Best Practices für dynamische Tabellen¶
Unter diesem Thema werden bewährte Verfahren und wichtige Hinweise zum Erstellen und Verwalten dynamischer Tabellen bereitgestellt.
Allgemeine Best Practices:
Best Practices für das Erstellen dynamischer Tabellen:
Best Practices für das Aktualisieren dynamischer Tabellen:
Best Practices zur Optimierung der Leistung:
Allgemeine Best Practices¶
MONITOR-Berechtigung zum Anzeigen von Metadaten verwenden¶
Für Szenarios, in denen der Benutzer nur die Metadaten und das Information Schema einer dynamischen Tabelle einsehen muss (z. B. Rollen für Data Scientists), verwenden Sie eine Rolle, die über die Berechtigung MONITOR für diese dynamische Tabelle verfügt. Die Berechtigung OPERATE gewährt ebenfalls diesen Zugriff, bietet aber auch die Fähigkeit, dynamische Tabellen zu ändern. MONITOR ist daher die geeignetere Option in Szenarios ist, in denen ein Benutzer eine dynamische Tabelle nicht ändern muss.
Weitere Informationen dazu finden Sie unter Zugriffssteuerung für dynamische Tabellen.
Zusammengesetzte Ausdrücke in Gruppierungsschlüsseln vereinfachen¶
Wenn ein Gruppierungsschlüssel einen zusammengesetzten Ausdruck und keine Basisspalte enthält, materialisieren Sie den Ausdruck in einer dynamischen Tabelle und wenden dann die Gruppierungsoperation auf die materialisierte Spalte in einer anderen dynamischen Tabelle an. Weitere Informationen dazu finden Sie unter Inkrementelle Aktualisierungen durch Operatoren.
Dynamische Tabellen zum Implementieren von Slowly Changing Dimensions¶
Dynamische Tabellen können verwendet werden, um Slowly Changing Dimensions (SCDs) vom Typ 1 und 2 zu implementieren. Wenn Sie aus einem Änderungsstream lesen, verwenden Sie Fensterfunktionen über Schlüssel pro Datensatz, die nach einem Änderungs-Zeitstempel sortiert sind. Mit dieser Methode verarbeiten dynamische Tabellen nahtlos außerplanmäßige Einfügungen, Löschungen und Aktualisierungen, um die SCD-Erstellung zu vereinfachen. Weitere Informationen dazu finden Sie unter Slowly Changing Dimensions mit dynamischen Tabellen.
Best Practices für das Erstellen dynamischer Tabellen¶
Pipelines dynamischer Tabellen verketten¶
Wenn Sie eine neue dynamische Tabelle definieren, sollten Sie keine große dynamische Tabelle mit vielen verschachtelten Anweisungen definieren, sondern stattdessen kleine dynamische Tabellen mit Pipelines verwenden.
Sie können eine dynamische Tabelle einrichten, um andere dynamische Tabellen abzufragen. Stellen Sie sich zum Beispiel ein Szenario vor, in dem Ihre Datenpipeline Daten aus einem Stagingbereich extrahiert, um verschiedene Dimensionstabellen zu aktualisieren (z. B. Kunde, Produkt, Datum und Uhrzeit). Außerdem aktualisiert Ihre Pipeline eine aggregierte Verkaufstabelle, die auf den Informationen aus diesen Dimensionstabellen basiert. Indem Sie die Dimensionstabellen so konfigurieren, dass sie die Staging-Tabelle abfragen, und die aggregierte Verkaufstabelle so, dass sie die Dimensionstabellen abfragt, erzeugen Sie einen Kaskadeneffekt, ähnlich wie bei einem Task-Graphen.
In diesem Setup wird die Aktualisierung der aggregierten Umsatztabelle erst ausgeführt, nachdem die Aktualisierungen der Dimensionstabellen erfolgreich abgeschlossen wurden. Dies stellt die Konsistenz der Daten und die Einhaltung der Verzögerungsziele sicher. Durch einen automatischen Aktualisierungsprozess lösen alle Änderungen in den Quelltabellen zu den entsprechenden Zeitpunkten Aktualisierungen in allen abhängigen Tabellen aus.
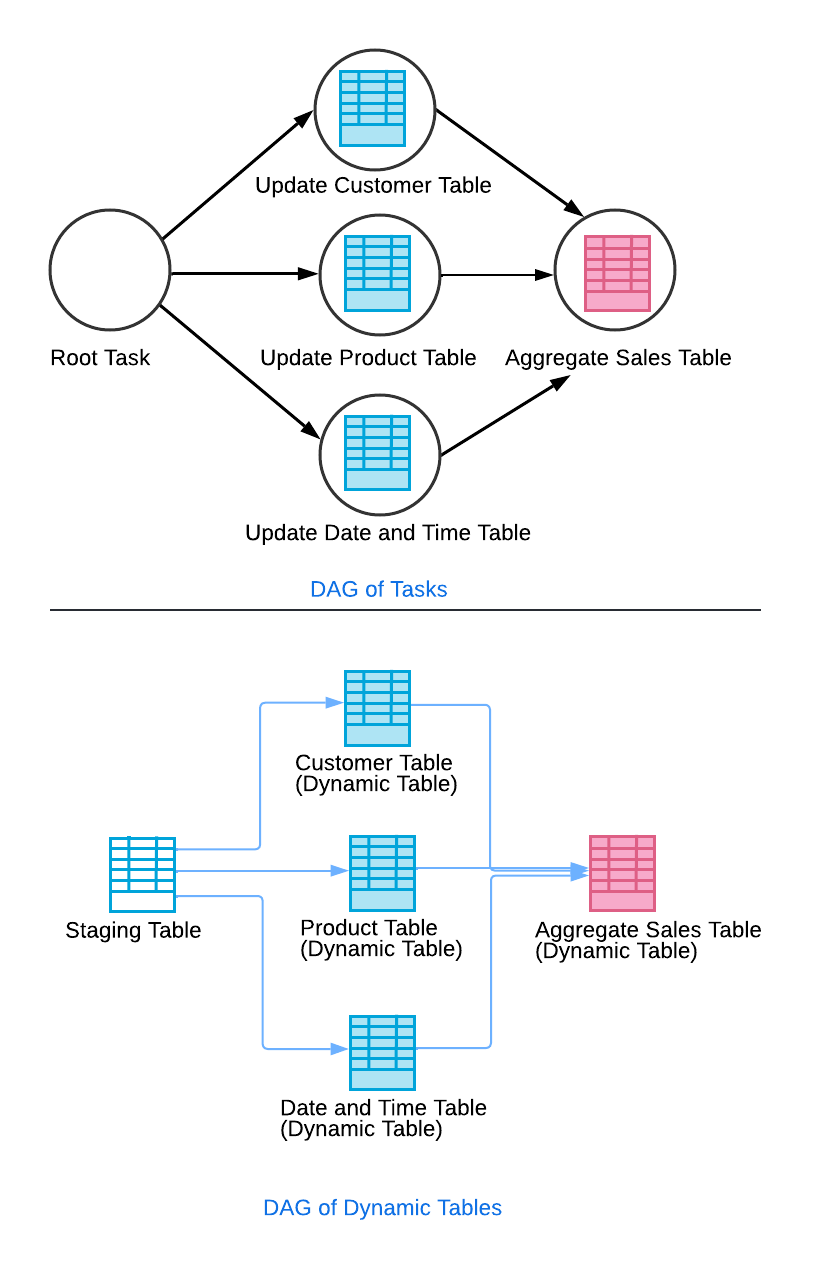
Dynamische „Controller“-Tabelle für komplexe Task-Graphen verwenden¶
Wenn Sie einen komplexen Graphen von dynamischen Tabellen mit vielen Wurzeln und Blättern haben und mit einem einzigen Befehl Operationen (z. B. Änderung der Verzögerung, manuelle Aktualisierung, Aussetzung) am gesamten Task-Graphen ausführen möchten, gehen Sie wie folgt vor:
Setzen Sie den Wert für
TARGET_LAGfür alle Ihre dynamischen Tabellen aufDOWNSTREAM.Erstellen Sie eine dynamische „Controller“-Tabelle, die alle Blätter in Ihrem Task-Graphen ausliest. Um sicherzustellen, dass dieser Controller keine Ressourcen verbraucht, gehen Sie wie folgt vor:
CREATE DYNAMIC TABLE controller TARGET_LAG = <target_lag> WAREHOUSE = <warehouse> AS SELECT 1 A FROM <leaf1>, …, <leafN> LIMIT 0;
Verwenden Sie den Controller, um den gesamten Task-Graphen zu steuern. Beispiel:
Legen Sie eine neue Zielverzögerung für den Task-Graphen fest.
ALTER DYNAMIC TABLE controller SET TARGET_LAG = <new_target_lag>Aktualisieren Sie den Task-Graphen manuell.
ALTER DYNAMIC TABLE controller REFRESH
Allgemeine Informationen zum Klonen der Pipelines von dynamischen Tabellen¶
Klonen Sie alle Elemente einer Pipeline für dynamische Tabellen mit demselben Klon-Befehl, um Neuinitialisierungen Ihrer Pipeline zu vermeiden. Sie können dies tun, indem Sie alle Elemente der Pipeline (z. B. Basistabellen, Ansichten und dynamische Tabellen) in demselben Schema oder derselben Datenbank konsolidieren. Weitere Informationen dazu finden Sie unter Bekannte Einschränkungen für dynamische Tabellen.
Verwenden Sie transiente dynamische Tabellen, um die Speicherkosten zu reduzieren¶
Transiente dynamische Tabellen halten Daten zuverlässig über die Zeit aufrecht und unterstützen Time Travel innerhalb der Datenaufbewahrungsfrist, bewahren aber keine Daten über die Fail-safe-Frist hinaus auf. Standardmäßig werden die dynamischen Tabellendaten 7 Tage lang im ausfallsicheren Fail-safe-Speicher aufbewahrt. Bei dynamischen Tabellen mit hohem Aktualisierungsdurchsatz kann dies den Speicherverbrauch erheblich erhöhen. Daher sollten Sie eine dynamische Tabelle nur dann zu einer transienten Tabelle machen, wenn ihre Daten nicht dasselbe Maß an Datenschutz und Wiederherstellung benötigen, das permanente Tabellen bieten.
Mit der Anweisung CREATE DYNAMIC TABLE können Sie eine transiente dynamische Tabelle erstellen oder bestehende dynamische Tabellen in transiente dynamische Tabellen klonen.
Best Practices für das Aktualisieren dynamischer Tabellen¶
Dedizierte Warehouses für Aktualisierungen verwenden¶
Dynamische Tabellen benötigen ein virtuelles Warehouse, um Aktualisierungen auszuführen. Um ein klares Bild von den Kosten Ihrer dynamischen Tabellenpipelines zu erhalten, sollten Sie Ihre dynamischen Tabellen mit dedizierten Warehouses testen, sodass der Verbrauch des virtuellen Warehouses, das den dynamischen Tabellen vorbehalten ist, isoliert werden kann. Weitere Informationen dazu finden Sie unter Erläuterungen zu den Kosten von dynamischen Tabellen.
Nachgelagerte Verzögerung verwenden¶
Eine nachgelagerte Verzögerung (Downstream Lag) zeigt an, dass die dynamische Tabelle aktualisiert werden sollte, wenn andere abhängige dynamische Tabellen aktualisiert werden müssen. Sie sollten die nachgelagerte Verzögerung aufgrund ihrer Benutzerfreundlichkeit und Kosteneffizienz als bewährtes Verfahren einsetzen. Ohne nachgelagerte Verzögerung würde die Verwaltung einer Kette komplexer dynamischer Tabellen erfordern, dass jeder Tabelle eine eigene Zielverzögerung zugewiesen und die zugehörigen Einschränkungen verwaltet werden, anstatt nur die Datenaktualität der letzten Tabelle zu überwachen. Weitere Informationen dazu finden Sie unter Erläuterungen zur Zielverzögerung.
Aktualisierungsmodus für alle dynamischen Tabellen in der Produktionsumgebung festlegen¶
Der tatsächliche Aktualisierungsmodus einer dynamischen Tabelle wird zum Zeitpunkt der Erstellung festgelegt und ist danach unveränderlich. Wenn nicht explizit angegeben, ist der Aktualisierungsmodus standardmäßig auf AUTO eingestellt, wodurch der Aktualisierungsmodus auf der Grundlage verschiedener Faktoren wie der Abfragekomplexität oder nicht unterstützter Konstrukte, Operatoren oder Funktionen ausgewählt wird.
Um den besten Modus für Ihren Anwendungsfall zu ermitteln, experimentieren Sie mit Aktualisierungsmodi und automatischen Empfehlungen. Um eine konsistente Verhaltensweise in allen Snowflake Releases zu gewährleisten, stellen Sie den Aktualisierungsmodus explizit für alle Produktionstabellen ein. Die Verhaltensweise von AUTO kann sich zwischen verschiedenen Releases von Snowflake ändern, was bei der Verwendung in Produktionspipelines zu unerwarteten Änderungen der Leistung führen kann.
Informationen zum Verifizieren des Aktualisierungsmodus für Ihre dynamischen Tabellen finden Sie unter Aktualisierungsmodus von dynamischen Tabellen anzeigen.
Best Practices zum Optimieren der Leistung¶
Um die Leistung Ihrer dynamischen Tabellen zu optimieren, sollten Sie das System verstehen, mit Ideen experimentieren und auf der Grundlage der Ergebnisse iterieren. Beispiel:
Entwickeln Sie Möglichkeiten zur Verbesserung Ihrer Datenpipeline auf der Grundlage Ihrer Anforderungen an Kosten, Datenverzögerung und Antwortzeiten.
Führen Sie die folgenden Aktionen durch:
Beginnen Sie mit einem kleinen, festen Datenset, um schnell Abfragen zu entwickeln.
Testen Sie die Leistung mit in Bewegung befindlichen Daten.
Skalieren Sie das Datenset, um zu überprüfen, ob es Ihren Anforderungen entspricht.
Passen Sie Ihren Workload auf der Grundlage der Ergebnisse an.
Wiederholen Sie den Vorgang nach Bedarf und priorisieren Sie dabei die Aufgaben mit den größten Auswirkungen auf die Leistung.
Nutzen Sie außerdem die nachgelagerte Verzögerung, um die Abhängigkeiten zwischen den Tabellen effizient zu verwalten und sicherzustellen, dass Aktualisierungen nur bei Bedarf durchgeführt werden. Leistung Weitere Informationen finden Sie in der Performance-Dokumentation.
Auswahl zwischen den Aktualisierungsmodi¶
Um den besten Modus für Ihren Anwendungsfall zu ermitteln, experimentieren Sie mit automatischen Empfehlungen und den konkreten Aktualisierungsmodi (vollständig und inkrementell). Der beste Modus für die Leistung Ihrer dynamischen Tabellen hängt vom Volumen der Datenänderungen und der Komplexität der Abfrage ab. Außerdem hilft das Testen verschiedener Aktualisierungsmodi mit einem speziellen Warehouse dabei, die Kosten zu isolieren und die Leistung auf der Grundlage des tatsächlichen Workloads zu verbessern.
Informationen zum Verifizieren des Aktualisierungsmodus für Ihre dynamischen Tabellen finden Sie unter Aktualisierungsmodus von dynamischen Tabellen anzeigen.
AUTO Aktualisierungsmodus: Das System versucht standardmäßig, eine inkrementelle Aktualisierung durchzuführen. Wenn die inkrementelle Aktualisierung nicht unterstützt wird oder keine gute Leistung erbringt, wählt die dynamische Tabelle stattdessen automatisch die vollständige Aktualisierung.
Um eine einheitliche Verhaltensweise zu gewährleisten, stellen Sie den Aktualisierungsmodus explizit für alle Produktionstabellen ein. Die Verhaltensweise von
AUTOkann sich zwischen verschiedenen Releases von Snowflake ändern, was bei der Verwendung in Produktionspipelines zu unerwarteten Änderungen der Leistung führen kann.
Inkrementelle Aktualisierung: Aktualisiert die dynamische Tabelle nur mit den Änderungen seit der letzten Aktualisierung. Dies ist ideal für große Datensets mit häufigen kleinen Aktualisierungen.
Am besten geeignet für Abfragen, die mit der inkrementellen Aktualisierung kompatibel sind (z. B. deterministische Funktionen, einfache Joins und grundlegende Ausdrücke in
SELECT,WHEREundGROUP BY). Wenn nicht unterstützte Features vorhanden sind und der Aktualisierungsmodus auf inkrementell festgelegt ist, kann Snowflake die dynamische Tabelle nicht erstellen.Eine wichtige Methode zur Leistungsoptimierung bei der inkrementellen Aktualisierung ist die Beschränkung des Änderungsvolumens auf etwa 5 % der Quelldaten und das Clustering Ihrer Daten nach den Gruppierungsschlüsseln, um den Verarbeitungsaufwand zu verringern.
Bedenken Sie, dass bestimmte Kombinationen von Operationen, wie Aggregationen auf vielen Joins, möglicherweise nicht effizient ausgeführt werden.
Vollständige Aktualisierung: Verarbeitet das gesamte Datenset neu und aktualisiert die dynamische Tabelle mit dem vollständigen Abfrageergebnis. Verwenden Sie diese Funktion für komplexe Abfragen oder wenn erhebliche Datenänderungen eine vollständige Aktualisierung erfordern.
Nützlich, wenn eine inkrementelle Aktualisierung aufgrund komplexer Abfragen, nicht-deterministischer Funktionen oder größerer Änderungen in den Daten nicht unterstützt wird.
Weitere Informationen dazu finden Sie unter Einfluss des Aktualisierungsmodus auf die Performance dynamischer Tabellen.
Leistung der vollständigen Aktualisierung¶
Die Leistung von dynamischen Tabellen mit vollständiger Aktualisierung ist ähnlich der von CREATE TABLE … AS SELECT (auch al CTAS bezeichnet). Solche Tabellen können wie jede andere Snowflake-Abfrage optimiert werden.
Leistung der inkrementellen Aktualisierung¶
So erreichen Sie eine optimale Leistung bei der inkrementellen Aktualisierung Ihrer dynamischen Tabellen:
Halten Sie die Änderungen zwischen den Aktualisierungen minimal, idealerweise weniger als 5 % des gesamten Datensets, sowohl bezüglich der Quellen als auch der dynamischen Tabelle.
Berücksichtigen Sie die Anzahl der geänderten Mikropartitionen, nicht nur die Anzahl der Zeilen. Der Arbeitsaufwand für eine inkrementelle Aktualisierung verhält sich proportional zur Größe dieser Mikropartitionen und nicht nur zu den Zeilen, die geändert wurden.
Minimieren Sie Gruppierungsoperationen wie Joins, GROUP BYs und PARTITION BYs in Ihrer Abfrage. Zerlegen Sie große Common Table Expressions (CTEs) in kleinere Teile, und erstellen Sie für jeden eine dynamische Tabelle. Vermeiden Sie es, eine einzelne dynamische Tabelle mit übermäßigen Aggregationen oder Joins zu überfrachten.
Stellen Sie die Datenlokalität sicher, indem Sie Tabellenänderungen mit Abfrageschlüsseln abgleichen (z. B. für Joins, GROUP BYs, PARTITION BYs). Wenn Ihre Tabellen nicht von Natur aus nach diesen Schlüsseln geclustert sind, sollten Sie Automatic Clustering aktivieren.