Configuration de sources de données JDBC pour Snowpark Connect for Spark¶
Cette section fournit un guide et un exemple de code pour la lecture de données à partir de bases de données externes et l’écriture de données dans des bases de données externes (comme MySQL et PostgreSQL) en utilisant la fonctionnalité de sources de données JDBC Snowpark Connect. Elle couvre à la fois la configuration côté client et celle du Notebook Snowflake.
Partie 1 : Configuration côté client (MySQL)¶
Cette configuration est requise lors de l’exécution de Snowpark Connect à partir d’une application cliente locale, telle qu’un script Python ou IDE.
Conditions préalables¶
Environnement d’exécution Java (JRE)/Kit de développement Java (JDK) :
Installez un JRE ou un JDK. L’architecture (par exemple, 64 bits) de votre installation Java doit correspondre à l’architecture de votre installation Python.
*Exemple de source pour l’installation :*Versions Adoptium Temurin _ (si vous utilisez Java 11).
Définition de la variable d’environnement ``JAVA_HOME`` :
Configurez la variable d’environnement
JAVA_HOMEpour pointer vers le répertoire racine de votre installation Java.Exemple (macOS/Linux) :
Définition de la variable d’environnement ``CLASSPATH`` :
Ajoutez le chemin d’accès au fichier
.jardu pilote JDBC de votre base de données à la variable d’environnementCLASSPATH. Cela permet à l’environnement Java de trouver le pilote nécessaire.Exemple (pour le pilote MySQL) :
Exemple de code client (lecture depuis MySQL)¶
Cet exemple montre comment lire une table depuis une base de données MySQL à l’aide de spark_session.read.jdbc().
Exemple de code client (écriture dans MySQL)¶
Cet exemple montre comment écrire des données dans une base de données MySQL à l’aide de spark_session.write.jdbc().
Partie 2 : Configuration du Snowflake Warehouse Notebook (PostgreSQL)¶
Cette configuration est utilisée lors de l’exécution de Snowpark Connect directement dans un environnement de Notebook Snowflake.
Étapes de configuration¶
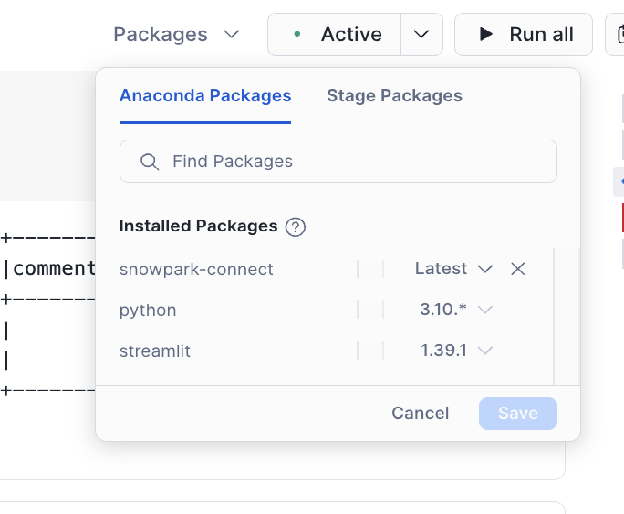
Ajouter le paquet ``snowpark-connect`` :
Assurez-vous que le paquet
snowflake-snowpark-connectest ajouté à l’environnement de votre notebook.
Télécharger et charger le pilote JDBC :
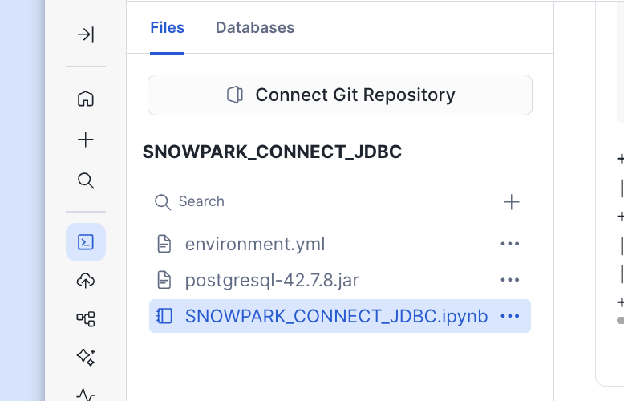
Téléchargez le fichier
.jarapproprié du pilote JDBC à votre base de données externe (par exemple, `le pilote JDBC PostgreSQL<https://jdbc.postgresql.org/download/postgresql-42.7.8.jar>`_ _).Chargez le fichier
.jartéléchargé directement dans l’environnement de votre notebook.
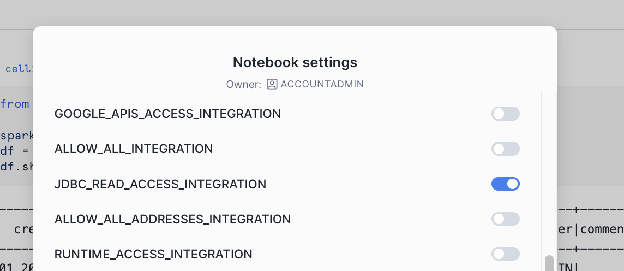
Activer les intégrations externes (règle réseau et intégration) :
Snowflake nécessite une intégration d’accès externe pour permettre au notebook de communiquer avec des emplacements réseau externes. Vous devez définir une règle réseau pour l’hôte et le port de votre base de données externe.
Exemple de code Warehouse Notebook (lecture depuis PostgreSQL)¶
Cet exemple montre le code Python nécessaire pour initialiser la session, charger le pilote et lire les données depuis PostgreSQL.
Exemple de code Warehouse Notebook (écriture dans PostgreSQL)¶
Cet exemple montre le code Python nécessaire pour initialiser la session, charger le pilote et écrire des données dans PostgreSQL.
Partie 3 : Configuration de Snowflake Workspace Notebook (PostgreSQL)¶
Cette configuration est utilisée lors de l’exécution de Snowpark Connect directement dans un environnement Snowflake Workspace Notebook.
Étapes de configuration¶
Le paquet
snowpark-connectest inclus par défaut dans Workspace Notebook.Télécharger et charger le pilote JDBC :
Téléchargez le fichier
.jarapproprié du pilote JDBC à votre base de données externe (par exemple, `le pilote JDBC PostgreSQL<https://jdbc.postgresql.org/download/postgresql-42.7.8.jar>`_ _).Chargez le fichier
.jartéléchargé directement dans l’environnement de votre notebook.
Créer une intégration externe :
Activer les intégrations externes (règle réseau et intégration) :
Snowflake nécessite une intégration d’accès externe pour permettre au notebook de communiquer avec des emplacements réseau externes. Vous devez définir une règle réseau pour l’hôte et le port de votre base de données externe.
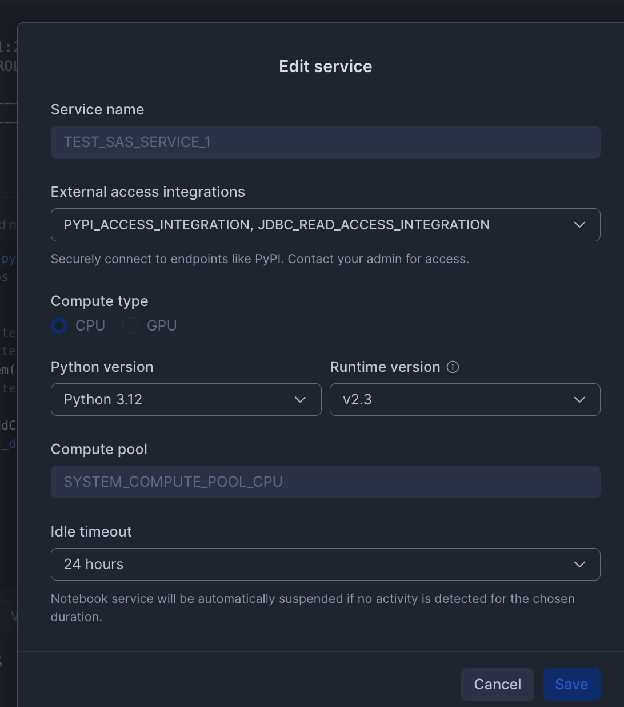
Exemple de code Workspace Notebook (lecture depuis PostgreSQL)¶
Cet exemple montre le code Python nécessaire pour initialiser la session, charger le pilote et lire les données depuis PostgreSQL.
Exemple de code Workspace Notebook (écriture dans PostgreSQL)¶
Cet exemple montre le code Python nécessaire pour initialiser la session, charger le pilote et écrire des données dans PostgreSQL.
Sources de données prises en charge¶
SQL Server
MySQL
PostgreSQL