ハイブリッドテーブルのクエリプロファイルの分析¶
Unistoreのワークロードは、 Snowsight クエリプロファイル機能や EXPLAIN の出力から得られる情報を使って調査できる、クエリ実行に関するいくつかの興味深い疑問を提起します。全体的なパフォーマンスとスループットの監視に加え、テーブルスキャンが行ストアまたはオブジェクトストレージに対して実行されているかどうか、あるいは特定のセカンダリインデックスが使用されているかどうかを知りたい場合があります。
このセクションでは、ハイブリッドテーブル操作に関連する Query Profile 演算子と属性を特定し、ハイブリッドテーブルにアクセスするクエリプランの読み方を理解するのに役立ついくつかの例を示します。クエリ履歴でクエリのアクティビティをモニターする もご参照ください。
ハイブリッドテーブルスキャンとインデックススキャン¶
テーブルおよびインデックススキャン演算子は、ハイブリッドテーブルへのアクセスを示すためにクエリプロファイルに表示されます。これらの演算子は通常、ツリーの一番下に表示され、特定のクエリを実行するために必要なデータを読み取る最初のステップを表します。標準テーブルに対するクエリは常にテーブルスキャンを使用し、インデックススキャンは使用しません。
プライマリキーインデックスを使用してハイブリッドテーブルをスキャンする場合、クエリプロファイルには IndexScan 演算子ではなく、 TableScan 演算子が表示されます。セカンダリインデックスなど、他のインデックスがハイブリッドテーブルのスキャンに使用される場合、 IndexScan 演算子が表示されます。
IndexScan 演算子の Attributes の下に、インデックスの完全修飾名と Access predicates が表示されます。これらは、スキャン中にインデックスに適用される述語です。また、テーブルスキャン中に適用されるフィルターの述語を見ることもできます。
述語がインデックスに「プッシュ」される時、述語はクエリで使用された定数のプレースホルダーを括弧の中に含みます。例: SENSOR_DATA_DEVICE2.DEVICE_ID = (:SFAP_PRE_NR_1)
スキャンモード¶
ハイブリッドテーブルデータは、運用と分析の両方のワークロードに対応するため、2つのフォーマットで管理されています。管理者からよく聞かれる質問は、あるクエリが行ストアと列ストア(オブジェクトストレージ)のどちらにアクセスするかということです。クエリは、対象となるテーブル、クエリの特定の要件、インデックスの可用性、その他の要因に応じて、どちらか一方または両方のタイプのストレージから読み込むことができます。
ハイブリッドテーブルクエリのクエリプロファイルには、ツリー内の各テーブルスキャン演算子の Scan Mode 属性が含まれます。
ROW-BASED: クエリは、行ストアのテーブルデータから読み込むか、インデックスを使用してクエリ結果を計算します。
COLUMN-BASED: クエリは、行ストアにロードされたのと同じデータのオブジェクトストレージコピーから読み取ります。インデックススキャンは、 Time Travel クエリのために、オブジェクトストレージにアクセスすることもできます。
スキャンモードはハイブリッドテーブル固有です。標準テーブルに対してテーブルスキャンを実行した場合、 Scan Mode 属性は表示されません。
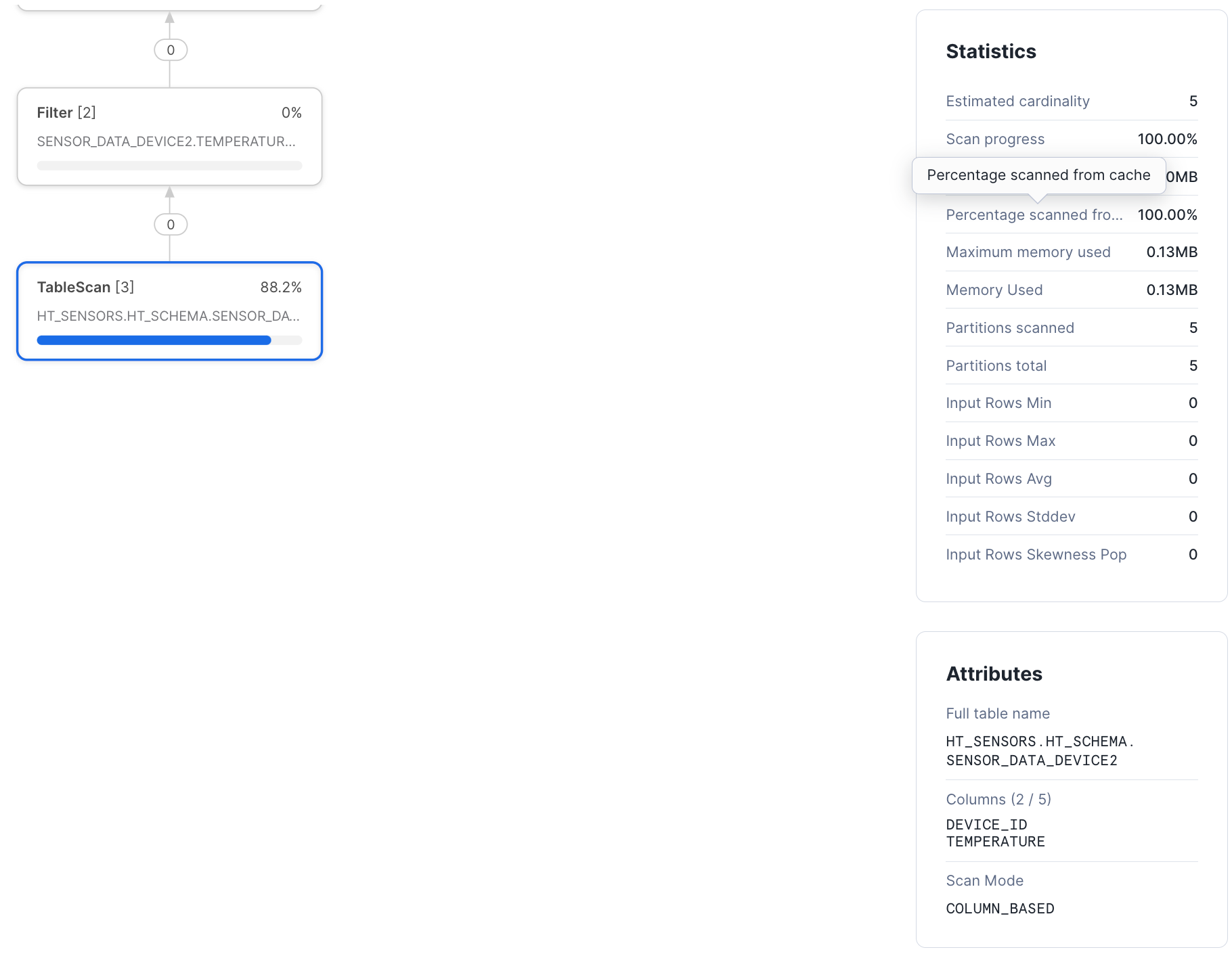
列ウェアハウスキャッシュから読み込まれたデータ¶
可能であれば、ハイブリッドテーブルのテーブルスキャンは列ウェアハウスキャッシュからデータを読み込みます。このキャッシュは標準ウェアハウスキャッシュを拡張したものです。ウェアハウスキャッシュの最適化 を参照してください。キャッシュにはハイブリッドテーブルストレージプロバイダーから読み込まれたデータが含まれ、ハイブリッドテーブルに対する読み取り専用クエリでアクセスできます。
指定したクエリプロファイルのキャッシュ使用状況を確認するには、テーブルスキャン演算子を選択し、 Statistics の下にある Percentage scanned from cache をチェックします。
ハイブリッドテーブルから選択するクエリは、 クエリ結果キャッシュ の恩恵を受けません。
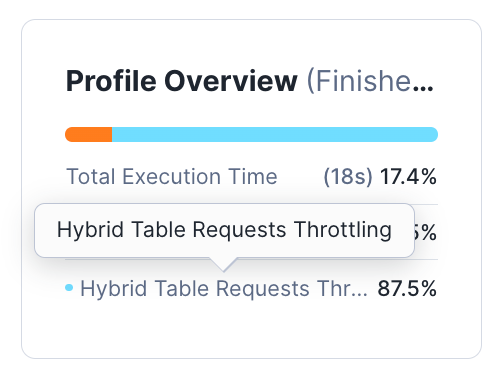
ハイブリッドテーブルリクエストのスロットリング¶
Profile Overview では、 Hybrid Table Requests Throttling のパーセンテージを見ることができます。この概要を表示するには、ツリー内の演算子を選択しないでください。概要はクエリプラン全体に適用されます。
例えば、以下のクエリは実行時間の87.5%がハイブリッドテーブルストレージプロバイダーによってスロットルされていることを記録しています。スロットリングのパーセンテージが高いということは、データベースのクォータに対して、あまりにも多くのハイブリッドテーブルの読み取りおよび書き込みリクエストがストレージプロバイダーに送信されていることを示します。詳細については、 クォータとスロットリング をご参照ください。
例¶
次のクエリプロファイルの Snowsight 例は、ハイブリッドテーブル操作に固有の属性を示しています。これらの例を理解するために、クエリされ変更されるテーブルを作成しロードする必要はありません。しかし、参考までに、あるテーブルの CREATE TABLE ステートメントをここに示します。PRIMARY KEY 制約(timestamp 列)とセカンダリインデックス(device_id 列)の定義に注意してください。
また、似たようなハイブリッドテーブル、 sensor_data_device2 も例で使われています。
主キー列にアクセスするクエリプラン¶
クエリがテーブルの主キー(timestamp)をフィルターする場合、自動的にインデックスが作成されますが、クエリプロファイルは TableScan 演算子を使用します。また、このクエリには ROW_BASED スキャンモードが使用されていることに注意してください。

セカンダリインデックスにアクセスするクエリプラン¶
このプロファイルを生成したクエリは次のようなものです。
ここではプロファイルの一部のみを紹介し、 IndexScan 演算子とその属性に焦点を当てます。スキャンモードは ROW_BASED で、アクセス述語 にカーソルを合わせると完全な述語を見ることができます。完全修飾インデックス名も表示されます。

INCLUDE列 もご参照ください。
ハイブリッドテーブルの DML のクエリプラン¶
ハイブリッドテーブルに対する DML 操作は通常、単一の行を変更します。例:
TableScan 演算子のクエリプロファイルは、この UPDATE がハイブリッドテーブルの行ストア(スキャンモードは ROW_BASED)にアクセスしていることを示しています。

キャッシュされたデータを利用する反復クエリ¶
この場合、ハイブリッドテーブルに対して以下のクエリを2回連続して実行したとします。
最初のクエリは、オブジェクトストレージからすべてのデータを読み込みます。クエリの2回目の実行では、列キャッシュから100%のデータを読み込みます。また、このクエリのスキャンモードは COLUMN_BASED であることに注意してください。
結合のクエリプラン(ハイブリッドテーブルから標準テーブルへ)¶
ハイブリッドテーブルを標準テーブルに結合すると、ハイブリッドテーブルにはスキャン用の Scan Mode 属性が表示されますが、標準テーブルには表示されません。例えば、この結合プランの左側の TableScan 演算子は、 ROW_BASED スキャンモードを使用しました。order_header テーブルは、 order_id を主キー(この例では結合列)とするハイブリッドテーブルです。もうひとつのテーブル、 truck_history は標準テーブルです。
