :
anomaly_res_table contient alors tous les résultats pour chaque tâche exécutée.
Pour mettre la tâche en pause, exécutez la commande ALTER TASK … SUSPEND :
Surveillance à l’aide d’une alerte Snowflake¶
Vous pouvez également utiliser des alertes Snowflake pour surveiller vos données à une fréquence donnée et vous envoyer un e-mail avec les anomalies détectées. Les instructions suivantes créent une alerte qui détecte les anomalies toutes les minutes. Vous définissez d’abord une procédure stockée pour détecter les anomalies, puis vous créez une alerte qui utilise cette procédure stockée.
Note
Vous devez configurer l’intégration du courrier électronique pour envoyer des messages à partir d’une procédure stockée ; voir Notifications dans Snowflake.
Pour démarrer ou reprendre l’alerte, exécutez la commande ALTER ALERT … RESUME :
Pour mettre l’alerte en pause, exécutez la commande ALTER ALERT … SUSPEND :
Présentation de l’importance des fonctions¶
Un modèle de détection des anomalies peut expliquer l’importance relative de toutes les fonctions utilisées dans votre modèle, y compris les variables exogènes que vous avez choisies, les caractéristiques temporelles générées automatiquement (telles que le jour de la semaine ou la semaine de l’année) et les transformations de votre variable cible (telles que les moyennes glissantes et les temps de latence autorégressifs). Ces informations sont utiles pour comprendre quels sont les facteurs qui influencent réellement vos données.
La méthode <nom_du_modèle>!EXPLAIN_FEATURE_IMPORTANCE compte le nombre de fois où les arborescences du modèle ont utilisé chaque fonction pour prendre une décision. Ces scores d’importance des fonctions sont ensuite normalisés à des valeurs comprises entre 0 et 1, de sorte que leur somme soit égale à 1. Les scores obtenus représentent un classement approximatif des fonctions de votre modèle entraîné.
Les fonctions dont le score est proche ont une importance similaire. Pour les séries extrêmement simples (par exemple, lorsque la colonne cible a une valeur constante), tous les scores d’importance des fonctions peuvent être nuls.
L’utilisation de plusieurs fonctions très similaires les unes aux autres peut entraîner une réduction des scores d’importance pour ces fonctions. Par exemple, si une fonction est la quantité d’articles vendus et une autre la quantité d’articles en stock, les valeurs peuvent être corrélées parce que vous ne pouvez pas vendre plus que vous n’avez, et parce que vous essayez de gérer les stocks de manière à ne pas avoir plus en stock que ce que vous allez vendre. Si deux fonctions sont identiques, le modèle peut les considérer comme interchangeables lors de la prise de décision, ce qui se traduit par des scores d’importance des fonctions inférieurs de moitié à ce qu’ils seraient si une seule des fonctions était incluse.
L’importance des fonctions signale également les fonctions de latence. Au cours de la formation, le modèle déduit la fréquence (horaire, quotidienne ou hebdomadaire) de vos données d’entraînement. La fonction lagx (par exemple lag24) est la valeur de la variable cible x unités de temps auparavant. Par exemple, si vos données sont déduites comme étant horaires, lag24 représente votre variable cible il y a 24 heures.
Toutes les autres transformations de votre variable cible (moyennes glissantes, etc.) sont résumées dans la table de résultats sous le nom de aggregated_endogenous_features.
Limitations¶
Vous ne pouvez pas choisir la technique utilisée pour calculer l’importance des fonctions.
Les scores d’importance des fonctions peuvent être utiles pour obtenir une intuition sur les fonctions qui sont importantes pour la précision de votre modèle ; mais les valeurs réelles doivent être considérées comme des estimations.
Exemple¶
Pour comprendre l’importance relative de vos fonctions pour votre modèle, entraînez un modèle, puis appelez <nom_du_modèle>!EXPLAIN_FEATURE_IMPORTANCE. Dans cet exemple, vous allez d’abord créer des données aléatoires avec deux variables exogènes, l’une qui est aléatoire et donc peu susceptible d’être très importante pour votre modèle, et l’autre qui est une copie de votre cible, et donc susceptible d’avoir une plus grande importance pour votre modèle.
Exécutez les instructions suivantes pour générer les données, entraîner un modèle sur celles-ci et obtenir l’importance des fonctions :
Sortie
Comme cet exemple utilise des données aléatoires, ne vous attendez pas à ce que votre sortie corresponde exactement à celle-ci.
Inspection des journaux d’entraînement¶
Lorsque vous entraînez plusieurs séries avec CONFIG_OBJECT => 'ON_ERROR': 'SKIP', les modèles de séries temporelles individuels peuvent échouer sans que le processus d’entraînement global n’échoue. Pour comprendre quelle série temporelle a échoué et pourquoi, appelez <model_instance>!SHOW_TRAINING_LOGS.
Exemple¶
Sortie
Considérations relatives aux clients¶
Pour plus de détails sur les coûts d’utilisation des fonctions ML, consultez Considérations relatives aux clients dans l’aperçu des fonctions ML.