Analysieren von Zeitreihendaten¶
Sie können in Snowflake Zeitreihendaten analysieren, indem Sie die speziell für diesen Zweck entwickelten Funktionen nutzen. Datenbankadministratoren, Data Scientists und Anwendungsentwickler müssen sicherstellen, dass die Zeitreihen effizient gespeichert und geladen und in vielen Fällen in einer vollständigen und konsistenten Form zusammengefasst werden, bevor sie die Daten für Geschäftsanalysten und andere Verbraucher zur Verfügung stellen.
Einführung in Zeitreihendaten¶
Eine Zeitreihe besteht aus aufeinanderfolgenden Beobachtungen, die erfassen, wie sich Systeme, Prozesse und Verhaltensweisen über einen bestimmten Zeitraum hinweg verändern. Zeitreihendaten werden von einer Vielzahl von Geräten in einer Vielzahl von Branchen gesammelt. Gängige Beispiele sind Aktienhandelsdaten, die für Finanzanwendungen gesammelt werden, Wetterbeobachtungen, Temperaturmessungen, die von Sensoren in intelligenten Fabriken erfasst werden, oder Protokolle der Klicks von Benutzern in der digitalen Werbung.
Ein einzelner Datensatz in einer Zeitreihe besteht in der Regel aus den folgenden Komponenten:
Datum, Uhrzeit oder Zeitstempel mit einer einheitlichen Granularität (Millisekunden, Sekunden, Minuten, Stunden usw.).
Eine oder mehrere Messungen oder Metriken irgendeiner Art, in der Regel numerisch (Fakten, die Trends oder Anomalien in den Daten aufzeigen können).
Dimensionen von Interesse, die mit der Messung verbunden sind, z. B. ein Standort für eine Temperaturmessung oder ein Aktiensymbol für einen bestimmten Handel.
Die folgende Wetterbeobachtung enthält beispielsweise Zeitstempel für Beginn und Ende, eine Niederschlagsmessung (0.32) und Standortinformationen:
Die folgenden von einem Fabrikgerät gesammelten Daten haben einen Namespace (IOT), eine Tag-ID oder Sensor-ID (3000), einen Zeitstempel für den Temperaturmesswert auf dem Gerät, den Temperaturmesswert selbst (21.1673) und einen „Broker-Zeitstempel“, der angibt, wann die Daten anschließend beim Datenbroker angekommen sind. Der Datenbroker könnte zum Beispiel ein Kafka-Server sein, der Daten in eine Snowflake-Tabelle einspeist.
Eine Zeitreihe kann Spitzen aufweisen, wenn sich die Messwerte aus irgendeinem Grund dramatisch verändern. Die folgende Abbildung zeigt zum Beispiel eine Sequenz von Temperaturmessungen, die in 15-Sekunden-Intervallen vorgenommen wurden. Die Werte erreichten Spitzenwerte von über 40 °C, nachdem sie am Vortag konstant im Bereich von 35 °C gelegen hatten.
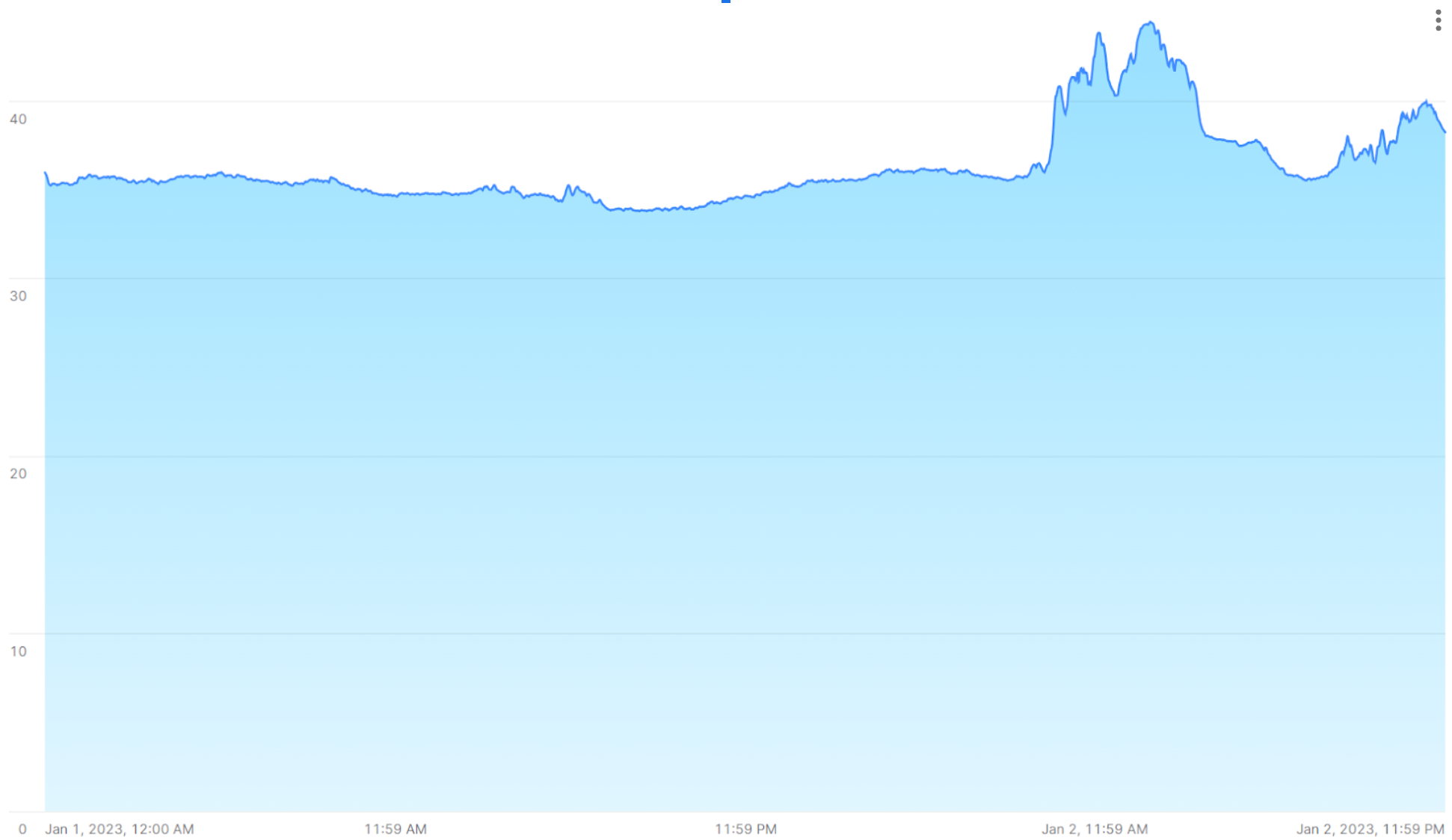
Die folgenden Abschnitte zeigen, wie Sie große Mengen dieser Art von Daten mit SQL-Funktionen und Verknüpfungen (Joins) analysieren und visualisieren können, die schnelle und genaue Ergebnisse liefern.
Speichern von Zeitreihendaten¶
Die folgenden datetime-Datentypen werden unterstützt:
DATE
TIME
TIMESTAMP (und Variationen, einschließlich TIMESTAMP_TZ)
Informationen zum Laden, Verwalten und Abfragen von Daten, die diese Datentypen verwenden, finden Sie unter Verwenden von Datums- und Zeitwerten.
Für das Speichern und Abfragen von Zeitreihendaten gibt es eine Reihe von häufig verwendeten SQL-Funktionen. Sie können zum Beispiel CONVERT_TIMEZONE verwenden, um Zeitstempel von einer Zeitzone in eine andere zu konvertieren, und Sie können Funktionen wie EXTRACT und TIMEADD verwenden, um zeitbasierte Daten nach Bedarf zu bearbeiten.
Bemerkung
Bei TIMESTAMP_TZ-Daten speichert Snowflake zum Zeitpunkt der Erstellung für einen bestimmten Wert nur den Offset einer gegebenen Zeitzone, nicht die Zeitzone selbst.
Um die Abfrageleistung zu optimieren, werden Tabellen, die für Zeitreihenanalysen verwendet werden, oft nach Zeit (und manchmal auch nach Sensor-ID oder einer ähnlichen Dimension) geclustert. Siehe Gruppierungsschlüssel und geclusterte Tabellen.
Aggregieren von Zeitreihendaten¶
Das Verwalten von Zeitreihendaten kann die Aggregation großer Mengen feinkörniger Datensätze in eine besser zusammengefasste Form erfordern (ein Prozess, der manchmal als „Downsampling“ bezeichnet wird). Bei einer großen Menge von Datensätzen mit einer bestimmten zeitlichen Granularität (Millisekunden, Sekunden, Minuten usw.) können Sie diese Datensätze auf eine gröbere Granularität hochrechnen und so effektiv eine kleinere Stichprobe erstellen.
Downsampling ist wertvoll, weil es die Größe eines Datensets und seine Speicheranforderungen verringert. Eine gröbere Granularität reduziert auch den Bedarf an Computeressourcen während der Ausführung der Abfrage. Ein weiterer wichtiger Grund für Downsampling ist, dass eine große Anzahl von Datensätzen in einer Zeitreihe aus Sicht eines Analysten redundant sein kann. Wenn ein Sensor beispielsweise einmal pro Sekunde einen neuen Wert ausgibt, dieser Messwert sich aber innerhalb eines 60-Sekunden-Intervalls kaum ändert, können die Daten zur Analyse auf die Minutenebene zusammengefasst werden.
Ein weiterer Fall für Downsampling tritt auf, wenn zwei verschiedene Datensets als ein einziger analysiert werden müssen, die Datensets jedoch eine unterschiedliche zeitliche Granularität aufweisen. Beispiel: Sensor A sammelt Daten in einer Fabrik alle 15 Sekunden, aber Sensor B sammelt die entsprechenden Daten alle 30 Sekunden. In diesem Fall könnte die Aggregation der Datensätze in 1-Minuten-Buckets eine gute Lösung sein. IDs und Dimensionen in jedem Datenset werden unverändert beibehalten, aber die numerischen Messungen werden summiert oder durch ein gemeinsames Zeitintervall gemittelt.
Beispiele für Downsampling¶
Sie können ein Datenset, das in einer Tabelle gespeichert ist, mit der Funktion TIME_SLICE verkleinern. Diese Funktion berechnet die Start- und Endzeiten von „Buckets“ fester Breite, sodass einzelne Datensätze gruppiert und zusammengefasst werden können, wobei Standardaggregatfunktionen wie SUM und AVG verwendet werden.
In ähnlicher Weise schneidet die Funktion DATE_TRUNC einen Teil einer Reihe von Datums- oder Zeitstempelwerten ab und reduziert so deren Granularität. In den folgenden Abschnitten finden Sie Beispiele für die einzelnen Funktionen.
Downsampling mit TIME_SLICE¶
Das folgende Beispiel zeigt eine Tabelle mit dem Namen sensor_data_ts, die Messwerte von zwei Werkssensoren enthält und 5,3 Millionen Zeilen umfasst. Diese Messwerte wurden pro Sekunde aufgenommen, sodass 5,3 Millionen Zeilen nur einen Monat an Daten darstellen, mit etwas mehr als 2,5 Millionen Zeilen pro Sensor. Sie können die Funktion TIME_SLICE verwenden, um beispielsweise eine Aggregation auf eine einzige Zeile pro Minute, pro Stunde oder pro Tag vorzunehmen.
Um dieses Beispiel auszuführen, erstellen und laden Sie zunächst die Tabelle sensor_data_ts. Informationen dazu finden Sie unter Erstellen der Tabelle „sensor_data_ts“. Hier ist eine kleine Stichprobe der Daten aus der Tabelle:
Die Tabelle enthält 60 Messwerte wie diese pro Minute für jedes Gerät, wie die folgende Abfrage zeigt:
In dieser Downsampling-Abfrage definiert die Funktion TIME_SLICE einminütige Buckets und gibt die Startzeit jedes Buckets zurück. Die Funktion AVG berechnet die durchschnittliche Temperatur für jeden Bucket pro Gerät. Die Funktion COUNT(*) ist nur als Referenz enthalten, um zu zeigen, wie viele Zeilen in jedem Bucket aufgenommen werden.
Die Spalten vibration und motor_rpm sind nicht enthalten, aber sie könnten auf die gleiche Weise wie die Spalte temperature oder durch Verwendung anderer Aggregatfunktionen aggregiert werden.
Wichtig
Wenn Sie dieses Beispiel selbst ausführen, wird Ihre Ausgabe nicht genau übereinstimmen, da die Tabelle sensor_data_ts mit zufällig generierten Werten geladen ist.
Mit der Funktion TIME_SLICE können Sie kleinere, aggregierte Tabellen für Analysezwecke erstellen und den Downsampling-Prozess auf verschiedenen Ebenen (Stunde, Tag, Woche usw.) anwenden.
Downsampling mit DATE_TRUNC¶
Im folgenden Beispiel werden Daten aus einer Tabelle namens order_header im Schema raw.pos der Beispieldatenbank „Tasty Bytes“ ausgewählt. Diese Tabelle enthält 248M Zeilen.
Die Tabelle order_header hat eine TIMESTAMP-Spalte namens order_ts. Die Abfrage erstellt eine aggregierte Zeitreihe, indem diese Spalte als zweites Argument der Funktion DATE_TRUNC verwendet wird. Das erste Argument gibt ein day-Intervall an. Das bedeutet, dass die einzelnen Datensätze, die eine Granularität von Stunden/Minuten/Sekunden haben, zu Tagen zusammengefasst werden.
Die Abfrage gruppiert die Datensätze nach zwei Dimensionen: truck_id und location_id. Die Spalte avg_amount gibt den Durchschnittspreis pro Bestellung, pro Food Truck, pro Standort für jeden erfassten Geschäftstag zurück.
Die hier gezeigte Abfrage beschränkt die Ergebnisse auf die ersten 25 Zeilen für den 1. Januar 2022. Wenn Sie diesen Datumsfilter und die LIMIT-Klausel entfernen, verkleinert die Abfrage die ursprünglichen 248M Zeilen auf etwa 500.000 Zeilen.
Verwenden von fensterbasierten Aggregationen für fortlaufende Berechnungen¶
Mithilfe von fensterbasierten Aggregatfunktionen können Sie beobachten, wie sich eine Kennzahl über die Zeit verändert, und eine Zeitreihe auf Trends hin analysieren. Fensterbasierte Aggregationen sind nützlich für die Analyse von Daten innerhalb definierter Teilmengen („Fenster“) eines größeren Datensets. Sie können fortlaufende Berechnung (wie gleitende Durchschnittswerte und Summen) für jede Zeile in einem Datenset durchführen und dabei eine Gruppe von Zeilen vor, nach oder um die aktuelle Zeile herum berücksichtigen. Diese Art der Analyse steht im Gegensatz zu regulären Aggregationen, die das gesamte Datenset zusammenfassen.
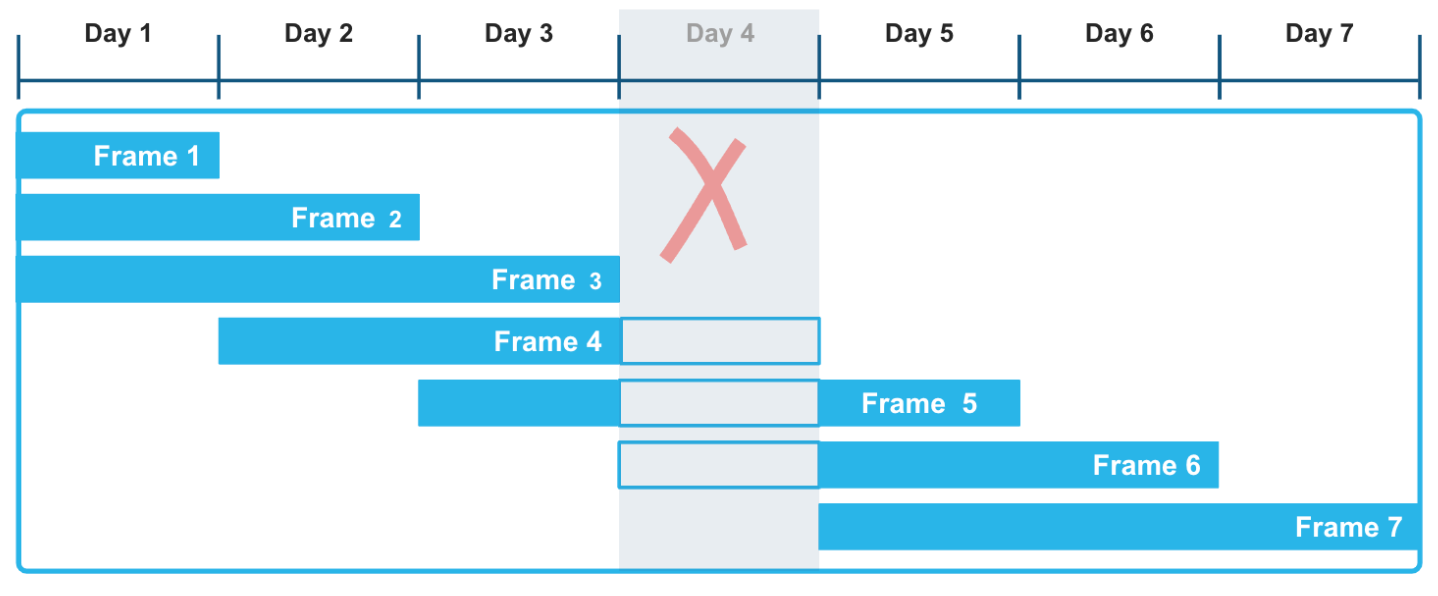
Durch die Verwendung von rangbezogenen Fensterrahmen mit expliziten Offsets können Sie einen sehr flexiblen Ansatz für die Berechnung dieser rollierenden Aggregationen anwenden. Der nach Zeitstempeln oder Zahlen geordnete Fensterrahmen RANGE BETWEEN wird nicht durch Lücken gestört, die in Zeitreihendaten auftreten können. In der folgenden Abbildung zum Beispiel hat die Tatsache, dass die Daten von Day 4 in der Datensatzreihe fehlen, keinen Einfluss auf die Berechnung der Aggregatfunktionen über ein gleitendes Zeitfenster von drei Tagen. Insbesondere die Rahmen 3, 4 und 5 werden korrekt berechnet, wobei berücksichtigt wird, dass die Daten von Day 4 unbekannt sind.
Im folgenden Beispiel wird eine gleitende Summe über Wetterdaten berechnet, die stündliche Niederschlagswerte in verschiedenen Städten und Landkreisen aufzeichnen. Sie können diese Art von Abfrage ausführen, um Trends in verschiedenen Zeitseriendatensätzen auszuwerten, z. B. von Sensoren und anderen IoT-Geräten, insbesondere wenn diese Datensätze bekanntermaßen oder voraussichtlich Lücken aufweisen.
Die Fensterfunktion umfasst in ihrem Rahmen den aktuellen Niederschlagsmesswert und alle Messwerte, die innerhalb des angegebenen Zeitintervalls vor dem aktuellen Messwert liegen. Die fortlaufende Berechnung basiert auf diesem flexiblen und logischen Bereich von Zeilen und nicht auf einer exakten Anzahl von Zeilen. Die erste Zeile für jede Stadt enthält übereinstimmende Werte für precip und moving_sum_precip. Danach wird die Summe für jede nachfolgende Zeile im Rahmen neu berechnet. Die Rohwerte schwanken erheblich, aber die gleitenden Summen haben einen starken Glättungseffekt.
Um dieses Beispiel auszuführen, befolgen Sie zunächst die folgenden Anweisungen: Erstellen und laden Sie die Tabelle heavy_weather. Diese sehr kleine Tabelle enthält sporadische stündliche Wetterbeobachtungen, mit vielen Lücken, einschließlich eines fehlenden Tages. Die Abfrage liefert die gleitende Summe der Niederschlagswerte, geordnet nach der Spalte start_time. Der Fensterrahmen definiert einen Bereich zwischen 12 Stunden vor der aktuellen Zeile und der aktuellen Zeile. Der Rahmen besteht also aus der aktuellen Zeile und nur aus den Zeilen, deren Zeitstempel bis zu 12 Stunden vor dem ORDER BY-Zeitstempel für die aktuelle Zeile liegt.
Die drei moving_sum_precip Werte für Big Bear City werden wie folgt berechnet:
0,42 = 0,42 (keine vorangehenden Zeilen)
0,42 + 0,09 = 0,51 (die ersten beiden Zeilen liegen innerhalb des 12-Stunden-Fensters)
0,07 = 0,07 (keine vorangehenden Zeilen liegen innerhalb des 12-Stunden-Fensters)
Die South Lake Tahoe-Zeilen enthalten zum Beispiel diese Berechnungen:
0,56 + 0,38 + 0,28 + 0,80 = 2,02 (alle vier Zeilen für den 23.12.2024 liegen innerhalb von 12 Stunden voneinander)
0,80 + 0,17 = 0,97 (eine vorangehende Zeile liegt innerhalb des 12-Stunden-Fensters)
Andere Fensterfunktionen, wie die Ranking-Funktionen LEAD und LAG, werden ebenfalls häufig bei Zeitreihenanalysen verwendet. Verwenden Sie die Fensterfunktionen LEAD, um den nächsten Datenpunkt in der Zeitreihe relativ zum aktuellen Datenpunkt zu finden, und die Funktion LAG, um den vorherigen Datenpunkt zu finden.
Visualisierung von Abfrageergebnissen in Snowsight¶
Sie können Snowsight verwenden, um die Ergebnisse von Aggregationsabfragen zu visualisieren und ein besseres Gefühl für den Glättungseffekt von Berechnungen mit gleitenden Fensterrahmen zu erhalten. Klicken Sie im Arbeitsblatt der Abfrage neben Results auf die Schaltfläche Chart.
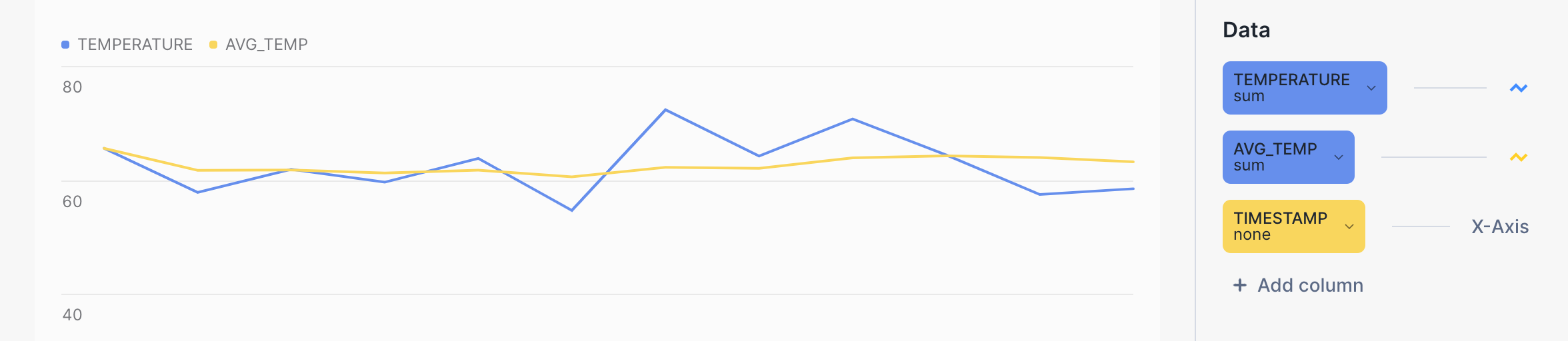
Die gelbe Linie im folgenden Balkendiagramm zeigt zum Beispiel einen viel gleichmäßigeren Trend für die Durchschnittstemperatur als die blaue Linie für den Rohwert der Temperatur. Die Abfrage selbst sieht wie folgt aus:
Verwenden der Aggregatfunktionen MIN_BY und MAX_BY¶
Die Möglichkeit, eine Spalte auf der Grundlage des Minimum- oder Maximumwerts einer anderen Spalte in derselben Zeile auszuwählen, ist eine häufige Anforderung an SQL-Entwickler, die mit Zeitreihendaten arbeiten. MIN_BY und MAX_BY sind Komfortfunktionen, die den Anfangs- und Endwert (oder den höchsten und niedrigsten oder den ersten und letzten) in einer Tabelle zurückgeben, wenn die Daten nach einer anderen Spalte, z. B. einem Zeitstempel, sortiert sind.
Das erste Beispiel sucht einfach den letzten (jüngsten) precip-Wert in der gesamten Tabelle. Die Funktion MAX_BY sortiert alle Zeilen nach ihrem start_time-Wert und gibt dann den precip-Wert für die „maximale“ Startzeit zurück.
Um die in den folgenden Beispielen verwendete Tabelle zu erstellen und zu laden, finden Sie entsprechende Informationen unter Erstellen der Tabelle „heavy_weather“.
Sie können dieses Ergebnis überprüfen (und weitere Informationen darüber erhalten), indem Sie folgende Abfrage ausführen:
Sie können eine GROUP BY-Klausel hinzufügen, um weitere interessante Fragen zu diesen Daten zu stellen. Die folgende Abfrage findet zum Beispiel den letzten Niederschlagswert, der für jeden Ort in Kalifornien beobachtet wurde, geordnet nach precip-Werten (hoch bis niedrig). Die Ergebnisse werden nach city gruppiert, um den letzten precip-Wert für jeden einzelnen Ort zurückzugeben.
Bei der letzten Beobachtung in der Stadt Alta war der precip-Wert 0.89 und bei der letzten Beobachtung in den Städten South Lake Tahoe, Big Bear City, Montague und Lebec war der precip-Wert 0.07 für alle vier Orte. (Beachten Sie, dass die Abfrage Ihnen nicht mitteilt, wann diese Beobachtungen erfasst wurden.)
Mit der Funktion MIN_BY können Sie das „umgekehrte“ Resultset zurückgeben (ältester precip-Datensatz versus jüngster).
Verknüpfen von Zeitreihendaten¶
Sie können das ASOF JOIN-Konstrukt verwenden, um Tabellen zu verknüpfen, die Zeitreihendaten enthalten. Obwohl ASOF JOIN-Abfragen durch die Verwendung von komplexer SQL, anderen Typen von Joins und Fensterfunktionen emuliert werden können, sind diese Abfragen einfacher zu schreiben (und oft leistungsfähiger), wenn Sie die ASOF JOIN-Syntax verwenden.
Eine häufige Anwendung für ASOF-Joins ist die Analyse von Finanzhandelsdaten. Für die Transaktionskostenanalyse sind beispielsweise „Slippage“-Berechnungen erforderlich, mit denen die Differenz zwischen dem zum Zeitpunkt der Kaufentscheidung einer Aktie notierten Kurs und dem tatsächlich gezahlten Preis bei Ausführung und Verbuchung der Order gemessen wird. Mit ASOF JOIN können diese Typen von Analysen beschleunigt werden. Da die Hauptfähigkeit dieser Join-Methode in der Analyse einer Zeitreihe in Bezug auf eine andere besteht, kann ASOF JOIN für die Analyse jedes beliebigen historischen Datensets nützlich sein. In vielen dieser Anwendungsfälle kann ASOF JOIN verwendet werden, um Daten zuzuordnen, wenn die Zeitstempel der Messwerte verschiedener Geräte nicht exakt übereinstimmen.
Es wird davon ausgegangen, dass die zu analysierenden Zeitreihendaten in zwei Tabellen vorliegen und dass es für jede Zeile in jeder Tabelle einen Zeitstempel gibt. Dieser Zeitstempel gibt das genauen („as of“) Zeitpunkt (Datum und Uhrzeit) für ein erfasstes Ereignis an. Für jede Zeile in der ersten (oder linken) Tabelle verwendet die Verknüpfung eine „Übereinstimmungsbedingung“ mit einem Vergleichsoperator, den Sie angeben, um eine einzelne Zeile in der zweiten (oder rechten) Tabelle zu finden, bei der der Zeitstempelwert eines der folgenden Merkmale aufweist:
Kleiner als oder gleich dem Zeitstempelwert in der linken Tabelle
Größer als oder gleich dem Zeitstempelwert in der linken Tabelle
Kleiner als der Zeitstempelwert in der linken Tabelle
Größer als der Zeitstempelwert in der linken Tabelle
Die passende Zeile auf der rechten Seite ist die mit der besten Übereinstimmung, deren Zeitpunkt gleich, früher oder später liegen kann, je nach dem angegebenen Vergleichsoperator.
Die Kardinalität des Ergebnisses von ASOF JOIN ist immer gleich der Kardinalität der linken Tabelle. Wenn die linke Tabelle 40 Millionen Zeilen enthält, gibt ASOF JOIN 40 Millionen Zeilen. Daher kann die linke Tabelle als „bewahrende“ Tabelle und die rechte Tabelle als „referenzierte“ Tabelle gedacht werden.
Verknüpfen zweier Tabellen anhand der engsten Übereinstimmung (Alignment)¶
In einer Finanzanwendung könnten Sie zum Beispiel eine Tabelle namens quotes und eine Tabelle namens trades haben. In der einen Tabelle wird die Historie der Kaufangebote für Aktien erfasst, in der anderen die Historie des tatsächlichen Handels. Ein Angebot zum Kauf von Aktien erfolgt vor dem Handel (oder möglicherweise zur „gleichen“ Zeit, je nach Granularität der erfassten Zeit). Beide Tabellen enthalten Zeitstempel, und beide enthalten andere Spalten von Interesse, die Sie vielleicht vergleichen möchten. Eine einfache ASOF JOIN-Abfrage liefert den (zeitlich) nächstgelegenen Aktienkurs vor dem jeweiligen Handel. Mit anderen Worten, die Frage lautet: Wie hoch war der Kurs einer bestimmten Aktie zu dem Zeitpunkt, als ich einen Handel tätigte?
Angenommen, die Tabelle trades enthält drei Zeilen und die Tabelle quotes enthält sieben Zeilen. Die Hintergrundfarbe der Zellen zeigt an, welche drei Zeilen aus quotes für ASOF JOIN in Frage kommen, wenn die Zeilen bei übereinstimmenden Aktiensymbolen verknüpft und ihre Zeitstempelspalten verglichen werden.
Tabelle TRADES (linke oder „bewahrende“ Tabelle)
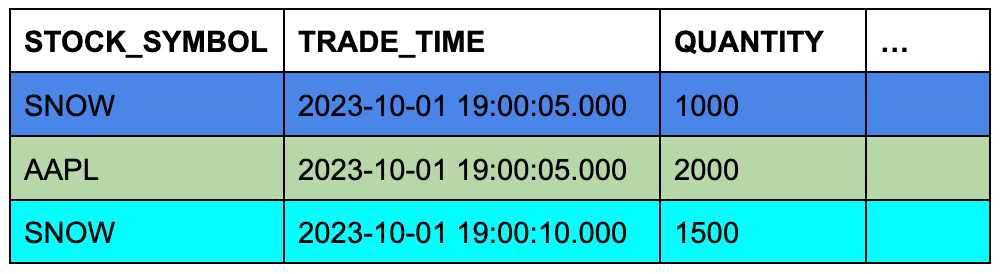
Tabelle QUOTES (rechte oder „referenzierte“ Tabelle)
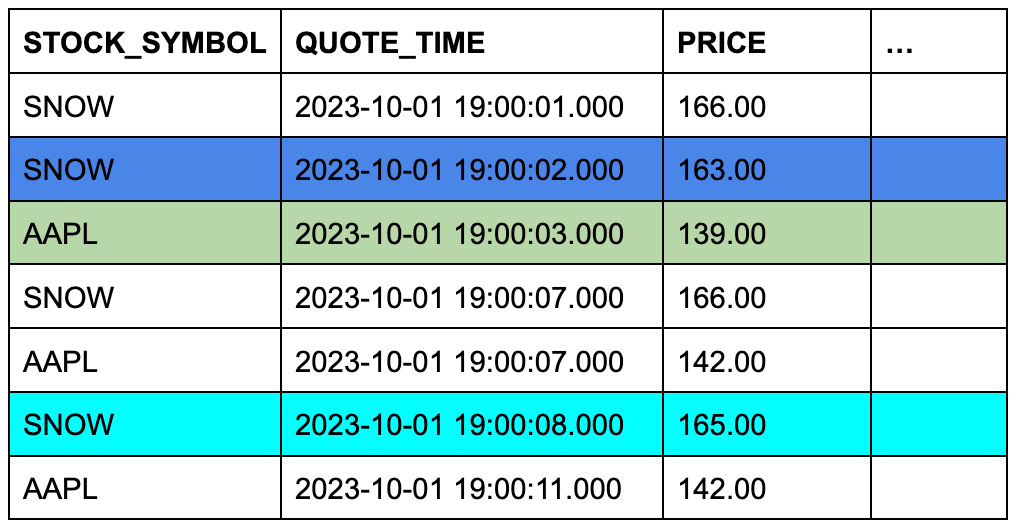
Dieses konzeptionelle Beispiel lässt sich leicht in eine konkrete ASOF JOIN-Abfrage umwandeln:
Die ON-Bedingung gruppiert die übereinstimmenden Zeilen nach ihren Aktiensymbolen.
Um dieses Beispiel auszuführen, erstellen und laden Sie die Tabellen wie folgt:
Weitere Beispiele für ASOF JOIN-Abfragen finden Sie unter Beispiele.
Füllen von Lücken in Zeitreihendaten¶
Zeitreihenanalysen erfordern oft Daten mit einer konsistenten Granularität und Aufzeichnungen für jedes Intervall, doch Daten aus der realen Welt kommen oft in unregelmäßigen Abständen oder enthalten Lücken. Beispielsweise könnten Sie über einen Datensatz verfügen, der überwiegend stündliche Daten enthält, Sie müssen aber Einträge für halbstündliche Daten generieren, um eine Übereinstimmung mit nachgelagerten Analysen zu erzielen, oder Sie verfügen bereits über eine konsistente Auflösung, entdecken jedoch Lücken in der Reihe. Die Snowflake-Funktion zum Füllen von Lücken bietet effiziente Möglichkeiten, ein einheitliches Intervall auf Zeitreihendaten anzuwenden und Lücken zu füllen.
Sehen Sie sich zum Beispiel die folgenden acht Datensätze an, die Wetterbeobachtungen für zwei Orte in Kalifornien am 15. März 2025 erfassen.
Obwohl diese Datensätze eine etwas konsistente Granularität (Tag, Stunde, Minute) haben, sind die Intervalle zwischen den Zeilen inkonsistent und variieren zwischen 1 und 15 Minuten. Wenn das Ziel darin besteht, Daten im Fünf-Minuten-Intervall zu sammeln, fehlen einige Zeilen.
Verwenden der RESAMPLE-Klausel¶
Sie können die Granularität ändern und die Konsistenz eines Satzes von Zeilen verbessern, indem Sie ein „Upsampling“ für ein bestimmtes Zeitintervall vornehmen. Um diese Art der Änderung vorzunehmen, verwenden Sie die Klausel RESAMPLE, die Sie innerhalb der FROM-Klausel einer SELECT-Anweisung definieren. Das Ergebnis eines neu gesampelten Datensets ist ein größeres Datenset, das alle vorhandenen Eingabezeilen beibehält und eine Anzahl neuer Zeilen mit Werten erzeugt, die Lücken in der Zeitreihe füllen. (Beachten Sie, dass Sie auch die Klausel RESAMPLE zum „Downsampling“ von Zeilen in ein kleineres, gröberes Resultset verwenden können.)
Per Definition hat eine Zeitreihe immer eine Spalte, die eine Sequenz von Datumsangaben, Zeitstempeln oder numerischen Werten enthält, die Daten oder Uhrzeiten darstellen. Das Resampling wird auf einer solchen Spalte der Quelltabelle ausgeführt, und die erforderliche Granularität muss mit einem INTERVAL-Wert angegeben werden, z. B. 5 minutes, 30 minutes oder 1 hour.
Normalerweise definieren Sie auch Partitionen, die Zeitreihenzeilen über bestimmte Dimensionen erstellen, anstatt nur einen neuen Zeitstempel pro Intervall zu generieren.
Die Struktur einer RESAMPLE-Abfrage sieht wie folgt aus:
Die Spalten in den generierten Zeilen werden auf NULL gesetzt, mit Ausnahme der in den Klauseln USING und PARTITION BY angegebenen Spalten. Die angegebene Datums-, Uhrzeit- oder numerische Spalte sowie die Partitionierungsspalten enthalten aussagekräftige generierte Werte.
Bemerkung
Wenn Sie planen, Ihre neu gesampelten Daten nach bestimmten Werten zu filtern (z. B. nach einer bestimmten Geräte-ID oder einem Speicherort), nehmen Sie diese Spalten in die PARTITION BY-Klausel auf. Dadurch wird sichergestellt, dass die generierten Zeilen tatsächliche Werte für diese Spalten haben und nicht NULL-Werte. Wenn Sie mit einer WHERE-Klausel nach Spalten filtern, die nicht in der PARTITION BY-Klausel enthalten sind, filtert die WHERE-Klausel alle generierten Zeilen für diese Spalten heraus, da sie NULL-Werte enthalten.
Um ein einfaches Beispiel auszuführen, das die acht zuvor gezeigten Datensätze verwendet, beginnen Sie mit dem Erstellen und Laden der folgenden Tabelle:
Wählen Sie nun upgesampelte Zeilen aus dieser Tabelle aus, wobei Sie ein Intervall von 5 minutes verwenden:
Diese Abfrage behält die ursprünglichen acht Zeilen bei und generiert drei neue Zeilen, was die Lücken für drei Zeitintervalle, um 09:45, 10:00 und 10:05, füllt. NULL-Werte werden in die Spalten temperature, city und county eingefügt.
Der Startpunkt für die Zeitreihe ist 2025-03-15 09:45:00.000, da er innerhalb von 5 Minuten nach dem frühesten Zeitstempel in den Eingabedaten liegt (2025-03-15 09:49:00.000).
Wenn Sie Zeilen entfernen möchten, die nicht in gleichmäßigen Abständen auftreten (in diesem Fall``09:49`` und 10:18), lesen Sie RESAMPLE-Beispiel, das BUCKET_START() zum Herausfiltern uneinheitlicher Zeilen verwendet.
Fügen Sie der Abfrage nun eine PARTITION BY-Klausel hinzu:
Die partitionierten Ergebnisse unterscheiden sich in zwei Punkten:
Es werden sieben Zeilen für insgesamt 15 Zeilen generiert. Jetzt gibt es für jedes 5-Minuten-Intervall für jede Partition eine Zeile.
Die Partitionierungsspalten haben die Werte
cityundcountykorrekt generiert. Die einzige Spalte, die über NULL-Werte in den generierten Zeilen verfügt, isttemperature.
Sie können auch den Parameter METADATA_COLUMNS in der RESAMPLE-Syntax angeben, um die folgenden Spalten zum Ergebnis hinzuzufügen:
Die Metadatenspalte
is_generatedgibt die Zeilen an, die von der Operation RESAMPLE generiert wurden, sowie die bereits vorhandenen Zeilen.Die Metadatenspalte
bucket_startgibt den Wert zurück, der den Beginn des aktuellen Buckets oder Intervalls markiert, das die RESAMPLE-Operation erzeugt. Sie können diese Spalte verwenden, um anzugeben, zu welchem Intervall eine bestimmte Zeile nach dem Resampling gehört. Außerdem können Sie sie verwenden, um aggregierte Abfragen auf den neu gesampelten Daten durchzuführen. Siehe RESAMPLE-Beispiel, das BUCKET_START() zum Aggregieren neu gesampelter Zeilen verwendet.
Die vollständige RESAMPLE-Syntax finden Sie unter RESAMPLE.
Zum Speichern der Ergebnisse einer RESAMPLE-Abfrage verwenden Sie eine CTAS-Anweisung, die die Daten auswählt und in eine neue Tabelle einfügt:
Interpolieren oder „Lückenfüllen“ von Werten in eine Zeitreihe¶
Sie können die RESAMPLE-Syntax und die Interpolationsfunktionen zwar unabhängig voneinander nutzen, sie werden jedoch am häufigsten zusammen verwendet, um Lücken in Zeitreihendaten im Rahmen einer einzigen Abfrage zu füllen. Nachdem Sie Ihr Datenset einem erneuten Sampling unterzogen haben, können Sie eine Interpolationsfunktion aufrufen, um die anderen Spalten von Interesse in den neu generierten Zeilen zu aktualisieren. Durch den Interpolationsprozess werden Spalten aktualisiert, die zuvor NULL waren, wie z. B. numerische Messungen. Dadurch erhalten sie aussagekräftige Werte, die auf den Werten basieren, die in den vorangegangenen oder nachfolgenden Zeilen gefunden wurden.
Sie können Werte interpolieren, indem Sie die Fensterfunktionen INTERPOLATE_FFILL, INTERPOLATE_BFILL und INTERPOLATE_LINEAR aufrufen. Die Funktion INTERPOLATE_FFILL findet z. B. den vorherigen (letzten) Wert in der Zeitreihe für die betreffende Spalte:
Die erste Zeile gibt NULL für die Spalte ffill_temp zurück, da es keine vorherige Zeile für die INTERPOLATE_FFILL-Funktion gibt, die herangezogen werden könnte.
Weitere Informationen zu diesen Fensterfunktionen finden Sie unter INTERPOLATE_BFILL, INTERPOLATE_FFILL, INTERPOLATE_LINEAR.
Upsampling, Lückenfüllen und Speichern der Ergebnisse in einer Operation¶
Um den gesamten Prozess des Füllens von Lücken in einem Datenset zu vereinfachen, können Sie ein Upsampling der Daten und eine Interpolation der Werte innerhalb einer einzelnen Abfrage durchführen und die Ergebnisse mithilfe einer CTAS-Operation speichern. Zum Beispiel erstellt die folgende CTAS-Anweisung eine neue Tabelle, die Messungen in ein upgesampeltes Datenset interpoliert:
Bemerkung
Wenn Sie INTERPOLATE-Funktionen mit Resampling verwenden, stimmen die Spalten, die Sie in der OVER-Klausel (PARTITION BY) für Fensterfunktionen angeben, normalerweise mit den Spalten in der RESAMPLE-Klausel (PARTITION BY) überein. Dieser Ansatz stellt sicher, dass die Interpolation innerhalb derselben logischen Partitionen erfolgt, die beim Resampling erstellt wurden. Im vorherigen Beispiel wird das Resampling durch city und county partitioniert, während dieINTERPOLATE-Funktionen nur nach city partitionieren. Dieses Beispiel funktioniert, weil die Interpolation mit einer gröberen Granularität erfolgt. Sie sollten jedoch immer sicherstellen, dass die Partitionierungsstrategie mit Ihren Datenanforderungen übereinstimmt.
Auffüllen von Lücken mit ASOF JOIN¶
Bemerkung
Informationen zur Verwendung des empfohlenen Ansatzes für das Füllen von Lücken und die Interpolation finden Sie unter Füllen von Lücken in Zeitreihendaten. Das RESAMPLE-Konstrukt und die INTERPOLATE-Funktionen sind Vorschau-Features; der folgende ASOF JOIN-Ansatz zum Füllen von Lücken ist nur als mögliche Problemumgehung enthalten.
Zusätzlich zum Abgleichen der Daten in zwei Tabellen anhand der Suche nach nicht exakten Übereinstimmungen in zeitbasierten Spalten ist ASOF JOIN nützlich, um Lücken in einer Zeitreihe zu füllen, wenn in Ihrer Rohdatentabelle Zeilen für bestimmte Daten oder Zeitstempel fehlen. Wenn beispielsweise Zeilen fehlen, weil fehlerhafte Geräte oder ein Stromausfall zu übersprungenen Sensormesswerten führen, können Sie ASOF JOIN verwenden, um Werte aus einer generierten Zeitreihe in die Tabelle zu interpolieren. Die fehlenden Zeilen werden mit dem letzten bekannten Wert für die fehlenden Messwerte aufgefüllt. Dieser Wert wird auch als „letzte übertragene Beobachtung“ (LOCF, Last Observation Carried Forward) bezeichnet. Die ASOF JOIN-Abfrage gibt einen vollständigen Satz von Zeilen zurück, die in chronologischer Reihenfolge und zusammenhängend sind.
Um ASOF JOIN für die Interpolation zu verwenden, gehen Sie wie folgt vor:
Identifizieren Sie die Lücken in Ihrer Tabelle, indem Sie eine einfache Abfrage durchführen.
Generieren Sie eine vollständige Zeitreihe mit der entsprechenden Körnung für den Zeitraum, den Sie abdecken möchten. Ihre Zeitreihe könnte beispielsweise eine einfache Sequenz von Daten für ein bestimmtes Jahr sein oder eine viel feinere Sequenz von Zeitstempeln pro Sekunde für eine bestimmte Anzahl von Tagen. Sie können SQL oder ein Tabellenkalkulationsprogramm verwenden, um die Liste der Werte zu generieren.
Die Zeitreihe benötigt außerdem eine aussagekräftige ID oder Dimension für jede Zeile, die Sie später in der ASOF JOIN ON-Bedingung angeben werden.
Schreiben Sie eine ASOF JOIN-Abfrage, die Werte in die fehlenden Zeilen interpoliert. Die generierte Zeitreihe ist die bewahrende Tabelle und die Rohdatentabelle ist die referenzierte Tabelle.
Für das folgende Beispiel benötigen Sie die Tabelle sensor_data_ts. Falls Sie diese noch nicht erstellt und geladen haben, finden Sie entsprechende Informationen unter Erstellen der Tabelle „sensor_data_ts“. Um die Notwendigkeit für eine Lückenfüller-Operation zu simulieren, löschen Sie einige Zeilen wie folgt aus der Tabelle:
Das Ergebnis ist eine Tabelle, in der fünf Zeilen für DEVICE2 am 7. März (1:16 bis 1:20) fehlen.
Führen Sie nun die folgenden Schritte aus, um die Lücken zu füllen.
Bemerkung
Wenn Sie dieses Beispiel selbst ausführen, wird Ihre Ausgabe nicht genau übereinstimmen, da die Tabelle sensor_data_ts mit zufällig generierten Werten geladen ist.
Schritt 1: Überprüfen, ob die Tabelle Lücken hat¶
Führen Sie die folgende Abfrage aus, um die Lücken zu identifizieren:
Diese Abfrage gibt zwei Zeilen für DEVICE2 zurück: die letzte Zeile vor der Lücke und die erste Zeile nach der Lücke.
Schritt 2: Generieren einer vollständigen Zeitreihe, um die bekannten Lücken abzudecken¶
Um eine Zeitreihe mit feiner Körnung (eine Zeile pro Sekunde) für die Lücke in der Tabelle sensor_data_ts zu generieren, erstellen Sie die folgende Tabelle, die generierte Zeitstempel enthält:
In dieser SQL-Anweisung steht 5 für die Anzahl der Sekunden, die Sie benötigen, um die Lücke zu schließen. Beachten Sie, dass der Wert für die Gerät-ID (DEVICE2) in den generierten Zeilen enthalten ist.
Die folgende Abfrage gibt die fünf generierten Zeilen zurück.
Schritt 3: Interpolieren der Werte mit ASOF JOIN¶
Jetzt können Sie eine ASOF JOIN-Abfrage ausführen, die continuous_timestamps mit sensor_data_ts verknüpft und Werte für fehlende Zeilen für DEVICE2 interpoliert. Die Übereinstimmungsbedingung findet für jede fehlende Zeile die zeitlich nächstgelegene Zeile, und die ON-Bedingung garantiert, dass die Interpolation auf übereinstimmenden Gerät-IDs erfolgt.
Die Zeile, die den fehlenden Zeilen am nächsten kommt, ist die Zeile mit dem Zeitstempel 2024-03-07 00:01:16.000, vorausgesetzt, dass >= in der Übereinstimmungsbedingung angegeben ist, wie in diesem Beispiel gezeigt.
Diese INSERT-Anweisung wählt fünf Zeilen aus der ASOF JOIN-Operation aus und fügt sie in die Tabelle sensor_data_ts ein.
Um die Ergebnisse der Interpolation zu überprüfen, markieren Sie in der Tabelle sensor_data_ts diese fünf Zeilen sowie die beiden Zeilen, die ihnen direkt vorausgehen bzw. nachfolgen. Beachten Sie, dass die fünf interpolierten Zeilen die Werte der Spalten temperature, vibration und motor_rpm unverändert übernommen haben, die in der Zeile 2024-03-07 00:01:15.000 erfasst wurden. Die Interpolation war erfolgreich.
Anwenden von ML-basierten Funktionen auf Zeitreihendaten¶
Sie können mit ML-Funktionen ein Modell trainieren, um eine prädiktive Analyse von Zeitreihendaten durchzuführen:
Bei der Prognoseerstellung werden historische Zeitreihendaten verwendet, um Vorhersagen über zukünftige Daten zu treffen. Ausgehend von einer erfassten Zeitreihe mit tatsächlich beobachteten Werten mit Zeitpunkten in der Vergangenheit prognostiziert das ML-Modell, wie die beobachteten Werte für Zeitpunkte in der Zukunft aussehen könnten.
Bei der Anomalieerkennung werden Ausreißer identifiziert, d. h. Datenpunkte, die von einem erwarteten Bereich abweichen. Im Zusammenhang mit einer Zeitreihe ist ein Ausreißer eine Messung, die viel größer oder kleiner ist als andere Messungen in einem ähnlichen Zeitintervall. Um Ausreißer zu finden, erstellt die ML-Funktion eine Prognose für den Zeitraum, der auf Anomalien geprüft wird, und vergleicht dann die Prognoseergebnisse mit den tatsächlichen Daten.
Top Insights findet die wichtigsten Dimensionen in einem Datenset, erstellt Segmente aus diesen Dimensionen und erkennt, welche dieser Segmente eine Kennzahl beeinflusst haben.
Bemerkung
Für die Zwecke des maschinellen Lernens müssen die Zeitstempel in Ihren Zeitreihen feste Zeitintervalle darstellen. Falls erforderlich, können Sie die Funktion DATE_TRUNC oder TIME_SLICE auf TIMESTAMP-Spalten anwenden, um Unregelmäßigkeiten beim Training des Prognosemodells zu entfernen.
Beispiel für die Anomalieerkennung in einer Zeitreihe¶
Das folgende Beispiel verwendet eine Ansicht mit nur 30 Zeilen, um ein Anomalieerkennungsmodell zu trainieren. Beginnen Sie mit dem Generieren von Daten in einer Tabelle, und erstellen Sie dann eine Ansicht auf diese Tabelle. Die Ansicht ist nicht erforderlich (Sie können eine Tabelle verwenden, um ein Modell zu trainieren), aber die Ansichtsoption gibt Ihnen eine gewisse Flexibilität, um Modelle iterativ zu trainieren, mit unterschiedlichen Zeilenzahlen und ohne die Quelldaten aktualisieren zu müssen.
Bemerkung
Wenn Sie dieses Beispiel selbst ausführen, wird Ihre Ausgabe nicht genau übereinstimmen, da die Tabelle sensor_data_30_rows mit zufällig generierten Werten geladen ist.
Erstellen Sie nun das Modell:
Wenn das Modell erfolgreich erstellt wurde, rufen Sie die Methode <Name_des_Modells>!DETECT_ANOMALIES auf, um Ausreißer in dem angegebenen Test-Datenset zu erkennen. Die Zeitstempel in den Testdaten müssen chronologisch auf die Zeitstempel in den Trainingsdaten folgen, aber es darf kein zu großer zeitlicher Abstand zwischen den Trainingsdaten und den Testdaten bestehen. Wenn Sie zum Beispiel Zeitstempel für jede Sekunde haben, sollten Sie keine Testdaten verwenden, die den Trainingsdaten um Millionen von Sekunden voraus sind.
In diesem Beispiel wird eine andere Tabelle als Testdaten verwendet, die nur drei Zeilen enthält. Diese Zeilen haben Zeitstempel, die denen in den Trainingsdaten sehr nahe kommen.
Wenn der Aufruf der Anomalieerkennung beendet ist, gibt er eine Ausgabe ähnlich der folgenden zurück:
Die Spalten TS und Y geben die Zeitstempel bzw. Temperaturwerte aus den Testdaten zurück. In diesem sehr kleinen Testfall fand die Funktion eine Anomalie (IS_ANOMALY=True). Weitere Informationen zu den Ausgabespalten finden Sie im Abschnitt „Rückgabewerte“ der Funktionsbeschreibung.
Erstellen der Tabelle „sensor_data_ts“¶
Wenn Sie die Beispiele in diesem Abschnitt, bei denen die Tabelle sensor_data_ts abgefragt wird, testen möchten, können Sie eine Kopie dieser Tabelle erstellen und laden, indem Sie das folgende SQL-Skript ausführen. Das Skript generiert einen Monat lang synthetische Daten für Sensormesswerte, indem es die Funktionen UNIFORM, RANDOM und GENERATOR aufruft. Daher wird Ihre Kopie der Tabelle keine identischen Ergebnisse liefern. Die Messwerte liegen im gleichen Bereich, aber sie sind nicht gleich.
Erstellen der Tabelle „heavy_weather“¶
Das folgende Skript erstellt und lädt die Tabelle heavy_weather, die in den Beispielen für die MAX_BY-Funktionen verwendet wird. Die Tabelle enthält 55 Zeilen mit Niederschlagsdaten für kalifornische Orte in der letzten Woche des Jahres 2021.