Identification des séquences de lignes qui correspondent à un modèle¶
Introduction¶
Dans certains cas, vous pouvez avoir besoin d’identifier des séquences de lignes de table qui correspondent à un modèle. Par exemple, vous pourriez avoir besoin de :
Déterminer les utilisateurs qui ont suivi une séquence spécifique de pages et d’actions sur votre site Web avant d’ouvrir un ticket d’assistance ou de faire un achat.
Trouver les stocks dont les prix ont suivi une reprise en courbe de V ou de W sur une période donnée.
Rechercher des modèles dans les données des capteurs qui pourraient indiquer une défaillance prochaine du système.
Pour identifier les séquences de lignes qui correspondent à un modèle spécifique, utilisez la sous-clause MATCH_RECOGNIZE de la clause FROM .
Note
Vous ne pouvez pas utiliser la clause MATCH_RECOGNIZE dans une expression de table commune (CTE) **récursive**.
Un exemple simple qui identifie une séquence de lignes¶
À titre d’exemple, supposons qu’une table contienne des données sur les prix des actions. Chaque ligne contient le prix de clôture de chaque symbole boursier à une date donnée. La table contient les colonnes suivantes :
Nom de la colonne |
Description |
|---|---|
|
La date du prix de clôture. |
|
Le cours de clôture de l’action à cette date. |
Supposons que vous souhaitiez détecter un modèle dans lequel le prix de l’action diminue puis augmente, ce qui produit une forme en « V » dans le graphique du prix de l’action.
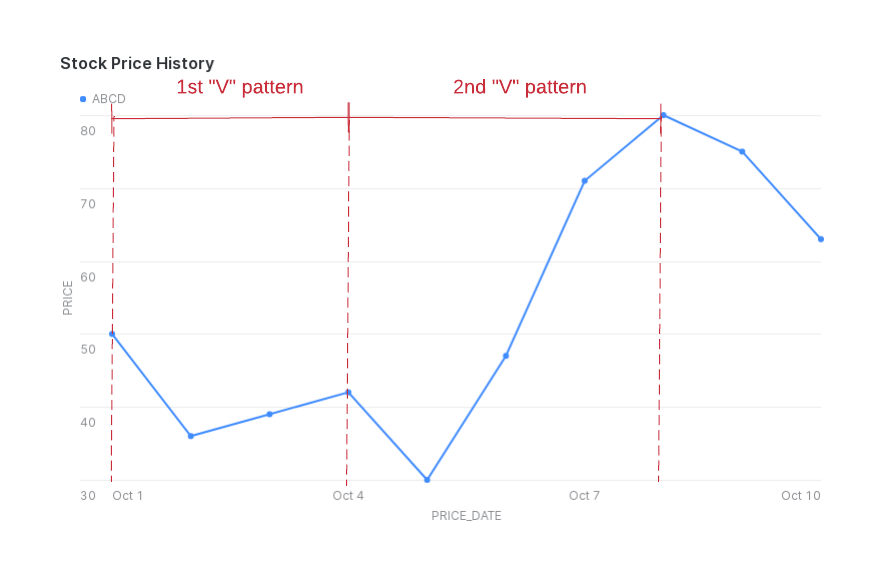
(Cet exemple ne tient pas compte des cas où le cours de l’action ne change pas d’un jour à l’autre).
Dans cet exemple, pour un symbole boursier donné, vous voulez trouver des séquences de lignes où la valeur de la colonne price diminue avant d’augmenter.
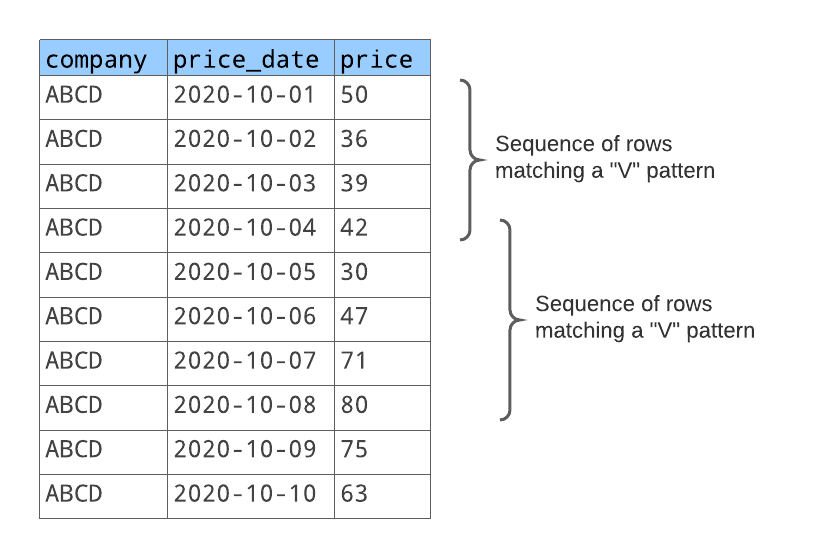
Pour chaque séquence de lignes qui correspond à ce modèle, vous voulez retourner :
Un numéro qui identifie la séquence (la première séquence correspondante, la seconde séquence correspondante, etc.)
La veille du jour où le prix de l’action a baissé.
Le dernier jour où le prix de l’action a augmenté.
Le nombre de jours du modèle en « V ».
Le nombre de jours où le prix de l’action a baissé.
Le nombre de jours où le prix de l’action a augmenté.
La figure suivante illustre les baisses (NUM_DECREASES) et les hausses (NUM_INCREASES) de prix à l’intérieur du modèle en « V » que les données retournées capturent. Notez que ROWS_IN_SEQUENCE comprend une ligne initiale qui n’est pas comptée dans NUM_DECREASES ou NUM_INCREASES.
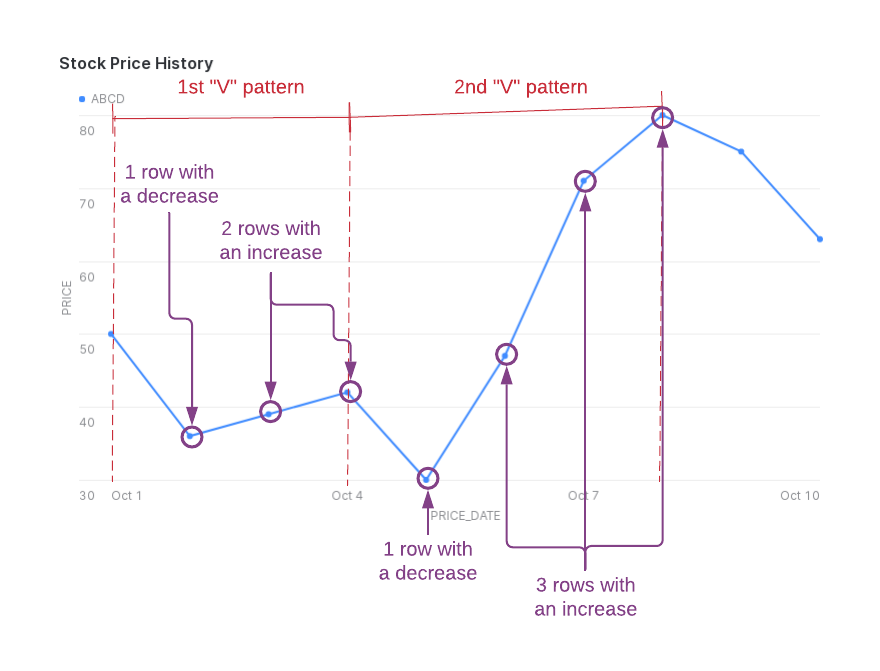
Pour produire cette sortie, vous pouvez utiliser la clause MATCH_RECOGNIZE présentée ci-dessous.
Comme nous l’avons vu plus haut, la clause MATCH_RECOGNIZE est constituée de nombreuses sous-clauses, chacune d’entre elles ayant un objectif différent (par exemple, spécifier le modèle à mettre en correspondance, spécifier les données à renvoyer, etc.)
Les sections suivantes expliquent chacune des sous-clauses de cet exemple.
Configuration des données pour cet exemple¶
Pour configurer les données utilisées dans cet exemple, exécutez les instructions SQL suivantes :
Étape 1 : Spécifier l’ordre et le regroupement des lignes¶
La première étape de l’identification d’une séquence de lignes consiste à définir le regroupement et l’ordre de tri des lignes que vous souhaitez rechercher. Exemple de recherche d’un modèle en « V » dans le cours de l’action d’une société :
Les lignes doivent être regroupées par entreprise, car vous souhaitez trouver une tendance dans le prix d’une entreprise donnée.
Dans chaque groupe de lignes (les prix pour une société donnée), les lignes doivent être triées par date dans l’ordre croissant.
Dans une clause MATCH_RECOGNIZE , vous utilisez les sous-clauses PARTITION BY et ORDER BY pour spécifier le regroupement et l’ordre des lignes. Par exemple :
Étape 2 : définition du modèle à mettre en correspondance¶
Ensuite, déterminez le modèle qui correspond à la séquence de lignes que vous voulez trouver.
Pour spécifier ce modèle, vous utilisez quelque chose de similaire à une expression régulière. Dans les expressions régulières, vous utilisez une combinaison de littéraux et de métacaractères pour spécifier un modèle à mettre en correspondance dans une chaîne.
Par exemple, pour trouver une séquence de caractères qui comprend :
tout caractère unique, suivi de
une ou plusieurs lettres majuscules, suivies de
une ou plusieurs lettres minuscules
vous pouvez utiliser l’expression régulière suivante, compatible avec Perl :
où :
.correspond à n’importe quel caractère unique.[A-Z]+correspond à une ou plusieurs lettres majuscules.[a-z]+correspond à une ou plusieurs lettres minuscules.
+ est un quantificateur qui spécifie qu’un ou plusieurs des caractères précédents doivent correspondre.
Par exemple, l’expression régulière ci-dessus correspond à des séquences de caractères comme :
1Stock@SFComputing%Fn
Dans une clause MATCH_RECOGNIZE , vous utilisez une expression similaire pour spécifier le modèle des lignes à mettre en correspondance. Dans ce cas, trouver des lignes qui correspondent à un modèle « V » implique de trouver une séquence de lignes qui comprend :
la ligne précédant la baisse du prix de l’action, suivie de
une ou plusieurs lignes où le prix de l’action diminue, suivies de
une ou plusieurs lignes où le prix de l’action augmente
Vous pouvez exprimer cela comme le modèle de ligne suivant :
Les modèles de lignes sont constitués de variables de modèle, de quantificateurs (qui sont similaires à ceux utilisés dans les expressions régulières), et d’opérateurs. Une variable de modèle définit une expression qui est évaluée par rapport à une ligne.
Dans ce modèle de ligne :
row_before_decrease,row_with_price_decrease, etrow_with_price_increasesont des variables de modèle. Les expressions pour ces variables de modèle doivent être évaluées à :n’importe quelle ligne (la ligne avant la baisse du prix de l’action)
une ligne où le prix de l’action diminue
une ligne où le prix de l’action augmente
row_before_decreaseest similaire à.dans une expression régulière. Dans l’expression régulière suivante,.correspond à tout caractère unique qui apparaît avant la première lettre majuscule du modèle.De même, dans le modèle de ligne,
row_before_decreasecorrespond à toute ligne unique qui apparaît avant la première ligne avec une baisse de prix.Les quantificateurs
+aprèsrow_with_price_decreaseetrow_with_price_increasespécifient qu’une ou plusieurs lignes de chacun de ces éléments doivent correspondre.
Dans une clause MATCH_RECOGNIZE , vous utilisez la sous-clause PATTERN pour spécifier le modèle de ligne à mettre en correspondance :
Pour spécifier les expressions des variables de modèles, vous utilisez la sous-clause DEFINE :
où :
row_before_decreasen’a pas besoin d’être défini ici car il doit être évalué à n’importe quelle ligne.row_with_price_decreaseest définie comme une expression pour une ligne avec une baisse de prix.row_with_price_increaseest définie comme l’expression d’une ligne avec une augmentation de prix.
Pour comparer les prix de différentes lignes, les définitions de ces variables utilisent la fonction de navigation LAG() pour spécifier le prix de la ligne précédente.
Le modèle de ligne correspond à deux séquences de lignes, comme illustré ci-dessous :

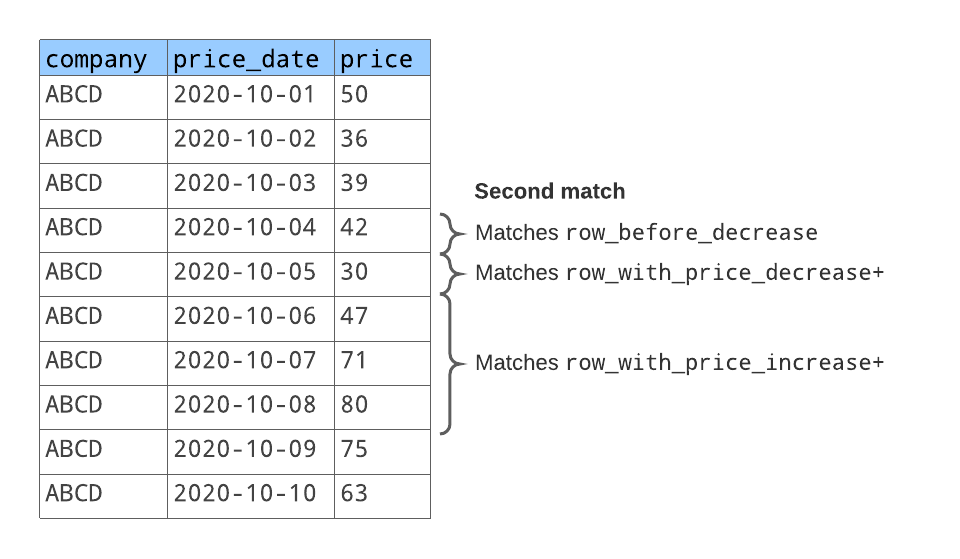
Pour la première séquence de lignes correspondantes :
row_before_decreasecorrespond à la ligne avec le prix de l’action50.row_with_price_decreasecorrespond à la ligne suivante avec le prix de l’action36.row_with_price_increasecorrespond aux deux lignes suivantes avec les prix des actions39et42.
Pour la deuxième séquence de lignes correspondantes :
row_before_decreasecorrespond à la ligne avec le prix de l’action42. (Il s’agit de la même ligne qui se trouve à la fin de la première séquence de lignes correspondante).row_with_price_decreasecorrespond à la ligne suivante avec le prix de l’action30.row_with_price_increasecorrespond aux deux lignes suivantes avec les prix des actions47,71, et80.
Étape 3 : spécification des lignes à retourner¶
MATCH_RECOGNIZE peut soit retourner :
une seule ligne qui résume chaque séquence correspondante, ou
chaque ligne de chaque séquence correspondante
Dans cet exemple, vous voulez renvoyer un résumé de chaque séquence correspondante. Utilisez la sous-clause ONE ROW PER MATCH pour spécifier qu’une ligne doit être retournée pour chaque séquence correspondante.
Étape 4 : spécification des mesures à sélectionner¶
Lorsque vous utilisez ONE ROW PER MATCH, MATCH_RECOGNIZE ne renvoie aucune des colonnes de la table (à l’exception de la colonne spécifiée par PARTITION BY), même si MATCH_RECOGNIZE se trouve dans une instruction SELECT *. Pour spécifier les données à renvoyer par cette instruction, vous devez définir des mesures. Les mesures sont des colonnes de données supplémentaires qui sont calculées pour chaque séquence de lignes correspondante (par exemple, la date de début de la séquence, la date de fin de la séquence, le nombre de jours dans la séquence, etc.)
Utilisez la sous-clause MEASURES pour spécifier ces colonnes supplémentaires à retourner dans la sortie. Le format général pour définir une mesure est le suivant :
où :
expressionspécifie l’information sur la séquence que vous voulez retourner. Pour l’expression, vous pouvez utiliser des fonctions avec les colonnes de la table et les variables de modèle que vous avez définies précédemment.column_namespécifie le nom de la colonne qui sera retournée dans la sortie.
Pour cet exemple, vous pouvez définir les mesures suivantes :
Un numéro qui identifie la séquence (la première séquence correspondante, la seconde séquence correspondante, etc.)
Pour cette mesure, utilisez la fonction
MATCH_NUMBER(), qui renvoie le numéro de la correspondance. Les numéros commencent par1pour la première correspondance pour une partition de lignes. S’il y a plusieurs partitions, le numéro commence par1pour chaque partition.La veille du jour où le prix de l’action a baissé.
Pour cette mesure, utilisez la fonction
FIRST(), qui renvoie la valeur de l’expression pour la première ligne de la séquence correspondante. Dans cet exemple,FIRST(price_date)renvoie la valeur de la colonneprice_datede la première ligne de chaque séquence correspondante, qui correspond à la date précédant la baisse du cours de l’action.Le dernier jour où le prix de l’action a augmenté.
Pour cette mesure, utilisez la fonction
LAST(), qui renvoie la valeur de l’expression pour la dernière ligne de la séquence correspondante.Le nombre de jours du modèle en « V ».
Pour cette mesure, utilisez
COUNT(*). Comme vous spécifiezCOUNT(*)dans la définition d’une mesure, l’astérisque (*) indique que vous voulez compter toutes les lignes d’une séquence correspondante (et non toutes les lignes de la table).Le nombre de jours où le stock a diminué.
Pour cette mesure, utilisez
COUNT(row_with_price_decrease.*). La période suivie d’un astérisque (.*) indique que vous voulez compter toutes les lignes d’une séquence correspondante qui correspondent à la variable de modèlerow_with_price_decrease.Le nombre de jours où le stock a augmenté.
Pour cette mesure, utilisez
COUNT(row_with_price_increase.*).
Voici la sous-clause MEASURES qui définit les mesures ci-dessus :
La figure suivante montre un exemple de sortie avec les mesures sélectionnées :
Comme mentionné précédemment, la sortie inclut la colonne company car la clause PARTITION BY spécifie cette colonne.
Étape 5 : spécification du moment où poursuivre la recherche de la correspondance suivante¶
Après avoir trouvé une séquence de lignes correspondante, MATCH_RECOGNIZE continue de rechercher la séquence correspondante suivante. Vous pouvez spécifier où MATCH_RECOGNIZE doit commencer à chercher la séquence correspondante suivante.
Comme le montre l’illustration des séquences correspondantes, une ligne peut faire partie de plus d’une séquence correspondante. Dans cet exemple, la ligne pour 2020-10-04 fait partie de deux modèles en « V ».
Dans cet exemple, pour trouver la séquence correspondante suivante, vous pouvez commencer par une ligne où le prix a augmenté. Pour spécifier ceci dans la clause MATCH_RECOGNIZE , utilisez AFTER MATCH SKIP :
où TO LAST row_with_price_increase indique que vous voulez commencer la recherche à la dernière ligne où le prix a augmenté.
Partitionnement et tri des lignes¶
La première étape de l’identification des modèles entre les lignes consiste à placer les lignes dans un ordre qui vous permette de trouver vos modèles. Par exemple, si vous voulez trouver un modèle d’évolution des prix des actions dans le temps pour les actions de chaque société :
Partitionnez les lignes par société, de manière à pouvoir effectuer des recherches sur les cours des actions de chaque société.
Triez les lignes de chaque partition par date, de manière à trouver les modifications du cours de l’action d’une société dans le temps.
Pour partitionner les données et spécifier l’ordre des lignes, utilisez les sous-clauses PARTITION BY et ORDER BY de MATCH_RECOGNIZE. Par exemple :
(La clause PARTITION BY pour MATCH_RECOGNIZE fonctionne de la même manière que la clause PARTITION BY pour les fonctions de fenêtre.)
Un avantage supplémentaire du partitionnement est qu’il permet de tirer parti du traitement parallèle.
Définition du modèle de lignes à mettre en correspondance¶
Avec MATCH_RECOGNIZE, vous pouvez trouver une séquence de lignes qui correspondent à un modèle. Vous spécifiez ce modèle en termes de lignes qui correspondent à des conditions spécifiques.
Dans l’exemple de la table des cours quotidiens des actions de différentes sociétés, supposons que vous souhaitiez trouver une séquence de trois lignes dans laquelle :
Un jour donné, le cours de l’action d’une société est inférieur à 45,00.
Le jour suivant, le prix de l’action diminue d’au moins 10 %.
Le jour suivant, le cours de l’action augmente d’au moins 3 %.
Pour trouver cette séquence, vous spécifiez un modèle qui correspond à trois lignes avec les conditions suivantes :
Dans la première ligne de la séquence, la valeur de la colonne
pricedoit être inférieure à 45,00.Dans la deuxième ligne, la valeur de la colonne
pricedoit être inférieure ou égale à 90 % de la valeur de la ligne précédente.Dans la troisième ligne, la valeur de la colonne
pricedoit être supérieure ou égale à 105 % de la valeur de la ligne précédente.
Les deuxième et troisième lignes comportent des conditions qui exigent une comparaison entre les valeurs des colonnes de différentes lignes. Pour comparer la valeur d’une ligne à celle de la ligne précédente ou suivante, utilisez les fonctions LAG() ou LEAD() :
LAG(column)renvoie la valeur decolumndans la ligne précédente.LEAD(column)renvoie la valeur decolumndans la ligne suivante.
Pour cet exemple, vous pouvez spécifier les conditions pour les trois lignes comme suit :
La première ligne de la séquence doit avoir
price < 45.00.La deuxième ligne doit avoir
LAG(price) * 0.90 >= price.La troisième ligne doit avoir
LAG(price) * 1.05 <= price.
Lorsque vous spécifiez le modèle pour la séquence de ces trois lignes, vous utilisez une variable de modèle pour chaque ligne qui présente une condition différente. Utilisez la sous-clause DEFINE pour définir chaque variable de modèle comme une ligne qui doit répondre à une condition spécifiée. L’exemple suivant définit trois variables de modèle pour les trois lignes :
Pour définir le modèle lui-même, utilisez la sous-clause PATTERN . Dans cette sous-clause, utilisez une expression régulière pour spécifier le modèle à mettre en correspondance. Pour les blocs de construction de l’expression, utilisez les variables de modèle que vous avez définies. Par exemple, le modèle suivant trouve la séquence de trois lignes :
L’instruction SQL ci-dessous utilise les sous-clauses DEFINE et PATTERN présentées ci-dessus :
Les sections suivantes expliquent comment définir des motifs qui correspondent à des numéros spécifiques de lignes et à des lignes qui apparaissent au début ou à la fin d’une partition.
Note
MATCH_RECOGNIZE utilise le retour sur trace pour rapprocher les motifs Comme c’est le cas avec d’autres moteurs d’expression régulière utilisant le retour sur trace, certaines combinaisons de motifs et de données à rapprocher peuvent prendre plus longtemps à s’exécuter, ce qui peut provoquer des coûts de calcul plus élevés.
Pour améliorer les performances, définissez un motif le plus spécifique possible :
Assurez-vous que chaque ligne corresponde à un seul symbole ou un petit nombre de symboles
Évitez d’utiliser des symboles qui correspondent à chaque ligne (par exemple des symboles non présents dans la clause
DEFINEou des symboles définis comme vrais)Définissez une limite supérieure pour les quantificateurs (par exemple
{,10}au lieu de*).
Par exemple, le motif suivant peut augmenter les coûts si aucune ligne ne correspond :
S’il existe une limite supérieure pour le nombre de lignes que vous souhaitez faire correspondre, vous pouvez indiquer cette limite dans les quantificateurs pour améliorer les performances. En outre, au lieu d’indiquer que vous souhaitez trouver any_symbol qui suit symbol1, vous pouvez rechercher une ligne qui n’est pas symbol1 (not_symbol1 dans cet exemple) :
En général, il est conseillé de surveiller la durée d’exécution de la requête pour vérifier que cela ne prend pas plus de temps que prévu.
Utilisation de quantificateurs avec des variables de modèle¶
Dans la sous-clause PATTERN, vous utilisez une expression régulière pour spécifier un modèle de lignes à mettre en correspondance. Vous utilisez des variables de modèle pour identifier les lignes de la séquence qui répondent à des conditions spécifiques.
Si vous devez faire correspondre plusieurs lignes qui répondent à une condition spécifique, vous pouvez utiliser un quantificateur, comme vous le feriez dans une expression régulière.
Par exemple, vous pouvez utiliser le quantificateur + pour spécifier que le modèle doit inclure une ou plusieurs lignes dans lesquelles le prix de l’action diminue de 10 %, suivies d’une ou plusieurs lignes dans lesquelles le prix de l’action augmente de 5 % :
Mise en correspondance des modèles par rapport au début ou à la fin d’une partition¶
Pour trouver une séquence de lignes relative au début ou à la fin d’une partition, vous pouvez utiliser les métacaractères ^ et $ dans la sous-clause PATTERN . Ces métacaractères dans un modèle de ligne ont une fonction similaire à celle des mêmes métacaractères dans une expression régulière:
^représente le début d’une partition.$représente la fin d’une partition.
Le modèle suivant correspond à une action dont le prix est supérieur à 75,00 au début de la partition :
Notez que ^ et $ spécifient des positions et ne représentent pas les lignes à ces positions (tout comme ^ et $ dans une expression régulière spécifient la position et non les caractères à ces positions). Dans PATTERN (^ GT75), la première ligne (pas la deuxième) doit avoir un prix supérieur à 75,00. Dans PATTERN (GT75 $), la dernière ligne (et non l’avant-dernière ligne) doit être supérieure à 75.
Voici un exemple complet avec ^. Notez que bien que l’action XYZ ait un prix supérieur à 60,00 dans plus d’une ligne de cette partition, seule la ligne au début de la partition est considérée comme une correspondance.
Voici un exemple complet avec $. Notez que bien que l’action ABCD ait un prix supérieur à 50,00 dans plus d’une ligne de cette partition, seule la ligne à la fin de la partition est considérée comme une correspondance.
Spécification des lignes de sortie¶
Les instructions qui utilisent MATCH_RECOGNIZE peuvent choisir les lignes à sortir.
Génération d’une ligne pour chaque correspondance et génération de toutes les lignes pour chaque correspondance¶
Lorsque MATCH_RECOGNIZE trouve une correspondance, la sortie peut être soit une ligne de résumé pour l’ensemble de la correspondance, soit une ligne pour chaque point de données du modèle.
ALL ROWS PER MATCHspécifie que la sortie inclut toutes les lignes de la correspondance.ONE ROW PER MATCHspécifie que la sortie inclut une seule ligne pour chaque correspondance dans chaque partition.La clause de projection de l’instruction SELECT ne peut utiliser que la sortie de l’instruction
MATCH_RECOGNIZE. En fait, cela signifie que l’instruction SELECT ne peut utiliser que les colonnes des sous-clauses suivantes deMATCH_RECOGNIZE:La sous-clause
PARTITION BY.Toutes les lignes d’une correspondance proviennent de la même partition, et ont donc la même valeur pour les expressions de la sous-clause
PARTITION BY.La clause
MEASURES.Lorsque vous utilisez
MATCH_RECOGNIZE ... ONE ROW PER MATCH, la sous-clauseMEASURESgénère non seulement des expressions qui renvoient la même valeur pour toutes les lignes de la correspondance (par exemple,MATCH_NUMBER()), mais aussi des expressions qui peuvent renvoyer des valeurs différentes pour différentes lignes de la correspondance (par exemple,MATCH_SEQUENCE_NUMBER()). Si vous utilisez des expressions qui peuvent renvoyer des valeurs différentes pour différentes lignes de la correspondance, la sortie n’est pas déterministe.
Si vous êtes familier avec les fonctions agrégées et
GROUP BY, l’analogie suivante pourrait vous aider à comprendreONE ROW PER MATCH:La clause
PARTITION BYdeMATCH_RECOGNIZEregroupe les données de la même manière queGROUP BYregroupe les données dans unSELECT.La clause
MEASURESdansMATCH_RECOGNIZE ... ONE ROW PER MATCHautorise les fonctions d’agrégation, telles queCOUNT(), qui renvoient la même valeur pour chaque ligne de la correspondance, comme le faitMATCH_NUMBER().
Si vous utilisez uniquement des fonctions d’agrégation et des expressions qui renvoient la même valeur pour chaque ligne de la correspondance, alors
... ONE ROW PER MATCHse comporte de la même manière queGROUP BYet les fonctions d’agrégation.
La valeur par défaut est ONE ROW PER MATCH.
Les exemples suivants montrent la différence de sorties entre ONE ROW PER MATCH et ALL ROWS PER MATCH. Ces deux exemples de code sont presque identiques, à l’exception de la clause ...ROW(S) PER MATCH . (Dans un usage typique, une instruction SQL avec ONE ROW PER MATCH a des sous-clauses MEASURES différentes de celles d’une instruction SQL avec ALL ROWS PER MATCH).
Exclusion de lignes de la sortie¶
Pour certaines requêtes, vous pouvez souhaiter n’inclure qu’une partie du modèle dans la sortie. Par exemple, vous pouvez rechercher des modèles dans lesquels les actions ont augmenté plusieurs jours de suite, mais n’afficher que les pics et quelques informations sommaires (par exemple, le nombre de jours de hausse des prix avant chaque pic).
Vous pouvez utiliser une syntaxe d’exclusion dans le modèle pour indiquer à MATCH_RECOGNIZE de rechercher une variable particulière du modèle mais de ne pas l’inclure dans la sortie. Pour inclure une variable de modèle dans le modèle à rechercher, mais pas dans la sortie, utilisez la notation {- <variable_de_modèle> -} .
Voici un exemple simple qui montre la différence entre l’utilisation de la syntaxe d’exclusion et sa non-utilisation. Cet exemple contient deux requêtes, chacune recherchant un prix d’action qui a commencé à moins de 45 $, puis qui a diminué, puis qui a augmenté. La première requête n’utilise pas la syntaxe d’exclusion, et montre donc toutes les lignes. La deuxième requête utilise la syntaxe d’exclusion et ne montre pas le jour où le prix de l’action a baissé.
L’exemple suivant est plus réaliste. Il recherche les modèles dans lesquels le cours d’une action a augmenté un ou plusieurs jours de suite, puis a baissé un ou plusieurs jours de suite. Comme la sortie peut être très importante, on utilise l’exclusion pour ne montrer que le premier jour de hausse de l’action (si elle a augmenté plus d’un jour de suite) et que le premier jour de baisse (si elle a baissé plus d’un jour de suite). Le modèle est présenté ci-dessous :
Ce modèle recherche les événements suivants dans l’ordre :
Un prix de départ inférieur à 45.
Une augmentation (UP) , éventuellement suivie immédiatement par d’autres qui ne sont pas incluses dans la sortie.
Une diminution (DOWN), éventuellement suivie immédiatement par d’autres qui ne sont pas incluses dans la sortie.
Voici le code et la sortie pour les versions du modèle précédent sans exclusion et avec exclusion :
Renvoi d’informations sur la correspondance¶
Informations de base sur les correspondances¶
Dans de nombreux cas, vous souhaitez que votre requête affiche non seulement les informations de la table qui contient les données, mais aussi les informations sur les modèles qui ont été trouvés. Lorsque vous voulez des informations sur les correspondances elles-mêmes, vous les spécifiez dans la clause MEASURES .
La clause MEASURES peut inclure les fonctions suivantes, qui sont spécifiques à MATCH_RECOGNIZE :
MATCH_NUMBER(): chaque fois qu’une correspondance est trouvée, on lui attribue un numéro de correspondance séquentiel, en commençant par un. Cette fonction renvoie ce numéro de correspondance.MATCH_SEQUENCE_NUMBER(): parce qu’un modèle implique généralement plus d’un point de données, vous pourriez vouloir savoir quel point de données est associé à chaque valeur de la table. Cette fonction renvoie le numéro séquentiel du point de données dans la correspondance.CLASSIFIER(): le classificateur est le nom de la variable de modèle à laquelle la ligne correspond.
La requête ci-dessous comprend une clause MEASURES avec le numéro de correspondance, le numéro de séquence de correspondance et le classificateur.
La sous-clause MEASURES peut produire beaucoup plus d’informations que cela. Pour plus de détails, voir la documentation de référence MATCH_RECOGNIZE.
Fenêtres, cadres de fenêtre et fonctions de navigation¶
La clause MATCH_RECOGNIZE opère sur une « fenêtre » de lignes. Si MATCH_RECOGNIZE contient une sous-clause PARTITION , alors chaque partition est une fenêtre. S’il n’y a pas de sous-clause PARTITION , alors l’entrée entière est une fenêtre.
La sous-clause PATTERN de MATCH_RECOGNIZE spécifie les symboles dans l’ordre de gauche à droite. Par exemple :
Si vous vous représentez les données comme une séquence de lignes en ordre croissant de gauche à droite, vous pouvez considérer que MATCH_RECOGNIZE se déplace vers la droite (par exemple, de la date la plus ancienne à la date la plus récente dans l’exemple du cours de l’action), en recherchant un modèle dans les lignes à l’intérieur de chaque fenêtre.
MATCH_RECOGNIZE commence par la première ligne de la fenêtre et vérifie si cette ligne et les lignes suivantes correspondent au modèle.
Dans le cas le plus simple, après avoir déterminé s’il y a une correspondance de modèle à partir de la première ligne de la fenêtre, MATCH_RECOGNIZE se déplace d’une ligne vers la droite et répète le processus, en vérifiant si la 2e ligne est le début d’une occurrence du modèle. MATCH_RECOGNIZE continue à se déplacer vers la droite jusqu’à atteindre la fin de la fenêtre.
(MATCH_RECOGNIZE peut se déplacer vers la droite de plus d’une ligne. Par exemple, vous pouvez dire à MATCH_RECOGNIZE de commencer à rechercher le modèle suivant après la fin du modèle actuel).
Vous pouvez vous représenter cela comme s’il y avait un « cadre » se déplaçant vers la droite à l’intérieur de la fenêtre. Le bord gauche de ce cadre se trouve à la première ligne de l’ensemble des lignes pour lequel une correspondance est en cours de vérification. Le bord droit du cadre n’est pas défini tant qu’une correspondance n’est pas trouvée ; une fois qu’une correspondance est trouvée, le bord droit du cadre est la dernière ligne de la correspondance. Par exemple, si le modèle de recherche est pattern (start down up), la ligne qui correspond à up est la dernière ligne avant le bord droit du cadre.
(Si aucune correspondance n’est trouvée, alors le bord droit du cadre n’est jamais défini et n’est jamais référencé).
Dans les cas simples, vous pouvez imaginer un cadre de fenêtre coulissant comme illustré ci-dessous :
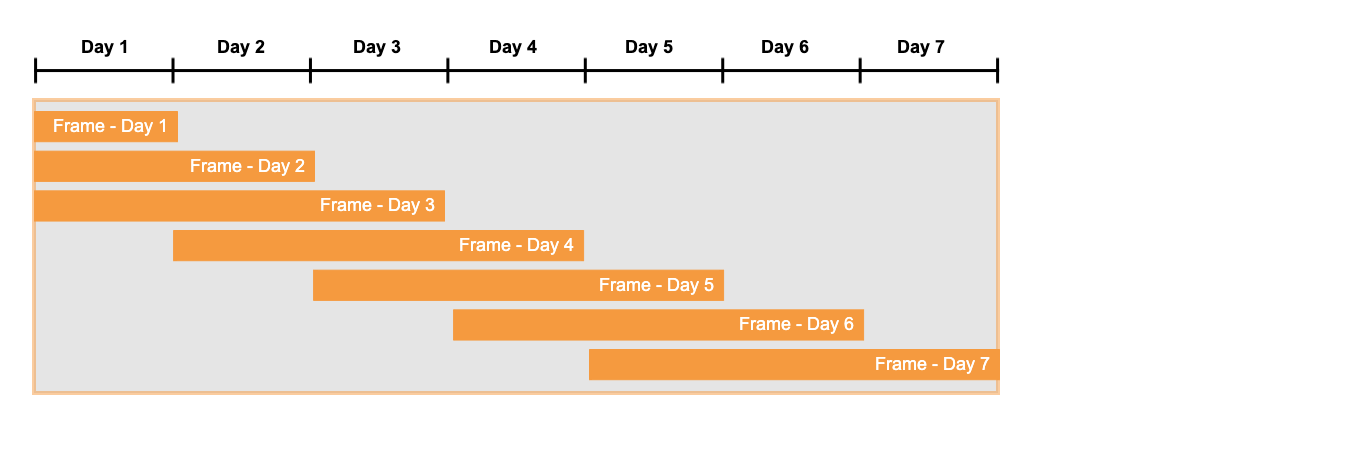
Vous avez déjà vu les fonctions de navigation telles que LAG() utilisées dans des expressions de la sous-clause DEFINE (par exemple DEFINE down_10_percent as LAG(price) * 0.9 >= price). La requête suivante montre que les fonctions de navigation peuvent également être utilisées dans la sous-clause MEASURES . Dans cet exemple, les fonctions de navigation indiquent les bords (et donc la taille) du cadre de la fenêtre qui contient la correspondance actuelle.
Chaque ligne de sortie de cette requête comprend les valeurs des fonctions de navigation LAG(), LEAD(), FIRST() et LAST() pour cette ligne. La taille du cadre de la fenêtre est le nombre de lignes entre FIRST() et LAST(), y compris la première et la dernière ligne elles-mêmes.
Les clauses DEFINE et PATTERN de la requête ci-dessous sélectionnent des groupes de trois lignes (1-3 octobre, 2-4 octobre, 3-5 octobre, etc.)
La sortie de cette requête montre également que les fonctions LAG() et LEAD() renvoient NULL pour les expressions qui tentent de référencer des lignes en dehors du groupe de correspondance (c’est-à-dire en dehors du cadre de la fenêtre).
Les règles relatives aux fonctions de navigation dans les clauses DEFINE sont légèrement différentes des règles relatives aux fonctions de navigation dans les clauses MEASURES . Par exemple, la fonction PREV() est disponible dans la clause MEASURES mais ne l’est pas actuellement dans la clause DEFINE. Au lieu de cela, vous pouvez utiliser LAG() dans la clause DEFINE. La documentation de référence pour MATCH_RECOGNIZE affiche la règle correspondante pour chaque fonction de navigation.
La sous-clause MEASURES peut également inclure les éléments suivants :
Fonctions d’agrégation. Par exemple, si le modèle peut correspondre à un nombre variable de lignes (par exemple, parce qu’il correspond à 1 ou à un plus grand nombre de cours boursiers en baisse), vous voudrez peut-être connaître le nombre total de lignes dans la correspondance ; vous pouvez afficher cette information en utilisant
COUNT(*).Expressions générales qui opèrent sur les valeurs de chaque ligne de la correspondance. Il peut s’agir d’expressions mathématiques, d’expressions logiques, etc. Par exemple, vous pouvez examiner les valeurs de la ligne et imprimer des descripteurs de texte tels que « ABOVE AVERAGE ».
N’oubliez pas que si vous regroupez des lignes (
ONE ROW PER MATCH), et si une colonne a des valeurs différentes pour différentes lignes du groupe, la valeur sélectionnée pour cette colonne pour cette correspondance est non déterministe, et les expressions basées sur cette valeur sont également susceptibles d’être non déterministes.
Pour plus d’informations sur la sous-clause MEASURES , voir la documentation de référence pour MATCH_RECOGNIZE.
Spécification du moment où rechercher la correspondance suivante¶
Par défaut, après que MATCH_RECOGNIZE a trouvé une correspondance, il commence à chercher la correspondance suivante immédiatement après la fin de la correspondance la plus récente. Par exemple, si MATCH_RECOGNIZE trouve une correspondance dans les lignes 2, 3 et 4, MATCH_RECOGNIZE commence à chercher la correspondance suivante à la ligne 5. Cela permet d’éviter le chevauchement des correspondances.
Toutefois, vous pouvez choisir d’autres points de départ.
Prenons les données suivantes :
Supposons que vous recherchiez dans les données un modèle W (bas, haut, bas-haut). Il y a trois formes W :
Mois : 1, 2, 3, 4, et 5.
Mois : 3, 4, 5, 6, et 7.
Mois : 5, 6, 7, 8, et 9.
Vous pouvez utiliser la clause SKIP pour spécifier si vous voulez tous les modèles, ou seulement les modèles qui ne se chevauchent pas. La clause SKIP prend également en charge d’autres options. La clause SKIP est documentée plus en détail dans MATCH_RECOGNIZE.
Meilleures pratiques¶
Incluez une clause ORDER BY dans votre clause
MATCH_RECOGNIZE.N’oubliez pas que cette clause ORDER BY ne s’applique qu’à l’intérieur de la clause
MATCH_RECOGNIZE. Si vous souhaitez que la requête entière renvoie les résultats dans un ordre spécifique, utilisez une clauseORDER BYsupplémentaire au niveau le plus externe de la requête.
Noms des variables du modèle :
Utilisez des noms de variables de modèles significatifs pour rendre vos modèles plus faciles à comprendre et à déboguer.
Vérifiez l’absence d’erreurs typographiques dans les noms de variables de modèle dans les clauses
PATTERNetDEFINE.
Évitez d’utiliser les valeurs par défaut pour les sous-clauses qui ont des valeurs par défaut. Rendez vos choix explicites.
Testez votre modèle avec un petit échantillon de données avant de l’étendre à l’ensemble de vos données.
MATCH_NUMBER(),MATCH_SEQUENCE_NUMBER()etCLASSIFIER()sont très utiles pour le débogage.Envisagez d’utiliser une clause
ORDER BYdans le niveau le plus externe de la requête pour forcer la sortie à être dans l’ordre en utilisantMATCH_NUMBER()etMATCH_SEQUENCE_NUMBER(). Si les données de sortie sont dans un autre ordre, la sortie peut sembler ne pas correspondre au modèle.
Éviter les erreurs d’analyse¶
Corrélation et causalité¶
La corrélation ne garantit pas la causalité. MATCH_RECOGNIZE peut renvoyer des « faux positifs » (cas où vous voyez un modèle, mais il s’agit juste d’une coïncidence).
La mise en correspondance de modèles peut également donner lieu à des « faux négatifs » (cas où il existe un modèle dans le monde réel, mais où ce modèle n’apparaît pas dans l’échantillon de données).
Dans la plupart des cas, trouver une correspondance (par exemple, trouver un modèle qui suggère une fraude à l’assurance) n’est que la première étape d’une analyse.
Les facteurs suivants augmentent généralement le nombre de faux positifs :
De grands ensembles de données.
Recherche d’un grand nombre de modèles.
Recherche de modèles courts ou simples.
Les facteurs suivants augmentent généralement le nombre de faux négatifs.
Petits ensembles de données.
Ne pas rechercher tous les modèles pertinents possibles.
Une recherche de modèles plus complexes que nécessaire.
Modèles insensibles à l’ordre¶
Bien que la plupart des correspondances de modèles exigent que les données soient dans l’ordre (par exemple, classées par heure), il existe des exceptions. Par exemple, si une personne commet une fraude à l’assurance à la fois lors d’un accident de voiture et lors d’un cambriolage, l’ordre dans lequel les fraudes se produisent importe peu.
Si le modèle que vous recherchez n’est pas sensible à l’ordre, vous pouvez utiliser des opérateurs tels que « alternative » (|) et PERMUTE pour rendre vos recherches moins sensibles à l’ordre.
Exemples¶
Cette section contient des exemples supplémentaires.
Vous trouverez d’autres exemples dans MATCH_RECOGNIZE.
Trouver des augmentations de prix sur plusieurs jours¶
La requête suivante trouve tous les modèles dans lesquels le prix de la société ABCD a augmenté deux jours de suite :
Démontrer l’opérateur PERMUTE¶
Cet exemple illustre l’opérateur PERMUTE dans le modèle. Recherchez tous les pics à la hausse et à la baisse dans les graphiques en limitant à deux le nombre de prix en hausse :
Démontrer l’option SKIP TO NEXT ROW¶
Cet exemple illustre l’option SKIP TO NEXT ROW . Cette requête recherche les courbes en W dans le graphique de chaque entreprise. Les correspondances peuvent se chevaucher.
Syntaxe d’exclusion¶
Cet exemple montre la syntaxe d’exclusion dans le modèle. Ce modèle (comme le modèle précédent) recherche les courbes W , mais la sortie de cette requête exclut les prix en baisse. Notez que dans cette requête, la correspondance se poursuit au-delà de la dernière ligne d’une correspondance :
Recherche de modèles dans des lignes non adjacentes¶
Dans certaines situations, vous pouvez rechercher des modèles dans des lignes non contiguës. Par exemple, si vous analysez des fichiers journaux, vous pouvez rechercher tous les modèles dans lesquels une erreur fatale a été précédée d’une séquence particulière d’avertissements. Il se peut qu’il n’existe pas de moyen naturel de partitionner et de trier les lignes de manière à ce que tous les messages pertinents (lignes) se trouvent dans une seule fenêtre et soient adjacents. Dans cette situation, vous pouvez avoir besoin d’un modèle qui recherche des événements particuliers, mais qui n’exige pas que les événements soient contigus dans les données.
Vous trouverez ci-dessous un exemple de clauses DEFINE et PATTERN qui reconnaissent des lignes contiguës ou non contiguës correspondant au modèle. Le symbole ANY_ROW est défini comme TRUE (il correspond donc à n’importe quelle ligne). Le * après chaque occurrence de ANY_ROW indique d’autoriser 0 ou plus d’occurrences de ANY_ROW entre le premier avertissement et le deuxième avertissement, et entre le deuxième avertissement et le message d’erreur fatale. Ainsi, le modèle complet indique qu’il faut rechercher WARNING1, suivi d’un nombre quelconque de lignes, puis de WARNING2, suivi d’un nombre quelconque de lignes, puis de FATAL_ERROR. Pour omettre les lignes non pertinentes de la sortie, la requête utilise la syntaxe exclusion ({- et -}).
Résolution des problèmes¶
Erreurs lors de l’utilisation de ONE ROW PER MATCH et de la spécification de colonnes dans la clause de sélection¶
La clause ONE ROW PER MATCH agit de la même manière qu’une fonction d’agrégation. Cela limite les colonnes de sortie que vous pouvez utiliser. Par exemple, si vous utilisez ONE ROW PER MATCH et que chaque correspondance contient trois lignes avec des dates différentes, vous ne pouvez pas spécifier la colonne date comme colonne de sortie dans la clause SELECT car aucune date n’est correcte pour les trois lignes.
Résultats inattendus¶
Vérifiez les erreurs typographiques dans les clauses
PATTERNetDEFINE.Si le nom d’une variable de modèle utilisée dans la clause
PATTERNn’est pas défini dans la clauseDEFINE(par exemple parce que le nom est mal saisi dans la clausePATTERNouDEFINE), aucune erreur n’est signalée. Au lieu de cela, le nom de la variable de modèle est simplement supposé être vrai pour chaque ligne.Examinez la clause
SKIPpour vous assurer qu’elle est appropriée, par exemple pour inclure ou exclure les modèles qui se chevauchent.