Aperçu du connecteur Spark¶
Le connecteur Snowflake pour Spark permet d’utiliser Snowflake comme source de données Apache Spark, de manière similaire aux autres sources de données (PostgreSQL, HDFS, S3, etc).
Note
As an alternative to using Spark, consider writing your code to use API Snowpark instead. Snowpark allows you to perform all of your work within Snowflake (rather than in a separate Spark compute cluster). Snowpark also supports pushdown of all operations, including Snowflake UDFs. However, when you want to enforce row and column policies on Iceberg tables, use the Snowflake Spark Connector. For more information, see Renforcer les politiques de protection des données lors de l’interrogation de tables Apache Iceberg™ Apache Spark™.
Interaction entre Snowflake et Spark¶
Le connecteur prend en charge le mouvement bidirectionnel des données entre un cluster Snowflake et un cluster Spark. Le cluster Spark peut être auto-hébergé ou accessible via un autre service, tel que Qubole, AWS EMR, ou Databricks.
A l’aide du connecteur, vous pouvez effectuer les opérations suivantes :
Remplissez un DataFrame Spark à partir d’une table (ou une requête) dans Snowflake.
Écrivez le contenu d’un DataFrame Spark vers une table dans Snowflake.
Le connecteur utilise 2.12.x ou 2.13.x pour effectuer ces opérations et utilise le pilote JDBC Snowflake pour communiquer avec Snowflake.
Note
Le connecteur Snowflake pour Spark n’est pas strictement requis pour connecter Snowflake et Apache Spark. D’autres pilotes JDBC tiers peuvent être utilisés. Cependant, nous recommandons d’utiliser le connecteur Snowflake pour Spark, car le connecteur, conjointement au pilote JDBC Snowflake, a été optimisé pour transférer de grandes quantités de données entre les deux systèmes. Il offre également des performances améliorées en prenant en charge le pushdown des requêtes de Spark à Snowflake.
Transfert de données¶
Le connecteur Snowflake Spark prend en charge deux modes de transfert :
Le transfert interne utilise un emplacement temporaire créé et géré de façon interne/transparente par Snowflake.
Le transfert externe utilise un emplacement de stockage, généralement temporaire, créé et géré par l’utilisateur.
Astuce
Utilisez le transfert de données externe si l’une des affirmations suivantes est vraie :
Vous utilisez la version 2.1.x ou une version inférieure du connecteur Spark (qui ne prend pas en charge le transfert interne).
Votre transfert prendra probablement 36 heures ou plus (le transfert interne utilise des identifications de connexion temporaires qui expirent après 36 heures).
Sinon, nous recommandons d’utiliser le transfert de données interne.
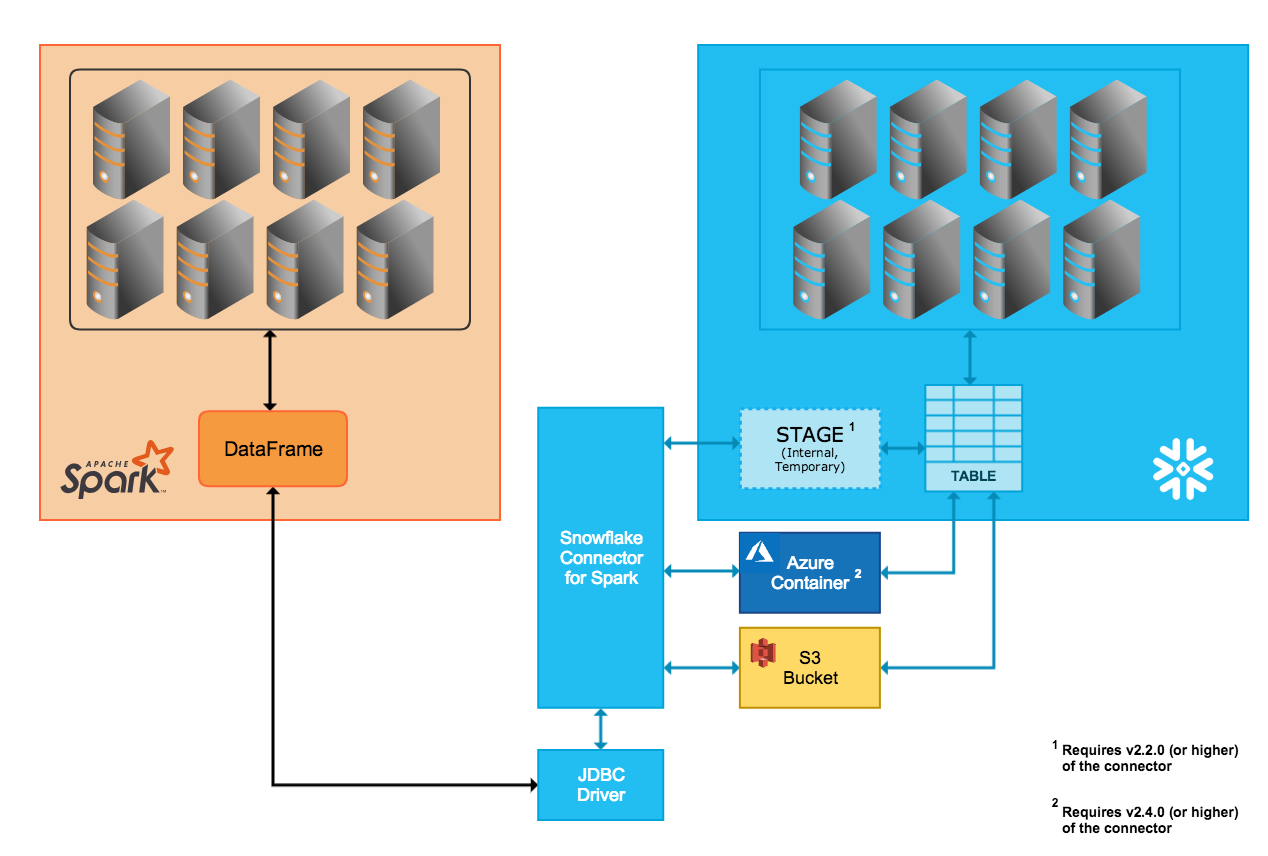
Transfert de données interne¶
Le transfert de données entre les deux systèmes est simplifié par une zone de préparation interne Snowflake que le connecteur crée et gère automatiquement :
Lors de la connexion à Snowflake et de l’initialisation d’une session dans Snowflake, le connecteur crée la zone de préparation interne.
Pendant toute la durée de la session Snowflake, le connecteur utilise la zone de préparation pour stocker les données tout en les transférant vers leur destination.
À la fin de la session Snowflake, le connecteur abandonne la zone de préparation, supprimant ainsi toutes les données temporaires de la zone de préparation.
Notez que la prise en charge du transfert interne nécessite une version spécifique (ou supérieure) du connecteur, basée sur la plateforme Cloud de votre compte Snowflake :
- AWS:
Le mode de transfert de données interne n’est pris en charge que dans la version 2.2.0 (et supérieure) du connecteur.
- Azure:
Le mode de transfert de données interne n’est pris en charge que dans la version 2.4.0 (et supérieure) du connecteur.
- GCP:
Le mode de transfert de données interne n’est pris en charge que dans la version 2.7.0 (et supérieure) du connecteur.
Transfert de données externe¶
Le transfert de données entre les deux systèmes est simplifié par un emplacement de stockage que l’utilisateur spécifie et des fichiers créés automatiquement par le connecteur :
- AWS:
Les fichiers de données de transfert sont créés et stockés dans un compartiment S3.
- Azure:
Les fichiers de données de transfert sont créés et stockés dans un conteneur de stockage Blob. Le transfert externe via Azure n’est pris en charge que dans la version 2.4.0 (et supérieure) du connecteur.
Le(s) paramètre(s) qui servent à spécifier l’emplacement de stockage sont documentés dans Réglage des options de configuration du connecteur :
Note
Pour le transfert de données externe, l’emplacement de stockage doit être créé et configuré dans le cadre de l’installation/configuration du connecteur Spark.
En outre, les fichiers créés par le connecteur pendant le transfert externe sont destinés à être temporaires, mais le connecteur ne supprime pas automatiquement les fichiers de l’emplacement de stockage. Pour supprimer les fichiers, utilisez l’une des méthodes suivantes :
Supprimez-les manuellement.
Réglez le paramètre
purgepour le connecteur. Pour plus d’informations sur ce paramètre, voir Réglage des options de configuration du connecteur.Définissez un paramètre de système de stockage, tel que le paramètre de politique de cycle de vie Amazon S3, pour nettoyer les fichiers une fois le transfert terminé.
Mappage de colonne¶
Lorsque vous copiez des données d’une table Spark vers une table Snowflake, si les noms de colonne ne correspondent pas, vous pouvez mapper les noms de colonne de Spark vers Snowflake en utilisant le paramètre columnmapping qui est documenté dans Réglage des options de configuration du connecteur.
Note
Le mappage des colonnes n’est pris en charge que pour le transfert des données interne.
Pushdown de requêtes¶
Pour des performances optimales, vous voulez généralement éviter de lire une grande quantité de données ou de transférer un grand nombre de résultats intermédiaires entre les systèmes. Idéalement, la majeure partie du traitement devrait avoir lieu près de l’emplacement où les données sont stockées afin de tirer parti des capacités des magasins de données participants pour éliminer dynamiquement les données qui ne sont pas nécessaires.
Le pushdown de requêtes permet de tirer parti de ces gains d’efficacité de performances en permettant de traiter dans Snowflake des plans logiques Spark volumineux et complexes (dans leur intégralité ou en partie), utilisant ainsi Snowflake pour effectuer la plus grande partie des opérations.
Le pushdown de requête est pris en charge dans la version 2.1.0 (et ultérieure) de Snowflake Connector pour Spark.
Le pushdown n’est pas possible dans toutes les situations. Par exemple, les UDFs Spark ne peuvent pas être push down à Snowflake. Voir Pushdown pour la liste des opérations prises en charge pour le pushdown.
Note
Si vous avez besoin de la fonction pushdown pour toutes les opérations, pensez à écrire votre code pour utiliser API Snowpark à la place. Snowpark prend également en charge le pushdown des UDFs Snowflake.
Intégration de Databricks¶
Databricks a intégré le connecteur Snowflake pour Spark dans la plateforme Databricks Unified Analytics Platform pour fournir une connectivité native entre Spark et Snowflake.
Pour plus de détails, y compris des exemples de code utilisant Scala et Python, voir Sources de données — Snowflake (dans la documentation Databricks) ou Configuration de Snowflake pour Spark dans Databricks.
Intégration de Qubole¶
Qubole a intégré le connecteur Snowflake pour Spark dans l’écosystème Qubole Data Service (QDS) pour fournir une connectivité native entre Spark et Snowflake. Grâce à cette intégration, Snowflake peut être ajouté directement dans Qubole en tant qu’entrepôt de données Spark.
Une fois que Snowflake a été ajouté en tant qu’entrepôt de données Spark, les ingénieurs et les scientifiques de données peuvent utiliser Spark, QDS UI, API et des notebooks pour :
Effectuer des transformations de données avancées, comme la préparation et la consolidation de sources de données externes vers Snowflake, ou l’affinage et la transformation des données Snowflake.
Construire, former et exécuter des modèles de machine learning et des modèles AI dans Spark en utilisant les données qui existent déjà dans Snowflake.
Pour plus de détails, voir le guide d’intégration Qubole-Snowflake (dans la documentation Qubole) ou Configuration de Snowflake pour Spark dans Qubole.