Snowpipe Streaming high-performance architecture¶
A arquitetura de alto desempenho do Snowpipe Streaming foi projetada para organizações modernas e com uso intensivo de dados que exigem insights quase em tempo real. Essa arquitetura de última geração aumenta significativamente o rendimento, a eficiência e a flexibilidade da ingestão em tempo real no Snowflake.
Para obter informações sobre a arquitetura clássica, consulte Arquitetura clássica do Snowpipe Streaming. Para diferenças entre o SDK clássico e o SDK de alto desempenho, consulte Comparação entre os SDKs de alto desempenho e clássicos do Snowpipe Streaming.
Requisitos de software¶
Java
Requer Java 11 ou posterior.
Repositório Maven do SDK: SDK Java com Snowpipe Streaming
Referência da API: Referência do SDK Java
Python
Requer a versão Python 3.9 ou posterior.
Repositório PyPI do SDK: SDKPython com Snowpipe Streaming
Referência da API: Referência do SDK Python
Principais recursos¶
Taxa de transferência e latência:
Alto rendimento: desenvolvido para oferecem suporte a velocidades de ingestão de até 10 GB/s por tabela.
Insights quase em tempo real: obtém latências de ingestão de ponta a ponta para consulta dentro de 5 a 10 segundos.
Faturamento:
Faturamento simplificado, transparente e baseado na taxa de transferência. Para obter mais informações, consulte Snowpipe Streaming high-performance architecture: Understand your costs.
Ingestão flexível:
Java SDK e Python SDK: use o novo
snowpipe-streamingSDK, com um núcleo de cliente baseado em Rust para melhorar o desempenho no cliente e diminuir o uso de recursos.REST API: Fornece um caminho de ingestão direta, simplificando a integração para cargas de trabalho leve, dados de dispositivos IoT e implantações de borda.
Nota
Recomendamos que você comece com oSDK do Snowpipe Streaming sobre API REST para se beneficiar do melhor desempenho e da experiência de introdução.
Manuseio otimizado de dados:
Transformações em trânsito: oferece suporte à limpeza e à remodelagem de dados durante a ingestão usando a sintaxe de comando COPY no objeto PIPE.
Visibilidade aprimorada do canal: melhor percepção do status de ingestão principalmente por meio da exibição do histórico do canal no Snowsight e de uma nova
GET_CHANNEL_STATUSAPI.
Essa arquitetura é recomendada para:
Ingestão consistente de cargas de trabalho de streaming de alto volume.
Alimentação de análises e painéis em tempo real para a tomada de decisões urgentes.
Integração eficiente de dados de dispositivos IoT e implementações de borda.
Organizações que buscam preços transparentes, previsíveis e baseados na taxa de transferência para ingestão de streaming.
Novos conceitos: o objeto PIPE¶
Ao mesmo tempo em que herda os principais conceitos, como canais e tokens de deslocamento, do Snowpipe Streaming Classic, essa arquitetura apresenta o objeto PIPE como um componente central.
O objeto PIPE é um objeto Snowflake nomeado que atua como ponto de entrada e camada de definição para todos os dados de streaming ingeridos. Ele fornece o seguinte:
Definição de processamento de dados: define como os dados de streaming são processados antes de serem confirmados na tabela de destino, incluindo buffer no lado do servidor para transformações ou mapeamento de esquema.
Habilitação das transformações: permite a manipulação de dados em andamento (por exemplo, filtragem, reordenação de colunas, expressões simples) incorporando a sintaxe de transformação do comando COPY.
Suporte a recursos de tabela: lida com a ingestão em tabelas com chaves de clustering definidas, colunas de valor DEFAULT e colunas AUTOINCREMENT (ou IDENTITY).
Gerenciamento de esquemas: ajuda a definir o esquema esperado dos dados de streaming recebidos e seu mapeamento para as colunas da tabela de destino, permitindo a validação do esquema no lado do servidor.
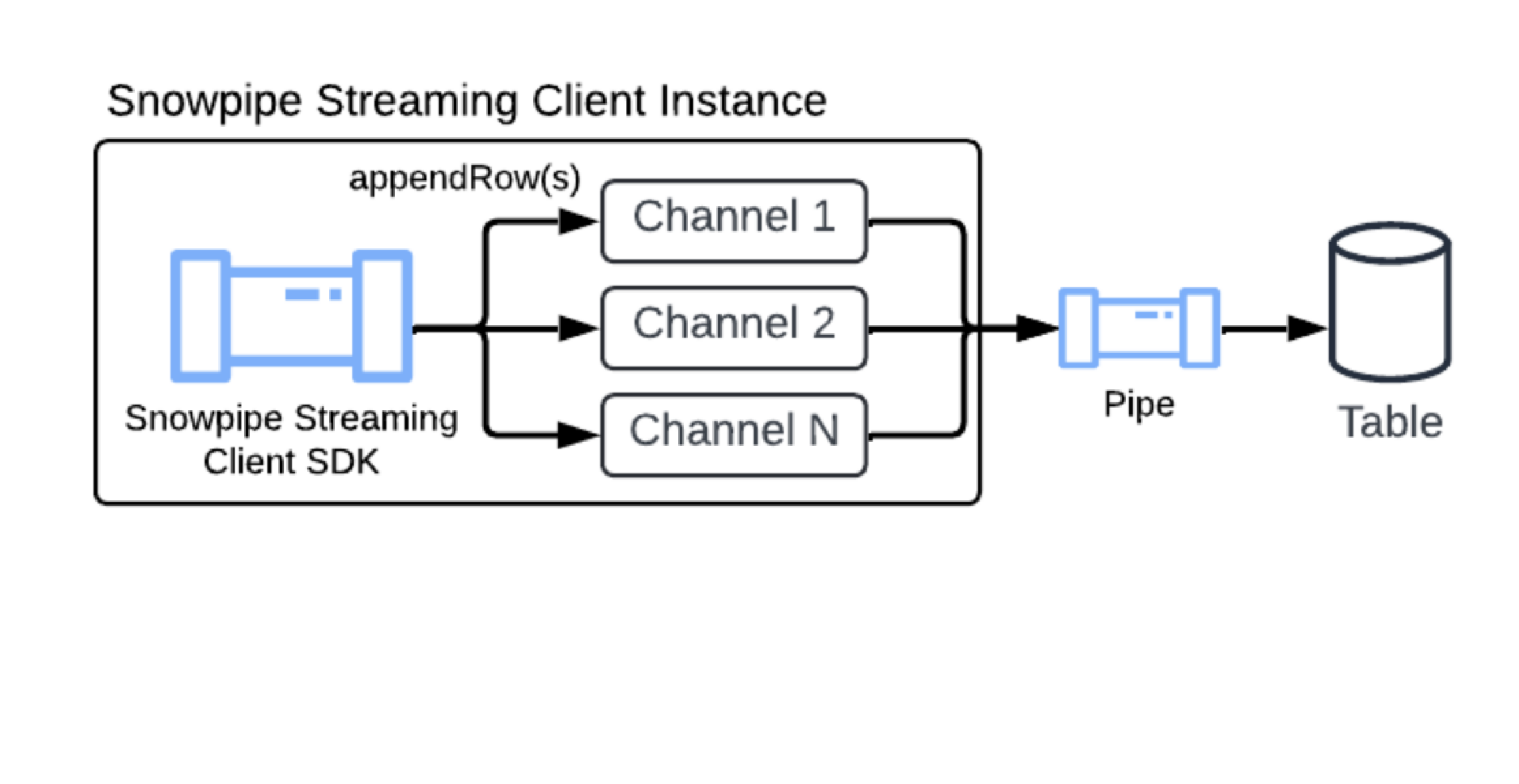
Canal padrão¶
Para simplificar o processo de configuração do Snowpipe Streaming, o Snowflake oferece um canal padrão para cada tabela de destino. Isso permite que você comece a transmitir dados imediatamente, sem precisar executar manualmente as instruções CREATE PIPE DDL.
O canal padrão está implicitamente disponível em qualquer tabela e oferece uma experiência simplificada e totalmente gerenciada:
Criação sob demanda: o canal padrão é criado sob demanda somente após a primeira chamada bem-sucedida de informações do canal ou de canal aberto feita na tabela de destino. Os clientes só podem visualizar ou descrever o canal (usando SHOW PIPES ou DESCRIBE PIPE) depois que ele é instanciado por uma dessas chamadas.
Convenção de nomenclatura: o canal padrão segue uma convenção de nomenclatura específica e previsível:
Formato:
<TABLE_NAME>-STREAMINGExemplo: se a sua tabela de destino se chamar
MY_TABLE, o canal padrão se chamaráMY_TABLE-STREAMING.
Totalmente gerenciado pelo Snowflake: o canal padrão é totalmente gerenciado pelo Snowflake. Os clientes não podem alterá-lo, como CREATE, ALTERou DROP o canal padrão.
Visibilidade: apesar de ser gerenciado automaticamente, os clientes podem inspecionar o canal padrão como fazem com um canal normal. Os clientes podem visualizá-lo usando os comandos SHOW PIPES, DESCRIBE PIPE, SHOW CHANNELS, e ele também está incluído nas exibições de metadados de uso da conta: ACCOUNT_USAGE.PIPES, ACCOUNT_USAGE.METERING_HISTORY ou ORGANIZATION_USAGE.PIPES.
O canal padrão foi projetado para simplicidade e tem certas limitações:
Sem transformações: o mecanismo interno do canal padrão usa
MATCH_BY_COLUMN_NAMEna instrução de cópia subjacente. Ele não oferece suporte a transformações de dados específicas.Sem pré-clustering: o canal padrão não oferece suporte a pré-clustering para a tabela de destino.
Se o fluxo de trabalho de streaming exigir transformações específicas; por exemplo, conversão, filtragem ou lógica complexa, ou se você precisar utilizar pré-clustering, crie manualmente seu próprio canal nomeado. Para obter mais informações, consulte CREATE PIPE.
Quando você configura o SDK ou a API REST do Snowpipe Streaming, pode referenciar o nome do canal padrão na configuração do seu cliente para iniciar o streaming. Para obter mais informações, consulte Tutorial: introdução ao SDK da arquitetura de alto desempenho do Snowpipe Streaming e Tutorial: introdução à API REST do Snowpipe Streaming usando cURL e um JWT:.
Pré-clustering de dados durante a ingestão¶
O Snowpipe Streaming pode fazer um clustering de dados em uso durante a ingestão, o que melhora o desempenho das consultas em suas tabelas de destino. Esse recurso classifica seus dados diretamente durante a ingestão antes de serem confirmados. Essa classificação dos dados otimiza a organização para acelerar as consultas.
Para aproveitar o pré-clustering, sua tabela de destino deve ter chaves de clustering definidas. Depois, você pode ativar esse recurso definindo o parâmetro CLUSTER_AT_INGEST_TIME como TRUE na instrução COPY INTO ao criar ou substituir o canal do Snowpipe Streaming.
Para obter mais informações, consulte CLUSTER_AT_INGEST_TIME. Esse recurso só está disponível na arquitetura de alto desempenho.
Importante
Ao usar o recurso de pré-clustering, não desabilite o recurso de clustering automático na tabela de destino. Desativar o clustering automático pode levar à degradação do desempenho da consulta ao longo do tempo.
Suporte à evolução do esquema¶
O Snowpipe Streaming oferece suporte à evolução automática do esquema de tabela. Com esse recurso, seus pipelines de dados podem se adaptar perfeitamente às estruturas de dados dinâmicas. Quando habilitado, o Snowflake pode expandir automaticamente a tabela de destino adicionando novas colunas que são detectadas no fluxo de entrada e descartando as restrições NOT NULL para acomodar novos padrões de dados. Para obter mais informações, consulte Evolução do esquema de tabela.
Limitações¶
Somente tabelas nativas: a evolução do esquema é compatível exclusivamente com as tabelas padrão do Snowflake. Tabelas externas e Iceberg não são compatíveis.
Sem ampliação de coluna: a precisão, a escala ou o comprimento das colunas existentes não podem ser aumentados automaticamente.
Sem suporte para tipo estruturado: a evolução do esquema não é compatível com tipos de dados estruturados; por exemplo, colunas OBJECT ou ARRAY estruturadas. No entanto, novas colunas que contêm tipos estruturados são inferidas como VARIANT, o que permite que objetos e matrizesJSON sejam compatíveis.
Diferenças em relação ao Snowpipe Streaming Classic¶
Para os usuários familiarizados com a arquitetura clássica, a arquitetura de alto desempenho apresenta as seguintes alterações:
Novos SDK e APIs: requer o novo
snowpipe-streamingSDK (Java SDK e REST API), exigindo atualizações do código de cliente para migração.Requisito de objeto PIPE: todas as definições de ingestão, configurações (por exemplo, transformações) e esquemas de dados são gerenciadas por meio do objeto PIPE no lado do servidor, uma mudança em relação à configuração mais orientada pelo cliente do Classic.
Associação de canais: os aplicativos clientes abrem canais em um objeto PIPE específico, não diretamente em uma tabela de destino.
Validação de esquema: passa do lado do cliente (SDK clássico) para a aplicação no lado do servidor pelo Snowflake, com base no objeto PIPE.
Requisitos de migração: é necessário modificar o código do aplicativo cliente para o novo SDK e definir objetos PIPE no Snowflake.