Configuração de fontes de dados JDBC para Snowpark Connect for Spark¶
Esta seção fornece um guia e um código de amostra para ler dados de bancos de dados externos e gravar dados em bancos de dados externos (como MySQL e PostgreSQL) usando o recurso de fonte de dados JDBC para Snowpark Connect. Ela aborda a configuração tanto do notebook Snowflake quanto do lado do cliente.
Parte 1: Configuração do lado do cliente (MySQL)¶
Essa configuração é necessária ao executar o Snowpark Connect de um aplicativo cliente local, como um script ou IDE Python.
Pré-requisitos¶
Java Runtime Environment (JRE)/Java Development Kit (JDK):
Instale um JRE ou JDK. A arquitetura (por exemplo, 64 bits) da instalação Java deve corresponder à arquitetura da instalação Python.
Exemplo de fonte para instalação: Versões do Adoptium Temurin (se usar Java 11).
Definir a variável de ambiente ``JAVA_HOME``:
Configure a variável de ambiente
JAVA_HOMEpara apontar para o diretório raiz da instalação Java.Exemplo (macOS/Linux):
Definir a variável de ambiente ``CLASSPATH``:
Adicione o caminho para o arquivo
.jardo driver JDBC do seu banco de dados específico à variável de ambienteCLASSPATH. Isso permite que o ambiente Java encontre o driver necessário.Exemplo (para driver MySQL):
Código do cliente de amostra (ler do MySQL)¶
Este exemplo demonstra como ler uma tabela de um banco de dados MySQL usando spark_session.read.jdbc().
Código do cliente de amostra (gravar no MySQL)¶
Este exemplo demonstra como gravar dados em um banco de dados MySQL usando spark_session.write.jdbc().
Parte 2: Configuração do notebook do warehouse Snowflake (PostgreSQL)¶
Essa configuração é usada ao executar o Snowpark Connect diretamente em um ambiente de notebook Snowflake.
Etapas de configuração¶
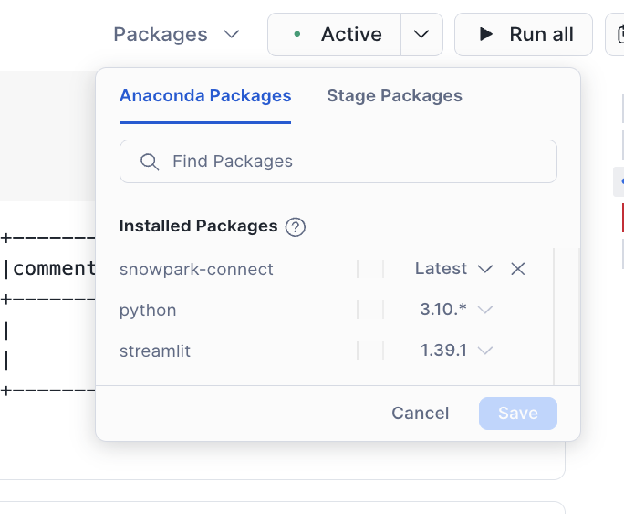
Adicionar o pacote ``snowpark-connect``:
Garanta que o pacote
snowflake-snowpark-connectseja adicionado ao seu ambiente de notebook.
Baixar e carregar o driver JDBC:
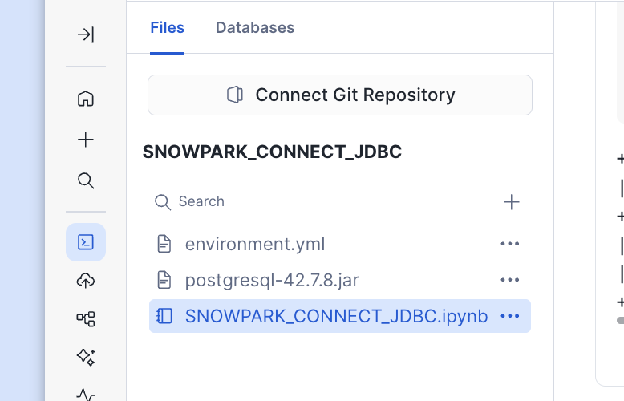
Baixe o arquivo
.jardo driver JDBC adequado ao seu banco de dados externo (por exemplo, driver JDBC do PostgreSQL).Carregue o arquivo
.jarbaixado diretamente em seu ambiente de notebook.
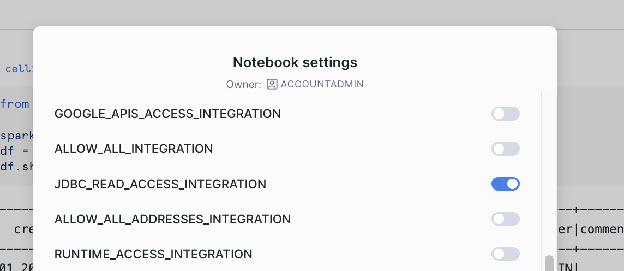
Ativar integrações externas (regra de rede e integração):
O Snowflake requer uma integração de acesso externo para permitir que o notebook se comunique com locais de rede externos. Você deve definir uma regra de rede para o host e a porta do seu banco de dados externo.
Código do notebook do warehouse de amostra (ler do PostgreSQL)¶
Este exemplo mostra o código Python necessário para inicializar a sessão, carregar o driver e ler dados do PostgreSQL.
Código do notebook do warehouse de amostra (gravar no PostgreSQL)¶
Este exemplo mostra o código Python necessário para inicializar a sessão, carregar o driver e gravar dados no PostgreSQL.
Parte 3: Configuração do notebook do espaço de trabalho Snowflake (PostgreSQL)¶
Essa configuração é usada ao executar o Snowpark Connect diretamente em um ambiente de notebook do espaço de trabalho Snowflake.
Etapas de configuração¶
Por padrão, o pacote
snowpark-connectestá incluído no notebook do espaço de trabalho.Baixar e carregar o driver JDBC:
Baixe o arquivo
.jardo driver JDBC adequado ao seu banco de dados externo (por exemplo, driver JDBC do PostgreSQL).Carregue o arquivo
.jarbaixado diretamente em seu ambiente de notebook.
Criar a integração externa:
Ativar integrações externas (regra de rede e integração):
O Snowflake requer uma integração de acesso externo para permitir que o notebook se comunique com locais de rede externos. Você deve definir uma regra de rede para o host e a porta do seu banco de dados externo.
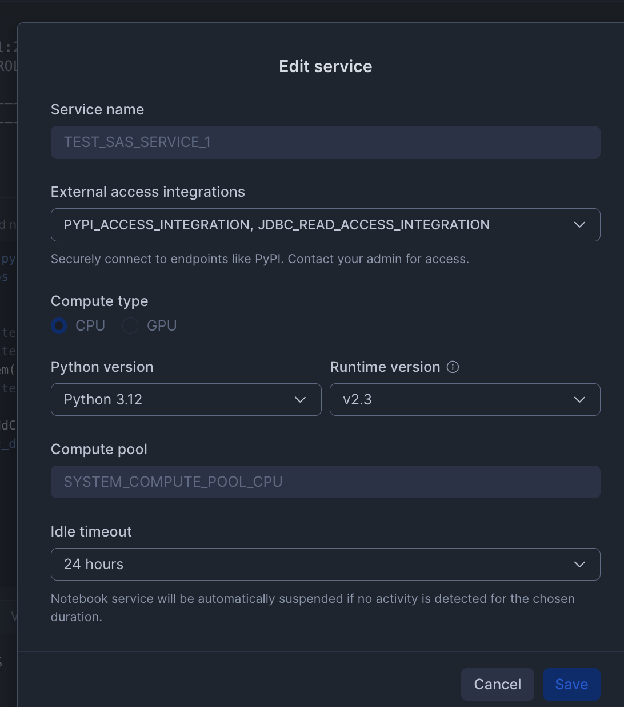
Código do notebook do espaço de trabalho de amostra (ler do PostgreSQL)¶
Este exemplo mostra o código Python necessário para inicializar a sessão, carregar o driver e ler dados do PostgreSQL.
Código do notebook do espaço de trabalho de amostra (gravar no PostgreSQL)¶
Este exemplo mostra o código Python necessário para inicializar a sessão, carregar o driver e gravar dados no PostgreSQL.
Fontes de dados compatíveis¶
SQL Server
MySQL
PostgreSQL