Transactions¶
A transaction is a sequence of SQL statements that are committed or rolled back as a unit.
Introduction¶
What is a transaction?¶
A transaction is a sequence of SQL statements that are processed as an atomic unit. All statements in the transaction are either applied (committed) or undone (rolled back) together. Snowflake transactions guarantee ACID properties.
A transaction can include both reads and writes.
Transactions follow these rules:
Transactions are never nested. For example, you cannot create an outer transaction that would roll back an inner transaction that was committed, or create an outer transaction that would commit an inner transaction that had been rolled back.
A transaction is associated with a single session. Multiple sessions cannot share the same transaction. For information about handling transactions with overlapping threads in the same session, see Transactions and multi-threading.
Terminology¶
In this topic:
The term DDL includes CTAS statements (CREATE TABLE AS SELECT) as well as other DDL statements that define database objects.
The term DML refers to INSERT, UPDATE, DELETE, MERGE, and TRUNCATE statements.
The term query statement refers to SELECT and CALL statements.
Although a CALL statement (which calls a stored procedure) is a single statement, the stored procedure it calls can contain multiple statements. There are special rules for stored procedures and transactions.
Explicit transactions¶
A transaction can be started explicitly by executing a BEGIN statement. Snowflake supports the synonyms BEGIN WORK and BEGIN TRANSACTION. Snowflake recommends using BEGIN TRANSACTION.
A transaction can be ended explicitly by executing COMMIT or ROLLBACK. Snowflake supports the synonym COMMIT WORK for COMMIT, and the synonym ROLLBACK WORK for ROLLBACK.
In general, if a transaction is already active, any BEGIN TRANSACTION statements are ignored. Users should avoid extra BEGIN TRANSACTION statements, however, because they make it much more difficult for human readers to pair up a COMMIT (or ROLLBACK) statement with the corresponding BEGIN TRANSACTION statement.
One exception to this rule involves a nested stored procedure call. For details, see Scoped transactions.
Note
Explicit transactions should contain only DML statements and query statements. DDL statements implicitly commit active transactions (for details, see the DDL section).
Implicit transactions¶
Transactions can be started and ended implicitly, without an explicit BEGIN TRANSACTION or COMMIT/ROLLBACK. Implicit transactions behave the same way as explicit transactions. However, the rules that determine when the implicit transaction starts are different from the rules that determine when an explicit transaction starts.
The rules for stopping and starting depend upon whether the statement is a DDL statement, a DML statement, or a query statement. If the statement is a DML or query statement, the rules depend upon whether AUTOCOMMIT is enabled.
DDL¶
Each DDL statement executes as a separate transaction.
If a DDL statement is executed while a transaction is active, the DDL statement:
Implicitly commits the active transaction.
Executes the DDL statement as a separate transaction.
Because a DDL statement is its own transaction, you cannot roll back a DDL statement; the transaction containing the DDL completes before you can execute an explicit ROLLBACK.
If a DDL statement is followed immediately by a DML statement, that DML statement implicitly starts a new transaction.
AUTOCOMMIT¶
Snowflake supports an AUTOCOMMIT parameter. The default setting for AUTOCOMMIT is TRUE (enabled).
While AUTOCOMMIT is enabled:
Each statement outside an explicit transaction is treated as though it is inside its own implicit single-statement transaction. In other words, that statement is automatically committed if it succeeds, and automatically rolled back if it fails.
Statements inside an explicit transaction are not affected by AUTOCOMMIT. For example, statements inside an explicit BEGIN TRANSACTION … ROLLBACK are rolled back even if AUTOCOMMIT is TRUE.
While AUTOCOMMIT is disabled:
An implicit BEGIN TRANSACTION is executed at:
The first DML statement after a transaction ends. This is true regardless of what ended the preceding transaction (for example, a DDL statement, or an explicit COMMIT or ROLLBACK).
The first DML statement after disabling AUTOCOMMIT.
An implicit COMMIT is executed as follows (if a transaction is already active):
When a DDL statement is executed.
When an
ALTER SESSION SET AUTOCOMMITstatement is executed, regardless of whether the new value is TRUE or FALSE, and whether the new value is different from the previous value. For example, even if you set AUTOCOMMIT to FALSE when it is already FALSE, an implicit COMMIT is executed.
An implicit ROLLBACK is executed as follows (if a transaction is already active):
At the end of a session.
At the end of a stored procedure.
Regardless of whether the stored procedure’s active transaction was started explicitly or implicitly, Snowflake rolls back the active transaction and issues an error message.
Caution
Do not change AUTOCOMMIT settings inside a stored procedure. You will get an error message.
Mixing implicit and explicit starts and ends of a transaction¶
To avoid writing confusing code, you should avoid mixing implicit and explicit starts and ends in the same transaction. The following are legal, but discouraged:
An implicitly started transaction can be ended by an explicit COMMIT or ROLLBACK.
An explicitly started transaction can be ended by an implicit COMMIT or ROLLBACK.
Failed statements within a transaction¶
Although a transaction is committed or rolled back as a unit, that is not quite the same as saying that it succeeds or fails as a unit. If a statement fails within a transaction, you can still commit the transaction, rather than roll it back.
When a DML statement or CALL statement in a transaction fails, the changes made by that failed statement are rolled back. However, the transaction stays active until the entire transaction is committed or rolled back. If the transaction is committed, the changes made by the successful statements are applied.
For example, consider the following code, which inserts two valid values and one invalid value into a table:
If the statements after the failed INSERT statement are executed, the output of the final SELECT statement includes the rows with integer values 1 and 2, even though one of the other statements in the transaction failed.
Note
The statements after the failed INSERT statement might or might not be executed. The behavior depends on how the statements are run and how errors are handled.
For example:
If these statements are inside a stored procedure written in Snowflake Scripting language, the failed INSERT statement throws an exception.
If the exception is not handled, the stored procedure never completes, and the COMMIT is never executed, so the open transaction is implicitly rolled back. In that case, the table does not contain the values
1or2.If the stored procedure handles the exception and commits the statements prior to the failed INSERT statement, but does not execute the statements after the failed INSERT statement, only the row with the value
1is stored in the table.
If these statements are not inside a stored procedure, the behavior depends on how the statements are executed. For example:
If the statements are executed through Snowsight, execution halts at the first error.
If the statements are executed by SnowSQL using the
-f(filename) option, execution does not halt at the first error, and the statements after the error are executed.
Transactions and multi-threading¶
Although multiple sessions cannot share the same transaction, multiple threads that use a single connection share the same session, and thus share the same transaction. This behavior can lead to unexpected results, such as one thread rolling back work that was done in another thread.
This situation can occur when a client application using a Snowflake driver (such as the Snowflake JDBC Driver) or a connector (such as the Snowflake Connector for Python) is multi-threaded. If two or more threads share the same connection, those threads also share the current transaction in that connection. A BEGIN TRANSACTION, COMMIT, or ROLLBACK by one thread affects all threads using that shared connection. If the threads are running asynchronously, the results can be unpredictable.
Similarly, changing the AUTOCOMMIT setting in one thread affects the AUTOCOMMIT setting in all other threads that use the same connection.
Snowflake recommends that multi-threaded client programs do at least one of the following:
Use a separate connection for each thread.
Note that even with separate connections, your code can still hit race conditions that generate unpredictable output; for example, one thread might delete data before another thread tries to update it.
Execute the threads synchronously rather than asynchronously, to control the order in which steps are performed.
Stored procedures and transactions¶
In general, the rules described in the previous sections also apply to stored procedures. This section provides additional information specific to stored procedures.
A transaction can be inside a stored procedure, or a stored procedure can be inside a transaction; however, a transaction cannot be partly inside and partly outside a stored procedure, or started in one stored procedure and finished in a different stored procedure.
For example:
You cannot start a transaction before calling the stored procedure, then complete the transaction inside the stored procedure. If you try to do this, Snowflake reports an error like this:
You cannot start a transaction inside the stored procedure, then complete the transaction after returning from the procedure. If a transaction is started inside a stored procedure and is still active when the stored procedure finishes, an error occurs and the transaction is rolled back.
These rules also apply to nested stored procedures. If procedure A calls procedure B, procedure B
cannot complete a transaction that was started in procedure A or vice versa. Each BEGIN TRANSACTION in A must
have a corresponding COMMIT (or ROLLBACK) in A, and each BEGIN TRANSACTION in B must have a corresponding
COMMIT (or ROLLBACK) in B.
If a stored procedure contains an explicit transaction, that transaction can contain either part or all of the body of the stored procedure. For example, in the following stored procedure, only some of the statements are inside the explicit transaction. (This example, and several subsequent examples, use pseudo-code for simplicity.)
Non-overlapping transactions¶
The sections below describe:
Using a stored procedure inside a transaction.
Using a transaction inside a stored procedure.
Using a stored procedure inside a transaction¶
In the simplest case, a stored procedure is considered to be inside of a transaction if the following conditions are met:
A BEGIN TRANSACTION is executed before the stored procedure is called.
The corresponding COMMIT (or ROLLBACK) is executed after the stored procedure completes.
The body of the stored procedure does not contain an explicit or implicit BEGIN TRANSACTION or COMMIT (or ROLLBACK).
The stored procedure inside the transaction follows the rules of the enclosing transaction:
If the transaction is committed, all the statements inside the procedure are committed.
If the transaction is rolled back, all statements inside the procedure are rolled back.
The following pseudo-code shows a stored procedure called entirely inside an explicit transaction:
This is equivalent to executing the following sequence of statements:
Using a transaction in a stored procedure¶
You can execute zero, one, or more transactions inside a stored procedure. The following pseudo-code shows an example of two transactions in one stored procedure:
The stored procedure could be called as shown here:
This is equivalent to executing the following sequence:
In this code, four separate transactions are executed. Each transaction either starts and completes outside the procedure, or starts and completes inside the procedure. No transaction is split across a procedure boundary (partly inside and partly outside the stored procedure). No transaction is nested in another transaction.
Scoped transactions¶
A stored procedure that contains a transaction can be called from within another transaction. For example, a transaction inside a stored procedure can include a call to another stored procedure that contains a transaction.
Snowflake does not treat the inner transaction as nested; instead, the inner transaction is a separate transaction. Snowflake calls these “autonomous scoped transactions” (or simply “scoped transactions”).
The starting point and ending point of each scoped transaction determine which statements are included in the transaction. The start and end can be explicit or implicit. Each SQL statement is part of only one transaction. An enclosing ROLLBACK or COMMIT does not undo an enclosed COMMIT or ROLLBACK.
Note
The terms “inner” and “outer” are commonly used when describing nested operations, such as nested stored procedure calls. However, transactions in Snowflake are not truly “nested”; therefore, to reduce confusion when referring to transactions, this document frequently uses the terms “enclosed” and “enclosing”, rather than “inner” and “outer”.
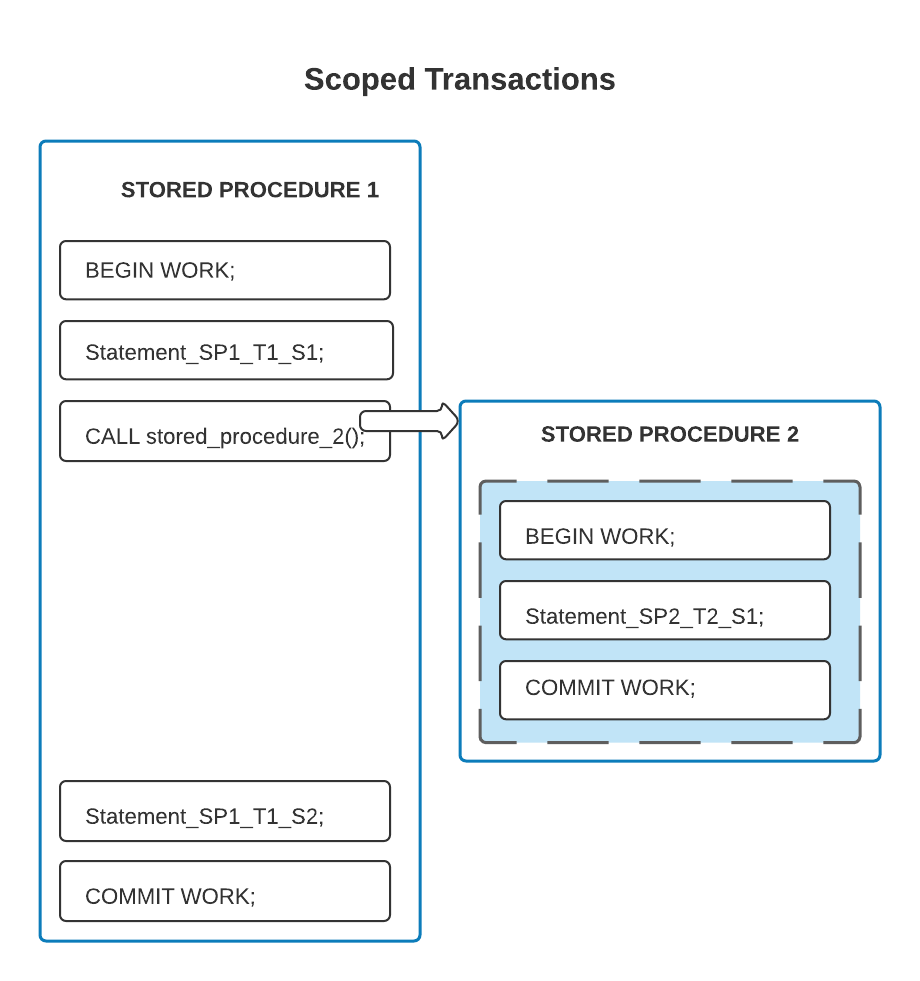
The diagram below shows two stored procedures and two scoped transactions. In this example, each stored procedure contains its own independent transaction. The first stored procedure calls the second stored procedure, so the procedures overlap in time; however, they do not overlap in content. All the statements inside the shaded inner box are in one transaction; all the other statements are in another transaction.
In the next example, the transaction boundaries are different from the stored procedure boundaries; the transaction that starts in the enclosing stored procedure includes some but not all of the statements in the enclosed stored procedure.
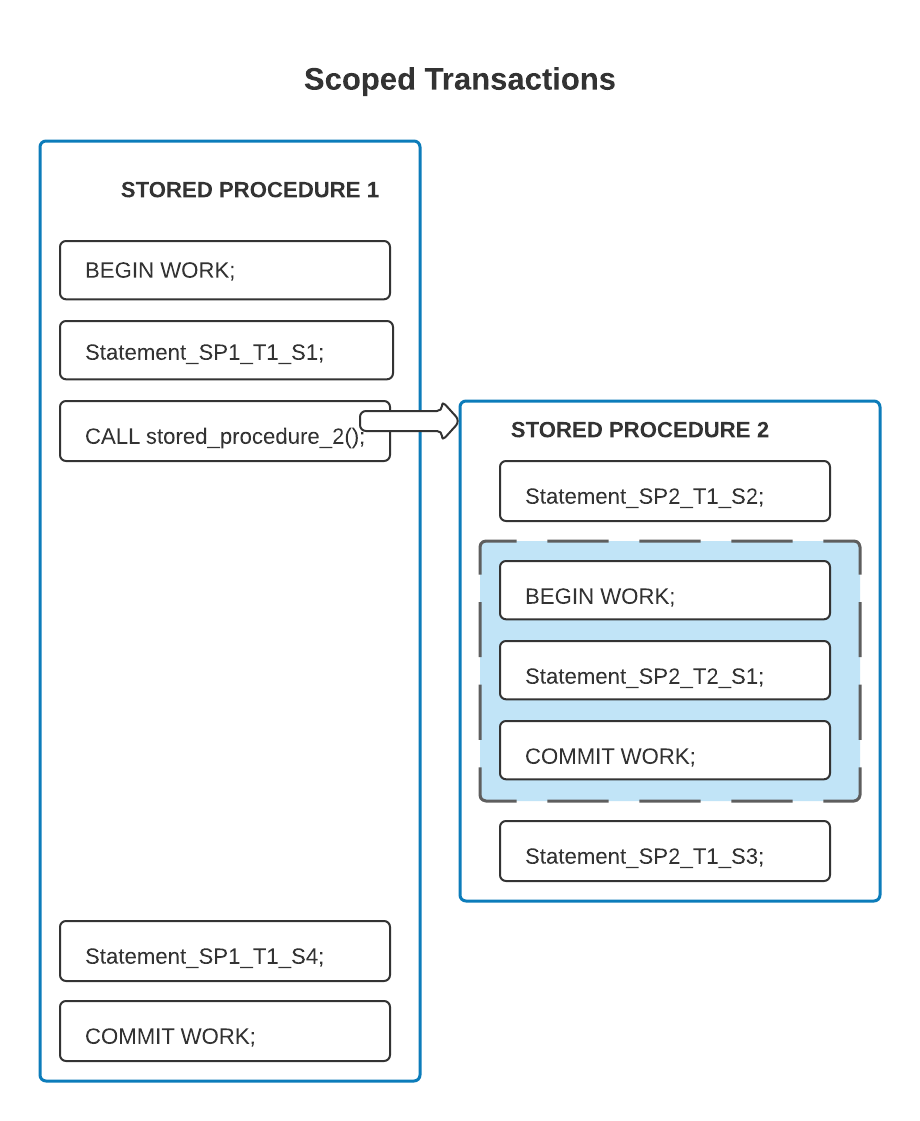
In the code above, the second stored procedure contains some statements (SP2_T1_S2 and SP2_T1_S3) that are in the
scope of the first transaction. Only statement SP2_T2_S1, inside the shaded inner box, is in the scope of the second
transaction.
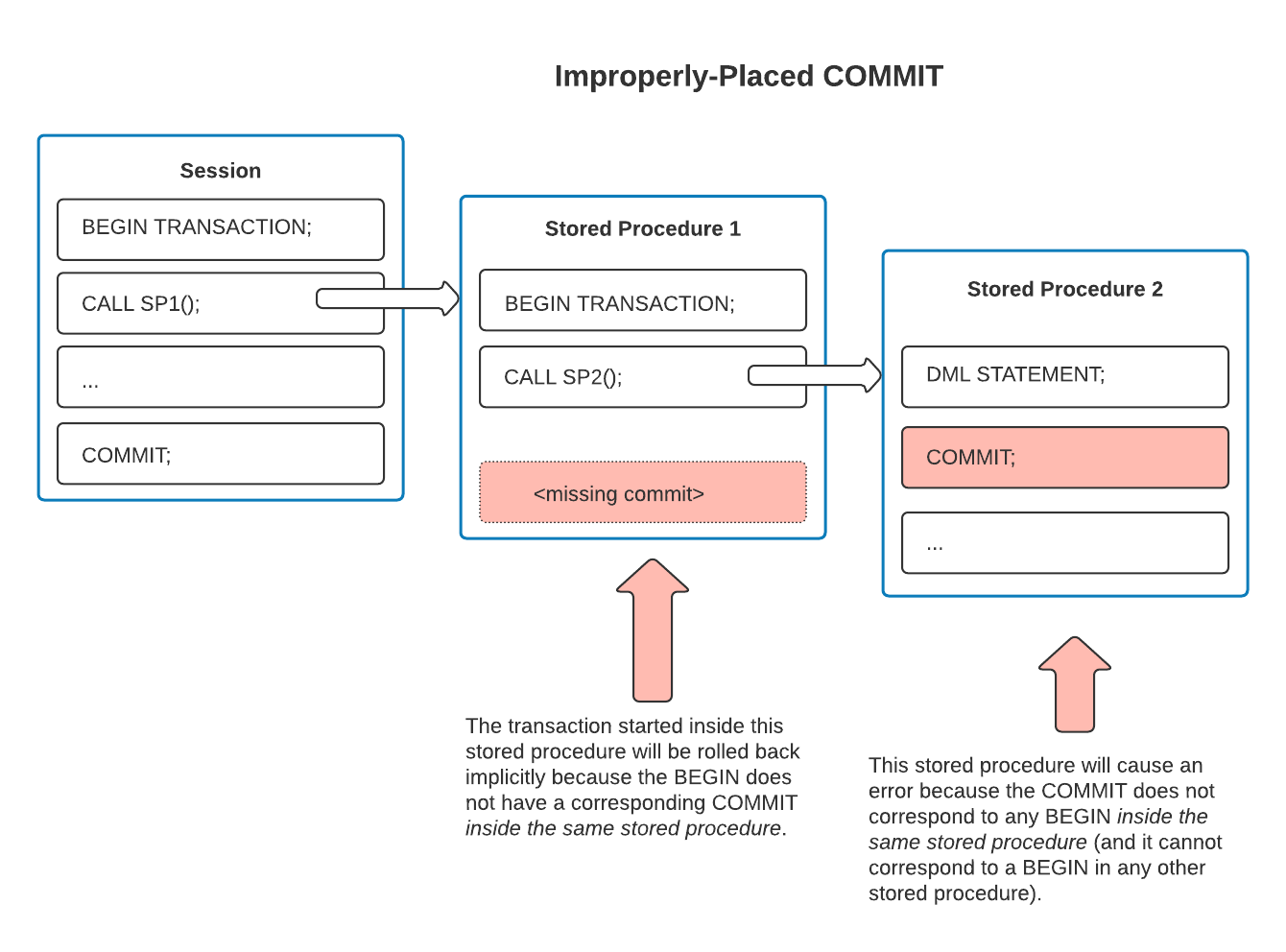
The next example demonstrates the problems that occur if a transaction does not begin and end within the same stored procedure. The example contains the same number of COMMIT statements as BEGIN statements. However, the BEGIN and COMMIT statements are not paired properly, so this example contains two errors:
The enclosing stored procedure starts a scoped transaction, but doesn’t explicitly complete it. Therefore that scoped transaction causes an error at the end of that stored procedure, and the active transaction is implicitly rolled back.
The second stored procedure contains a COMMIT, but there is no corresponding BEGIN in that stored procedure. This COMMIT does not commit the open transaction started in the first stored procedure. Instead, the improperly paired COMMIT causes an error.
The next example shows three scoped transactions that overlap in time. In this example,
stored procedure p1() calls another stored procedure p2() from inside a transaction, and p2()
contains its own transaction, so the transaction started in p2() also runs independently.
(This example uses pseudo-code.)
In these three scoped transactions:
The transaction that is outside any stored procedure contains statements
AandE.The transaction in stored procedure
p1()contains statementsBandDThe transaction in
p2()contains statementC.
The rules for scoped transactions also apply to recursive stored procedure calls. A recursive call is just a specific type of nested call, and follows the same transaction rules as a nested call.
Caution
Overlapping scoped transactions can cause a deadlock if they manipulate the same database object (such as a table). Scoped transactions should be used only when necessary.
Implicit commits for transactions inside stored procedures¶
Some commands, including most DDL statements, implicitly commit any active transaction. If an outer stored procedure opens a transaction and an inner stored procedure executes such a command, the command returns the following error message:
For example, the following code fails because the DROP TAG statement in the inner procedure attempts to implicitly commit the transaction that was started in the outer procedure:
To avoid this error, do not execute DDL statements (or other commands that implicitly commit transactions) inside a stored procedure that might be called from within an active transaction started in another scope.
Implicit ROLLBACK for transactions at the end of stored procedures¶
When AUTOCOMMIT is disabled, be especially careful with combining implicit transactions and stored procedures. If you accidentally leave a transaction active at the end of a stored procedure, the transaction is rolled back.
For example, the following pseudo-code example causes an implicit ROLLBACK at the end of the stored procedure:
In this example, the command to set AUTOCOMMIT commits any active transaction. A new transaction is not started immediately. The stored procedure contains a DML statement, which implicitly begins a new transaction. That implicit BEGIN TRANSACTION does not have a matching COMMIT or ROLLBACK in the stored procedure. Because there is an active transaction at the end of the stored procedure, that active transaction is implicitly rolled back.
If you want to run the entire stored procedure in a single transaction, start the transaction before you call the stored procedure, and commit the transaction after the call:
In this case, the BEGIN and COMMIT are properly paired, and the code executes without error.
As an alternative, put both the BEGIN TRANSACTION and the COMMIT inside the stored procedure, as shown in the following pseudo-code example:
Improperly paired BEGIN/COMMIT blocks in scoped transactions¶
If you do not pair your BEGIN/COMMIT blocks properly in a scoped transaction, Snowflake reports an error. That error can have further impacts, such as preventing a stored procedure from being completed or preventing an enclosing transaction from being committed. For example, in the following pseudo-code example, some statements in the enclosing stored procedure, as well as the enclosed stored procedure, are rolled back:
In this example, the only value that is inserted is osp1_alpha. None of the other values are inserted because a COMMIT is not correctly
paired with a BEGIN. The error is handled as follows:
When procedure
inner_sp2()finishes, Snowflake detects that the BEGIN ininner_sp2()has no corresponding COMMIT (or ROLLBACK).Snowflake implicitly rolls back the scoped transaction that started in
inner_sp2().Snowflake also returns an error because the CALL to
inner_sp2()failed.
Because the CALL to
inner_sp2()failed, and because that CALL statement was inouter_sp1(), the stored procedureouter_sp1()itself also fails and returns an error, rather than continuing.Because
outer_sp1()does not finish executing:The INSERT statements for values
osp1_deltaandosp1_omeganever execute.The open transaction in
outer_sp1()is implicitly rolled back rather than committed, so the insert of valueosp1_betais never committed.
Apache Iceberg™ tables and transactions¶
The Snowflake transaction principles generally apply to Apache Iceberg™ tables. For more information about transactions specific to Iceberg tables, see the Iceberg topic on transactions.
READ COMMITTED isolation level¶
READ COMMITTED is the only isolation level currently supported for tables. With READ COMMITTED isolation, a statement sees only data that was committed before the statement began. It never sees uncommitted data.
When a statement is executed inside a multi-statement transaction:
A statement sees only data that was committed before the statement began. Two successive statements in the same transaction can see different data if another transaction is committed between the execution of the first and the second statements.
A statement does see the changes made by previous statements executed within the same transaction, even though those changes are not yet committed.
Read consistency across sessions¶
In general, Snowflake maintains read consistency for all changes that occur within any given session, such as changes introduced by DDL and DML operations. When a user starts a new session, all changes that were committed before the session started, and all changes that are committed within the session, are immediately visible to subsequent queries in that session. This is standard behavior and matches the requirements for most workloads.
If you want to extend read consistency to be guaranteed across sessions that are running queries in a near-concurrent fashion, and you are willing to accept a
small delay in query response times (usually milliseconds), set the READ_CONSISTENCY_MODE parameter to 'GLOBAL'. By setting
this parameter, you change the default behavior such that queries read any near-concurrent changes that occur in concurrently running sessions. An alternative way to
guarantee this level of consistency is to run all queries in the same session.
For example, using the default 'SESSION' value:
Session 1 starts.
Session 2 starts.
Session 1 inserts a row into table
t.Session 1 selects data from table
tand sees the new row immediately.Session 2 runs the same query. Session 2 might not see the new row.
To guarantee that Sessions 1 and 2 get the same result for the same query in this scenario, follow one of these three steps, which are presented in order, from most recommended to least recommended:
Use a single session for all of the queries that depend on each other. In this case:
Session 1 starts.
Session 1 inserts a row into table
t.Session 1 selects data from table
tand sees the new row immediately.
Start Session 2 after the changes are committed in Session 1. In this case:
Session 1 starts.
Session 1 inserts a row into table
t.Session 2 starts.
Session 1 selects data from table
tand sees the new row immediately.Session 2 runs the same query and is guaranteed to see the new row.
Use the ALTER ACCOUNT command to set READ_CONSISTENCY_MODE to
'GLOBAL':This parameter can only be set at the account level by a user with ACCOUNTADMIN privileges.
Resource locking¶
Transactional operations acquire locks on a resource, such as a table, while that resource is being modified. Locks block other statements from modifying the resource until the lock is released.
The following guidelines apply in most situations:
COMMIT operations (including both AUTOCOMMIT and explicit COMMIT) lock resources, but usually only briefly.
CREATE TABLE, CREATE DYNAMIC TABLE, CREATE STREAM, and ALTER TABLE operations all lock their underlying resources when setting CHANGE_TRACKING = TRUE, but usually only briefly. Only UPDATE and DELETE DML operations are blocked when a table is locked. INSERT operations are not blocked.
UPDATE, DELETE, and MERGE statements hold locks that generally prevent them from running in parallel with other UPDATE, DELETE, and MERGE statements.
For hybrid tables, locks are held on individual rows. Locks on UPDATE, DELETE, and MERGE statements only prevent parallel UPDATE, DELETE, and MERGE statements that operate on the same row or rows. UPDATE, DELETE, and MERGE on different rows in the same table can progress.
Most INSERT and COPY statements write only new partitions. Those statements often can run in parallel with other INSERT and COPY operations, and sometimes can run in parallel with an UPDATE, DELETE, or MERGE statement.
Avoid executing INSERT and COPY statements concurrently with DDL statements on the same object in different sessions, because doing so can result in inconsistencies. When INSERT or COPY statements are executed on an object in an explicit transaction, avoid DDL statements on the same object in different sessions for the duration of the transaction. For example, don’t run INSERT statements on a table in one session while simultaneously running a DDL statement that changes the data type of a column in the table in a different session.
Locks held by a statement are released on COMMIT or ROLLBACK of the transaction.
Lock timeout parameters¶
Two parameters control timeout for locks: LOCK_TIMEOUT and HYBRID_TABLE_LOCK_TIMEOUT.
LOCK_TIMEOUT parameter¶
A blocked statement either acquires a lock on the resource it is waiting for or times out, while waiting for the resource to become available. You can set the length of time (in seconds) that a statement should block by setting the LOCK_TIMEOUT parameter.
For example, to change the lock timeout to 2 hours (7200 seconds) for the current session:
HYBRID_TABLE_LOCK_TIMEOUT parameter¶
A blocked statement on a hybrid table either acquires a row-level lock on the table it is waiting for or times out, while waiting for the table to become available. You can set the length of time (in seconds) that a statement should block by setting the HYBRID_TABLE_LOCK_TIMEOUT parameter.
For example, to change the hybrid table lock timeout to 10 minutes (600 seconds) for the current session:
Deadlocks¶
Deadlocks may occur when concurrent transactions are waiting on resources that are locked by each other.
Note the following rules:
Deadlocks cannot occur while autocommit query statements are being executed concurrently. This is true for both standard tables and hybrid tables because SELECT statements are always read-only.
Deadlocks cannot occur with autocommit DML operations on standard tables, but they can occur with autocommit DML operations on hybrid tables.
Deadlocks can occur when transactions are started explicitly and multiple statements are executed in each transaction. Snowflake detects deadlocks and chooses the most recent statement that is part of the deadlock as the victim. The statement is rolled back, but the transaction itself remains active and must be committed or rolled back.
Deadlock detection can take time.
Managing transactions and locks¶
Snowflake provides the following SQL commands to help you monitor and manage transactions and locks:
The LOCK_WAIT_HISTORY view logs a detailed history of transactions with respect to locking, showing when specific locks were requested and acquired.
In addition, Snowflake provides the following context functions for obtaining information about transactions within a session:
You can call the following function to abort a transaction: SYSTEM$ABORT_TRANSACTION.
Aborting transactions¶
If a transaction is running in a session and the session disconnects abruptly, preventing the transaction from committing or rolling back, the transaction is left in a detached state, including any locks that the transaction is holding on resources. If this happens, you might need to abort the transaction.
To abort a running transaction, the user who started the transaction or an account administrator can call the system function, SYSTEM$ABORT_TRANSACTION.
If the transaction is not aborted by the user:
And it blocks another transaction from acquiring a lock on the same table and is idle for 5 minutes, it is automatically aborted and rolled back.
And it does not block other transactions from modifying the same table and is older than 4 hours, it is automatically aborted and rolled back.
And it reads from or writes to hybrid tables, and is idle for 5 minutes, it is automatically aborted and rolled back, regardless of whether it blocks other transactions from modifying the same table.
To allow a statement error within a transaction to abort the transaction, set the TRANSACTION_ABORT_ON_ERROR parameter at the session or account level.
Analyzing blocked transactions with the LOCK_WAIT_HISTORY view¶
The LOCK_WAIT_HISTORY view returns transaction details that can be useful in analyzing blocked transactions. Each row in the output includes the details for a transaction that is waiting on a lock and the details of transactions that are holding that lock or waiting ahead for that lock.
For example, see the scenario below:
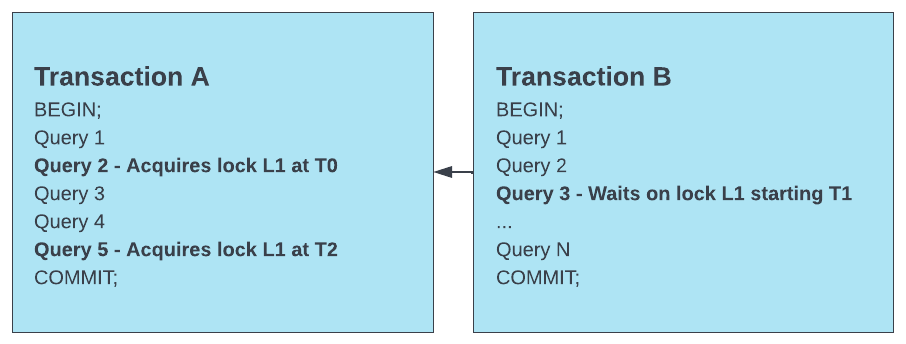
In this scenario, the following data is returned:
Transaction B is the transaction that is waiting for a lock.
Transaction B requested the lock at timestamp T1.
Transaction A is the transaction that holds the lock.
Query 2 in Transaction A is the blocker query.
Query 2 is the blocker query because it is the first statement in Transaction A (the transaction holding the lock) that Transaction B (the transaction waiting for the lock) started waiting on.
However, note that a later query in Transaction A (Query 5) also acquired the lock. It is possible that subsequent concurrent executions of these transactions could cause Transaction B to block on a different query that acquires the lock in Transaction A. Therefore, you must investigate all queries in the first blocker transaction.
See also Transaction and lock visibility for hybrid tables.
Examining a long-running statement¶
Query the Account Usage QUERY_HISTORY view for transactions that waited for locks in the last 24 hours:
Review the results of the query and note the query IDs of the queries with high TRANSACTION_BLOCKED_TIME values.
To find blocker transactions for the queries identified from the previous step, query the LOCK_WAIT_HISTORY view for rows with those query IDs:
There may be multiple queries in the
blocker_queriescolumn in the results. Note thetransaction_idof each blocker query in the output.Query the QUERY_HISTORY view for each transaction in the
blocker_queriesoutput:Investigate the query results. If a statement in the transaction was a DML statement and operated on the locked resource, it may have acquired the lock at some point during the transaction.
Monitoring transactions and locks¶
You can use the SHOW TRANSACTIONS command to return a list of transactions being run by the current user (in all of that user’s sessions) or by all users in all sessions in the account. The following example is for the current user’s sessions.
Every Snowflake transaction is assigned a unique transaction ID. The id value is a signed 64-bit (long) integer. The range of
values is -9,223,372,036,854,775,808 (-2 63) to 9,223,372,036,854,775,807 (2 63 - 1).
You can also use the CURRENT_TRANSACTION function to return the transaction ID of the transaction currently running in the session.
If you know the transaction ID you want to monitor, you can use the DESCRIBE TRANSACTION command to return details about the transaction, while it is still running or after it has committed or aborted. For example:
Transaction and lock visibility for hybrid tables¶
When you are looking at the output of commands and views for transactions that access hybrid tables, or locks on hybrid table rows, note the following behavior:
Transactions are listed only if they are blocking other transactions, or if they are blocked.
Keep in mind that transactions that access hybrid tables hold row-level locks (
ROWtype). If two transactions access different rows in the same table, they do not block each other.Transactions are listed only if a blocked transaction has been blocked for more than 5 seconds.
When a transaction is no longer blocked, it might still appear in the output, but for no more than 15 seconds.
Similarly, in the SHOW LOCKS output, the following rules apply:
A lock is listed only if one transaction holds the lock and the other transaction is blocked on that particular lock.
In the
typecolumn, hybrid table locks showROW.The
resourcecolumn always shows the blocking transaction ID. (The blocked transaction is blocked by the transaction with this ID.)In many cases, queries against hybrid tables do not generate query IDs. See Usage notes.
For example:
In the LOCK_WAIT_HISTORY view, the output behaves as follows:
The
requested_atandacquired_atcolumns define when row-level locks were requested and acquired, subject to the general rules for reporting transaction activity with hybrid tables.The
lock_typeandobject_namecolumns both show the valueRow.The
schema_idandschema_namecolumns are always empty (0and NULL, respectively).The
object_idcolumn always shows the blocking object’s ID.The
blocker_queriescolumn is a JSON array with exactly one element, which shows the blocking transaction.Even if multiple transactions are blocked on the same row, they are shown as multiple rows in the output.
For example:
Best practices¶
A transaction should contain statements that are related and should succeed or fail together, for example, withdrawing money from one account and depositing that same money to another account. If a rollback occurs, either the payer or the recipient ends up with the money; the money never “disappears” (withdrawn from one account but never deposited to the other account).
In general, one transaction should contain only related statements. Making a statement less granular means that when a transaction is rolled back, it might roll back useful work that didn’t actually need to be rolled back.
Larger transactions can improve performance in some cases for standard tables, but not typically for hybrid tables.
Although the preceding bullet point emphasized the importance of grouping only statements that truly need to be committed or rolled back as a group, larger transactions can sometimes be useful. In Snowflake, as in most databases, managing transactions consumes resources. For example, inserting 10 rows in one transaction is generally faster and cheaper than inserting one row each in 10 separate transactions. Combining multiple statements into a single transaction can improve performance.
Overly large transactions can reduce parallelism or increase deadlocks. If you do decide to group unrelated statements to improve performance (as described in the previous bullet point), keep in mind that a transaction can acquire locks on resources, which can delay other queries or lead to deadlocks.
For hybrid tables:
AUTOCOMMIT DML statements in general run much faster than non-AUTOCOMMIT DML statements.
Relatively small AUTOCOMMIT DML statements run much faster than non-AUTOCOMMIT DML statements. DML statements that run in under 5 seconds or access no more than 1 MB of data take advantage of a fast mode that is not available to longer-running or larger DML statements.
Snowflake recommends keeping AUTOCOMMIT enabled and using explicit transactions as much as possible. Using explicit transactions makes it easier for human readers to see where transactions begin and end. This, combined with AUTOCOMMIT, makes your code less likely to experience unintended rollbacks, for example at the end of a stored procedure.
Avoid changing AUTOCOMMIT merely to start a new transaction implicitly. Instead, use BEGIN TRANSACTION to make it more obvious where a new transaction starts.
Avoid executing more than one BEGIN TRANSACTION statement in a row. Extra BEGIN TRANSACTION statements make it harder to see where a transaction actually begins, and make it harder to pair COMMIT/ROLLBACK commands with the corresponding BEGIN TRANSACTION.
Examples¶
Simple example of scoped transaction and stored procedure¶
This is a simple example of scoped transactions. The stored procedure contains a transaction that inserts a row with the value 12 and then rolls back. The outer transaction commits. The output shows that all rows in the scope of the outer transaction are kept, while the row in the scope of the inner transaction is not kept.
Note that because only part of the stored procedure is inside its own transaction, values inserted by the INSERT statements that are in the stored procedure, but outside the stored procedure’s transaction, are kept.
Create two tables:
Create the stored procedure:
Call the stored procedure:
The results should include 00, 11, 13, and 09. The row with ID = 12 should not be included. This row was in the scope of the enclosed transaction, which was rolled back. All other rows were in the scope of the outer transaction, and were committed. Note in particular that the rows with IDs 11 and 13 were inside the stored procedure, but outside the innermost transaction; they are in the scope of the enclosing transaction, and were committed with that.
Logging information independently of a transaction’s success¶
This is a simple, practical example of how to use a scoped transaction. In this example, a transaction logs certain information; that logged information is preserved whether the transaction itself succeeds or fails. This technique can be used to track all attempted actions, whether or not each succeeded.
Create two tables:
Create the stored procedure:
Call the stored procedure:
The data table is empty because the transaction was rolled back:
However, the logging table is not empty; the insert into the logging table was done in a separate transaction from the insert into data_table.
Examples of scoped transactions and stored procedures¶
The next few examples use the tables and stored procedures shown below. By passing appropriate parameters, the caller can control where BEGIN TRANSACTION, COMMIT, and ROLLBACK statements are executed inside the stored procedures.
Create the tables:
This procedure is the enclosing stored procedure, and depending upon the parameters passed to it, can create an enclosing transaction.
This procedure is the inner stored procedure, and depending upon the parameters passed to it, can create an enclosed transaction.
Commit the middle level of three levels¶
This example contains 3 transactions. This example commits the “middle” level (the transaction enclosed by the outer-most transaction and enclosing the inner-most transaction). This rolls back the outer-most and inner-most transactions.
The result is that only the rows in the middle transaction (12, 21, and 23) are committed. The rows in the outer transaction and the inner transaction are not committed.
Roll back the middle level of three levels¶
This example contains 3 transactions. This example rolls back the “middle” level (the transaction enclosed by the outer-most transaction and enclosing the inner-most transaction). This commits the outer-most and inner-most transactions.
The result is that all rows except the rows in the middle transaction (12, 21, and 23) are committed.
Using error handling with transactions in stored procedures¶
The following code shows simple error handling for a transaction in a stored procedure. If the parameter value ‘fail’ is passed, the stored procedure tries to delete from two tables that exist and one table that doesn’t exist, and the stored procedure catches the error and returns an error message. If the parameter value ‘fail’ is not passed, the procedure tries to delete from two tables that do exist, and succeeds.
Create the tables and stored procedure:
Call the stored procedure and force an error:
Call the stored procedure without forcing an error: