Anomalieerkennung (Snowflake ML-Funktionen)¶
Übersicht¶
Die Anomalieerkennung ist der Prozess des Identifizierens von Ausreißern in Daten. Mit der Anomalieerkennungsfunktion können Sie ein Modell trainieren, um Ausreißer in Ihren Zeitreihendaten zu erkennen. Ausreißer, d. h. Datenpunkte, die vom erwarteten Bereich abweichen, können einen übergroßen Einfluss auf die aus Ihren Daten abgeleiteten Statistiken und Modell haben. Das Erkennen und Entfernen von Ausreißern kann daher die Qualität Ihrer Ergebnisse verbessern.
Bemerkung
Anomaly Detection ist Teil der Snowflake-Suite von Business-Analyse-Tools, die auf maschinellem Lernen basieren.
Das Erkennen von Ausreißern kann auch nützlich sein, um den Ursprung von Problemen oder von Abweichungen in Prozessen zu ermitteln, wenn die Ursachen nicht offensichtlich sind. Beispiel:
Feststellen, seit wann ein bestimmtes Problem mit Ihrer Protokollierungs-Pipeline auftritt.
Identifizieren der Tage, an denen Ihre Snowflake-Computekosten höher als erwartet waren.
Die Anomalieerkennung funktioniert entweder mit Einzelreihen- oder Mehrreihendaten. Mehrreihendaten repräsentieren mehrere unabhängige Ereignisstränge. Wenn Sie z. B. Verkaufsdaten für mehrere Filialen haben, können die Verkäufe jeder Filiale separat mit einem einzigen Modell auf Grundlage des Bezeichners der Filiale überprüft werden.
Die Daten müssen Folgendes enthalten:
Eine Spalte für Zeitstempel
Eine Zielspalte, die zu jedem Zeitstempel eine relevante Messgröße repräsentiert.
Bemerkung
Idealerweise weisen die Trainingsdaten für ein Modell zur Anomalienerkennung Zeitschritte in gleichmäßigen Abständen (z. B. täglich) auf. Das Modelltraining kann jedoch mit Daten aus der realen Welt umgehen, bei denen Zeitschritte fehlen, doppelt vorhanden sind oder falsch ausgerichtet sind. Weitere Informationen dazu finden Sie unter Der Umgang mit Daten aus der realen in der Zeitreihenprognose.
Um Ausreißer in Zeitreihendaten zu erkennen, verwenden Sie die in Snowflake integrierte Klasse ANOMALY_DETECTION (SNOWFLAKE.ML). Gehen Sie dabei wie folgt vor:
Erstellen Sie ein Anomalieerkennungsobjekt, indem Sie eine Referenz auf die Trainingsdaten übergeben.
Dieses Objekt passt ein Modell an die von Ihnen bereitgestellten Trainingsdaten an. Das Modell ist ein Objekt auf Schemaebene.
Rufen Sie mit diesem Anomalieerkennungsmodell-Objekt die Methode <Name_des_Modells>!DETECT_ANOMALIES zum Erkennen von Anomalien auf, und übergeben Sie dabei eine Referenz auf die zu analysierenden Daten.
Die Methode verwendet das Modell, um Ausreißer in den Daten zu identifizieren.
Die Anomalieerkennung ist eng mit Prognosen verbunden. Das Anomalieerkennungsmodell erstellt eine Prognose für denselben Zeitraum wie die Daten, die Sie auf Anomalien überprüfen, und vergleicht dann die tatsächlichen Daten mit der Prognose, um mögliche Ausreißer zu identifizieren.
Wichtig
Rechtlicher Hinweis. Diese Funktion von Snowflake ML wird von Technologien des maschinellen Lernens unterstützt. Sie allein – nicht Snowflake – entscheiden, wann und wie Sie diese Funktion verwenden. Die Machine Learning-Technologie und die bereitgestellten Ergebnisse können ungenau, unangemessen oder verzerrt sein. Snowflake stellt Ihnen Machine-Learning-Modelle zur Verfügung, die Sie in Ihren eigenen Workflows verwenden können. Entscheidungen auf der Grundlage von Ergebnissen aus Prozessen des maschinellen Lernens, einschließlich solcher, die in automatische Pipelines integriert sind, erfordern eine von Menschen durchgeführte Überwachung und Überprüfung, um sicherzustellen, dass die vom Modell generierten Inhalte korrekt sind. Snowflake stellt Algorithmen (ohne Vortraining) zur Verfügung, und Sie sind für die Daten verantwortlich, die Sie dem Algorithmus zur Verfügung stellen (z. B. für Training und Inferenz), sowie für die Entscheidungen, die Sie anhand der Ergebnisse des Modells treffen. Abfragen für dieses Feature oder diese Funktion werden wie jede andere SQL-Abfrage behandelt und können als Metadaten betrachtet werden.
Metadaten. Wenn Sie Snowflake ML-Funktionen verwenden, protokolliert Snowflake allgemeine Fehlermeldungen, die von einer ML-Funktion zurückgegeben werden. Diese Fehlerprotokolle helfen uns, auftretende Probleme zu beheben und diese Funktionen zu verbessern, um unser Angebot für Sie zu optimieren.
Weitere Informationen dazu finden Sie unter Snowflake AI Trust and Safety FAQ.
Allgemeine Informationen zum Algorithmus zur Anomalieerkennung¶
Der Anomalieerkennungsalgorithmus wird von einem Gradient-Boosting-Modul (GBM) unterstützt. Wie ein ARIMA-Modell verwendet es eine Transformation aus Differenzbildung (Differenzierung), um Daten mit einem nichtstationären Trend zu modellieren, und verwendet autoregressive Lags der historischen Zieldaten als Modellvariablen.
Darüber hinaus verwendet der Algorithmus gleitende Durchschnitte historischer Zieldaten, um Trends vorherzusagen, und erstellt aus den Zeitstempeldaten automatisch zyklische Kalendervariablen (z. B. Wochentag und Woche des Jahres).
Sie können Modelle nur mit historischen Ziel- und Zeitstempeldaten anpassen, oder Sie können exogene Daten (Variablen) einbeziehen, die den Zielwert beeinflusst haben könnten. Die exogenen Variablen können numerisch oder kategorisch sein, und sie können möglicherweise auch NULL sein (Zeilen, die für exogene Variablen NULL-Werte enthalten, werden nicht gelöscht).
Der Algorithmus verlässt sich beim Training auf kategorialen Variablen nicht auf One-Hot-Codierung, sodass Sie kategoriale Daten mit vielen Dimensionen (hohe Kardinalität) verwenden können.
Wenn Ihr Modell exogene Variablen enthält, müssen Sie beim Erkennen von Anomalien Werte für diese Variablen zu Zeitpunkten in der Zukunft angeben. Geeignete exogene Variablen könnten Wetterinformationen (Temperatur, Niederschlag), unternehmensspezifische Informationen (historische und geplante Betriebsferien, Werbekampagnen, Veranstaltungstermine) oder andere externe Faktoren sein, von denen Sie glauben, dass sie zur Vorhersage Ihrer Zielvariablen beitragen können.
Optional können einzelne historische Zeilen mithilfe einer separaten booleschen Spalte als anomal oder nicht anomal gekennzeichnet werden.
Ein Vorhersageintervall ist ein geschätzter Wertebereich innerhalb einer Ober- und einer Untergrenze, in den ein bestimmter Prozentsatz der Daten wahrscheinlich fallen wird. Ein Wert von 0,99 bedeutet zum Beispiel, dass 99 % der Daten wahrscheinlich innerhalb des Intervalls liegen. Das Anomalieerkennungsmodell identifiziert alle Daten, die außerhalb des Vorhersageintervalls liegen, als Anomalie. Sie können ein Vorhersageintervall angeben oder den Standardwert von 0,99 verwenden. Sie können diesen Wert sehr nahe an 1,0 festlegen, wie 0,9999 oder sogar noch näher.
Wichtig
Von Zeit zu Zeit kann Snowflake den Algorithmus zur Anomalieerkennung verfeinern. Solche Verbesserungen werden im Rahmen des regulären Snowflake Release-Prozesses eingeführt. Sie können nicht zu einer früheren Version des Features zurückkehren, aber Modelle, die Sie mit einer früheren Version erstellt haben, verwenden weiterhin diese Version für die Anomalieerkennung.
Einschränkungen¶
Sie können den Algorithmus zur Anomalieerkennung weder auswählen noch anpassen. Insbesondere bietet der Algorithmus keine Parameter, um Trend, Saisonalität oder saisonale Amplituden zu überschreiben; diese werden aus den Daten abgeleitet.
Die Mindestanzahl von Zeilen für den Hauptalgorithmus zur Anomalieerkennung beträgt 12 pro Zeitreihe. Bei Zeitreihen mit 2 bis 11 Beobachtungen führt die Anomalieerkennung zu einem „naiven“ Ergebnis, bei dem alle vorhergesagten Werte gleich dem letzten beobachteten Zielwert sind. Bei der beschrifteten Anomalieerkennung entspricht die Anzahl der verwendeten Beobachtungen der Anzahl der Zeilen, in denen die Beschriftungsspalte „false“ ist.
Die minimal akzeptable Granularität der Daten ist eine Sekunde. (Die Zeitstempel dürfen nicht weniger als eine Sekunde auseinanderliegen.)
Die Mindestgranularität der saisonalen Komponenten beträgt eine Minute. (Die Funktion kann keine zyklischen Muster bei kleineren Zeitdeltas erkennen.)
Die „Saisonlänge“ der autoregressiven Features ist an die Eingabefrequenz gebunden (24 für stündliche Daten, 7 für tägliche Daten usw.).
Einmal trainierte Anomalieerkennungsmodelle sind unveränderlich. Sie können bestehende Modelle nicht mit neuen Daten aktualisieren, sondern Sie müssen ein völlig neues Modell trainieren. Modelle unterstützen keine Versionierung. Im Allgemeinen sollten Sie das Modell in regelmäßigen Abständen neu trainieren, z. B. einmal täglich, einmal pro Woche oder einmal pro Monat, je nachdem, wie häufig Sie neue Daten erhalten, damit das Modell mit den sich ändernden Trends Schritt halten kann.
Dieses Feature erkennt nur Anomalien in den Testdaten; es kann keine Anomalien in den Trainingsdaten erkennen. Außerdem müssen die Zeitstempel in den Testdaten alle größer sein als die Zeitstempel in den Trainingsdaten. Stellen Sie sicher, dass die Trainingsdaten einen typischen Zeitraum ohne tatsächliche Ausreißer abdecken, oder kennzeichnen (beschriften) Sie bekannte Ausreißer mithilfe einer Boolean-Spalte.
Sie können Modelle weder klonen noch über Rollen oder Konten hinweg freigeben. Beim Klonen eines Schemas oder einer Datenbank werden Modellobjekte übersprungen.
Sie können Instanzen der ANOMALY_DETECTION-Klasse nicht replizieren.
Vorbereiten der Anomalieerkennung¶
Bevor Sie die Anomalieerkennung nutzen können, müssen Sie Folgendes tun:
Wählen Sie ein virtuelles Warehouse aus, in dem Sie Ihre Modelle trainieren und ausführen können.
Erteilen Sie die Berechtigungen zum Erstellen von Anomalieerkennungsobjekten.
Sie können auch Ihren Suchpfad ändern, um SNOWFLAKE.ML einzuschließen.
Auswählen eines virtuellen Warehouses¶
Ein virtuelles Warehouse von Snowflake stellt die Computeressourcen für das Training und die Verwendung Ihrer Machine Learning-Modelle für dieses Feature bereit. In diesem Abschnitt finden Sie allgemeine Hinweise zur Auswahl der optimalen Größe und des passenden Warehouse-Typs für diesen Zweck. Der Schwerpunkt liegt dabei auf dem Trainingsschritt (dem zeit- und speicherintensivsten Teil des Prozesses).
Training mit Daten einer einzelnen Zeitreihe¶
Bei Modellen, die mit Daten einzelner Zeitreihen trainiert werden, sollten Sie den Warehouse-Typ auf Grundlage des Umfangs Ihrer Trainingsdaten auswählen. Standard-Warehouses unterliegen einer niedrigeren Snowpark-Speichergrenze und eignen sich besser für Trainingsjobs mit weniger Zeilen oder exogenen Features. Wenn Ihre Trainingsdaten keine exogenen Features enthalten und das Datenset höchstens 5 Millionen Zeilen umfasst, können Sie zum Trainieren ein Standard-Warehouse verwenden. Wenn Ihre Trainingsdaten fünf oder mehr exogene Features verwenden, ist die maximale Zeilenanzahl niedriger. Andernfalls empfiehlt Snowflake für größere Trainingsjobs die Verwendung eines Snowpark-optimierten Warehouses.
Im Allgemeinen führt bei Daten einer einzelnen Zeitreihe eine größere Warehouse-Größe nicht zu schnelleren Trainingszeiten oder höheren Speichergrenzen. Als grobe Faustregel kann gelten, dass die Trainingszeit proportional zur Anzahl der Zeilen in der Zeitreihe ist. Auf einem XS-Standard-Warehouse dauert das Training eines Datensets mit 100.000 Zeilen bei ausgeschalteter Auswertung (CONFIG_OBJECT => {'evaluate': False}) beispielsweise etwa 60 Sekunden, während das Training eines Datensets mit 1.000.000 Zeilen etwa 125 Sekunden dauert. Wenn die Auswertung aktiviert ist, erhöht sich die Trainingszeit ungefähr linear um die Anzahl der verwendeten Splits.
Um optimale Performance zu erzielen, empfiehlt Snowflake die Verwendung eines dedizierten Warehouses, mit dem Sie Ihr Modell trainieren können, ohne dass parallel andere Workloads ausgeführt werden.
Training mit Daten aus mehreren Zeitreihen¶
Wählen Sie wie bei Daten aus einzelnen Zeitreihen den Warehouse-Typ auf Grundlage der Anzahl der Zeilen Ihrer größten Zeitreihe. Wenn Ihre größte Zeitreihe mehr als 5 Millionen Zeilen enthält, wird der Trainingsjob wahrscheinlich die Speichergrenzen eines Standard-Warehouses überschreiten.
Im Gegensatz zu Daten einzelner Zeitreihen werden Daten mehrere Zeitreihen bei größeren Warehouse-Größen wesentlich schneller verarbeitet. Die folgenden Datenpunkte können Sie bei Ihrer Auswahl unterstützen. Wie zuvor wurden alle diese Zeiten mit deaktivierter Auswertung ermittelt.
Typ und Größe des Warehouses |
Anzahl der Zeitreihen |
Anzahl der Zeilen pro Zeitreihe |
Trainingszeit (Sekunden) |
|---|---|---|---|
Standard-XS |
1 |
100,000 |
60 Sekunden |
Standard-XS |
10 |
100,000 |
204 Sekunden |
Standard-XS |
100 |
100,000 |
720 Sekunden |
Standard-XL |
10 |
100,000 |
104 Sekunden |
Standard-XL |
100 |
100,000 |
211 Sekunden |
Standard-XL |
1000 |
100,000 |
840 Sekunden |
Snowpark-optimiertes XL |
10 |
100,000 |
65 Sekunden |
Snowpark-optimiertes XL |
100 |
100,000 |
293 Sekunden |
Snowpark-optimiertes XL |
1000 |
100,000 |
831 Sekunden |
Erkennen von Anomalien¶
Beim Inferenzschritt dauert die Verarbeitung von 100 Zeilen des Eingabe-Datensets unabhängig von der Größe des Warehouses etwa 1 Sekunde.
Erteilen von Berechtigungen zum Erstellen von Anomalieerkennungsobjekten¶
Das Training eines Anomalieerkennungsmodells führt zu einem Objekt auf Schemaebene. Daher muss die Rolle, mit der Sie Modelle erstellen, über die Berechtigung CREATE SNOWFLAKE.ML.ANOMALY_DETECTION für das Schema verfügen, in dem das Modell erstellt wird, damit das Modell dort gespeichert werden kann. Diese Berechtigung ist vergleichbar mit anderen Schemaberechtigungen wie CREATE TABLE oder CREATE VIEW.
Snowflake empfiehlt, eine Rolle mit dem Namen analyst zu erstellen, die von Personen verwendet wird, deren Aufgabe das Erkennen von Anomalien ist.
Im folgenden Beispiel ist die Rolle admin der Eigentümer des Schemas admin_db.admin_schema. Die Rolle analyst muss in der Lage sein, Modelle in diesem Schema zu erstellen.
USE ROLE admin;
GRANT USAGE ON DATABASE admin_db TO ROLE analyst;
GRANT USAGE ON SCHEMA admin_schema TO ROLE analyst;
GRANT CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema TO ROLE analyst;
Um dieses Schema verwenden zu können, wird einem Benutzer die Rolle analyst zugewiesen:
USE ROLE analyst;
USE SCHEMA admin_db.admin_schema;
Wenn die Rolle analyst über die Berechtigung CREATE SCHEMA in der Datenbank analyst_db verfügt, kann die Rolle ein neues Schema analyst_db.analyst_schema erstellen und in diesem Schema Anomalieerkennungsmodelle erstellen:
USE ROLE analyst;
CREATE SCHEMA analyst_db.analyst_schema;
USE SCHEMA analyst_db.analyst_schema;
Um einer Rolle die Berechtigung zum Erstellen eines Modells für das Schema zu entziehen, verwenden Sie REVOKE <Berechtigungen> … FROM ROLE:
REVOKE CREATE SNOWFLAKE.ML.ANOMALY_DETECTION ON SCHEMA admin_db.admin_schema FROM ROLE analyst;
Einrichten der Daten für die Beispiele¶
Die Beispiele in den folgenden Abschnitten verwenden ein Beispiel-Datenset, das tägliche Umsätze für Artikel in verschiedenen Filialen sowie tägliche Wetterdaten (Luftfeuchtigkeit und Temperatur) enthält. Das Datenset enthält auch eine Spalte, die angibt, ob der Tag ein Feiertag ist.
Führen Sie die folgenden Anweisungen aus, um eine Tabelle namens
historical_sales_datazu erstellen, die die Trainingsdaten für das Modell enthält:
CREATE OR REPLACE TABLE historical_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, label BOOLEAN, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO historical_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-01'), 2.0, false, 50, 0.3, 'new year'), (1, 'jacket', to_timestamp_ntz('2020-01-02'), 3.0, false, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-03'), 5.0, false, 54, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-04'), 30.0, true, 54, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-05'), 8.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-06'), 6.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-07'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-08'), 2.7, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-09'), 8.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-10'), 9.2, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-11'), 4.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-12'), 7.0, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-13'), 3.6, false, 55, 0.2, null), (1, 'jacket', to_timestamp_ntz('2020-01-14'), 8.0, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-01'), 3.4, false, 50, 0.3, 'new year'), (2, 'umbrella', to_timestamp_ntz('2020-01-02'), 5.0, false, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-03'), 4.0, false, 54, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-04'), 5.4, false, 54, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-05'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-06'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-07'), 3.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-08'), 5.6, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-09'), 7.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-10'), 8.2, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-11'), 3.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-12'), 5.7, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-13'), 6.3, false, 55, 0.2, null), (2, 'umbrella', to_timestamp_ntz('2020-01-14'), 2.9, false, 55, 0.2, null);
Führen Sie die folgenden Anweisungen aus, um eine Tabelle namens
new_sales_datazu erstellen, die die zu analysierenden Daten enthält:
CREATE OR REPLACE TABLE new_sales_data ( store_id NUMBER, item VARCHAR, date TIMESTAMP_NTZ, sales FLOAT, temperature NUMBER, humidity FLOAT, holiday VARCHAR); INSERT INTO new_sales_data VALUES (1, 'jacket', to_timestamp_ntz('2020-01-16'), 6.0, 52, 0.3, null), (1, 'jacket', to_timestamp_ntz('2020-01-17'), 20.0, 53, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-16'), 3.0, 52, 0.3, null), (2, 'umbrella', to_timestamp_ntz('2020-01-17'), 70.0, 53, 0.3, null);
Trainieren, Verwenden, Anzeigen, Löschen und Aktualisieren von Modellen¶
Verwenden Sie CREATE SNOWFLAKE.ML.ANOMALY_DETECTION, um ein Modell zu erstellen und zu trainieren. Das Modell wird mit dem von Ihnen bereitgestellten Datenset trainiert.
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION mydetector(...);
Umfassende Informationen zum Konstruktor SNOWFLAKE.ML.ANOMALY_DETECTION finden Sie unter ANOMALY_DETECTION (SNOWFLAKE.ML). Beispiele für das Erstellen eines Modells finden Sie unter Erkennen von Anomalien.
Bemerkung
SNOWFLAKE.ML.ANOMALY_DETECTION wird mit eingeschränkten Berechtigungen ausgeführt, sodass der Konstruktor standardmäßig keinen Zugriff auf Ihre Daten hat. Sie müssen daher Tabellen und Ansichten als Referenzen übergeben, mit denen auch die Berechtigungen des Aufrufers weitergeben werden. Sie können anstelle eines Verweises auf eine Tabelle oder Ansicht auch eine Abfragereferenz angeben.
Um diesen Verweis zu erstellen, können Sie das Schlüsselwort TABLE mit dem Tabellennamen, dem Ansichtsnamen oder der Abfrage verwenden, oder Sie können die Funktion SYSTEM$REFERENCE oder SYSTEM$QUERY_REFERENCE aufrufen.
Um Anomalien zu erkennen, rufen Sie die Methode <Name_des_Modells>!DETECT_ANOMALIES des Modells auf:
CALL mydetector!DETECT_ANOMALIES(...);
Um Spalten aus der tabellarischen Ausgabe der Methode auszuwählen, können Sie die Methode in der FROM-Klausel aufrufen:
SELECT ts, forecast FROM TABLE(mydetector!DETECT_ANOMALIES(...));
Um eine Liste Ihrer Modelle anzuzeigen, verwenden Sie den Befehl SHOW SNOWFLAKE.ML.ANOMALY_DETECTION:
SHOW SNOWFLAKE.ML.ANOMALY_DETECTION;
Um ein Modell zu entfernen, verwenden Sie den Befehl DROP SNOWFLAKE.ML.ANOMALY_DETECTION:
DROP SNOWFLAKE.ML.ANOMALY_DETECTION <name>;
Um ein Modell zu aktualisieren, löschen Sie es und trainieren ein neues Modell. Modelle sind unveränderlich und können nicht direkt aktualisiert werden.
Erkennen von Anomalien¶
In den folgenden Abschnitten erfahren Sie, wie Sie mithilfe der Anomalieerkennung Ausreißer erkennen können. In den folgenden Abschnitten finden Sie Beispiele für das Erkennen von Anomalien in einer einzelnen Zeitreihe, in mehreren Zeitreihen, mit und ohne exogene Variablen, mit einem benutzerdefinierten Vorhersageintervall und mit einem überwachten Ansatz (mit beschrifteten Daten).
Erkennen von Anomalien in einer einzelnen Zeitreihe (nicht überwacht)
Trainieren eines Anomalieerkennungsmodells mit beschrifteten Daten
Festlegen des Vorhersageintervalls für die Anomalieerkennung
Erkennen von Anomalien in einer einzelnen Zeitreihe (nicht überwacht)¶
So können Sie Anomalien in Ihren Daten erkennen:
Trainieren Sie ein Anomalieerkennungsmodell mithilfe historischer Daten.
Verwenden Sie das trainierte Anomalieerkennungsmodell, um Anomalien in historischen oder projizierten Daten zu erkennen. Die Zeitstempel in den Testdaten müssen chronologisch den Zeitstempeln in den Trainingsdaten folgen. Sie benötigen mindestens 2 Datenpunkte, um ein Modell zu trainieren, mindestens 12 Datenpunkte für nicht naive Ergebnisse und mindestens 60 Datenpunkte für nichtlineare Ergebnisse.
Weitere Informationen zu den Parametern, die beim Erstellen und Verwenden eines Modells verwendet werden, finden Sie unter ANOMALY_DETECTION (SNOWFLAKE.ML).
Trainieren eines Anomalieerkennungsmodells¶
Um ein Modellobjekt zur Anomalieerkennung zu erstellen, führen Sie den Befehl CREATE SNOWFLAKE.ML.ANOMALY_DETECTION aus.
Angenommen, Sie möchten die Verkäufe von Jacken in einer Filiale mit store_id = 1 analysieren:
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die Daten für das Trainieren des Anomalieerkennungsmodells zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_training_datazu erstellen, die das Datum und die Verkaufsinformationen enthält:CREATE OR REPLACE VIEW view_with_training_data AS SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket';
Erstellen Sie ein Anomalieerkennungsobjekt, und trainieren Sie dessen Modell anhand der Daten in dieser Ansicht.
Führen Sie für dieses Beispiel den Befehl CREATE SNOWFLAKE.ML.ANOMALY_DETECTION aus, um ein Anomalieerkennungsobjekt namens
basic_modelzu erstellen. Übergeben Sie die folgenden Argumente:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(view_with_training_data), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
In diesem Beispiel wird eine Referenz auf eine Ansicht als INPUT_DATA-Argument übergeben. Das Beispiel verwendet das Schlüsselwort TABLE zum Erstellen der Referenz. Alternativ können Sie SYSTEM$REFERENCE aufrufen, um die Referenz zu erstellen.
Der Zweck der Beschriftungsspalte ist es, dem Modell mitzuteilen, welche Zeilen bekannte Anomalien sind. Da bei diesem Beispiel ein nicht überwachtes Training verwendet wird, benötigen Sie keine Beschriftungsspalte. Übergeben Sie eine leere Zeichenfolge als Namen für die Beschriftungsspalte.
Tipp
Wenn Sie für das INPUT_DATA-Argument keine Ansicht erstellen möchten, können Sie eine Referenz zu einer Abfrage übergeben, die eine SELECT-Anweisung verwendet, die wiederum als Inline-Ansicht dient.
Sie können das Schlüsselwort TABLE verwenden, um diese Abfragereferenz zu erstellen. Beispiel:
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION basic_model( INPUT_DATA => TABLE(SELECT date, sales FROM historical_sales_data WHERE store_id=1 AND item='jacket'), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => '');
Maskieren Sie alle einfachen Anführungszeichen und andere Sonderzeichen mit einem Backslash.
Alternativ zur Verwendung des Schlüsselworts TABLE können Sie SYSTEM$QUERY_REFERENCE aufrufen, um die Abfragereferenz zu erstellen.
Wenn der Befehl erfolgreich ausgeführt wurde, wird eine Meldung angezeigt, dass Ihre Anomalieerkennungsinstanz erfolgreich erstellt wurde:
+--------------------------------------------+ | status | +--------------------------------------------+ | Instance basic_model successfully created. | +--------------------------------------------+
Verwenden eines Anomalieerkennungsmodells zum Erkennen von Anomalien¶
Durch das Erstellen des Anomalieerkennungsobjekts wird das Modell trainiert und im Schema gespeichert. Um das Anomalieerkennungsobjekt zum Erkennen von Anomalien zu verwenden, rufen Sie die Methode <Name_des_Modells>!DETECT_ANOMALIES des Objekts auf. Beispiel:
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die Daten für die Analyse zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_data_to_analyzezu erstellen, die das Datum und die Verkaufsinformationen enthält:CREATE OR REPLACE VIEW view_with_data_to_analyze AS SELECT date, sales FROM new_sales_data WHERE store_id=1 and item='jacket';
Rufen Sie mit dem Objekt für das Anomalieerkennungsmodell (in diesem Beispiel
basic_model, das Sie zuvor erstellt haben) die Methode <Name_des_Modells>!DETECT_ANOMALIES auf:CALL basic_model!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
Die Methode gibt eine Tabelle zurück, die Zeilen für die Daten enthält, die sich derzeit in der Ansicht
view_with_data_to_analyzebefinden, sowie die Vorhersage aus der Anomalieerkennung. Eine Beschreibung der Spalten in dieser Tabelle finden Sie unter Rückgabewerte.
Ausgabe
Die Ergebnisse wurden zur besseren Lesbarkeit gerundet.
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 4.6 | -7.185885251 | 16.385885251 | False | 0.6201873452 | 0.3059728606 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 9 | -2.785885251 | 20.785885251 | False | 0.9918932208 | 2.404072476 |
+--------+-------------------------+----+----------+--------------+--------------+------------+--------------+--------------|
Um Ihre Ergebnisse direkt in einer Tabelle zu speichern, verwenden Sie CREATE TABLE … AS SELECT … und rufen Sie die Methode DETECT_ANOMALIES in der FROM-Klausel auf:
CREATE TABLE my_anomalies AS
SELECT * FROM TABLE(basic_model!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME =>'date',
TARGET_COLNAME => 'sales'
));
Wie im obigen Beispiel gezeigt, lassen Sie beim Aufruf der Methode den Befehl CALL weg. Stattdessen setzen Sie den Aufruf in Klammern, denen das Schlüsselwort TABLE vorangestellt ist.
Trainieren eines Anomalieerkennungsmodells mit beschrifteten Daten¶
Das Ergebnis aus dem Modell im vorherigen Beispiel scheint ungenau zu sein. Mögliche Gründe sind:
Das Anomalieerkennungsmodell wurde mit sehr wenigen Eingabedaten trainiert.
Eine größere Anzahl von Jacken (30) wurde am „2020-01-03“ verkauft. Dadurch wurden die Vorhersagen nach oben verzerrt und das Vorhersageintervall vergrößert.
Um die Genauigkeit des Anomalieerkennungsmodells zu verbessern, können Sie entweder mehr Trainingsdaten einbeziehen oder die Trainingsdaten beschriften (überwachtes Training). Beschriftete Trainingsdaten haben eine zusätzliche boolesche Spalte, die angibt, ob es sich bei jeder Zeile um eine bekannte Anomalie handelt. Das Beschriften kann dem Anomalieerkennungsmodell helfen, eine Überanpassung an bekannte Anomalien in den Trainingsdaten zu vermeiden.
Um beschriftete Daten in die Trainingsdaten aufzunehmen, geben Sie die Spalte mit der Beschriftung im Konstruktorargument LABEL_COLNAME des Befehls CREATE SNOWFLAKE.ML.ANOMALY_DETECTION an. Beispiel:
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die Beschriftungen mit den Trainingsdaten zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_labeled_datazu erstellen, die in der Spaltelabeldie Beschriftungen enthält:CREATE OR REPLACE VIEW view_with_labeled_data_for_training AS SELECT date, sales, label FROM historical_sales_data WHERE store_id=1 and item='jacket';
Erstellen Sie ein Objekt für das Anomalieerkennungsmodell, und trainieren Sie das Modell anhand der Daten in dieser Ansicht.
Führen Sie für dieses Beispiel den Befehl CREATE SNOWFLAKE.ML.ANOMALY_DETECTION aus, um ein Anomalieerkennungsobjekt namens
model_trained_with_labeled_datazu erstellen. Mit der folgenden Anweisung wird das Anomalieerkennungsobjekt erstellt:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data( INPUT_DATA => TABLE(view_with_labeled_data_for_training), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Rufen Sie mit diesem neuen Anomalieerkennungsmodell die Methode <Name_des_Modells>!DETECT_ANOMALIES auf, und übergeben Sie dabei dieselben Argumente, die Sie unter Erkennen von Anomalien in einer einzelnen Zeitreihe (nicht überwacht) verwendet haben:
CALL model_trained_with_labeled_data!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_to_analyze), TIMESTAMP_COLNAME =>'date', TARGET_COLNAME => 'sales' );
Die Methode gibt eine Tabelle zurück, die Zeilen für die Daten enthält, die sich derzeit in der Ansicht
view_with_data_to_analyzebefinden, sowie die Vorhersage aus der Anomalieerkennung. Eine Beschreibung der Spalten in dieser Tabelle finden Sie unter Rückgabewerte.
Ausgabe
Die Ergebnisse wurden zur besseren Lesbarkeit gerundet.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.82 | 11.18 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.39 | 12.33 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
Festlegen des Vorhersageintervalls für die Anomalieerkennung¶
Beim Erkennen von Anomalien können unterschiedliche Empfindlichkeitsstufen verwendet werden. Um den Prozentsatz der Beobachtungen anzugeben, die als Anomalien eingestuft werden sollen, erstellen Sie ein OBJECT, das Konfigurationseinstellungen für <Name_des_Modells>!DETECT_ANOMALIES enthält, und setzen Sie dann den Schlüssel prediction_interval auf den Prozentsatz der Beobachtungen, die als Anomalien markiert werden sollen.
Um dieses Objekt zu erstellen, können Sie entweder eine Objektkonstante oder die Funktion OBJECT_CONSTRUCT verwenden.
Wenn Sie dann die Methode <Name_des_Modells>!DETECT_ANOMALIES aufrufen, geben Sie dieses Objekt als CONFIG_OBJECT-Argument an.
Standardmäßig ist der mit dem Schlüssel „prediction_interval“ verknüpfte Wert auf 0,99 eingestellt, was bedeutet, dass etwa 1 % der Daten als Anomalien markiert werden. Sie können einen Wert zwischen 0 und 1 angeben:
Um weniger Beobachtungen als Anomalien zu markieren, geben Sie einen höheren Wert für
prediction_intervalan.Um mehr Beobachtungen als Anomalien zu markieren, reduzieren Sie den Wert für
prediction_interval.
Im folgenden Beispiel wird die Anomalieerkennung strenger konfiguriert, indem prediction_interval auf 0,995 gesetzt wird. In dem Beispiel wird auch das auf beschrifteten Daten trainierte Modell (das Sie unter Trainieren eines Anomalieerkennungsmodells mit beschrifteten Daten eingerichtet haben) mit der Ansicht verwendet, die die zu analysierenden Daten enthält (die Sie unter Erkennen von Anomalien in einer einzelnen Zeitreihe (nicht überwacht) eingerichtet haben).
CALL model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.995}
);
Mit dieser Anweisung wird eine Tabelle erstellt, die Zeilen für die Daten enthält, die sich derzeit in der Ansicht view_with_data_to_analyze befinden. Jede Zeile enthält eine Spalte mit der Vorhersage aus der Anomalieerkennung. Es zeigt sich, dass das Ergebnis dieses Modells genauer ist als das Beispiel ohne Beschriftung.
Ausgabe
Die Ergebnisse wurden zur besseren Lesbarkeit gerundet.
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
| SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE |
+--------|-------------------------+----+----------+---------------+--------------+------------+--------------+------------|
| NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 |
| NULL | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 |
+--------+-------------------------+----+----------+---------------+--------------+------------+--------------+------------+
Einbeziehen zusätzlicher Spalten in die Analyse¶
Sie können zusätzliche Spalten in die Daten für Training und Analyse aufnehmen (z. B. temperature, weather, is_black_friday), wenn diese Spalten Ihnen helfen können, das Identifizieren echter Anomalien zu verbessern.
So beziehen Sie neue Spalten in die Analyse ein:
Erstellen Sie für die Trainingsdaten eine Ansicht, oder entwerfen Sie eine Abfrage, die die neuen Spalten enthält, und erstellen Sie ein neues Anomalieerkennungsobjekt, indem Sie eine Referenz auf diese Ansicht bzw. Abfrage übergeben.
Erstellen Sie für die zu analysierenden Daten eine Ansicht, oder entwerfen Sie eine Abfrage, die die neuen Spalten enthält, und übergeben Sie der Methode <Name_des_Modells>!DETECT_ANOMALIES eine Referenz auf diese Ansicht bzw. Abfrage.
Das Anomalieerkennungsobjekt erkennt und verwendet die zusätzlichen Spalten automatisch.
Bemerkung
Für die Ansicht oder Abfrage, die Sie zum Ausführen des Befehls CREATE SNOWFLAKE.ML.ANOMALY_DETECTION und zum Aufrufen der Methode <Name_des_Modells>!DETECT_ANOMALIES verwenden, müssen Sie jeweils denselben Satz zusätzlicher Spalten bereitstellen. Wenn die Spalten in den Trainingsdaten, die dem Befehl übergeben wurden, und die Spalten in den Analysedaten, die der Funktion übergeben wurden, nicht übereinstimmen, tritt ein Fehler auf.
Angenommen, Sie möchten die Spalten temperature, humidity und holiday hinzufügen:
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die Trainingsdaten mit diesen zusätzlichen Spalten zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_training_data_extra_columnszu erstellen:CREATE OR REPLACE VIEW view_with_training_data_extra_columns AS SELECT date, sales, label, temperature, humidity, holiday FROM historical_sales_data WHERE store_id=1 AND item='jacket';
Erstellen Sie ein Objekt für das Anomalieerkennungsmodell, und trainieren Sie das Modell anhand der Daten in dieser Ansicht.
Führen Sie für dieses Beispiel den Befehl CREATE SNOWFLAKE.ML.ANOMALY_DETECTION aus, um ein Anomalieerkennungsobjekt namens
model_with_additional_columnszu erstellen, und übergeben Sie dabei eine Referenz auf die neue Ansicht:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_with_additional_columns( INPUT_DATA => TABLE(view_with_training_data_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die zu analysierenden Daten mit diesen zusätzlichen Spalten zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_data_for_analysis_extra_columnszu erstellen:CREATE OR REPLACE VIEW view_with_data_for_analysis_extra_columns AS SELECT date, sales, temperature, humidity, holiday FROM new_sales_data WHERE store_id=1 AND item='jacket';
Rufen Sie mit diesem neuen Anomalieerkennungsobjekt die Methode <Name_des_Modells>!DETECT_ANOMALIES auf, und übergeben Sie dabei die neue Ansicht:
CALL model_with_additional_columns!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_extra_columns), TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.93} );
Mit dieser Anweisung wird eine Tabelle erstellt, die Zeilen für die Daten enthält, die sich derzeit in der Ansicht
view_with_data_for_analysis_extra_columnsbefinden, sowie die Vorhersage aus der Anomalieerkennung. Das Ausgabeformat ist dasselbe wie bei den Befehlen, die Sie zuvor ausgeführt haben.
Ausgabe
Die Ergebnisse wurden zur besseren Lesbarkeit gerundet.
+--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | +--------|-------------------------+----+----------+-------------+--------------+------------+--------------+------------| | NULL | 2020-01-16 00:00:00.000 | 6 | 6 | 2.34 | 9.64 | False | 0.5 | 0 | | NULL | 2020-01-17 00:00:00.000 | 20 | 6 | 1.56 | 10.451 | True | 0.99 | 5.70 | +--------+-------------------------+----+----------+-------------+--------------+------------+--------------+------------+
Erkennen von Anomalien in mehreren Zeitreihen¶
In den vorangegangenen Abschnitten wurden Beispiele für das Erkennen von Anomalien in einer einzelnen Zeitreihe bereitgestellt. In diesen Beispielen wurden Anomalien für den Verkauf eines Typs von Artikel (Jacken) in einer Filiale (Filial-ID 1) markiert. So erkennen Sie Anomalien für mehrere Zeitreihen gleichzeitig (z. B. für mehrere Kombinationen von Artikeln und Filialen):
Erstellen Sie für die Trainingsdaten eine Ansicht, oder entwerfen Sie eine Abfrage, die eine Spalte enthält, die die Zeitreihe identifiziert, und erstellen Sie dann ein neues Anomalieerkennungsobjekt, indem Sie eine Referenz auf diese Ansicht bzw. Abfrage übergeben und den Namen der Zeitreihenspalte für das Argument SERIES_COLNAME angeben.
Erstellen Sie für die zu analysierenden Daten eine Ansicht, oder entwerfen Sie eine Abfrage, die die Spalte enthält, mit der die Zeitreihe identifiziert wird. Rufen Sie die Methode <Name_des_Modells>!DETECT_ANOMALIES auf, wobei Sie eine Referenz auf diese Ansicht oder Abfrage übergeben und den Namen der Zeitreihenspalte für das Argument SERIES_COLNAME angeben.
Angenommen, Sie möchten die Kombination der Spalten store_id und item verwenden, um die Zeitreihe zu identifizieren:
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die Trainingsdaten mithilfe der Zeitreihenspalte zurückgibt.
Führen Sie für dieses Beispiel den Befehl CREATE VIEW aus, um eine Ansicht mit dem Namen
view_with_training_data_multiple_serieszu erstellen, die eine Spalte mit dem Namenstore_itementhält, mit der die Zeitreihe als Kombination aus Filial-ID und Artikel identifiziert wird:CREATE OR REPLACE VIEW view_with_training_data_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, label, temperature, humidity, holiday FROM historical_sales_data;
Erstellen Sie ein Objekt für die Anomalieerkennung, und trainieren Sie das Modell anhand der Daten in dieser Ansicht.
Führen Sie für dieses Beispiel den Befehl CREATE SNOWFLAKE.ML.ANOMALY_DETECTION aus, um ein Anomalieerkennungsobjekt namens
model_for_multiple_serieszu erstellen, und übergeben Sie dabei eine Referenz auf die neue Ansicht, wobei Sie für das Argument SERIES_COLNAME den Wertstore_itemangeben:CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_for_multiple_series( INPUT_DATA => TABLE(view_with_training_data_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', LABEL_COLNAME => 'label' );
Erstellen Sie eine Ansicht, oder entwerfen Sie eine Abfrage, die die zu analysierenden Daten mit der Zeitreihenspalte zurückgibt.
In diesem Beispiel führen Sie den Befehl CREATE VIEW aus, um eine Ansicht namens
view_with_data_for_analysis_multiple_serieszu erstellen, die eine Spalte namensstore_itemfür die Zeitreihe enthält:CREATE OR REPLACE VIEW view_with_data_for_analysis_multiple_series AS SELECT [store_id, item] AS store_item, date, sales, temperature, humidity, holiday FROM new_sales_data;
Rufen Sie mit diesem neuen Anomalieerkennungsobjekt die Methode <Name_des_Modells>!DETECT_ANOMALIES auf, und übergeben Sie die neue Ansicht, wobei Sie
store_itemals SERIES_COLNAME-Argument angeben.CALL model_for_multiple_series!DETECT_ANOMALIES( INPUT_DATA => TABLE(view_with_data_for_analysis_multiple_series), SERIES_COLNAME => 'store_item', TIMESTAMP_COLNAME => 'date', TARGET_COLNAME => 'sales', CONFIG_OBJECT => {'prediction_interval':0.995} );
Mit dieser Anweisung wird eine Tabelle erstellt, die Zeilen für die Daten enthält, die sich derzeit in der Ansicht
view_with_data_for_analysis_multiple_seriesbefinden, sowie die Vorhersage aus der Anomalieerkennung. Die Ausgabe enthält die Spalte, mit der die Zeitreihe identifiziert wird.
Ausgabe
Die Ergebnisse wurden zur besseren Lesbarkeit gerundet.
+--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+ | SERIES | TS | Y | FORECAST | LOWER_BOUND | UPPER_BOUND | IS_ANOMALY | PERCENTILE | DISTANCE | |--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------| | [ | 2020-01-16 00:00:00.000 | 3 | 6.3 | 2.07 | 10.53 | False | 0.01 | -2.19 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 70 | 2.9 | -1.33 | 7.13 | True | 1 | 44.54 | | 2, | | | | | | | | | | "umbrella" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-16 00:00:00.000 | 6 | 6 | 0.36 | 11.64 | False | 0.5 | 0 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | | [ | 2020-01-17 00:00:00.000 | 20 | 6 | -0.90 | 12.90 | True | 0.99 | 5.70 | | 1, | | | | | | | | | | "jacket" | | | | | | | | | | ] | | | | | | | | | +--------------+-------------------------+----+----------+---------------+--------------+------------+---------------+--------------+
Visualisieren von Anomalien und Interpretieren der Ergebnisse¶
Verwenden Sie Snowsight, um die Ergebnisse der Anomalieerkennung zu überprüfen und zu visualisieren. Wenn Sie in Snowsight die Methode <Name_des_Modells>!DETECT_ANOMALIES aufrufen, werden die Ergebnisse in einer Tabelle unter dem Arbeitsblatt angezeigt.

Um die Ergebnisse zu visualisieren, können Sie das Diagramm-Feature von Snowsight verwenden.
Nachdem Sie die Methode <Name_des_Modells>!DETECT_ANOMALIES aufgerufen haben, wählen Sie oberhalb der Ergebnistabelle die Option Charts aus.
Führen Sie im Data-Bereich auf der rechten Seite der Tabelle Folgendes aus:
Wählen Sie die Spalte Y aus, und wählen Sie unter Aggregation die Option None aus.
Wählen Sie die Spalte TS aus, und wählen Sie unter Bucketing die Option None aus.
Fügen Sie die Spalten LOWER_BOUND und UPPER_BOUND hinzu, und wählen Sie unter Aggregation die Option None aus.
Wählen Sie Chart aus, um die initiale Visualisierung anzuzeigen.

Wählen Sie auf der rechten Seite Add Column aus, und wählen Sie dann die Spalte aus, die Sie visualisieren möchten:
LOWER_BOUND
UPPER_BOUND
IS_ANOMALY
Ergebnisse:
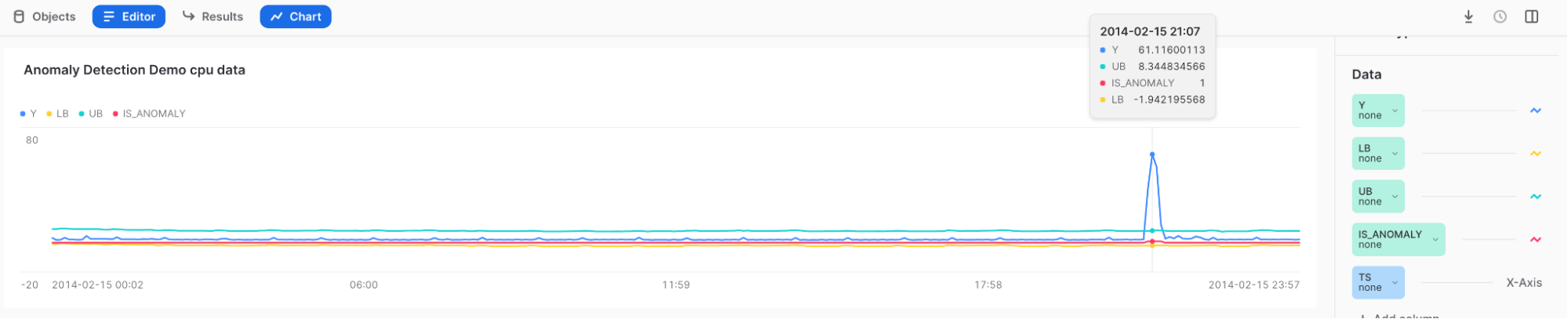
Wenn Sie den Mauszeiger über die hohe Spitze bewegen, können Sie sehen, dass Y außerhalb der oberen Grenze liegt und im Feld IS_ANOMALY mit einer 1 getaggt ist.
Tipp
Um Ihre Ergebnisse besser zu verstehen, können Sie auch Top Insights verwenden.
Automatisieren der Anomalieerkennung mithilfe von Snowflake-Aufgaben und -Alerts¶
Mit den Anomalieerkennungsfunktionen in Snowflake-Aufgaben oder -Alerts können Sie eine automatische Pipeline zur Anomalieerkennung erstellen, sodass Sie gleichzeitig das Modell neu trainieren und Ihre Daten auf Anomalien überwachen können.
Wiederkehrendes Training mit Snowflake-Aufgaben¶
Sie können Ihr Modell mithilfe von Snowflake-Aufgaben trainieren, damit es die aktuellen Daten widerspiegelt.
Um eine Aufgabe zu erstellen, die das Anomalieerkennungsobjekt stündlich aktualisiert, führen Sie die folgende Anweisung aus, wobei Sie your_warehouse_name durch den Namen Ihres Warehouses ersetzen:
CREATE OR REPLACE TASK ad_model_retrain_task
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '60 MINUTE'
AS
EXECUTE IMMEDIATE
$$
BEGIN
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION model_trained_with_labeled_data(
INPUT_DATA => TABLE(view_with_labeled_data_for_training),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => 'label'
);
END;
$$;
Standardmäßig sind neu erstellte Aufgaben im Modus „Angehalten“.
Um die Aufgabe fortzusetzen, führen Sie den Befehl ALTER TASK … RESUME aus:
ALTER TASK ad_model_retrain_task RESUME;
Um die Aufgabe anzuhalten, führen Sie den Befehl ALTER TASK … SUSPEND aus:
ALTER TASK ad_model_retrain_task SUSPEND;
Überwachen mit Snowflake-Aufgaben¶
Sie können Snowflake-Aufgaben auch verwenden, um Ihre Daten in regelmäßigen Abständen zu überwachen.
Erstellen Sie zuerst eine Tabelle, in der die Ergebnisse der Anomalieerkennung gespeichert werden:
CREATE OR REPLACE TABLE anomaly_res_table (
ts TIMESTAMP_NTZ, y FLOAT, forecast FLOAT, lower_bound FLOAT, upper_bound FLOAT,
is_anomaly BOOLEAN, percentile FLOAT, distance FLOAT);
Erstellen Sie eine Aufgabe, mit der die Ergebnisse einer sich wiederholenden Anomalieerkennungsoperation in der Tabelle gespeichert werden: In diesem Beispiel wird der Parameter WAREHOUSE auf snowhouse gesetzt. Sie können diesen Wert durch Ihr eigenes Warehouse ersetzen:
CREATE OR REPLACE TASK ad_model_monitoring_task
WAREHOUSE = snowhouse
SCHEDULE = '1 minute'
AS
EXECUTE IMMEDIATE
$$
BEGIN
INSERT INTO anomaly_res_table (ts, y, forecast, lower_bound, upper_bound, is_anomaly, percentile, distance)
SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
)
);
END;
$$;
Um die Aufgabe fortzusetzen, führen Sie den Befehl ALTER TASK … RESUME aus:
ALTER TASK ad_model_monitoring_task RESUME;
anomaly_res_table enthält dann alle Ergebnisse für jede Aufgabenausführung.
Um die Aufgabe anzuhalten, führen Sie den Befehl ALTER TASK … SUSPEND aus:
ALTER TASK ad_model_monitoring_task SUSPEND;
Überwachen mit Snowflake-Alerts¶
Sie können auch Snowflake-Alerts verwenden, um Ihre Daten in regelmäßigen Abständen zu überwachen und Ihnen E-Mails bei Erkennen von Anomalien zu senden. Mit den folgenden Anweisungen wird ein Alert erstellt, der jede Minute auf erkannte Anomalien prüft. Zuerst definieren Sie eine gespeicherte Prozedur, um Anomalien zu erkennen, und erstellen dann einen Alert, der diese gespeicherte Prozedur verwendet.
Bemerkung
Sie müssen die E-Mail-Integration einrichten, um E-Mails aus einer gespeicherten Prozedur zu versenden. Weitere Informationen dazu finden Sie unter Benachrichtigungen in Snowflake.
CREATE OR REPLACE PROCEDURE extract_anomalies()
RETURNS TABLE()
LANGUAGE SQL
AS
$$
BEGIN
let res RESULTSET := (SELECT * FROM TABLE(
model_trained_with_labeled_data!DETECT_ANOMALIES(
INPUT_DATA => TABLE(view_with_data_to_analyze),
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
CONFIG_OBJECT => {'prediction_interval':0.99}
))
WHERE is_anomaly = TRUE
);
RETURN TABLE(res);
END;
$$
;
CREATE OR REPLACE ALERT sample_sales_alert
WAREHOUSE = <your_warehouse_name>
SCHEDULE = '1 MINUTE'
IF (EXISTS (CALL extract_anomalies()))
THEN
CALL SYSTEM$SEND_EMAIL(
'sales_email_alert',
'your_email@snowflake.com',
'Anomalous Sales Data Detected in data stream',
CONCAT(
'Anomalous Sales Data Detected in data stream \n',
'Value outside of prediction interval detected in the most recent run at ',
current_timestamp(1)
));
Um den Alert zu starten oder fortzusetzen, führen Sie den Befehl ALTER ALERT … RESUME aus:
ALTER ALERT sample_sales_alert RESUME;
Um den Alert anzuhalten, führen Sie den Befehl ALTER ALERT … SUSPEND aus:
ALTER ALERT sample_sales_alert SUSPEND;
Erläuterungen zur Feature Importance¶
Ein Anomalieerkennungsmodell kann die relative Bedeutung aller in Ihrem Modell verwendeten Features erklären, einschließlich der von Ihnen gewählten exogenen Variablen, der automatisch generierten zeitlichen Features (wie z. B. Wochentag oder Woche des Jahres) sowie der Transformationen Ihrer Zielvariablen (wie z. B. gleitende Durchschnitte und autoregressive Lags). Diese Informationen sind nützlich, um zu verstehen, welche Faktoren Ihre Daten wirklich beeinflussen.
Die Methode <Name_des_Modells>!EXPLAIN_FEATURE_IMPORTANCE zählt, wie oft die Modellbäume die jeweiligen Features für eine Entscheidung verwendet haben. Diese Feature Importance-Bewertungen werden dann auf Werte zwischen 0 und 1 normalisiert, sodass sie in der Summe 1 ergeben. Die sich daraus resultierenden Punktzahlen ergeben eine ungefähre Rangliste der Features in Ihrem trainierten Modell.
Features, deren Punktzahlen nahe beieinander liegen, sind ähnlich wichtig. Bei extrem einfachen Zeitreihen (z. B. wenn die Zielspalte einen konstanten Wert hat) können alle Feature Importance-Bewertungen null sein.
Die Verwendung mehrerer Features, die einander sehr ähnlich sind, kann dazu führen, dass die Importance-Bewertung dieser Features sinkt. Wenn beispielweise ein Feature die Menge der verkauften Artikel und ein anderes die Menge der Artikel im Bestand ist, können die Werte korrelieren, da Sie nicht mehr verkaufen können, als Sie haben, und weil Sie versuchen, den Bestand so zu verwalten, dass Sie nicht mehr auf Lager haben, als Sie verkaufen werden. Wenn zwei Features identisch sind, kann es sein, dass das Modell sie bei der Entscheidungsfindung als austauschbar behandelt. Dies führt zu einer Feature Importance-Bewertung, die nur halb so hoch ist, wie die bei Berücksichtigung nur eines der Features.
Die Feature Importance zeigt auch Lag-Features an. Während des Trainings schließt das Modell auf die Häufigkeit (stündlich, täglich oder wöchentlich) Ihrer Trainingsdaten. Das Feature lagx (z. B. lag24) ist der Wert der Ziel-Variable, der x Zeiteinheiten zurückliegt. Wenn Ihre Daten zum Beispiel stündlich erhoben werden, steht lag24 für den Wert der Zielvariablen vor 24 Stunden.
Alle anderen Transformationen der Zielvariablen (gleitende Durchschnitte usw.) werden als aggregated_endogenous_features in der Ergebnistabelle zusammengefasst.
Einschränkungen¶
Sie können das zur Berechnung der Feature Importance verwendete Verfahren nicht frei wählen.
Die Feature Importance-Bewertung kann hilfreich sein, um ein Gefühl dafür zu bekommen, welche Features für die Genauigkeit Ihres Modells wichtig sind, aber die tatsächlichen Werte müssen als Schätzung angesehen werden.
Beispiel¶
Um die relative Bedeutung Ihrer Features für Ihr Modell zu verstehen, trainieren Sie ein Modell, und rufen Sie dann <Name_des_Modells>!EXPLAIN_FEATURE_IMPORTANCE auf. In diesem Beispiel erstellen Sie zunächst Zufallsdaten mit zwei exogenen Variablen, von denen eine zufällig ist und daher wahrscheinlich keine große Bedeutung für Ihr Modell hat, während die andere eine Kopie Ihrer Zielvariablen ist und daher wahrscheinlich eine größere Bedeutung für Ihr Modell hat.
Führen Sie die folgenden Anweisungen aus, um die Daten zu generieren, dann darauf ein Modell zu trainieren und schließlich die Feature Importance zu ermitteln:
CREATE OR REPLACE VIEW v_random_data AS SELECT
DATEADD('minute', ROW_NUMBER() over (ORDER BY 1), '2023-12-01')::TIMESTAMP_NTZ ts,
MOD(SEQ1(),10) y,
UNIFORM(1, 100, RANDOM(0)) exog_a
FROM TABLE(GENERATOR(ROWCOUNT => 500));
CREATE OR REPLACE VIEW v_feature_importance_demo AS SELECT
ts,
y,
exog_a
FROM v_random_data;
SELECT * FROM v_feature_importance_demo;
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION anomaly_model_feature_importance_demo(
INPUT_DATA => TABLE(v_feature_importance_demo),
TIMESTAMP_COLNAME => 'ts',
TARGET_COLNAME => 'y',
LABEL_COLNAME => ''
);
CALL anomaly_model_feature_importance_demo!EXPLAIN_FEATURE_IMPORTANCE();
Ausgabe
Da in diesem Beispiel zufällige Daten verwendet werden, dürfen Sie nicht erwarten, dass Ihre Ausgabe genau mit dieser Beispielausgabe übereinstimmt.
+--------+------+--------------------------------------+-------+-------------------------+
| SERIES | RANK | FEATURE_NAME | SCORE | FEATURE_TYPE |
+--------+------+--------------------------------------+-------+-------------------------+
| NULL | 1 | aggregated_endogenous_trend_features | 0.36 | derived_from_endogenous |
| NULL | 2 | exog_a | 0.22 | user_provided |
| NULL | 3 | epoch_time | 0.15 | derived_from_timestamp |
| NULL | 4 | minute | 0.13 | derived_from_timestamp |
| NULL | 5 | lag60 | 0.07 | derived_from_endogenous |
| NULL | 6 | lag120 | 0.06 | derived_from_endogenous |
| NULL | 7 | hour | 0.01 | derived_from_timestamp |
+--------+------+--------------------------------------+-------+-------------------------+
Überprüfen der Trainingsprotokolle¶
Wenn Sie mehrere Zeitreihen mit CONFIG_OBJECT => 'ON_ERROR': 'SKIP' trainieren, können einzelne Zeitreihenmodelle fehlschlagen, ohne dass der gesamte Trainingsprozess fehlschlägt. Um zu verstehen, welche Zeitreihen fehlgeschlagen sind und warum, rufen Sie <model_instance>!SHOW_TRAINING_LOGS auf.
Beispiel¶
CREATE TABLE t_error(date TIMESTAMP_NTZ, sales FLOAT, series VARCHAR);
INSERT INTO t_error VALUES
(TO_TIMESTAMP_NTZ('2019-12-20'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-21'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-22'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-23'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-24'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-25'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-26'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-27'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-28'), 1.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-29'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-30'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2019-12-31'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-01'), 2.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-02'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-03'), 3.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-04'), 7.0, 'A'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 10.0, 'B'), -- the same timestamp used again and again
(TO_TIMESTAMP_NTZ('2020-01-06'), 13.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 15.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 14.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 18.0, 'B'),
(TO_TIMESTAMP_NTZ('2020-01-06'), 12.0, 'B');
CREATE SNOWFLAKE.ML.ANOMALY_DETECTION model(
INPUT_DATA => TABLE(SELECT date, sales, series FROM t_error),
SERIES_COLNAME => 'series',
TIMESTAMP_COLNAME => 'date',
TARGET_COLNAME => 'sales',
LABEL_COLNAME => '',
CONFIG_OBJECT => {'ON_ERROR': 'SKIP'}
);
CALL model!SHOW_TRAINING_LOGS();
Ausgabe
+--------+--------------------------------------------------------------------------+
| SERIES | LOGS |
+--------+--------------------------------------------------------------------------+
| "B" | { "Errors": [ "At least two unique timestamps are required." ] } |
| "A" | NULL |
+--------+--------------------------------------------------------------------------+
Hinweise zu Kosten¶
Einzelheiten zu den Kosten für die Nutzung der ML-Funktionen finden Sie unter Hinweise zu Kosten in der Übersicht über die ML-Funktionen.