Tabelas híbridas¶
Uma tabela híbrida é um tipo de tabela Snowflake que é otimizada para baixa latência e alta taxa de transferência usando leituras e gravações aleatórias baseadas em índices. As tabelas híbridas oferecem um mecanismo de armazenamento baseado em linhas que é compatível com o bloqueio de linhas para alta simultaneidade. As tabelas híbridas também aplicam restrições exclusivas e de integridade referencial, que são essenciais para cargas de trabalho transacionais. Você pode usar uma tabela híbrida junto com outras tabelas e recursos do Snowflake para potencializar cargas de trabalho Unistore que reúnem dados transacionais e analíticos em uma única plataforma.
Os casos de uso que podem se beneficiar das tabelas híbridas incluem:
Metadados para aplicativos e fluxos de trabalho, como a manutenção do estado de um fluxo de trabalho de ingestão que exige atualizações de alta simultaneidade em uma única tabela de milhares de trabalhadores paralelos.
Serviço de baixa latência de agregados pré-computados por meio de uma API ou de uma interface de usuário.
Aplicativos transacionais leves com modelos de dados relacionais.
Dica
Antes de criar e usar tabelas híbridas, você deve se familiarizar com alguns recursos e limitações não compatíveis.
Arquitetura¶
As tabelas híbridas se integram perfeitamente à arquitetura Snowflake existente. Os clientes se conectam ao mesmo serviço de banco de dados Snowflake. As consultas são compiladas e otimizadas na camada de serviços em nuvem e executadas no mesmo mecanismo de consulta e warehouses virtuais que as tabelas padrão. Essa arquitetura tem vários benefícios importantes:
Os recursos da plataforma Snowflake, como governança de dados, funcionam com tabelas híbridas prontas para uso.
Você pode executar cargas de trabalho híbridas que combinem consultas operacionais e analíticas.
Você pode unir tabelas híbridas a outras tabelas do Snowflake; as consultas são executadas de forma nativa e eficiente no mesmo mecanismo de consulta. Nenhuma federação é necessária.
Você pode executar uma transação atômica em tabelas híbridas e outras tabelas Snowflake. Não há necessidade de orquestrar sua própria confirmação em duas fases.
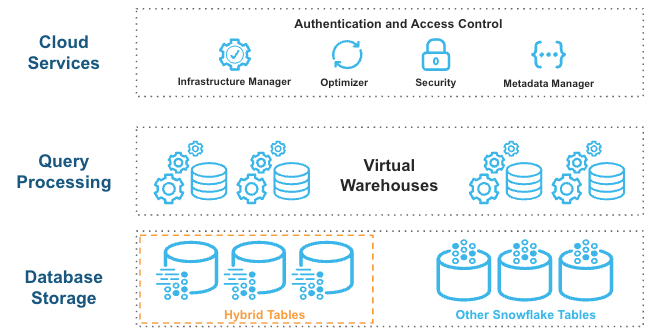
As tabelas híbridas utilizam um armazenamento de linhas como armazenamento de dados primário para fornecer excelente desempenho de consulta operacional. Quando você grava em uma tabela híbrida, os dados são gravados diretamente no armazenamento de linhas. Os dados são copiados de forma assíncrona no armazenamento de objetos para fornecer melhor desempenho e isolamento de carga de trabalho para grandes verificações sem afetar suas cargas de trabalho operacionais contínuas. Alguns dados também podem ser armazenados em cache no formato colunar em seu warehouse, a fim de proporcionar melhor desempenho para consultas analíticas. Você simplesmente executa instruções SQL na tabela híbrida lógica e o otimizador de consulta do Snowflake decide de onde ler os dados para fornecer o melhor desempenho. Você obtém uma exibição consistente dos seus dados sem precisar se preocupar com a infraestrutura subjacente.
Nota
Como o armazenamento primário para tabelas híbridas é um armazenamento de linhas, as tabelas híbridas normalmente têm uma área de armazenamento maior do que as tabelas padrão. O principal motivo para a diferença é que dados em colunas para tabelas padrão geralmente atingem taxas mais altas de compressão. Para obter detalhes sobre custos de armazenamento, consulte Avaliar custo para tabelas híbridas.
Recursos¶
As tabelas híbridas fornecem alguns recursos adicionais que não são suportados por outros tipos de tabela Snowflake.
Recurso |
Tabelas híbridas |
Tabelas padrão |
|---|---|---|
Layout de dados primários |
Orientado a linhas, com armazenamento colunar secundário |
Micropartições colunares |
Bloqueio |
Nível de linha |
Partição ou tabela |
Restrições PRIMARY KEY |
Obrigatório, imposto |
Opcional, não obrigatório |
Restrições FOREIGN KEY |
Opcionais e impostas (integridade referencial) |
Opcional, não obrigatório |
Restrições UNIQUE |
Opcional (exceto para PRIMARY KEY), aplicado |
Opcional, não obrigatório |
Restrições NOT NULL |
Opcional (exceto para PRIMARY KEY), aplicado |
Opcionais e impostas |
Índices |
Suporte a desempenho; atualizadas de forma síncrona nas gravações |
O serviço de otimização de pesquisa indexa colunas para melhor desempenho de pesquisa de pontos; as atualizações em lote são realizadas e mantidas de forma assíncrona. |
Uma restrição é aplicada quando protege uma coluna de ser atualizada de determinadas maneiras. Por exemplo, uma coluna declarada NOT NULL não pode conter um valor NULL. Uma tentativa de copiar ou inserir um valor NULL em uma coluna NOT NULL sempre resulta em um erro.
Para tabelas híbridas, não é possível definir a propriedade NOT ENFORCED nas restrições PRIMARY KEY, FOREIGN KEY e UNIQUE. Definir esta propriedade resulta em um erro de “propriedade de restrição inválida”. Para obter mais informações sobre regras para restrições, consulte Restrições para tabelas híbridas.
Uma restrição é obrigatória quando uma ou mais colunas em uma tabela devem ter tal restrição, o que é verdadeiro apenas para restrições PRIMARY KEY em tabelas híbridas.
Quando usar uma tabela híbrida¶
Embora você deva esperar que as tabelas padrão Snowflake ofereçam melhor desempenho em grandes consultas analíticas, as tabelas híbridas permitem resultados mais rápidos em consultas operacionais de curta duração. As tabelas híbridas oferecem alta simultaneidade e baixa latência para muitas cargas de trabalho. Os seguintes tipos de consultas têm maior probabilidade de se beneficiar das tabelas híbridas:
Leituras de ponto aleatório baseadas em índices que recuperam um pequeno número de registros, como objetos de clientes
Gravações aleatórias de alta simultaneidade, incluindo inserções, atualizações e fusões:
Os aplicativos geralmente trabalham com uma combinação de tabelas híbridas e tabelas padrão, com diferentes conjuntos de dados armazenados em cada tipo de tabela. Por exemplo, você pode ter alguns dados que frequentemente carrega em massa, examina e agrega para fins de análise, e outros dados que acessa uma linha por vez, filtrados em uma coluna ID em alta simultaneidade. Você pode combinar o uso de tabelas padrão e tabelas híbridas em um único banco de dados com base nas necessidades de sua carga de trabalho.