Snowflake Cortex Vector Search¶
Modern deep learning techniques can create structured numerical representations (vectors) from unstructured data like text and images, preserving semantic notions of similarity and dissimilarity in the geometry of the embedding vectors they produce.
Bemerkung
„Embedding“ refers to the reduction of high-dimensional data (such as unstructured text) to a representation with fewer dimensions, such as a vector.
The illustration below is a simplified example of the vector embedding and geometric similarity of natural language text. In practice, neural networks produce embedding vectors with hundreds or even thousands of dimensions, not two as shown here, but the concept is the same. Semantically similar text yields vectors that „point“ in the same general direction.
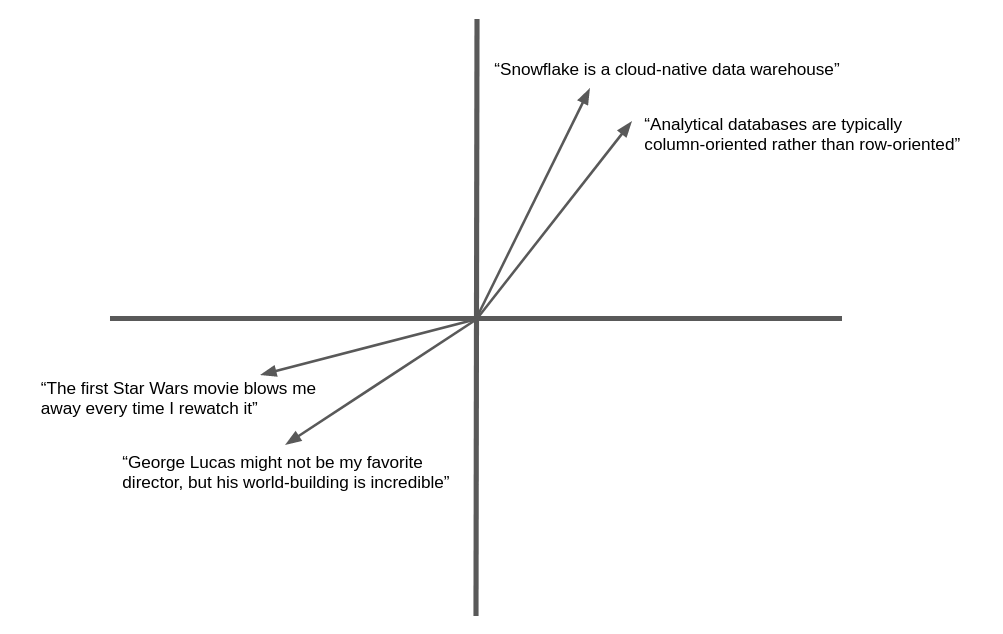
Many applications can benefit from the ability to find text or images similar to a target. For example, when a new support case is logged at a help desk, the support team can benefit from the ability to find similar cases that have already been resolved. The advantage of using embedding vectors in this application is that it goes beyond keyword matching to semantic similarity, so related records can be found even if they don’t contain exactly the same words.
Tipp
All Snowflake Cortex LLM functions are in the SNOWFLAKE.CORTEX schema. Update your search path to avoid having to specify the schema with every function call.
Vector Data Type¶
With the VECTOR data type, Snowflake encodes and processes vectors efficiently. This new type supports semantic vector search and retrieval applications, such as for large language models (LLMs), and common operations on vectors in vector processing applications.
A value of type VECTOR is defined by two parameters:
The type of the elements (either 32-bit integers or 32-bit floating point numbers).
The dimension (length) of the vector.
Syntax¶
VECTOR({INT | FLOAT}, <dimension>)
Examples¶
-- valid
VECTOR(FLOAT, 256) -- a vector of 256 32-bit float values
VECTOR(INT, 16) -- a vector of 16 32-bit integer values
-- invalid
VECTOR(STRING, 256) -- not a valid type
VECTOR(INT, -1) -- not a valid vector size
Limitations¶
In this preview, vectors are not supported in materialized views and in variants. In addition, direct vector comparisons (e.g. v1 < v2) are lexicographic, and arithmetic operations on vectors are not supported other than through user-defined functions (UDFs). Only Python UDFs are supported; table functions (UDTFs) are not supported.
Creating an Embedding¶
Wichtig
The E5-base-v2 model has an input limit of 512 tokens. Some tokens do not represent words, so the number of words supported is somewhat less. You will receive an error message if the text is too long.
To create an embedding from a piece of text, use the EMBED_TEXT function. This function returns the vector embeddings for a given English-language text. This vector can be used with the vector comparison functions to determine the semantic similarity of two documents.
SNOWFLAKE.CORTEX.EMBED_TEXT(model, text) -- returns VECTOR
model: The language model to be used to generate the embeddings. Currently this must be ‚e5-base-v2‘.text: The text for which an embedding should be calculated.
Tipp
You can use other embedding models through Snowpark Container Services. For more information, see Embed Text Container Service.
Vector Search and Distance Functions¶
The calculation of distances between vectors is a fundamental operation in semantic comparison. For example, you need this operation to find the top K closest vectors to a query vector, which can be used for a semantic search. Vector search also enables developers to improve the accuracy of their generative AI responses by providing related documents to a large language model.
Snowflake Cortex provides three vector distance functions: inner product, L2 distance, and cosine similarity. Each function takes two vector arguments of equal element type and dimension and computes the specified metric over them.
Bemerkung
Due to computational optimizations in these functions, floating point errors may be slightly larger than usual (e.g. about 1e-4).
VECTOR_INNER_PRODUCT¶
The inner product (also known as the dot or scalar product) multiplies two vectors together. The result represents the combined direction of the two vectors. Similar vectors result in larger inner products than dissimilar ones.
VECTOR_INNER_PRODUCT(<vector>, <vector>)
VECTOR_L2_DISTANCE¶
L2 distance is the L² norm Euclidean line distance between two vectors in the vector space, calculated by taking the square root of the sum of the squared differences of vector elements. The distance can be any value between zero and infinity. If the distance is zero, the vectors are identical. The larger the distance, the farther apart the vectors are.
VECTOR_L2_DISTANCE(<vector>, <vector>)
VECTOR_COSINE_SIMILARITY¶
Cosine similarity is based on the angle between two vectors in a multi-dimensional space; the magnitude of the vectors is not considered. It is the inner product of the vectors divided by the product of their lengths. The cosine similarity is always in the interval [-1, 1]. For example, identical vectors have a cosine similarity of 1, two orthogonal vectors have a similarity of 0, and two opposite vectors have a similarity of -1.
VECTOR_COSINE_DISTANCE(<vector>, <vector>)
Examples¶
SQL¶
CREATE TABLE vectors (a VECTOR(float, 3), b VECTOR(float, 3));
INSERT INTO vectors SELECT [1.1,2.2,3]::VECTOR(FLOAT,3), [1,1,1]::VECTOR(FLOAT,3);
INSERT INTO vectors SELECT [1,2.2,3]::VECTOR(FLOAT,3), [4,6,8]::VECTOR(FLOAT,3);
-- Compute the pairwise inner product between columns a and b
SELECT VECTOR_INNER_PRODUCT(a, b) FROM vectors;
Output:
+------+
| 6.3 |
|------|
| 41.2 |
+------+
-- Find the closest vector to [1,2,3]
SELECT a, VECTOR_COSINE_DISTANCE(a, [1,2,3]::VECTOR(FLOAT, 3)) AS similarity
FROM vectors
ORDER BY similarity DESC
LIMIT 1;
Output:
+-------------------------+
| [1, 2.2, 3] | 0.9990... |
+-------------------------+
Snowflake Python Connector¶
Bemerkung
Support for the VECTOR type was introduced in version 3.6 of the Snowflake Python Connector.
import snowflake.connector
conn = ... # Set up connection
cur = conn.cursor()
cur.execute("CREATE or replace TABLE vectors (a VECTOR(float, 3), b VECTOR(float, 3))")
values = [([1.1, 2.2, 3], [1, 1, 1]), ([1, 2.2, 3], [4, 6, 8])]
for row in values:
cur.execute(f"""
INSERT INTO vectors(a, b)
SELECT {row[0]}::VECTOR(float,3), {row[1]}::VECTOR(FLOAT,3)
""")
# Compute the pairwise inner product between columns a and b
cur.execute("SELECT VECTOR_INNER_PRODUCT(a, b) FROM vectors")
print(cur.fetchall())
Output:
[(6.30...,), (41.2...,)]
# Find the closest vector to [1,2,3]
cur.execute(f"""
SELECT a, VECTOR_COSINE_DISTANCE(a, {[1,2,3]}::VECTOR(FLOAT, 3))
AS similarity
FROM vectors
ORDER BY similarity DESC
LIMIT 1;
""")
print(cur.fetchall())
Output:
[([1.0, 2.2..., 3.0], 0.9990...)]
Snowpark Python¶
Bemerkung
Support for the VECTOR type was introduced in version 1.11 of Snowpark Python.
from snowflake.snowpark import Session, Row
session = ... # Set up session
from snowflake.snowpark.types import VectorType, StructType, StructField
from snowflake.snowpark.functions import col, lit, vector_l2_distance
schema = StructType([StructField("vec", VectorType(int, 3))])
data = [Row([1, 2, 3]), Row([4, 5, 6]), Row([7, 8, 9])]
df = session.create_dataframe(data, schema)
df.select(
"vec",
vector_l2_distance(df.vec, lit([1, 2, 2]).cast(VectorType(int, 3))).as_("dist"),
).sort("dist").limit(1).show()
Output:
----------------------
|"VEC" |"DIST" |
----------------------
|[1, 2, 3] |1.0 |
----------------------
Vector Search¶
To implement a search for semantically similar documents, first store the embeddings for the documents to be searched. (Keep the embeddings up to date when documents are added or edited.)
In this example, the documents are call center issues logged by support representatives. The issue is stored in a column
called issue_text in the table issues. The following SQL creates a new vector column to hold the
embeddings of the issues.
ALTER TABLE issues ADD COLUMN issue_vec VECTOR(FLOAT, 768);
UPDATE TABLE issues
SET issue_vec = SNOWFLAKE.CORTEX.EMBED_TEXT('e5-base-v2', issue_text);
To perform a search, create an embedding of the search term or target document, then use a vector distance function to locate documents with similar embeddings. Use ORDER BY and LIMIT clauses to select the top k matching documents, and optionally use a WHERE condition to specify a minimum similarity.
Generally, the call to the vector distance function should appear in the SELECT clause, not in the WHERE clause. This way, the function is called only for the rows specified by the WHERE clause, which may restrict the query based on some other criteria, instead of operating over all rows in the table. To test a similarity value in the WHERE clause, define a column alias for the VECTOR_SIMILARITY call in the SELECT clause, and use that alias in a condition in the WHERE clause.
This example finds up to five issues matching the search term from the last 90 days, assuming the cosine similarity with the search term is at least 0.7.
SET search_term = "User could not install Facebook app on his phone"
SET search_wec = SNOWFLAKE.VECTOR.EMBED_TEXT('e5-base-v2', $search_term)
SELECT
issue,
SNOWFLAKE.CORTEX.VECTOR_COSINE_DISTANCE(issue_vec, $search_vec) AS similarity
FROM issues
ORDER BY similarity DESC
LIMIT 5
WHERE DATEDIFF(day, CURRENT_DATE(), issue_date) < 90 AND similarity > 0.7;
Retrieval Augmented Generation¶
In retrieval augmented generation (RAG), a user’s query is used to find similar documents using vector search. The top document is then passed to a large language model (LLM) along with the user’s query, providing context for the generative response (completion). This can improve the appropriateness of the response significantly.
In the following example, wiki is a table with a text column content, and query is a single-row
table with a text column :text.
-- Create embedding vectors for wiki articles (only do once)
ALTER TABLE wiki ADD COLUMN vec VECTOR(FLOAT, 768);
UPDATE wiki SET vec = SNOWFLAKE.CORTEX.EMBED_TEXT('e5-base-v2', content);
-- Embed incoming query
ALTER TABLE query ADD COLUMN vec VECTOR(FLOAT, 768);
UPDATE query SET vec = SNOWFLAKE.CORTEX.EMBED_TEXT('e5-base-v2', text);
-- Do a semantic search to find the relevant wiki for the query
WITH result AS (
SELECT
content,
text AS query_text,
SNOWFLAKE.CORTEX.VECTOR_COSINE_DISTANCE(wiki.vec, query.vec) AS similarity
FROM wiki, query
ORDER BY similarity DESC
LIMIT 1
)
-- Pass to large language model as context
SELECT SNOWFLAKE.CORTEX.COMPLETE('mistral-7b',
CONCAT('Answer this question: ', query_text, ' using this text: ', content)) FROM result;
Cost Considerations¶
During this preview, the use of EMBED_TEXT is free but limited. You may embed 100,000 strings daily. We will announce changes to this polity well in advance. The use of the vector similarity functions is not limited.
Snowflake Cortex functions run in the warehouse that runs the query that calls them. The cost of running the function is part of the cost of running the query. The cost of vector embedding functions grows linearly with the size of the text. The cost of vector distance queries like the example grows linearly with the number of vectors and dimensions.
Legal Notices¶
The Snowflake Cortex EMBED_VECTOR function is powered by machine learning technology. Machine learning technology and results provided may be inaccurate, inappropriate, or biased. Decisions based on machine learning outputs, including those built into automatic pipelines, should have human oversight and review processes to ensure model-generated content is accurate.
LLM function queries will be treated as any other SQL query and may be considered metadata.