패턴과 일치하는 행의 시퀀스 찾기¶
소개¶
일부 경우 패턴과 일치하는 테이블 행의 시퀀스를 찾아야 할 수 있습니다. 예를 들어, 다음을 수행해야 할 수 있습니다.
지원 티켓을 등록하거나 구매하기 전에 웹사이트에서 일련의 페이지 및 작업을 거친 사용자를 판단합니다.
일정 기간 동안 V자형 또는 W자형으로 가격이 회복된 재고를 찾습니다.
센서 데이터에서 곧 발생할 시스템 장애를 나타낼 수 있는 패턴이 있는지 찾아봅니다.
특정 패턴과 일치하는 행의 시퀀스를 찾아보려면 FROM 절의 MATCH_RECOGNIZE 하위 절을 사용합니다.
참고
재귀 공통 테이블 식(CTE) 에서는 MATCH_RECOGNIZE 절을 사용할 수 없습니다.
행의 시퀀스를 찾는 간단한 예¶
예를 들어, 주가에 대한 데이터가 포함된 테이블을 가정해 보겠습니다. 각 행에는 특정 날짜에 각 상장 코드에 대한 종가가 포함됩니다. 테이블에 포함되는 열은 다음과 같습니다.
열 이름 |
설명 |
|---|---|
|
종가의 날짜입니다. |
|
해당 날짜의 주식 종가입니다. |
주가가 하락한 후 상승하여 주가 그래프에서 “V”자를 만드는 패턴을 감지하려는 경우를 가정해 보겠습니다.
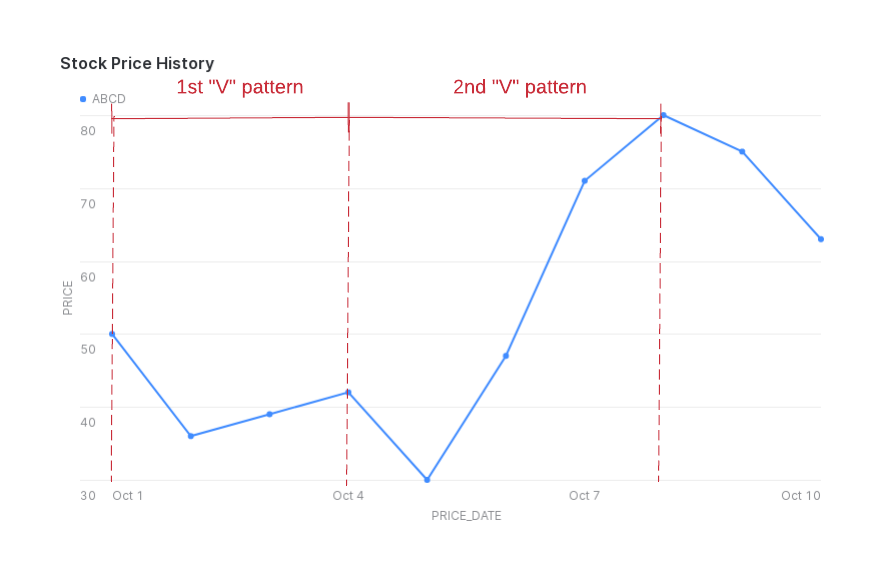
(이 예에서는 주가가 수시로 변동하는 경우를 설명하지 않습니다.)
이 예에서는 해당 상장 코드에서 price 열의 값이 감소한 후 증가하는 행의 시퀀스를 찾아보려고 합니다.
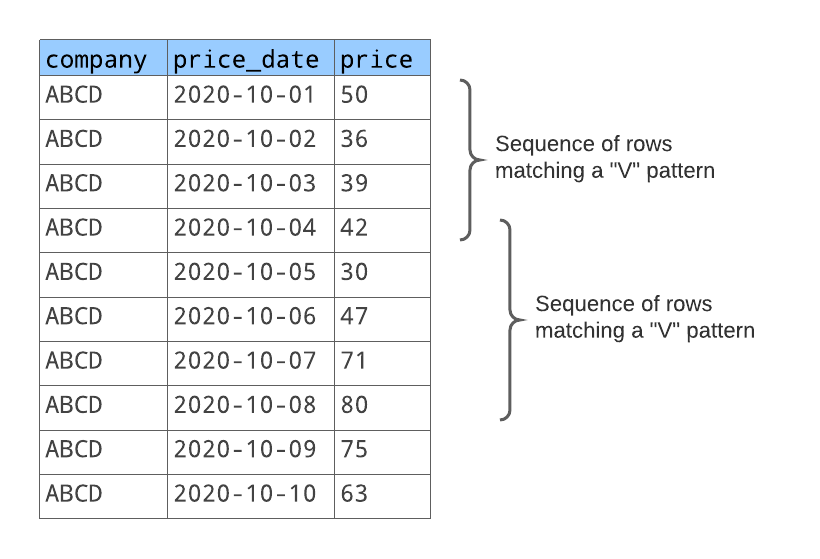
이 패턴과 일치하는 행의 각 시퀀스에 대하여 반환하려고 하는 사항은 다음과 같습니다.
시퀀스(첫 번째 일치 시퀀스, 두 번째 일치 시퀀스 등)를 식별하는 숫자.
주가 하락 전일.
마지막 주가 상승일.
“V”자 패턴의 일 수.
주가 하락 일 수.
주가 상승 일 수.
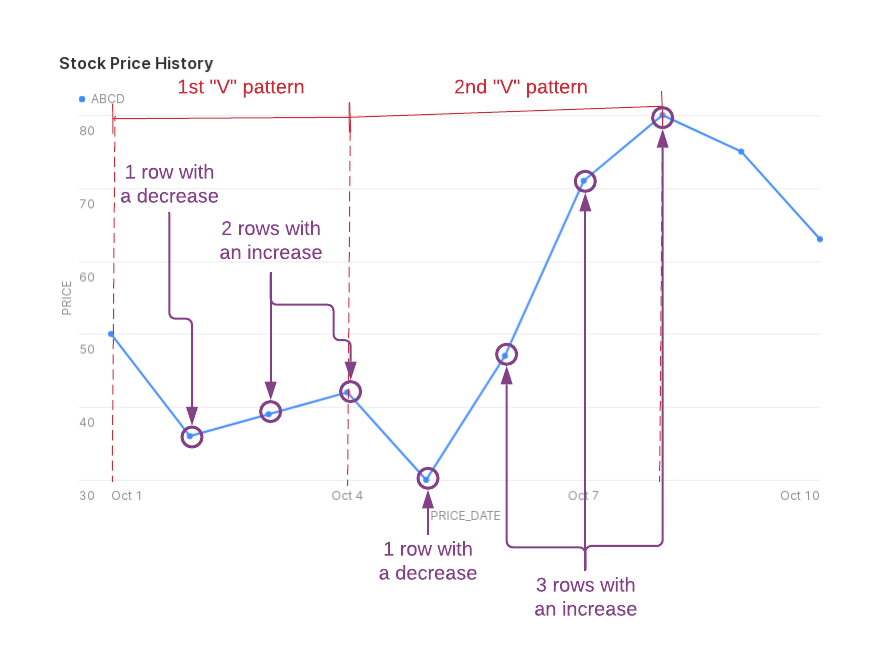
다음 그림은 반환 데이터에서 수집하는 “V”자 패턴 내에서의 주가 하락(NUM_DECREASES) 및 상승(NUM_INCREASES)을 보여줍니다. ROWS_IN_SEQUENCE 에는 NUM_DECREASES 또는 NUM_INCREASES 에서 포함되지 않은 초기 행이 포함되었음에 유의하십시오.
이러한 결과를 생성하기 위해서는 아래에 표시된 MATCH_RECOGNIZE 절을 사용할 수 있습니다.
위에서와 같이, MATCH_RECOGNIZE 절은 여러 하위 절로 구성되며, 각 하위 절은 다른 목적(예: 일치하는 패턴 지정, 반환할 데이터 지정 등)을 수행합니다.
다음 섹션에서는 이 예에서 제공되는 각 하위 절에 대해 설명합니다.
이 예를 위한 데이터 설정하기¶
이 예에서 사용되는 데이터를 설정하기 위해 실행해야 하는 SQL 문은 다음과 같습니다.
1단계: 순서 지정 및 행 그룹화하기¶
행의 시퀀스를 식별하기 위한 첫 번째 단계는 검색할 행을 그룹화 및 정렬 순서를 정의하는 것입니다. 회사 주가에서 “V”자 패턴을 찾는 예에서:
해당 회사의 주가 패턴을 검색할 것이므로 행은 회사를 기준으로 그룹화되어야 합니다.
행의 각 그룹(해당 회사의 주가) 내에서 행은 날짜를 기준으로 오름차순으로 정렬되어야 합니다.
MATCH_RECOGNIZE 절에서는 PARTITION BY 및 ORDER BY 하위 절을 사용하여 행의 그룹화 및 순서를 지정할 수 있습니다. 예:
2단계: 일치 패턴 정의하기¶
다음으로 검색할 행의 시퀀스와 일치하는 패턴을 결정합니다.
이 패턴을 지정하려면 정규식 과 유사한 식이 필요합니다. 정규식에서는 리터럴 및 메타 문자의 조합을 사용하여 문자열에서 일치 패턴을 지정합니다.
예를 들어, 다음이 포함된 문자 시퀀스를 찾으려면:
임의의 문자 1개, 다음에
대문자 1개 이상, 다음에
소문자 1개 이상
사용할 수 있는 Perl 호환 정규식:
여기서,
.는 임의의 문자 1개와 일치합니다.[A-Z]+는 1개 이상의 대문자와 일치합니다.[a-z]+는 1개 이상의 소문자와 일치합니다.
+ 는 1개 이상의 선행 문자와 일치해야 함을 지정하는 수량자 입니다.
예를 들어, 위의 정규식은 다음과 같은 문자 시퀀스와 일치합니다.
1Stock@SFComputing%Fn
MATCH_RECOGNIZE 절에서는 유사한 식을 사용하여 일치시킬 행의 패턴을 지정할 수 있습니다. 이 경우 “V”자 패턴과 일치하는 행을 찾기 위해서는 다음이 포함된 행의 시퀀스를 찾아야 합니다.
주가 하락 전 행, 다음에
주가가 하락하는 1개 이상의 행, 다음에
주가가 상승하는 1개 이상의 행
이는 다음과 같은 행 패턴으로 표현할 수 있습니다.
행 패턴은 패턴 변수, 수량자 (정규식에서 사용되는 수량자와 유사) 및 연산자 로 구성됩니다. 패턴 변수는 행에 대하여 평가되는 식을 정의합니다.
이 행 패턴에서:
row_before_decrease,row_with_price_decrease및row_with_price_increase은 패턴 변수입니다. 이러한 패턴 변수를 위한 식에서 평가해야 하는 사항:모든 행(주가 감소 전 행)
주가가 감소하는 행
주가가 상승하는 행
정규식에서
row_before_decrease은.와 유사합니다. 다음 정규식에서.는 패턴에서 첫 번째 대문자 앞에 오는 문자 1개와 일치합니다.유사하게 행 패턴에서
row_before_decrease은 주가가 감소하는 첫 번째 행 앞에 오는 행 1개와 일치합니다.row_with_price_decrease및row_with_price_increase뒤의+수량자는 이러한 1개 이상의 각 행이 일치해야 함을 지정합니다.
MATCH_RECOGNIZE 절에서는 PATTERN 하위 절을 사용하여 일치시킬 행의 패턴을 지정합니다.
패턴 변수를 위한 식을 지정하려면 DEFINE 하위 절을 사용합니다.
여기서,
모든 행을 평가해야 하므로 여기에서는
row_before_decrease을 정의할 필요가 없습니다.row_with_price_decrease은 주가가 하락하는 행에 대한 식으로 정의됩니다.row_with_price_increase은 주가가 상승하는 행에 대한 식으로 정의됩니다.
다른 행의 주가를 비교하기 위해 이러한 변수의 정의에서는 탐색 함수 LAG() 를 사용하여 이전 행의 주가를 지정합니다.
행 패턴은 아래와 같이 행 2개의 시퀀스와 일치합니다.

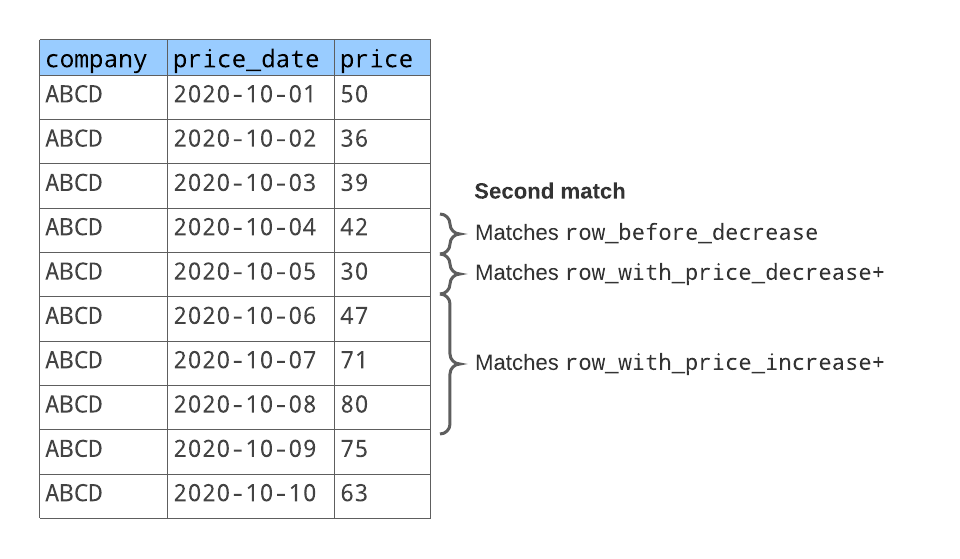
첫 번째로 일치하는 행 시퀀스의 경우:
row_before_decrease은 주가가50인 행과 일치합니다.row_with_price_decrease은 주가가36인 다음 행과 일치합니다.row_with_price_increase은 주가가39및42인 다음 2개 행과 일치합니다.
두 번째로 일치하는 행 시퀀스의 경우:
row_before_decrease은 주가가42인 행과 일치합니다. (이 행은 첫 번째로 일치하는 행 시퀀스의 마지막에 오는 동일한 행입니다.)row_with_price_decrease은 주가가30인 다음 행과 일치합니다.row_with_price_increase은 주가가47,71및80인 다음 2개 행과 일치합니다.
3단계: 반환할 행 지정하기¶
MATCH_RECOGNIZE 에서 반환될 수 있는 항목:
각 일치 시퀀스를 요약하는 단일 행 또는
각 일치 시퀀스의 각 행
이 예에서는 각 일치 시퀀스의 요약을 반환해 보겠습니다. ONE ROW PER MATCH 하위 절을 사용하여 일치하는 각 시퀀스에 대해 1개의 행이 반환되어야 함을 지정합니다.
4단계: 선택할 측정값 지정하기¶
ONE ROW PER MATCH 를 사용할 때 MATCH_RECOGNIZE 는 테이블에 있는 열을 반환하지 않으며(PARTITION BY 에 의해 지정된 열 제외), 이는 MATCH_RECOGNIZE 가 SELECT * 문에 있는 경우에도 마찬가지입니다. 이 문에 의해 반환될 데이터를 지정하려면 측정값 을 정의해야 합니다. 측정값은 일치하는 각 행의 시퀀스에 대하여 계산되는 데이터(예: 시퀀스 시작일, 시퀀스 종료일, 시퀀스 내의 일 수 등)의 추가 열입니다.
MEASURES 하위 절을 사용하여 출력에서 반환할 이러한 추가 열을 지정합니다. 측정값을 정의하기 위한 일반 형식은 다음과 같습니다.
여기서,
expression은 반환할 시퀀스에 대한 정보를 지정합니다. 이 식의 경우 이전에 정의한 테이블의 열 및 패턴 변수가 포함된 함수를 사용할 수 있습니다.column_name은 출력에서 반환될 열의 이름을 지정합니다.
이 예에서 정의할 수 있는 측정값은 다음과 같습니다.
시퀀스(첫 번째 일치 시퀀스, 두 번째 일치 시퀀스 등)를 식별하는 숫자.
이 측정값에서는
MATCH_NUMBER()함수를 사용하며 일치 개수가 반환됩니다. 번호는 행 파티션 의 첫 번째 일치 항목에 대해1부터 시작합니다. 파티션이 여러 개인 경우 번호는 각 파티션에 대해1부터 시작합니다.주가 하락 전일.
이 측정값에서는
FIRST()함수를 사용하며, 일치 시퀀스에서 첫 번째 행에 대한 식의 값이 반환됩니다. 이 예에서FIRST(price_date)는 일치하는 각 시퀀스의 첫 행에서price_date열의 값을 반환하며, 이는 주가가 하락한 이전 날짜입니다.마지막 주가 상승일.
이 측정값에서는
LAST()함수를 사용하며, 일치 시퀀스에서 마지막 행에 대한 식의 값이 반환됩니다.“V”자 패턴의 일 수.
이 측정값에서는
COUNT(*)를 사용합니다. 측정값의 정의에COUNT(*)를 지정하고 있으므로 별표(*)는 일치하는 시퀀스의 모든 행(테이블의 모든 행 아님)을 계산하도록 지정합니다.주가가 하락한 일 수입니다.
이 측정값에서는
COUNT(row_with_price_decrease.*)를 사용합니다. 별표(.*) 뒤에 오는 마침표는row_with_price_decrease패턴 변수와 일치하는 일치 시퀀스에서 모든 행을 계산하도록 지정합니다.주가가 상승한 일 수입니다.
이 측정값에서는
COUNT(row_with_price_increase.*)를 사용합니다.
위의 측정값을 정의하는 MEASURES 하위 절은 다음과 같습니다.
다음은 선택한 측정값이 포함된 출력의 예를 보여줍니다.
앞서 설명한 바와 같이, PARTITION BY 절이 해당 열을 지정하므로 출력에는 company 열이 포함됩니다.
5단계: 다음 일치를 찾을 위치 지정하기¶
행의 일치하는 시퀀스를 찾은 후 MATCH_RECOGNIZE 는 계속해서 다음으로 일치하는 시퀀스를 찾습니다. 사용자는 MATCH_RECOGNIZE 가 다음으로 일치하는 시퀀스의 검색을 시작할 위치를 지정할 수 있습니다.
일치하는 시퀀스 설명 에서와 같이, 행은 2개 이상 일치하는 시퀀스의 일부일 수 있습니다. 이 예에서 2020-10-04 행은 2개 “V”자 패턴의 일부입니다.
이 예에서 다음으로 일치하는 시퀀스를 찾기 위해서는 주가가 상승하는 행에서부터 시작할 수 있습니다. MATCH_RECOGNIZE 절에 이를 지정하려면 AFTER MATCH SKIP 을 사용합니다.
여기서 TO LAST row_with_price_increase 는 주가가 상승한 마지막 행 에서 검색을 시작하도록 지정합니다.
행 분할 및 정렬하기¶
행 전체에서 패턴을 식별하기 위한 첫 번째 단계는 패턴을 찾을 수 있는 순서로 행을 배치하는 것입니다. 예를 들어, 시간 경과에 따른 각 회사의 주가 변동 패턴을 찾으려면:
회사를 기준으로 행을 분할합니다. 그러면 각 회사의 주가를 검색할 수 있습니다.
각 파티션의 행을 날짜별로 정렬합니다. 그러면 시간 경과에 따른 회사 주가의 변동 사항을 찾을 수 있습니다.
데이터를 분할하고 행의 순서를 지정하려면, MATCH_RECOGNIZE 에서 PARTITION BY 및 ORDER BY 하위 절을 사용합니다. 예:
(MATCH_RECOGNIZE 를 위한 PARTITION BY 절은 윈도우 함수 를 위한 PARTITION BY 절과 동일한 방식으로 작동합니다.)
분할의 추가적인 이점은 병렬 처리를 이용할 수 있다는 것입니다.
일치하는 행의 패턴 정의하기¶
MATCH_RECOGNIZE 를 사용하면 패턴과 일치하는 행의 시퀀스를 찾을 수 있습니다. 이 패턴은 특정 조건과 일치하는 행과 관련하여 지정합니다.
여러 회사의 일일 주가 테이블 예에서 다음과 같은 3개 행 시퀀스를 찾는 경우를 가정해 보겠습니다.
지정된 날짜에 회사의 주가가 45.00보다 작습니다.
다음 날짜에 주가가 10% 이상 하락합니다.
그 다음 날짜에 주가가 3% 이상 상승합니다.
이러한 시퀀스를 찾으려면 조건이 다음과 같은 3개 행과 일치하는 패턴을 지정합니다.
시퀀스의 첫 번째 행에서
price열의 값이 45.00보다 작아야 합니다.두 번째 행에서
price열의 값이 이전 행의 값보다 90% 이하여야 합니다.세 번째 행에서
price열의 값이 이전 행의 값보다 105% 이상이어야 합니다.
두 번째 및 세 번째 행에는 다른 행의 열 값을 비교해야 하는 조건이 있습니다. 한 행의 값과 이전 또는 다음 행의 값을 비교하려면, LAG() 또는 LEAD() 함수를 사용합니다.
LAG(column)는 이전 행의column값을 반환합니다.LEAD(column)는 다음 행의column값을 반환합니다.
이러한 예를 위해 3개 행에 대한 조건을 다음과 같이 지정할 수 있습니다.
시퀀스에서 첫 번째 행은
price < 45.00여야 합니다.두 번째 행은
LAG(price) * 0.90 >= price여야 합니다.세 번째 행은
LAG(price) * 1.05 <= price여야 합니다.
이러한 3개 행 시퀀스에 대한 패턴을 지정하는 경우에는 조건이 다른 각 행에 대한 패턴 변수를 사용합니다. DEFINE 하위 절을 사용하여 각 패턴 변수를 지정된 조건을 충족해야 하는 행으로 정의합니다. 다음 예에서는 3개 행에 대하여 3개의 패턴 변수를 정의합니다.
패턴 자체를 정의하려면 PATTERN 하위 절을 사용합니다. 이 하위 절에서는 정규식을 사용하여 일치 패턴을 지정합니다. 식의 구성 요소로는 정의한 패턴 변수를 사용합니다. 예를 들어, 3개 행 시퀀스를 찾는 패턴은 다음과 같습니다.
아래 SQL 문에서는 위의 DEFINE 및 PATTERN 하위 절을 사용합니다.
다음 섹션에서는 특정 개수의 행 및 파티션의 시작 또는 마지막에 표시되는 행과 일치하는 패턴을 정의하는 방법에 대해 설명합니다.
참고
MATCH_RECOGNIZE는 역추적 을 사용하여 패턴을 일치시킵니다. 역추적을 사용하는 다른 정규식 엔진 의 경우와 마찬가지로, 일치시킬 패턴과 데이터의 일부 조합을 실행하는 데 시간이 오래 걸릴 수 있으므로 높은 계산 비용이 발생할 수 있습니다.
성능을 향상하려면 패턴을 다음과 같이 최대한 구체적으로 정의하십시오.
각 행은 기호 1개 또는 적은 수의 기호와만 일치해야 합니다.
모든 행과 일치하는 기호를 사용하지 마십시오(예:
DEFINE절에 없는 기호 또는 true로 정의된 기호).수량자의 상한을 정의하십시오(예:
{,10}대신*).
예를 들어, 다음 패턴은 일치하는 행이 없으면 비용이 증가할 수 있습니다.
일치시키려는 행 수에 상한이 있는 경우, 수량자에 해당 제한을 지정하여 성능을 향상시킬 수 있습니다. 또한, symbol1 다음에 오는 any_symbol 을 찾도록 지정하는 대신, symbol1 이 아닌 행(이 예에서는 not_symbol1)을 찾을 수 있습니다.
일반적으로, 쿼리 실행 시간을 모니터링하여 쿼리가 예상보다 오래 걸리지 않는지 확인하는 것이 좋습니다.
패턴 변수가 포함된 수량자 사용하기¶
PATTERN 하위 절에서는 정규식을 사용하여 일치시킬 행의 패턴을 지정할 수 있습니다. 패턴 변수를 사용하여 특정 조건을 충족하는 시퀀스의 행을 식별합니다.
특정 조건을 충족하는 여러 행과 일치해야 하는 경우에는 정규식 에서와 같이 수량자 를 사용할 수 있습니다.
예를 들어, + 수량자를 사용하여 주가가 10% 하락하는 1개 이상의 행 이후에 주가가 5% 상승하는 1개 이상의 행이 포함되는 패턴을 지정할 수 있습니다.
파티션의 시작 또는 마지막과 관련된 일치 패턴¶
파티션의 시작 또는 마지막과 관련된 행의 시퀀스를 찾으려면 PATTERN 하위 절에 ^ 및 $ 메타 문자를 사용할 수 있습니다. 행 패턴에서 이러한 메타 문자는 정규식에서의 동일한 메타 문자 와 목적이 유사합니다.
^는 파티션의 시작을 나타냅니다.$는 파티션의 마지막을 나타냅니다.
다음 패턴은 파티션 시작 시 주가가 75.00보다 높은 주식과 일치합니다.
^ 및 $ 는 위치를 지정하며 해당 위치의 행을 나타내는 것이 아님에 유의하십시오(매우 유사하게 정규식의 ^ 및 $ 도 위치를 지정하며 해당 위치의 문자를 지정하지 않음). PATTERN (^ GT75) 에서 첫 번째 행(두 번째 행이 아닌)의 주가는 75.00보다 커야 합니다. PATTERN (GT75 $) 에서 마지막 행(두 번째부터 마지막행까지 아님)은 75보다 커야 합니다.
^ 를 사용한 전체 예는 다음과 같습니다. 이 파티션의 2개 이상 행에서 XYZ 주식의 주가가 60.00보다 높더라도, 파티션 시작 행만 일치하는 것으로 간주됨에 유의하십시오.
$ 를 사용한 전체 예는 다음과 같습니다. 이 파티션의 2개 이상 행에서 ABCD 주식의 주가가 50.00보다 높더라도, 파티션 마지막 행만 일치하는 것으로 간주됨에 유의하십시오.
출력 행 지정하기¶
MATCH_RECOGNIZE 를 사용하는 문으로 출력할 행을 선택할 수 있습니다.
각 일치에 대해 행 1개 생성하기 vs 각 일치에 대해 모든 행 생성하기¶
MATCH_RECOGNIZE 에서 일치가 발견되면 전체 일치에 해당 요약 행 1개 또는 패턴에서 각 데이터 요소에 대한 행 1개를 출력할 수 있습니다.
ALL ROWS PER MATCH를 사용하면 일치하는 모든 행을 출력에 포함하도록 지정합니다.ONE ROW PER MATCH를 사용하면 각 파티션에서 각 일치에 대한 행 1개만 출력에 포함하도록 지정합니다.SELECT 절의 프로젝션 절에서는
MATCH_RECOGNIZE의 출력만 사용할 수 있습니다. 이는 사실상 SELECT 문에서MATCH_RECOGNIZE의 다음 하위 절에 있는 열만 사용할 수 있음을 의미합니다.PARTITION BY하위 절.일치 항목의 모든 행은 동일한 파티션에서 제공되므로
PARTITION BY하위 절 식에 대한 값이 동일합니다.MEASURES절.MATCH_RECOGNIZE ... ONE ROW PER MATCH를 사용하는 경우MEASURES하위 절은 일치의 모든 행에 대한 동일한 값(예:MATCH_NUMBER())을 반환하는 식뿐만 아니라 일치에서 다른 행에 대한 다른 값(예:MATCH_SEQUENCE_NUMBER())을 반환하는 식도 생성합니다. 일치에서 다른 행에 대한 다른 값을 반환할 수 있는 식을 사용하는 경우에는 출력이 명확하지 않습니다.
집계 함수 및
GROUP BY에 익숙한 경우에는 다음의 비유가ONE ROW PER MATCH를 이해하는 데 유용할 수 있습니다.MATCH_RECOGNIZE의GROUP BY절은SELECT가PARTITION BY의 데이터를 그룹화하는 방법과 유사한 방식으로 데이터를 그룹화합니다.MATCH_RECOGNIZE ... ONE ROW PER MATCH의MEASURES절에서는COUNT()와 같은 집계 함수를 사용할 수 있으며, 이를 통해MATCH_NUMBER()에서와 같이 일치에서 각 행에 대한 동일한 값을 반환합니다.
일치에서 각 행에 대한 동일한 값을 반환하는 집계 함수 및 식만 사용하는 경우
... ONE ROW PER MATCH는GROUP BY및 집계 함수와 유사하게 동작합니다.
기본값은 ONE ROW PER MATCH 입니다.
다음 예는 ONE ROW PER MATCH 와 ALL ROWS PER MATCH 의 출력 차이를 보여줍니다. 이러한 두 코드 예시는 ...ROW(S) PER MATCH 절을 제외하고 거의 동일합니다. (일반적인 사용에서 ONE ROW PER MATCH 가 포함된 SQL 문은 ALL ROWS PER MATCH 가 포함된 SQL 문과 MEASURES 하위 절이 다릅니다.)
출력에서 행 제외하기¶
일부 쿼리의 경우 패턴의 일부만을 출력에 포함할 수 있습니다. 예를 들어, 며칠 동안 연속으로 주가가 상승한 패턴을 찾은 후 최고가 및 일부 요약 정보(예: 각 최고가 이전에 주가가 상승한 일 수)만 표시할 수 있습니다.
패턴에서 제외 구문 을 사용하여 MATCH_RECOGNIZE 에 특정 패턴 변수를 검색하지만 출력에는 포함하지 않도록 지시할 수 있습니다. 검색할 패턴의 일부로 패턴 변수를 포함하지만 출력의 일부로는 포함하지 않으려면 {- <패턴_변수> -} 표기법을 사용합니다.
제외 구문을 사용할 때와 사용하지 않을 때의 차이를 보여주는 간단한 예는 다음과 같습니다. 이 예에는 쿼리 2개가 포함되어 있으며, 각 쿼리는 $45 미만에서 시작하여 하락한 후 상승하는 주가를 검색합니다. 첫 번째 쿼리에서는 제외 구문을 사용하지 않으므로 모든 행이 표시됩니다. 두 번째 쿼리에서는 제외 구문을 사용하며 주가가 하락하는 날짜가 표시되지 않습니다.
다음 예는 보다 현실적입니다. 이 예에서는 주가가 1일 이상 동안 연속으로 상승한 후 1일 이상 동안 연속으로 하락하는 패턴을 검색합니다. 출력이 상당히 클 수 있으므로, 이 예에서는 제외를 사용하여 첫 번째 주가 상승일(2일 이상 연속 상승 시) 및 첫 번째 주가 하락일(2일 이상 연속 하락 시)만 표시합니다. 이러한 패턴은 아래와 같습니다.
이 패턴에서는 다음 이벤트를 순서대로 검색합니다.
45 미만의 시작 주가.
UP, 출력에 포함되지 않은 다른 항목이 바로 뒤에 올 수 있음.
DOWN, 출력에 포함되지 않은 다른 항목이 바로 뒤에 올 수 있음.
앞서 설명한 패턴의 제외가 포함되지 않은 버전과 제외가 포함된 버전의 코드 및 출력은 다음과 같습니다.
일치에 대한 정보 반환하기¶
기본 일치 정보¶
데이터가 포함된 테이블의 정보뿐만 아니라 발견된 패턴에 대한 정보도 쿼리에서 표시하기를 원하는 경우가 많습니다. 일치에 대한 정보 자체를 표시하려면 MEASURES 절에 해당 정보를 지정합니다.
MEASURES 절에는 MATCH_RECOGNIZE 와 관련된 다음 함수를 포함할 수 있습니다.
MATCH_NUMBER(): 일치가 발견될 때마다 1부터 시작하는 순차적인 일치 번호를 할당합니다. 이 함수에서는 해당하는 일치 번호가 반환됩니다.MATCH_SEQUENCE_NUMBER(): 일반적으로 패턴에는 2개 이상의 데이터 요소가 포함되므로, 테이블의 각 값과 연결된 데이터 요소를 확인하고자 할 수 있습니다. 이 함수에서는 일치 내에서 해당 데이터 요소의 순차적 번호를 반환합니다.CLASSIFIER(): 분류자는 행과 일치하는 패턴 변수의 이름입니다.
아래 쿼리에서는 일치 번호, 일치 시퀀스 번호 및 분류자와 함께 MEASURES 절이 포함됩니다.
MEASURES 하위 절에서는 보다 자세한 정보를 제공할 수 있습니다. 자세한 내용은 MATCH_RECOGNIZE 참조 설명서 를 참조하십시오.
윈도우, 윈도우 프레임 및 탐색 기능¶
MATCH_RECOGNIZE 절은 행의 “윈도우”에서 동작합니다. MATCH_RECOGNIZE 에 PARTITION 하위 절이 포함된 경우 각 파티션 은 1개의 윈도우입니다. PARTITION 하위 절이 없는 경우에는 전체 입력이 1개 윈도우입니다.
MATCH_RECOGNIZE 의 PATTERN 하위 절은 왼쪽에서 오른쪽의 순서로 기호를 지정합니다. 예:
왼쪽에서 오른쪽으로 행의 시퀀스에 따라 오름차순으로 데이터를 배열된 경우 MATCH_RECOGNIZE 가 오른쪽으로 이동(예: 주가의 예에서 가장 빠른 날짜에서 가장 최근 날짜로)하여 각 윈도우 내의 행에서 패턴을 검색하는 것으로 생각할 수 있습니다.
MATCH_RECOGNIZE 는 윈도우의 첫 번째 행에서 시작하며 해당 행 및 이후 행이 패턴과 일치하는지 확인합니다.
가장 간단한 사례에서 윈도우의 첫 번째 행부터 패턴이 일치함을 판단한 후 MATCH_RECOGNIZE 는 오른쪽으로 행 1개를 이동하고 이러한 프로세스를 반복하여 두 번째 행에서 패턴이 시작되는지 확인합니다. MATCH_RECOGNIZE 는 윈도우의 마지막에 도달할 때까지 오른쪽으로 계속해서 이동합니다.
(MATCH_RECOGNIZE 는 오른쪽으로 2개 행 이상 이동할 수 있습니다. 예를 들어, MATCH_RECOGNIZE 에 현재 패턴을 종료한 후 다음 패턴 검색을 시작하도록 지시할 수 있습니다.)
이를 대략적으로 생각하면 윈도우 내부에서 오른쪽으로 이동하는 “프레임”이 있는 것과 같습니다. 이러한 프레임의 왼쪽 모서리는 현재 일치를 확인 중인 행 세트의 첫 번째 행에 위치합니다. 프레임의 오른쪽 행은 일치를 찾을 때까지 정의되지 않으며, 일치가 발견되면 프레임의 오른쪽 모서리가 일치의 마지막 행이 됩니다. 예를 들어, 검색 패턴이 pattern (start down up) 인 경우 up 과 일치하는 행은 프레임의 오른쪽 모서리 앞의 마지막 행이 됩니다.
(일치 항목이 발견되지 않으면 프레임의 오른쪽 모서리가 정의되지 않고 참조되지 않습니다.)
단순한 사례로 슬라이딩 윈도우 프레임을 아래와 같이 생각할 수 있습니다.
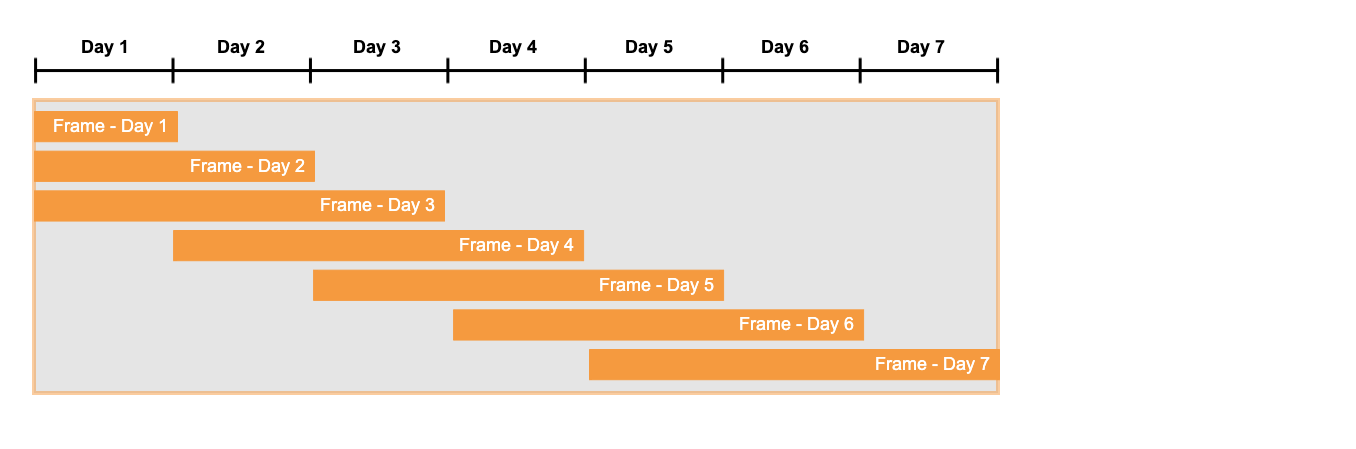
DEFINE 하위 절(예: DEFINE down_10_percent as LAG(price) * 0.9 >= price)의 식에서 사용된 LAG() 와 같은 탐색 함수 에 대해서는 앞에서 살펴봤습니다. MEASURES 하위 절에서도 사용할 수 있는 탐색 함수를 보여주는 쿼리는 다음과 같습니다. 이 예에서 탐색 함수는 현재 일치 항목이 포함된 윈도우 프레임의 모서리(및 그러므로 크기)를 보여줍니다.
이 쿼리의 각 출력 행에는 해당 행에 대한 LAG(), LEAD(), FIRST() 및 LAST() 탐색 함수의 값이 포함됩니다. 윈도우 프레임의 크기는 첫 번째 및 마지막 행을 포함하여 FIRST() 와 LAST() 사이의 행 수입니다.
아래 쿼리에서 DEFINE 및 PATTERN 절은 3개 행 그룹(10월 1~3일, 10월 2~4일, 10월 3~5일 등)을 선택합니다.
이 쿼리의 출력은 일치 그룹이 아닌(즉, 윈도우 프레임 외부) 행을 참조하는 식의 경우 LAG() 및 LEAD() 함수가 NULL을 반환한다는 것도 보여줍니다.
DEFINE 절의 탐색 함수 규칙은 MEASURES 절의 탐색 함수 규칙과 약간 다릅니다. 예를 들어, PREV() 함수는 MEASURES 절에서 사용할 수 있지만 현재 DEFINE 절에서는 사용할 수 없습니다. 대신 DEFINE 절에 LAG() 를 사용할 수 있습니다. MATCH_RECOGNIZE 의 참조 문서에는 각 탐색 함수 에 해당하는 규칙이 나열됩니다.
MEASURES 하위 절에는 다음도 포함됩니다.
집계 함수. 예를 들어, 패턴이 다양한 개수의 행과 일치할 수 있는 경우(예: 1개 이상의 하락하는 주가와 일치하므로) 일치하는 전체 행 개수를 확인하려면
COUNT(*)를 사용하여 표시할 수 있습니다.일치 항목의 각 행에 있는 값에서 작동하는 일반 식입니다. 이러한 식은 수학식, 논리식 등일 수 있습니다. 예를 들어, 행의 값을 살펴본 후 “ABOVE AVERAGE”와 같은 텍스트 설명자를 인쇄할 수 있습니다.
행(
ONE ROW PER MATCH)을 그룹화하고 열의 값이 그룹의 다른 행 값과 다른 경우, 해당 일치 항목에서 선택된 값은 비결정적이며 이 값을 기반으로 하는 식도 비결정적일 가능성이 높음을 기억해야 합니다.
MEASURES 하위 절에 대한 자세한 내용은 MATCH_RECOGNIZE 참조 문서 를 참조하십시오.
다음 일치 항목을 검색할 위치 지정하기¶
기본적으로 MATCH_RECOGNIZE 는 일치 항목을 발견한 후 가장 최근 일치 항목의 종료 직후에 다음 일치 항목을 검색하기 시작합니다. 예를 들어, MATCH_RECOGNIZE 에서 2, 3 및 4행에서 일치 항목을 찾으면 MATCH_RECOGNIZE 는 5행에서 다음 일치 항목을 찾기 시작합니다. 이를 통해 일치 항목이 중첩되지 않습니다.
그러나 사용자는 대체 시작점을 선택할 수 있습니다.
다음 데이터를 살펴보겠습니다.
W 패턴(하락, 상승, 하락, 상승)에 해당하는 데이터를 찾고 있다고 가정해 보겠습니다. 다음과 같은 3가지 W 모양이 있습니다.
월: 1, 2, 3, 4 및 5.
월: 3, 4, 5, 6 및 7.
월: 5, 6, 7, 8 및 9.
SKIP 절을 사용하여 모든 패턴이 필요한지 아니면 중첩되지 않는 패턴만 필요한지를 지정할 수 있습니다. SKIP 절에서는 다른 옵션도 지원됩니다. SKIP 절에 대해서는 MATCH_RECOGNIZE 에서 보다 자세한 설명이 제공됩니다.
모범 사례¶
MATCH_RECOGNIZE절에 ORDER BY 절을 포함해야 합니다.이 ORDER BY는
MATCH_RECOGNIZE절 내에만 적용된다는 점을 기억해야 합니다. 특정 순서로 결과를 반환하는 전체 쿼리가 필요한 경우에는 쿼리의 가장 바깥쪽 수준에서ORDER BY절을 추가로 사용합니다.
패턴 변수 이름:
패턴을 쉽게 이해 및 디버그할 수 있도록 의미 있는 패턴 변수 이름을 사용해야 합니다.
PATTERN및DEFINE절 모두에서 패턴 변수 이름에 오타가 있는지 확인합니다.
기본값이 있는 하위 절에서 기본값을 사용하지 마십시오. 선택한 값을 명확하게 사용해야 합니다.
소규모 샘플 데이터로 패턴을 테스트한 후 전체 데이터 세트로 확장합니다.
MATCH_NUMBER(),MATCH_SEQUENCE_NUMBER()및CLASSIFIER()는 디버깅할 때 매우 유용합니다.쿼리의 가장 바깥쪽 수준에서
ORDER BY절을 사용하여MATCH_NUMBER()및MATCH_SEQUENCE_NUMBER()를 사용한 순서대로 출력을 정렬하는 것이 좋습니다. 출력 데이터의 순서가 다른 경우에는 출력이 패턴과 일치하지 않는 것처럼 보일 수 있습니다.
분석 오류 방지하기¶
상관 관계 vs 인과 관계¶
상관 관계는 인과 관계를 보장하지 않습니다. MATCH_RECOGNIZE 는 “거짓 긍정”(패턴을 볼 수 있지만 우연의 일치인 경우)을 반환할 수 있습니다.
패턴 일치가 “거짓 긍정”일 수도 있습니다(실제에는 패턴이 있지만, 데이터 샘플에 패턴이 표시되지 않는 경우).
대부분의 경우 일치 항목 찾기(예: 보험 사기를 나타내는 패턴 찾기)는 분석의 첫 번째 단계에 불과합니다.
일반적으로 거짓 긍정 수를 증가시키는 요소는 다음과 같습니다.
대규모 데이터 세트.
대규모 패턴 검색.
짧거나 단순한 패턴 검색.
일반적으로 거짓 부정 수를 증가시키는 요소는 다음과 같습니다.
소규모 데이터 세트.
가능성이 있는 모든 관련 패턴을 검색하지 않음.
필요 이상으로 복잡한 패턴 검색.
순서가 중요한 패턴¶
대부분의 패턴 일치에서는 데이터가 순서대로 위치(예: 시간 기준)해야 하지만, 예외가 있습니다. 예를 들어, 한 사람이 자동차 사고와 자택 절도 모두에 대한 보험 사기를 저지른 경우에는 사기의 발생 순서가 중요하지 않습니다.
찾고 있는 패턴에서 순서가 중요하지 않은 경우 “대체”(|) 및 PERMUTE 등의 연산자를 사용하여 검색에서 순서가 덜 중요하도록 설정할 수 있습니다.
예¶
이 섹션에서는 추가적인 예가 제공됩니다.
더 많은 예는 MATCH_RECOGNIZE 에서 확인할 수 있습니다.
며칠 동안의 주가 상승 찾기¶
ABCD 회사의 주가가 2일 연속으로 상승하는 모든 패턴을 찾는 쿼리는 다음과 같습니다.
PERMUTE 연산자 시연¶
이 예는 패턴에서 PERMUTE 연산자를 보여줍니다. 차트에서 주가 상승 수를 2개로 제한하는 모든 상승 및 하락 스파이크를 찾습니다.
SKIP TO NEXT ROW 옵션 시연¶
이 예는 SKIP TO NEXT ROW 옵션을 보여줍니다. 이 쿼리에서는 각 회사의 차트에서 W자 곡선을 찾습니다. 일치는 중첩될 수 있습니다.
제외 구문¶
이 예는 패턴에서의 제외 구문을 보여줍니다. 이 패턴(이전 패턴과 같이)에서는 W 모양을 찾지만, 이 쿼리의 출력에서는 하락하는 주가가 제외됩니다. 이 쿼리에서는 일치가 일치 항목의 마지막 행을 지나서 계속 진행됨에 유의하십시오.
비인접 행에서 패턴 검색¶
일부 상황에서는 연속하지 않은 행에서 패턴을 검색할 수 있습니다. 예를 들어, 로그 파일을 분석할 때 특정 경고 시퀀스 이후에 치명적인 오류가 나타나는 모든 패턴을 검색할 수 있습니다. 모든 관련 메시지(행)가 단일 윈도우 내에 인접하도록 행을 분할 및 정렬할 수 있는 자연스러운 방법이 없을 수 있습니다. 이러한 경우에는 특정 이벤트를 찾는 패턴이 필요하지만 데이터 내에서 이벤트가 연속일 필요는 없습니다.
패턴에 적합한 연속적인 또는 연속하지 않은 행을 인식하는 DEFINE 및 PATTERN 절의 예는 아래와 같습니다. ANY_ROW 기호는 TRUE(즉, 모든 행과 일치)로 정의됩니다. 각 ANY_ROW 이후의 * 는 첫 번째 경고와 두 번째 경고 사이 및 두 번째 경고와 치명적인 오류 로그 메시지 사이에서 ANY_ROW 가 0개 이상 발생하도록 허용합니다. 그러므로 전체 패턴에서는 WARNING1 이후에 개수와 상관없이 행이 오고 이후에 WARNING2 가 오고 이후에 개수와 상관없이 행이 오고 이후에 FATAL_ERROR 가 오는 패턴을 검색하게 됩니다. 관계가 없는 행을 출력에서 생략하려면 쿼리에서 제외 구문({- 및 -})을 사용합니다.
문제 해결하기¶
ONE ROW PER MATCH 사용 시 및 Select 절에 열 지정 시의 오류¶
ONE ROW PER MATCH 절은 집계 함수와 유사하게 동작합니다. 이로 인해 사용할 수 있는 출력 열이 제한됩니다. 예를 들어, ONE ROW PER MATCH 를 사용하고 각 일치에 날짜가 다른 행 3개가 포함된 경우에는 1개의 날짜가 모든 3개 행에 정확하지 않으므로 날짜 열을 SELECT 절의 출력 열로 지정할 수 없습니다.
예기치 않은 결과¶
PATTERN및DEFINE절에서 오타를 확인합니다.PATTERN절에서 사용된 패턴 변수 이름이DEFINE절에 정의되지 않은 경우(예:PATTERN또는DEFINE절의 이름에 오타가 있기 때문에) 오류가 보고되지 않습니다. 대신, 각 행에 대하여 패턴 변수 이름이 단순히 true인 것으로 가정됩니다.SKIP절을 검토하여 중첩 패턴 포함 또는 제외와 같이 올바른지 확인합니다.