- Catégories :
MATCH_RECOGNIZE¶
Reconnaît les correspondances d’un modèle dans un ensemble de lignes. MATCH_RECOGNIZE accepte un ensemble de lignes (d’une table, d’une vue, d’une sous-requête ou d’une autre source) en entrée, et renvoie toutes les correspondances pour un modèle de ligne donné dans cet ensemble. Le modèle est défini de la même manière qu’une expression régulière.
La clause peut retourner soit :
Toutes les lignes appartenant à chaque correspondance.
Une ligne de résumé par correspondance.
MATCH_RECOGNIZE est typiquement utilisé pour détecter des événements dans des séries temporelles. Par exemple, MATCH_RECOGNIZE peut rechercher dans une table d’historique des cours boursiers des courbes telles que V (baisse suivie d’une hausse) ou W (baisse, hausse, baisse, hausse).
MATCH_RECOGNIZE est une sous-clause facultative de la clause FROM .
Note
Vous ne pouvez pas utiliser la clause MATCH_RECOGNIZE dans une expression de table commune (CTE) **récursive**.
Syntaxe¶
Sous-clauses obligatoires¶
DEFINE : définition de symboles¶
Les symboles (également appelés « variables de modèle ») sont les éléments constitutifs du modèle.
Un symbole est défini par une expression. Si l’expression est vraie pour une ligne, le symbole est attribué à cette ligne. Plusieurs symboles peuvent être attribués à une ligne.
Les symboles qui ne sont pas définis dans la clause DEFINE, mais qui sont utilisés dans le modèle, sont toujours affectés à toutes les lignes. Implicitement, ils sont équivalents à l’exemple suivant :
Les modèles sont définis à partir de symboles et d”opérateurs.
PATTERN : spécification du modèle à mettre en correspondance¶
Le modèle définit une séquence valide de lignes qui représente une correspondance. Le modèle est défini comme une expression régulière (regex) et est construit à partir de symboles, d’opérateurs et de quantificateurs.
Par exemple, supposons que le symbole S1 soit défini comme stock_price < 55, et que le symbole S2 soit défini comme stock price > 55. Le modèle suivant spécifie une séquence de lignes dans lesquelles le prix de l’action est passé de moins de 55 à plus de 55 :
Voici un exemple plus complexe de définition de modèle :
La section suivante décrit en détail les différents composants de ce modèle.
Note
MATCH_RECOGNIZE utilise le retour sur trace pour rapprocher les motifs Comme c’est le cas avec d’autres moteurs d’expression régulière utilisant le retour sur trace, certaines combinaisons de motifs et de données à rapprocher peuvent prendre plus longtemps à s’exécuter, ce qui peut provoquer des coûts de calcul plus élevés.
Pour améliorer les performances, définissez un motif le plus spécifique possible :
Assurez-vous que chaque ligne corresponde à un seul symbole ou un petit nombre de symboles
Évitez d’utiliser des symboles qui correspondent à chaque ligne (par exemple des symboles non présents dans la clause
DEFINEou des symboles définis comme vrais)Définissez une limite supérieure pour les quantificateurs (par exemple
{,10}au lieu de*).
Par exemple, le motif suivant peut augmenter les coûts si aucune ligne ne correspond :
S’il existe une limite supérieure pour le nombre de lignes que vous souhaitez faire correspondre, vous pouvez indiquer cette limite dans les quantificateurs pour améliorer les performances. En outre, au lieu d’indiquer que vous souhaitez trouver any_symbol qui suit symbol1, vous pouvez rechercher une ligne qui n’est pas symbol1 (not_symbol1 dans cet exemple) :
En général, il est conseillé de surveiller la durée d’exécution de la requête pour vérifier que cela ne prend pas plus de temps que prévu.
- Symboles:
Un symbole correspond à une ligne à laquelle ce symbole a été attribué. Les symboles suivants sont disponibles :
symbol. Par exemple,S1, … ,S4Ce sont des symboles qui ont été définis dans la sous-clauseDEFINEet qui sont évalués par ligne. (Il peut également s’agir de symboles qui n’ont pas été définis et qui sont automatiquement affectés à toutes les lignes).^(Début de la partition.) Il s’agit d’un symbole virtuel qui indique le début d’une partition et auquel aucune ligne n’est associée. Vous pouvez l’utiliser pour exiger qu’une correspondance ne commence qu’au début d’une partition.Pour un exemple, voir Mise en correspondance des modèles par rapport au début ou à la fin d’une partition.
$(Fin de la partition.) Il s’agit d’un symbole virtuel qui indique la fin d’une partition et auquel aucune ligne n’est associée. Vous pouvez l’utiliser pour exiger qu’une correspondance ne se termine qu’à la fin d’une partition.Pour un exemple, voir Mise en correspondance des modèles par rapport au début ou à la fin d’une partition.
- Quantificateurs:
Un quantificateur peut être placé après un symbole ou une opération. Un quantificateur indique le nombre minimum et maximum d’occurrences du symbole ou de l’opération associé. Les quantificateurs suivants sont disponibles :
Quantificateur
Signification
+1 ou plus. Par exemple,
( {- S3 -} S4 )+.
*0 ou plus. Par exemple,
S2*?.
?0 ou 1.
{n}Exactement n.
{n,}n ou plus.
{,m}0 à m.
{n, m}n à m. Par exemple,
PERMUTE(S1, S2){1,2}.
Par défaut, les quantificateurs sont en « mode gourmand », ce qui signifie qu’ils essaient de correspondre à la quantité maximale si possible. Pour mettre un quantificateur en « mode réticent », dans lequel le quantificateur essaie de correspondre à la quantité minimale si possible, placez un ? après le quantificateur (par exemple S2*?).
- Opérateurs:
Les opérateurs précisent dans quel ordre les symboles ou autres opérations doivent se produire dans la séquence de lignes pour former une correspondance valide. Les opérateurs suivants sont disponibles :
Opérateur
Signification
... ...(espace)Concaténation. Spécifie qu’un symbole ou une opération doit en suivre un autre. Par exemple,
S1 S2signifie que la condition définie pourS2doit se produire après la condition définie pourS1.
{- ... -}Exclusion. Exclut les symboles ou les opérations contenus de la sortie. Par exemple,
{- S3 -}exclut l’opérateurS3de la sortie. Les lignes exclues n’apparaîtront pas dans la sortie, mais seront incluses dans l’évaluation des expressionsMEASURES.
( ... )Groupement. Utilisé pour remplacer la précédence d’un opérateur ou pour appliquer le même quantificateur aux symboles ou aux opérations du groupe. Dans cet exemple, le quantificateur
+s’applique à la séquence{- S3 -} S4, et pas seulement àS4.
PERMUTE(..., ...)Permutation. Correspond à toute permutation des motifs spécifiés. Par exemple,
PERMUTE(S1, S2)correspond àS1 S2ouS2 S1.PERMUTE()accepte un nombre illimité d’arguments.
... | ...Alternative. Spécifie que soit le premier symbole ou la première opération, soit l’autre doit se produire. Par exemple,
( S3 S4 ) | PERMUTE(S1, S2). L’opérateur alternatif a la priorité sur l’opérateur de concaténation.
Sous-clauses facultatives¶
ORDER BY : tri des lignes avant la mise en correspondance¶
{}Où :
Définissez l’ordre des lignes comme vous le feriez pour les fonctions de fenêtre. C’est l’ordre dans lequel les lignes individuelles de chaque partition sont transmises à l’opérateur
MATCH_RECOGNIZE.Pour plus d’informations, voir Partitionnement et tri des lignes.
PARTITION BY : partitionnement des lignes en fenêtres¶
{}Partitionnez l’ensemble de lignes d’entrée comme vous le feriez pour les fonctions de fenêtre.
MATCH_RECOGNIZEeffectue la correspondance individuellement pour chaque partition résultante.Le partitionnement permet non seulement de regrouper les lignes qui sont liées les unes aux autres, mais aussi d’exploiter la capacité de traitement des données distribuées de Snowflake, car des partitions distinctes peuvent être traitées en parallèle.
Pour plus d’informations sur le partitionnement, voir Partitionnement et tri des lignes.
MEASURES : spécification de colonnes de sortie supplémentaires¶
Les « mesures » sont des colonnes supplémentaires facultatives qui sont ajoutées à la sortie de l’opérateur MATCH_RECOGNIZE . Les expressions de la sous-clause MEASURES ont les mêmes capacités que les expressions de la sous-clause DEFINE. Pour plus d’informations, voir Symboles.
Au sein de la sous-clause MEASURES, les fonctions suivantes, spécifiques à MATCH_RECOGNIZE , sont disponibles :
MATCH_NUMBER()Renvoie le numéro séquentiel de la correspondance. Le MATCH_NUMBER commence à partir de 1, et est incrémenté pour chaque correspondance.MATCH_SEQUENCE_NUMBER()Renvoie le numéro de ligne dans une correspondance. MATCH_SEQUENCE_NUMBER est séquentiel et commence à partir de 1.CLASSIFIER()Renvoie une valeur TEXT qui contient le symbole correspondant à la ligne concernée. Par exemple, si une ligne correspond au symboleGT75, la fonctionCLASSIFIERrenvoie la chaîne « GT75 ».
Note
Lorsque vous spécifiez des mesures, n’oubliez pas les restrictions mentionnées dans la section Limitations des fonctions de fenêtre utilisées dans DEFINE et MEASURES .
ROW(S) PER MATCH : spécification des lignes à renvoyer¶
Spécifie les lignes qui sont retournées pour une correspondance réussie. La sous-clause est facultative.
ALL ROWS PER MATCH: retourne toutes les lignes de la correspondance.ONE ROW PER MATCH: renvoie une ligne de résumé pour chaque correspondance, quel que soit le nombre de lignes dans la correspondance. C’est la configuration par défaut.
Soyez attentif aux cas particuliers suivants :
Correspondances vides : une correspondance vide se produit si un modèle est capable de correspondre à zéro ligne. Par exemple, si le modèle est défini comme
A*et que la première ligne au début d’une tentative de correspondance est affectée au symboleB, une correspondance vide comprenant uniquement cette ligne est générée, car le quantificateur*dans le modèleA*permet de traiter 0 occurrence deAcomme une correspondance. Les expressionsMEASURESsont évaluées différemment pour cette ligne :La fonction CLASSIFIER retourne NULL.
Les fonctions de fenêtre renvoient NULL.
La fonction COUNT renvoie 0.
Lignes sans correspondance : si une ligne n’a pas été mise en correspondance avec le modèle, elle est appelée « ligne sans correspondance ».
MATCH_RECOGNIZEpeut également être configuré pour renvoyer des lignes sans correspondance. Pour les lignes sans correspondance, les expressions de la sous-clauseMEASURESrenvoient NULL.
Exclusions
La syntaxe d’exclusion
({- ... -})dans la définition du modèle permet aux utilisateurs d’exclure certaines lignes de la sortie. Si tous les symboles du modèle ont été exclus, aucune ligne n’est générée pour cette correspondance siALL ROWS PER MATCHa été spécifié. Notez que MATCH_NUMBER est incrémenté de toute façon. Les lignes exclues ne font pas partie du résultat, mais sont incluses pour l’évaluation des expressionsMEASURES.Lorsqu’on utilise la syntaxe d’exclusion, la sous-clause ROWS PER MATCH peut être spécifiée comme suit :
ONE ROW PER MATCH (par défaut)
Renvoie exactement une ligne pour chaque correspondance réussie. La sémantique par défaut des fonctions de fenêtre dans la sous-clause
MEASURESestFINAL.Les colonnes de sortie de l’opérateur
MATCH_RECOGNIZEsont toutes les expressions données dans la sous-clausePARTITION BYet toutes les expressionsMEASURES. Toutes les lignes résultantes d’une correspondance sont regroupées par les expressions données dans la sous-clausePARTITION BYet lesMATCH_NUMBERen utilisant la fonction d’agrégationANY_VALUEpour toutes les mesures. Par conséquent, si les mesures donnent une valeur différente pour différentes lignes de la même correspondance, la sortie est non déterministe.L’omission de la sous-clause
PARTITION BYetMEASURESentraîne une erreur indiquant que le résultat ne comprend aucune colonne.Pour les correspondances vides, une ligne est générée. Les lignes sans correspondance ne font pas partie de la sortie.
ALL ROWS PER MATCHRenvoie une ligne pour chaque ligne faisant partie de la correspondance, à l’exception des lignes correspondant à une partie du modèle marqué pour l”exclusion.
Les lignes exclues sont toujours prises en compte dans les calculs de la sous-clause
MEASURES.Les correspondances peuvent se chevaucher en fonction de la sous-clause
AFTER MATCH SKIP TO, de sorte que la même ligne puisse apparaître plusieurs fois dans la sortie.La sémantique par défaut des fonctions de fenêtre dans la sous-clause
MEASURESestRUNNING.Les colonnes de sortie de l’opérateur
MATCH_RECOGNIZEsont les colonnes de l’ensemble des lignes en entrée et les colonnes définies dans la sous-clauseMEASURES.Les options suivantes sont disponibles pour
ALL ROWS PER MATCH:SHOW EMPTY MATCHES (default)Ajouter des correspondances vides à la sortie. Les lignes sans correspondance ne sont pas sorties.OMIT EMPTY MATCHESNi les correspondances vides ni les lignes sans correspondance ne sont dans la sortie. Cependant, le MATCH_NUMBER est toujours incrémenté par une correspondance vide.WITH UNMATCHED ROWSAjoute les correspondances vides et les lignes sans correspondance à la sortie. Si cette clause est utilisée, le modèle ne doit pas contenir d’exclusions.
Pour un exemple qui utilise l’exclusion pour réduire les sorties non pertinentes, voir Recherche de modèles dans des lignes non adjacentes.
AFTER MATCH SKIP : spécification du point à partir duquel continuer après une correspondance¶
Cette sous-clause indique où poursuivre la correspondance après qu’une correspondance positive a été trouvée.
PAST LAST ROW (default)Continuer la correspondance après la dernière ligne de la correspondance en cours.
Cela empêche les correspondances qui contiennent des lignes qui se chevauchent. Par exemple, si vous avez un modèle de stock qui contient 3
Vformes dans une ligne, alorsPAST LAST ROWtrouve un modèleW, pas deux.TO NEXT ROWContinuer la correspondance après la première ligne de la correspondance en cours.
Cela permet des correspondances qui contiennent des lignes qui se chevauchent. Par exemple, si vous avez un modèle de stock qui contient 3 formes
Vdans une ligne, alorsTO NEXT ROWtrouve deux modèlesW(le premier modèle est basé sur les deux premières formesV, et la deuxième formeWest basée sur les deuxième et troisième formesV; ainsi les deux modèles contiennent le mêmeV).TO [ { FIRST | LAST } ] <symbole>Continuez la mise en correspondance à la première ou à la dernière ligne (par défaut) qui correspondait au symbole donné.
Au moins une ligne doit être associée au symbole donné, sinon une erreur est signalée.
Si cette opération ne permet pas de dépasser la première ligne de la correspondance en cours, une erreur est signalée.
Notes sur l’utilisation¶
Expressions dans les clauses DEFINE et MEASURES¶
Les clauses DEFINE et MEASURES autorisent les expressions. Ces expressions peuvent être complexes et inclure des fonctions de fenêtre et des fonctions de navigation spéciales (qui sont un type de fonction de fenêtre).
Dans la plupart des cas, les expressions dans DEFINE et MEASURES suivent les règles applicables aux expressions ailleurs dans la syntaxe SQL de Snowflake. Toutefois, il existe certaines différences, décrites ci-dessous :
- Fonctions de la fenêtre:
-
PREV( expr [ , offset [, default ] ] )Permet de naviguer jusqu’à la ligne précédente de la correspondance actuelle dans la sous-clause MEASURES.Cette fonction n’est actuellement pas disponible dans la sous-clause DEFINE. Au lieu de cela, vous pouvez utiliser LAG qui navigue vers la ligne précédente dans le cadre de la fenêtre.
NEXT( expr [ , offset [ , default ] ] )Permet de naviguer vers la ligne suivante dans le cadre actuel de la fenêtre. Cette fonction est équivalente à LEAD.FIRST( expr )Permet de naviguer jusqu’à la première ligne de la correspondance actuelle dans la sous-clause MEASURES.Cette fonction n’est actuellement pas disponible dans la sous-clause DEFINE. À la place, vous pouvez utiliser FIRST_VALUE qui permet de naviguer vers la première ligne du cadre actuel de la fenêtre.
LAST( expr )Permet de naviguer vers la dernière ligne du cadre actuel de la fenêtre. Cette fonction est similaire à LAST_VALUE, mais pour LAST le cadre de la fenêtre est limité à la ligne actuelle de la tentative de correspondance actuelle lorsque LAST est utilisé dans la sous-clause DEFINE .
Pour un exemple qui utilise les fonctions de navigation, voir Renvoi d’informations sur la correspondance.
En général, lorsqu’une fonction de fenêtre est utilisée à l’intérieur d’une clause
MATCH_RECOGNIZE, la fonction de fenêtre ne nécessite pas sa propre clauseOVER (PARTITION BY ... ORDER BY ...). La fenêtre est implicitement déterminée parPARTITION BYetORDER BYde la clauseMATCH_RECOGNIZE. (Toutefois, voir Limitations des fonctions de fenêtre utilisées dans DEFINE et MEASURES pour certaines exceptions).En général, le cadre de la fenêtre est également dérivé implicitement du contexte actuel dans lequel la fonction de fenêtre est utilisée. La limite inférieure du cadre est définie comme décrit ci-dessous :
Dans la sous-clause
DEFINE:Le cadre commence au début de la tentative de correspondance en cours, sauf en cas d’utilisation de
LAG,LEAD,FIRST_VALUEetLAST_VALUE.Dans la sous-clause
MEASURES:Le cadre commence au début de la correspondance qui a été trouvée.
Les bords du cadre de la fenêtre peuvent être spécifiés en utilisant la sémantique
RUNNINGouFINAL.RUNNING:En général, le cadre se termine à la ligne actuelle. Toutefois, les exceptions suivantes existent :
Dans la sous-clause
DEFINE, pourLAG,LEAD,FIRST_VALUE,LAST_VALUE, etNEXTet , le cadre se termine à la dernière ligne de la fenêtre.Dans la sous-clause
MEASURES, pourPREV,NEXT,LAGetLEAD, le cadre se termine à la dernière ligne de la fenêtre.
Dans la sous-clause
DEFINE,RUNNINGest la sémantique par défaut (et la seule autorisée).Dans la sous-clause
MEASURES, lorsque la sous-clauseALL ROWS PER MATCHest utilisée,RUNNINGest la valeur par défaut.FINAL:Le cadre se termine à la dernière ligne de la correspondance.
FINALn’est autorisé que dans la sous-clauseMEASURES. C’est la valeur par défaut lorsqueONE ROW PER MATCHs’applique. - Prédicats de symboles:
Les expressions comprises dans les sous-clauses
DEFINEetMEASURESautorisent les symboles comme prédicats pour les références de colonnes.Le
<symbole>indique une ligne qui a été trouvée et le symbole<colonne>identifie une colonne spécifique dans cette ligne.Une référence de colonne avec prédicats signifie que la fonction de fenêtre environnante ne recherche que les lignes qui ont été finalement mappées au symbole spécifié.
Les références de colonnes avec prédicats peuvent être utilisées à l’extérieur et à l’intérieur d’une fonction de fenêtre. En cas d’utilisation en dehors d’une fonction de fenêtre,
<symbol>.<column>est identique àLAST(<symbole>.<colonne>). À l’intérieur d’une fonction de fenêtre, toutes les références de colonnes doivent être associées à un prédicat ayant le même symbole ou toutes doivent ne pas avoir de prédicat.Ceci explique comment les fonctions liées à la navigation se comportent avec les références de colonnes avec prédicat :
{}Recherche dans le cadre de la fenêtre, vers l’arrière, à partir de la ligne actuelle incluse (ou de la dernière ligne dans le cas d’une sémantiqueFINAL), la première ligne qui a finalement été associée au<symbole>spécifié, puis est<décalée>de lignes (la valeur par défaut est 1) vers l’arrière en ignorant le symbole auquel ces lignes ont été associées. Si la partie recherchée du cadre ne contient pas de ligne associée au<symbole>ou si la recherche devait dépasser le bord du cadre, NULL est renvoyé.{}Recherche dans le cadre de la fenêtre, vers l’arrière, à partir de la ligne actuelle incluse (ou de la dernière ligne dans le cas d’une sémantiqueFINAL), la première ligne qui a finalement été associée au<symbole>spécifié, puis est<décalée>de lignes (la valeur par défaut est 1) vers l’arrière en ignorant le symbole auquel ces lignes ont été associées. Si la partie recherchée du cadre ne contient pas de ligne associée au<symbole>ou si la recherche devait dépasser le bord du cadre, NULL est renvoyé.{}Recherche dans le cadre de la fenêtre vers l’avant, à partir de la première ligne incluse (ou la dernière ligne dans le cas d’une sémantiqueFINAL), la première ligne qui a finalement été associée au<symbole>spécifié. Si la partie recherchée du cadre ne contient pas de ligne associée au<symbole>, NULL est renvoyé.{}Recherche dans le cadre de la fenêtre, vers l’arrière, à partir de la ligne actuelle incluse (ou la dernière ligne dans le cas d’une sémantiqueFINAL), la première ligne qui a finalement été associée au<symbole>spécifié. Si la partie recherchée du cadre ne contient pas de ligne associée au<symbole>, NULL est renvoyé.
Note
Les restrictions sur les fonctions de fenêtre sont documentées dans la section Limitations des fonctions de fenêtre utilisées dans DEFINE et MEASURES .
Limitations des fonctions de fenêtre utilisées dans DEFINE et MEASURES¶
Les expressions des sous-clauses DEFINE et MEASURES peuvent inclure des fonctions de fenêtre. Toutefois, l’utilisation des fonctions de fenêtre dans ces sous-clauses est soumise à certaines restrictions. Ces limitations sont présentées dans le tableau ci-dessous :
Fonction
DEFINE (En cours) <column/symbol.column>
MEASURES (En cours) <column/symbol.column>
MEASURES (Final) <column/symbol.column>
Colonne
✔ / ❌
✔ / ❌
✔ / ✔
PREV(…)
❌ / ❌
✔ / ❌
✔ / ❌
NEXT(…)
✔ / ❌
✔ / ❌
✔ / ❌
FIRST(…)
❌ / ❌
✔ / ❌
✔ / ✔
LAST(…)
✔ / ❌
✔ / ❌
✔ / ✔
LAG()
✔ / ❌
✔ / ❌
✔ / ❌
LEAD()
✔ / ❌
✔ / ❌
✔ / ❌
FIRST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
LAST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
Agrégations [1]
✔ / ❌
✔ / ✔
✔ / ✔
Autres fonctions de la fenêtre [1]
✔ / ❌
✔ / ❌
✔ / ❌
Les fonctions spécifiques à MATCH_RECOGNIZE MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER() et CLASSIFIER() ne sont actuellement pas disponibles dans la sous-clause DEFINE .
Résolution des problèmes¶
Message d’erreur : « SELECT sans colonnes » lors de l’utilisation de ONE ROW PER MATCH¶
Lorsque vous utilisez la clause ONE ROW PER MATCH , seules les colonnes et expressions des sous-clauses PARTITION BY et MEASURES sont autorisées dans la clause de projection de SELECT. Si vous essayez d’utiliser MATCH_RECOGNIZE sans une clause PARTITION BY ou MEASURES , vous obtenez une erreur similaire à SELECT with no columns.
Pour plus d’informations sur ONE ROW PER MATCH et ALL ROWS PER MATCH, voir Génération d’une ligne pour chaque correspondance et génération de toutes les lignes pour chaque correspondance.
Exemples¶
Le sujet Identification des séquences de lignes qui correspondent à un modèle contient de nombreux exemples, dont certains sont plus simples que la plupart des exemples présentés ici. Si vous n’êtes pas déjà familiarisé avec MATCH_RECOGNIZE, il est préférable de lire ces exemples en premier.
Certains de ces exemples ci-dessous utilisent le tableau et les données suivants :
Le graphique suivant montre les formes des courbes :
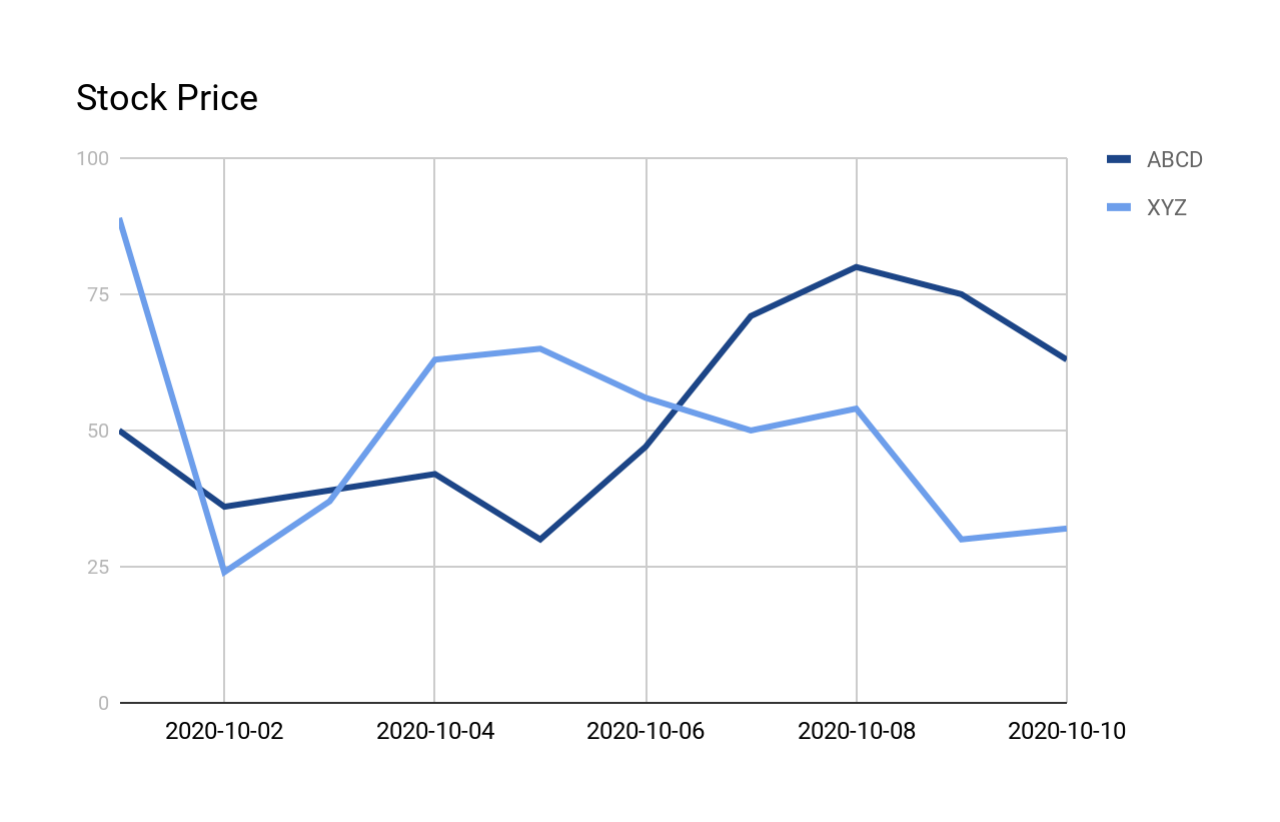
Signaler une ligne de résumé pour chaque forme V¶
La requête suivante recherche toutes les courbes V dans le stock_price_history présenté précédemment. La sortie est expliquée plus en détail après la requête et la sortie.
La sortie montre une ligne par correspondance (quel que soit le nombre de lignes faisant partie de la correspondance).
La sortie comprend les colonnes suivantes :
COMPANY : le symbole boursier de la société.
Le MATCH_NUMBER est un numéro séquentiel identifiant la correspondance dans cet ensemble de données (par exemple, la première correspondance a MATCH_NUMBER 1, la deuxième correspondance a MATCH_NUMBER 2, etc.) Si les données ont été partitionnées, alors le MATCH_NUMBER est le numéro séquentiel à l’intérieur de la partition (dans cet exemple, pour chaque société/action).
START_DATE : date à laquelle cette occurrence du modèle commence.
END_DATE : date à laquelle cette occurrence du modèle se termine.
ROWS_IN_SEQUENCE : nombre de lignes dans la correspondance. Par exemple, la première correspondance est basée sur les prix mesurés les 4 jours (du 1er octobre au 4 octobre), donc ROWS_IN_SEQUENCE est 4.
NUM_DECREASES : nombre de jours (dans la correspondance) où le prix a baissé. Par exemple, dans la première correspondance, le prix a baissé pendant 1 jour puis a augmenté pendant 2 jours, donc NUM_DECREASES est 1.
NUM_INCREASES : nombre de jours (dans la correspondance) où le prix a augmenté. Par exemple, dans la première correspondance, le prix a baissé pendant 1 jour puis a augmenté pendant 2 jours, donc NUM_INCREASES est 2.
Signaler toutes les lignes de toutes les correspondances d’une entreprise¶
Cet exemple renvoie toutes les lignes de chaque correspondance (et pas seulement une ligne de résumé par correspondance). Ce modèle recherche les prix en hausse de l’entreprise ABCD :
Omettre les correspondances vides¶
Ceci recherche les plages de prix supérieures à la moyenne de l’ensemble du graphique d’une entreprise. Cet exemple ne tient pas compte des correspondances vides. Notez, cependant, que les correspondances vides incrémentent néanmoins le MATCH_NUMBER :
Démontrer l’option WITH UNMATCHED ROWS¶
Cet exemple illustre WITH UNMATCHED ROWS option . Comme l’exemple Omettre les correspondances vides ci-dessus, cet exemple recherche les plages de prix supérieures au prix moyen du graphique de chaque entreprise. Notez que le quantificateur dans cette requête est +, alors que le quantificateur dans la requête précédente était * :
Démontrer des prédicats de symbole dans la clause MEASURES¶
Cet exemple montre l’utilisation de la notation de colonne <symbole>.<colonne> avec des prédicats de symbole :