Utilisation du service d’accélération des requêtes (QAS)¶
Le service d’accélération des requêtes (QAS) peut accélérer certaines parties de la charge de travail des requêtes dans un entrepôt. Lorsqu’elle est activée pour un entrepôt, elle peut améliorer les performances globales de l’entrepôt en réduisant l’impact des requêtes aberrantes, qui sont des requêtes qui utilisent plus de ressources que la requête ordinaire. Pour ce faire, le service d’accélération des requêtes décharge des parties du travail de traitement des requêtes sur des ressources de calcul partagées qui sont fournies par le service.
Voici quelques exemples des types de charges de travail qui pourraient bénéficier du service d’accélération des requêtes :
Analyses ad hoc.
Charges de travail avec un volume de données imprévisible par requête.
Requêtes avec de grandes analyses et des filtres sélectifs.
Le service d’accélération des requêtes peut traiter ces types de charges de travail plus efficacement en effectuant davantage de travaux en parallèle et en réduisant le temps de type durée chronométrée consacré à l’analyse et au filtrage.
Note
Query Acceleration Service dépend de la disponibilité des serveurs. Par conséquent, les améliorations des performances peuvent fluctuer dans le temps.
Commandes SQL que QAS peut accélérer¶
Le service d’accélération des requêtes prend en charge les commandes suivantes SQL :
SELECT
INSERT
CREATE TABLE AS SELECT (CTAS)
COPY INTO <table>
Dans le cadre d’une commande SQL prise en charge, QAS peut accélérer une requête entière, une sous-requête ou une clause de la requête, si la commande est éligible à l’accélération.
Activation de l’accélération des requêtes¶
Pour activer le service d’accélération des requêtes, spécifiez la clause ENABLE_QUERY_ACCELERATION = TRUE avec la commande CREATE WAREHOUSE ou ALTER WAREHOUSE.
Exemples¶
L’exemple suivant active le service d’accélération des requêtes pour un nouvel entrepôt nommé my_wh, et pour un entrepôt nommé my_other_wh qui est initialement créé avec QAS désactivé :
Exécutez la commande SHOW WAREHOUSES pour afficher les détails de l’entrepôt my_wh. La requête suivante utilise l”opérateur de canal (->>) pour renvoyer des informations concernant uniquement les colonnes de la sortieSHOW qui sont pertinents pour le traitementQAS :
Le service d’accélération des requêtes peut augmenter le taux de consommation des crédits d’un entrepôt. Le facteur d’échelle maximal peut contribuer à limiter le taux de consommation. Consultez Ajustement du facteur d’échelle pour savoir comment spécifier la propriété QUERY_ACCELERATION_MAX_SCALE_FACTOR. Vous le faites en utilisant les commandes CREATE WAREHOUSE et ALTER WAREHOUSE.
La vue QUERY_ACCELERATION_ELIGIBLE et la fonction SYSTEM$ESTIMATE_QUERY_ACCELERATION peuvent être utiles pour déterminer un facteur d’échelle approprié pour un entrepôt. Pour plus de détails, voir Identification des requêtes et des entrepôts qui pourraient bénéficier de l’accélérations de requêtes (dans ce chapitre).
Identification des requêtes et des entrepôts qui pourraient bénéficier de l’accélérations de requêtes¶
Pour identifier les requêtes ou les entrepôts qui pourraient bénéficier du service d’accélération des requêtes, vous pouvez interroger la vue QUERY_ACCELERATION_ELIGIBLE. Vous pouvez également utiliser la fonction SYSTEM$ESTIMATE_QUERY_ACCELERATION pour déterminer si une requête spécifique est éligible à l’accélération.
Requêtes éligibles¶
En général, les requêtes sont éligibles parce qu’elles comportent une partie du plan de requête qui peut être exécutée en parallèle en utilisant les ressources de calcul de QAS. Ces requêtes peuvent être classées dans l’un des deux modèles suivants :
Les grandes analyses avec un filtre d’agrégation ou sélectif.
Les grandes analyses qui insèrent ou copient de nombreuses nouvelles lignes (par exemple, les commandes INSERT et COPY).
Snowflake n’a pas fixé de seuil spécifique pour ce qui constitue une analyse « suffisamment importante » pour être éligible. Le seuil d’éligibilité dépend de divers facteurs, notamment du plan de requête et de la taille de l’entrepôt. Snowflake ne marque une requête comme éligible que s’il y a de fortes chances que la requête soit accélérée si QAS est activé. Au fil du temps, Snowflake développe les modèles de requêtes éligibles à l’accélération. Par exemple, auparavant, QAS n’accélérait pas les requêtes avec une clause LIMIT et aucune clause ORDER BY, mais désormais Snowflake détermine automatiquement si ces requêtes peuvent bénéficier de QAS.
Raisons courantes pour lesquelles les requêtes ne sont pas éligibles¶
Certaines requêtes ne sont pas éligibles pour l’accélération des requêtes. Voici les raisons courantes pour lesquelles une requête ne peut pas être accélérée :
Il n’y a pas assez de partitions dans l’analyse. S’il n’existe pas assez de partitions à analyser, les avantages de l’accélération des requêtes sont compensés par la latence nécessaire à l’acquisition des ressources pour le service d’accélération des requêtes.
Même si une requête dispose d’un filtre, il se peut que les filtres ne soient pas suffisamment sélectifs. Par ailleurs, si la requête comporte une agrégation avec GROUP BY, la cardinalité de l’expression GROUP BY peut être trop élevée pour être éligible.
La requête comprend une clause LIMIT qui empêche l’accélération. QAS détermine automatiquement quelles requêtes avec les clauses LIMIT(y compris celles sans ORDER BY) peuvent être accélérées.
La requête comprend des fonctions qui renvoient des résultats non déterministes (par exemple, SEQ ou RANDOM).
Identification des requêtes avec la fonction SYSTEM$ESTIMATE_QUERY_ACCELERATION¶
La fonction SYSTEM$ESTIMATE_QUERY_ACCELERATION peut aider à déterminer si une requête exécutée précédemment peut bénéficier du service d’accélération des requêtes. Si la requête est éligible à l’accélération des requêtes, la fonction renvoie le temps d’exécution estimé de la requête pour différents facteurs d’échelle d’accélération.
Exemple¶
Exécutez l’instruction suivante pour déterminer si l’accélération des requêtes peut être bénéfique à une requête spécifique :
Dans cet exemple, la requête est éligible au service d’accélération des requêtes. La valeur du résultat comprend les temps de requête estimés en utilisant ce service. La propriété ineligibleReason est vide.
L’exemple suivant montre les résultats d’une requête qui n’est pas éligible au service d’accélération des requêtes :
L’instruction ci-dessus produit la sortie suivante : Les temps de requête estimés sont vides. La propriété ineligibleReason indique la raison pour laquelle la requête n’a pas utilisé QAS.
Identification des requêtes et des entrepôts avec la vue QUERY_ACCELERATION_ELIGIBLE¶
Interrogez la vue QUERY_ACCELERATION_ELIGIBLE pour identifier les requêtes et les entrepôts qui pourraient bénéficier le plus du service d’accélération des requêtes. Pour chaque requête, la vue inclut la quantité de temps d’exécution de la requête qui est éligible pour le service d’accélération des requêtes.
Exemples¶
Note
Ces exemples supposent que le rôle ACCOUNTADMIN (ou un rôle ayant obtenu des PRIVILEGES IMPORTED pour la base de données SNOWFLAKE partagée) est utilisé. S’il n’est pas utilisé, exécutez la commande suivante avant d’exécuter les requêtes dans les exemples :
Identifiez les requêtes au cours de la semaine écoulée qui pourraient bénéficier le plus du service en fonction du temps d’exécution de la requête qui pourrait être accéléré :
Identifiez les requêtes au cours de la semaine écoulée qui pourraient bénéficier le plus du service dans un entrepôt spécifique mywh :
Identifiez les entrepôts ayant le plus de requêtes éligibles au service d’accélération des requêtes au cours de la semaine écoulée.
Identifiez les entrepôts dont le temps d’éligibilité au service d’accélération des requêtes a été le plus élevé au cours de la semaine écoulée :
Identifiez le facteur d’échelle de la limite supérieure pour le service d’accélération des requêtes pour un entrepôt au cours de la semaine écoulée mywh :
Identifiez la distribution des facteurs d’échelle pour le service d’accélération des requêtes pour un entrepôt au cours de la semaine écoulée mywh :
Ajustement du facteur d’échelle¶
Le facteur d’échelle est un mécanisme de contrôle des coûts qui vous permet de fixer une limite supérieure à la quantité de ressources informatiques qu’un entrepôt peut louer pour l’accélération des requêtes. Cette valeur est utilisée comme un multiplicateur basé sur la taille et le coût de l’entrepôt.
Par exemple, supposons que vous définissiez le facteur d’échelle à 5 pour un entrepôt de taille moyenne. Cela signifie que :
L’entrepôt peut louer des ressources informatiques jusqu’à 5 fois la taille d’un entrepôt moyen.
Comme un entrepôt moyen coûte 4 crédits par heure, la location de ces ressources peut coûter jusqu’à 20 crédits supplémentaires par heure (4 crédits par entrepôt x 5 fois sa taille).
Astuce
Le facteur d’échelle s’applique à l’ensemble de l’entrepôt, qu’il s’agisse d’un entrepôt à un ou multi-clusters. Si vous utilisez QAS pour un entrepôt multi-clusters, envisagez d’augmenter le facteur d’échelle. De cette manière, tous les clusters de l’entrepôt peuvent profiter des optimisations de QAS.
Le coût est le même, quel que soit le nombre de requêtes qui utilisent Query Acceleration Service en même temps. Query Acceleration Service est facturé à la seconde, uniquement lorsqu’il est utilisé. Ces crédits sont facturés indépendamment de l’utilisation de l’entrepôt.
Toutes les requêtes ne nécessitent pas l’ensemble des ressources rendues disponibles par le facteur d’échelle. La quantité de ressources demandées pour le service dépend de la quantité de la requête qui peut être accélérée et de la quantité de données qui seront traitées pour y répondre. Quelle que soit la valeur du facteur d’échelle ou la quantité de ressources demandées, la quantité de ressources informatiques disponibles pour l’accélération des requêtes est limitée par la disponibilité des ressources dans le service et le nombre d’autres requêtes simultanées. Query Acceleration Service n’utilise que les ressources dont il a besoin et qui sont disponibles au moment de l’exécution de la requête.
Si le facteur d’échelle n’est pas explicitement défini, la valeur par défaut est 8. La définition du facteur d’échelle à 0 élimine la limite supérieure et permet aux requêtes de louer autant de ressources que nécessaire et autant de ressources que disponibles pour traiter la requête.
Exemple¶
L’exemple suivant modifie l’entrepôt nommé my_wh pour activer Query Acceleration Service avec un facteur d’échelle maximum de 0.
Surveillance de l’utilisation du service d’accélération des requêtes¶
Cette section décrit comment contrôler l’utilisation du service d’accélération des requêtes. Grâce au contrôle, vous pouvez comprendre l’impact sur les performances, identifier les requêtes qui bénéficient le plus de l’accélération et évaluer l’efficacité globale de la fonctionnalité. Cela peut vous aider à gérer vos coûts et à optimiser vos charges de travail.
Utilisation de l’interface Web pour surveiller l’utilisation de l’accélération des requêtes¶
Une fois que vous avez activé le service d’accélération des requêtes, vous pouvez consulter le panneau Profile Overview dans l”onglet Profil de requête pour voir les effets des résultats de l’accélération des requêtes.
La capture d’écran suivante montre un exemple des statistiques affichées pour la requête globale. Si plusieurs opérations d’une requête ont été accélérées, les résultats sont agrégés dans cette vue afin que vous puissiez voir la quantité totale de travail effectué par le service d’accélération des requêtes.
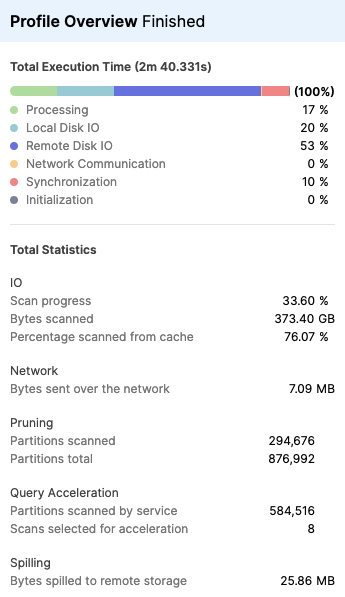
La section Query Acceleration du panneau Profile Overview comprend les statistiques suivantes :
Partitions analysées par le service — nombre de fichiers déchargés dont l’analyse a été confiée au service d’accélération des requêtes.
Analyses sélectionnées pour l’accélération — nombre d’analyses de table en cours d’accélération.
Dans les détails de l’opérateur (voir Statistiques), cliquez sur l’opérateur pour voir des informations détaillées. La capture d’écran suivante montre un exemple des statistiques affichées pour une opération TableScan :
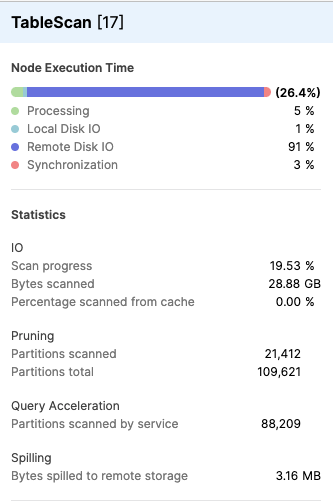
La section Query Acceleration du panneau de détails TableScan comprend les statistiques suivantes :
Partitions analysées par le service — nombre de fichiers déchargés dont l’analyse a été confiée au service d’accélération des requêtes.
Utilisation de la vue QUERY_HISTORY Account Usage pour surveiller l’utilisation de l’accélération des requêtes¶
Pour voir les effets de l’accélération des requêtes sur une requête, vous pouvez utiliser les colonnes suivantes dans Vue QUERY_HISTORY.
QUERY_ACCELERATION_BYTES_SCANNED
QUERY_ACCELERATION_PARTITIONS_SCANNED
QUERY_ACCELERATION_UPPER_LIMIT_SCALE_FACTOR
Vous pouvez utiliser ces colonnes pour identifier les requêtes qui ont bénéficié du service d’accélération des requêtes. Pour chaque requête, vous pouvez également déterminer le nombre total de partitions et d’octets analysés par le service d’accélération des requêtes.
Pour la description de chacune de ces colonnes, voir Vue QUERY_HISTORY.
Note
Pour une requête donnée, la somme des colonnes QUERY_ACCELERATION_BYTES_SCANNED et BYTES_SCANNED peut être plus importante lorsque le service d’accélération des requêtes est utilisé que lorsqu’il ne l’est pas. Il en va de même pour la somme des colonnes QUERY_ACCELERATION_PARTITIONS_SCANNED et PARTITIONS_SCANNED.
L’augmentation du nombre d’octets et de partitions est due aux résultats intermédiaires générés par le service pour faciliter l’accélération des requêtes.
Par exemple, pour trouver les requêtes ayant le plus d’octets analysés par le service d’accélération des requêtes au cours des 24 dernières heures :
Trouver les requêtes avec le plus grand nombre de partitions analysées par le service d’accélération des requêtes dans les 24 dernières heures :
Coût du service de l’accélération des requêtes¶
L’accélération des requêtes consomme des crédits car elle utilise des ressources de calcul sans serveur pour exécuter des parties de requêtes éligibles.
L’accélération des requêtes est facturée comme les autres fonctionnalités sans serveur de Snowflake, en ce sens que vous payez à la seconde les ressources de calcul utilisées. Pour savoir combien de crédits par heure de calcul sont consommés par Query Acceleration Service, reportez-vous au « Tableau des crédits de fonctionnalité sans serveur » dans la Table de consommation du service Snowflake.
Affichage des informations de facturation dans Snowsight¶
Si le service d’accélération des requêtes est activé pour votre compte, utilisez la page de gestion des coûts dans Snowsight pour afficher les informations de facturation pour le service d’accélération des requêtes.
Pour voir les dépenses du service d’accélération des requêtes, procédez comme suit :
Connectez-vous à Snowsight.
Dans le menu de navigation, sélectionnez Admin » Cost management.
Sélectionnez l’onglet Consumption.
Sélectionnez Query Acceleration dans le menu déroulant Service Type.
Snowsight affiche les dépenses du service d’accélération des requêtes pour votre compte.
Visualisation de la facturation en utilisant la vue QUERY_ACCELERATION_HISTORY Account Usage¶
Vous pouvez voir les données de facturation dans Vue QUERY_ACCELERATION_HISTORY Account Usage.
Exemple¶
Cette requête renvoie le nombre total de crédits utilisés par chaque entrepôt de votre compte pour Query Acceleration Service (depuis le début du mois) :
Vue de la facturation à l’aide de la vue QUERY_ACCELERATION_HISTORY Utilisation de l’organisation¶
Vous pouvez voir les données de facturation du service d’accélération des requêtes pour tous les comptes de votre organisation dans la section Vue QUERY_ACCELERATION_HISTORY Utilisation de l’organisation.
Exemple¶
Cette requête renvoie le nombre total de crédits utilisés par chaque entrepôt dans chaque compte pour le service d’accélération de requêtes (depuis le début du mois) :
Affichage de la facturation à l’aide de la fonction QUERY_ACCELERATION_HISTORY¶
Vous pouvez également consulter les données de facturation à l’aide de la fonction Information Schema QUERY_ACCELERATION_HISTORY.
Exemple¶
L’exemple suivant utilise la fonction QUERY_ACCELERATION_HISTORY pour renvoyer des informations sur les requêtes accélérées par ce service au cours des 12 dernières heures :
Évaluation des coûts et des performances¶
Cette section comprend des exemples de requêtes qui peuvent vous aider à évaluer les performances et le coût des requêtes avant et après l’activation du service d’accélération des requêtes.
Visualisation des coûts du service d’accélération de l’entrepôt et des requêtes¶
La requête suivante calcule les coûts de l’entrepôt et du service d’accélération des requêtes pour un entrepôt spécifique. Vous pouvez exécuter cette requête après avoir activé le service d’accélération des requêtes pour un entrepôt afin de comparer les coûts avant et après l’activation de l’accélération des requêtes. La plage de dates pour la requête commence 8 semaines avant la première utilisation du crédit pour le service d’accélération des requêtes et se termine 8 semaines après le dernier coût encouru pour le service d’accélération des requêtes (ou jusqu’à la date actuelle).
Note
Cette requête est particulièrement utile pour évaluer le coût du service si les propriétés de l’entrepôt et la charge de travail restent les mêmes avant et après l’activation du service d’accélération des requêtes.
Cette requête ne renvoie des résultats que si des crédits ont été utilisés pour des requêtes accélérées dans l’entrepôt.
Cet exemple de requête renvoie les coûts de l’entrepôt et du service d’accélération des requêtes pour my_warehouse :
Affichage des performances des requêtes¶
Cette requête renvoie le temps d’exécution moyen des requêtes éligibles à l’accélération des requêtes pour un entrepôt donné. La plage de dates pour la requête commence 8 semaines avant la première utilisation du crédit pour le service d’accélération des requêtes et se termine 8 semaines après le dernier coût encouru pour le service d’accélération des requêtes (ou jusqu’à la date actuelle). Les résultats peuvent vous aider à évaluer l’évolution des performances moyennes des requêtes après l’activation du service d’accélération des requêtes.
Note
Cette requête est particulièrement utile pour évaluer les performances des requêtes si la charge de travail de l’entrepôt reste la même avant et après l’activation du service d’accélération des requêtes.
Si la charge de travail de l’entrepôt reste stable, la valeur de la colonne
num_execsdevrait rester la même.Si la valeur de la colonne
num_execsdes résultats de la requête augmente ou diminue de façon spectaculaire, les résultats de cette requête ne seront probablement pas utiles pour l’évaluation des performances de la requête.
Cet exemple de requête renvoie le temps d’exécution des requêtes par jour et calcule la moyenne des 7 jours de la semaine précédente pour les requêtes éligibles à l’accélération dans l’entrepôt my_warehouse :
La sortie de l’instruction comprend les colonnes suivantes :
Colonne |
Description |
|---|---|
EXEC_DATE |
Date d’exécution des requêtes. |
AVG_EXEC_TIME_7DAYS |
Le temps d’exécution moyen pour les 7 jours précédents, y compris EXEC_DATE. |
AVG_EXEC_TIME |
Le temps moyen d’exécution de la requête. |
QAS_ACCEL_FLAG |
1 si des requêtes ont été accélérées ; NULL si aucune requête n’a été accélérée. |
NUM_EXECS |
Nombre de requêtes accélérées. |
EXEC_TIME |
Temps d’exécution total de toutes les requêtes éligibles à l’accélération des requêtes. |
Astuce
Lorsque le service d’accélération des requêtes (QAS) est activé, Snowflake écrit une petite quantité de données dans le stockage distant pour chaque requête éligible, même si QAS n’est pas utilisé pour cette requête. Par conséquent, ne vous souciez pas d’une valeur non nulle pour bytes_spilled_to_remote_storage dans la vue QUERY_HISTORY quand QAS est activé.
Compatibilité avec l’optimisation de la recherche¶
L’accélération des requêtes et l”optimisation de la recherche peuvent fonctionner ensemble pour optimiser les performances des requêtes. Tout d’abord, l’optimisation de la recherche permet d’assainir les micro-partitions qui ne sont pas nécessaires pour une requête. Ensuite, pour les requêtes éligibles, l’accélération des requêtes peut décharger une partie du reste du travail sur des ressources de calcul partagées fournies par le service.
Les performances des requêtes accélérées par les deux services varient en fonction de la charge de travail et des ressources disponibles.