Carregamento em massa a partir do Amazon S3¶
If you already have an Amazon Web Services (AWS) account and use S3 buckets for storing and managing your data files, you can make use of your existing buckets and folder paths for bulk loading into Snowflake. This set of topics describes how to use the COPY command to bulk load from an S3 bucket into tables.
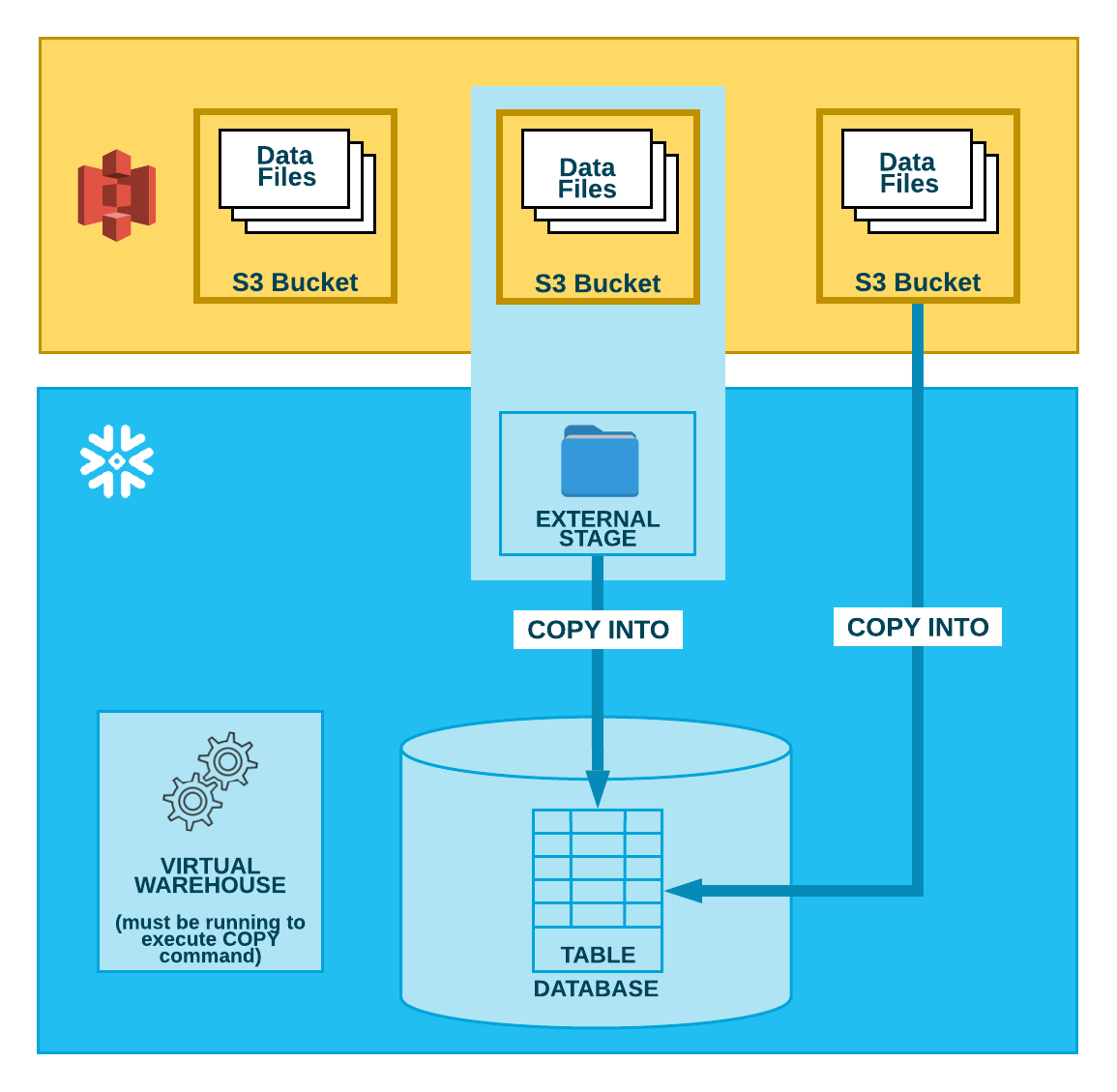
Como ilustrado no diagrama abaixo, o carregamento de dados de um bucket S3 é realizado em duas etapas:
- Etapa 1:
O Snowflake assume que os arquivos de dados já tenham sido preparados em um bucket S3. Se eles ainda não tiverem sido preparados, use os utilitários/interfaces de upload fornecidos pela AWS para preparar os arquivos.
- Etapa 2:
Use o comando COPY INTO <tabela> para carregar o conteúdo do(s) arquivo(s) preparado(s) em uma tabela do banco de dados Snowflake. Você pode carregar diretamente do bucket, mas a Snowflake recomenda que você crie um estágio externo que faça referência ao bucket e use o estágio externo.
Independentemente do método utilizado, esta etapa requer um warehouse virtual atual e em funcionamento para a sessão se você executar o comando manualmente ou dentro de um script. O warehouse fornece os recursos computacionais para realizar a inserção real de linhas na tabela.
Nota
O Snowflake utiliza os pontos de extremidade de gateway do Amazon S3 em cada instância do Amazon Virtual Private Clouds.
Enquanto sua conta Snowflake estiver hospedada no AWS, seu tráfego de rede não atravessará a Internet pública. Isso é verdade independentemente da região em que seu bucket S3 está.
Dica
As instruções neste conjunto de tópicos supõem que você tenha lido Preparação para carregar dados e criado um formato de arquivo nomeado, se desejar.
Antes de começar, você também pode ler Considerações sobre o carregamento de dados para obter práticas recomendadas, dicas e outras orientações.
Próximos tópicos:
Tarefas de configuração (complete conforme necessário):
Tarefas de carregamento de dados (completas para cada conjunto de arquivos que você carrega):