윈도우 함수는 파티션 이라고 하는 관련 행 그룹에서 작업하는 분석 SQL 함수입니다. 파티션은 일반적으로 제품 카테고리, 위치, 기간 또는 사업 단위와 같은 익숙한 차원에 따라 논리적으로 그룹화된 행입니다. 함수 결과는 암시적 또는 명시적 윈도우 프레임 을 기준으로 각 파티션에 대해 계산됩니다. 윈도우 프레임은 현재 행 을 기준으로 고정되거나 가변적인 행 집합입니다. 현재 행은 현재 함수 결과가 계산되고 있는 단일 입력 행입니다. 함수 결과는 각 파티션 내에서 행별로 계산되고, 윈도우 프레임의 각 행이 현재 행이 됩니다.
이 동작을 정의하는 구문은 함수에 대한 OVER 절입니다. 많은 경우 OVER 절은 윈도우 함수를 이름(예: AVG 또는 SUM)이 동일한 일반 SQL 함수와 구분합니다. OVER 절은 다음의 세 주요 구성 요소로 이루어져 있습니다.
PARTITION BY 절
ORDER BY 절
윈도우 프레임 사양
해당 함수 또는 쿼리에 따라 이러한 구성 요소는 모두 선택 사항일 수 있으며, OVER 절이 비어 있는 윈도우 함수는 유효한 OVER() 입니다. 그러나 대부분의 분석 쿼리에서 윈도우 함수는 하나 이상의 명시적 OVER 절 구성 요소를 필요로 합니다. 다른 SQL 함수를 지원하는 모든 컨텍스트에서 윈도우 함수를 호출할 수 있습니다. 다음 섹션에서는 윈도우 함수의 개념을 더 자세히 설명하고 몇 가지 소개 예제를 제시합니다. 전체 구문 정보는 윈도우 함수 구문 및 사용법 섹션을 참조하십시오.
이 함수는 각 파티션의 각 행에 대한 평균을 반환하고 파티션 열 값이 변경되면 계산을 재설정합니다. 윈도우 함수의 값을 더 명확하게 표시하려면 함수 정의에 ORDER BY 절과 윈도우 프레임을 추가합니다. 또한 평균값 외에 원시 menu_cogs_usd 값도 반환하므로 특정 계산이 어떻게 작동하는지 확인할 수 있습니다. 이 쿼리는 명시적 윈도우 프레임에 따라 달라지는 롤링 계산인 “이동 평균”의 간단한 예입니다. 이와 같은 예를 더 보려면 시계열 데이터 분석하기 섹션을 참조하십시오.
윈도우 프레임은 현재 행과 그 뒤에 오는 두 행(파티션 내)만 고려되도록 평균 계산을 조정합니다. 파티션의 마지막 행에는 다음 행이 없으므로, 예를 들어 마지막 Beverage 행의 평균은 해당 menu_cogs_usd 값(0.65)과 동일합니다. 윈도우 함수의 출력은 함수에 전달된 개별 행과 윈도우 프레임에 적합한 다른 행의 값에 따라 달라집니다.
참고
ORDER BY 절과 함께 윈도우 함수를 사용하는 경우 순서가 결정적인지 확인합니다. ORDER BY 열에 대해 동일한 값이 여러 행에 있는 경우, 쿼리 실행 전반에 걸쳐 일관되고 예측 가능한 결과를 보장하기 위해 추가 열을 순위 결정자로 추가합니다. 이 예제에서는 여러 행에 동일한 menu_price_usd 값이 있을 수 있으므로 ``menu_cogs_usd``가 순위 결정자로 포함됩니다.
앞의 AVG 윈도우 함수 예제에서는 함수 정의 내에 menu_price_usd 절을 사용하여 윈도우 프레임이 정렬된 데이터(이 경우 ORDER BY 기준)에 적용되도록 합니다.
두 가지 유형의 윈도우 함수에는 ORDER BY 절이 필요합니다.
명시적 윈도우 프레임이 있는 윈도우 함수는 각 파티션의 행 하위 집합에 대해 누적 합계나 이동 평균을 계산하는 등 롤링 작업을 수행합니다. ORDER BY 절이 없으면 윈도우 프레임은 의미가 없으며, “선행”과 “후행”의 집합은 결정론적이어야 합니다.
행의 “순위”에 따라 정보를 반환하는 순위 윈도우 함수(예: CUME_DIST, RANK, DENSE_RANK)를 사용할 수 있습니다. 예를 들어, 월별 수익에 따라 내림차순으로 매장의 순위를 매기면 수익이 가장 높은 매장이 1순위, 두 번째로 수익이 높은 매장이 2순위가 되는 식으로 순위를 매길 수 있습니다.
윈도우 함수에 대한 ORDER BY 절은 쿼리의 최종 결과를 정렬하는 기본 ORDER BY 절과 동일한 구문을 지원합니다. 이 두 ORDER BY 절은 별개의 절입니다. ORDER BY 절 내의 OVER 절은 윈도우 함수가 행을 처리하는 순서만 제어하며, 전체 쿼리의 출력은 제어하지 않습니다. 많은 경우 윈도우 함수 쿼리에는 두 가지 유형의 ORDER BY 절이 모두 포함됩니다.
참고
윈도우 함수에 대한 ORDER BY 절은 :code:`OVER (PARTITION BY 1 ORDER BY 2)`와 같은 순서 위치 사용을 지원하지 않습니다. 이러한 맥락에서, ``2``는 상수 ``2``로 해석되며, 쿼리의 두 번째 열을 참조하지 않습니다.
OVER 절 내의 PARTITION BY 및 ORDER BY 절도 독립적입니다. ORDER BY 절은 PARTITION BY 절 없이도 사용할 수 있고, 그 반대도 마찬가지입니다.
쿼리를 작성하기 전에 개별 윈도우 함수의 구문을 확인합니다. ORDER BY 절의 구문 요구 사항은 함수에 따라 다릅니다.
일부 윈도우 함수에는 ORDER BY 절이 필요합니다.
일부 윈도우 함수에서는 ORDER BY 절이 있으면 사용하지만 필수가 아닙니다.
일부 윈도우 함수는 ORDER BY 절을 허용하지 않습니다.
일부 윈도우 함수는 ORDER BY 절을 암시적 윈도우 프레임으로 해석합니다.
조심
일반적으로 SQL은 암시적 조항이 거의 없는 명시적 언어입니다. 그러나 일부 윈도우 함수의 경우 ORDER BY 절은 윈도우 프레임을 의미합니다. 자세한 내용은 윈도우 프레임 사용법 노트 섹션을 참조하십시오.
명시적이지 않고 암시적인 동작은 이해하기 어려운 결과를 초래할 수 있으므로 명시적으로 윈도우 프레임을 선언하는 것이 좋습니다.
윈도우 프레임은 명시적이거나 암시적으로 정의됩니다. 이는 OVER 절 내에 ORDER BY 절이 있는지 여부에 따라 달라집니다.
명시적인 프레임 구문은 구문 의 windowFrameClause 섹션을 참조하십시오. 개방형 경계를 정의할 수 있습니다. 즉, 파티션 시작부터 현재 행까지, 현재 행부터 파티션 끝까지 또는 완전히 “제한 없는” 경계를 정의할 수 있습니다. 또는 파티션의 현재 행을 기준으로 하는 명시적 오프셋(포함)을 사용할 수 있습니다.
암시적 프레임은 OVER 절에 windowFrameClause 가 포함되지 않은 경우 기본적으로 사용됩니다. 기본 프레임은 해당 함수에 따라 달라집니다. 윈도우 프레임 사용법 노트 도 참조하십시오.
현재 행으로부터의 물리적 오프셋을 기준으로 행의 정확한 순서가 프레임에 속합니다. 예를 들어, 5PRECEDING 은 현재 행 앞에 있는 5개의 행을 의미합니다. 오프셋은 숫자여야 합니다. ROWS 모드가 포함되고 항상 현재 행을 기준으로 합니다. 지정된 앞 또는 뒤 행의 개수가 파티션의 한계를 초과하는 경우 Snowflake는 해당 값을 NULL로 처리합니다.
프레임에 명확하게 번호가 매겨진 경계가 아니라 개방형 경계가 있는 경우에도 비슷한 물리적 오프셋이 적용됩니다. 예를 들어, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW는 프레임이 현재 행과 현재 행 자체에 물리적으로 선행하는 전체 행 세트(0개 이상)로 구성됨을 의미합니다.
범위 기반:
현재 행의 ORDER BY 값에서 오프셋이 주어진 논리적 범위의 행이 프레임에 속합니다. 예를 들어, 5PRECEDING 은 현재 행의 ORDER BY 값에 최대 5를 더하거나 뺀 ORDER BY 값이 있는 행을 의미합니다(DESC 순서의 경우 더하기, ASC 순서의 경우 빼기). 오프셋 값은 숫자나 간격일 수 있습니다.
프레임에 번호가 매겨진 경계가 아닌 개방형 경계가 있는 경우에도 비슷한 논리적 오프셋이 적용됩니다. 예를 들어, RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 는 프레임이 현재 행의 물리적으로 앞에 있는 모든 행, 현재 행 자체 그리고 현재 행과 동일한 ORDER BY 값을 가진 인접 행으로 구성됨을 의미합니다. RANGE 윈도우 프레임의 경우 CURRENT ROW는 물리적으로 현재 행을 의미하는 것이 아니라, 현재 물리적 행과 동일한 ORDER BY 값을 갖는 모든 행을 의미합니다.
윈도우 함수 쿼리는 ORDER BY 식, 테이블의 데이터, 프레임의 정확한 정의에 따라 매우 다른 결과를 반환할 수 있기 때문에 ROWS BETWEEN과 RANGE BETWEEN 윈도우 프레임의 구분은 중요합니다. 다음 예제에서는 동작의 차이점을 보여줍니다.
+-------------------------+--------+-------+-------------+| START_TIME | PRECIP | CITY | COUNTY ||-------------------------+--------+-------+-------------|| 2021-12-30 11:23:00.000 | 0.12 | Lebec | Los Angeles || 2021-12-30 11:43:00.000 | 0.98 | Lebec | Los Angeles || 2021-12-30 13:53:00.000 | 0.23 | Lebec | Los Angeles || 2021-12-30 14:53:00.000 | 0.13 | Lebec | Los Angeles || 2021-12-30 15:15:00.000 | 0.29 | Lebec | Los Angeles || 2021-12-30 17:53:00.000 | 0.10 | Lebec | Los Angeles || 2021-12-30 18:53:00.000 | 0.09 | Lebec | Los Angeles || 2021-12-30 19:53:00.000 | 0.07 | Lebec | Los Angeles || 2021-12-30 20:53:00.000 | 0.07 | Lebec | Los Angeles |+-------------------------+--------+-------+-------------+
쿼리가 start_time 로 정렬된 윈도우 프레임을 사용하여 precip (강수량) 열에 대한 3시간 이동 평균(AVG)을 계산한다고 가정해 보겠습니다.
위의 샘플 행이 주어졌을 때 현재 행이 2021-12-3011:23:00.000 (첫 번째 샘플 행)인 경우 다음 두 행(2021-12-3011:43:00.000 및 2021-12-3013:53:00.000)만 프레임 안에 들어갑니다. 이후 타임스탬프는 3시간 이상 후입니다.
그러나 윈도우 프레임을 1일 간격으로 변경하면 현재 행 뒤에 오는 모든 샘플 행은 모두 같은 날짜(2021-12-30)의 타임스탬프가 있기 때문에 프레임 내부에 포함됩니다.
RANGEBETWEENCURRENTROWANDINTERVAL'1 day'FOLLOWING
이 구문을 RANGE BETWEEN에서 ROWS BETWEEN으로 변경하려면 프레임에 고정 경계를 지정해야 하는데, 고정 경계는 현재 행에 1, 3 또는 10 행과 같이 ORDER BY 식에서 반환되는 값에 관계없이 정확히 정렬된 행의 수(예: 현재 행과 다음의 정확한 행 수)를 나타내는 것입니다.
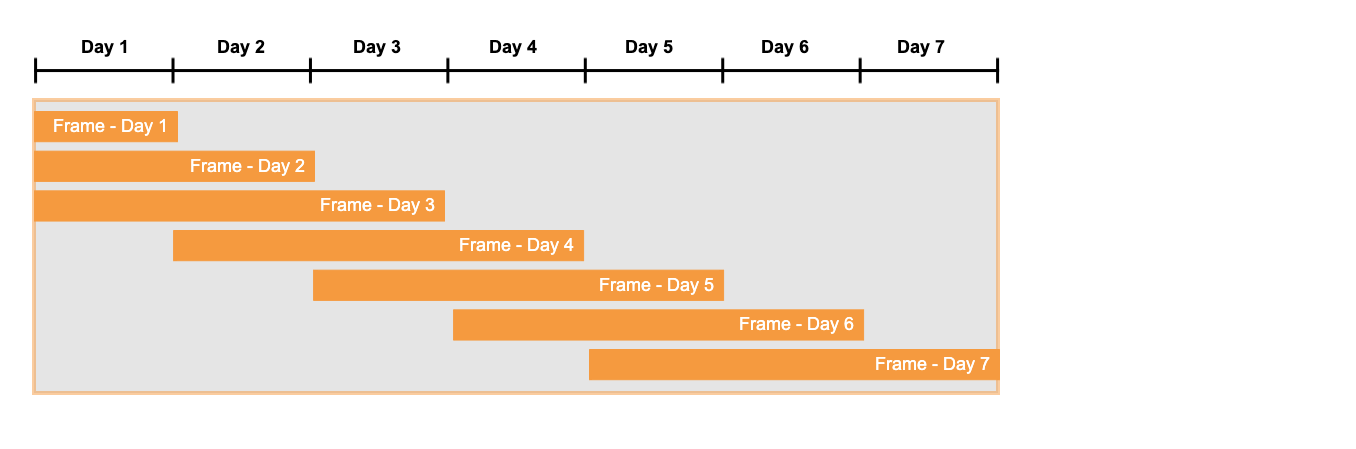
슬라이딩 윈도우 프레임은 파티션의 행을 따라 “밀어가며” 움직이는 고정 너비의 프레임으로, 매번 파티션의 다른 부분을 덮습니다. 프레임의 행 수는 파티션의 시작 또는 끝 부분을 제외하고는 동일하게 유지되며, 이 부분에서는 행 수가 줄어들 수 있습니다.
슬라이딩 윈도우는 종종 이동 평균을 계산하는 데 사용되는데, 이동 평균은 고정된 크기 간격(예: 일 수)을 기반으로 합니다. 간격의 크기가 일정하지만, 시간이 지나면서(또는 다른 차원에 따라) 간격의 실제 값이 변합니다.
예를 들어, 주식 시장 애널리스트는 주가의 13주 이동 평균 중 일부를 기준으로 주가를 분석합니다. 오늘의 이동 평균 가격은 오늘 장 마감 시간의 주가와 최근 13주 동안 각 날짜 마감 시간 주가의 평균입니다. 주 5일 주식을 거래하고 최근 13주 동안 공휴일이 없는 경우, 이동 평균은 최근 65 거래일(오늘 포함)의 평균 주가입니다.
다음 예제는 6월 말일 및 7월 초 며칠 동안 주가의 13주(91일) 이동 평균을 보여줍니다.
6월 30일에 함수는 4월 1일에서 6월 30일(포함)까지의 평균 주가를 반환합니다.
7월 1일에 함수는 4월 2일에서 7월 1일(각 날짜 포함)까지의 평균 가격을 반환합니다.
7월 2일에 함수는 4월 3일에서 7월 2일(각 날짜 포함)까지의 평균 가격을 반환합니다.
다음 예에서는 해당 월의 첫 7일 동안 작은(3일) 슬라이딩 윈도우를 사용합니다. 이 예제에서는 기간의 시작 시 파티션이 가득 차지 않았을 수 있다는 사실을 고려합니다.
쿼리 결과의 해당 모형에서 볼 수 있듯이 마지막 열에는 가장 최근 3일간의 판매 데이터 합계가 포함되어 있습니다. 예를 들어, 4일차에 해당하는 열의 값은 36 이며, 이는 2, 3, 4일차 매출의 합계(11+12+13)입니다.
순위를 지정하려면 먼저 행을 정렬해야 합니다. 따라서 OVER 절 내에 ORDER BY 절을 사용해야 합니다.
다음 예제를 생각해 보십시오. 다음 예제에서는 매장 순위 1, 2, 3 등과 같이 매장 체인의 지점 중 매장 수익 순위를 확인합니다. 이 예제에서는 도시 내 각 매장의 수익성을 기준으로 순위를 매겼습니다. 행은 내림차순 순서(최고 수익 먼저)로 배치되므로 가장 수익이 높은 매장의 순위가 1입니다.
SELECTcity,branch_ID,net_profit,RANK()OVER(PARTITIONBYcityORDERBYnet_profitDESC)ASrankFROMstore_salesORDERBYcity,rank;+-----------+-----------+------------+------+| CITY | BRANCH_ID | NET_PROFIT | RANK ||-----------+-----------+------------+------|| Montreal | 3 | 10000.00 | 1 || Montreal | 4 | 9000.00 | 2 || Vancouver | 2 | 15000.00 | 1 || Vancouver | 1 | 10000.00 | 2 |+-----------+-----------+------------+------+
참고
net_profit 열은 RANK 함수에 인자로 전달할 필요가 없습니다. 대신, 입력 행은 net_profit 을 기준으로 정렬됩니다. RANK 함수는 파티션 내에서 행의 위치(1, 2, 3 등)만 반환해야 합니다.
순위 함수의 출력은 다음에 따라 달라집니다.
함수로 전달된 개별 행.
파티션에 있는 다른 행의 값.
파티션에서 모든 행의 순서.
Snowflake는 다양한 순위 함수를 제공합니다. 이러한 함수의 목록과 구문에 대한 자세한 내용은 윈도우 함수 섹션을 참조하십시오.
도시 내의 다른 매장뿐만 아니라 체인 내 다른 모든 매장과 비교하여 매장의 순위를 매기려면 아래 쿼리를 사용합니다.
그러나 이 예에서는 테이블에 가장 최근 주에 해당하는 데이터만 포함된 것으로 가정하겠습니다.
CREATETABLEstore_sales_2(dayINTEGER,sales_todayINTEGER);+-------------------------------------------+| status ||-------------------------------------------|| Table STORE_SALES_2 successfully created. |+-------------------------------------------+INSERTINTOstore_sales_2(day,sales_today)VALUES(1,10),(2,14),(3,6),(4,6),(5,14),(6,16),(7,18);+-------------------------+| number of rows inserted ||-------------------------|| 7 |+-------------------------+
예를 들어, X축은 시간이고 Y축은 지난 13주 동안의 주식 평균 가격(즉, 13주 이동 평균)을 표시하는 그래프가 있을 수 있습니다. 13주 평균 주가 그래프에서, 6월 30일에 표시된 주가는 6월 30일의 평균 주가가 아니라, 6월 30일을 포함하여 13주 동안의 평균 주가(즉, 4월 1일부터 6월 30일까지)입니다. 7월 1일의 값은 4월 2일부터 7월 1일까지의 평균 주가이고, 7월 2일의 값은 4월 3일부터 7월 2일까지의 평균 주가이며 이외의 날짜도 마찬가지입니다. 매일 윈도우는 가장 최근 날짜의 값을 이동 평균에 추가하고 가장 오래된 날짜의 값을 제거합니다. 이를 통해 일일 변동이 완화되고 추세를 보다 쉽게 이해할 수 있습니다.
이동 평균은 슬라이딩 윈도우 프레임을 사용하여 계산할 수 있습니다. 프레임의 행은 특정 너비를 갖습니다. 위의 주가 예에서 13주는 91일이므로 슬라이딩 윈도우는 91일이 됩니다. 하루에 1회(예: 장마감 시간) 측정하는 경우, 윈도우는 91개 행 “너비”가 됩니다.
쿼리 결과에는 SLIDING_SUM_QUANTITY 열의 계산 방법을 보여주는 추가 설명이 포함됩니다.
+-----------+----------+----------------------+| MONTH_NUM | QUANTITY | SLIDING_SUM_QUANTITY ||-----------+----------+----------------------+|1|1|1|-- sum = 1|1|3|4|-- sum = 1 + 3|1|5|8|-- sum = 3 + 5 (1 is no longer in the window)|2|2|7|-- sum = 5 + 2 (3 is no longer in the window)+-----------+----------+----------------------+
“슬라이딩 윈도우” 기능은 윈도우 프레임에 들어오고 나가는 행의 순서에 따라 함수가 달라지므로 ORDER BY 절이 필요합니다.