Hybrid tables¶
A hybrid table is a Snowflake table type that is optimized for low latency and high throughput using index-based random reads and writes. Hybrid tables provide a row-based storage engine that supports row locking for high concurrency. Hybrid tables also enforce unique and referential integrity constraints, which are critical for transactional workloads. You can use a hybrid table along with other Snowflake tables and features to power Unistore workloads that bring transactional and analytical data together in a single platform.
Use cases that may benefit from hybrid tables include:
- Metadata for applications and workflows, such as maintaining state for an ingestion workflow that requires high-concurrency updates to a single table from thousands of parallel workers.
- Lower-latency serving of precomputed aggregates through an API or a user interface.
- Lightweight transactional applications with relational data models.
Tip
Before creating and using hybrid tables, you should become familiar with some unsupported features and limitations.
Architecture¶
Hybrid tables integrate seamlessly into the existing Snowflake architecture. Customers connect to the same Snowflake database service. Queries are compiled and optimized in the cloud services layer and executed in the same query engine and virtual warehouses as standard tables. This architecture has several key benefits:
- Snowflake platform features, such as data governance, work with hybrid tables out of the box.
- You can run hybrid workloads that mix operational and analytical queries.
- You can join hybrid tables with other Snowflake tables; queries executed natively and efficiently in the same query engine. No federation is required.
- You can execute an atomic transaction across hybrid tables and other Snowflake tables. There is no need to orchestrate your own two-phase commit.
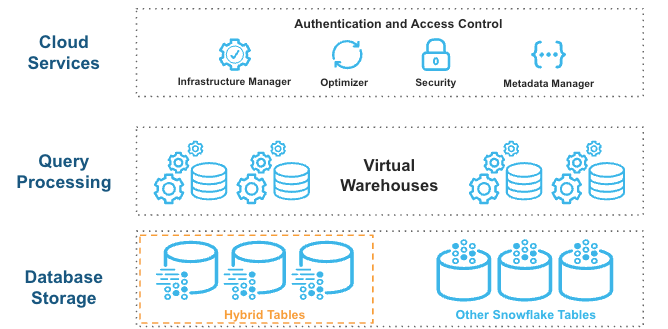
Hybrid tables leverage a row store as the primary data store to provide excellent operational query performance. When you write to a hybrid table, the data is written directly into the row store. Data is asynchronously copied into object storage in order to provide better performance and workload isolation for large scans without affecting your ongoing operational workloads. Some data may also be cached in columnar format on your warehouse in order to provide better performance for analytical queries. You simply execute SQL statements against the logical hybrid table and the Snowflake query optimizer decides where to read data from in order to provide the best performance. You get one consistent view of your data without needing to worry about the underlying infrastructure.
Note
Because the primary storage for hybrid tables is a row store, hybrid tables typically have a larger storage footprint than standard tables. The main reason for the difference is that columnar data for standard tables often achieves higher rates of compression. For details about storage costs, see Evaluate cost for hybrid tables.
Features¶
Hybrid tables provide some additional features that are not supported by other Snowflake table types.
| Feature | Hybrid tables | Standard tables |
|---|---|---|
| Primary data layout | Row-oriented, with secondary columnar storage | Columnar micro-partitions |
| Locking | Row-level | Partition or table |
| PRIMARY KEY constraints | Required, enforced | Optional, not enforced |
| FOREIGN KEY constraints | Optional, enforced (referential integrity) | Optional, not enforced |
| UNIQUE constraints | Optional (except for PRIMARY KEY), enforced | Optional, not enforced |
| NOT NULL constraints | Optional (except for PRIMARY KEY), enforced | Optional, enforced |
| Indexes | Supported for performance; updated synchronously on writes | The search optimization service indexes columns for better point-lookup performance; batch updated/maintained asynchronously |
A constraint is enforced when it protects a column from being updated in certain ways. For example, a column that is declared NOT NULL cannot contain a NULL value. An attempt to copy or insert a NULL value into a NOT NULL column always results in an error.
For hybrid tables, you cannot set the NOT ENFORCED property on PRIMARY KEY, FOREIGN KEY, and UNIQUE constraints. Setting this property results in an “invalid constraint property” error. For more information about rules for constraints, see Constraints for hybrid tables.
A constraint is required when one or more columns in a table must have such a constraint, which is only true for PRIMARY KEY constraints on hybrid tables.
When to use a hybrid table¶
While you should expect Snowflake standard tables to offer better performance on large analytical queries, hybrid tables allow for faster results on short-running operational queries. Hybrid tables deliver high concurrency and low latency for many workloads. The following types of queries are most likely to benefit from hybrid tables:
- Index-based random-point reads that retrieve a small number of records, such as customer objects
- High-concurrency random writes, including inserts, updates, and merges:
Applications commonly work with a mix of hybrid tables and standard tables, with different data sets stored in each table type. For example, you might have some data that you frequently bulk load, scan, and aggregate for analytics purposes, and other data that you access one row at a time, filtered on an ID column at high concurrency. You can blend the use of standard tables and hybrid tables in a single database based on the needs of your workload.