Analyzing data with window functions¶
This topic contains introductory conceptual information about window functions. If you are already familiar with the usage of window functions, you might find the following reference information sufficient:
- Window functions, which contains a list of functions and links to individual function descriptions.
- Window function syntax and usage, which describes general syntax rules for all window functions.
Introduction¶
A window function is an analytic SQL function that operates on a group of related rows known as a partition. A partition is usually a logical group of rows along some familiar dimension, such as product category, location, time period, or business unit. Function results are computed over each partition, with respect to an implicit or explicit window frame. A window frame is a fixed or variable set of rows relative to the current row. The current row is a single input row for which the function result is currently being computed. Function results are calculated row by row within each partition, and each row in the window frame takes its turn as the current row.
The syntax that defines this behavior is the OVER clause for the function. In many cases, the OVER clause distinguishes a window function from a regular SQL function with the same name (such as AVG or SUM). The OVER clause consists of three main components:
- A PARTITION BY clause
- An ORDER BY clause
- A window frame specification
Depending on the function or query in question, all of these components may be optional; a window function with an empty OVER clause is valid:
OVER(). However, in most analytic queries, window functions require one or more explicit OVER clause components. You can call a window
function in any context that supports other SQL functions. The following sections explain the concepts behind window functions in more detail
and present some introductory examples. For complete syntax information, see Window function syntax and usage.
Window functions versus aggregate functions¶
A good way to start learning about window functions is to compare regular aggregate functions with their window function counterparts. Several standard aggregate functions, such as SUM, COUNT, and AVG, have corresponding window functions with the same name. To distinguish the two, note that:
- For an aggregate function, the input is a group of rows, and the output is one row.
- For a window function, the input is each row within a partition, and the output is one row per input row.
For example, the SUM aggregate function returns a single total value for all of the input rows, whereas a window function returns multiple totals: one for each row (the current row) relative to all the other rows in the partition.
To see how this works, first create and load the menu_items table, which contains the cost of goods sold and prices for foodtruck menu items. Use a regular AVG function to find the average cost of goods for menu items in different categories:
Note that the function returns one grouped result for avg_cogs.
Alternatively, you can specify an OVER clause and use AVG as a window function. (The result is limited to 15 rows from the 60-row table.)
Note that the function returns an average for each row in each partition and resets the calculation when the partitioning column value
changes. To make the value of the window function more apparent, add an ORDER BY clause and a window frame to the function definition.
Also return the raw menu_cogs_usd values, in addition to the averages, so you can see how the specific calculations work. This query is
a simple example of a “moving average,” a rolling calculation that depends on an explicit window frame. For more examples like this, see
Analyzing time-series data.
The window frame adjusts the average calculations such that only the current row and the two rows that follow it (within the
partition) are considered. The last row in a partition has no following rows so the average for the last Beverage row, for example,
is the same as the corresponding menu_cogs_usd value (0.65). The output of the window function depends on the
individual row that is passed to the function and the values of the other rows that qualify for the window frame.
Note
When using window functions with ORDER BY clauses, ensure that the ordering is deterministic. If multiple rows
have the same value for the ORDER BY columns, add additional columns as tiebreakers to ensure consistent,
predictable results across query executions. In this example, menu_cogs_usd is included as a tiebreaker because
multiple rows can have the same menu_price_usd value.
Ordering the rows for window functions¶
The previous AVG window function example uses an ORDER BY clause within the function definition to ensure that the window frame is
subject to data that is sorted (by menu_price_usd in this case).
Two types of window functions require an ORDER BY clause:
- Window functions with explicit window frames, which perform rolling operations on subsets of the rows in each partition, such as calculating running totals or moving averages. Without an ORDER BY clause, the window frame is meaningless; the set of “preceding” and “following” rows must be deterministic.
- Ranking window functions, such as CUME_DIST, RANK, and DENSE_RANK, which return information based on the “rank” of a row. For example, if you rank stores in descending order by profit per month, the store with the highest profit will be ranked 1; the second-most profitable store will be ranked 2, and so on.
The ORDER BY clause for a window function supports the same syntax as the main ORDER BY clause that sorts the final results of a query. These two ORDER BY clauses are separate and distinct. An ORDER BY clause within an OVER clause controls only the order in which the window function processes rows; it does not control the output of the entire query. In many cases, your window function queries will contain both types of ORDER BY clauses.
Note
The ORDER BY clause for window functions does not support the use of an ordinal position, such as OVER (PARTITION BY 1 ORDER BY 2).
In this context, 2 is interpreted as the constant 2; it does not refer to the second column in the query.
The PARTITION BY and ORDER BY clauses within the OVER clause are also independent. You can use the ORDER BY clause without the PARTITION BY clause and vice versa.
Check the syntax for individual window functions before writing queries. Syntax requirements for the ORDER BY clause vary by function:
- Some window functions require an ORDER BY clause.
- Some window functions use an ORDER BY clause if one is present, but do not require it.
- Some window functions do not allow an ORDER BY clause.
- Some window functions interpret an ORDER BY clause as an implied window frame.
Caution
Generally speaking, SQL is an explicit language, with few implied clauses. However, for some window functions, an ORDER BY clause implies a window frame. For details, see Usage notes for window frames.
Because behavior that is implied rather than explicit can lead to results that are difficult to understand, Snowflake recommends declaring window frames explicitly.
Using different types of window frames¶
Window frames are defined explicitly or implicitly. They depend on the presence of an ORDER BY clause within the OVER clause:
- For explicit frame syntax, see the
windowFrameClauseunder Syntax. You can define open-ended boundaries: from the beginning of the partition to the current row; from the current row to the end of the partition; or completely “unbounded” end to end. Alternatively, you can use explicit offsets (inclusive) that are relative to the current row in the partition. - Implicit frames are used by default when the OVER clause does not include a
windowFrameClause. The default frame depends on the function in question. See also Usage notes for window frames.
Range-based versus row-based window frames¶
Snowflake supports two main types of window frames:
- Row-based:
An exact sequence of rows belongs to the frame, based on a physical offset from the current row. For example,
5 PRECEDINGmeans the five rows preceding the current row. The offset must be a number. ROWS mode is inclusive and is always relative to the current row. If the specified number of preceding or following rows extends beyond the limits of the partition, Snowflake treats the value as NULL.If the frame has open-ended rather than explicitly numbered boundaries, a similar physical offset applies. For example, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW means that the frame consists of the whole set of rows (zero or more) that physically precede the current row and the current row itself.
- Range-based:
A logical range of rows belongs to the frame, given an offset from the ORDER BY value for the current row. For example,
5 PRECEDINGmeans rows with ORDER BY values that have the ORDER BY value of the current row, plus or minus a maximum of 5 (plus for DESC order, minus for ASC order). The offset value may be a number or an interval.If the frame has open-ended rather than numbered boundaries, a similar logical offset applies. For example, RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW means that the frame consists of all the rows that physically precede the current row, the current row itself, and any adjacent rows that have the same ORDER BY value as the current row. For a RANGE window frame, CURRENT ROW does not mean physically the current row; it means all the rows that have the same ORDER BY value as the current physical row.
The distinctions in ROWS BETWEEN and RANGE BETWEEN window frames are important because window function queries may return very different results, depending on the ORDER BY expression, the data in the tables, and the exact definition of the frame. The following examples demonstrate the differences in behavior.
Comparing RANGE BETWEEN and ROWS BETWEEN with explicit offsets¶
A range-based window frame requires an ORDER BY column or expression and a RANGE BETWEEN specification. The logical boundary of the window frame depends on the ORDER BY value (a numeric constant or interval literal) for the current row.
For example, a time-series table named heavy_weather is defined as follows:
Sample rows in this table look like this:
Assume that a query computes a 3-hour moving average (AVG) over the precip (precipitation) column, using a window frame ordered by start_time:
Given the sample rows above, when the current row is 2021-12-30 11:23:00.000 (the first sample row), only the next two rows fall inside the frame
(2021-12-30 11:43:00.000 and 2021-12-30 13:53:00.000). Subsequent timestamps are greater than 3 hours later.
However, if you change the window frame to a 1-day interval, all of the sample rows that follow the current row fall inside the frame because
they all have timestamps on the same date (2021-12-30):
If you were to change this syntax from RANGE BETWEEN to ROWS BETWEEN, the frame would have to specify fixed boundaries, which represent an exact number of rows: the current row plus the following exact ordered number of rows, such as 1, 3, or 10 rows, regardless of the values returned by the ORDER BY expression.
See also RANGE BETWEEN example with explicit numeric offsets.
Comparing RANGE BETWEEN and ROWS BETWEEN with open-ended boundaries¶
The following example compares results when the following window frames are calculated against the same set of rows:
This example selects from a small table named menu_items. See Create and load the menu_items table.
The SUM window function aggregates the menu_price_usd values for each menu_category partition. With the ROWS BETWEEN
syntax, it is easy to see how the running totals are cumulative within each partition.
When the RANGE BETWEEN syntax is used with an otherwise identical query, the calculations are not so obvious at first; they depend on a different interpretation of current row: the current row itself plus any adjacent rows that have the same ORDER BY value as that row.
For example, the sum_price values for the second and third rows in the result are both 8.00 because the
ORDER BY value for those rows is the same. This behavior occurs in two other places in the result set,
where sum_price is calculated consecutively as 24.00 and 12.00.
Window frames for cumulative and sliding calculations¶
Window frames are a very flexible mechanism for running different types of analytic queries, including both cumulative calculations and moving calculations. To return cumulative sums, for example, you can specify a window frame that starts at a fixed point and moves row by row through the whole partition:
Another example of this type of frame might be:
The number of rows that qualify for these frames is variable, but the start and end points of the frames are fixed, using named boundaries rather than numeric or interval boundaries.
If you want the window function calculation to slide forward over a specific number (or range) of rows, you can use explicit offsets:
In this case, the result is a sliding frame that consists of a maximum of seven rows (3 + current row + 3). Another example of this type of frame might be:
Window frames can contain a mix of named boundaries and explicit offsets.
Sliding window frames¶
A sliding window frame is a fixed-width frame that “slides through” the rows in the partition, covering a different slice of the partition each time. The number of rows in the frame remains the same, except at the beginning or end of a partition, where it may contain fewer rows.
Sliding windows are often used to calculate moving averages, which are based on a fixed-size interval (such as a number of days). The average is “moving” because although the size of the interval is constant, the actual values in the interval change over time (or over some other dimension).
For example, stock market analysts often analyze stocks based in part on the 13-week moving average of a stock’s price. The moving average price today is the average of price at the end of today and the price at the end of each day during the most recent 13 weeks. If stocks are traded 5 days a week, and if there were no holidays in the last 13 weeks, the moving average is the average price on each of the most recent 65 trading days (including today).
The following example shows what happens to a 13-week (91-day) moving average of a stock price on the last day of June and the first few days of July:
- On June 30th, the function returns the average price for April 1 to June 30 (inclusive).
- On July 1st, the function returns the average price for April 2 to July 1 (inclusive).
- On July 2nd, the function returns the average price for April 3 to July 2 (inclusive).
The following example uses a small (3-day) sliding window over the first 7 days in the month. This example takes into account the fact that at the beginning of the period, the partition might not be full:
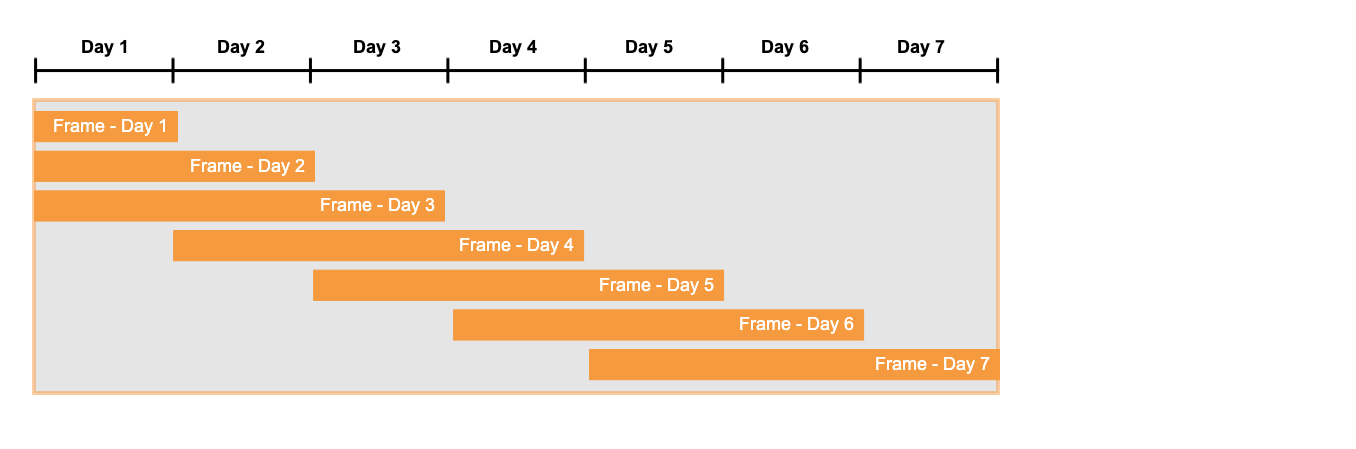
As you can see in the corresponding mockup of a query result, the last column contains the sum of the three most recent days’ of sales
data. For example, the column value for day 4 is 36, which is the sum of the sales for days 2, 3, and 4 (11 + 12 + 13):
Ranking window functions¶
The syntax for a ranking window function is essentially the same as the syntax for other window functions. The exceptions include:
- Ranking window functions require the ORDER BY clause inside the OVER clause.
- For some ranking functions, such as RANK itself, no input argument is required. For the RANK function, the value returned is based solely on numeric ranking, as determined by the ORDER BY clause inside the OVER clause. Therefore, passing a column name or expression to the function is unnecessary.
The simplest ranking function is named RANK. You can use this function to:
- Rank salespeople on revenue (sales), from highest to lowest.
- Rank countries based on their per-capita GDP (income per person), from highest to lowest.
- Rank countries on air pollution, from lowest to highest.
This function simply identifies the numeric ranking position of a row in an ordered set of rows. The first row has rank 1, the second has rank 2,
and so on. The following example shows the rank order of salespeople based on Amount Sold:
The rows must already be sorted before the rankings can be assigned. Therefore, you must use an ORDER BY clause within the OVER clause.
Consider the following example: you’d like to know where your store profit ranks among branches of the store chain (whether your store ranks first, second, third, and so on). This example ranks each store by profitability within its city. The rows are put in descending order (highest profit first), so the most profitable store is ranked 1:
Note
The net_profit column does not need to be passed as an argument to the RANK function. Instead, the input rows are sorted by net_profit.
The RANK function merely needs to return the position of the row (1, 2, 3, and so on) within the partition.
The output of a ranking function depends on:
- The individual row passed to the function.
- The values of the other rows in the partition.
- The order of all the rows in the partition.
Snowflake provides several different ranking functions. For a list of these functions, and more details about their syntax, see Window functions.
To rank your store against all other stores in the chain, not just against other stores in your city, use the query below:
The following query uses the first ORDER BY clause to control processing by the window function and the second ORDER BY clause to control the order of the entire query’s output:
Illustrated example¶
This example uses a sales scenario to illustrate many of the concepts described earlier in this topic.
Suppose that you need to generate a financial report that shows values based on sales over the last week:
- Daily sales
- Ranking within the week (that is, sales ranked highest to lowest for the week)
- Sales so far this week (that is, the “cumulative sum” for all days from the beginning of the week up through and including the current day)
- Total sales for the week
- Three-day moving average (that is, the average over the current day and the two previous days)
The report might look something like this:
The SQL for this query is somewhat complex. Rather than show the example as a single query, this discussion breaks down the SQL for the individual columns.
In a real-world scenario, you would have years of data, so to calculate sums and averages for one specific week of data, you would need to use a one-week window, or use a filter similar to:
However, for this example, assume that the table contains only the most recent week’s worth of data.
Calculating sales rank¶
The Rank column is calculated using the RANK function:
Although there are 7 days in the time period, there are only 5 different ranks (1, 2, 3, 5, 6). There were two ties (for 3rd place and 6th place), so there are no rows with ranks 4 or 7.
Calculating sales so far this week¶
The Sales So Far This Week column is calculated using SUM as a window function
with a window frame:
This query orders the rows by date and then, for each date, calculates the sum of sales from the start of the window up to the current date (inclusive).
Calculating total sales this week¶
The Total Sales This Week column is calculated using SUM.
Calculating a three-day moving average¶
The 3-Day Moving Average column is calculated using AVG as a window function with a
window frame:
The difference between this window frame and the window frame described earlier is the starting point: a fixed boundary versus an explicit offset.
Putting it all together¶
Here’s the final version of the query, showing all of the columns:
Additional examples¶
This section provides more examples of window functions, and illustrates how the PARTITION BY and ORDER BY clauses work together.
These examples use the following table and data:
Window function with ORDER BY clause¶
The ORDER BY clause controls the order of the data within each window (and each partition if there is more than one partition). This is useful if you want to show a “running sum” over time as new rows are added.
A running sum can be calculated either from the beginning of the window to the current row (inclusive) or from the current row to the end of the window.
A query can use a “sliding” window, which is a fixed-width window that processes n specified rows relative to the current row (for example, the 10 most recent rows, including the current row).
Window frames with fixed boundaries¶
When the window frame has a fixed boundary, values can be computed from the beginning of the window to the current row (or from the current row to the end of the window):
The query result includes additional comments that show how the CUMULATIVE_SUM_QUANTITY column was calculated:
Window frames with explicit offsets¶
In the financial world, analysts often study “moving averages.”
For example, you might have a graph in which the X axis is time, and the Y axis shows the average price of the stock over the last 13 weeks (that is, a 13-week moving average). In a graph of a 13-week moving average of a stock price, the price shown for June 30th is not the price of the stock on June 30th, but the average price of the stock for the 13 weeks up to and including June 30th (April 1st through June 30th). The value on July 1st is the average price for April 2nd through July 1st; the value on July 2nd is the average price for April 3rd through July 2nd, and so on. Each day, the window effectively adds the most recent day’s value to the moving average, and removes the oldest day’s value. This smooths out day-to-day fluctuations and can make trends easier to recognize.
Moving averages can be calculated using a sliding window frame. The frame has a specific width in rows. In the stock price example above, 13 weeks is 91 days, so the sliding window would be 91 days. If the measurements are taken once per day (for example, at the end of the day), the window would be 91 rows “wide.”
To define a window that is 91 rows wide:
Note
The initial window frame might be less than 91 days wide. For example, suppose that you want the 13-week moving average price of a stock. If the stock was first created on April 1st, on April 3rd only 3 days’ of price information exists, so the window is only 3 rows wide.
The following example shows the result of summing over a sliding window frame that is wide enough to hold two samples:
The query result includes additional comments that show how the SLIDING_SUM_QUANTITY column was calculated:
Note that the “sliding window” functionality requires the ORDER BY clause; the function depends on the order of rows that enter and exit the window frame.
Running totals with PARTITION BY and ORDER BY clauses¶
You can combine PARTITION BY and ORDER BY clauses to get running sums within partitions. In this example, the partitions
are one month, and because the sums apply only within a partition, the sum is reset to 0 at the beginning of each new month:
The query result includes additional comments showing how the MONTHLY_CUMULATIVE_SUM_QUANTITY column was calculated:
You can combine partitions and sliding window frames. In the example below, the sliding window is usually two rows wide, but each time a new partition (that is, a new month) is reached, the sliding window starts with only the first row in that partition:
The query result includes additional comments showing how the MONTHLY_SLIDING_SUM_QUANTITY column was calculated:
Calculate the ratio of a value to a sum of values¶
You can use the RATIO_TO_REPORT function to calculate the ratio of a value to the sum of the values in a partition, then return the ratio as a percentage of that sum. The function divides the value in the current row by the sum of the values in all of the rows in a partition.
The PARTITION BY clause defines partitions on the city column. If you want to see the profit percentage relative to the entire chain,
rather than just the stores within a specific city, omit the PARTITION BY clause: