시계열 데이터 분석하기¶
이 목적을 위해 특별히 설계된 기능을 사용하여 Snowflake에서 시계열 데이터를 분석할 수 있습니다. 데이터베이스 관리자, 데이터 과학자, 애플리케이션 개발자는 시계열이 효율적으로 저장되고 로드되었는지 확인해야 하며, 많은 경우 완전하고 일관적인 형태로 요약된 후에야 비즈니스 분석가와 기타 컨슈머에게 데이터를 제공할 수 있습니다.
시계열 데이터 소개¶
시계열 은 시스템, 프로세스, 행동이 일정 기간 동안 어떻게 변화하는지를 파악하는 순차적인 관찰로 구성됩니다. 시계열 데이터는 다양한 산업 분야의 다양한 디바이스에서 수집됩니다. 일반적인 예로는 금융 애플리케이션을 위해 수집된 주식 거래 데이터, 날씨 관측, 스마트 공장의 센서에서 수집한 온도 판독값, 디지털 광고의 사용자 클릭 로그 등이 있습니다.
시계열의 단일 레코드는 일반적으로 다음과 같은 구성 요소를 갖습니다.
일관적인 수준의 세부성(밀리초, 초, 분, 시 등)이 있는 날짜, 시간 또는 타임스탬프입니다.
어떤 종류의 하나 이상의 측정 또는 메트릭, 보통 숫자형(데이터의 추세나 이상값를 보여줄 수 있는 사실).
온도 측정 위치나 주어진 거래에 대한 주식 기호 등 측정과 관련된 관심 차원.
예를 들어, 다음 날씨 관측에는 시작 및 종료 타임스탬프, 강수량 측정(0.32), 및 위치 정보:
팩토리 디바이스에서 수집된 다음 데이터에는 네임스페이스(IOT), 태그 ID 또는 센서 ID(3000), 디바이스의 온도 측정값에 대한 타임스탬프, 온도 측정값 자체(21.1673), 데이터가 이후 데이터 브로커에 도착한 시점인 “브로커 타임스탬프”가 있습니다. 예를 들어, 데이터 브로커는 Snowflake 테이블에 데이터를 수집하는 Kafka 서버일 수 있습니다.
시계열에서는 어떤 이유로든 판독값이 급격하게 변할 때 스파이크가 나타날 수 있습니다. 예를 들어, 다음 이미지는 15초 간격으로 측정한 일련의 온도 판독값을 보여 주며, 전날 35°C 범위를 꾸준히 유지한 후 40°C가 넘는 최고값을 나타냅니다.
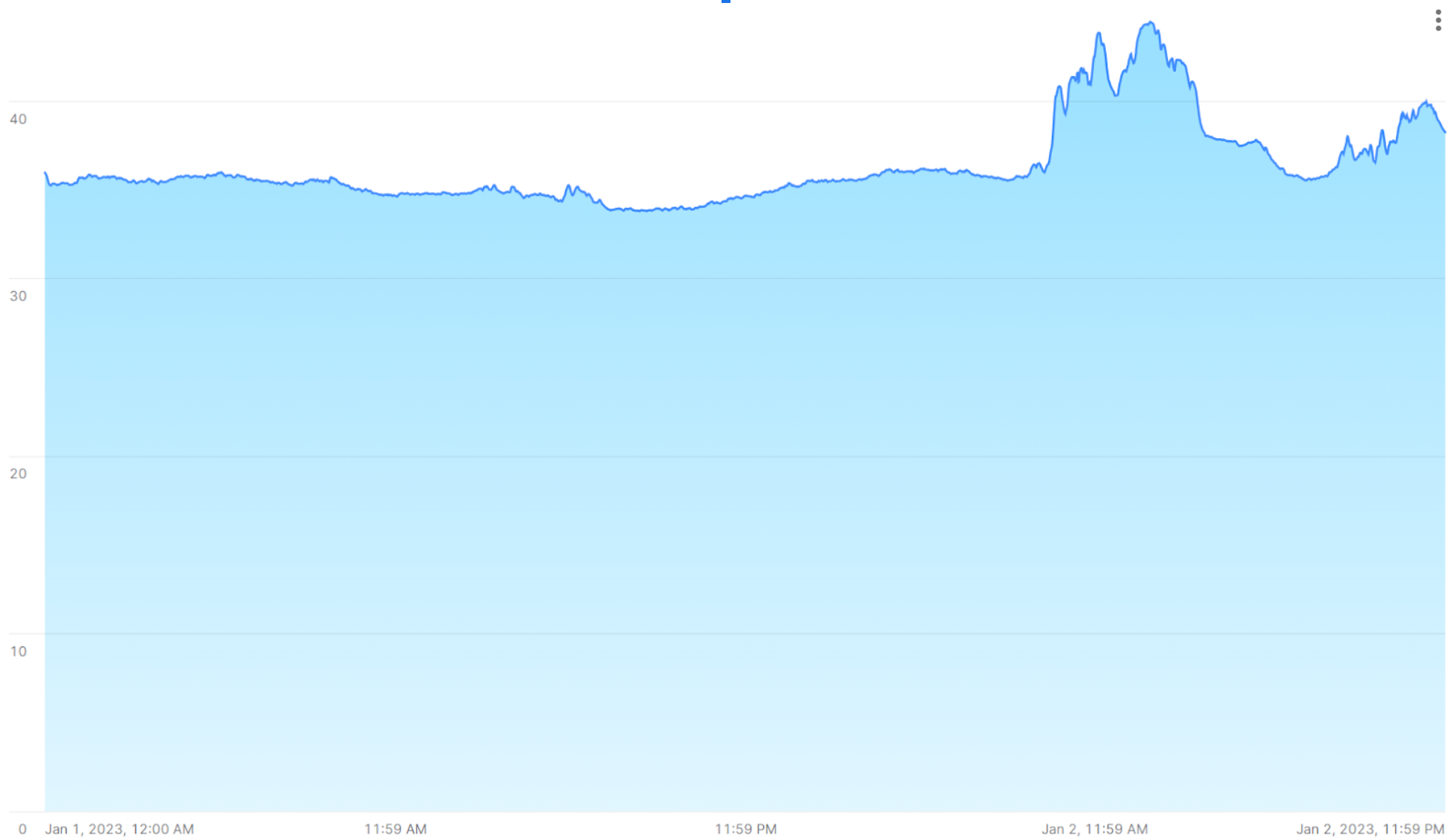
다음 섹션에서는 빠르고 정확한 결과를 제공하는 SQL 함수와 조인을 사용하여 이러한 종류의 대량의 데이터를 분석하고 시각화하는 방법을 보여줍니다.
시계열 데이터를 저장하는 방법¶
지원되는 날짜/시간 데이터 타입 은 다음과 같습니다.
DATE
TIME
TIMESTAMP(및 변형, TIMESTAMP_TZ 포함)
이러한 데이터 타입을 사용하는 데이터의 로드, 관리 및 쿼리에 대한 정보는 날짜 및 시간 값 작업하기 섹션을 참조하십시오.
시계열 데이터를 저장하고 쿼리하는 데 도움이 되는 여러 가지 일반적인 SQL 함수 를 사용할 수 있습니다. 예를 들어, CONVERT_TIMEZONE 을 사용하여 타임스탬프를 한 타임존에서 다른 타임존으로 변환할 수 있으며, EXTRACT 및 TIMEADD 같은 함수를 사용하여 필요에 따라 시간 기반 데이터를 조작할 수 있습니다.
참고
TIMESTAMP_TZ 데이터의 경우, Snowflake는 지정된 값에 대해 생성 시점에 실제 타임존이 아닌 지정된 타임존의 오프셋을 저장합니다.
쿼리 성능을 최적화하기 위해 시계열 분석에 사용되는 테이블은 종종 시간별로(때로는 센서 ID 또는 유사한 차원별로) 클러스터링됩니다. 클러스터링 키 및 클러스터링된 테이블 섹션을 참조하십시오.
시계열 데이터 집계하기¶
시계열 데이터를 관리하려면 대량의 세분화된 레코드를 더욱 요약된 형태로 집계해야 할 수도 있습니다(이 프로세스를 “다운샘플링”이라고도 함). 특정 시간 기반 세분성(밀리초, 초, 분 등)이 있는 대규모 레코드 세트가 주어지면 이러한 레코드를 더 거친 세분성으로 롤업하여 더 작은 샘플을 효과적으로 생성할 수 있습니다.
다운샘플링은 데이터 세트의 크기와 저장소 요구 사항을 줄여주기 때문에 유용합니다. 세분화 수준이 더 세밀할수록 쿼리 실행 중 컴퓨팅 리소스 요구 사항도 줄어듭니다. 다운샘플링의 또 다른 주요 이유는 분석가의 관점에서 시계열에 많은 수의 레코드가 중복될 수 있다는 점입니다. 예를 들어, 센서가 1초에 한 번씩 새로운 값을 내보내지만 이 측정값이 60초 간격마다 거의 변하지 않는 경우, 데이터를 분 단위까지 롤업하여 분석할 수 있습니다.
다운샘플링의 또 다른 사례는 서로 다른 두 데이터 세트를 하나로 분석해야 하지만 시간 세분성이 다른 경우에 발생합니다. 예를 들어, 공장의 센서 A는 15초마다 데이터를 수집하지만, 센서 B는 30초마다 관련 데이터를 수집합니다. 이런 경우에는 기록을 1분 버킷으로 집계하는 것이 좋은 해결책이 될 수 있습니다. 각 데이터 세트의 IDs 및 차원은 그대로 유지되지만 숫자 측정값은 공통 시간 간격을 기준으로 합산되거나 평균화됩니다.
다운샘플링 예제¶
TIME_SLICE 함수를 사용하여 테이블에 저장된 데이터 세트를 다운샘플링할 수 있습니다. 이 함수는 고정 너비 ‘버킷’의 시작 시간과 종료 시간을 계산하여 SUM 및 AVG와 같은 표준 집계 함수를 사용하여 개별 기록을 그룹화 및 요약할 수 있도록 합니다.
마찬가지로, DATE_TRUNC 함수는 일련의 날짜 또는 타임스탬프 값의 일부를 잘라내어 세분성을 줄입니다. 다음 섹션에서는 각 함수의 예를 보여줍니다.
TIME_SLICE를 사용한 다운샘플링¶
다음 예제는 두 개의 공장 센서의 판독값이 포함되어 있고 530만 개의 행을 포함하는 이름이 sensor_data_ts 인 테이블을 다운샘플링합니다. 이러한 판독값은 1초마다 수집되었으므로 530만 개의 행은 1개월 분의 데이터에 불과하며 센서당 250만 개의 행이 조금 넘습니다. 예를 들어, TIME_SLICE 함수를 사용하여 분당, 시간당 또는 일당 최대 하나의 행을 집계할 수 있습니다.
이 예제를 실행하려면 먼저 sensor_data_ts 테이블을 생성하고 로드합니다. sensor_data_ts 테이블 만들기 섹션을 참조하십시오. 다음은 테이블에 있는 데이터의 작은 샘플입니다.
이 쿼리에서 볼 수 있듯이 테이블에는 각 디바이스에 대해 분당 60개의 판독값이 포함되어 있습니다.
이 다운샘플링 쿼리에서 TIME_SLICE 함수는 1분 버킷을 정의하고 각 버킷의 시작 시간을 반환합니다. AVG 함수는 디바이스당 각 버킷의 평균 온도를 계산합니다. COUNT(*) 함수는 각 시간 버킷에 얼마나 많은 행이 있는지 보여주기 위해 참조용으로 포함되어 있습니다.
vibration 및 motor_rpm 열은 포함되지 않지만 temperature 열과 같은 방식으로 집계하거나 다른 집계 함수를 사용하여 집계할 수 있습니다.
중요
이 예제를 직접 실행하면 무작위로 생성된 값으로 sensor_data_ts 테이블이 로드되므로 출력이 정확히 일치하지 않습니다.
TIME_SLICE 함수를 사용하면 분석 목적으로 더 작은 규모의 집계된 테이블을 만들 수 있으며, 다양한 수준(시간, 일, 주 등)에서 다운샘플링 프로세스를 적용할 수 있습니다.
DATE_TRUNC를 사용한 다운샘플링¶
다음 예제는 Tasty Bytes 샘플 데이터베이스 의 raw.pos 스키마에 있는 이름이 order_header 인 테이블에서 데이터를 선택합니다. 이 테이블에는 2억 4,800만 개의 행이 있습니다.
order_header 테이블에는 이름이 order_ts 인 TIMESTAMP 열이 있습니다. 쿼리는 이 열을 DATE_TRUNC 함수의 두 번째 인자로 사용하여 집계된 시계열을 생성합니다. 첫 번째 인자는 day 간격을 지정합니다. 즉, 시간/분/초 단위로 구성된 개별 기록이 일별로 집계됩니다.
쿼리는 레코드를 truck_id 및 location_id 의 두 차원으로 그룹화합니다. avg_amount 열은 기록된 각 영업일의 주문당, 푸드트럭당, 위치당 평균 가격을 반환합니다.
여기에 표시된 쿼리는 결과를 2022년 1월 1일의 처음 25개 행으로 제한합니다. 이 날짜 필터와 LIMIT 절을 제거하면 쿼리는 원래 2억 4800만 개 행을 약 50만 개 행으로 다운샘플링합니다.
롤링 계산을 위한 윈도우 집계 사용하기¶
윈도우형 집계 함수를 사용하여 시간 경과에 따라 메트릭이 어떻게 변화하는지 관찰하면 시계열을 분석하여 추세를 파악할 수 있습니다. 윈도우형 집계는 더 큰 데이터 세트의 정의된 하위 집합(“윈도우”) 내에서 데이터를 분석하는 데 유용합니다. 현재 행의 이전, 이후 또는 주변 행 그룹을 고려하여 데이터 집합의 각 행에 대해 롤링 계산(예: 이동 평균 및 합계)을 계산할 수 있습니다. 이러한 종류의 분석은 전체 데이터 세트를 요약하는 일반적인 집계와 대조됩니다.
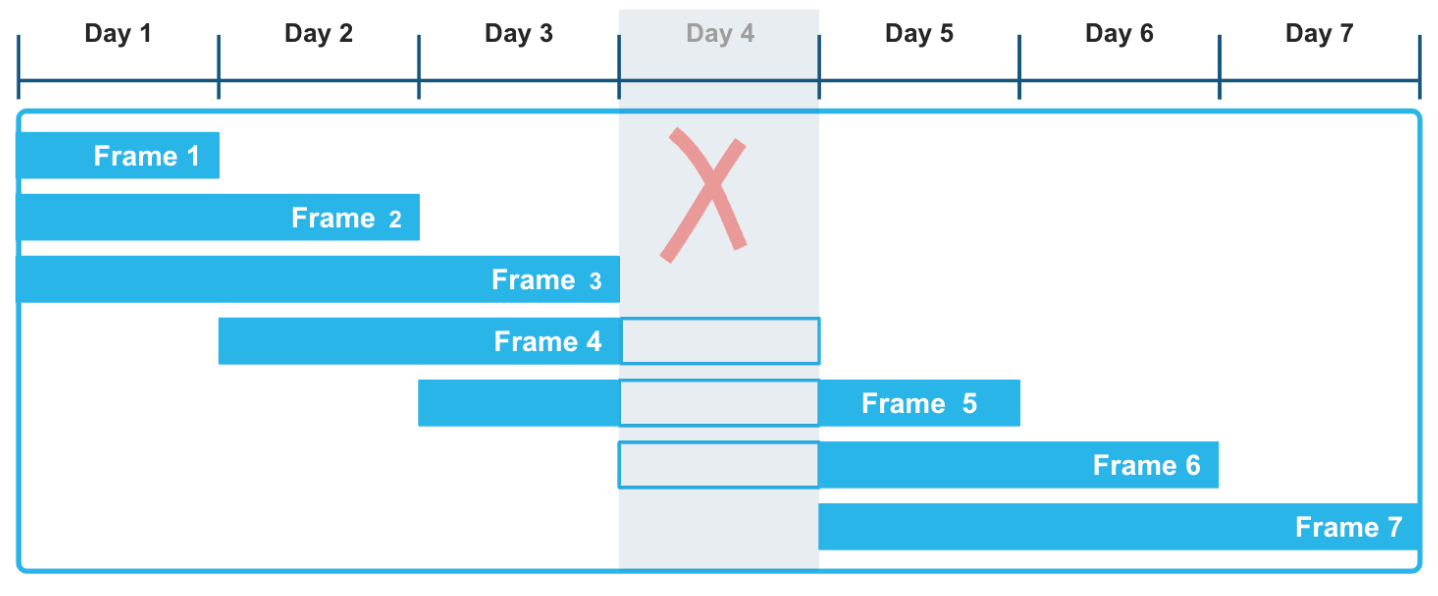
명시적 오프셋이 있는 범위 기반 윈도우 프레임을 사용하면 이러한 롤링 집계를 계산하는 데 매우 유연한 액세스 방식을 적용할 수 있습니다. 타임스탬프 또는 숫자로 정렬된 RANGE BETWEEN 윈도우 프레임은 시계열 데이터에서 발생할 수 있는 간격으로 인해 방해를 받지 않습니다. 예를 들어, 다음 그림에서 Day 4 데이터가 계열 레코드에서 누락되었다는 사실은 3일 이동 윈도우에 대한 집계 함수 계산에 영향을 미치지 않습니다. 특히 프레임 3, 4, 5는 Day 4 데이터를 알 수 없다는 점을 고려하여 올바르게 계산됩니다.
다음 예에서는 다양한 도시와 카운티의 매시간 강수량을 기록한 날씨 데이터에 대한 이동 합계를 계산합니다. 이러한 종류의 쿼리를 실행하여 센서 및 기타 IoT 디바이스와 같은 다양한 시계열 데이터 세트의 추세를 평가할 수 있으며, 특히 이러한 데이터 세트에 차이가 있거나 차이가 있을 것으로 예상되는 경우 더욱 그렇습니다.
윈도우 함수는 프레임에 현재 강수량 측정값과 현재 측정값 이전의 지정된 시간 간격에 해당하는 모든 측정값 을 포함하며, 롤링 계산은 정확한 행 수 가 아닌 이 유연하고 논리적인 범위 의 행을 기반으로 합니다. 각 도시의 첫 번째 행에는 일치하는 precip 및 moving_sum_precip 값이 있습니다. 그 후에는 프레임의 각 행에 대해 합계가 다시 계산됩니다. 원시 값은 크게 변동하지만 이동 합계는 강력한 평활화 효과가 있습니다.
이 예제를 실행하려면 먼저 heavy_weather 테이블 생성 및 로드하기 지침을 따르십시오. 매우 소규모인 이 테이블에는 시간당의 산발적인 날씨 관측값이 담겨 있으며, 누락된 날을 포함하여 많은 공백이 있습니다. 이 쿼리는 start_time 열에 정렬된 강수량 값의 이동 합계를 반환합니다. 윈도우 프레임은 현재 행의 12시간 전과 현재 행 사이의 범위를 정의합니다. 따라서 프레임은 현재 행과 현재 행의 ORDER BY 타임스탬프보다 최대 12시간 빠른 타임스탬프가 있는 행으로만 구성됩니다.
Big Bear City의 세 가지 moving_sum_precip 값은 다음과 같이 계산됩니다.
0.42 = 0.42(선행 행 없음)
0.42 + 0.09 = 0.51(첫 번째 두 행은 12시간 윈도우 내에 있음)
0.07 = 0.07(이전 행이 12시간 윈도우 내에 없음)
사우스 레이크 타호 행에는 다음과 같은 계산이 포함됩니다.
0.56 + 0.38 + 0.28 + 0.80 = 2.02 (2024-12-23의 네 행 모두 12시간 간격)
0.80 + 0.17 = 0.97(앞의 행 중 하나는 12시간 윈도우 내에 있음)
순위 함수와 같은 기타 윈도우 함수(예: LEAD 및 LAG)도 시계열 분석에 일반적으로 사용됩니다. 현재 데이터 요소를 기준으로 시계열에서 다음 데이터 요소를 찾으려면 LAG 윈도우 함수를 사용하고, 이전 데이터 요소를 찾으려면 LEAD 함수를 사용합니다.
Snowsight에서 쿼리 결과 시각화¶
Snowsight 를 사용하여 집계 쿼리의 결과를 시각화하고 슬라이딩 창 프레임을 통해 계산의 평활화 효과를 더 잘 파악할 수 있습니다. 쿼리 워크시트에서 Results 옆에 있는 Chart 버튼을 클릭합니다.
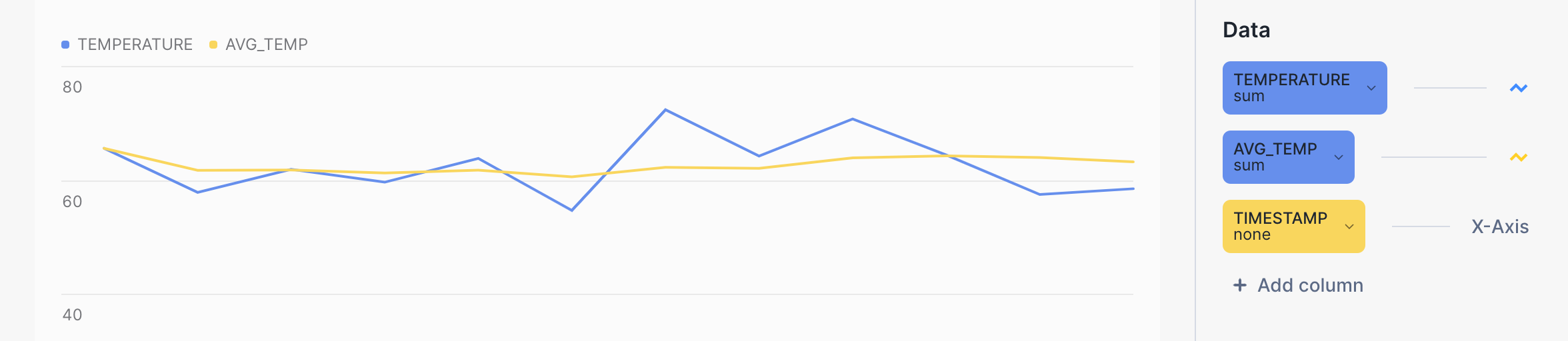
예를 들어, 다음 막대 차트의 노란색 선은 원시 온도를 나타내는 파란색 선에 비해 평균 온도에 대한 훨씬 더 완만한 추세를 보여줍니다. 쿼리 자체는 다음과 같습니다.
MIN_BY 및 MAX_BY 집계 함수 사용하기¶
같은 행에 있는 다른 열의 최소값 또는 최대값을 기준으로 한 열을 선택하는 기능은 시계열 데이터로 작업하는 SQL 개발자에게 흔히 요구되는 기능입니다. MIN_BY 및 MAX_BY 는 타임스탬프와 같은 다른 열을 기준으로 데이터가 정렬될 때 테이블의 시작과 끝(또는 최고와 최저, 또는 첫 번째와 마지막) 값을 반환하는 편의 함수입니다.
첫 번째 예제는 전체 테이블에서 마지막(가장 최근) precip 값을 찾기만 하면 됩니다. MAX_BY 함수는 모든 행을 start_time 값으로 정렬한 다음 “최대” 시작 시간에 대한 precip 값을 반환합니다.
다음 예제에서 사용된 테이블을 생성하고 로드하려면 heavy_weather 테이블 만들기 섹션을 참조하십시오.
다음 쿼리를 실행하면 이 결과를 확인할 수 있고 이에 대한 자세한 정보도 얻을 수 있습니다.
이 데이터에 대해 더 흥미로운 질문을 하려면 GROUP BY 절을 추가할 수 있습니다. 예를 들어, 다음 쿼리는 캘리포니아의 각 도시에서 관측된 마지막 강수량 값을 precip 값(높은 값부터 낮은 값순)으로 정렬하여 찾습니다. 결과는 city 를 기준으로 그룹화되어 각 다른 도시에 대한 마지막 precip 값을 반환합니다.
마지막으로 알타시를 관측했을 때 precip 값은 0.89 였고, 마지막으로 사우스 레이크 타호, 빅 베어 시티, 몬태규, 레벡의 도시들을 관측했을 때 precip 값은 네 곳 모두 0.07 이었습니다. (참고로, 이 쿼리는 해당 관찰이 수행된 시점은 알려주지 않습니다.)
MIN_BY 함수를 사용하여 “반대” 결과 세트(가장 오래된 precip 레코드와 가장 최근 레코드)를 반환할 수 있습니다.
시계열 데이터 결합하기¶
ASOF JOIN 구문을 사용하여 시계열 데이터가 포함된 테이블을 조인할 수 있습니다. 복잡한 SQL, 다른 유형의 조인, 윈도우 함수를 사용하여 ASOF JOIN 쿼리를 에뮬레이트할 수 있지만 ASOF JOIN 구문을 사용하면 이러한 쿼리가 작성하기 더 쉬워지고 최적화됩니다.
ASOF 조인의 일반적인 용도는 금융 거래 데이터 분석입니다. 예를 들어, 거래 비용 분석에는 주식 구매 결정 시 호가와 거래가 실행되고 기록될 때 실제로 지불한 가격 간의 차이를 측정하는 “슬리피지” 계산이 필요합니다. ASOF JOIN은 이러한 유형의 분석을 촉진할 수 있습니다. 이 조인 메서드의 핵심 기능이 하나의 시계열을 다른 시계열에 대해 분석하는 것이므로, ASOF JOIN은 본질적으로 기록적인 모든 데이터 집합을 분석하는 데 유용할 수 있습니다. 이러한 사용 사례 중 다수에서는 서로 다른 디바이스에서 판독한 데이터에 정확히 동일하지 않은 타임스탬프가 있는 경우 ASOF JOIN을 사용하여 데이터를 연결할 수 있습니다.
분석해야 하는 시계열 데이터가 두 테이블에 존재하고 각 테이블의 각 행에 대한 타임스탬프가 있다고 가정합니다. 이 타임스탬프는 기록된 이벤트의 정확한 “현재” 날짜와 시간을 나타냅니다. 첫 번째(또는 왼쪽) 테이블의 각 행에 대해 조인은 타임스탬프 값이 다음 중 하나인 두 번째(또는 오른쪽) 테이블에서 단일 행을 찾기 위해 지정하는 비교 연산자와 함께 “일치 조건”을 사용합니다.
왼쪽 테이블의 타임스탬프 값보다 작거나 같습니다.
왼쪽 테이블의 타임스탬프 값보다 크거나 같습니다.
왼쪽 테이블의 타임스탬프 값보다 작습니다.
왼쪽 테이블의 타임스탬프 값보다 큽니다.
오른쪽에 있는 적격 행은 가장 가까운 일치 항목이며, 지정된 비교 연산자에 따라 시간상 동일하거나 이전 또는 이후일 수 있습니다.
ASOF JOIN 결과의 카디널리티는 항상 왼쪽 테이블의 카디널리티와 같습니다. 왼쪽 테이블에 4,000만 개의 행이 있는 경우 ASOF JOIN은 4,000만 개의 행을 반환합니다. 따라서 왼쪽 테이블은 “보존하는” 테이블로, 오른쪽 테이블은 “참조되는” 테이블로 생각할 수 있습니다.
가장 가까운 일치 항목에서 두 테이블 결합하기(정렬)¶
예를 들어 금융 애플리케이션에는 quotes 라는 테이블과 trades 라는 테이블이 있을 수 있습니다. 한 테이블에는 주식 매수 입찰 내역이 기록되고, 다른 테이블에는 실제 거래 내역이 기록됩니다. 주식 매수 입찰은 거래 전에 이루어집니다(또는 기록된 시간의 세분성에 따라 “동시에” 이루어질 수도 있음). 두 테이블 모두 타임스탬프가 있으며, 둘 다 관심을 두고서 비교할 수 있는 다른 열이 있습니다. 간단한 ASOF JOIN 쿼리는 각 거래 이전에 가장 가까운 호가(시간 기준)를 반환합니다. 즉, 쿼리는 다음과 같이 묻습니다. “내가 거래할 당시 해당 주식의 주가는 얼마였습니까?”
trades 테이블에 3개의 행이 있고 quotes 테이블에 7개의 행이 있다고 가정합니다. 셀의 배경색은 행이 일치하는 티커 심벌에서 조인되고 이들 행의 타임스탬프 열이 비교될 때 quotes 의 3개 행이 ASOF JOIN에 적합하다는 것을 보여줍니다.
TRADES 테이블(왼쪽 또는 “보존하는” 테이블)
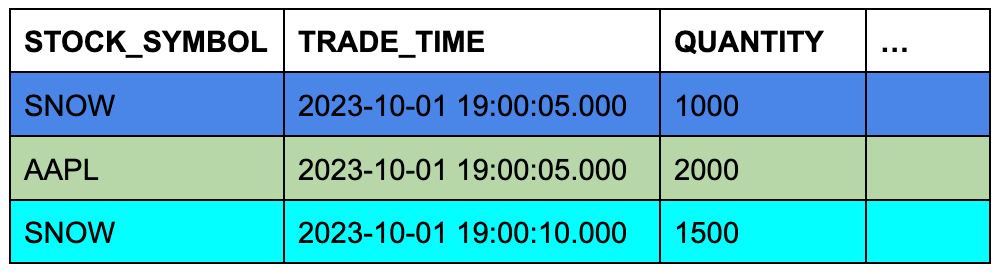
QUOTES 테이블(오른쪽 또는 “참조되는” 테이블)
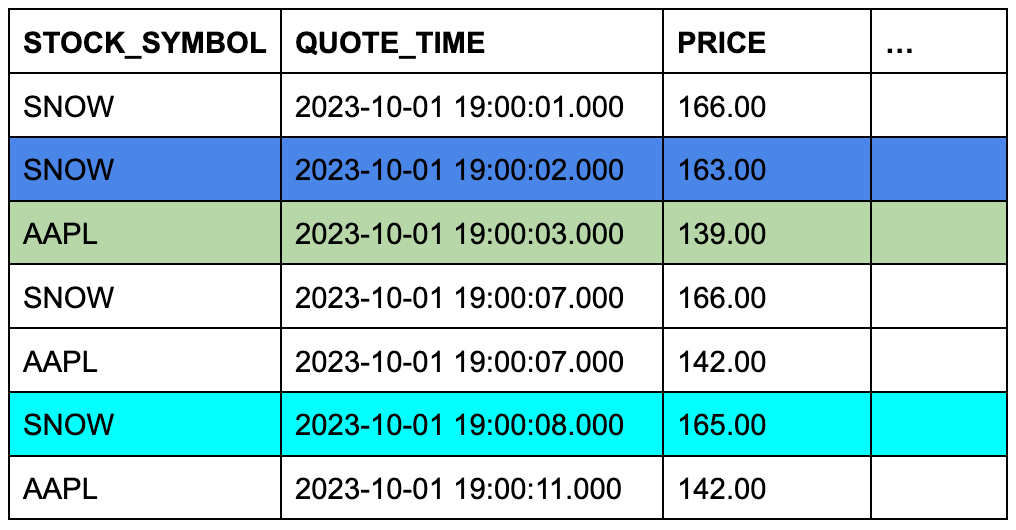
이 개념적 예제는 구체적인 ASOF JOIN 쿼리로 쉽게 전환할 수 있습니다.
ON 조건은 일치하는 행을 티커 심벌별로 그룹화합니다.
이 예제를 실행하려면 다음과 같이 테이블을 만들고 로드합니다.
ASOF JOIN 쿼리의 더 많은 예제를 살펴보려면 예 섹션을 참조하십시오.
시계열 데이터의 공백 채우기¶
시계열 분석에서는 대개 모든 간격마다 레코드에 대한 일관된 세분성을 가진 데이터를 요구하지만, 실제 데이터는 불규칙한 간격으로 도착하거나 공백이 포함된 경우가 많습니다. 예를 들어, 주로 시간 단위 데이터 세트가 있지만 다운스트림 분석에 맞게 30분 단위 항목을 생성해야 하거나, 이미 일관된 분해능을 갖추고 있지만 시계열에서 공백을 발견할 수 있습니다. Snowflake 공백 채우기 기능은 시계열 데이터에 균일한 간격을 적용하고 공백을 채우는 효율적인 방법을 제공합니다.
예를 들어, 2025년 3월 15일 캘리포니아의 두 도시에 대한 날씨 관측 데이터를 기록하는 다음 8개의 레코드가 있다고 생각해 보세요.
이러한 레코드의 세분성 수준(일, 시간, 분)은 어느 정도 일관된 편이지만, 행 사이의 간격은 1분에서 15분 사이로 일관되지 않습니다. 5분 간격으로 데이터를 수집하는 것이 목표인 경우 여러 행이 누락됩니다.
RESAMPLE 절 사용하기¶
특정 시간 간격으로 “업샘플링”하여 행 세트의 세분성을 수정하고 일관성을 개선할 수 있습니다. 이러한 변경을 수행하려면 SELECT 문의 FROM 절 내에 정의하는 RESAMPLE 절을 사용합니다. 리샘플링된 데이터 세트의 결과는 기존 입력 행을 모두 보존하면서 시계열의 공백을 채우는 값으로 새 행을 생성하는 더 큰 데이터 세트입니다. (RESAMPLE 절을 사용하여 행을 더 작고 덜 세밀한 결과 세트로 “다운샘플링”할 수도 있습니다.)
정의에 따라, 시계열은 항상 일련의 날짜, 타임스탬프 또는 날짜나 시간을 나타내는 숫자 값이 포함된 열을 갖습니다. 리샘플링은 소스 테이블의 이러한 열에 적용되며, 필요한 세분성은 INTERVAL 값으로 지정해야 합니다(예: 5 minutes, 30 minutes 또는 1 hour).
일반적으로, 간격당 하나의 새 타임스탬프를 생성하는 대신, 특정 차원에 대해 시계열 행을 생성하는 파티션도 정의합니다.
RESAMPLE 쿼리의 구조는 다음과 같습니다.
생성된 행의 열은 USING 및 PARTITION BY 절에 지정된 열을 제외하고 NULL로 설정됩니다. 지정된 날짜, 시간 또는 숫자 열과 파티셔닝 열에는 생성된 유의미한 값이 있습니다.
참고
리샘플링된 데이터를 특정 값(예: 특정 디바이스 ID 또는 위치)별로 필터링하려는 경우 PARTITION BY 절에 해당 열을 포함합니다. 이를 통해 생성된 행에 NULL 값이 아닌 해당 값에 대한 실제 값이 포함되도록 보장합니다. PARTITION BY 절에 없는 열에 대해 WHERE 절로 필터링하는 경우 WHERE 절은 NULL 값을 포함하기 때문에 해당 열에 대해 생성된 모든 행을 필터링합니다.
앞서 설명한 8개의 레코드를 사용하는 간단한 예를 실행하려면 먼저 다음 테이블을 만들고 로드합니다.
이제 ``5 minutes``의 간격을 사용하여 해당 테이블에서 업샘플링된 행을 선택합니다.
이 쿼리는 원래 8개 행을 유지하고 3개의 새 행을 생성하여 세 가지 시간 간격 09:45, 10:00 및 10:05 동안의 공백을 채웁니다. temperature, city 및 county 열에는 NULL 값이 삽입됩니다.
시계열의 시작점은 입력 데이터 세트의 가장 빠른 타임스탬프(2025-03-15 09:49:00.000)의 5분 이내에 있으므로 ``2025-03-15 09:45:00.000``입니다.
균일한 간격으로 발생하지 않는 행(이 경우 09:49 및 10:18)을 제거하려는 경우 BUCKET_START()를 사용하여 균일하지 않은 행을 필터링하는 RESAMPLE 예제 섹션을 참조하세요.
이제 쿼리에 PARTITION BY 절을 추가합니다.
파티셔닝된 결과는 다음 두 가지 측면에서 다릅니다.
총 15개의 행에 대해 7개의 행이 생성됩니다. 이제 모든 파티션에 대해 5분 간격으로 행이 존재합니다.
파티셔닝 열에는 올바르게 생성된
city및county값이 있습니다. 생성된 행에 NULL 값이 있는 유일한 열은 ``temperature``입니다.
RESAMPLE 구문에 METADATA_COLUMNS 매개 변수를 지정하여 결과에 다음 열을 추가할 수도 있습니다.
is_generated메타데이터 열은 RESAMPLE 작업에 의해 생성된 행과 이미 존재했던 행을 식별합니다.bucket_start메타데이터 열은 현재 버킷의 시작 또는 RESAMPLE 작업이 생성하는 간격을 표시하는 값을 반환합니다. 이 열을 사용하여 리샘플링 후 특정 행이 속한 간격을 식별할 수 있으며, 이 열을 사용하여 리샘플링된 데이터에 대한 집계 쿼리를 실행할 수 있습니다. BUCKET_START()를 사용하여 리샘플링된 행을 집계하는 RESAMPLE 예제 섹션을 참조하십시오.
전체 RESAMPLE 구문에 대해서는 RESAMPLE 섹션을 참조하세요.
RESAMPLE 쿼리의 결과를 저장하려면 데이터를 선택하고 새 테이블에 삽입하는 :ref:`CTAS 문<label-CTAS_syntax>`을 사용합니다.
시계열로 값 보간 또는 “공백 채우기”¶
RESAMPLE 구문 및 보간 함수를 독립적으로 사용할 수 있지만, :ref:`단일 쿼리<label-resample_in_one_op>`의 범위에서 시계열 데이터의 공백을 채우기 위해 함께 사용하는 것이 일반적입니다. 데이터 세트를 리샘플링한 후에는 보간 함수를 호출하여 새로 생성된 행에서 관심 있는 다른 열을 업데이트할 수 있습니다. 보간 프로세스는 숫자 측정값과 같이 이전에 NULL이었던 열을 업데이트하여 이전 또는 다음 행에서 찾은 값을 기준으로 유의미한 값을 제공합니다.
INTERPOLATE_FFILL, INTERPOLATE_BFILL 및 INTERPOLATE_LINEAR 윈도우 함수를 호출하여 값을 보간할 수 있습니다. 예를 들어, INTERPOLATE_FFILL 함수는 해당 열의 시계열 데이터에서 이전(마지막) 값을 찾습니다.
INTERPOLATE_FFILL 함수가 사용할 이전 행이 없으므로 첫 번째 행은 ffill_temp 열에 대해 NULL을 반환합니다.
이러한 윈도우 함수에 대한 자세한 내용은 INTERPOLATE_BFILL, INTERPOLATE_FFILL, INTERPOLATE_LINEAR 섹션을 참조하세요.
한 번의 작업으로 결과 업샘플링, 공백 채우기 및 저장¶
데이터 세트 공백 채우기의 전체 프로세스를 간소화하려면 단일 쿼리 내에서 데이터를 업샘플링하고 값을 보간한 다음, CTAS 작업을 사용하여 결과를 저장하면 됩니다. 예를 들어, 다음 CTAS 문은 측정값을 업샘플링된 데이터 세트로 보간하는 새 테이블을 생성합니다.
참고
리샘플링과 함께 INTERPOLATE 함수를 사용할 때, 윈도우 함수의 OVER(PARTITION BY) 절에 지정하는 열은 일반적으로 RESAMPLE(PARTITION BY) 절의 열과 일치합니다. 이 접근 방식을 사용하면 리샘플링 중에 생성된 것과 동일한 논리 파티션 내에서 보간이 발생합니다. 이전 예제에서 리샘플링은 city 및 ``county``에 의해 분할되지만, INTERPOLATE 함수는 ``city``로만 분할됩니다. 이 예제는 보간이 더 거친 세분성에서 발생하기 때문에 작동하지만, 분할 전략이 데이터 요구 사항에 부합하는지 항상 확인해야 합니다.
ASOF JOIN으로 공백 채우기¶
참고
공백 채우기 및 보간에 권장되는 접근 방식을 사용하려면 시계열 데이터의 공백 채우기 섹션을 참조하세요. RESAMPLE 구문 및 INTERPOLATE 함수는 미리 보기 기능이며 공백 채우기를 위한 다음의 ASOF JOIN 접근 방식은 잠재적인 해결 방법으로만 포함되어 있습니다.
시간 기반 열에서 정확히 일치하지 않는 항목을 찾아 두 테이블의 데이터를 정렬하는 것 외에도, ASOF JOIN은 원시 데이터 테이블에 특정 날짜 또는 타임스탬프에 대한 행이 누락된 경우 시계열의 공백을 채우는 데 유용합니다. 예를 들어, 장비에 결함이 있거나 정전으로 인해 행이 누락되어 센서 판독값을 건너뛰는 경우 ASOF JOIN을 사용하여 생성된 시계열의 값을 테이블로 보간합니다. 누락된 행은 누락된 판독값의 마지막으로 알려진 값으로 채워집니다. 이 값을 “LOCF(이월된 마지막 관측값)”라고도 합니다. ASOF JOIN 쿼리는 시간순으로 되어 있고 연속적인 전체 행 세트를 반환합니다.
보간을 위해 ASOF JOIN을 사용하려면 다음 단계를 따릅니다.
간단한 쿼리를 실행하여 테이블의 차이를 파악합니다.
필요한 기간에 대해 적절한 범위의 완전한 시계열을 생성합니다. 예를 들어, 시계열은 특정 연도에 대한 단순한 날짜 시퀀스일 수 있고, 며칠 동안 초당 타임스탬프의 훨씬 더 세분화된 시퀀스일 수도 있습니다. SQL 또는 스프레드시트 애플리케이션을 사용하여 값 목록을 생성할 수 있습니다.
또한 시계열에는 나중에 ASOF JOIN ON 조건에서 지정할 각 행에 대해 의미 있는 ID 또는 차원도 필요합니다.
누락된 행에 값을 보간하는 ASOF JOIN 쿼리를 작성합니다. 생성된 시계열은 보존 테이블이 되고 원시 데이터 테이블은 참조 테이블이 됩니다.
다음 예제에는 sensor_data_ts 테이블이 필요합니다. 아직 생성하여 로드하지 않은 경우 sensor_data_ts 테이블 만들기 섹션을 참조하십시오. 갭 채우기 작업이 필요한지 시뮬레이션하려면 다음과 같이 테이블에서 일부 행을 삭제합니다.
그 결과, 3월 7일(1:16~1:20)의 DEVICE2 에 대해 5개의 행이 누락된 테이블이 생성됩니다.
이제 다음 단계에 따라 갭 채우기 연습을 완료합니다.
참고
이 예제를 직접 실행하면 무작위로 생성된 값으로 sensor_data_ts 테이블이 로드되므로 출력이 정확히 일치하지 않습니다.
1단계: 테이블에 갭이 있는지 확인¶
다음 쿼리를 실행하여 갭을 식별합니다.
이 쿼리는 DEVICE2 에 대해 2개 행, 즉 공백 앞의 마지막 행과 공백 뒤의 첫 행을 반환합니다.
2단계: 알려진 갭을 채우기 위한 완전한 시계열 생성¶
sensor_data_ts 테이블의 갭에 대해 세밀한 입자(초당 한 행)의 시계열을 생성하려면 생성된 타임스탬프가 포함된 다음 테이블을 만듭니다.
이 SQL 문에서 5 는 갭을 채우는 데 필요한 시간(초)입니다. 디바이스 ID 값(DEVICE2)이 생성된 행에 포함되어 있습니다.
다음 쿼리는 생성된 5개의 행을 반환합니다.
3단계: ASOF JOIN을 사용하여 값 보간¶
이제 continuous_timestamps 를 sensor_data_ts 에 조인하고 DEVICE2 의 누락된 행에 대한 값을 보간하는 ASOF JOIN 쿼리를 실행할 수 있습니다. 일치 조건은 누락된 각 행에 대해 가장 가까운 행을 찾고, ON 조건은 일치하는 디바이스 IDs에서 보간이 수행되도록 보장합니다.
이 예제와 같이 일치 조건에 >= 가 지정되어 있다고 가정할 때 누락된 행에 가장 가까운 행은 2024-03-07 00:01:16.000 타임스탬프가 있는 행입니다.
이 INSERT 문은 ASOF JOIN 연산에서 5개의 행을 선택하여 sensor_data_ts 테이블에 삽입합니다.
보간 결과를 확인하려면 sensor_data_ts 테이블에서 해당 5개 행과 그 바로 앞과 뒤에 있는 2개 행을 선택합니다. 보간된 5개의 행은 2024-03-07 00:01:15.000 행에 기록된 temperature, vibration, motor_rpm 열에 대해 동일한 값을 가져온 것을 확인할 수 있습니다. 보간에 성공했습니다.
시계열 데이터에 ML 기반 함수 적용하기¶
시계열 데이터에 대한 예측 분석을 수행하기 위해 ML Functions를 사용하여 모델을 훈련시킬 수 있습니다.
예측은 과거 시계열 데이터를 사용하여 미래 데이터에 대한 예측을 수행합니다. 과거 날짜와 시간에 대한 실제 관측값이 기록된 시계열이 주어지면 ML 모델은 미래의 날짜와 시간에 대한 관측값이 어떻게 될지 예측합니다.
변칙 감지는 예상 범위에서 벗어나는 데이터 요소인 이상값을 식별합니다. 시계열의 맥락에서 이상값은 비슷한 시간 간격의 다른 측정값보다 훨씬 크거나 작은 측정값입니다. 이상값을 찾기 위해 ML 함수는 이상 징후를 확인하는 동일한 기간에 대한 예측을 생성한 다음 예측 결과를 실제 데이터와 비교합니다.
Top Insights는 데이터 세트에서 가장 중요한 차원을 찾고, 그 차원으로부터 세그먼트를 만들고, 그 세그먼트 중 어떤 세그먼트가 메트릭에 영향을 미쳤는지 감지합니다.
참고
머신 러닝 목적으로 시계열의 타임스탬프는 고정된 시간 간격을 나타내야 합니다. 필요한 경우, 예측 모델을 훈련할 때 TIMESTAMP 열의 DATE_TRUNC 또는 TIME_SLICE 함수를 사용하여 불규칙성을 제거할 수 있습니다.
시계열에서 변칙 감지의 예제¶
다음 예제에서는 행이 30개인 뷰를 사용하여 변칙 감지 모델을 훈련시킵니다. 먼저 테이블에 데이터를 생성한 다음, 테이블에 대한 뷰를 만듭니다. 뷰는 필수는 아니지만(테이블을 사용하여 모델을 훈련시킬 수 있음), 뷰 옵션을 사용하면 원본 데이터를 업데이트하지 않고도 다른 행 개수로 반복적으로 모델을 훈련할 수 있는 유연성을 제공합니다.
참고
이 예제를 직접 실행하면 무작위로 생성된 값으로 sensor_data_30_rows 테이블이 로드되므로 출력이 정확히 일치하지 않습니다.
이제 모델을 생성합니다.
모델이 성공적으로 빌드되면 <model_name>!DETECT_ANOMALIES 메서드를 호출하여 지정된 테스트 데이터 세트에서 이상값을 감지합니다. 테스트 데이터의 타임스탬프는 시간순으로 훈련 데이터의 타임스탬프를 따라야 하지만, 훈련 데이터와 테스트 데이터 사이에 시간적 간격이 너무 커서는 안 됩니다. 예를 들어, 매 초마다 타임스탬프가 있는 경우 훈련 데이터보다 수백만 초 앞선 테스트 데이터를 사용하지 마십시오.
이 예제에서는 3개의 행만 있는 다른 테이블을 테스트 데이터로 사용합니다. 이러한 행의 타임스탬프는 훈련 데이터의 타임스탬프와 거의 동일합니다.
변칙 감지 호출이 완료되면 다음과 유사한 출력이 반환됩니다.
TS 및 Y 열은 테스트 데이터의 타임스탬프와 온도 값을 반환합니다. 이 매우 작은 테스트 케이스에서 함수가 변칙(IS_ANOMALY=True)을 발견했습니다. 출력 열에 대한 자세한 내용은 함수 설명 의 “반환” 섹션을 참조하십시오.
sensor_data_ts 테이블 만들기¶
sensor_data_ts 테이블을 쿼리하는 이 섹션의 예제를 테스트하려면 다음 SQL 스크립트를 실행하여 이 테이블의 복사본을 생성하고 로드할 수 있습니다. 스크립트는 UNIFORM, RANDOM, GENERATOR 함수를 호출하여 센서 판독값에 대한 한 달간의 합성 데이터를 생성하므로 테이블의 복사본은 동일한 결과를 반환하지 않습니다. 판독값은 동일한 범위에 있지만 동일하지는 않습니다.
heavy_weather 테이블 만들기¶
다음 스크립트는 heavy_weather 함수에 대한 예제에서 사용되는 MAX_BY 테이블을 생성하고 로드합니다. 이 테이블에는 2021년 마지막 주 동안 캘리포니아 도시의 강설량 기록이 55개 행으로 포함되어 있습니다.