Detecção de anomalias (funções de ML Snowflake)¶
Visão geral¶
A detecção de anomalias é o processo de identificação de valores discrepantes nos dados. A função de detecção de anomalias permite treinar um modelo para detectar valores discrepantes em seus dados de séries temporais. Valores discrepantes, que são pontos de dados que se desviam do intervalo esperado, podem ter um impacto desproporcional nas estatísticas e modelos derivados de seus dados. Identificar e remover exceções pode, portanto, ajudar a melhorar a qualidade de seus resultados.
Nota
A detecção de anomalias faz parte do conjunto de ferramentas de análise de negócios do Snowflake, com tecnologia de aprendizado de máquina.
A detecção de exceções também pode ser útil para identificar a origem de problemas ou desvios em processos quando não há causa óbvia. Por exemplo:
Determinar quando um problema começou a ocorrer com o pipeline de registro.
Identificar os dias em que os custos de computação do Snowflake são maiores do que o esperado.
A detecção de anomalias funciona com dados de série única ou multisséries. Os dados multisséries representam vários threads independentes de eventos. Por exemplo, se você tiver dados de vendas para várias lojas, as vendas de cada loja podem ser verificadas separadamente por um único modelo baseado no identificador da loja.
Os dados devem incluir:
Uma coluna de carimbo de data/hora.
Uma coluna de destino que representa alguma quantidade de interesse em cada carimbo de data/hora.
Nota
O ideal é que os dados de treinamento para um modelo de detecção de anomalias tenham etapas de tempo em intervalos igualmente espaçados (por exemplo, diariamente). No entanto, o treinamento do modelo pode lidar com dados do mundo real que tenham etapas de tempo ausentes, duplicadas ou desalinhadas. Para obter mais informações, consulte Como lidar com dados do mundo real na previsão de séries temporais.
Para detectar discrepâncias em dados de séries temporais, use a classe integrada ANOMALY_DETECTION (SNOWFLAKE.ML) do Snowflake e siga estes passos:
Crie um objeto de detecção de anomalias, passando uma referência aos dados de treinamento.
Este objeto ajusta um modelo aos dados de treinamento que você fornece. O modelo é um objeto em nível de esquema.
Usando este objeto de modelo de detecção de anomalias, chame o método <nome_do_modelo>!DETECT_ANOMALIES para detectar anomalias, passando uma referência aos dados a serem analisados.
O método usa o modelo para identificar exceções nos dados.
A detecção de anomalias está intimamente relacionada à previsão. Um modelo de detecção de anomalias produz uma previsão para o mesmo período que os dados que você está verificando em busca de anomalias e, em seguida, compara os dados reais com a previsão para identificar valores discrepantes.
Importante
Aviso legal. Essa função do Snowflake ML é alimentada pela tecnologia de aprendizado de máquina, que você, e não a Snowflake, determina quando e como usar. A tecnologia de aprendizado de máquina e os resultados fornecidos podem ser imprecisos, inadequados ou tendenciosos. A Snowflake fornece os modelos de aprendizado de máquina que você pode usar em seus próprios fluxos de trabalho. As decisões baseadas em resultados de aprendizado de máquina, incluindo aquelas incorporadas em pipelines automáticos, devem ter supervisão humana e processos de revisão para garantir que o conteúdo gerado pelo modelo seja preciso. A Snowflake fornece algoritmos (sem qualquer pré-treinamento) e você é responsável pelos dados que fornece ao algoritmo (por exemplo, para treinamento e inferência) e pelas decisões que toma usando a saída do modelo resultante. As consultas para esse recurso ou função são tratadas como qualquer outra consulta SQL e podem ser consideradas metadados.
Metadados. Quando você usa as funções do Snowflake ML, o Snowflake registra mensagens de erro genéricas retornadas por uma função ML. Esses logs de erros nos ajudam a solucionar problemas que surgem e a melhorar essas funções para melhor atender você.
Para obter mais informações, consulte FAQ sobre confiança e segurança do Snowflake AI.
Sobre o algoritmo para detecção de anomalias¶
O algoritmo de detecção de anomalias é alimentado por uma máquina de gradient boosting (GBM). Como um modelo ARIMA, ele usa uma transformação diferencial para modelar dados com uma tendência não estacionária e usa atrasos auto-regressivos dos dados de destino históricos como variáveis de modelo.
Além disso, o algoritmo usa médias contínuas de dados de destino históricos para ajudar a prever tendências e produz automaticamente variáveis de calendário cíclico (como dia da semana e semana do ano) a partir de dados do carimbo de data/hora.
Você pode ajustar modelos apenas com dados históricos de destino e carimbo de data/hora ou pode incluir dados exógenos (variáveis) que podem ter influenciado o valor de destino. As variáveis exógenas podem ser numéricas ou categóricas e podem ser NULL (linhas contendo NULLs para variáveis exógenas não são descartadas).
O algoritmo não depende de one-hot encoding ao treinar em variáveis categóricos, portanto, você pode usar dados categóricos com muitas dimensões (alta cardinalidade).
Se seu modelo incorporar variáveis exógenas, você deverá fornecer valores para essas variáveis em carimbos de data/hora no futuro ao detectar anomalias. Variáveis exógenas apropriadas podem incluir dados meteorológicos (temperatura, precipitação), informações específicas da empresa (feriados históricos e planejados da empresa, campanhas publicitárias, programações de eventos) ou quaisquer outros fatores externos que você acredita que possam ajudar a prever sua variável desejada.
Opcionalmente, linhas históricas individuais podem ser rotuladas como anômalas ou não anômalas usando uma coluna booliana separada.
Um intervalo de previsão é um intervalo estimado de valores dentro de um limite superior e um limite inferior no qual uma certa porcentagem de dados provavelmente ficará. Por exemplo, um valor de 0,99 significa que 99% dos dados provavelmente aparecem dentro do intervalo. O modelo de detecção de anomalias identifica qualquer dado que esteja fora do intervalo de previsão como uma anomalia. Você pode especificar um intervalo de previsão ou usar o padrão, que é 0,99. Talvez você queira definir esse valor para ficar bem próximo de 1,0; 0,9999 ou ainda mais perto.
Importante
De tempos em tempos, a Snowflake pode refinar o algoritmo de detecção de anomalias. Essas melhorias são implementadas por meio do processo de lançamento regular do Snowflake. Não é possível reverter para uma versão anterior do recurso, mas os modelos criados com uma versão anterior continuam a usar essa versão para detecção de anomalias.
Limitações¶
Você não pode escolher ou ajustar o algoritmo de detecção de anomalias. Em especial, o algoritmo não fornece parâmetros para substituir a tendência, a sazonalidade ou as amplitudes sazonais; elas são inferidas a partir dos dados.
O número mínimo de linhas para o algoritmo principal de detecção de anomalias é 12 por série temporal. Para séries temporais com observações entre 2 e 11, a detecção de anomalias produz um resultado «ingênuo» em que todos os valores previstos são iguais ao último valor nominal observado. Para o caso de detecção de anomalia rotulada, o número de observações utilizadas é o número de linhas onde a coluna do rótulo é falsa.
A granularidade mínima aceitável de dados é um segundo. (Carimbos de data/hora não devem ter menos de um segundo de intervalo.)
A granularidade mínima dos componentes sazonais é de um minuto. (A função não pode detectar padrões cíclicos em deltas de tempo menores.)
A “duração da temporada” dos recursos autorregressivos está vinculada à frequência de entrada (24 para dados horários, 7 para dados diários e assim por diante).
Depois de treinados, os modelos de detecção de anomalias são imutáveis. Você não pode atualizar modelos existentes com novos dados; você deve treinar um modelo inteiramente novo. Os modelos não oferecem suporte ao controle de versão. Em geral, você deve retreinar os modelos em uma cadência regular, como uma vez por dia, uma vez por semana ou uma vez por mês, dependendo da frequência com que recebe novos dados, para ajudar o modelo a acompanhar as tendências em constante mudança.
Este recurso detecta apenas anomalias nos dados de teste; ele não pode detectar anomalias nos dados de treinamento. Além disso, os carimbos de data/hora nos dados de teste devem ser todos maiores que os carimbos de data/hora nos dados de treinamento. Certifique-se de que os dados de treinamento abranjam um período típico livre de exceções reais ou rotule as exceções conhecidas em uma coluna booliana.
Você não pode clonar modelos ou compartilhar modelos entre funções ou contas. Ao clonar um esquema ou banco de dados, os objetos do modelo são ignorados.
Você não pode replicar uma instância da classe ANOMALY_DETECTION.
Preparação para detecção de anomalias¶
Antes de poder usar a detecção de anomalias, você deve:
Selecionar um warehouse virtual para treinar e executar seus modelos.
Conceder os privilégios para criar objetos de detecção de anomalias.
Você também pode modificar seu caminho de pesquisa para incluir SNOWFLAKE.ML.
Seleção de um warehouse virtual¶
Um warehouse virtual Snowflake fornece os recursos de computação para treinar e usar seus modelos de aprendizado de máquina para esse recurso. Esta seção fornece orientações gerais sobre como selecionar o melhor tamanho e tipo de warehouse para essa finalidade, com foco na etapa de treinamento (a parte mais demorada e que consome muita memória do processo).
Treinamento em dados de série única¶
Para modelos treinados em dados de série única, você deve escolher o tipo de warehouse com base no tamanho dos seus dados de treinamento. Os warehouses padrão estão sujeitos a um limite de memória do Snowpark menor e são mais apropriados para tarefas de treinamento com menos linhas ou recursos exógenos. Se seus dados de treinamento não contiverem nenhum recurso exógeno, você poderá treinar em um warehouse padrão se o conjunto de dados tiver 5 milhões de linhas ou menos. Se seus dados de treinamento usarem 5 ou mais recursos exógenos, a contagem máxima de linhas será menor. Caso contrário, Snowflake sugere usar um warehouse otimizado para Snowpark para tarefas de treinamento maiores.
Em geral, para dados de série única, um tamanho de warehouse maior não resulta em um tempo de treinamento mais rápido ou em limites de memória mais altos. Como regra geral, o tempo de treinamento é proporcional ao número de linhas em sua série temporal. Por exemplo, em um warehouse padrão XS, com a avaliação desativada (CONFIG_OBJECT => {'evaluate': False}), o treinamento em um conjunto de dados de 100.000 linha leva cerca de 60 segundos, enquanto o treinamento em um conjunto de dados de 1.000.000 de linha leva cerca de 125 segundos. Com a avaliação ativada, o tempo de treinamento aumenta de forma aproximadamente linear pelo número de divisões usadas.
Para obter melhor desempenho, Snowflake recomenda usar um warehouse dedicado sem outras cargas de trabalho simultâneas para treinar seu modelo.
Treinamento em dados multisséries¶
Assim como ocorre com os dados de série única, escolha o tipo de warehouse com base no número de linhas em sua maior série temporal. Se sua maior série temporal contiver mais de 5 milhões de linhas, a tarefa de treinamento provavelmente excederá os limites de memória em um warehouse padrão.
Ao contrário dos dados de série única, os dados multisséries são treinados consideravelmente mais rápido em warehouses maiores. Os seguintes pontos de dados podem orientar você em sua seleção. Mais uma vez, todos esses momentos são feitos com a avaliação desativada.
Tipo e tamanho do warehouse |
Número de séries temporais |
Número de linhas por série temporal |
Tempo de treinamento (segundos) |
|---|---|---|---|
Padrão XS |
1 |
100,000 |
60 segundos |
Padrão XS |
10 |
100,000 |
204 segundos |
Padrão XS |
100 |
100,000 |
720 segundos |
Padrão XL |
10 |
100,000 |
104 segundos |
Padrão XL |
100 |
100,000 |
211 segundos |
Padrão XL |
1000 |
100,000 |
840 segundos |
XL otimizado para Snowpark |
10 |
100,000 |
65 segundos |
XL otimizado para Snowpark |
100 |
100,000 |
293 segundos |
XL otimizado para Snowpark |
1000 |
100,000 |
831 segundos |
Detecção de anomalias¶
A etapa de inferência leva aproximadamente 1 segundo para processar 100 linhas no conjunto de dados de entrada, independentemente do tamanho do warehouse.
Concessão de privilégios para criar objetos de detecção de anomalias¶
O treinamento de um modelo de detecção de anomalias resulta em um objeto em nível de esquema. Portanto, a função que você usa para criar modelos deve ter o privilégio CREATE SNOWFLAKE.ML.ANOMALY_DETECTION no esquema onde o modelo é criado, o que permite que o modelo seja armazenado lá. Este privilégio é semelhante a outros privilégios de esquema como CREATE TABLE ou CREATE VIEW.
Snowflake recomenda que você crie uma função chamada analyst para ser usada por pessoas que precisam detectar anomalias.
No exemplo a seguir, a função admin é a proprietária do esquema admin_db.admin_schema. A função analyst precisa criar modelos neste esquema.
USE ROLE admin;
GRANT USAGE ON DATABASE admin_db TO ROLE analyst;
GRANT USAGE ON SCHEMA admin_schema TO ROLE analyst;
GRANT CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema TO ROLE analyst;
Para usar este esquema, um usuário assume a função analyst:
USE ROLE analyst;
USE SCHEMA admin_db.admin_schema;
Se a função analyst tiver privilégios CREATE SCHEMA no banco de dados analyst_db, a função pode criar um novo esquema analyst_db.analyst_schema e criar modelos de detecção de anomalias nesse esquema:
USE ROLE analyst;
CREATE SCHEMA analyst_db.analyst_schema;
USE SCHEMA analyst_db.analyst_schema;
Para revogar o privilégio de criação de modelo de uma função no esquema, use REVOKE <privilégios> … FROM ROLE:
REVOKE CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema FROM ROLE analyst;
Configuração dos dados para os exemplos¶
Os exemplos nas seções a seguir usam um conjunto de dados de amostra que contém vendas diárias de itens em diferentes lojas, juntamente com dados climáticos diários (umidade e temperatura). O conjunto de dados também contém uma coluna que indica se o dia é feriado.
Execute as seguintes instruções para criar uma tabela chamada
historical_sales_dataque contém os dados de treinamento para o modelo:
CREATE OR REPLACE TABLE historical_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO historical_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'), (1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'), (2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);
Execute as seguintes instruções para criar uma tabela chamada
new_sales_dataque contém os dados para análise:
CREATE OR REPLACE TABLE new_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO new_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);
Treinamento, uso, visualização, exclusão e atualização de modelos¶
Use CREATE SNOWFLAKE.ML.ANOMALY_DETECTION para criar e treinar um modelo. O modelo é treinado no conjunto de dados que você fornece.
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION mydetector(...);
Consulte ANOMALY_DETECTION (SNOWFLAKE.ML) para obter detalhes completos sobre o construtor SNOWFLAKE.ML.ANOMALY_DETECTION. Para obter exemplos de criação de um modelo, consulte Detecção de anomalias.
Nota
SNOWFLAKE.ML.ANOMALY_DETECTION é executado usando privilégios limitados, portanto, por padrão, ele não tem acesso aos seus dados. Você deve, portanto, passar tabelas e exibições como referências, que transmitem os privilégios do chamador. Você também pode fornecer uma referência de consulta em vez de uma referência a uma tabela ou exibição.
Para criar esta referência, você pode usar a palavra-chave TABLE com o nome da tabela, nome da exibição ou consulta, ou você pode chamar a função SYSTEM$REFERENCE ou SYSTEM$QUERY_REFERENCE.
Para detectar anomalias, chame o método <nome_do_modelo>!DETECT_ANOMALIES do modelo:
CALL mydetector!DETECT_ANOMALIES(...);
Para selecionar colunas da saída tabular do método, você pode chamar o método na cláusula FROM:
SELECT ts, forecast FROM TABLE(mydetector!DETECT_ANOMALIES(...));
Para visualizar uma lista dos seus modelos, use o comando SHOW SNOWFLAKE.ML.ANOMALY_DETECTION:
SHOW SNOWFLAKE.ML.ANOMALY_DETECTION;
Para remover um modelo, use o comando DROP SNOWFLAKE.ML.ANOMALY_DETECTION:
DROP SNOWFLAKE.ML.ANOMALY_DETECTION <name>;
Para atualizar um modelo, exclua-o e treine um novo. Os modelos são imutáveis e não podem ser atualizados no local.
Detecção de anomalias¶
As seções a seguir demonstram como usar a detecção de anomalias para detectar exceções. Estas seções fornecem exemplos de detecção de anomalias para uma única série temporal, para várias séries temporais, com e sem variáveis exógenas, com um intervalo de previsão definido pelo usuário e com uma abordagem supervisionada (rotulada).
Detecção de anomalias para uma única série temporal (sem supervisão)
Treinamento de um modelo de detecção de anomalias com dados rotulados
Especificação do intervalo de previsão para detecção de anomalias
Detecção de anomalias para uma única série temporal (sem supervisão)¶
Para detectar anomalias em seus dados:
Treine um modelo de detecção de anomalias usando dados históricos.
Use o modelo treinado de detecção de anomalias para detectar anomalias em dados históricos ou projetados. Os carimbos de data/hora nos dados de teste devem seguir cronologicamente os carimbos de data/hora nos dados de treinamento. Você precisa de pelo menos 2 pontos de dados para treinar um modelo, pelo menos 12 para resultados não ingênuos e pelo menos 60 para resultados não lineares.
Consulte ANOMALY_DETECTION (SNOWFLAKE.ML) para obter informações sobre os parâmetros usados na criação e uso de um modelo.
Treinamento de um modelo de detecção de anomalias¶
Para criar um objeto de modelo de detecção de anomalias, execute o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION.
Por exemplo, suponha que você queira analisar as vendas de jaquetas na loja com o store_id de 1:
Crie uma exibição ou projete uma consulta que retorne os dados para treinar o modelo para detecção de anomalias.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_training_dataque contém a data e informações de vendas:CREATE OR REPLACE VIEW view_with_training_data AS SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket';
Crie um objeto de detecção de anomalias e treine seu modelo nos dados dessa exibição.
Para este exemplo, execute o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION para criar um objeto de detecção de anomalias chamado
basic_model. Passe os seguintes argumentos:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(view_with_training_data), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
Este exemplo passa uma referência para uma exibição como o argumento INPUT_DATA. O exemplo usa a palavra-chave TABLE para criar a referência. Como alternativa, você pode chamar SYSTEM$REFERENCE para criar a referência.
O objetivo da coluna de rótulo é informar ao modelo quais linhas são anomalias conhecidas. Como este exemplo utiliza treinamento não supervisionado, você não precisa usar a coluna de rótulo. Passe uma cadeia de caracteres vazia como o nome da coluna do rótulo.
Dica
Se não quiser criar uma exibição para o argumento INPUT_DATA, você pode passar uma referência a uma consulta que usa uma instrução SELECT que serve como uma exibição em linha.
Você pode usar a palavra-chave TABLE para criar esta referência de consulta. Por exemplo:
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket'), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
Faça o escape de aspas simples e outros caracteres especiais com uma barra invertida.
Como alternativa ao uso da palavra-chave TABLE, você pode chamar SYSTEM$QUERY_REFERENCE para criar a referência de consulta.
Se o comando for executado com sucesso, uma mensagem indicará que sua instância de detecção de anomalias foi criada com sucesso:
+--------------------------------------------+ | status | +--------------------------------------------+ | Instance basic_model successfully created. | +--------------------------------------------+
Como usar um modelo de detecção de anomalias para detectar anomalias¶
A criação do objeto de detecção de anomalias treina o modelo e o armazena no esquema. Para usar o objeto de detecção de anomalias para detectar anomalias, chame o método do objeto <nome_do_modelo>!DETECT_ANOMALIES. Por exemplo:
Crie uma exibição ou crie uma consulta que retorne os dados para análise.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_data_to_analyzeque contém a data e informações de vendas:CREATE OR REPLACE VIEW view_with_data_to_analyze AS SELECT date, sales FROM new_sales_data WHERE store_id=1 and item='jacket';
Usando o objeto para o modelo de detecção de anomalias (neste exemplo,
basic_model, que você criou anteriormente), chame o método <nome_do_modelo>!DETECT_ANOMALIES:CALL basic_model!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
O método retorna uma tabela que inclui linhas para os dados atualmente na exibição
view_with_data_to_analyzejuntamente com a previsão do detector. Para obter uma descrição das colunas nesta tabela, consulte Retornos.
Saída
Os resultados foram arredondados para facilitar a leitura.
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 4.6 | -7.185885251 | 16.385885251 | False | 0.6201873452 | 0.3059728606 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 9 | -2.785885251 | 20.785885251 | False | 0.9918932208 | 2.404072476 |
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
Para salvar seus resultados diretamente em uma tabela, use CREATE TABLE … AS SELECT … e chame o método DETECT_ANOMALIES na cláusula FROM:
CREATE TABLE my_anomalies AS
SELECT * FROM TABLE(basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
));
Conforme mostrado no exemplo acima, ao chamar o método, omita o comando CALL. Em vez disso, coloque a chamada entre parênteses, precedida pela palavra-chave TABLE.
Treinamento de um modelo de detecção de anomalias com dados rotulados¶
No exemplo anterior, o resultado do modelo parece ser impreciso. Isso acontece provavelmente porque:
O modelo de detecção de anomalias foi treinado com poucos dados de entrada.
Um número maior de jaquetas (30) foi vendido em 2020-01-03. Isso distorceu as previsões para cima e aumentou o tamanho do intervalo de previsão.
Para melhorar a precisão do modelo de detecção de anomalias, você pode incluir mais dados de treinamento ou rotular os dados de treinamento (treinamento supervisionado). Os dados de treinamento rotulados têm uma coluna booliana adicional que indica se cada linha é uma anomalia conhecida. O rótulo pode ajudar o modelo de detecção de anomalias a evitar o ajuste excessivo a anomalias conhecidas nos dados de treinamento.
Para incluir dados rotulados nos dados de treinamento, especifique a coluna que contém o rótulo no argumento do construtor LABEL_COLNAME do comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION. Por exemplo:
Crie uma exibição ou crie uma consulta que retorne os rótulos com os dados de treinamento.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_labeled_dataque contém os rótulos em uma coluna chamadalabel:CREATE OR REPLACE VIEW view_with_labeled_data_for_training AS SELECT date, sales, label FROM historical_sales_data WHERE store_id=1 and item='jacket';
Crie um objeto para o modelo de detecção de anomalias e treine o modelo nos dados dessa exibição.
Para este exemplo, execute o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION para criar um objeto de detecção de anomalias chamado
model_trained_with_labeled_data. A instrução a seguir cria o objeto de detecção de anomalias:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data( INPUT_DATA => TABLE(view_with_labeled_data_for_training), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Usando este novo modelo de detecção de anomalias, chame o método <nome_do_modelo>!DETECT_ANOMALIES, passando os mesmos argumentos que você usou em Detecção de anomalias para uma única série temporal (sem supervisão):
CALL model_trained_with_labeled_data!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
O método retorna uma tabela que inclui linhas para os dados atualmente na exibição
view_with_data_to_analyzejuntamente com a previsão do detector. Para obter uma descrição das colunas nesta tabela, consulte Retornos.
Saída
Os resultados foram arredondados para facilitar a leitura.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.82 | 11.18 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.39 | 12.33 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
Especificação do intervalo de previsão para detecção de anomalias¶
Você pode detectar anomalias com vários níveis de sensibilidade. Para especificar a porcentagem de observações a serem classificadas como anomalias, crie um OBJECT que contenha definições de configuração para <nome_do_modelo>!DETECT_ANOMALIES e defina a chave prediction_interval para a porcentagem das observações que devem ser marcadas como anomalias.
Para construir esse objeto, você pode usar uma constante de objeto ou a função OBJECT_CONSTRUCT.
Então, ao chamar o método <nome_do_modelo>!DETECT_ANOMALIES, passe este objeto como o argumento CONFIG_OBJECT.
Por padrão, o valor associado à chave prediction_interval é definido como 0,99, o que significa que aproximadamente 1% dos dados é marcado como anomalias. Você pode especificar um valor entre 0 e 1:
Para marcar mais observações como anomalias, especifique um valor mais alto para
prediction_interval.Para marcar mais observações como anomalias, reduza o valor
prediction_interval.
O exemplo a seguir configura a detecção de anomalias para ser mais rigorosa, definindo prediction_interval como 0,995. O exemplo também usa o modelo treinado em dados rotulados (que você configurou em Treinamento de um modelo de detecção de anomalias com dados rotulados) com a exibição que contenha os dados a serem analisados (que você configurou em Detecção de anomalias para uma única série temporal (sem supervisão)).
CALL model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.995}
);
Esta instrução produz uma tabela que inclui linhas para os dados atualmente na exibição view_with_data_to_analyze. Cada linha inclui uma coluna com a previsão do detector. Você pode ver que o resultado desse modelo é mais preciso do que o exemplo sem rótulo.
Saída
Os resultados foram arredondados para facilitar a leitura.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 |
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
Como incluir colunas adicionais para análise¶
Você pode incluir colunas adicionais nos dados (por exemplo, temperature, weather, is_black_friday) nos dados para treinamento e análise, se essas colunas puderem ajudar você a melhorar a identificação de verdadeiras anomalias.
Para incluir novas colunas para análise:
Para os dados de treinamento, crie uma exibição ou projete uma consulta que inclua as novas colunas e crie um novo objeto de detecção de anomalias, transmitindo uma referência a essa exibição ou consulta.
Para os dados a serem analisados, crie uma exibição ou projete uma consulta que inclua as novas colunas e passe uma referência a essa exibição ou consulta para o método <nome_do_modelo>!DETECT_ANOMALIES.
O modelo de detecção de anomalias detecta e usa as colunas adicionais automaticamente.
Nota
Você deve fornecer uma exibição ou consulta com o mesmo conjunto de colunas adicionais ao executar o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION e ao chamar o método <nome_do_modelo>!DETECT_ANOMALIES. Se houver uma incompatibilidade entre as colunas nos dados de treinamento passados para o comando e as colunas nos dados para análise passados para a função, ocorrerá um erro.
Por exemplo, suponha que você queira adicionar as colunas temperature, humidity e holiday:
Crie uma exibição ou crie uma consulta que retorne os dados de treinamento com essas colunas adicionais.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_training_data_extra_columns:CREATE OR REPLACE VIEW view_with_training_data_extra_columns AS SELECT date, sales, label, temperature, humidity, holiday FROM historical_sales_data WHERE store_id=1 AND item='jacket';
Crie um objeto para o modelo de detecção de anomalias e treine o modelo nos dados dessa exibição.
Para este exemplo, execute o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION para criar um objeto de detecção de anomalias chamado
model_with_additional_columns, passando uma referência à nova exibição:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_with_additional_columns( INPUT_DATA => TABLE(view_with_training_data_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Crie uma exibição ou crie uma consulta que retorne os dados para análise com essas colunas adicionais.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_data_for_analysis_extra_columns:CREATE OR REPLACE VIEW view_with_data_for_analysis_extra_columns AS SELECT date, sales, temperature, humidity, holiday FROM new_sales_data WHERE store_id=1 AND item='jacket';
Usando esse novo objeto de detecção de anomalias, chame o método <nome_do_modelo>!DETECT_ANOMALIES, passando a nova exibição:
CALL model_with_additional_columns!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.93} );
Esta instrução produz uma tabela que inclui linhas para os dados atualmente na exibição
view_with_data_for_analysis_extra_columnsjuntamente com a previsão do detector. O formato da saída é o mesmo que o formato da saída mostrado para os comandos executados anteriormente.
Saída
Os resultados foram arredondados para facilitar a leitura.
+--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+-------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 2.34 | 9.64 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | 1.56 | 10.451 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+
Detecção de anomalias em séries múltiplas¶
As seções anteriores forneceram exemplos de detecção de anomalias para uma única série. Esses exemplos sinalizaram anomalias para a venda de um tipo de item (jaquetas) em uma loja (ID da loja 1). Para detectar anomalias em múltiplas séries temporais ao mesmo tempo (por exemplo, para diversas combinações de itens e lojas):
Para os dados de treinamento, crie uma exibição ou projete uma consulta que inclua uma coluna que identifique a série e crie um novo objeto de detecção de anomalias, passando uma referência a essa exibição ou consulta e especificando o nome da coluna da série para o argumento SERIES_COLNAME.
Para os dados a serem analisados, crie uma exibição ou desenhe uma consulta que inclua a coluna que identifica a série. Chame o método <nome_do_modelo>!DETECT_ANOMALIES, passando uma referência a essa exibição ou consulta e especificando o nome da coluna da série para o argumento SERIES_COLNAME.
Por exemplo, suponha que você queira usar a combinação das colunas store_id e item para identificar a série:
Crie uma exibição ou crie uma consulta que retorne os dados de treinamento com a coluna da série.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_training_data_multiple_seriesque contém uma coluna chamadastore_itemque identifica a série como uma combinação de ID da loja e artigo:CREATE OR REPLACE VIEW view_with_training_data_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, label, temperature, humidity, holiday FROM historical_sales_data;
Crie um objeto para a detecção de anomalias e treine o modelo nos dados dessa exibição.
Para este exemplo, execute o comando CREATE SNOWFLAKE.ML.ANOMALY_DETECTION para criar um objeto de detecção de anomalias chamado
model_for_multiple_series, passando uma referência para a nova exibição e especificandostore_itempara o argumento SERIES_COLNAME:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_for_multiple_series( INPUT_DATA => TABLE(view_with_training_data_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Crie uma exibição ou crie uma consulta que retorne os dados para análise com a coluna da série.
Para este exemplo, execute o comando CREATE VIEW para criar uma exibição chamada
view_with_data_for_analysis_multiple_seriesque contém uma coluna chamadastore_itempara a série:CREATE OR REPLACE VIEW view_with_data_for_analysis_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, temperature, humidity, holiday FROM new_sales_data;
Usando este novo objeto de detecção de anomalias, chame o método <nome_do_modelo>!DETECT_ANOMALIES, passando a nova exibição e especificando
store_itempara o argumento SERIES_COLNAME:CALL model_for_multiple_series!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.995} );
Esta instrução produz uma tabela que inclui linhas para os dados atualmente na exibição
view_with_data_for_analysis_multiple_seriesjuntamente com a previsão do detector. A saída inclui a coluna que identifica a série.
Saída
Os resultados foram arredondados para facilitar a leitura.
+--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | |--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------| | [ | 2020-01-16 00:00:00.000 | 3 | 6.3 | 2.07 | 10.53 | False | 0.01 | -2.19 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 70 | 2.9 | -1.33 | 7.13 | True | 1 | 44.54 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | +--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+
Visualização de anomalias e interpretação dos resultados¶
Use Snowsight para revisar e visualizar os resultados da detecção de anomalias. Em Snowsight, ao chamar o método <nome_do_modelo>!DETECT_ANOMALIES, os resultados são exibidos em uma tabela sob a planilha.

Para visualizar os resultados, você pode usar o recurso de gráfico em Snowsight.
Depois de chamar o método <nome_do_modelo>!DETECT_ANOMALIES, selecione Charts acima da tabela de resultados.
Na seção Data no lado direito do gráfico:
Selecione a coluna Y e, em Aggregation, selecione None.
Selecione a coluna TS e, em Bucketing, selecione None.
Adicione as colunas LOWER_BOUND e UPPER_BOUND e, em Aggregation, selecione None.
Para mostrar a exibição inicial, selecione Chart.

Selecione Add Column no lado direito da página e selecione as colunas que deseja visualizar:
LOWER_BOUND
UPPER_BOUND
IS_ANOMALY
Resultados:
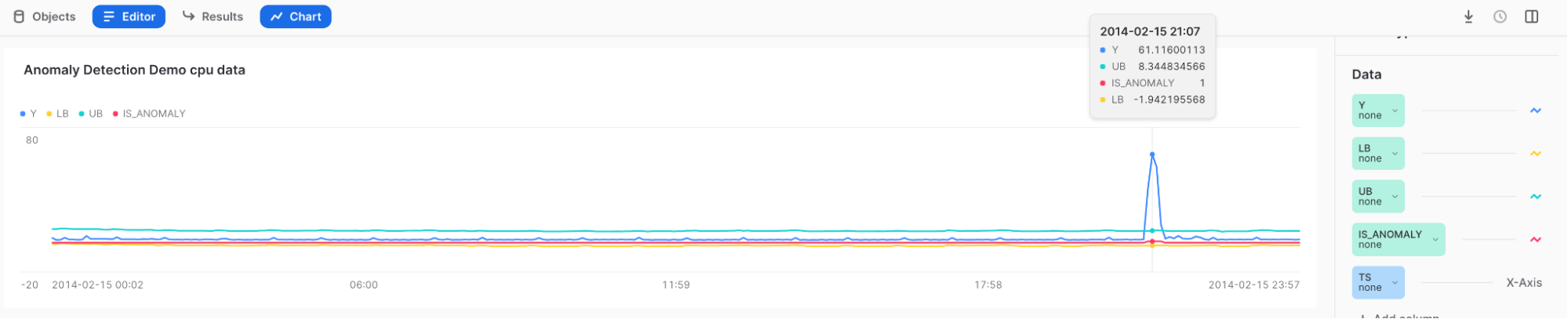
Passe o mouse sobre o pico alto para ver que Y está fora do limite superior e é marcado com um 1 no campo IS_ANOMALY.
Dica
Para entender melhor seus resultados, experimente o Top Insights.
Automação da detecção de anomalias com tarefas e alertas Snowflake¶
Você pode criar um pipeline automatizado de detecção de anomalias, tanto para treinar novamente o modelo quanto para monitorar seus dados em busca de anomalias, usando funções de detecção de anomalias em tarefas ou alertas do Snowflake.
Treinamento recorrente com uma tarefa Snowflake¶
Você pode atualizar seu modelo para refletir os dados mais atualizados usando as tarefas Snowflake.
Para criar uma tarefa que atualize o objeto de detecção de anomalias a cada hora, execute a instrução a seguir, substituindo your_warehouse_name pelo nome do seu warehouse:
CREATE OR REPLACE TASK ad_model_retrain_task
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '60 MINUTE'
AS
EXECUTE IMMEDIATE
$$
BEGIN
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data(
INPUT_DATA => TABLE(view_with_labeled_data_for_training),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => 'label'
);
END;
$$;
Por padrão, as tarefas recém-criadas são suspensas.
Para retomar a tarefa, execute o comando ALTER TASK … RESUME:
ALTER TASK ad_model_retrain_task RESUME;
Para pausar a tarefa, execute o comando ALTER TASK … SUSPEND:
ALTER TASK ad_model_retrain_task SUSPEND;
Monitoramento com uma tarefa Snowflake¶
Você também pode usar as tarefas Snowflake para monitorar seus dados em uma determinada frequência.
Primeiro, crie uma tabela para armazenar os resultados da detecção de anomalias:
CREATE OR REPLACE TABLE anomaly_res_table (
ts TIMESTAMP_NTZ, y FLOAT, forecast FLOAT, lower_bound FLOAT, upper_bound FLOAT,
is_anomaly BOOLEAN, percentile FLOAT, distance FLOAT);
Crie uma tarefa para armazenar os resultados de uma operação recorrente de detecção de anomalias na tabela. Este exemplo define o parâmetro WAREHOUSE como snowhouse. Você pode substituir isso pelo seu próprio warehouse:
CREATE OR REPLACE TASK ad_model_monitoring_task
WAREHOUSE = snowhouse
SCHEDULE = '1 minute'
AS
EXECUTE IMMEDIATE
$$
BEGIN
INSERT INTO anomaly_res_table (ts, y, forecast, lower_bound, upper_bound, is_anomaly, percentile, distance)
SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
)
);
END;
$$;
Para retomar a tarefa, execute o comando ALTER TASK … RESUME:
ALTER TASK ad_model_monitoring_task RESUME;
anomaly_res_table contém então todos os resultados para cada tarefa executada.
Para pausar a tarefa, execute o comando ALTER TASK … SUSPEND:
ALTER TASK ad_model_monitoring_task SUSPEND;
Monitoramento com um alerta Snowflake¶
Você também pode usar alertas Snowflake para monitorar seus dados com uma determinada frequência e enviar um e-mail a você com as anomalias detetadas. As instruções a seguir criam um alerta que detecta anomalias a cada minuto. Primeiro você define um procedimento armazenado para detectar anomalias, depois crie um alerta que use esse procedimento armazenado.
Nota
Você deve configurar a integração de e-mail para enviar e-mail de um procedimento armazenado; consulte Notificações no Snowflake.
CREATE OR REPLACE PROCEDURE extract_anomalies()
RETURNS TABLE()
LANGUAGE SQL
AS
$$
BEGIN
let res RESULTSET := (SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
))
WHERE is_anomaly = TRUE
);
RETURN TABLE(res);
END;
$$
;
CREATE OR REPLACE ALERT sample_sales_alert
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '1 MINUTE'
IF (EXISTS (CALL extract_anomalies()))
THEN
CALL SYSTEM$SEND_EMAIL(
'sales_email_alert',
'your_email@snowflake.com',
'Anomalous Sales Data Detected in data stream',
CONCAT(
'Anomalous Sales Data Detected in data stream \n',
'Value outside of prediction interval detected in the most recent run at ',
current_timestamp(1)
));
Para iniciar ou retomar o alerta, execute o comando ALTER ALERT … RESUME:
ALTER ALERT sample_sales_alert RESUME;
Para pausar o alerta, execute o comando ALTER ALERT … SUSPEND:
ALTER ALERT sample_sales_alert SUSPEND;
Como entender a importância do recurso¶
Um modelo de detecção de anomalias pode explicar a importância relativa de todos os recursos usados em seu modelo, incluindo quaisquer variáveis exógenas que você escolher, recursos de tempo gerados automaticamente (como dia da semana ou semana do ano) e transformações de sua variável de destino (como médias rolantes e defasagens auto-regressivas). Essas informações são úteis para entender quais fatores estão realmente influenciando seus dados.
O método <nome_do_modelo>!EXPLAIN_FEATURE_IMPORTANCE conta o número de vezes que as árvores do modelo usaram cada recurso para tomar uma decisão. Essas pontuações de importância do recurso são então normalizadas para valores entre 0 e 1 para que sua soma seja 1. As pontuações resultantes representam uma classificação aproximada dos recursos em seu modelo treinado.
Recursos que estão próximos em pontuação têm importância semelhante. Para séries extremamente simples (por exemplo, quando a coluna de destino tem um valor constante), todas as pontuações de importância do recurso podem ser zero.
O uso de vários recursos muito semelhantes entre si pode resultar em pontuações de importância reduzidas para esses recursos. Por exemplo, se uma característica for a quantidade de itens vendidos e outra for a quantidade de itens em estoque, os valores podem estar correlacionados porque você não pode vender mais do que tem e porque tenta gerenciar o estoque para não ter mais em estoque do que você vai vender. Se dois recursos forem idênticos, o modelo pode tratá-los como intercambiáveis ao tomar decisões, resultando em pontuações de importância de recurso que são metade do que essas pontuações seriam se apenas um dos recursos fosse incluído.
A importância do recurso também informa recursos de atraso. Durante o treinamento, o modelo infere a frequência (por hora, diariamente ou semanalmente) dos seus dados de treinamento. O recurso lagx (por exemplo, lag24) é o valor da variável de destino x unidades de tempo atrás. Por exemplo, se seus dados forem inferidos por hora, lag24 representará sua variável de destino 24 horas atrás.
Todas as outras transformações da sua variável de destino (médias móveis etc.) são resumidas como aggregated_endogenous_features na tabela de resultados.
Limitações¶
Você não pode escolher a técnica usada para calcular a importância do recurso.
As pontuações de importância do recurso podem ser úteis para obter intuição sobre quais recursos são importantes para a precisão do seu modelo, mas os valores reais devem ser considerados estimativas.
Exemplo¶
Para entender a importância relativa dos seus recursos para o modelo, treine um modelo e chame <nome_do_modelo>!EXPLAIN_FEATURE_IMPORTANCE. Neste exemplo, você primeiro cria dados aleatórios com duas variáveis exógenas: uma que é aleatória e, portanto, provavelmente não será muito importante para seu modelo, e outra que é uma cópia do seu destino e, portanto, provavelmente será mais importante para o seu modelo.
Execute as seguintes instruções para gerar os dados, treine um modelo nele e obtenha a importância dos recursos:
CREATE OR REPLACE VIEW v_random_data AS SELECT
DATEADD('minute', ROW_NUMBER() over (ORDER BY 1), '2023-12-01')::TIMESTAMP_NTZ ts,
MOD(SEQ1(),10) y,
UNIFORM(1, 100, RANDOM(0)) exog_a
FROM TABLE(GENERATOR(ROWCOUNT => 500));
CREATE OR REPLACE VIEW v_feature_importance_demo AS SELECT
ts,
y,
exog_a
FROM v_random_data;
SELECT * FROM v_feature_importance_demo;
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION anomaly_model_feature_importance_demo(
INPUT_DATA => TABLE(v_feature_importance_demo),
TIMESTAMP_COLNAME => 'ts',
TARGET_COLNAME => 'y',
LABEL_COLNAME => ''
);
CALL anomaly_model_feature_importance_demo!EXPLAIN_FEATURE_IMPORTANCE();
Saída
Como este exemplo usa dados aleatórios, não espere que sua saída corresponda exatamente a isso.
+--------+------+--------------------------------------+-------+-------------------------+
| SERIES | RANK | FEATURE_NAME | SCORE | FEATURE_TYPE |
+--------+------+--------------------------------------+-------+-------------------------+
| NULL | 1 | aggregated_endogenous_trend_features | 0.36 | derived_from_endogenous |
| NULL | 2 | exog_a | 0.22 | user_provided |
| NULL | 3 | epoch_time | 0.15 | derived_from_timestamp |
| NULL | 4 | minute | 0.13 | derived_from_timestamp |
| NULL | 5 | lag60 | 0.07 | derived_from_endogenous |
| NULL | 6 | lag120 | 0.06 | derived_from_endogenous |
| NULL | 7 | hour | 0.01 | derived_from_timestamp |
+--------+------+--------------------------------------+-------+-------------------------+
Inspeção de logs de treinamento¶
Quando você treina várias séries com CONFIG_OBJECT => 'ON_ERROR': 'SKIP', modelos de séries temporais individuais podem falhar no treinamento sem que o processo de treinamento geral falhe. Para entender quais séries temporais falharam e por quê, chame <instância_do_modelo>!SHOW_TRAINING_LOGS.
Exemplo¶
CREATE TABLE t_error(date TIMESTAMP_NTZ, sales FLOAT, series VARCHAR);
INSERT INTO t_error VALUES
(TO_TIMESTAMP_NTZ('2019-12-20'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-21'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-22'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-23'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-24'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-25'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-26'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-27'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-28'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-29'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-30'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-31'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-03'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-04'), 7.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 10.0, 'B'), -- the same timestamp used again and again
(TO_TIMESTAMP_NTZ('2020-01-06'), 13.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 15.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 14.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 18.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B');
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION model(
INPUT_DATA => TABLE(SELECT date, sales, series FROM t_error),
SERIES_COLNAME => 'series',
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '',
CONFIG_OBJECT => {'ON_ERROR': 'SKIP'}
);
CALL model!SHOW_TRAINING_LOGS();
Saída
+--------+--------------------------------------------------------------------------+
| SERIES | LOGS |
+--------+--------------------------------------------------------------------------+
| "B" | { "Errors": [ "At least two unique timestamps are required." ] } |
| "A" | NULL |
+--------+--------------------------------------------------------------------------+
Considerações sobre custo¶
Para obter detalhes sobre os custos de utilização das funções ML, consulte Considerações sobre custo na visão geral das funções ML.