Hinweise zur Replikation¶
Unter diesem Thema wird das Verhalten bestimmter Snowflake-Features in Sekundärdatenbanken und Objekten beim Replizieren mit Replikations- oder Failover-Gruppen oder bei der Datenbankreplikation beschrieben, und es werden allgemeine Hinweise zur Verwendung replizierter Objekte und Daten bereitgestellt.
Wenn Sie zuvor die Datenbankreplikation für einzelne Datenbanken mit dem Befehl ALTER DATABASE … ENABLE REPLICATION TO ACCOUNTS aktiviert haben, finden Sie unter Hinweise zur Datenbankreplikation zusätzliche Hinweise speziell zur Datenbankreplikation.
Einschränkungen für Replikationsgruppen und Failover-Gruppen¶
In den folgenden Abschnitten werden die Einschränkungen beim Hinzufügen von Kontoobjekten, Datenbanken und Freigaben zu Replikations- und Failover-Gruppen erläutert.
Kontoobjekte¶
Ein Konto kann nur genau eine Replikations- oder Failover-Gruppe haben, die neben Datenbanken und Freigaben auch andere Kontoobjekte enthält.
Replikationsberechtigungen¶
In diesem Abschnitt werden die Replikationsberechtigungen beschrieben, die Rollen erteilt werden können, um die Operationen festzulegen, die Benutzer auf Replikations- und Failover-Gruppenobjekten im System ausführen können. Die vollständige Syntax des GRANT-Befehls finden Sie unter GRANT <Berechtigungen> … TO ROLE.
Bemerkung
Bei der Datenbankreplikation kann nur ein Benutzer mit der Rolle ACCOUNTADMIN Datenbankreplikation und Failover aktivieren und verwalten. Weitere Informationen zu den erforderlichen Berechtigungen für die Datenbankreplikation finden Sie in der Tabelle mit den erforderlichen Berechtigungen unter Schritt 6: Aktualisieren einer Sekundärdatenbank nach einem Zeitplan.
Berechtigung |
Objekt |
Verwendung |
Anmerkungen |
|---|---|---|---|
OWNERSHIP |
Replikationsgruppe Failover-Gruppe |
Ermöglicht das Löschen und Ändern eines Objekts sowie das Zuweisen und Entziehen des Zugriffs auf das Objekt. |
Kann durch folgende Rollen erteilt werden:
|
CREATE REPLICATION GROUP |
Konto |
Ermöglich das Erstellen von Replikationsgruppen. |
Muss von der Rolle ACCOUNTADMIN gewährt werden. |
CREATE FAILOVER GROUP |
Konto |
Ermöglicht das Erstellen von Failover-Gruppen. |
Muss von der Rolle ACCOUNTADMIN gewährt werden. |
FAILOVER |
Failover-Gruppe |
Ermöglicht das Heraufstufen einer sekundären Failover-Gruppe zur primären Failover-Gruppe. |
Kann von einer Rolle mit OWNERSHIP-Berechtigung für die Gruppe zugewiesen oder entzogen werden. |
REPLICATE |
Replikationsgruppe Failover-Gruppe |
Ermöglicht das Aktualisieren einer sekundären Gruppe. |
Kann von einer Rolle mit OWNERSHIP-Berechtigung für die Gruppe zugewiesen oder entzogen werden. |
MODIFY |
Replikationsgruppe Failover-Gruppe |
Ermöglicht das Ändern der Einstellungen oder Eigenschaften eines Objekts. |
Kann von einer Rolle mit OWNERSHIP-Berechtigung für die Gruppe zugewiesen oder entzogen werden. |
MONITOR |
Replikationsgruppe Failover-Gruppe |
Ermöglicht das Anzeigen von Details zu einem Objekt. |
Kann von einer Rolle mit OWNERSHIP-Berechtigung für die Gruppe zugewiesen oder entzogen werden. |
Eine Anleitung zum Erstellen einer kundenspezifischen Rolle mit einer bestimmten Gruppe von Berechtigungen finden Sie unter Erstellen von kundenspezifischen Rollen.
Allgemeine Informationen zu Rollen und Berechtigungen zur Durchführung von SQL-Aktionen auf sicherungsfähigen Objekten finden Sie unter Übersicht zur Zugriffssteuerung.
Replikation und Referenzen über Replikationsgruppen hinweg¶
Objekte in einer Replikationsgruppe (oder Failover-Gruppe), die verwaiste Referenzen (d. h. Referenzen auf Objekte in einer anderen Replikations- oder Failover-Gruppe) haben, können unter Umständen erfolgreich in ein Zielkonto repliziert werden. Wenn die Replikationsoperation zu einem Verhalten im Zielkonto führt, das mit dem Verhalten übereinstimmt, das im Quellkonto auftreten kann, ist die Replikation erfolgreich.
Wenn beispielsweise eine Spalte in einer Tabelle der Failover-Gruppe fg_a auf eine Sequenz in der Failover-Gruppe fg_b verweist, ist die Replikation für beide Gruppen erfolgreich. Wenn fg_a vor fg_b repliziert wird, werden (nach dem Failover) Einfügeoperationen in die Tabelle, die auf die Sequenz verweist, fehlschlagen, falls fg_b noch nicht repliziert wurde. Dieses Verhalten kann bei einem Quellkonto auftreten. Wenn eine Sequenz in einem Quellkonto gelöscht wird, werden Einfügeoperationen in einer Tabelle mit einer Spalte, die auf die gelöschte Sequenz verweist, fehlschlagen.
Wenn es sich bei der verwaisten Referenz um eine Sicherheitsrichtlinie handelt, die Daten schützt, muss die Replikationsgruppe (oder Failover-Gruppe) mit der Sicherheitsrichtlinie vor jeder Replikationsgruppe repliziert werden, die Objekte enthält, die auf die Richtlinie verweisen.
Achtung
Aktualisierungen von Sicherheitsrichtlinien, die Daten in separaten Replikations- oder Failover-Gruppen schützen, können zu Inkonsistenzen führen und sollten daher mit Vorsicht ausgeführt werden.
Für Datenbankobjekte können Sie Objektabhängigkeiten in der Account Usage-Ansicht OBJECT_DEPENDENCIES anzeigen.
Verwaiste Referenzen und Netzwerkrichtlinien¶
Verwaiste Referenzen in Netzwerkrichtlinien können dazu führen, dass die Replikation mit der folgenden Fehlermeldung fehlschlägt:
Um verwaiste Referenzen zu vermeiden, geben Sie beim Ausführen des CREATE- oder ALTER-Befehls für die Replikations- oder Failover-Gruppe die folgenden Objekttypen in der Liste OBJECT_TYPES an:
Wenn eine Netzwerkrichtlinie eine Netzwerkregel verwendet, geben Sie die Datenbank an, die das Schema enthält, in dem die Netzwerkregel erstellt wurde.
Wenn dem Konto eine Netzwerkrichtlinie zugeordnet ist, nehmen Sie
NETWORK POLICIESundACCOUNT PARAMETERSin die ListeOBJECT_TYPESauf.Wenn eine Netzwerkrichtlinie einem Benutzer zugeordnet ist, fügen Sie
NETWORK POLICIESundUSERSin die ListeOBJECT_TYPESein.
Weitere Details dazu finden Sie unter Replizieren von Netzwerkrichtlinien.
Verwaiste Referenzen und Paketrichtlinien¶
Wenn für das Konto eine Paketrichtlinie festgelegt ist, tritt während der Aktualisierungsoperation für eine Replikations- oder Failover-Gruppe, die Kontoobjekte enthält, der folgende Fehler aufgrund verwaister Referenzen auf:
Um verwaiste Referenzen zu vermeiden, replizieren Sie die Datenbank, die die Paketrichtlinie enthält, in das Zielkonto. Die Datenbank, die die Richtlinie enthält, kann sich in der gleichen oder einer anderen Replikations- oder Failover-Gruppe befinden.
Verwaiste Referenzen und Geheimnisse¶
Weitere Details dazu finden Sie unter Replikation und Geheimnisse.
Verwaiste Referenzen und Streams¶
Verwaiste Referenzen für Streams können dazu führen, dass die Replikation mit der folgenden Fehlermeldung fehlschlägt:
So vermeiden Sie Fehler durch verwaiste Referenzen:
Die Primärdatenbank muss sowohl den Stream als auch dessen Basisobjekt enthalten oder
Die Datenbank, die den Stream enthält, und die Datenbank, die das vom Stream referenzierte Basisobjekt enthält, müssen in derselben Replikations- oder Failover-Gruppe enthalten sein.
Replikation und schreibgeschützte Sekundärobjekte¶
Alle Sekundärobjekte in einem Zielkonto, einschließlich sekundäre Datenbanken und Freigaben, sind schreibgeschützt. Änderungen an replizierten Objekten oder Objekttypen können nicht lokal in einem Zielkonto vorgenommen werden. Wenn beispielsweise der Objekttyp USERS von einem Quellkonto in ein Zielkonto repliziert wird, können im Zielkonto keine neuen Benutzer erstellt oder geändert werden.
Neue, lokale Datenbanken und Freigaben können aber in einem Zielkonto erstellt und geändert werden. Wenn auch ROLES in das Zielkonto repliziert werden, können in diesem Zielkonto keine neuen Rollen erstellt oder geändert werden. Daher können einer Rolle keine Berechtigungen für ein sekundäres Objekt im Zielkonto erteilt (oder entzogen) werden. Allerdings können einer Sekundärrolle Berechtigungen für lokale Objekte (z. B. Datenbanken, Freigaben oder Replikations- oder Failover-Gruppen), die im Zielkonto erstellt wurden, erteilt (oder entzogen) werden.
Replikation und Objekte in Zielkonten¶
Wenn Sie Kontoobjekte wie Benutzer und Rollen in Ihrem Zielkonto auf andere Weise als durch Replikation (z. B. mithilfe von Skripten) erstellen, haben diese Benutzer und Rollen standardmäßig keine globale ID. Wenn ein Zielkonto vom Quellkonto aus aktualisiert wird, führt die Aktualisierungsoperation zum Löschen aller Kontoobjekte der Typen in der OBJECT_TYPES-Liste des Zielkontos, die keine globale ID haben.
Bemerkung
Die erste Aktualisierungsoperation zum Replizieren von USERS oder ROLES kann zu einem Fehler führen. Dies soll verhindern, dass Daten und Metadaten, die Benutzern und Rollen zugeordnet sind, versehentlich gelöscht werden. Weitere Informationen zu den Umständen, die bestimmen, ob diese Objekttypen gelöscht werden oder die Aktualisierungsoperation fehlschlägt, finden Sie unter Erstmalige Replikation von Benutzern und Rollen.
Informationen dazu, wie Sie das Löschen dieser Objekte verhindern können, finden Sie unter Globale IDs auf Objekte anwenden, die von Skripten in Zielkonten erstellt wurden.
In Zielkonten neu erstellt Objekte¶
Wenn ein bestehendes Objekt im Quellkonto mit einer CREATE OR REPLACE-Anweisung ersetzt wird, wird in einer einzigen Transaktion das bestehende Objekt gelöscht und anschließend ein neues Objekt mit demselben Namen erstellt. Wenn Sie beispielsweise eine CREATE OR REPLACE-Anweisung für eine bestehende Tabelle t1 ausführen, wird die Tabelle t1 gelöscht und anschließend eine neue Tabelle t1 erstellt. Weitere Informationen dazu finden Sie in den Nutzungshinweisen für CREATE TABLE.
Wenn Objekte im Zielkonto ersetzt werden, werden die Anweisungen DROP und CREATE während einer Aktualisierungsoperation nicht atomar ausgeführt. Das bedeutet, dass das Objekt möglicherweise kurzzeitig aus dem Zielkonto verschwindet, während es als neues Objekt neu erstellt wird.
Replikation und Sicherheitsrichtlinien¶
Die Datenbank, die eine Sicherheitsrichtlinie und die Referenzen (d. h. Zuweisungen) enthält, kann mithilfe von Replikations- und Failover-Gruppen repliziert werden. Sicherheitsrichtlinien umfassen:
Sitzungsrichtlinien, einschließlich Sitzungsrichtlinien mit Sekundärrollen
Wenn Sie die Datenbankreplikation verwenden, finden Sie weitere Informationen unter Datenbankreplikation und Sicherheitsobjekte.
Authentifizierungs-, Kennwort- und Sitzungsrichtlinien¶
Referenzen von Authentifizierungs-, Kennwort- und Sitzungsrichtlinien für Benutzer werden repliziert, wenn in einer Replikations- oder Failover-Gruppe die Datenbank, die die Richtlinie enthält (ALLOWED_DATABASES = policy_db), und USERS angegeben werden.
Wenn entweder die Richtliniendatenbank oder die Benutzer bereits in ein Zielkonto repliziert wurden, aktualisieren Sie die Replikations- oder Failover-Gruppe im Quellkonto, um die Datenbanken und Objekttypen aufzunehmen, die für eine erfolgreiche Replikation der Richtlinie erforderlich sind. Führen Sie dann eine Aktualisierungsoperation aus, um das Zielkonto zu aktualisieren.
Wenn auf Benutzerebene keine Richtlinien verwendet werden, muss USERS nicht in die Replikations- oder Failover-Gruppe aufgenommen werden.
Bemerkung
Die Richtlinie muss sich in demselben Konto befinden wie die Richtlinienzuweisung auf Kontoebene und die Richtlinienzuweisung auf Benutzerebene.
Wenn Sie einen Satz von Sicherheitsrichtlinie für das Konto oder für einen Benutzer im Konto festgelegt haben und Sie die Replikations- oder Failover-Gruppe nicht aktualisieren, sodass die Datenbank policy_db, die die Richtlinie und USERS enthält, hinzugefügt wird, tritt im Zielkonto eine verwaiste Referenz auf. In diesem Fall bedeutet eine verwaiste Referenz, dass Snowflake die Richtlinie im Zielkonto nicht finden kann, weil der vollqualifizierte Name der Richtlinie auf die Datenbank im Quellkonto verweist. Folglich müssen das Zielkonto oder die Benutzer des Zielkontos die Sitzungsrichtlinie oder die Kennwortrichtlinie nicht einhalten.
Um eine Sicherheitsrichtlinie erfolgreich zu replizieren, prüfen Sie also vorher, ob die Replikations- oder Failover-Gruppe auch tatsächlich die Objekttypen und Datenbanken enthält, die erforderlich sind, um eine verwaiste Referenz zu verhindern.
Datenschutzrichtlinien¶
Beachten Sie bei der Replikation von Datenschutzrichtlinien sowie datenschutzgeschützten Tabellen und Ansichten, die mit Differential Privacy (differentieller Privatsphäre) verbunden sind, die folgenden Punkte:
Wenn einer Tabelle oder Ansicht im Quellkonto eine Datenschutzrichtlinie zugewiesen ist, muss diese Richtlinie im Zielkonto repliziert werden.
Der kumulative Datenschutzverlust für ein Datenschutzbudget wird nicht repliziert.
Der kumulative Datenschutzverlust in den Ziel- und Quellkonten wird separat verfolgt.
Administratoren im Zielkonto können das replizierte Datenschutzbudget nicht anpassen. Das Datenschutzbudget wird mit dem des Quellkontos synchronisiert.
Wenn ein Analyst sowohl im Quell- als auch im Zielkonto Zugriff auf die datenschutzgeschützte Tabelle oder Ansicht hat, kann er die doppelte Menge an Datenschutzverlust erleiden, bevor er die Beschränkung des Datenschutzbudgets erreicht.
Die für die Spalten eingestellten Datenschutzbereiche werden ebenfalls repliziert.
Sitzungsrichtlinien mit Sekundärrollen¶
Wenn Sie Sitzungsrichtlinien mit Sekundärrollen verwenden, müssen Sie die Richtliniendatenbank in derselben Replikationsgruppe angeben, die auch die Rollen enthält. Beispiel:
Wenn Sie die Sitzungsrichtliniendatenbank, die auf Sekundärrollen verweist, in einer anderen Replikations- oder Failover-Gruppe (rg2) als der Replikations- oder Failover-Gruppe angeben, die Objekte auf Kontoebene (myrg) enthält, und Sie zuerst eine Replikation oder einen Failover von rg2 durchführen, tritt eine Verwaiste Referenz auf. Eine Fehlermeldung weist Sie darauf hin, dass Sie die Sitzungsrichtliniendatenbank in der Replikations- oder Failover-Gruppe platzieren müssen, die die Rollen enthält. Diese Verhaltensweise tritt auf, wenn die Sitzungsrichtlinie für das Konto oder die Benutzer eingestellt ist.
Wenn sich die Sitzungsrichtlinie und die Objekte auf Kontoebene in verschiedenen Replikationsgruppen befinden und die Sitzungsrichtlinie nicht auf das Konto oder die Benutzer eingestellt ist, können Sie das Zielkonto replizieren und aktualisieren. Achten Sie darauf, dass Sie zuerst die Replikationsgruppe aktualisieren, die die Objekte auf Kontoebene enthält.
Wenn Sie das Zielkonto nach einer Replikation oder einem Failover der Sitzungsrichtlinie mit Sekundärrollen und Rollenobjekten aktualisieren, spiegelt das Zielkonto die Verhaltensweise der Sitzungsrichtlinie und der Sekundärrollen im Quellkonto wider.
Wenn Sie außerdem die Datenbank im Zielkonto aktualisieren und die Datenbank eine Sitzungsrichtlinie enthält, die auf Sekundärrollen verweist, ergibt ALLOWED_SECONDARY_ROLES immer [ALL].
Replikation und Geheimnisse¶
Sie können das Geheimnis nur mithilfe einer Replikations- oder Failover-Gruppe replizieren. Geben Sie in einer einzigen Replikations- oder Failover-Gruppe die Datenbank an, die das Geheimnis enthält, die Datenbank, die die UDFs oder Prozeduren enthält, die auf das Geheimnis verweisen, sowie die Integrationen, die auf das Geheimnis verweisen.
Wenn sich die Datenbank, die das Geheimnis enthält, in einer Replikations- oder Failover-Gruppe befindet, und die Integration, die auf das Geheimnis verweist, in einer anderen Replikations- oder Failover-Gruppe, passiert Folgendes:
Wenn Sie zuerst die Integration und dann das Geheimnis replizieren, ist die Operation erfolgreich: Alle Objekte werden repliziert, und es gibt keine verwaisten Referenzen.
Wenn Sie das Geheimnis vor der Integration replizieren und das Geheimnis nicht bereits im Zielkonto vorhanden ist, wird im Zielkonto ein „Platzhaltergeheimnis“ hinzugefügt, um eine verwaiste Referenz zu verhindern. Snowflake ordnet das Platzhaltergeheimnis der Integration zu.
Nachdem Sie die Gruppe, die die Integration enthält, repliziert haben, aktualisiert Snowflake bei der nächsten Aktualisierungsoperation auf der Gruppe, die das Geheimnis enthält, das Zielkonto, um das Platzhaltergeheimnis durch das Geheimnis zu ersetzen, auf das in der Integration verwiesen wird.
Wenn Sie das Geheimnis replizieren, aber die Integration nicht von
account1nachaccount2replizieren, funktioniert die Integration im Zielkonto (account2) nicht, da es keine Integration zur Verwendung des Geheimnisses gibt. Wenn Sie ein Failover ausführen und das Zielkonto zum Quellkonto heraufgestuft wird, funktioniert die Integration nicht.Wenn Sie entscheiden, ein Failover auszuführen, um
account1zum Quellkonto zu machen, stimmen Geheimnis und Integrationsreferenzen überein und das Platzhaltergeheimnis wird nicht verwendet. Auf diese Weise können Sie die Sicherheitsintegration und das Geheimnis, das die Anmeldeinformationen enthält, verwenden, da die Objekte gegenseitig aufeinander verweisen können.
Replikation und Klonen¶
In der Vergangenheit geklonte Objekte wurden physisch und nicht logisch auf sekundäre Datenbanken repliziert. Das heißt, geklonte Tabellen in einer Standarddatenbank tragen nicht zum gesamten Datenspeicher bei, es sei denn, DML-Operationen auf dem Klon ergänzen oder verändern die vorhandenen Daten. Wenn jedoch eine geklonte Tabelle in eine sekundäre Datenbank repliziert wird, werden auch die physischen Daten repliziert, wodurch sich die Datenspeichernutzung für Ihr Konto erhöht.
Eine logisch replizierte geklonte Tabelle teilt sich die Mikropartitionen der Originaltabelle, von der sie geklont wurde, wodurch der physische Speicherplatz der sekundären Tabelle im Zielkonto reduziert wird.
Wenn die Originaltabelle und die geklonte Tabelle in derselben Replikations- oder Failover-Gruppe enthalten sind, kann die geklonte Tabelle logisch auf das Zielkonto repliziert werden.
Logische Replikation von Klonen¶
Wenn das Original und die geklonte Tabelle in derselben Replikations- oder Failover-Gruppe enthalten sind, kann die geklonte Tabelle logisch auf das Zielkonto repliziert werden.
Wenn zum Beispiel die Tabelle t2 in der Datenbank db2 ein Klon der Tabelle t1 in der Datenbank db1 ist und beide Datenbanken in der Replikationsgruppe rg1 enthalten sind, wird die Tabelle t2 als logischer Klon im Zielkonto erstellt.
Ein geklontes Objekt kann geklont werden, um weitere Klone des Originalobjekts zu erstellen. Das Originalobjekt und die geklonten Objekte sind Teil derselben Klongruppe. Wenn zum Beispiel die Tabelle t3 in der Datenbank db3 als Klon von t2 erstellt wird, befindet sie sich in derselben Klongruppe wie die Originaltabelle t1 und die geklonte Tabelle t2.
Wenn die Datenbank db3 später zur Replikationsgruppe rg1 hinzugefügt wird, wird die Tabelle t3 im Zielkonto als logischer Klon der Tabelle t1 erstellt.
Hinweise¶
Tabellen, die sich im Quellkonto in derselben Klongruppe befinden, sind möglicherweise nicht in derselben Klongruppe im Zielkonto.
Die Originaltabelle und die geklonte Tabelle müssen sich in derselben Replikations- oder Failover-Gruppe befinden.
In einigen Fällen können nicht alle Mikropartitionen der Klongruppe gemeinsam mit der geklonten Tabelle genutzt werden. Dies kann zu einer zusätzlichen Speichernutzung für die geklonte Tabelle im Zielkonto führen.
Beispiel¶
Die Tabelle t2 in der Datenbank db2 ist ein Klon der Tabelle t1 in der Datenbank db1. Nehmen Sie beide Datenbanken in die Replikationsgruppe myrg auf, um t2 logisch auf das Zielkonto zu replizieren:
Replikation und Automatic Clustering¶
In einer Primärdatenbank überwacht Snowflake geclusterte Tabellen mithilfe von Automatic Clustering und gruppiert sie nach Bedarf neu. Im Rahmen einer Aktualisierungsoperation werden gruppierte Tabellen mit der aktuellen Sortierung der Tabellenmikropartitionen in eine sekundäre Datenbank repliziert. Daher wird in der gruppierten Tabelle der sekundären Datenbank kein Reclustering ausgeführt, da dies redundant wäre.
Wenn eine sekundäre Datenbank gruppierte Tabellen enthält und die Datenbank zur primären Datenbank heraufgestuft wird, beginnt Snowflake mit dem Automatic Clustering der Tabellen in dieser Datenbank, während gleichzeitig die Überwachung gruppierter Tabellen in der bisherigen primären Datenbank ausgesetzt wird.
Informationen zu Automatic Clustering für materialisierte Ansichten finden Sie unter Replikation und materialisierte Ansichten (unter diesem Thema).
Replikation und große Tabellen mit hohen Änderungsraten¶
Wenn eine oder mehrere Zeilen einer Tabelle aktualisiert oder gelöscht werden, werden alle betroffenen Mikropartitionen, die diese Daten in einer Primärdatenbank speichern, neu erstellt und müssen mit Sekundärdatenbanken synchronisiert werden. Bei großen Tabellen mit hoher Änderungsrate können erhebliche Replikationskosten entstehen.
Für großen Tabellen mit hoher Änderungsrate, bei denen erhebliche Replikationskosten anfallen, können die Auswirkungen wie folgt abgeschwächt werden:
Verringern Sie die Häufigkeit der Replikation für alle Primärdatenbanken, in denen solche Tabellen gespeichert sind.
Ändern Sie Ihr Datenmodell, um die Änderungsrate zu verringern.
Weitere Informationen dazu finden Sie unter Verwalten der Kosten für große Tabellen mit hoher Änderungsrate.
Replikation und Time Travel¶
Time Travel- und Fail-safe-Daten einer Sekundärdatenbank werden unabhängig verwaltet und nicht von einer Primärdatenbank repliziert. Das Abfragen von Tabellen und Ansichten in einer Sekundärdatenbank mithilfe von Time Travel kann andere Ergebnisse liefern als das Ausführen derselben Abfrage in der Primärdatenbank.
- Historische Daten:
Historische Daten, die in einer Primärdatenbank mithilfe von Time Travel abgefragt werden können, werden nicht in Sekundärdatenbanken repliziert.
Angenommen, Daten werden alle 10 Minuten mit Snowpipe kontinuierlich in eine Tabelle geladen, und eine sekundäre Datenbank wird jede Stunde aktualisiert. Die Aktualisierungsoperation repliziert nur die neueste Version der Tabelle. Während jede stündliche Version der Tabelle im Aufbewahrungsfenster zur Abfrage mit Time Travel verfügbar ist, ist keine der iterativen Versionen innerhalb jeder Stunde (die einzelnen Snowpipe-Ladevorgänge) verfügbar.
- Datenaufbewahrungsfrist:
Die Datenaufbewahrungsfrist für Tabellen einer Sekundärdatenbank beginnt, wenn die Sekundärdatenbank mit den in Tabellen der Primärdatenbank geschriebenen DML-Operationen (d. h. Ändern oder Löschen von Daten) aktualisiert wird.
Bemerkung
Der Parameter DATA_RETENTION_TIME_IN_DAYS für die Datenaufbewahrungsfrist wird nur für Datenbankobjekte der Sekundärdatenbank repliziert, nicht für die Datenbank selbst. Weitere Einzelheiten zur Parameterreplikation finden Sie unter Parameter.
Replikation und materialisierte Ansichten¶
In einer Primärdatenbank führt Snowflake eine automatische Hintergrundwartung für materialisierte Ansichten durch. Wenn sich eine Basistabelle ändert, werden alle auf der Tabelle definierten materialisierten Ansichten von einem Hintergrunddienst aktualisiert, der von Snowflake bereitgestellte Computeressourcen nutzt. Wenn das Automatic Clustering für eine materialisierte Ansicht aktiviert ist, wird die Ansicht außerdem überwacht und bei Bedarf in einer Primärdatenbank erneut geclustert.
Eine Aktualisierungsoperation repliziert die materialisierte Ansicht Definitionen in eine Sekundärdatenbank. Die materialisierte Ansicht Daten werden nicht repliziert. Die automatische Hintergrundwartung von materialisierten Ansichten in einer Sekundärdatenbank ist standardmäßig aktiviert. Wenn für eine materialisierte Ansicht in einer Primärdatenbank Automatic Clustering aktiviert wird, wird dabei auch das automatische Überwachen und das Reclustering der materialisierten Ansicht in der Sekundärdatenbank aktiviert.
Bemerkung
Die Gebühren für die automatische Hintergrundsynchronisierung von materialisierten Ansichten werden jedem Konto in Rechnung gestellt, das eine Sekundärdatenbank enthält.
Replikation und Apache Iceberg™-Tabellen¶
Beachten Sie die folgenden Punkte, wenn Sie die Replikation für Iceberg-Tabellen verwenden:
Snowflake currently supports replication of Snowflake-managed tables only.
Die Replikation von konvertierten Iceberg-Tabellen wird nicht unterstützt. Snowflake überspringt konvertierte Tabellen bei Aktualisierungsoperationen.
Für replizierte Tabellen müssen Sie den Zugriff auf einen Speicherort in derselben Region wie das Zielkonto konfigurieren.
Wenn Sie einen Speicherort löschen oder ändern, der für die Replikation auf dem primären externen Volumen verwendet wird, können Aktualisierungsoperationen fehlschlagen.
Sekundäre Tabellen im Zielkonto sind schreibgeschützt, bis Sie das Zielkonto zum Quellkonto heraufstufen.
Snowflake verwaltet die Verzeichnishierarchie der primären Iceberg-Tabelle für die sekundäre Tabelle.
Für dieses Feature fallen Replikationskosten an. Weitere Informationen dazu finden Sie unter Erläuterungen zu den Replikationskosten.
Hinweise zu den Kontoobjekten für Replikations- und Failover-Gruppen finden Sie unter Kontoobjekte.
Replicating dynamic Iceberg tables isn’t supported. Snowflake skips converted tables during refresh operations.
Replikation und dynamische Tabellen¶
Die Verhaltensweise der Replikation dynamischer Tabellen hängt davon ab, ob die primäre Datenbank, die die dynamische Tabelle enthält, Teil einer Replikationsgruppe oder einer Failover-Gruppe ist.
Dynamische Tabellen und Replikationsgruppen¶
Eine Datenbank, die eine dynamische Tabelle enthält, kann mithilfe einer Replikationsgruppe repliziert werden. Das/die Quellobjekt(e), von dem/denen es abhängt, müssen sich nicht in derselben Replikationsgruppe befinden.
Replizierte Objekte in jedem Zielkonto werden als sekundäre Objekte bezeichnet und sind Repliken der primären Objekte im Quellkonto. Sekundäre Objekte sind im Zielkonto schreibgeschützt. Wenn eine sekundäre Replikationsgruppe in einem Zielkonto gelöscht wird, werden die Datenbanken, die in der Gruppe enthalten waren, zu Lese-/Schreibdatenbanken. Alle dynamischen Tabellen, die in einer Replikationsgruppe enthalten sind, bleiben jedoch schreibgeschützt, auch wenn die sekundäre Gruppe im Zielkonto gelöscht wird. Auf diesen schreibgeschützten dynamischen Tabellen können keine DML-Befehle oder Aktualisierungen ausgeführt werden.
Dynamische Tabellen und Failover-Gruppen¶
Eine Datenbank, die eine dynamische Tabelle enthält, kann mithilfe einer Failover-Gruppe repliziert werden. Wenn eine dynamische Tabelle Quellobjekte außerhalb der Failover-Gruppe oder der Datenbankreplikation referenziert, kann sie dennoch repliziert werden. Nach einem Failover löst die dynamische Tabelle die Quellobjekte während der Aktualisierung über die Namensauflösung auf. Die Aktualisierung kann erfolgreich sein oder fehlschlagen, je nach dem Zustand der Quellobjekte. Bei Erfolg wird die dynamische Tabelle mit den neuesten Daten aus den Quellobjekten reinitialisiert.
Sekundäre dynamische Tabellen sind schreibgeschützt und werden nicht aktualisiert. Nachdem ein Failover stattgefunden hat und eine sekundäre dynamische Tabelle zur primären dynamischen Tabelle heraufgestuft wurde, ist die erste Aktualisierung eine Neuinitialisierung, gefolgt von inkrementellen Aktualisierungen, wenn die dynamische Tabelle für eine inkrementelle Aktualisierung der Daten konfiguriert ist.
Bemerkung
Die reinitialisierte dynamische Tabelle kann sich vom ursprünglichen Replikat unterscheiden, da nicht garantiert werden kann, dass die Quellobjekte und die dynamische Tabelle denselben Replikations-Snapshot verwenden.
Beispiel: Aktualisierungsfehler aufgrund von fehlenden Quellobjekten
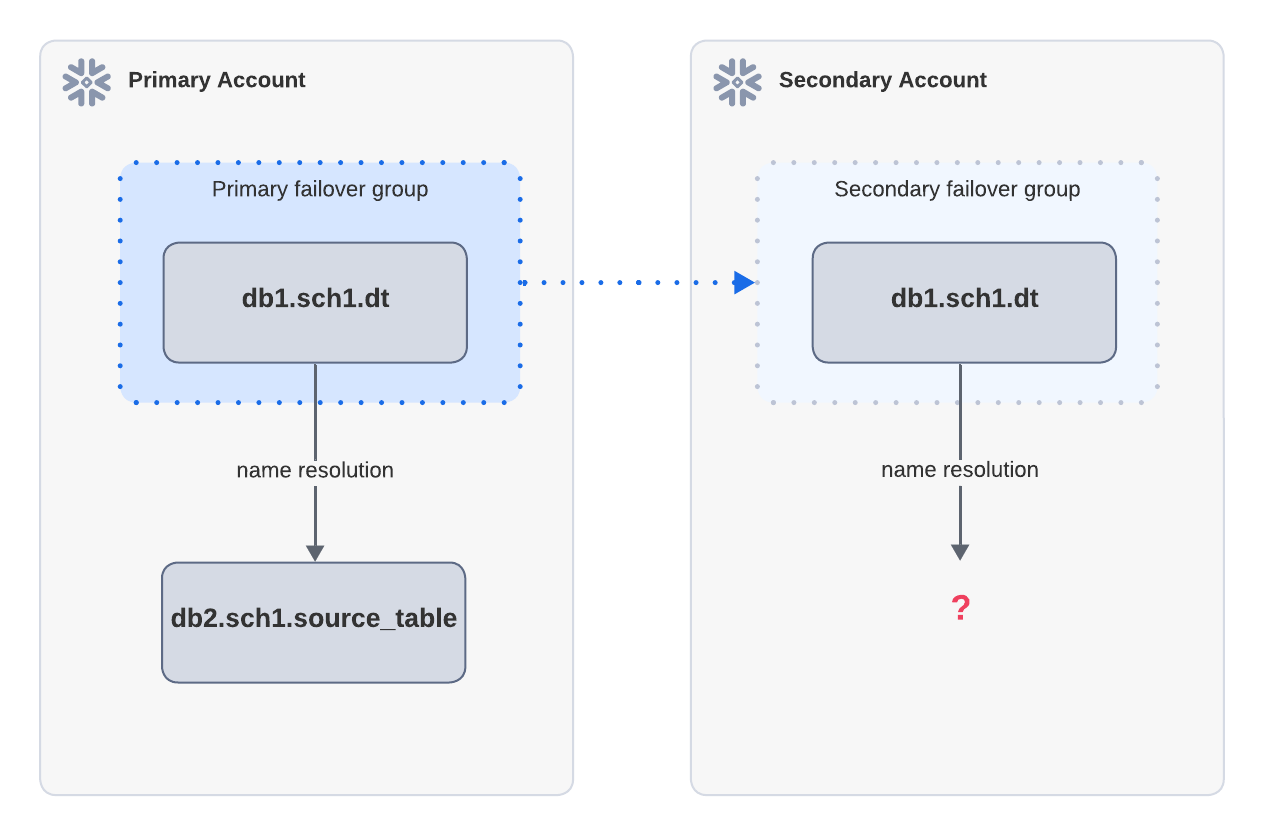
Wenn eine dynamische Tabelle von einer Quelltabelle außerhalb der Failover-Gruppe abhängt, kann sie nach einem Failover nicht aktualisiert werden. Im obigen Diagramm wird die dynamische Tabelle dt im primären Konto auf das sekundäre Konto repliziert. dt hängt von der source_table ab, die nicht in der gleichen Failover-Gruppe wie das primäre Konto enthalten ist. Nach dem Failover schlägt die Aktualisierung im sekundären Konto fehl, da die source_table nicht aufgelöst werden kann.
Beispiel: Erfolgreiche Aktualisierung, wenn Quellobjekte im sekundären Konto über eine separate Replikation vorhanden sind
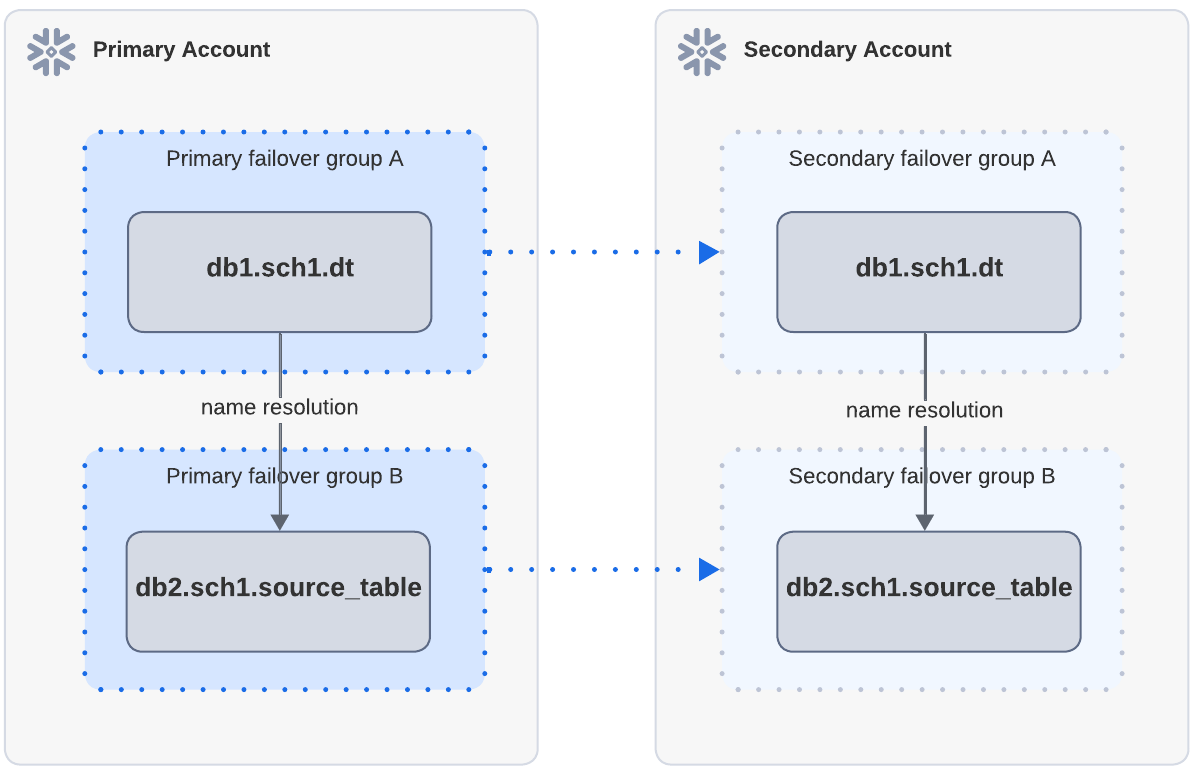
In dem obigen Diagramm hängt die dynamische Tabelle dt von der source_table ab. Sowohl dt als auch die source_table im primären Konto werden über unabhängige Failover-Gruppen auf das sekundäre Konto repliziert. Wenn dt nach der Replikation und dem Failover im sekundären Konto aktualisiert wird, ist die Aktualisierung erfolgreich, da die source_table über die Namensauflösung gefunden werden kann.
Beispiel: Erfolgreiche Aktualisierung, wenn Quellobjekte im sekundären Konto lokal vorhanden sind
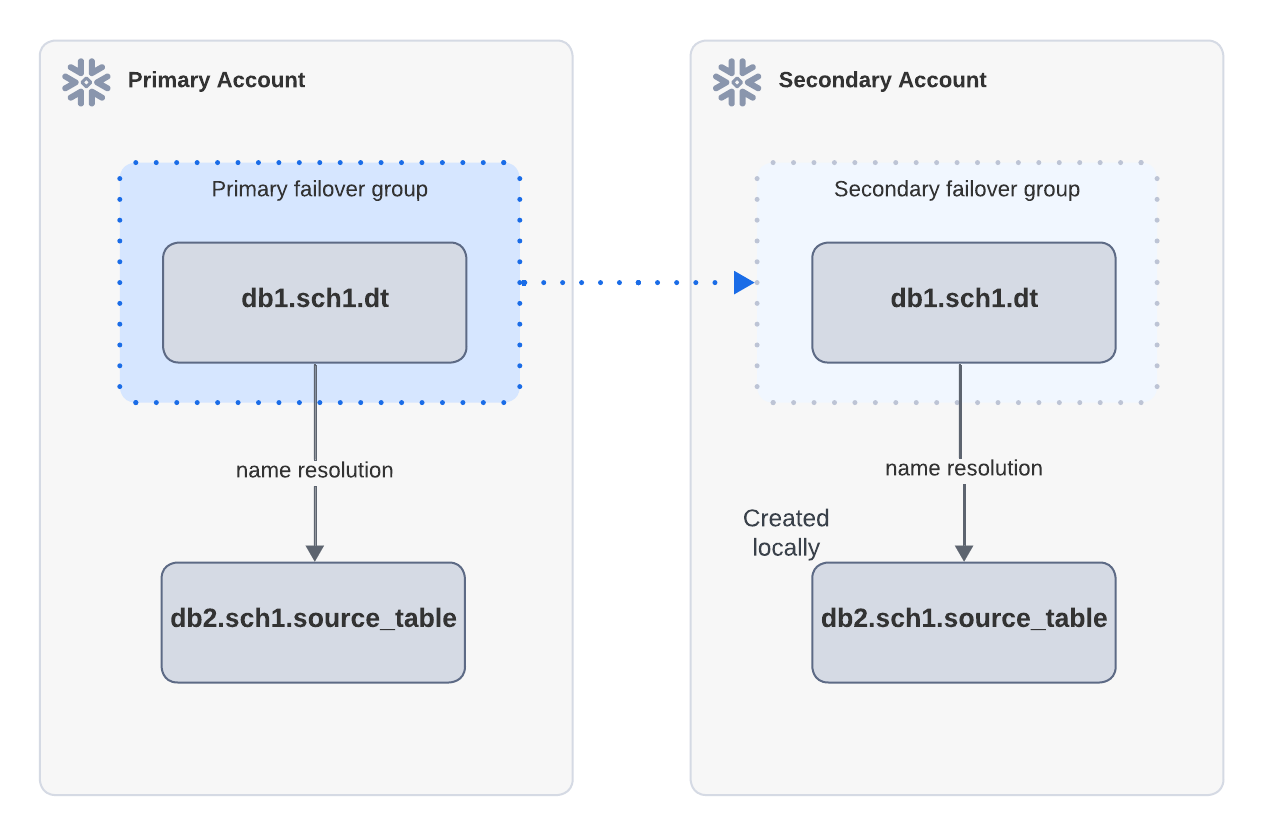
In dem obigen Diagramm hängt die dynamische Tabelle dt von die source_table ab und wird über eine Failover-Gruppe vom primären Konto auf das sekundäre Konto repliziert. Eine source_table wird lokal im sekundären Konto erstellt. Wenn dt1 nach dem Failover im sekundären Konto aktualisiert wird, kann die Aktualisierung erfolgreich sein, da die source_table über die Namensauflösung gefunden werden kann.
Replikation und Snowpipe Streaming¶
Eine Tabelle, die von Snowpipe Streaming in einer Primärdatenbank gefüllt wird, wird in die Sekundärdatenbank in einem Zielkonto repliziert.
In der Primärdatenbank werden Tabellen erstellt und Zeilen über Kanäle eingefügt. Mithilfe von Offset-Tokens wird der Erfassungsfortschritt verfolgt. Eine Aktualisierungsoperation repliziert das Tabellenobjekt, die Tabellendaten und die mit der Tabelle verbundenen Kanal-Offsets von der Primärdatenbank in die Sekundärdatenbank.
Snowpipe Streaming-Architekturen¶
Snowflake unterstützt zwei zugrunde liegende Architekturen für Snowpipe Streaming, die die verfügbaren Client-APIs und Leistungsmerkmale bestimmen.
Snowpipe Streaming mit klassischer Architektur¶
Schreibgeschützte Operationen (in Quell- und Zielkonten verfügbar):
getLatestCommittedOffsetToken-API des KanalsBefehl
SHOW CHANNELS
Schreiboperationen (nur im Quellkonto verfügbar):
openChannel-API des Clients
Kanal insertRow API
Kanal insertRows API
Snowpipe Streaming mit leistungsstarker Architektur¶
Diese Architektur bietet optimierte Features, einschließlich Massenoperationen und verbesserte Statusprüfungen, die für die Verwaltung von replizierten Umgebungen mit hohem Volumen entscheidend sind.
Alle unten beschriebenen Funktionen sind sowohl über Snowpipe Streaming SDKs als auch die Snowpipe Streaming REST API zugänglich, die eine flexible Integration auf der Grundlage Ihrer Infrastrukturanforderungen ermöglicht.
Schreib- und Verwaltungsoperationen (nur im Quellkonto verfügbar):
Management des Lebenszyklus eines Kanals: Öffnen und verwalten Sie die Datenerfassungskanäle, die für den Aufbau eines Datenstreams erforderlich sind. Beispiel: openChannel-Methode im Java SDK.
Transaktionskonsistente Datenerfassung: Die Kernfunktion zum Anhängen von Zeilen. Daten, die hier eingefügt werden, werden auf jeden Fall nach dem Commit in den Replikations-Snapshot aufgenommen. Beispiel: die appendRows-Methode im Java- SDK.
Verfolgung von Offset-Tokens: Rufen Sie die letzten bestätigten Offset-Token ab, um die Datenintegrität sicherzustellen und Duplizierungen während der Erfassung zu verhindern. Beispiel: die getLatestCommittedOffsetToken-Methode im Java-SDK.
Gesammelte Statusüberwachung: Überwachen Sie effizient die Zustands- und Verzögerungsmetriken über mehrere Kanäle hinweg. Dies ist entscheidend, um vor der Replikation zu überprüfen, ob die Datenlatenz akzeptabel ist. Beispiel: die getChannelStatus-Methode im Java-SDK.
Schreibgeschützte Operationen (sowohl in Quell- als auch in Zielkonten verfügbar):
Kanalüberprüfung: Verwenden Sie Metadaten-Befehle, wie z. B.
SHOW CHANNELS, um Konfigurationsdetails, Status und Eigenschaften von bestehenden Erfassungskanälen in der replizierten Umgebung anzuzeigen.
Vermeidung von Datenverlusten¶
Um Datenverluste bei einem Failover zu vermeiden, muss die Datenaufbewahrungsdauer für erfolgreich eingefügte Zeilen in Ihrer Upstream-Datenquelle größer sein als die der konfigurierte Replikationsplan. Wenn Daten in die Tabelle einer Primärdatenbank eingefügt werden und ein Failover stattfindet, bevor die Daten in die Sekundärdatenbank repliziert werden können, müssen dieselben Daten in die Tabelle der neu heraufgestuften Primärdatenbank eingefügt werden. Das folgende Beispiel zeigt ein Failover-Szenario:
Die Tabelle
t1in der Primärdatenbankrepl_dbwird über Snowpipe Streaming und den Kafka-Konnektor mit Daten gefüllt.Der Wert von
offsetTokenist 100 für Kanal 1 und 100 für Kanal 2 fürt1in der Primärdatenbank.Eine Aktualisierungsoperation wird im Zielkonto erfolgreich abgeschlossen.
Der Wert von
offsetTokenist 100 für Kanal 1 und 100 für Kanal 2 fürt1in der Sekundärdatenbank.Weitere Zeilen werden in
t1in der Primärdatenbank eingefügt.Der Wert von
offsetTokenist jetzt 200 für Kanal 1 und 200 für Kanal 2 fürt1in der Primärdatenbank.Ein Failover findet statt, bevor die zusätzlichen Zeilen und neuen Kanal-Offsets in die Sekundärdatenbank repliziert werden können.
In diesem Fall fehlen 100 Offsets in jedem Kanal für die Tabelle t1 in der neu heraufgestuften Primärdatenbank. Weitere Informationen zum Einfügen der fehlenden Daten finden Sie unter Aktive Kanäle für Snowpipe Streaming im neu heraufgestuften Quellkonto wieder öffnen.
Anforderungen an die Replikationsunterstützung¶
Snowpipe Streaming mit klassischer Architektur¶
Für die Snowpipe Streaming-Replikation bei der klassischen Architektur sind die folgenden Mindestversionen erforderlich:
Snowflake Ingest SDK Version 1.1.1 oder höher.
Bei Verwendung des Kafka-Konnektors: Kafka-Konnektor Version 1.9.3 oder höher.
Snowpipe Streaming mit leistungsstarker Architektur¶
Für die Snowpipe Streaming-Replikation bei der leistungsstarken Architektur sind die folgenden Mindestversionen erforderlich:
Snowpipe Streaming SDK Version 1.1.0 oder höher.
Datenaufbewahrungsanforderungen für beide Architekturen¶
Die Datenaufbewahrungsdauer für erfolgreich eingefügte Zeilen in Ihrer Upstream-Datenquelle muss größer sein als der konfigurierte Replikationsplan. Wenn Sie den Kafka-Konnektor verwenden, vergewissern Sie sich, dass Ihre log.retention-Konfiguration einen ausreichenden Puffer vorsieht.
Replikation und Stagingbereiche¶
Für Stagingobjekte gelten die folgenden Einschränkungen:
Snowflake unterstützt derzeit die Stagingbereichsreplikation als Teil der gruppenbasierten Replikation (Replikations- und Failover-Gruppen). Die Stagingbereichsreplikation wird für die Datenbankreplikation nicht unterstützt.
Sie können einen externen Stagingbereich replizieren. Die Dateien in einem externen Stagingbereich werden jedoch nicht repliziert.
Sie können einen internen Stagingbereich replizieren. Um die Dateien in einem internen Stagingbereich zu replizieren, müssen Sie in dem Stagingbereich eine Verzeichnistabelle aktivieren. Snowflake repliziert nur die Dateien, die durch die Verzeichnistabelle zugeordnet sind.
Wenn Sie einen internen Stagingbereich mit Verzeichnistabelle replizieren, können Sie die Verzeichnistabelle weder im primären noch im sekundären Stagingbereich deaktivieren. Die Verzeichnistabelle enthält wichtige Informationen zu den replizierten Dateien und zu Dateien, die mit einer COPY-Anweisung geladen wurden.
Eine Aktualisierungsoperation schlägt fehl, wenn die Verzeichnistabelle in einem internen Stagingbereich eine Datei enthält, die größer als 2 GB ist. Um diese Einschränkung zu umgehen, verschieben Sie alle Dateien, die größer als 5 GB sind, in einen anderen Stagingbereich.
Sie können die Verzeichnistabelle eines primären oder sekundären Stagingbereichs oder eines Stagingbereichs, der zuvor repliziert wurde, nicht deaktivieren. Führen Sie diese Schritte aus, bevor Sie die Datenbank, die den Stagingbereich enthält, zu einer Replikations- oder Failover-Gruppe hinzufügen.
Deaktivieren Sie die Verzeichnistabelle des primären Stagingbereichs.
Verschieben Sie die Dateien, die größer als 5 GB sind, in einen anderen Stagingbereich, bei dem keine Verzeichnistabelle aktiviert ist.
Nachdem Sie die Dateien in einen anderen Stagingbereich verschoben haben, aktivieren Sie die Verzeichnistabelle für den primären Stagingbereich wieder.
Dateien in Benutzer-Stagingbereichen und in Tabellen-Stagingbereichen werden nicht repliziert.
Bei benannten externen Stagingbereichen, die eine Speicherintegration verwenden, müssen Sie vor dem Failover die Vertrauensstellung für sekundäre Speicherintegrationen in Ihren Zielkonten konfigurieren. Weitere Informationen dazu finden Sie unter Cloudspeicherzugriff für sekundäre Speicherintegrationen konfigurieren.
Wenn Sie einen externen Stagingbereich mit Verzeichnistabelle replizieren und die automatische Aktualisierung für die primäre Verzeichnistabelle konfiguriert haben, müssen Sie vor dem Failover die automatische Aktualisierung für die sekundäre Verzeichnistabelle konfigurieren. Weitere Informationen dazu finden Sie unter Konfigurieren der automatischen Aktualisierung von Verzeichnistabellen in sekundären Stagingbereichen.
Ein Kopierbefehl kann länger dauern als erwartet, wenn die Verzeichnistabelle eines replizierten Stagingbereichs nicht mit den replizierten Dateien in dem Stagingbereich konsistent ist. Um die Konsistenz einer Verzeichnistabelle herzustellen, aktualisieren Sie diese mit einer ALTER STAGE … REFRESH-Anweisung. Um den Konsistenzstatus einer Verzeichnistabelle zu überprüfen, verwenden Sie die Funktion SYSTEM$GET_DIRECTORY_TABLE_STATUS.
Replikation und Pipes¶
Für Pipe-Objekte gelten die folgenden Einschränkungen:
Snowflake unterstützt derzeit die Pipe-Replikation als Teil der gruppenbasierten Replikation (Replikations- und Failover-Gruppen). Die Pipe-Replikation wird für die Datenbankreplikation nicht unterstützt.
Snowflake repliziert den Kopierverlauf einer Pipe nur dann, wenn die Pipe zur gleichen Replikationsgruppe gehört wie ihre Zieltabelle.
Die Replikation von Benachrichtigungsintegrationen wird nicht unterstützt.
Snowflake repliziert den Ladeverlauf erst nach der letzten Tabellenkürzung.
Um Benachrichtigungen zu erhalten, müssen Sie vor dem Failover eine sekundäre Auto-Erfassungs-Pipe in einem Zielkonto konfigurieren. Weitere Informationen dazu finden Sie unter Konfigurieren von Benachrichtigungen für sekundäre Auto-Erfassungs-Pipes.
Verwenden Sie die Funktion SYSTEM$PIPE_STATUS, um alle Pipes aufzulösen, die sich nach dem Failover nicht in ihrem erwarteten Ausführungsstatus befinden.
Snowflake unterstützt keine Replikation und kein Failover für Snowpipe mit dem Kafka Connector, aber Snowflake unterstützt Replikation und Failover für Snowpipe Streaming mit dem Kafka Connector. Weitere Informationen dazu finden Sie unter Snowpipe Streaming und der Kafka-Konnektor.
Replikation von Datenmetrikfunktionen (DMFs)¶
Die folgenden Verhaltensweisen gelten für die DMF-Replikation:
- Ereignistabellen
Die Ereignistabelle, in der die Ergebnisse des manuellen Aufrufs oder der Planung einer auszuführenden DMF gespeichert werden, wird nicht repliziert, da die Ereignistabelle lokal zu Ihrem Snowflake-Konto ist und Snowflake die Replikation von Ereignistabellen nicht unterstützt.
- Replikationsgruppen
Wenn Sie die Datenbank(en), die Ihre DMFs enthalten, zu einer Replikationsgruppe hinzufügen, geschieht im Zielkonto Folgendes:
DMFs werden vom Quellkonto repliziert.
Tabellen oder Ansichten, die in der DMF-Definition angegeben sind, z. B. mit einem Fremdschlüsselverweis, werden vom Quellkonto repliziert, es sei denn, die Tabelle oder Ansicht ist mit Cross-Cloud Auto-Fulfillment (Cloud-übergreifende automatische Ausführung) verbunden.
Geplante DMFs auf dem Zielkonto werden angehalten. Die sekundären DMFs setzen ihren Zeitplan fort, wenn Sie das Zielkonto zum Quellkonto heraufstufen und die sekundären DMFs zu primären DMFs werden.
- Failover-Gruppen
Wenn Sie die Datenbank(en), die Ihre DMFs enthalten, mit einer Failover-Gruppe replizieren, geschieht im Falle eines Failovers Folgendes:
Der Zeitplan der angehaltenen DMFs wird fortgesetzt, wenn Sie das Zielkonto zum Quellkonto heraufstufen.
Geplante DMFs im Zielkonto werden angehalten, nachdem Sie ein anderes Konto zum Quellkonto heraufgestuft haben.
Wenn Sie die Datenbank, die die DMF enthält, nicht in ein Zielkonto replizieren, werden die DMF-Zuordnungen zu einer Tabelle oder Ansicht gelöscht, wenn das Zielkonto zum Quellkonto heraufgestuft wird, da sie im neu heraufgestuften Quellkonto nicht verfügbar sind.
Tipp
Bevor Sie Ihr Konto übergeben, überprüfen Sie die DMF-Referenzen, indem Sie die Information Schema-Tabellenfunktion DATA_METRIC_FUNCTION_REFERENCES aufrufen, um die Tabellenobjekte zu ermitteln, die vor den Heraufstufungs- und Aktualisierungsoperationen mit einer DMF verbunden sind.
Replikation von gespeicherten Prozeduren und benutzerdefinierten Funktionen (UDFs)¶
Gespeicherte Prozeduren und UDFs werden von einer Primärdatenbank in Sekundärdatenbanken repliziert.
Gespeicherte Prozeduren und UDFs und Stagingbereiche¶
Wenn eine gespeicherte Prozedur oder UDF von Dateien in einem Stagingbereich abhängt (z. B. wenn die gespeicherte Prozedur in Python-Code definiert ist, der aus einem Stagingbereich hochgeladen wird), müssen Sie den Stagingbereich und die Dateien in die Sekundärdatenbank replizieren. Weitere Informationen zum Replizieren von Stagingbereichen finden Sie unter Replikation von Stagingbereichen, Pipes und des Ladeverlaufs.
Wenn beispielsweise eine Primärdatenbank über eine Python-Inline-UDF verfügt, die jeden Code importiert, der in einem Stagingbereich gespeichert ist, funktioniert die UDF erst, wenn auch der Stagingbereich und der importierte Code in die Sekundärdatenbank repliziert wurden.
Gespeicherte Prozeduren und UDFs und externer Netzwerkzugriff¶
Wenn eine gespeicherte Prozedur oder UDF vom Zugriff auf einen externen Netzwerkstandort abhängt, müssen Sie die folgenden Objekte replizieren:
EXTERNAL ACCESS INTEGRATIONS muss in der Liste
allowed_integration_typesder Replikations- oder Failover-Gruppe enthalten sein.Die Datenbank, die die Netzwerkregel enthält.
Die Datenbank, die das Geheimnis enthält, in dem die Anmeldeinformationen für die Authentifizierung beim externen Netzwerkstandort gespeichert sind.
Wenn das Geheimnisobjekt auf eine Sicherheitsintegration verweist, müssen Sie SECURITY INTEGRATIONS in die Liste
allowed_integration_typesder Replikations- oder Failover-Gruppe aufnehmen.
Replikation und Speicherlebenszyklusrichtlinien¶
Snowflake repliziert Speicherlebenszyklusrichtlinien und deren Zuordnungen zu Tabellen in Zielkonten, führt die Richtlinien jedoch nicht aus. Snowflake repliziert keine archivierten Daten in den Ebenen COOL oder COLD Tier. Archivierte Daten in Ihrem Quellkonto sind im Zielkonto nicht verfügbar.
Nach einem Failover auf ein Zielkonto hält Snowflake die Ausführung der Speicherlebenszyklusrichtlinie im ursprünglichen Quellkonto an. Nach dem Failback auf das Quellkonto setzt Snowflake die Ausführung der Richtlinien fort.
Snowflake führt Speicherlebenszyklusrichtlinien niemals automatisch auf sekundären Tabellen aus, auch nicht nach einem Failover. Sie können jedoch sekundäre Richtlinien in einem Zielkonto verwenden, indem Sie sie an neue Tabellen anhängen. Für diese neuen Tabellen führt Snowflake die Richtlinien aus.
Replikation und Streams¶
In diesem Abschnitt werden empfohlene Vorgehensweisen und potenzielle Problembereiche bei der Replikation von Streams in Replizieren von Datenbanken über mehrere Konten oder Kontoreplikation und Failover/Failback beschrieben.
Unterstützte Quellobjekte für Streams¶
Replizierte Streams können erfolgreich die Änderungsdaten für Tabellen und Ansichten innerhalb derselben Datenbank verfolgen.
Derzeit werden die folgenden Quellobjekttypen nicht unterstützt:
Externe Tabellen
Tabellen oder Ansichten in Datenbanken, die von den Stream-Datenbanken getrennt sind, es sei denn, beide Datenbanken – die Stream-Datenbank und die Datenbank, die das Quellobjekt speichert – sind in derselben Replikations- oder Failover-Gruppe enthalten.
Tabellen oder Ansichten in freigegebenen Datenbanken (d. h. Datenbanken, die von Anbieterkonten für Ihr Konto freigegeben wurden)
Die Replikation von Streams auf Verzeichnistabellen wird unterstützt, wenn Sie Replikation von Stagingbereichen, Pipes und des Ladeverlaufs aktivieren.
Die Replikations- oder Aktualisierungsoperation einer Datenbank schlägt fehl, wenn die Primärdatenbank einen Stream mit einem nicht unterstützten Quellobjekt enthält. Die Operation schlägt auch fehl, wenn das Quellobjekt eines Streams gelöscht wurde.
Nur-Anfügen-Streams werden bei replizierten Quellobjekten nicht unterstützt.
Vermeiden von Datenkopien¶
Bemerkung
Zusätzlich zu dem in diesem Abschnitt beschriebenen Szenario können Datenstreams in einer Sekundärdatenbank bei der erstmaligen Aktualisierungsoperation möglicherweise doppelte Zeilen zurückgeben. In diesem Fall bezieht sich doppelte Zeilen auf eine einzelne Zeile mit mehreren METADATA$ACTION-Spaltenwerten.
Nach der ersten Aktualisierungsoperation sollte dieses spezielle Problem von Sekundärdatenbanken nicht mehr auftreten.
Eine Datenduplizierung tritt auf, wenn DML-Operationen dieselben Änderungsdaten aus einem Stream mehrfach schreiben, ohne eine Eindeutigkeitsprüfung auszuführen. Dies kann vorkommen, wenn ein Stream und eine Zieltabelle für die Stream-Änderungsdaten in separaten Datenbanken gespeichert sind und diese Datenbanken nicht in dieselbe Replikations- oder Failover-Gruppe übertragen werden.
Angenommen, Sie fügen regelmäßig Änderungsdaten aus Stream s in Tabelle dt ein. (Für dieses Beispiel spielt das Quellobjekt für den Stream keine Rolle.) Stream- und Zieltabelle werden in getrennten Datenbanken gespeichert.
Zum Zeitstempel
t1wird eine Zeile in die Quelltabelle von Streamseingefügt und eine neue Tabellenversion erstellt. Der Stream speichert den Offset dieser Tabellenversion.Zum Zeitstempel
t2wird die Sekundärdatenbank, in der der Stream gespeichert ist, aktualisiert. Der replizierte Streamsspeichert nun den Offset.Zum Zeitstempel
t3werden die Änderungsdaten von Streamsin die Tabelledteingefügt.Zum Zeitstempel
t4wird für die Sekundärdatenbank, die Streamsspeichert, ein Failover ausgeführt.Zum Zeitstempel
t5werden die Änderungsdaten von Streamserneut in die Tabelledteingefügt.
Um diese Situation zu vermeiden, müssen Sie Replikation und Failover für alle Datenbanken, in denen die Streams und deren Zieltabellen gespeichert sind, zusammen ausführen.
Streamreferenzen in WHEN-Klausel von Aufgaben¶
Um unerwartetes Verhalten zu vermeiden, wenn Sie replizierte Aufgaben ausführen, die Streams in der WHEN boolean_expr-Klausel referenzieren, gibt es folgende Optionen:
Erstellen Sie die Aufgaben und Streams in derselben Datenbank oder
Wenn Streams in einer anderen Datenbank gespeichert sind als die Aufgaben, die auf sie verweisen, schließen Sie beide Datenbanken in dieselbe Failover-Gruppe ein.
Wenn eine Aufgabe auf einen Stream in einer separaten Datenbank verweist und beide Datenbanken nicht in der gleichen Failover-Gruppe enthalten sind, könnte das Failover der Datenbank, die die Aufgabe enthält, ohne die Datenbank ausgeführt werden, die den Stream enthält. In diesem Szenario wird bei Fortsetzung der Aufgabe in der ausgefallenen Datenbank ein Fehler erfasst, wenn versucht wird, die Aufgabe auszuführen, und der referenzierte Stream nicht gefunden wird. Dieses Problem kann gelöst werden, indem entweder ein Failover der Datenbank ausgeführt wird, die den Stream enthält, oder Datenbank und Stream in demselben Konto wie die fehlgeschlagene Datenbank, die die Aufgabe enthält, neu erstellt werden.
Veralten von Streams¶
Wenn ein Stream in der Primärdatenbank veraltet, veraltet auch der replizierte Stream in einer Sekundärdatenbank, sodass dessen Daten nicht mehr abgefragt und Änderungsdaten nicht mehr verbraucht werden können. Um dieses Problem zu lösen, erstellen Sie den Stream in der Primärdatenbank neu (mit CREATE OR REPLACE STREAM). Wenn die Sekundärdatenbank aktualisiert wird, ist der replizierte Stream wieder lesbar.
Beachten Sie, dass der Offset für einen neu erstellten Stream standardmäßig die aktuelle Tabellenversion ist. Sie können einen Stream, der auf eine frühere Tabellenversion verweist, mit Time Travel neu erstellen. Der replizierte Stream wäre dann jedoch nicht lesbar. Weitere Informationen dazu finden Sie unter Streamreplikation und Time Travel (unter diesem Thema).
Streamreplikation und Time Travel¶
Wenn nach dem Failover einer Primärdatenbank ein Stream in der Datenbank Time Travel verwendet, um eine Tabellenversion für das Quellobjekt zu einem Zeitpunkt vor dem letzten Aktualisierungszeitstempel zu lesen, kann der replizierte Stream nicht abgefragt und Änderungsdaten können nicht verbraucht werden. Ebenso schlägt das Abfragen der Änderungsdaten für ein Quellobjekt zu einem Zeitpunkt vor dem letzten Aktualisierungszeitstempel bei Verwendung der CHANGES-Klausel in SELECT-Anweisungen mit einem Fehler fehl.
Dies liegt daran, dass bei einer Aktualisierungsoperation die Tabellenhistorie zu einer einzigen Tabellenversion zusammenfasst wird. Iterative Tabellenversionen, die vor dem Zeitstempel der Aktualisierungsoperation erstellt wurden, werden in der Tabellenhistorie der replizierten Quellobjekte nicht aufbewahrt.
Betrachten Sie das folgende Beispiel:
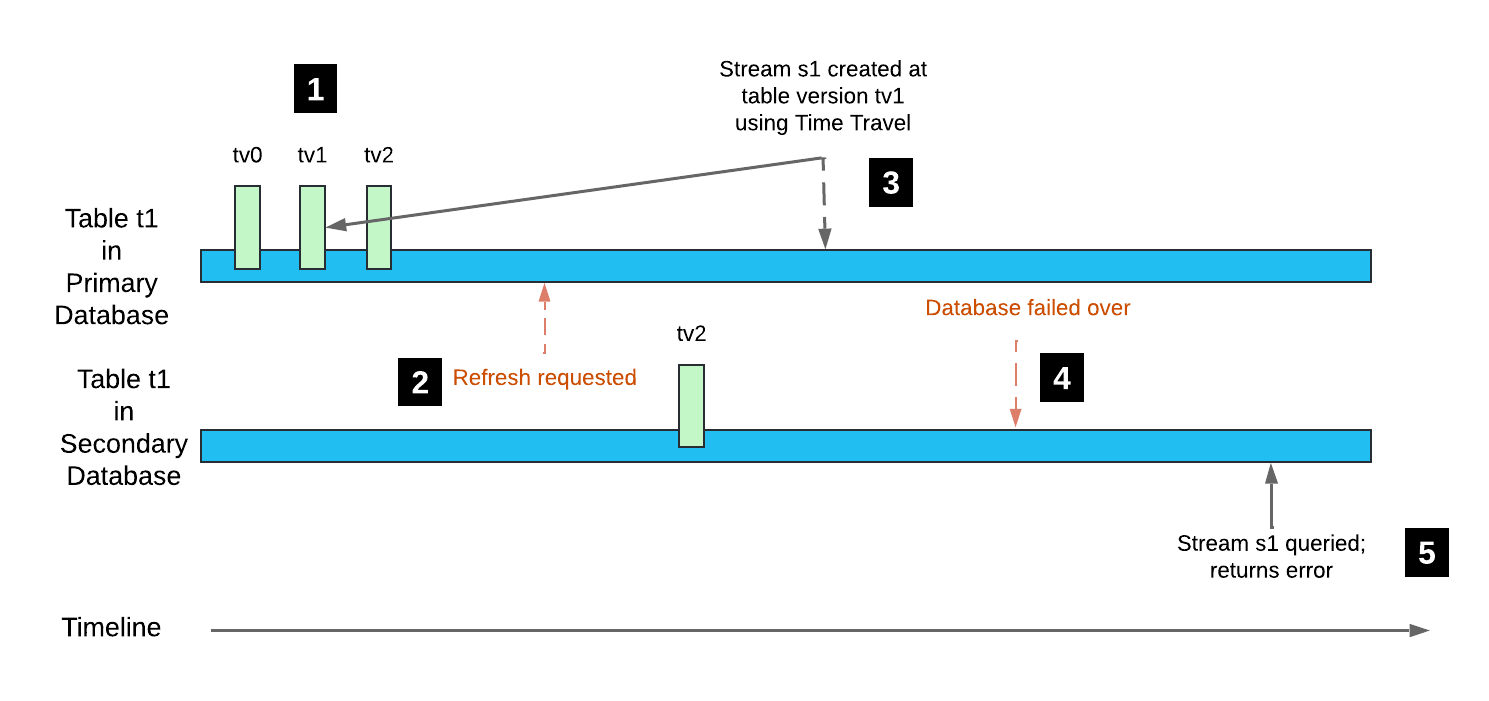
Tabelle
t1wird in der Primärdatenbank erstellt und die Änderungsverfolgung aktiviert (Tabellenversiontv0). Durch nachfolgende DML-Transaktionen werden die Tabellenversionentv1undtv2erstellt.Die Sekundärdatenbank, die die Tabelle
t1enthält, wird aktualisiert. Die Tabellenversion dieser replizierten Tabelle isttv2, wobei die Tabellenhistorie jedoch nicht repliziert wird.In der Primärdatenbank wird ein Stream erstellt, dessen Offset mithilfe von Time Travel auf die Tabellenversion
tv1gesetzt wird.Für die Sekundärdatenbank wird ein Failover ausgeführt, wodurch sie zur Primärdatenbank wird.
Das Abfragen von Stream
s1gibt einen Fehler zurück, da die Tabellenversiontv1nicht in der Tabellenhistorie enthalten ist.
Beachten Sie Folgendes: Wenn durch eine nachfolgende DML-Transaktion auf Tabelle t1 die Tabellenversion auf tv3 iteriert wird, wird der Offset für Stream s1 vorverlegt. Der Stream ist wieder lesbar.
Vermeiden von Datenverlusten¶
Datenverlusten können auftreten, wenn die letzte Aktualisierungsoperation einer Sekundärdatenbank nicht vor der Failover-Operation abgeschlossen ist. Wir empfehlen, Ihre Sekundärdatenbanken regelmäßig zu aktualisieren, um dieses Risiko zu minimieren.
Replikation und Aufgaben¶
In diesem Abschnitt wird die Replikation von Aufgaben in Replizieren von Datenbanken über mehrere Konten oder Kontoreplikation und Failover/Failback beschrieben.
Bemerkung
Die Datenbankreplikation funktioniert nicht für Task-Graphen, wenn das Diagramm einer anderen Rolle gehört als der Rolle, die die Replikation durchführt.
Replikationsszenarios¶
In der folgenden Tabelle sind die verschiedenen Aufgabenszenarios beschrieben, und es wird angegeben, ob die Aufgaben repliziert werden oder nicht. Sofern nicht anders angegeben, beziehen sich die Szenarios sowohl auf eigenständige Aufgaben als auch auf Aufgaben in einem Task-Graphen:
Szenario |
Repliziert |
Anmerkungen |
|---|---|---|
Aufgabe wurde erstellt und entweder fortgesetzt oder manuell ausgeführt (mit EXECUTE TASK). Durch Fortsetzen oder Ausführen einer Aufgabe wird eine Erstversion der Aufgabe erstellt. |
✔ |
|
Aufgabe wurde erstellt, aber nie fortgesetzt oder ausgeführt. |
❌ |
|
Aufgabe wurde neu erstellt (mit CREATE OR REPLACE TASK), aber nie fortgesetzt oder ausgeführt. |
✔ |
Die letzte Version vor dem Neuerstellen der Aufgabe wurde repliziert. Durch Fortsetzen oder manuelles Ausführen der Aufgabe wird eine neue Version festgeschrieben. Wenn die Datenbank erneut repliziert wird, wird die neue oder neueste Version in die Sekundärdatenbank repliziert. |
Aufgabe wurde erstellt und fortgesetzt oder ausgeführt, aber anschließend gelöscht. |
❌ |
|
Aufgabendiagramm wurde erstellt und fortgesetzt oder ausgeführt. Anschließend wurde eine Aufgabe im Aufgabendiagramm geändert, aber die Stammaufgabe des Aufgabendiagramms wurde nicht fortgesetzt oder ausgeführt. Beispiele für Änderungen sind die folgenden:
|
✔ |
Die letzte Version des Aufgabendiagramms, bevor die Aufgabe geändert wurde, wird repliziert. Durch die Wiederaufnahme oder manuelle Ausführung einer Aufgabe wird eine neue Version übertragen, die alle Änderungen an den Parametern der Aufgaben im Aufgabendiagramm enthält. Da die neuen Änderungen nie übertragen wurden, wird nur die vorherige Version des Aufgabendiagramms repliziert. Beachten Sie: Wenn das geänderte Aufgabendiagramm nicht innerhalb einer Aufbewahrungsfrist (derzeit 30 Tage) fortgesetzt wird, wird die letzte Version der Aufgabe gelöscht. Nach diesem Zeitraum wird die Aufgabe nicht mehr in eine Sekundärdatenbank repliziert, es sei denn, sie wird erneut fortgesetzt. |
Stammaufgabe eines Task-Graphen wurde erstellt und fortgesetzt oder ausgeführt, aber anschließend angehalten und gelöscht. |
❌ |
Der gesamte Task-Graph wird nicht in eine Sekundärdatenbank repliziert. |
Eine untergeordnete Aufgabe in einem Task-Graphen wird erstellt und fortgesetzt oder ausgeführt, aber anschließend angehalten und gelöscht. |
✔ |
Die letzte Version des Task-Graphen (bevor die Aufgabe angehalten und gelöscht wurde) wird in eine Sekundärdatenbank repliziert. |
Status „Fortgesetzt“ oder „Angehalten“ von replizierten Aufgaben¶
Wenn jede der folgenden Bedingungen erfüllt ist, wird eine Aufgabe im Status „Fortgesetzt“ in die Sekundärdatenbank repliziert:
Eine eigenständige oder Stammaufgabe befindet sich in der Primärdatenbank im Status „Fortgesetzt“, wenn die Replikations- oder Aktualisierungsoperation beginnt und bis zum Abschluss der Operation. Befindet sich eine Aufgabe nur während eines Teils dieses Zeitraums im Status „Fortgesetzt“, kann sie dennoch im Status „Fortgesetzt“ repliziert werden.
Eine untergeordnete Aufgabe befindet sich mit seiner neuesten Version im Status „Fortgesetzt“.
Die übergeordnete Datenbank wurde zusammen mit Rollenobjekten derselben oder einer anderen Replikations- oder Failover-Gruppe in das Zielkonto repliziert.
Nachdem die Rollen und die Datenbank repliziert wurden, müssen Sie die Objekte im Zielkonto aktualisieren, indem Sie ALTER REPLICATION GROUP … REFRESH bzw. ALTER FAILOVER GROUP … REFRESH ausführen. Wenn Sie die Datenbank durch Ausführen von ALTER DATABASE … REFRESH aktualisieren, wird der Status der Aufgaben in der Datenbank in „Angehalten“ geändert.
Eine Replikations- oder Aktualisierungsoperation umfasst auch Berechtigungszuweisungen für eine Aufgabe, die zum Zeitpunkt der Commit-Ausführung der neuesten Tabellenversion gültig waren. Weitere Informationen dazu finden Sie unter Replizierte Aufgaben und Berechtigungszuweisungen (unter diesem Thema).
Wenn diese Bedingungen nicht erfüllt sind, wird die Aufgabe im Status „Angehalten“ in eine Sekundärdatenbank repliziert.
Bemerkung
Sekundäre Aufgaben werden erst nach einem Failover geplant, unabhängig von ihrem state-Wert. Weitere Informationen dazu finden Sie unter Aufgabenausführung nach einem Failover.
Replizierte Aufgaben und Berechtigungszuweisungen¶
Wenn die übergeordnete Datenbank zusammen mit Rollenobjekten derselben oder einer anderen Replikations- oder Failover-Gruppe in ein Zielkonto repliziert wird, werden auch die den Aufgaben in der Datenbank erteilten Berechtigungen repliziert.
Die folgende Logik bestimmt, welche Aufgabenberechtigungen bei einer Replikations- oder Aktualisierungsoperation repliziert werden:
Wenn der aktuelle Aufgabeneigentümer (d. h. die Rolle mit OWNERSHIP-Berechtigung für die Aufgabe) dieselbe Rolle ist wie bei der letzten Fortsetzung der Aufgabe, werden alle aktuell für die Aufgabe erteilten Berechtigungen in die Sekundärdatenbank repliziert.
Wenn der aktuelle Aufgabeneigentümer nicht dieselbe Rolle ist wie bei der letzten Fortsetzung der Aufgabe, dann wird in die Sekundärdatenbank nur die OWNERSHIP-Berechtigung repliziert, die der Eigentümerrolle in der Aufgabenversion zugewiesen wurde.
Wenn die aktuelle Rolle des Aufgabeneigentümers nicht verfügbar ist (z. B. wenn eine untergeordnete Aufgabe gelöscht wurde, aber eine neue Version des Task-Graphen noch nicht mit Commit bestätigt wurde), wird in die Sekundärdatenbank nur die OWNERSHIP-Berechtigung repliziert, die der Eigentümerrolle in der Aufgabenversion zugewiesen wurde.
Aufgabenausführung nach einem Failover¶
Nachdem eine sekundäre Failover-Gruppe zur primären Gruppe heraufgestuft wurde, werden alle fortgesetzten Aufgaben in Datenbanken innerhalb der Failover-Gruppe schrittweise geplant. Die Zeit, die zur Wiederherstellung der normalen Planung aller fortgesetzten eigenständigen Aufgaben und Task-Graphen benötigt wird, hängt von der Anzahl der fortgesetzten Aufgaben in einer Datenbank ab.
Replikation und dbt-Projekte¶
dbt-Projektobjekte werden von einer Primärdatenbank in Sekundärdatenbanken repliziert.
Alle Sekundärobjekte in einem Zielkonto, einschließlich Sekundärdatenbanken, sind schreibgeschützt. Ein sekundäres dbt-Projekt kann nicht ausgeführt werden.
Alle Objekte, auf die ein dbt-Projekt verweist, wie z. B. Quelltabellen und Ansichten, sollten mit dem dbt-Projekt repliziert werden, damit die Ausführung dieses dbt-Projekts nach dem Failover erfolgreich ist.
dbt-Projekte und externer Netzwerkzugriff¶
Wenn ein dbt-Projekt vom Zugriff auf einen externen Netzwerkstandort abhängt, müssen Sie die folgenden Objekte replizieren:
EXTERNAL ACCESS INTEGRATIONS muss in der Liste
allowed_integration_typesder Replikations- oder Failover-Gruppe enthalten sein.Die Datenbank, die die Netzwerkregel enthält.
Die Datenbank, die das Geheimnis enthält, in dem die Anmeldeinformationen für die Authentifizierung beim externen Netzwerkstandort gespeichert sind.
Wenn das Geheimnisobjekt auf eine Sicherheitsintegration verweist, müssen Sie SECURITY INTEGRATIONS in die Liste
allowed_integration_typesder Replikations- oder Failover-Gruppe aufnehmen.
Ein dbt-Projekt speichert nicht die Integrationen für den Zugriff auf externe Netzwerke, mit denen es verbunden ist. Integrationen für den Zugriff auf externe Netzwerke werden angegeben, wenn der Benutzende den Befehl EXECUTEDBTPROJECT ausführt. Dadurch wird die Anforderung, Integrationen für den externen Zugriff separat zu replizieren, deutlicher.
Replikation und Instanzen von Snowflake-Klassen¶
Eine Instanz der Klasse CUSTOM_CLASSIFIER wird repliziert, wenn die Datenbank, die die Instanz enthält, repliziert wird. Die Replikation von Instanzen anderer Snowflake-Klassen wird nicht unterstützt.
Historische Nutzungsdaten¶
Historische Nutzungsdaten für Aktivitäten in einer Primärdatenbank werden nicht in Sekundärdatenbanken repliziert. Jedes Konto verfügt über einen eigenen Abfrageverlauf, einen eigenen Anmeldeverlauf usw.
Historische Nutzungsdaten umfassen die Abfragedaten, die von den folgenden Snowflake Information Schema-Tabellenfunktionen oder Account Usage-Ansichten zurückgegeben werden:
COPY_HISTORY
LOGIN_HISTORY
QUERY_HISTORY
usw.