Einrichtung von JDBC-Datenquellen für Snowpark Connect for Spark¶
Dieser Abschnitt enthält eine Anleitung und Beispielcode zum Lesen von Daten aus externen Datenbanken und zum Schreiben von Daten in externe Datenbanken (z. B.MySQL undPostgreSQL) über das Snowpark Connect-Feature für JDBC-Datenquellen. Er deckt sowohl die clientseitige Einrichtung als auch die Einrichtung von Snowflake Notebook ab.
Teil 1: Clientseitige Einrichtung (MySQL )¶
Diese Einrichtung ist erforderlich, wenn Sie Snowpark Connect von einer lokalen Clientanwendung aus ausführen, z. B. einem Python-Skript oder einer IDE.
Voraussetzungen¶
Java Runtime Environment (JRE) / Java Development Kit (JDK):
Installieren Sie eine JRE oder ein JDK. Die Architektur (z. B. 64-Bit) Ihrer Java-Installation muss mit der Architektur Ihrer Python-Installation übereinstimmen.
Beispielquelle für die Installation: Adoptium Temurin Releases (bei Verwendung von Java 11).
Festlegen der ``JAVA_HOME``-Umgebungsvariablen:
Konfigurieren Sie die
JAVA_HOME-Umgebungsvariable, die auf das Stammverzeichnis Ihrer Java-Installation verweist.Beispiel (macOS/Linux):
Festlegen der ``CLASSPATH``-Umgebungsvariablen:
Fügen Sie den Pfad zu der spezifischen
.jar-Datei des JDBC-Treibers Ihrer Datenbank in dieCLASSPATH-Umgebungsvariable ein. Dadurch kann die Java-Umgebung den erforderlichen Treiber finden.Beispiel (für den MySQL-Treiber):
Beispiel für Clientcode (lesen aus MySQL)¶
Dieses Beispiel zeigt, wie eine Tabelle mit spark_session.read.jdbc() aus einer MySQL-Datenbank gelesen wird.
Beispiel für Clientcode (schreiben inMySQL)¶
Dieses Beispiel zeigt, wie Daten mit spark_session.write.jdbc() in eine MySQL-Datenbank geschrieben werden.
Teil 2: Einrichtung von Snowflake Warehouse Notebook (PostgreSQL)¶
Diese Einrichtung wird verwendet, wenn Sie Snowpark Connect direkt innerhalb einer Snowflake Notebook-Umgebung ausführen.
Einrichtungsschritte¶
Hinzufügen des ``snowpark-connect``-Pakets:
Stellen Sie sicher, dass das
snowflake-snowpark-connect-Paket zu Ihrer Notebook-Umgebung hinzugefügt wird.
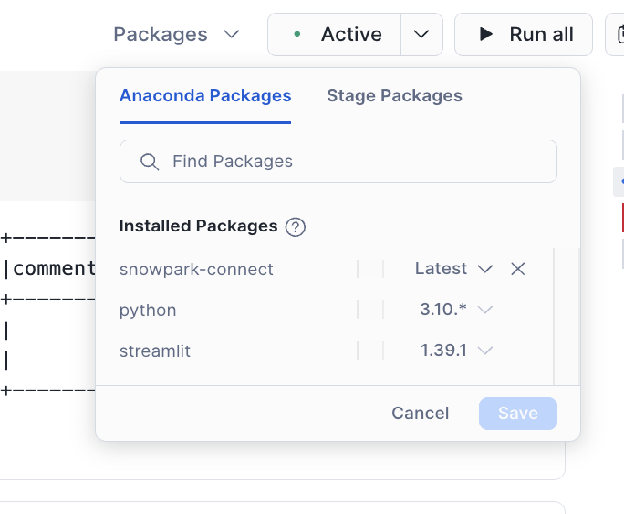
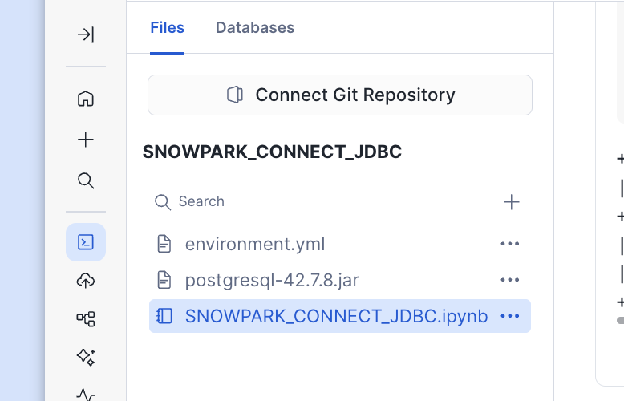
Herunter- und Hochladen des JDBC-Treibers:
Laden Sie die entsprechende
.jar-Datei des JDBC-Treibers für Ihre externe Datenbank (z. B. PostgreSQL JDBC-Treiber _) herunter.Laden Sie die heruntergeladene
.jar-Datei direkt in Ihre Notebook-Umgebung hoch.
Externe Integrationen aktivieren (Netzwerkregel und -Integration):
Snowflake benötigt eine Integration für den externen Zugriff, damit das Notebook mit externen Netzwerkstandorten kommunizieren kann. Sie müssen eine Netzwerkregel für den Host und den Port Ihrer externen Datenbank definieren.
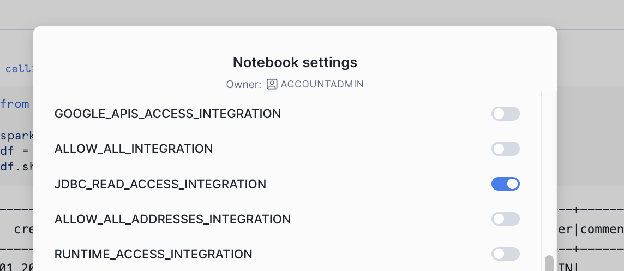
Beispielcode für ein Warehouse Notebook (lesen aus PostgreSQL)¶
Dieses Beispiel zeigt den notwendigen Python-Code, um die Sitzung zu initialisieren, den Treiber zu laden und Daten aus PostgreSQL zu lesen.
Beispielcode für Warehouse Notebook (schreiben in PostgreSQL)¶
Dieses Beispiel zeigt den notwendigen Python-Code, um die Sitzung zu initialisieren, den Treiber zu laden und Daten in PostgreSQL zu schreiben.
Teil 3: Einrichten von Snowflake Workspace Notebook (PostgreSQL)¶
Diese Einrichtung wird verwendet, wenn Sie Snowpark Connect direkt innerhalb einer Snowflake Workspace Notebook-Umgebung ausführen.
Einrichtungsschritte¶
Das
snowpark-connect-Paket ist standardmäßig in Workspace Notebook enthalten.Herunter- und Hochladen des JDBC-Treibers:
Laden Sie die entsprechende
.jar-Datei des JDBC-Treibers für Ihre externe Datenbank (z. B. PostgreSQL JDBC-Treiber _) herunter.Laden Sie die heruntergeladene
.jar-Datei direkt in Ihre Notebook-Umgebung hoch.
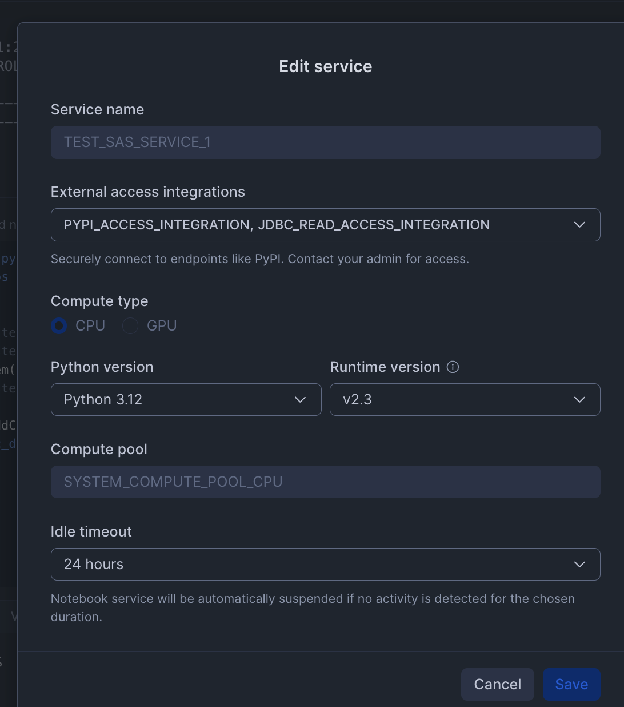
Erstellen der externen Integration:
Externe Integrationen aktivieren (Netzwerkregel und -Integration):
Snowflake benötigt eine Integration für den externen Zugriff, damit das Notebook mit externen Netzwerkstandorten kommunizieren kann. Sie müssen eine Netzwerkregel für den Host und den Port Ihrer externen Datenbank definieren.
Beispielcode für Workspace Notebook (lesen aus PostgreSQL)¶
Dieses Beispiel zeigt den notwendigen Python-Code, um die Sitzung zu initialisieren, den Treiber zu laden und Daten aus PostgreSQL zu lesen.
Beispielcode für Workspace Notebook (schreiben in PostgreSQL)¶
Dieses Beispiel zeigt den notwendigen Python-Code, um die Sitzung zu initialisieren, den Treiber zu laden und Daten in PostgreSQL zu schreiben.
Unterstützte Datenquellen¶
SQL Server
MySQL
PostgreSQL