Unload into Amazon S3¶
Wenn Sie bereits ein Amazon Web Services (AWS)-Konto haben und S3-Buckets zur Speicherung und Verwaltung Ihrer Datendateien verwenden, können Sie beim Entladen von Daten aus Snowflake-Tabellen Ihre vorhandenen Buckets und Ordnerpfade verwenden. Unter diesem Thema wird beschrieben, wie Sie mit dem Befehl COPY Daten aus einer Tabelle in einen Amazon S3-Bucket entladen. Sie können die entladenen Datendateien dann in Ihr lokales Dateisystem herunterladen.
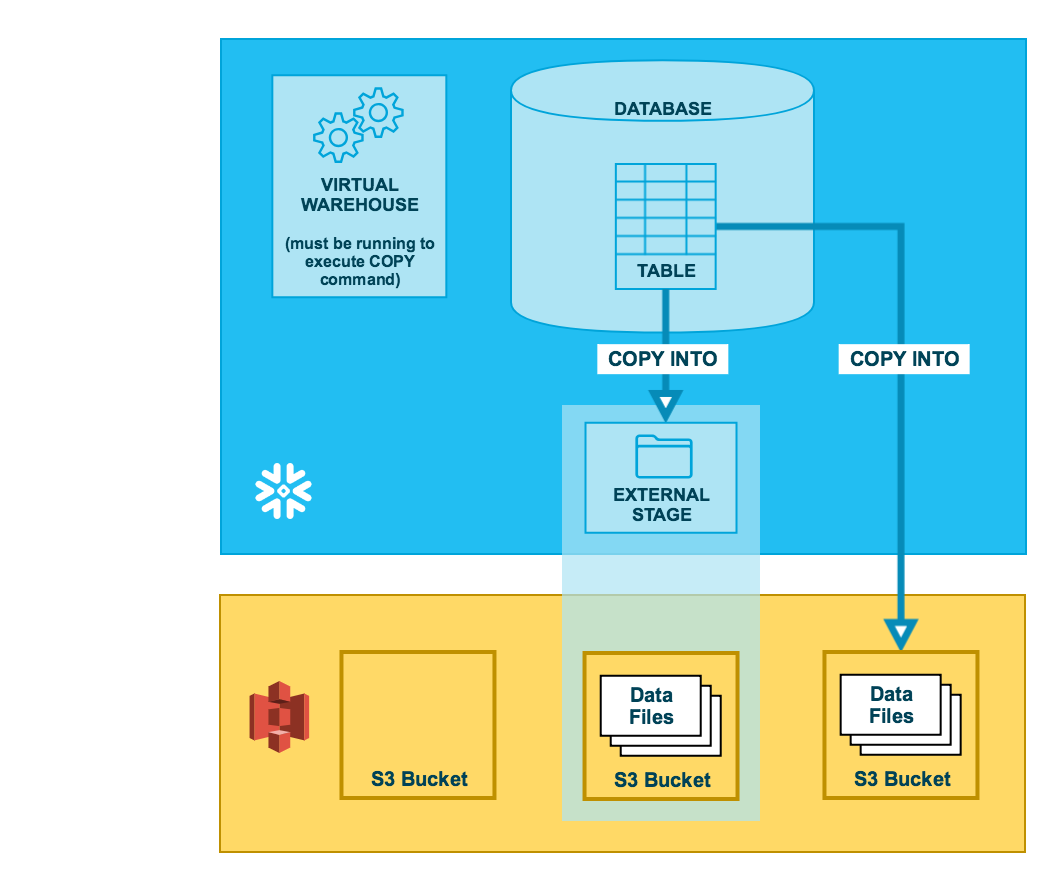
Wie in der folgenden Abbildung dargestellt, erfolgt das Entladen von Daten in einen S3-Bucket in zwei Schritten:
- Schritt 1::
Verwenden Sie den Befehl COPY INTO <Speicherort>, um die Daten aus der Snowflake-Datenbanktabelle in eine oder mehrere Dateien eines S3-Buckets zu kopieren. Geben Sie im Befehl ein benanntes externes Stagingobjekt an, das auf den S3-Bucket verweist (empfohlen), oder wählen Sie aus, dass die Daten direkt in den Bucket entladen werden, indem Sie die URI und entweder die Speicherintegration oder die Sicherheitsanmeldeinformationen (falls erforderlich) für den Bucket angeben.
Unabhängig davon, welche Methode Sie verwenden, erfordert dieser Schritt ein aktives, aktuelles virtuelles Warehouse für die Sitzung, wenn Sie den Befehl manuell oder aus einem Skript heraus ausführen. Das Warehouse stellt die Computeressourcen zur Verfügung, um Zeilen aus der Tabelle zu schreiben.
- Schritt 2::
Verwenden Sie die von Amazon bereitgestellten Schnittstellen/Tools, um die Dateien aus dem S3-Bucket herunterzuladen.
Tipp
Die unter diesem Thema bereitgestellten Anleitungen gehen davon aus, dass Sie File formats to unload data gelesen und ggf. ein benanntes Dateiformat erstellt haben.
Bevor Sie beginnen, sollten Sie vielleicht auch Hinweise zum Entladen von Daten für bewährte Verfahren, Tipps und andere Hinweise lesen.
Allow the Amazon Virtual Private Cloud IDs¶
Wenn ein AWS-Administrator Ihrer Organisation Snowflake nicht explizit Zugriff auf Ihr AWS S3-Speicherkonto gewährt hat, können Sie dies jetzt tun. Führen Sie die Schritte aus, die in der Anleitung zur Konfiguration des Datenladens unter Zulassen von Virtual Private Cloud-IDs beschrieben sind.
Configure an S3 bucket for unloading data¶
In Snowflake sind folgende Berechtigungen für einen S3-Bucket und S3-Ordner erforderlich, um neue Dateien im Ordner (und allen Unterordnern) zu erstellen:
s3:DeleteObjects3:PutObject
Als bewährte Methode empfiehlt Snowflake, ein Speicherintegrationsobjekt zu konfigurieren, um die Authentifizierungsverantwortung für externen Cloudspeicher an eine Snowflake-Entität für Identitäts- und Zugriffsverwaltung (IAM) zu delegieren.
Weitere Informationen zur Konfiguration finden Sie unter Konfigurieren des sicheren Zugriffs auf Amazon S3.
(Optional) Configure support for Amazon S3 access control lists¶
Snowflake-Speicherintegrationen unterstützen AWS-Zugriffssteuerungslisten (ACLs), um dem Bucket-Eigentümer volle Kontrolle zu gewähren. Dateien, die in Amazon S3-Buckets aus entladenen Tabellendaten erstellt werden, sind Eigentum einer AWS-Rolle für Identitäts- und Zugriffsmanagement (IAM). ACLs unterstützen den Anwendungsfall, bei dem IAM-Rollen in einem AWS-Konto für den Zugriff auf S3-Buckets in einem oder mehreren anderen AWS-Konten konfiguriert sind. Ohne ACL-Unterstützung konnten Benutzer in Konten von Bucket-Eigentümern nicht auf die Datendateien zugreifen, die mithilfe einer Speicherintegration in einen externen (S3) Stagingbereich entladen wurden. Wenn Benutzer Snowflake-Tabellendaten in Datendateien in einem externen (S3) Stagingbereich mit COPY INTO <Speicherort> entladen, wendet die Entladeoperation eine ACL auf die entladenen Datendateien an. Die Datendateien wenden die Berechtigung "s3:x-amz-acl":"bucket-owner-full-control" auf die Dateien an und gewähren dem Besitzer des S3-Buckets volle Kontrolle über sie.
Aktivieren Sie die ACL-Unterstützung in der Speicherintegration für einen S3-Stagingbereich über den optionalen Parameter STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control'. Eine Speicherintegration ist ein Snowflake-Objekt, in dem ein für Ihren S3-Cloudspeicher generierter IAM-Benutzer (Identitäts- und Zugriffsverwaltung) zusammen mit einem optionalen Satz zulässiger oder blockierter Speicherorte (d. h. S3-Buckets) gespeichert wird. Ein AWS-Administrator Ihrer Organisation fügt den generierten IAM-Benutzer zu der Rolle hinzu, um Snowflake Berechtigungen für den Zugriff auf bestimmte S3-Buckets zu erteilen. Dank dieser Funktion müssen Benutzer beim Erstellen von Stagingbereichen oder beim Laden von Daten keine Anmeldeinformationen eingeben. Ein Administrator kann den Wert für den Parameter STORAGE_AWS_OBJECT_ACL beim Erstellen einer Speicherintegration (mit CREATE STORAGE INTEGRATION) oder später (mit ALTER STORAGE INTEGRATION) festlegen.
Unload data into an external stage¶
Externe Stagingbereiche sind benannte Datenbankobjekte, die ein Höchstmaß an Flexibilität beim Entladen von Daten bieten. Da es sich um Datenbankobjekte handelt, können Berechtigungen für benannte Stagingbereiche jeder Rolle zugewiesen werden.
Sie können einen externen benannten Stagingbereich entweder über die Snowsight oder mit SQL erstellen:
- Snowsight:
Wählen Sie im Navigationsmenü Catalog » Database Explorer » <db_name> » Stages » Create
- SQL:
Create a named stage¶
Snowflake verwendet beim Hochladen auf Amazon S3 und Google Cloud Storage mehrteilige Uploads. Bei diesem Prozess kann es zu unvollständigen Uploads im Speicherort Ihres externen Stagingbereichs kommen.
Um zu verhindern, dass sich unvollständige Uploads ansammeln, empfehlen wir Ihnen, eine Lebenszyklusregel festzulegen. Eine Anleitung dazu finden Sie in der Dokumentation Amazon S3 oder Google Cloud Storage.
Im folgenden Beispiel wird ein externer Stagingbereich namens my_ext_unload_stage mithilfe eines S3-Buckets namens unload mit einem Ordnerpfad namens files erstellt. Der Stagingbereich greift über eine vorhandene Speicherintegration mit dem Namen s3_int auf den S3-Bucket zu.
Der Stagingbereich verweist auf ein benanntes Dateiformatobjekt mit dem Namen my_csv_unload_format. Anleitungen dazu finden Sie unter File formats to unload data.
CREATE OR REPLACE STAGE my_ext_unload_stage URL='s3://unload/files/'
STORAGE_INTEGRATION = s3_int
FILE_FORMAT = my_csv_unload_format;
Unload data to the named stage¶
Verwenden Sie den Befehl COPY INTO <Speicherort>, um Daten aus einer Tabelle über einen externen Stagingbereich in einen S3-Bucket zu entladen.
Im folgenden Beispiel wird der Stagingbereich
my_ext_unload_stageverwendet, um alle Zeilen der Tabellemytablein eine oder mehrere Dateien des S3-Buckets zu entladen. Alle Dateien erhalten das Dateinamen-Präfixd1:COPY INTO @my_ext_unload_stage/d1 from mytable;
Verwenden Sie die S3-Konsole (oder eine ähnliche Clientanwendung), um die Objekte (d. h. die durch den Befehl generierten Dateien) aus dem Bucket abzurufen.
Unload data directly into an S3 bucket¶
Verwenden Sie den Befehl COPY INTO <Speicherort>, um Daten aus einer Tabelle direkt in einen angegebenen S3-Bucket zu entladen. Diese Option eignet sich gut für die Ad-hoc-Entladung, wenn Sie keine regelmäßige Datenentladung mit den gleichen Tabellen- und Bucketparametern planen.
Sie müssen im Befehl COPY den URI für den S3-Bucket und die Speicherintegration oder Anmeldeinformationen für den Zugriff auf den Bucket angeben.
Im folgenden Beispiel werden alle Zeilen der Tabelle
mytablein eine oder mehrere Dateien des S3-Bucketsmybucketmit dem Ordnerpfadpräfixunload/entladen:COPY INTO 's3://mybucket/unload/' FROM mytable STORAGE_INTEGRATION = s3_int;
Bemerkung
In diesem Beispiel wird mithilfe einer referenzierten Speicherintegration namens
s3_intauf den referenzierten S3-Bucket zugegriffen.Verwenden Sie die S3-Konsole (oder eine ähnliche Clientanwendung), um die Objekte (d. h. die durch den Befehl generierten Dateien) aus dem Bucket abzurufen.