Analyse des données de séries temporelles¶
Vous pouvez analyser des données de séries temporelles dans Snowflake, à l’aide d’une fonctionnalité spécialement conçue à cet effet. Les administrateurs de bases de données, les scientifiques des données et les développeurs d’applications doivent s’assurer que les séries temporelles sont stockées et chargées efficacement et, dans de nombreux cas, résumées sous une forme complète et cohérente, avant de mettre les données à la disposition des analystes commerciaux et d’autres consommateurs.
Introduction aux données de séries temporelles¶
Une série temporelle est constituée d’observations séquentielles qui rendent compte de l’évolution des systèmes, des processus et des comportements au cours d’une période donnée. Les données de séries temporelles sont collectées à partir d’un large éventail de dispositifs dans un grand nombre de secteurs. Parmi les exemples courants, on peut citer les données boursières collectées pour les applications financières, les observations météorologiques, les relevés de température collectés par des capteurs dans les usines intelligentes et les journaux des clics des utilisateurs dans la publicité numérique.
Un enregistrement unique dans une série temporelle comporte généralement les éléments suivants :
Une date, une heure ou un horodatage ayant un niveau de granularité cohérent (millisecondes, secondes, minutes, heures, etc.).
Une ou plusieurs mesures ou métriques quelconques, généralement numériques (faits susceptibles de révéler des tendances ou des anomalies dans les données).
Dimensions d’intérêt associées à la mesure, telles que l’emplacement d’un relevé de température ou le symbole d’une action pour une transaction donnée.
Par exemple, l’observation météorologique suivante comporte des horodatages de début et de fin, une mesure des précipitations (0.32) et des informations sur le lieu :
Les données suivantes, collectées à partir d’un appareil industriel, ont un espace de noms (IOT), un ID de balise ou un ID de capteur (3000), un horodatage pour la lecture de la température sur l’appareil, la lecture de la température elle-même (21.1673), et un « horodatage du courtier », qui est le moment où les données sont arrivées par la suite au courtier en données. Par exemple, le courtier de données peut être un serveur Kafka qui ingère des données dans une table Snowflake.
Une série temporelle peut révéler des pics lorsque les relevés changent radicalement pour une raison ou une autre. Par exemple, l’image suivante montre une séquence de relevés de température effectués à 15 secondes d’intervalle, avec des valeurs culminant à plus de 40 °C après avoir été constamment dans la plage des 35 °C pendant la journée précédente.
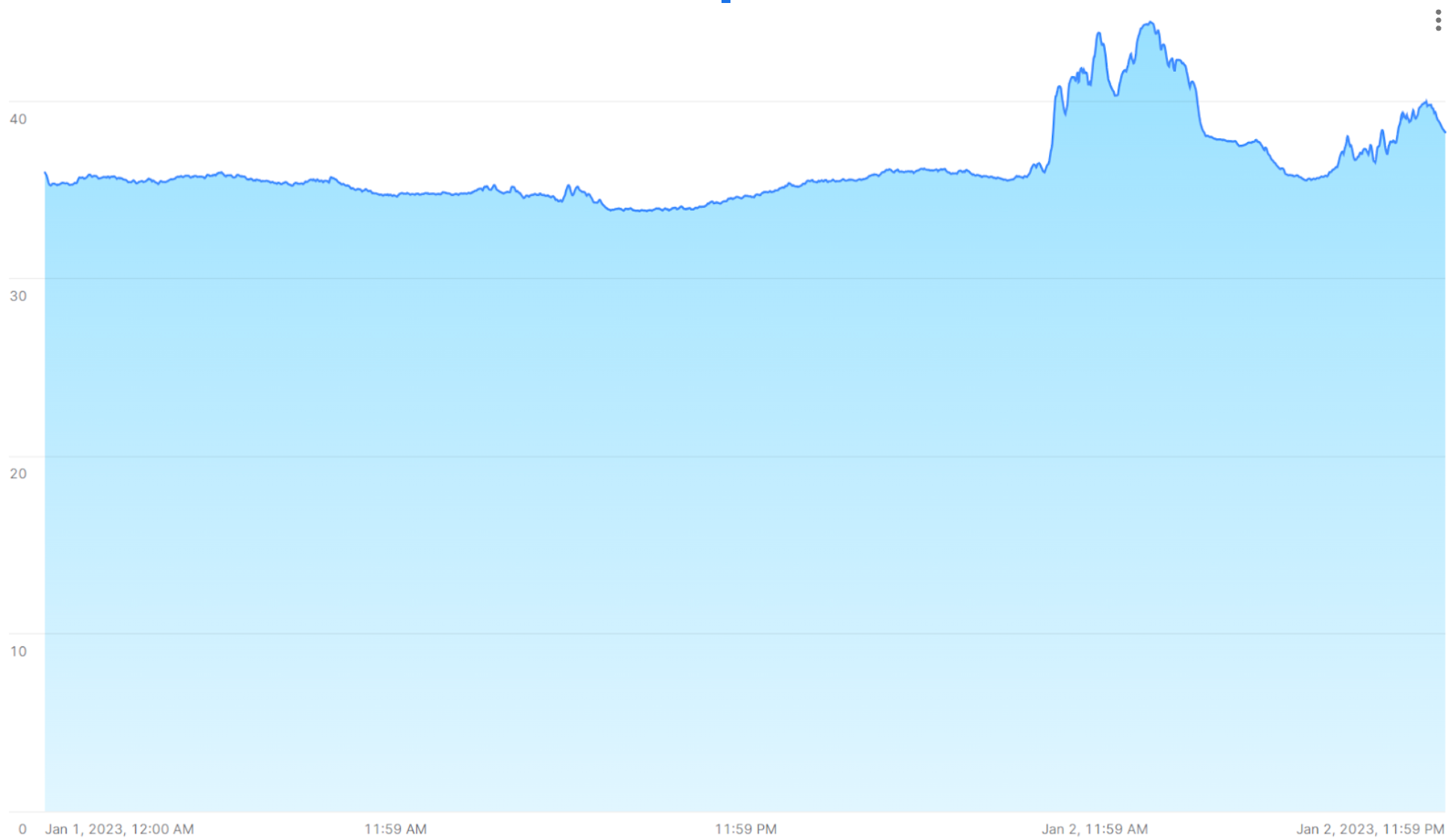
Les sections suivantes montrent comment analyser et visualiser de grands volumes de ce type de données à l’aide de fonctions SQL et de jointures qui fournissent des résultats rapides et précis.
Stockage de données de séries temporelles¶
Les types de données datetime suivants sont pris en charge :
DATE
TIME
TIMESTAMP (et variantes, y compris TIMESTAMP_TZ)
Pour obtenir des informations sur le chargement, la gestion et l’interrogation de données utilisant ces types de données, consultez Utilisation des valeurs de date et d’heure.
Un certain nombre de fonctions SQL couramment utilisées sont disponibles pour faciliter le stockage et la requête de données de séries temporelles. Par exemple, vous pouvez utiliser CONVERT_TIMEZONE pour convertir les horodatages d’un fuseau horaire à un autre et vous pouvez utiliser des fonctions telles que EXTRACT et TIMEADD pour manipuler les données temporelles selon vos besoins.
Note
Pour les données TIMESTAMP_TZ, Snowflake ne stocke actuellement que le décalage d’un fuseau horaire au moment de la création d’une valeur donnée et non le fuseau horaire réel.
Pour optimiser les performances des requêtes, les tables utilisées pour les analyses de séries temporelles sont souvent mises en cluster en fonction du temps (et parfois aussi en fonction de l’ID du capteur ou d’une dimension similaire). Voir Clés de clustering et tables en cluster.
Agrégation de données de séries temporelles¶
La gestion des données de séries temporelles peut nécessiter l’agrégation de grands volumes d’enregistrements fins sous une forme plus synthétique (un processus parfois appelé « sous-échantillonnage » ou « downsampling »). Si vous disposez d’un grand nombre d’enregistrements avec une granularité temporelle spécifique (millisecondes, secondes, minutes, etc.), vous pouvez regrouper ces enregistrements à une granularité plus grossière, ce qui permet d’obtenir un échantillon plus petit.
Le sous-échantillonnage est utile, car il permet de réduire la taille d’un ensemble de données et ses besoins en stockage. Un niveau de granularité plus grossier réduit également les besoins en ressources de calcul pendant l’exécution de la requête. Une autre raison clé du sous-échantillonnage est qu’un grand nombre d’enregistrements dans une série temporelle peut être redondant du point de vue de l’analyste. Par exemple, si un capteur émet une nouvelle valeur une fois par seconde, mais que cette mesure change rarement dans chaque intervalle de 60 secondes, les données peuvent être remontées au niveau de la minute pour être analysées.
Un autre cas pour le sous-échantillonnage se produit lorsque deux ensembles de données différents doivent être analysés comme un seul, mais qu’ils ont des granularités temporelles différentes. Par exemple, le capteur A d’une usine collecte des données toutes les 15 secondes, mais le capteur B collecte des données connexes toutes les 30 secondes. Dans ce cas, l’agrégation des enregistrements en compartiments d’une minute peut être une bonne solution. Les IDs et les dimensions de chaque ensemble de données sont conservés tels quels, mais les mesures numériques sont additionnées ou moyennées par un intervalle de temps commun.
Exemples de sous-échantillonnage¶
Vous pouvez réduire l’échantillonnage d’un ensemble de données stockées dans une table en utilisant la fonction TIME_SLICE. Cette fonction calcule les heures de début et de fin des « compartiments » de largeur fixe afin que les enregistrements individuels puissent être regroupés et résumés à l’aide de fonctions d’agrégation standard, telles que SUM et AVG.
De même, la fonction DATE_TRUNC tronque une partie d’une série de valeurs de date ou d’horodatage, réduisant ainsi leur granularité. Les sections suivantes présentent des exemples de chaque fonction.
Sous-échantillonnage à l’aide de TIME_SLICE¶
L’exemple suivant sous-échantillonne une table nommée sensor_data_ts, qui contient les relevés de deux capteurs d’usine et contient 5,3 millions de lignes. Ces relevés ont été ingérés par seconde, de sorte que 5,3 millions de lignes représentent seulement un mois de données, avec un peu plus de 2,5 millions de lignes par capteur. Vous pouvez utiliser la fonction TIME_SLICE pour agréger jusqu’à une seule ligne par minute, par heure ou par jour, par exemple.
Pour exécuter cet exemple, créez et chargez d’abord la table sensor_data_ts ; voir Création de la table sensor_data_ts. Voici un petit échantillon des données figurant dans la table :
La table contient 60 relevés de ce type par minute pour chaque appareil, comme le montre cette requête :
Dans cette requête de sous-échantillonnage, la fonction TIME_SLICE définit des compartiments d’une minute et renvoie l’heure de début de chaque compartiment. La fonction AVG calcule la température moyenne de chaque compartiment par appareil. La fonction COUNT(*) est incluse à titre de référence, juste pour montrer combien de lignes atterrissent dans chaque compartiment temporel.
Les colonnes vibration et motor_rpm ne sont pas incluses, mais elles pourraient être agrégées de la même manière que la colonne temperature ou en utilisant des fonctions d’agrégation différentes.
Important
Si vous exécutez cet exemple vous-même, votre sortie ne correspondra pas exactement, car la table sensor_data_ts est chargée de valeurs générées de manière aléatoire.
En utilisant la fonction TIME_SLICE, vous pouvez créer des tables agrégées plus petites à des fins d’analyse et vous pouvez appliquer le processus de sous-échantillonnage à différents niveaux (heure, jour, semaine, etc.).
Sous-échantillonnage à l’aide de DATE_TRUNC¶
L’exemple suivant sélectionne les données d’une table nommée order_header dans le schéma raw.pos de la base de données d’échantillon Tasty Bytes. Cette table contient 248 millions de lignes.
La table order_header possède une colonne TIMESTAMP nommée order_ts. La requête crée une série temporelle agrégée en utilisant cette colonne comme deuxième argument de la fonction DATE_TRUNC. Le premier argument spécifie un intervalle day. Cela signifie que chaque enregistrement, ayant une granularité heures/minutes/secondes, sont regroupés par jour.
La requête regroupe les enregistrements selon deux dimensions : truck_id et location_id. La colonne avg_amount indique le prix moyen par commande, par camion-restaurant, par emplacement pour chaque jour ouvrable enregistré.
La requête présentée ici limite les résultats aux 25 premières lignes pour le 1er janvier 2022. Si vous supprimez ce filtre de date et la clause LIMIT, la requête sous-échantillonne les 248 millions de lignes d’origine à environ 500 000 lignes.
Utilisation d’agrégations fenêtrées pour les calculs glissants¶
En utilisant les fonctions d’agrégation fenêtrées pour observer l’évolution d’une métrique dans le temps, vous pouvez analyser les tendances d’une série temporelle. Les agrégations fenêtrées sont utiles pour analyser des données dans des sous-ensembles définis (« fenêtres ») d’un ensemble de données plus large. Vous pouvez effectuer des calculs glissants (comme des moyennes et des sommes mobiles) pour chaque ligne d’un ensemble de données, en tenant compte d’un groupe de lignes précédant, suivant ou entourant la ligne actuelle. Ce type d’analyse contraste avec les agrégations régulières qui résument l’ensemble des données.
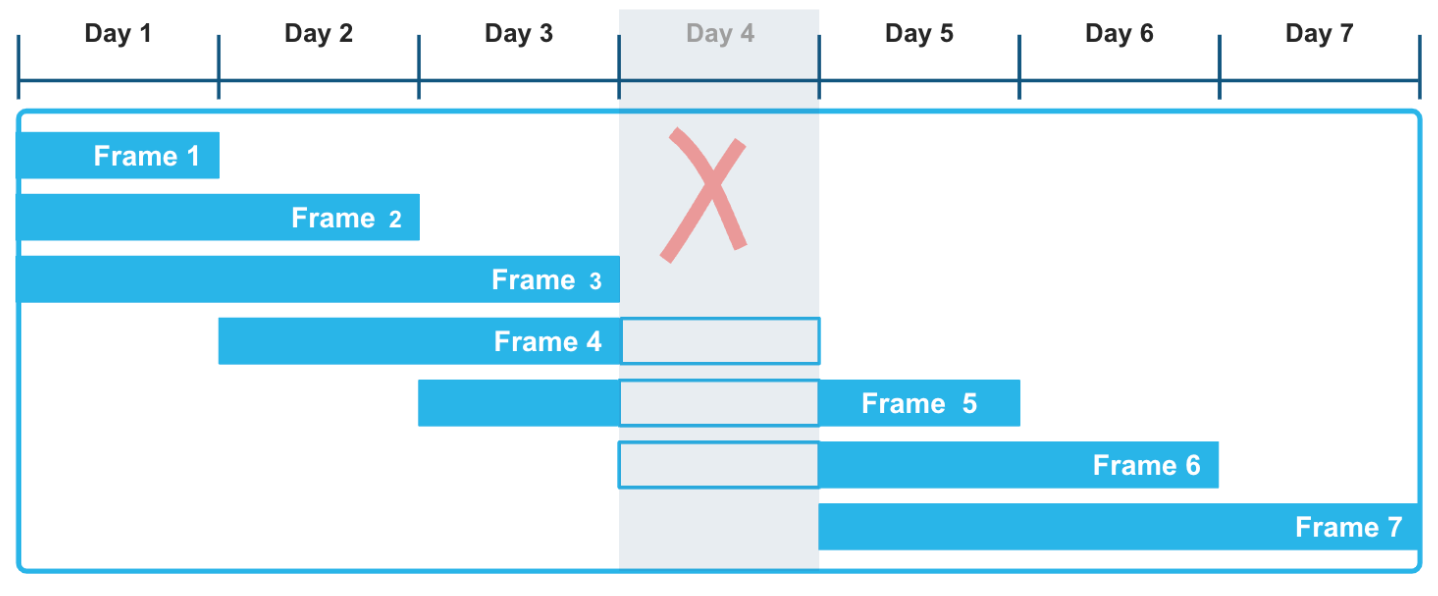
En utilisant des cadres de fenêtre basés sur des plages avec des décalages explicites, vous pouvez appliquer une approche très flexible au calcul de ces agrégations glissantes. Le cadre de fenêtre RANGE BETWEEN, classé par horodatages ou par numéros, n’est pas perturbé par les écarts qui peuvent se produire dans les données de séries temporelles. Par exemple, dans l’illustration suivante, le fait que les données du Day 4 manquent dans la série d’enregistrements n’affecte pas le calcul des fonctions d’agrégation sur une fenêtre mobile de trois jours. En particulier, les cadres 3, 4 et 5 sont calculés correctement, en tenant compte du fait que les données du Day 4 sont inconnues.
L’exemple suivant calcule une somme mobile sur des données météorologiques qui enregistrent les relevés de précipitations par heure dans différentes villes et différents comtés. Vous pouvez exécuter ce type de requête pour évaluer les tendances dans divers ensembles de données de séries chronologiques, comme des capteurs et autres dispositifs IoT, notamment lorsque ces ensembles de données sont connus pour comporter des écarts ou sont susceptibles d’en comporter.
La fonction de fenêtre inclut dans son cadre le relevé actuel des précipitations et tous les relevés qui se situent dans l’intervalle de temps spécifié avant le relevé actuel. Le calcul glissant est basé sur cette plage flexible et logique de lignes plutôt que sur un nombre exact de lignes. La première ligne de chaque ville a des valeurs precip et moving_sum_precip correspondantes. Après cela, la somme est recalculée pour chaque ligne suivante dans le cadre. Les valeurs brutes fluctuent de manière significative, mais les sommes mobiles ont un fort effet de lissage.
Pour exécuter cet exemple, suivez d’abord ces instructions : Créer et charger la table heavy_weather. Cette toute petite table contient des observations météorologiques par heure sporadiques, avec de nombreux écarts, y compris un jour manquant. La requête renvoie la somme mobile des valeurs de précipitations triées en fonction de la colonne start_time. Le cadre de fenêtre définit une plage comprise entre 12 heures avant la ligne actuelle et la ligne actuelle. Par conséquent, le cadre se compose de la ligne actuelle et uniquement des lignes dont les horodatages sont antérieurs de 12 heures maximum à l’horodatage ORDER BY de la ligne actuelle.
Les trois valeurs moving_sum_precip pour Big Bear City sont calculées comme suit :
0,42 = 0,42 (pas de lignes précédentes)
0,42 + 0,09 = 0,51 (les deux premières lignes se situent dans la fenêtre de 12 heures)
0,07 = 0,07 (aucune ligne précédente ne se trouve dans la fenêtre de 12 heures)
Les lignes relatives à South Lake Tahoe incluent ces calculs, par exemple :
0,56 + 0,38 + 0,28 + 0,80 = 2,02 (les quatre lignes du 23/12/2024 sont à 12 heures d’intervalle)
0,80 + 0,17 = 0,97 (une ligne précédente se trouve dans la fenêtre de 12 heures)
D’autres fonctions de fenêtre telles que les fonctions de classement LEAD et LAG sont également couramment utilisées dans l’analyse des séries temporelles. Utilisez la fonction de fenêtre LEAD pour trouver le point de données suivant dans la série temporelle, par rapport au point de données actuel et la fonction LAG pour trouver le point de données précédent.
Visualisation des résultats de la requête dans Snowsight¶
Vous pouvez utiliser Snowsight pour visualiser les résultats des requêtes d’agrégation et obtenir une meilleure idée de l’effet de lissage des calculs avec des fenêtres glissantes. Dans la feuille de calcul de la requête, cliquez sur le bouton Chart à côté de Results.
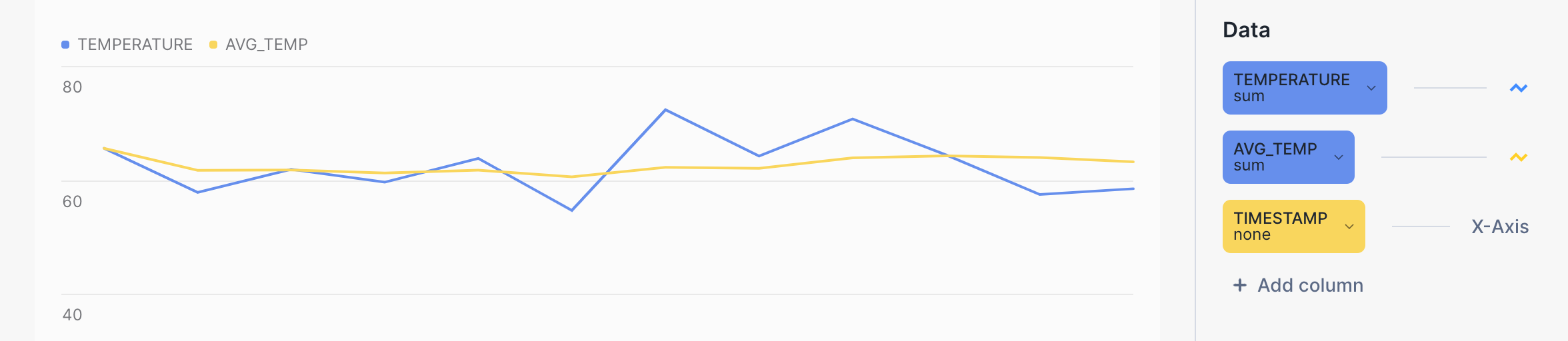
Par exemple, la ligne jaune du diagramme à barres suivant montre une tendance beaucoup plus douce pour la température moyenne que la ligne bleue pour la température brute. La requête elle-même ressemble à ceci :
Utilisation des fonctions d’agrégation MIN_BY et MAX_BY¶
La possibilité de sélectionner une colonne en fonction de la valeur minimale ou maximale d’une autre colonne de la même ligne est une exigence courante pour les développeurs SQL qui travaillent avec des données de séries temporelles. MIN_BY et MAX_BY sont des fonctions de commodité qui renvoient les valeurs de début et de fin (ou la plus haute et la plus basse, ou la première et la dernière) d’une table lorsque les données sont triées en fonction d’une autre colonne, telle qu’un horodatage.
Le premier exemple permet simplement de trouver la dernière valeur (la plus récente) de precip dans l’ensemble de la table. La fonction MAX_BY trie toutes les lignes en fonction de leur valeur start_time, puis renvoie la valeur precip pour l’heure de début « max ».
Pour créer et charger la table utilisée dans les exemples suivants, voir Création de la table heavy_weather.
Vous pouvez vérifier ce résultat (et obtenir plus d’informations à ce sujet) en exécutant cette requête :
Vous pouvez ajouter une clause GROUP BY pour poser des questions plus intéressantes sur ces données. Par exemple, la requête suivante permet de trouver la dernière valeur de précipitations observée pour chaque ville de Californie, classée par ordre de valeurs precip (de la plus élevée à la plus faible). Les résultats sont regroupés par city afin d’obtenir la dernière valeur de precip pour chaque ville différente.
La dernière fois qu’une observation a été faite pour la ville d’Alta, la valeur de precip était 0.89, et la dernière fois qu’une observation a été faite pour les villes de South Lake Tahoe, Big Bear City, Montague et Lebec, la valeur de precip était 0.07 pour les quatre localités. (Notez que la requête ne vous indique pas quand ces observations ont été faites)
Vous pouvez renvoyer l’ensemble de résultats « opposé » (l’enregistrement le plus ancien de precip par rapport au plus récent) en utilisant la fonction MIN_BY.
Jointure de données de séries temporelles¶
Vous pouvez utiliser la construction ASOF JOIN pour joindre des tables contenant des données de série chronologique. Bien que les requêtes ASOF JOIN puissent être émulées par l’utilisation de SQL complexe, d’autres types de jointures et de fonctions de fenêtre, ces requêtes sont plus faciles à écrire (et sont optimisées) si vous utilisez la syntaxe ASOF JOIN.
L’analyse des données de transactions financières est une utilisation courante des jointures ASOF. L’analyse des coûts de transaction, par exemple, nécessite des calculs de « glissement », qui mesurent la différence entre le prix coté au moment de la décision d’acheter des actions et le prix effectivement payé lorsque la transaction a été exécutée et enregistrée. La syntaxe ASOF JOIN peut accélérer ce type d’analyse. Étant donné que la capacité clé de cette méthode de jointure est l’analyse d’une série temporelle par rapport à une autre, ASOF JOIN peut être utile pour l’analyse de tout ensemble de données de nature historique. Dans bon nombre de ces cas d’utilisation, la syntaxe ASOF JOIN peut être utilisée pour associer des données lorsque les relevés de différents appareils ont des horodatages qui ne sont pas exactement les mêmes.
On suppose que les données de série chronologique que vous devez analyser existent dans deux tables, et qu’il existe un horodatage pour chaque ligne de chaque table. Cet horodatage représente la date et l’heure « à compter de » précises d’un événement enregistré. Pour chaque ligne de la première table (ou table de gauche), la jointure utilise une « condition de correspondance » avec un opérateur de comparaison que vous spécifiez pour trouver une seule ligne dans la deuxième table (ou table de droite) où la valeur de l’horodatage est l’une des suivantes :
Inférieure ou égale à la valeur d’horodatage dans la table de gauche.
Supérieure ou égale à la valeur d’horodatage dans la table de gauche.
Inférieure à la valeur d’horodatage dans la table de gauche.
Supérieure à la valeur d’horodatage dans la table de gauche.
La ligne éligible située à droite est la correspondance la plus proche, qui peut être égale dans le temps, antérieure dans le temps ou postérieure dans le temps, selon l’opérateur de comparaison spécifié.
La cardinalité du résultat de ASOF JOIN est toujours égale à la cardinalité de la table de gauche. Si la table de gauche contient 40 millions de lignes, ASOF JOIN renvoie 40 millions de lignes. Par conséquent, la table de gauche peut être considérée comme la table « préservante » et la table de droite comme la table « référencée ».
Jointure de deux tables sur la correspondance la plus proche (alignement)¶
Par exemple, dans une application financière, vous pouvez avoir une table nommée quotes et une table nommée trades. Une table enregistre l’historique des offres d’achat d’actions et l’autre l’historique des transactions effectives. Une offre d’achat d’actions a lieu avant la transaction (ou éventuellement au « même » moment, selon la granularité du temps enregistré). Les deux tables contiennent des horodatages et d’autres colonnes intéressantes que vous souhaiterez peut-être comparer. Une simple requête ASOF JOIN renverra la valeur cotée la plus proche (dans le temps) avant chaque transaction. En d’autres termes, la requête pose la question suivante : « Quel était le prix d’une action donnée au moment où j’ai effectué une transaction ? ».
Supposons que la table trades contienne trois lignes et que la table quotes en contienne sept. La couleur d’arrière-plan des cellules indique les trois lignes de quotes qui seront éligibles à ASOF JOIN lorsque les lignes seront jointes sur des symboles boursiers correspondants et que leurs colonnes d’horodatage seront comparées.
Table TRADES (table gauche ou « préservante »)
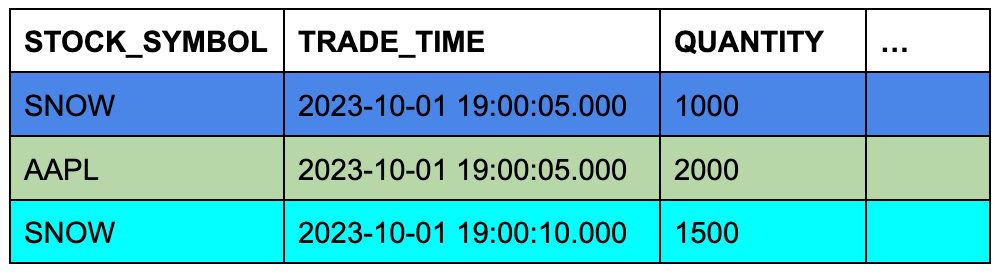
Table QUOTES (table droite ou « référencée »)
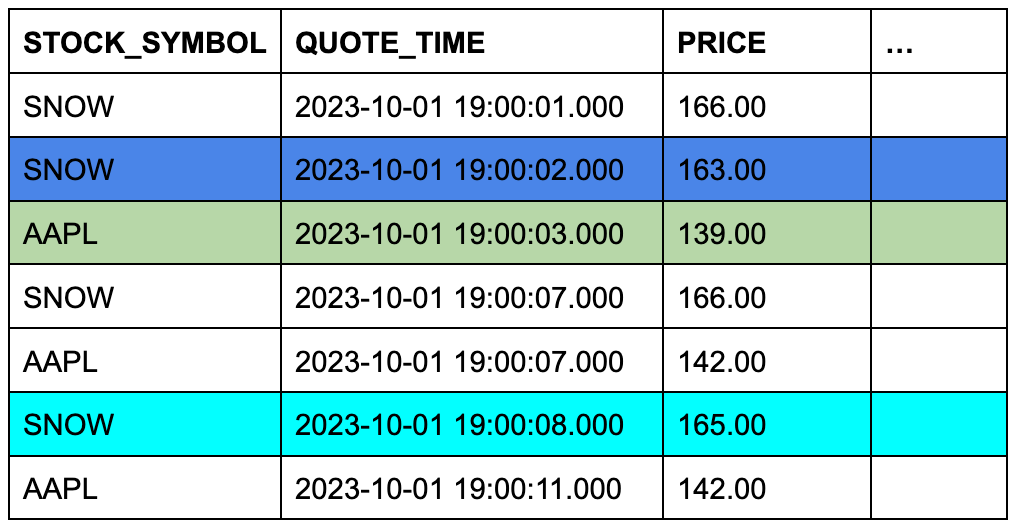
Cet exemple conceptuel est facile à transformer en une requête ASOF JOIN spécifique :
La condition ON regroupe les lignes correspondantes en fonction de leurs symboles boursiers.
Pour exécuter cet exemple, créez et chargez les tables comme suit :
Pour d’autres exemples de requêtes ASOF JOIN, voir Exemples.
Comblement des écarts dans les données de séries temporelles¶
L’analyse des séries temporelles requiert souvent que les données aient une granularité cohérente avec des enregistrements pour chaque intervalle, mais les données réelles arrivent fréquemment à des intervalles irréguliers ou contiennent des écarts. Par exemple, vous pouvez disposer d’un ensemble de données principalement horaires mais avoir besoin de générer des entrées toutes les demi-heures afin de les aligner sur les analyses en aval, ou vous pouvez déjà disposer d’une résolution cohérente mais découvrir des écarts dans les séries. La fonctionnalité de comblement des écarts de Snowflake offre des moyens efficaces d’appliquer un intervalle uniforme aux données de séries temporelles et de combler tout écart.
Prenons par exemple les huit enregistrements suivants, qui reprennent les observations météorologiques de deux villes de Californie le 15 mars 2025.
Bien que ces enregistrements aient un niveau de granularité relativement cohérent (jour, heure, minute), les intervalles entre les lignes sont incohérents, variant entre 1 et 15 minutes. Si l’objectif est de collecter des données à des intervalles de 5 minutes, il manque plusieurs lignes.
Utilisation de la clause RESAMPLE¶
Vous pouvez modifier la granularité et améliorer la cohérence d’un ensemble de lignes en les « sur-échantillonnant » à un intervalle de temps spécifique. Pour apporter ce type de modification, utilisez la clause RESAMPLE, que vous définissez dans la clause FROM d’une instruction SELECT. Le résultat d’un ensemble de données rééchantillonné est un ensemble de données plus grand qui préserve toutes les lignes d’entrée existantes et génère un certain nombre de nouvelles lignes avec des valeurs qui comblent les écarts dans les séries temporelles. (Notez que vous pouvez également utiliser la clause RESAMPLE pour « sous-échantillonner » des lignes en un jeu de résultats plus petit et moins granulaire).
Par définition, une série temporelle possède toujours une colonne qui contient une séquence de dates, d’horodatages ou de valeurs numériques représentant des dates ou des heures. Le rééchantillonnage s’effectue sur cette colonne dans la table source, et la granularité requise doit être spécifiée avec une valeur INTERVAL, par exemple 5 minutes, 30 minutes ou 1 hour.
En règle générale, vous définissez également des partitions qui créent des lignes de séries temporelles sur certaines dimensions, plutôt que de simplement générer un nouvel horodatage par intervalle.
La structure d’une requête RESAMPLE ressemble à ceci :
Les colonnes des lignes qui sont générées sont définies sur NULL, à l’exception des colonnes spécifiées dans les clauses USING et PARTITION BY. La date, l’heure ou la colonne numérique spécifiée et les colonnes de partitionnement possèdent des valeurs générées significatives.
Note
Si vous prévoyez de filtrer vos données rééchantillonnées par valeurs spécifiques (par exemple, par ID d’appareil ou emplacement spécifique), incluez ces colonnes dans la clause PARTITION BY. Ceci garantit que les lignes générées ont des valeurs réelles pour ces colonnes plutôt que des valeurs NULL. Si vous filtrez avec une clause WHERE sur les colonnes qui ne sont pas dans la clause PARTITION BY, la clause WHERE filtre toutes les lignes générées pour ces colonnes car elles contiennent des valeurs NULL.
Pour exécuter un exemple simple qui utilise les huit enregistrements présentés précédemment, commencez par créer et charger la table suivante :
Sélectionnez ensuite les lignes sur-échantillonnées de cette table, en utilisant un intervalle de 5 minutes :
Cette requête préserve les huit lignes d’origine et génère trois nouvelles lignes, comblant les écarts pour trois intervalles de temps, à 09:45, 10:00 et 10:05. Les valeurs NULL sont insérées dans les colonnes temperature, city et county.
Le point de départ de la série temporelle est 2025-03-15 09:45:00.000, car il se situe dans les 5 minutes de l’horodatage le plus ancien de l’ensemble de données d’entrée (2025-03-15 09:49:00.000).
Si vous souhaitez supprimer des lignes qui n’apparaissent pas à intervalles réguliers (09:49 et 10:18, dans ce cas), consultez Exemple de RESAMPLE qui utilise BUCKET_START() pour filtrer les lignes non uniformes.
Ajoutez ensuite une cause PARTITION BY à la requête :
Les résultats partitionnés diffèrent de deux manières :
Sept lignes sont générées, pour un total de 15 lignes. Il existe désormais une ligne pour chaque intervalle de 5 minutes pour chaque partition.
Les colonnes de partitionnement ont correctement généré les valeurs
cityetcounty. La seule colonne qui possède des valeurs NULL dans les lignes générées esttemperature.
Vous pouvez également spécifier le paramètre METADATA_COLUMNS dans la syntaxe RESAMPLE pour ajouter les colonnes suivantes au résultat :
La colonne de métadonnées
is_generatedidentifie les lignes qui ont été générées par l’opération RESAMPLE et les lignes qui étaient déjà présentes.La colonne de métadonnées
bucket_startrenvoie la valeur qui marque le début du compartiment ou de l’intervalle actuel que l’opération RESAMPLE produit. Vous pouvez utiliser cette colonne pour identifier à quel intervalle appartient une ligne particulière après le rééchantillonnage, et vous pouvez également l’utiliser pour exécuter des requêtes agrégées sur les données rééchantillonnées. Voir Exemple de RESAMPLE qui utilise BUCKET_START() pour agréger des lignes rééchantillonnées.
Pour tout savoir sur la syntaxe RESAMPLE, consultez RESAMPLE.
Pour enregistrer les résultats d’une requête RESAMPLE, utilisez une instruction CTAS qui sélectionne et insère les données dans une nouvelle table :
Valeurs d’interpolation ou de « comblement des écarts » dans une série temporelle¶
Bien que vous puissiez utiliser la syntaxe RESAMPLE et les fonctions d’interpolation de façon indépendante, elles sont le plus souvent utilisées ensemble pour combler les écarts de données des séries temporelles dans le cadre d’une requête unique. Après avoir rééchantillonné votre ensemble de données, vous pouvez appeler une fonction d’interpolation pour mettre à jour les autres colonnes d’intérêt dans les lignes nouvellement générées. Le processus d’interpolation met à jour les colonnes qui étaient auparavant NULL, comme des mesures numériques, en leur attribuant des valeurs significatives basées sur les valeurs trouvées dans les lignes précédentes ou suivantes.
Vous pouvez interpoler les valeurs en appelant les fonctions de fenêtre INTERPOLATE_FFILL, INTERPOLATE_BFILL et INTERPOLATE_LINEAR. Par exemple, la fonction INTERPOLATE_FFILL recherche la (dernière) valeur précédente dans la série temporelle pour la colonne en question :
La première ligne renvoie NULL pour la colonne ffill_temp, car il n’existe pas de ligne précédente pour la fonction INTERPOLATE_FFILL à utiliser.
Pour plus d’informations sur les fonctions de fenêtre, consultez INTERPOLATE_BFILL, INTERPOLATE_FFILL, INTERPOLATE_LINEAR.
Sur-échantillonnage, comblement des écarts et stockage des résultats en une seule opération¶
Pour simplifier l’ensemble du processus de comblement des écarts d’un ensemble de données, vous pouvez sur-échantillonner les données et interpoler les valeurs dans une seule requête et enregistrer les résultats en utilisant une opération CTAS. Par exemple, l’instruction CTAS suivante crée une nouvelle table qui interpole les mesures dans un ensemble de données sur-échantillonné :
Note
Lorsque vous utilisez les fonctions INTERPOLATE avec le rééchantillonnage, les colonnes que vous spécifiez dans la clause OVER (PARTITION BY) pour les fonctions de fenêtre correspondent généralement aux colonnes de la clause RESAMPLE (PARTITION BY). Cette approche garantit que l’interpolation se produit dans les mêmes partitions logiques que celles créées lors du rééchantillonnage. Dans l’exemple précédent, le rééchantillonnage est partitionné par city et county, tandis que les fonctions INTERPOLATE sont partitionnées par city uniquement. Cet exemple fonctionne, car l’interpolation se fait à une granularité plus grossière, mais vous devez toujours vous assurer que la stratégie de partitionnement s’aligne sur vos exigences en matière de données.
Comblement des écarts avec ASOF JOIN¶
Note
Pour utiliser l’approche recommandée pour le comblement des écarts et l’interpolation, consultez Comblement des écarts dans les données de séries temporelles. La construction RESAMPLE et les fonctions INTERPOLATE sont des fonctions de prévisualisation, et l’approche ASOF JOIN de comblement des écarts suivante n’est incluse qu’en tant que solution de contournement potentielle.
Outre l’alignement des données dans deux tables en recherchant des correspondances non exactes sur des colonnes temporelles, ASOF JOIN est utile pour combler les écarts d’une série temporelle lorsque votre table de données brutes ne contient pas de lignes pour des dates ou des horodatages particuliers. Par exemple, lorsque des lignes sont manquantes car un équipement défectueux ou une panne de courant entraîne l’omission de relevés de capteurs, vous pouvez utiliser ASOF JOIN pour interpoler les valeurs d’une série temporelle générée dans la table. Les lignes manquantes sont complétées par la dernière valeur connue pour les relevés manquants. Cette valeur est également appelée « dernière observation reportée » (LOCF). La requête ASOF JOIN renvoie un ensemble complet de lignes qui sont dans l’ordre chronologique et contiguës.
Pour utiliser ASOF JOIN pour l’interpolation, procédez comme suit :
Identifiez les écarts de votre table en exécutant une requête simple.
Générez une série temporelle complète, avec le grain approprié, pour la période que vous devez couvrir. Par exemple, votre série temporelle peut être une simple séquence de dates pour une année donnée ou une séquence beaucoup plus granulaire d’horodatages par seconde pour un certain nombre de jours. Vous pouvez utiliser SQL ou un tableur pour générer la liste des valeurs.
La série temporelle aura également besoin d’un ID significatif ou d’une dimension significative pour chaque ligne, que vous spécifierez plus tard dans la condition ASOF JOIN ON.
Écrivez une requête ASOF JOIN qui interpole les valeurs dans les lignes manquantes. La série temporelle générée sera la table de conservation et la table de données brutes sera la table de référence.
L’exemple suivant requiert la table sensor_data_ts. Si vous ne l’avez pas encore créée et chargée, consultez Création de la table sensor_data_ts. Pour simuler la nécessité d’une opération de comblement des écarts, supprimez quelques lignes de la table comme suit :
Le résultat est une table à laquelle il manque cinq lignes pour DEVICE2 le 7 mars (1:16 à 1:20).
Suivez maintenant les étapes suivantes pour compléter l’exercice de comblement des écarts.
Note
Si vous exécutez cet exemple vous-même, votre sortie ne correspondra pas exactement, car la table sensor_data_ts est chargée de valeurs générées de manière aléatoire.
Étape 1 : vérifier que la table présente des écarts¶
Exécutez la requête suivante pour identifier les écarts :
Cette requête renvoie deux lignes pour DEVICE2 : la dernière ligne avant l’écart et la première ligne après l’écart.
Étape 2 : générer une série temporelle complète pour couvrir les écarts connus¶
Pour générer une série temporelle avec un grain fin (une ligne par seconde) pour l’écart dans la table sensor_data_ts , créez la table suivante, qui contient les horodatages générés :
Dans cette instruction SQL, 5 est le nombre de secondes dont vous avez besoin pour couvrir l’écart. Notez que la valeur de l’ID de l’appareil (DEVICE2) est incluse dans les lignes générées.
La requête suivante renvoie les cinq lignes générées.
Étape 3 : interpoler les valeurs à l’aide de ASOF JOIN¶
Vous pouvez maintenant exécuter une requête ASOF JOIN qui joint continuous_timestamps à sensor_data_ts et interpole les valeurs des lignes manquantes pour DEVICE2. La condition de correspondance permet de trouver la ligne la plus proche dans le temps pour chaque ligne manquante et la condition ON garantit que l’interpolation a lieu sur les IDs des appareils correspondants.
La ligne la plus proche des lignes manquantes est la ligne avec l’horodatage 2024-03-07 00:01:16.000 en supposant que >= soit spécifié dans la condition de correspondance, comme indiqué dans cet exemple.
Cette instruction INSERT sélectionne cinq lignes de l’opération ASOF JOIN et les insère dans la table sensor_data_ts.
Pour vérifier les résultats de l’interpolation, sélectionnez ces cinq lignes, ainsi que les deux lignes qui les précèdent et les suivent directement, dans la table sensor_data_ts. Notez que les cinq lignes interpolées ont repris les mêmes valeurs pour les colonnes temperature, vibration, et motor_rpm que celles enregistrées dans la ligne 2024-03-07 00:01:15.000. L’interpolation a réussi.
Application de fonctions ML à des données de séries temporelles¶
Vous pouvez former un modèle avec des fonctions ML pour effectuer une analyse prédictive sur des données de séries temporelles :
La prévision utilise des données historiques de séries temporelles pour faire des prédictions sur les données futures. Étant donné une série temporelle enregistrée avec des valeurs réelles observées pour des dates et des heures passées, le modèle ML prévoit ce que les valeurs observées pourraient être pour des dates et des heures futures.
La détection des anomalies permet d’identifier les valeurs aberrantes, c’est-à-dire les points de données qui s’écartent d’une fourchette attendue. Dans le contexte d’une série temporelle, une valeur aberrante est une mesure qui est beaucoup plus grande ou plus petite que d’autres mesures dans un intervalle de temps similaire. Pour trouver les valeurs aberrantes, la fonction ML produit une prévision pour la même période que celle qui fait l’objet de la recherche d’anomalies, puis compare les résultats de la prévision aux données réelles.
Top Insights détermine les dimensions les plus importantes d’un ensemble de données, construit des segments à partir de ces dimensions et détecte lesquels de ces segments ont influencé une métrique.
Note
À des fins de machine-learning, les horodatages de vos séries temporelles doivent représenter des intervalles de temps fixes. Si nécessaire, vous pouvez utiliser la fonction DATE_TRUNC ou TIME_SLICE sur les colonnes TIMESTAMP pour supprimer les irrégularités lors de l’entraînement du modèle de prévision.
Exemple de détection d’anomalies dans une série temporelle¶
L’exemple suivant utilise une vue ne comportant que 30 lignes pour entraîner un modèle de détection d’anomalies. Commencez par générer des données dans une table, puis créez une vue sur cette table. La vue n’est pas obligatoire (vous pouvez utiliser une table pour entraîner un modèle), mais l’option de vue vous donne une certaine flexibilité pour entraîner des modèles de manière itérative, avec différents nombres de lignes, sans mettre à jour les données sources.
Note
Si vous exécutez cet exemple vous-même, votre sortie ne correspondra pas exactement, car la table sensor_data_30_rows est chargée de valeurs générées de manière aléatoire.
Créez maintenant le modèle :
Lorsque le modèle a été construit avec succès, appelez la méthode <nom_du_modèle>!DETECT_ANOMALIES pour détecter les valeurs aberrantes dans l’ensemble de données de test spécifié. Les horodatages des données de test doivent suivre chronologiquement les horodatages des données d’entraînement, mais il ne doit pas y avoir d’écart trop important entre les données d’entraînement et les données de test. Par exemple, si vous disposez d’horodatages pour chaque seconde, n’utilisez pas de données de test qui ont des millions de secondes d’avance sur les données d’entraînement.
Cet exemple utilise une autre table comme données de test, avec seulement trois lignes. Ces lignes ont des horodatages qui suivent de près ceux des données d’entraînement.
Lorsque l’appel de détection d’anomalie se termine, il renvoie une sortie similaire à celui qui suit :
Les colonnes TS et Y renvoient les horodatages et les valeurs de température des données de test. Dans ce très petit cas, la fonction a détecté une anomalie (IS_ANOMALY=True). Pour plus d’informations sur les colonnes de sortie, voir la section « Renvois » dans la description de la fonction.
Création de la table sensor_data_ts¶
Si vous souhaitez tester les exemples de cette section qui interrogent la table sensor_data_ts , vous pouvez créer et charger une copie de cette table en exécutant le script SQL suivant. Le script génère un mois de données synthétiques pour les relevés des capteurs en appelant les fonctions UNIFORM, RANDOM, et GENERATOR ; par conséquent, votre copie de la table ne renverra pas des résultats identiques. Les relevés se situent dans la même fourchette, mais ils ne sont pas identiques.
Création de la table heavy_weather¶
Le script suivant crée et charge la table heavy_weather qui est utilisée dans les exemples pour les fonctions MAX_BY. La table contient 55 lignes d’enregistrements de précipitations neigeuses pour les villes de Californie au cours de la dernière semaine de l’année 2021.