Micro-partitions et clustering de données¶
Les entrepôts de données classiques reposent sur le partitionnement statique de grandes tables pour obtenir des performances acceptables et permettre une meilleure mise à l’échelle. Dans ces systèmes, une partition correspond à une unité de gestion qui est manipulée indépendamment à l’aide de DDL et d’une syntaxe spécialisés. Cependant, le partitionnement statique a un certain nombre de limites bien connues, telles que les frais généraux de maintenance et la déformation des données, ce qui peut entraîner des partitions de taille disproportionnée.
Contrairement à un entrepôt de données, Snowflake Data Platform implémente un type de partitionnement puissant et unique appelé micro-partitionnement qui offre tous les avantages du partitionnement statique sans les limitations que l’on connaît, ainsi que des avantages significatifs supplémentaires.
Attention
Les Tables hybrides sont basées sur une architecture qui ne prend pas en charge certaines des fonctionnalités, telles que les clés de clustering, qui sont disponibles dans les tables Snowflake standards.
Que sont les micro-partitions ?¶
Toutes les données des tables Snowflake sont automatiquement divisées en micro-partitions qui sont des unités de stockage contiguës. Chaque micro-partition contient entre 50 MB et 500 MB de données non compressées (notez que la taille réelle dans Snowflake est plus petite car les données sont toujours stockées compressées). Les groupes de lignes dans les tables sont mappés en micro-partitions individuelles organisées en colonnes. Cette taille et cette structure permettent « d’élaguer » granulairement de très grandes tables qui peuvent comprendre des millions, voire des centaines de millions, de micro-partitions.
Snowflake stocke les métadonnées de toutes les lignes stockées dans une micro-partition, y compris :
La plage de valeurs pour chacune des colonnes de la micro-partition.
Le nombre de valeurs distinctes.
Propriétés supplémentaires utilisées à la fois pour l’optimisation et le traitement efficace des requêtes.
Note
Le micro-partitionnement est automatiquement effectué sur toutes les tables Snowflake. Les tables sont partitionnées de manière transparente en suivant l’ordre des données au fur et à mesure de leur insertion/chargement.
Avantages du micro-partitionnement¶
Les avantages de l’approche de Snowflake en matière de partitionnement des données de table sont les suivants :
Contrairement au partitionnement statique classique, les micro-partitions Snowflake sont dérivées automatiquement. Elles n’ont pas besoin d’être explicitement définies à l’avance ou entretenues par les utilisateurs.
Comme son nom l’indique, les micro-partitions sont de petite taille (50 à 500 MB, avant compression), ce qui permet un DML très efficace et un élagage granulaire pour des requêtes plus rapides.
Les micro-partitions peuvent se chevaucher dans leur plage de valeurs, ce qui, combiné à leur taille uniformément petite, permet d’éviter les déformations.
Les colonnes sont stockées indépendamment dans des micro-partitions, souvent appelées stockage en colonnes. Ceci permet une analyse efficace des colonnes individuelles. Seules les colonnes référencées par une requête sont analysées.
Les colonnes sont également compressées individuellement dans les micro-partitions. Snowflake détermine automatiquement l’algorithme de compression le plus efficace pour les colonnes de chaque micro-partition.
Vous pouvez activer le clustering sur des tables spécifiques en spécifiant une clé de clustering pour chacune de ces tables. Pour plus d’informations sur la spécification d’une clé de clustering, voir :
Pour plus d’informations sur le clustering, y compris les stratégies pour choisir les tables à clusteriser, voir :
Conséquence des micro-partitions¶
DML¶
Toutes les opérations DML (par ex. DELETE, UPDATE, MERGE) exploitent les métadonnées de micro-partition sous-jacentes pour faciliter et simplifier la maintenance des tables. Par exemple, certaines opérations, comme la suppression de toutes les lignes d’une table, sont des opérations portant uniquement sur les métadonnées.
Suppression d’une colonne dans une table¶
Lorsqu’une colonne d’une table est supprimée, les micropartitions qui contiennent les données de la colonne supprimée ne sont pas réécrites lorsque l’instruction de suppression est exécutée. Les données de la colonne supprimée restent dans le stockage. Pour plus d’informations, consultez les notes sur l’utilisation pour ALTER TABLE.
Élagage de requête¶
Les métadonnées de micro-partition gérées par Snowflake permettent un élagage précis des colonnes dans les micro-partitions au moment de l’exécution de la requête, y compris les colonnes contenant des données semi-structurées. En d’autres termes, une requête qui spécifie un prédicat de filtre sur une plage de valeurs qui accède à 10 % des valeurs de la plage ne devrait idéalement analyser que 10 % des micro-partitions.
Par exemple, supposons qu’une grande table contienne une année de données historiques avec des colonnes de date et d’heure. En supposant une distribution uniforme des données, une requête ciblant une heure particulière devrait idéalement balayer 1/8760e des micro-partitions de la table, et ensuite seulement analyser la partie des micro-partitions qui contiennent les données de la colonne des heures. Snowflake utilise l’analyse en colonnes des partitions afin qu’une partition entière ne soit pas analysée si une requête ne filtre que par une colonne.
En d’autres termes, plus le rapport des micro-partitions analysées et des données en colonnes est proche du rapport des données réellement sélectionnées, plus l’élagage effectué sur la table est efficace.
Pour les données de séries temporelles, ce niveau d’écrémage permet des temps de réponse potentiellement inférieurs à la seconde pour les requêtes situées dans des plages (c’est-à-dire des « tranches ») aussi fines qu’une heure ou moins.
Toutes les expressions de prédicat ne peuvent pas être utilisées pour l’écrémage. Par exemple, Snowflake n’écrème pas les micro-partitions basées sur un prédicat avec une sous-requête, même si la sous-requête aboutit à une constante.
Qu’est-ce que le clustering de données ?¶
En règle générale, les données stockées dans les tables sont triées/rangées selon leurs dimensions naturelles (p. ex. date et/ou régions géographiques). Ce « clustering » est un facteur clé pour les requêtes, car les données de table qui ne sont pas triées ou qui ne le sont que partiellement peuvent avoir des conséquences sur la performance des requêtes, en particulier sur les très grandes tables.
Dans Snowflake, lorsque les données sont insérées/chargées dans une table, les métadonnées de clustering sont collectées et enregistrées pour chaque micro-partition créée au cours du processus. Snowflake exploite ensuite ces informations de clustering pour éviter une analyse inutile des micro-partitions lors des requêtes, accélérant ainsi considérablement les performances des requêtes faisant référence à ces colonnes.
Le diagramme suivant illustre une table Snowflake, t1, avec 4 colonnes triées par date :
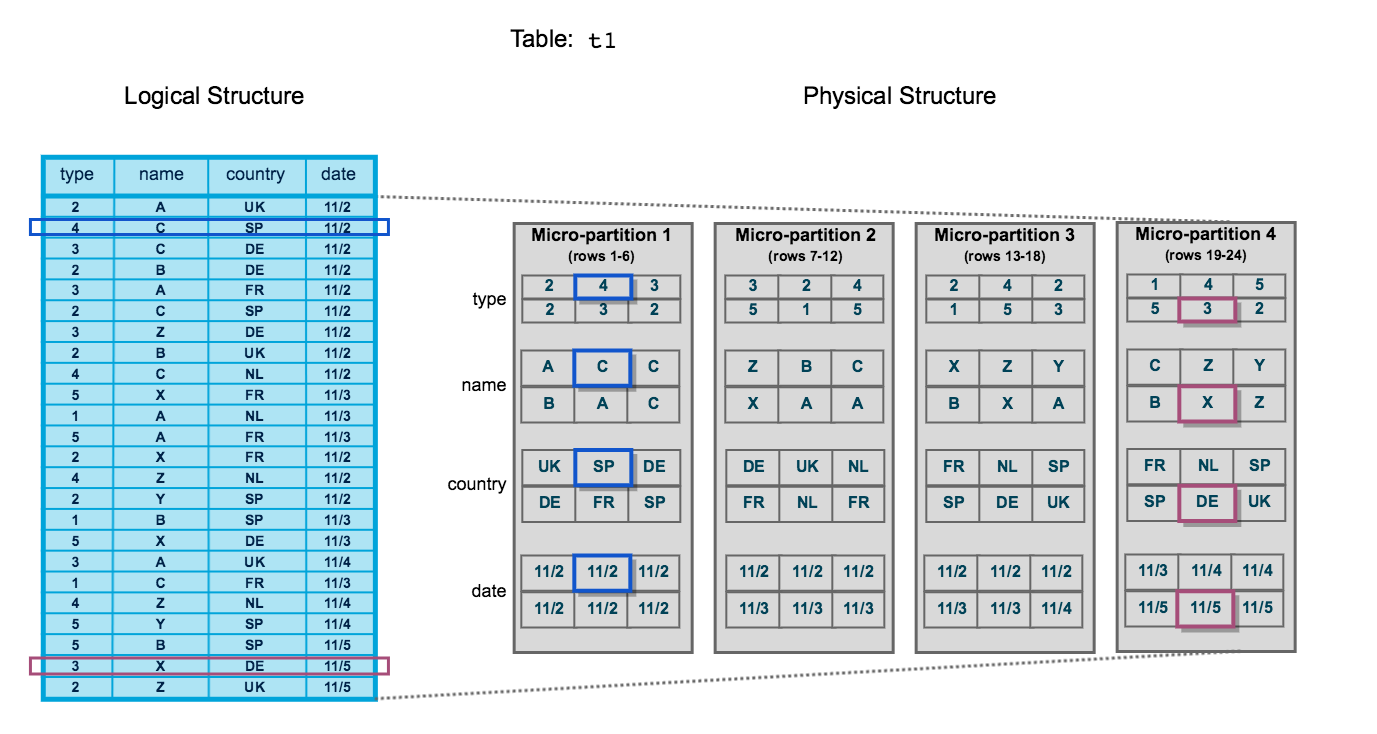
La table se compose de 24 lignes réparties sur 4 micro-partitions, les lignes étant réparties de manière égale entre chaque micro-partition. Dans chaque micro-partition, les données sont triées et stockées par colonne, ce qui permet à Snowflake d’effectuer les actions suivantes pour les requêtes sur la table :
Tout d’abord, écrémez les micro-partitions qui ne sont pas nécessaires pour la requête.
Ensuite, écrémez colonne par colonne dans les micro-partitions restantes.
Notez que ce diagramme n’est qu’une représentation conceptuelle à petite échelle du clustering de données que Snowflake utilise dans les micro-partitions. Une table Snowflake typique peut consister en des milliers, voire des millions, de micro-partitions.
Informations de clustering gérées pour les micro-partitions¶
Snowflake gère les métadonnées de clustering pour les micro-partitions d’une table, y compris :
Le nombre total de micro-partitions qui composent la table.
Le nombre de micro-partitions contenant des valeurs qui se chevauchent (dans un sous-ensemble spécifié de colonnes de table).
La profondeur des micro-partitions qui se chevauchent.
Profondeur de clustering¶
La profondeur de clustering pour une table remplie mesure la profondeur moyenne (supérieure ou égale à 1) des micro-partitions qui se chevauchent pour les colonnes spécifiées dans une table. Plus la profondeur moyenne est faible, mieux la table est groupée en ce qui concerne les colonnes spécifiées.
La profondeur de clustering peut être utilisée à de nombreuses fins, par exemple :
Suivre la « santé » de clustering d’une grande table, en particulier dans le temps puisque DML est effectué sur la table.
Déterminer si une grande table bénéficierait d’une clé de clustering définie explicitement.
Une table sans micro-partitions (c’est-à-dire une table vide ou non remplie) a une profondeur de clustering de 0.
Note
La profondeur de clustering d’une table n’est pas une mesure absolue ou précise de la qualité du clustering de la table. Par ailleurs, la performance des requêtes est le meilleur indicateur de la qualité du cluster d’une table :
Si les requêtes sur une table fonctionnent comme prévu, la table est probablement bien regroupée en cluster.
Si les performances des requêtes se dégradent avec le temps, la table n’est probablement plus mise en cluster de manière optimale et un clustering serait profitable.
Profondeur de clustering illustrée¶
Le diagramme suivant fournit un exemple conceptuel d’une table composée de 5 micro-partitions avec des valeurs allant de A à Z, et illustre comment le chevauchement affecte la profondeur de clustering :
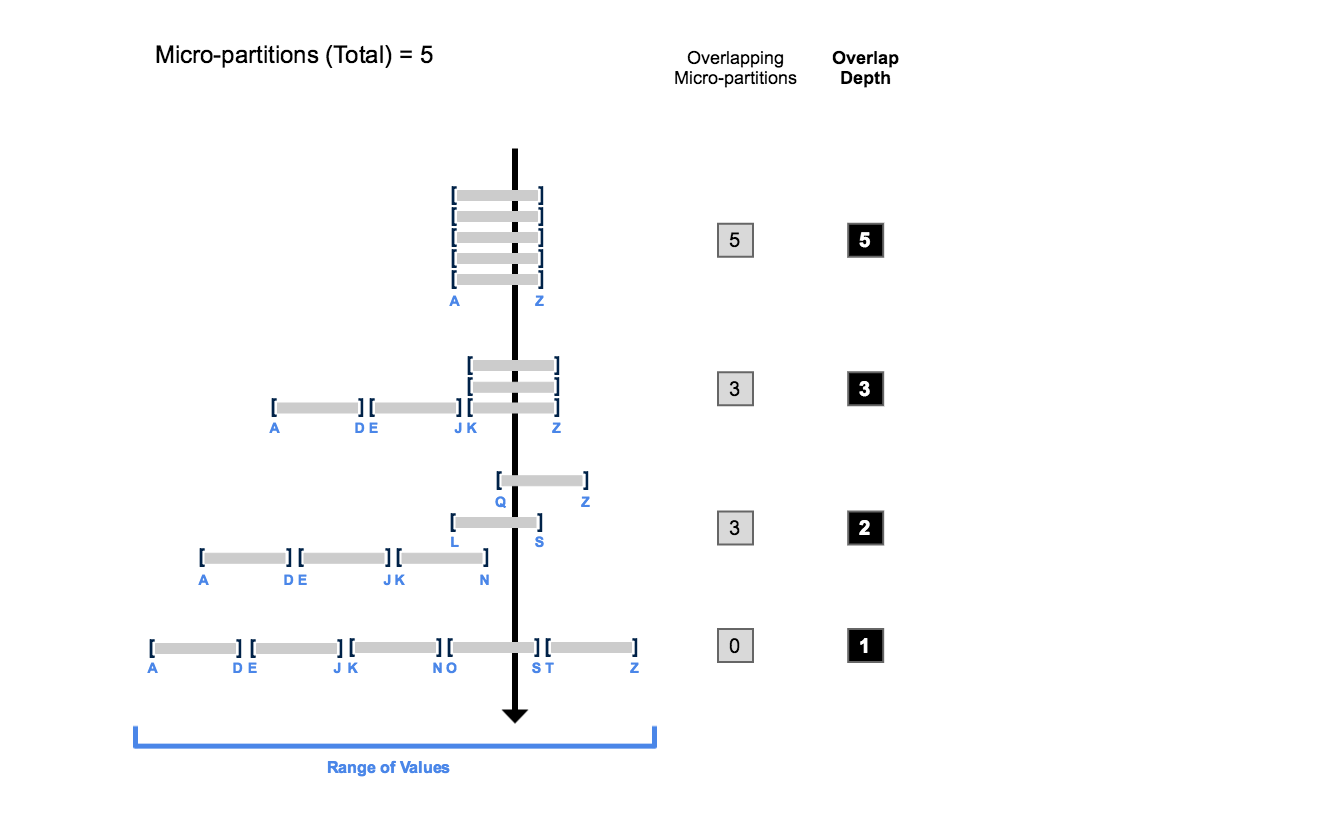
Comme l’illustre ce diagramme :
Au début, la plage de valeurs dans toutes les micro-partitions se chevauchent.
Au fur et à mesure que le nombre de micro-partitions qui se chevauchent diminue, la profondeur de chevauchement diminue.
Lorsqu’il n’y a pas de chevauchement dans la plage de valeurs entre toutes les micro-partitions, les micro-partitions sont considérées comme étant dans un état constant (c’est-à-dire qu’elles ne peuvent pas être améliorées par un clustering).
Le diagramme n’est pas destiné à représenter une table réelle. Dans une table réelle, avec des données contenues dans un grand nombre de micro-partitions, il n’est ni probable ni nécessaire d’atteindre un état constant dans toutes les micro-partitions pour améliorer les performances des requêtes.
Suivi des informations de clustering pour les tables¶
Pour voir/surveiller les métadonnées de clustering d’une table, Snowflake fournit les fonctions système suivantes :
SYSTEM$CLUSTERING_INFORMATION (y compris la profondeur de clustering)
Pour plus d’informations sur la manière dont ces fonctions utilisent les métadonnées de clustering, voir Profondeur de clustering illustrée (dans cette rubrique).