벡터 임베딩¶
임베딩 은 비정형 텍스트와 같은 고차원 데이터를 벡터와 같이 차원이 적은 표현으로 축소하는 것을 의미합니다. 최신 딥러닝 기술은 텍스트나 이미지와 같은 비정형 데이터에서 정형 숫자 표현인 벡터 임베딩을 생성하는 동시에 생성되는 벡터의 기하학적 유사성 및 비 유사성에 대한 의미 개념을 보존할 수 있습니다.
다음 그림은 자연어 텍스트의 벡터 임베딩과 기하학적 유사성에 대한 단순화된 예시입니다. 실제로 신경망은 여기에 표시된 것처럼 두 차원이 아닌 수백 또는 수천 개의 차원을 가진 임베딩 벡터를 생성하지만 개념은 동일합니다. 의미 체계가 유사한 텍스트는 동일한 일반 방향을 ‘가리키는’ 벡터를 생성합니다.
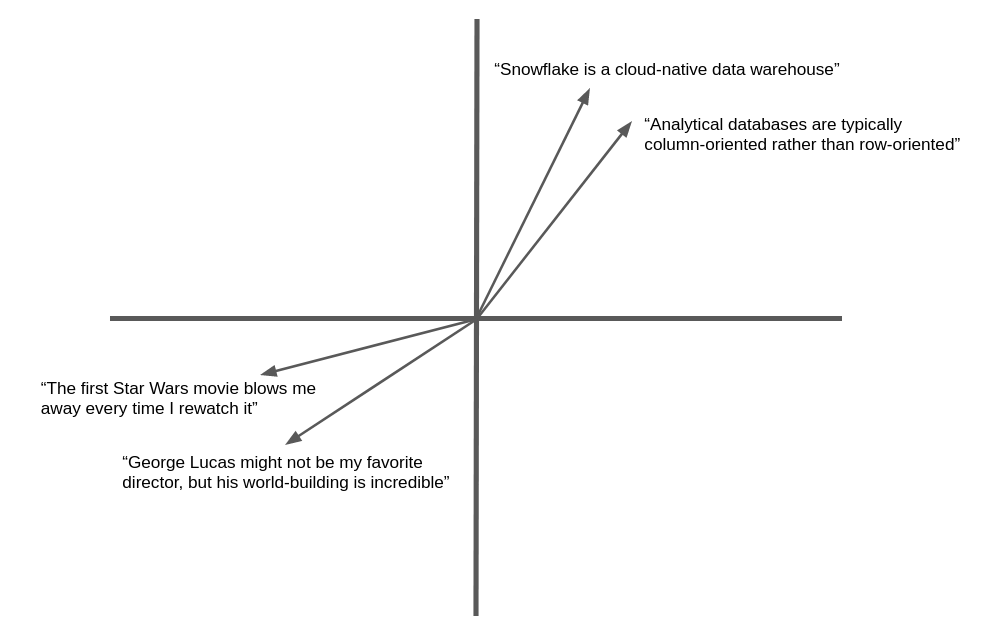
많은 응용 사례에서는 대상과 유사한 텍스트나 이미지를 찾는 기능을 통해 이점을 얻을 수 있습니다. 예를 들어, 헬프 데스크에 새로운 지원 사례가 등록되면 지원팀은 이미 해결된 유사한 사례를 찾을 수 있는 기능을 활용할 수 있습니다. 이 응용 사례에서 임베딩 벡터를 사용하면 키워드 매칭을 넘어 의미 체계의 유사성까지 고려하므로 정확히 같은 단어가 포함되어 있지 않더라도 관련 기록을 찾을 수 있다는 장점이 있습니다.
Snowflake Cortex는 EMBED_TEXT_768 및 EMBED_TEXT_1024 함수와 여러 벡터 함수 를 제공하여 다양한 애플리케이션에 대해 비교할 수 있습니다.
텍스트 임베딩 모델¶
Snowflake는 다음과 같은 텍스트 임베딩 모델을 제공합니다. 자세한 내용은 아래 를 참조하십시오.
모델 이름입니다. |
출력 치수 |
컨텍스트 윈도우 |
언어 지원 |
|---|---|---|---|
snowflake-arctic-embed-m-v1.5 |
768 |
512 |
영어 전용 |
snowflake-arctic-embed-m |
768 |
512 |
영어 전용 |
e5-BASE-V2 |
768 |
512 |
영어 전용 |
snowflake-arctic-embed-l-v2.0 |
1024 |
512 |
다국어 |
voyage-multilingual-2 |
1024 |
32000 |
다국어(지원 언어) |
nv-embed-qa-4 |
1024 |
512 |
영어 전용 |
지원되는 모델은 비용 이 다를 수 있습니다.
벡터 유사성 함수 정보¶
벡터 간의 유사성을 측정하는 것은 의미적 비교에서 기본적인 연산입니다. Snowflake Cortex는 VECTOR_INNER_PRODUCT, VECTOR_L1_distance, VECTOR_L2_DISTANCE, VECTOR_COSINE_SIMILARITY 의 네 가지 벡터 비교 함수를 제공합니다. 이러한 함수에 대한 자세한 내용은 벡터 함수 섹션을 참조하십시오.
구문과 사용법에 대한 자세한 내용은 각 함수의 참조 페이지를 참조하십시오.
예¶
다음 예제에서는 벡터 유사성 함수를 사용합니다.
이 SQL 예제는 VECTOR_INNER_PRODUCT 함수를 사용하여 테이블에서 a 열과 b 열 사이에 가장 가까운 벡터를 결정합니다.
CREATE TABLE vectors (a VECTOR(float, 3), b VECTOR(float, 3));
INSERT INTO vectors SELECT [1.1,2.2,3]::VECTOR(FLOAT,3), [1,1,1]::VECTOR(FLOAT,3);
INSERT INTO vectors SELECT [1,2.2,3]::VECTOR(FLOAT,3), [4,6,8]::VECTOR(FLOAT,3);
-- Compute the pairwise inner product between columns a and b
SELECT VECTOR_INNER_PRODUCT(a, b) FROM vectors;
+------+
| 6.3 |
|------|
| 41.2 |
+------+
이 SQL 예제에서는 VECTOR_COSINE_SIMILARITY 함수를 호출하여 [1,2,3] 에 가장 가까운 벡터를 찾습니다.
SELECT a, VECTOR_COSINE_SIMILARITY(a, [1,2,3]::VECTOR(FLOAT, 3)) AS similarity
FROM vectors
ORDER BY similarity DESC
LIMIT 1;
+-------------------------+
| [1, 2.2, 3] | 0.9990... |
+-------------------------+
Snowflake Python Connector¶
이 예제는 Python 커넥터에서 VECTOR 데이터 타입과 벡터 유사도 함수를 사용하는 방법을 보여줍니다.
참고
VECTOR 타입에 대한 지원은 Snowflake Python Connector 버전 3.6에서 도입되었습니다.
import snowflake.connector
conn = ... # Set up connection
cur = conn.cursor()
# Create a table and insert some vectors
cur.execute("CREATE OR REPLACE TABLE vectors (a VECTOR(FLOAT, 3), b VECTOR(FLOAT, 3))")
values = [([1.1, 2.2, 3], [1, 1, 1]), ([1, 2.2, 3], [4, 6, 8])]
for row in values:
cur.execute(f"""
INSERT INTO vectors(a, b)
SELECT {row[0]}::VECTOR(FLOAT,3), {row[1]}::VECTOR(FLOAT,3)
""")
# Compute the pairwise inner product between columns a and b
cur.execute("SELECT VECTOR_INNER_PRODUCT(a, b) FROM vectors")
print(cur.fetchall())
[(6.30...,), (41.2...,)]
# Find the closest vector to [1,2,3]
cur.execute(f"""
SELECT a, VECTOR_COSINE_SIMILARITY(a, {[1,2,3]}::VECTOR(FLOAT, 3))
AS similarity
FROM vectors
ORDER BY similarity DESC
LIMIT 1;
""")
print(cur.fetchall())
[([1.0, 2.2..., 3.0], 0.9990...)]
Snowpark Python¶
이 예제에서는 VECTOR 데이터 타입과 벡터 유사도 함수를 사용하는 방법을 Snowpark Python 라이브러리와 함께 보여줍니다.
참고
VECTOR 유형에 대한 지원은 1.11 버전 Snowpark Python에서 도입되었습니다.
Snowpark Python 라이브러리는 VECTOR_COSINE_SIMILARITY 함수를 지원하지 않습니다.
from snowflake.snowpark import Session, Row
session = ... # Set up session
from snowflake.snowpark.types import VectorType, StructType, StructField
from snowflake.snowpark.functions import col, lit, vector_l2_distance
schema = StructType([StructField("vec", VectorType(int, 3))])
data = [Row([1, 2, 3]), Row([4, 5, 6]), Row([7, 8, 9])]
df = session.create_dataframe(data, schema)
df.select(
"vec",
vector_l2_distance(df.vec, lit([1, 2, 2]).cast(VectorType(int, 3))).as_("dist"),
).sort("dist").limit(1).show()
----------------------
|"VEC" |"DIST" |
----------------------
|[1, 2, 3] |1.0 |
----------------------
텍스트에서 벡터 임베딩 만들기¶
텍스트 조각에서 벡터 임베딩을 생성하려면 모델의 출력 크기에 따라 EMBED_TEXT_768(SNOWFLAKE.CORTEX) 또는 EMBED_TEXT_1024(SNOWFLAKE.CORTEX) 함수를 사용할 수 있습니다. 이 함수는 지정된 영어 텍스트에 대한 벡터 임베딩을 반환합니다. 이 벡터는 벡터 비교 함수 와 함께 사용하여 두 문서의 의미 체계 유사성을 판단할 수 있습니다.
SELECT SNOWFLAKE.CORTEX.EMBED_TEXT_768(model, text)
팁
다른 임베딩 모델은 Snowpark Container Services 를 통해 사용할 수 있습니다. 자세한 내용은 텍스트 컨테이너 서비스 포함 섹션을 참조하십시오.
중요
EMBED_TEXT_768 and EMBED_TEXT_1024는 Cortex LLM 함수이므로 다른 Cortex LLM 함수와 동일한 액세스 제어가 적용됩니다. 이러한 함수에 액세스하는 방법에 대한 지침은 Cortex LLM 함수 필수 권한 섹션을 참조하십시오
예시 사용 사례¶
이 섹션에서는 임베딩, 벡터 유사도 함수, VECTOR 데이터 타입을 사용하여 벡터 유사도 검색 및 검색 증강 생성(RAG)과 같은 자주 사용되는 사용 사례를 구현하는 방법을 보여줍니다.
벡터 유사도 검색¶
의미 체계가 유사한 문서에 대한 검색을 구현하려면 먼저 검색할 문서의 임베딩을 저장합니다. 문서가 추가되거나 편집될 때마다 임베딩을 최신 상태로 유지합니다.
이 예제에서 문서는 지원 담당자가 기록한 콜센터 문제입니다. 문제는 issues 테이블의 issue_text 열에 저장됩니다. 다음 SQL은 문제의 임베딩을 보관할 새 벡터 열을 만듭니다.
ALTER TABLE issues ADD COLUMN issue_vec VECTOR(FLOAT, 768);
UPDATE issues
SET issue_vec = SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m', issue_text);
검색을 수행하려면 검색어 또는 대상 문서의 임베딩을 생성한 다음 벡터 유사성 함수를 사용하여 유사한 임베딩을 가진 문서를 찾습니다. ORDER BY 및 LIMIT 절을 사용하여 상위 k 개의 일치하는 문서를 선택하고, 선택적으로 WHERE 조건을 사용하여 최소 유사성을 지정합니다.
일반적으로, 벡터 유사도 함수에 대한 호출은 WHERE 절이 아닌 SELECT 절에 표시되어야 합니다. 이 방법을 사용하면 함수가 WHERE 절에 지정된 행에 대해서만 호출되므로 테이블의 모든 행에 대해 작동하는 대신 다른 기준에 따라 쿼리가 제한될 수 있습니다. WHERE 절에서 유사성 값을 테스트하려면 SELECT 절에서 VECTOR_COSINE_SIMILARITY 호출에 대한 열 별칭을 정의하고 WHERE 절의 조건에 해당 별칭을 사용합니다.
이 예제는 검색어와의 코사인 유사도가 0.7 이상이라고 가정하여 지난 90일 동안의 검색어와 일치하는 문제를 최대 5개까지 찾아냅니다.
SELECT
issue,
VECTOR_COSINE_SIMILARITY(
issue_vec,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m', 'User could not install Facebook app on his phone')
) AS similarity
FROM issues
ORDER BY similarity DESC
LIMIT 5
WHERE DATEDIFF(day, CURRENT_DATE(), issue_date) < 90 AND similarity > 0.7;
검색 증강 생성(RAG)¶
검색 증강 생성(RAG)에서는 사용자의 쿼리가 벡터 유사도 를 사용하여 유사한 문서를 찾는 데 사용됩니다. 그런 다음 최상위 문서는 사용자의 쿼리와 함께 대규모 언어 모델(LLM)로 전달되어 생성 응답(완성)을 위한 컨텍스트를 제공합니다. 이를 통해 응답의 적합성이 크게 향상될 수 있습니다.
다음 예제에서 wiki 는 텍스트 열 content 가 있는 테이블이고, query 는 텍스트 열 text 가 있는 단일 행 테이블입니다.
-- Create embedding vectors for wiki articles (only do once)
ALTER TABLE wiki ADD COLUMN vec VECTOR(FLOAT, 768);
UPDATE wiki SET vec = SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m', content);
-- Embed incoming query
SET query = 'in which year was Snowflake Computing founded?';
CREATE OR REPLACE TABLE query_table (query_vec VECTOR(FLOAT, 768));
INSERT INTO query_table SELECT SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m', $query);
-- Do a semantic search to find the relevant wiki for the query
WITH result AS (
SELECT
w.content,
$query AS query_text,
VECTOR_COSINE_SIMILARITY(w.vec, q.query_vec) AS similarity
FROM wiki w, query_table q
ORDER BY similarity DESC
LIMIT 1
)
-- Pass to large language model as context
SELECT SNOWFLAKE.CORTEX.COMPLETE('mistral-7b',
CONCAT('Answer this question: ', query_text, ' using this text: ', content)) FROM result;
비용 고려 사항¶
EMBED_TEXT_768 및 EMBED_TEXT_1024 등 Snowflake Cortex LLM 함수는 처리된 토큰 수에 따라 계산 비용이 발생합니다.
참고
토큰은 Snowflake Cortex LLM 함수가 처리하는 가장 작은 텍스트 단위로, 대략 텍스트 4자와 같습니다. 원시 입력 또는 출력 텍스트와 토큰의 동등성은 모델에 따라 다를 수 있습니다.
EMBED_TEXT_768 및 EMBED_TEXT_1024 함수의 경우, 입력 토큰만 청구 가능 총액에 계산됩니다.
벡터 유사도 함수는 토큰 기반 비용이 발생하지 않습니다.
Cortex LLM 함수 청구에 대한 자세한 내용은 Cortex LLM 함수 비용 고려 사항 을 참조하십시오. 컴퓨팅 비용에 대한 일반적인 정보는 컴퓨팅 비용 이해하기 를 참조하십시오.