Hinweise zur Datenbankreplikation¶
Wichtig
In diesem Abschnitt wird ein beschränktes Feature zur Datenbankreplikation beschrieben, das sich vom Feature Kontoreplikation unterscheidet. Snowflake empfiehlt dringend die Verwendung des Features Kontoreplikation für die Replikation und das Failover von Datenbanken.
Unter diesem Thema wird das Verhalten bestimmter Snowflake-Features in Sekundärdatenbanken bei Verwendung der Datenbankreplikation erläutert. Weitere Hinweise zur Verwendung replizierter Objekte und Daten finden Sie unter Hinweise zur Replikation.
Datenbankreplikation und Sicherheitsobjekte¶
In diesem Abschnitt wird das Verhalten der Datenbankreplikation von Sicherheitsrichtlinien und Geheimnissen beschrieben.
- Richtlinien für Maskierung und Zeilenzugriff:
Die Replikationsoperation schlägt fehl, wenn eine der folgenden Bedingungen erfüllt ist:
Die Primärdatenbank befindet sich in einem Enterprise-Konto (oder höher) und enthält eine Richtlinie bzw. ein Tag, aber mindestens eines der zur Replikation genehmigten Konten weist eine niedrigere Edition auf.
Ein in der Primärdatenbank enthaltenes Objekt hat eine verwaiste Referenz auf ein Tag in einer anderen Datenbank.
Das Verhalten von verwaisten Referenzen bei der Datenbankreplikation kann umgangen werden, wenn mehrere Datenbanken in einer Replikations- oder Failover-Gruppen repliziert werden.
- Tag-basierte Maskierungsrichtlinien:
Die Replikationsoperation schlägt fehl, wenn eine der folgenden Bedingungen erfüllt ist:
Die Primärdatenbank befindet sich in einem Enterprise-Konto (oder höher) und enthält eine Richtlinie bzw. ein Tag, aber mindestens eines der zur Replikation genehmigten Konten weist eine niedrigere Edition auf.
Ein in der Primärdatenbank enthaltenes Objekt hat eine verwaiste Referenz auf ein Tag in einer anderen Datenbank.
Weitere Informationen zu Tag-basierten Maskierungsrichtlinien finden Sie unter Tag-basierte Maskierungsrichtlinien.
- Kennwort-, Sitzungs- und Authentifizierungsrichtlinien:
Die Replikationsoperation schlägt fehl, wenn eine der folgenden Bedingungen erfüllt ist:
Die Primärdatenbank befindet sich in einem Enterprise-Konto (oder höher) und enthält eine Richtlinie, aber mindestens eines der zur Replikation genehmigten Konten befindet sich in einer niedrigeren Edition.
Jedes dieser in der Primärdatenbank enthaltenen Objekte ist mit einem Benutzer desselben Kontos verbunden. In diesem Fall sorgt Snowflake für das Fehlschlagen der Replikationsoperation.
Um das Fehlschlagen einer Datenbankreplikationsoperation aufgrund eines Verweises auf einen Benutzer zu vermeiden, verwenden Sie stattdessen eine Replikations- oder Failover-Gruppe.
Weitere Informationen dazu finden Sie unter Replikation und Sicherheitsrichtlinien.
- Geheimnisse:
Sie können ein Geheimnis nicht über die Datenbankreplikation replizieren. Verwenden Sie eine Replikations- oder Failover-Gruppe, um ein Geheimnis zu replizieren. Weitere Details dazu finden Sie unter Replikation und Geheimnisse.
Verwaiste Referenzen¶
Verweise auf Objekte in einer anderen Datenbank¶
Analysieren Sie sorgfältig, ob Ansichten oder Tabelleneinschränkungen einer Primärdatenbank auf Objekte einer anderen Datenbank verweisen. Für Datenbankobjekte können Sie Objektabhängigkeiten in der Account Usage-Ansicht OBJECT_DEPENDENCIES anzeigen.
In der folgenden Tabelle wird das Verhalten der Datenbankreplikation beschrieben, wenn ein Objekt (das referenzierende Objekt) in einer Datenbank auf ein Objekt in einer anderen Datenbank (das referenzierte Objekt) verweist:
Referenzierendes Objekt |
Referenziertes Objekt |
Replikationsverhalten |
|---|---|---|
Objekt |
Erfolgreich |
|
Objekt |
Fehler |
|
Materialisierte Ansicht |
Fehler |
|
Primärschlüssel |
Fehler |
|
Tabelle |
Fehler |
|
Richtlinie/Tag wird Objekt zugewiesen |
Fehler |
|
Objekt |
Fehler |
Nicht materialisierte Ansichten¶
Nicht materialisierte Ansichten, die auf ein Objekt in einer anderen Datenbank verweisen (z. B. Tabellenspalten, andere Ansichten, UDFs oder Stagingbereiche), können repliziert werden, da diese Art von Referenz auf Namen basiert. Namensbasierte Verweise führen nicht zum Fehlschlagen der Replikation. Abfragen auf Ansichten sekundärer Datenbanken schlagen jedoch fehl, wenn die anderen Datenbanken nicht in derselben Region repliziert werden.
Angenommen, die Ansicht v1 in der Datenbank d1 verweist auf die Tabellen t1 und t2 in den Datenbanken d1 bzw. d2. Um die Ansicht v1 der Sekundärdatenbank d1 erfolgreich abzufragen, muss auch die Sekundärdatenbank d2 im Konto vorhanden sein (z. B. als eine weitere Sekundärdatenbank). Außerdem müssen für konsistente Abfrageergebnisse auf den Primärdatenbanken die Sekundärdatenbanken d1 und d2 gleichzeitig aktualisiert werden.
Materialisierte Ansichten¶
Verwaiste Referenzen in materialisierten Ansichten können dazu führen, dass die Replikation mit der folgenden Fehlermeldung fehlschlägt:
Diese verwaisten Referenzen können in folgenden Fällen auftreten:
Eine materialisierte Ansicht verweist auf ein beliebiges Objekt in einer anderen Datenbank.
Materialisierte Ansichten verweisen auf Objekte mittels ID und nicht mittels Namen. Ein Datenbank-Snapshot kann keine ID-basierten Verweise auf Objekte außerhalb der Datenbank auflösen.
Um diese Einschränkung zu umgehen, replizieren Sie beide Datenbanken zusammen in der gleichen Replikations- oder Failover-Gruppe. Alternativ dazu können Sie materialisierte Ansichten und die Objekte, auf die sie verweisen, in derselben Datenbank speichern.
Eine materialisierte Ansicht ist ungültig (d. h. sie verweist auf ein gelöschtes Objekt).
Um einen durch eine verwaiste Referenz verursachten Fehler für ungültige materialisierte Ansichten zu vermeiden, identifizieren und beheben Sie das Problem mit der materialisierten Ansicht. Weitere Informationen dazu finden Sie im Abschnitt Problembehandlung des Themas „Materialisierte Ansichten“.
Einschränkungen¶
Derzeit führen verwaiste Fremdschlüssel zum Fehlschlagen der Replikation mit folgender Fehlermeldung:
Diese Situation tritt auf, wenn ein Fremdschlüssel in der Primärdatenbank auf einen Primärschlüssel in einer anderen Datenbank verweist oder umgekehrt. Dies liegt daran, dass Verweise auf Nebenbedingungen ID-basiert sind. Ein Datenbank-Snapshot kann keine ID-basierten Verweise auf Objekte außerhalb der Datenbank auflösen.
Um die Fremdschlüsselreferenzen in Ihrem Konto anzuzeigen, fragen Sie die Information Schema-Ansicht TABLE_CONSTRAINTS oder die Account Usage-Ansicht TABLE_CONSTRAINTS ab.
Um diese Einschränkung zu umgehen, replizieren Sie beide Datenbanken zusammen in der gleichen Replikations- oder Failover-Gruppe. Alternativ dazu können Sie verknüpfte Tabellen in derselben Datenbank speichern.
Sequenzen¶
Derzeit führen verwaiste Sequenzen zum Fehlschlagen der Replikation mit folgender Fehlermeldung:
Diese Situation tritt auf, wenn eine Tabelle in einer Primärdatenbank auf eine Sequenz in einer anderen Datenbank verweist. Das liegt daran, dass die Sequenzreferenzen auf ID basieren. Ein Datenbank-Snapshot kann keine ID-basierten Verweise auf Objekte außerhalb der Datenbank auflösen.
Um diese Einschränkung zu umgehen, replizieren Sie beide Datenbanken zusammen in der gleichen Replikations- oder Failover-Gruppe. Alternativ können Sie auch auf Sequenzen in derselben Datenbank verweisen.
Referenzen auf gelöschte Objekte¶
Das Löschen eines Objekts, das von einem anderen Objekt in derselben oder einer anderen Datenbank referenziert wird, führt zu einer verwaisten Referenz. Wenn ein Objekt in der Primärdatenbank auf ein gelöschtes Objekt verweist, schlägt ein Replikationsvorgang mit folgender Fehlermeldung fehl:
Um diese Einschränkung zu umgehen, empfehlen wir Ihnen, eine der folgenden Aktionen auszuführen:
Löschen Sie alle referenzierten Objekte.
Modifizieren Sie die verweisenden Objekte (z. B. modifizieren Sie eine materialisierte Ansicht mit ALTER MATERIALIZED VIEW). Verweisen Sie entweder auf ein anderes Objekt, oder entfernen Sie den Verweis auf das gelöschte Objekt.
Löschen Sie alle Objekte in der primären Datenbank, die auf gelöschte Objekte verweisen.
Replikation von mehreren Datenbanken¶
Wenn mehrere Datenbanken repliziert werden, ist eine zeitliche Konsistenz zwischen den Datenbanken nicht verfügbar. Von jeder primären Datenbank wird unabhängig ein Snapshot erstellt, und Änderungen an der sekundären Datenbank werden unabhängig voneinander übertragen. Dies kann problematisch sein, wenn Sie Ansichten haben, die Tabellen in verschiedenen Datenbanken verknüpfen oder die von datenbankübergreifenden Transaktionen abhängen. So wird beispielsweise eine Transaktion, die zwei Primärdatenbanken atomar aktualisiert, möglicherweise nicht gleichzeitig in den Sekundärdatenbanken wiedergegeben.
Um mehrere Datenbanken mit zeitlicher Konsistenz zu replizieren, verwenden Sie eine Replikations- oder Failover-Gruppe.
Dynamische Tabellen und Datenreplikation¶
Wenn eine dynamische Tabelle Quellobjekte außerhalb der Datenbankreplikation referenziert, kann sie dennoch repliziert werden. Die Namensauflösung kann jedoch komplex werden, wenn die sekundäre Datenbank einen anderen Namen hat als die primäre. Nach einem Failover kann dies zu unerwarteten Aktualisierungsergebnissen führen, je nachdem, wie das Quellobjekt referenziert wird. Um dies zu verhindern, vermeiden Sie die Umbenennung der Datenbank während der Einrichtung der Replikation oder verwenden Sie stattdessen die Failover-Gruppenreplikation.
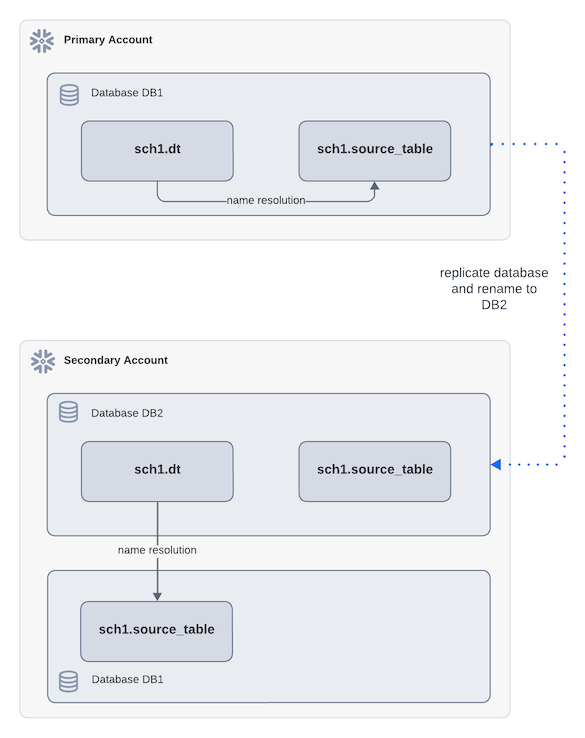
Im folgenden Diagramm referenziert die dynamische Tabelle dt ein Quellobjekt source_table unter Verwendung eines vollständig qualifizierten Namens. Beispiel:
Während der Replikation wird DB1 im sekundären Konto in DB2 umbenannt. Nach dem Failover wird bei der Aktualisierung der dynamischen Tabelle dt in DB2 im sekundären Konto die Quelltabelle in derselben Datenbank aufgelöst, nicht in der ursprünglichen primären Datenbank. Dies entspricht zwar den Regeln für die Namensauflösung, kann aber zu unerwarteten Ergebnissen führen.
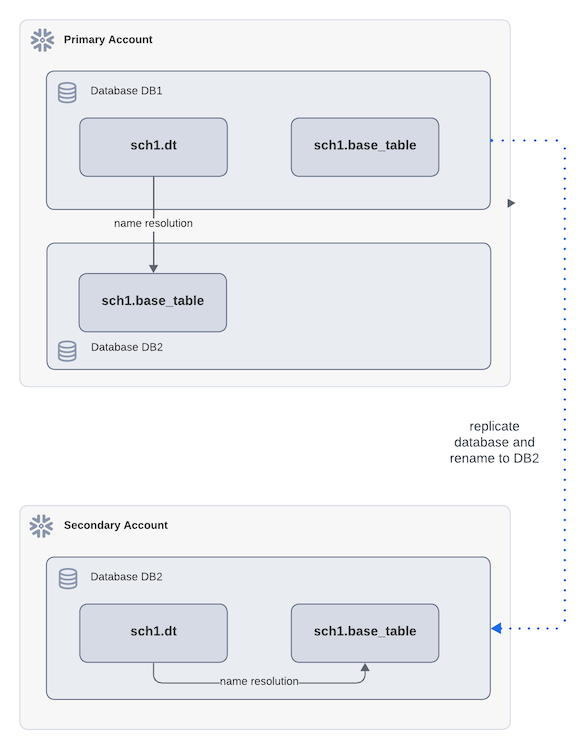
Im folgenden Diagramm verweist dt mit einem vollständig qualifizierten Namen auf source_table, und die Replikation benennt DB1 im sekundären Konto in DB2 um. dt im sekundären Konto verweist nun auf eine Quelltabelle, die sich außerhalb der enthaltenden Datenbank befindet.