- Kategorien:
MATCH_RECOGNIZE¶
Erkennt Übereinstimmungen eines Musters in einer Menge von Zeilen. MATCH_RECOGNIZE akzeptiert eine Menge von Zeilen (aus einer Tabelle, Ansicht, Unterabfrage oder einer anderen Quelle) als Eingabe und gibt alle Übereinstimmungen für ein gegebenes Zeilenmuster innerhalb dieser Menge zurück. Das Muster wird ähnlich wie ein regulärer Ausdruck definiert.
Die Klausel kann Folgendes zurückgeben:
Alle Zeilen, die zu jeder Übereinstimmung gehören oder
Eine Zusammenfassungszeile pro Übereinstimmung.
MATCH_RECOGNIZE wird typischerweise verwendet, um Ereignisse in Zeitreihen zu erkennen. Beispielsweise kann MATCH_RECOGNIZE in einer Aktienkursverlaufstabelle nach Formen wie V (abwärts gefolgt von aufwärts) oder W (abwärts, aufwärts, abwärts, aufwärts) suchen.
MATCH_RECOGNIZE ist eine optionale Unterklausel der FROM-Klausel.
Bemerkung
Sie können die MATCH_RECOGNIZE-Klausel nicht in einem rekursiven allgemeinen Tabellenausdruck verwenden.
Syntax¶
Erforderliche Unterklauseln¶
DEFINE: Definieren von Symbolen¶
Symbole (auch als „Mustervariablen“ bezeichnet) sind die Bausteine des Musters.
Ein Symbol wird durch einen Ausdruck definiert. Wenn der Ausdruck für eine Zeile als wahr interpretiert wird, wird das Symbol dieser Zeile zugewiesen. Einer Zeile können mehrere Symbole zugewiesen werden.
Symbole, die nicht in der DEFINE-Klausel definiert sind, aber im Muster verwendet werden, werden immer allen Zeilen zugewiesen. Implizit sind sie äquivalent zum folgenden Beispiel:
Muster werden auf Basis von Symbolen und Operatoren definiert.
PATTERN: Festlegen des zu übereinstimmenden Musters¶
Das Muster definiert eine gültige Sequenz von Zeilen, die eine Übereinstimmung darstellt. Das Muster ist wie ein regulärer Ausdruck (regex) definiert und setzt sich aus Symbolen, Operatoren und Quantifizierer zusammen.
Beispiel: Angenommen, das Symbol S1 als stock_price < 55 definiert ist und das Symbol S2 als stock price > 55 definiert ist. Das folgende Muster gibt eine Sequenz von Zeilen an, in denen der Aktienkurs von kleiner als 55 auf größer als 55 gestiegen ist:
Im Folgenden finden Sie ein komplexeres Beispiel für eine Musterdefinition:
Der folgende Abschnitt beschreibt die einzelnen Komponenten dieses Musters im Detail.
Bemerkung
MATCH_RECOGNIZE verwendet die Rückverfolgung, um Muster abzugleichen. Wie bei anderen regulären Ausdrücken, die Backtracking verwenden, können einige Kombinationen von Mustern und Daten, die übereinstimmen müssen, eine lange Ausführungszeit benötigen, was zu hohen Computekosten führen kann.
Um die Leistung zu verbessern, definieren Sie ein Muster, das so spezifisch wie möglich ist:
Stellen Sie sicher, dass in jeder Zeile nur ein Symbol oder eine kleine Anzahl von Symbolen übereinstimmt.
Vermeiden Sie die Verwendung von Symbolen, die in jeder Zeile übereinstimmen (z. B. Symbole, die nicht in der
DEFINE-Klausel enthalten sind, oder Symbole, die als „true“ definiert sind).Definieren Sie eine Obergrenze für Quantifizierer (z. B.
{,10}statt*).
Beispielsweise kann das folgende Muster zu erhöhten Kosten führen, wenn keine Zeilen übereinstimmen:
Wenn es eine Obergrenze für die Anzahl der Zeilen gibt, die Sie abgleichen möchten, können Sie diese Grenze in den Quantifizierern angeben, um die Leistung zu verbessern. Außerdem können Sie, anstatt anzugeben, dass Sie any_symbol finden möchten, das auf symbol1 folgt, nach einer Zeile suchen, die nicht symbol1 ist (not_symbol1 in diesem Beispiel).
Im Allgemeinen sollten Sie die Abfrageausführungszeit überwachen, um sicherzustellen, dass die Abfrage nicht länger als erwartet dauert.
- Symbole:
Ein Symbol stimmt mit einer Zeile überein, der dieses Symbol zugewiesen wurde. Die folgenden Symbole sind verfügbar:
symbol. Zum BeispielS1, … ,S4Das sind Symbole, die in derDEFINE-Unterklausel definiert wurden und pro Zeile ausgewertet werden. (Dazu können auch Symbole gehören, die nicht definiert wurden und automatisch allen Zeilen zugewiesen werden).^(Beginn der Partition.) Dies ist ein virtuelles Symbol, das den Beginn einer Partition kennzeichnet und dem keine Zeile zugeordnet ist. Sie können damit festlegen, dass eine Übereinstimmung nur am Anfang einer Partition beginnen soll.Ein Beispiel dazu finden Sie unter Abgleichen von Mustern relativ zum Anfang oder Ende einer Partition.
$(Ende der Partition.) Dies ist ein virtuelles Symbol, das das Ende einer Partition kennzeichnet und dem keine Zeile zugeordnet ist. Sie können damit festlegen, dass eine Übereinstimmung nur am Ende einer Partition enden soll.Ein Beispiel dazu finden Sie unter Abgleichen von Mustern relativ zum Anfang oder Ende einer Partition.
- Quantifizierer:
Ein Quantifizierer kann nach einem Symbol oder einer Operation platziert werden. Ein Quantifizierer gibt die minimale und maximale Anzahl des Auftretens des zugehörigen Symbols oder der Operation an. Die folgenden Quantifizierer sind verfügbar:
Quantifizierer
Bedeutung
+1 oder mehr. Beispiel:
( {- S3 -} S4 )+.
*0 oder mehr. Beispiel:
S2*?.
?0 oder 1
{n}Genau n.
{n,}n oder mehr.
{,m}0 bis m.
{n, m}n bis m. Beispiel:
PERMUTE(S1, S2){1,2}.
Standardmäßig befinden sich Quantifizierer im „gierigen Modus“, d. h. sie versuchen, möglichst mit der maximalen Menge übereinzustimmen. Um einen Quantifizierer in den „zurückhaltenden Modus“ zu versetzen, in dem der Quantifizierer versucht, möglichst mit der Mindestmenge übereinzustimmen, setzen Sie hinter den Quantifizierer ein ? (z. B. S2*?).
- Operatoren:
Operatoren geben an, in welcher Reihenfolge Symbole oder andere Operationen in der Sequenz von Zeilen auftreten sollen, um eine gültige Übereinstimmung zu bilden. Die folgenden Operatoren sind verfügbar:
Operator
Bedeutung
... ...(Leerzeichen)Verkettung. Gibt an, dass ein Symbol oder eine Operation auf ein anderes Symbol bzw. eine andere Operation folgen soll. Zum Beispiel bedeutet
S1 S2, dass die fürS2definierte Bedingung nach der fürS1definierten Bedingung auftreten soll.
{- ... -}Ausschluss. Schließt die enthaltenen Symbole oder Operationen von der Ausgabe aus. Zum Beispiel schließt
{- S3 -}den OperatorS3von der Ausgabe aus. Ausgeschlossene Zeilen erscheinen nicht in der Ausgabe, werden aber bei der Auswertung vonMEASURES-Ausdrücken berücksichtigt.
( ... )Gruppierung. Wird verwendet, um die Rangfolge eines Operators außer Kraft zu setzen oder um denselben Quantifizierer für Symbole oder Operationen in der Gruppe anzuwenden. Im folgenden Beispiel gilt der Quantifizierer
+für die Sequenz{- S3 -} S4, nicht nur fürS4.
PERMUTE(..., ...)Permutation. Jede Permutation des angegebenen Musters stimmt überein. Beispiel:
PERMUTE(S1, S2)stimmt entweder mitS1 S2oderS2 S1überein.PERMUTE()nimmt eine unbegrenzte Anzahl von Argumenten an.
... | ...Alternative. Legt fest, dass entweder das erste Symbol bzw. die erste Operation oder das andere Symbol bzw. die andere Operation auftreten soll. Beispiel:
( S3 S4 ) | PERMUTE(S1, S2). Der Alternativoperator hat Vorrang vor dem Verkettungsoperator.
Optionale Unterklausel¶
ORDER BY: Sortieren der Zeilen vor dem Abgleich¶
{}Wobei:
Definieren Sie die Reihenfolge der Zeilen wie bei den Fensterfunktionen. Dies ist die Reihenfolge, in der die einzelnen Zeilen jeder Partition an den
MATCH_RECOGNIZE-Operator übergeben werden.Weitere Informationen dazu finden Sie unter Partitionierung und Sortierung von Zeilen.
PARTITION BY: Partitionieren der Zeilen in Fenstern¶
{}Partitionieren Sie die Eingabemenge von Zeilen, wie Sie es für Fensterfunktionen tun würden.
MATCH_RECOGNIZEführt den Abgleich individuell für jede resultierende Partition durch.Beim Partitionieren werden nicht nur Zeilen gruppiert, die miteinander in Beziehung stehen, sondern es wird auch die Fähigkeit von Snowflake zur verteilten Datenverarbeitung genutzt, da separate Partitionen parallel verarbeitet werden können.
Weitere Informationen zum Partitionieren finden Sie unter Partitionierung und Sortierung von Zeilen.
MEASURES: Festlegen zusätzlicher Ausgabespalten¶
„Measures“ sind optionale zusätzliche Spalten, die der Ausgabe des MATCH_RECOGNIZE-Operators hinzugefügt werden. Die Ausdrücke in der MEASURES-Unterklausel haben die gleichen Fähigkeiten wie die Ausdrücke in der DEFINE-Unterklausel. Weitere Informationen dazu finden Sie unter Symbole.
Innerhalb der MEASURES-Unterklausel sind die folgenden für MATCH_RECOGNIZE spezifischen Funktionen verfügbar:
MATCH_NUMBER()gibt die fortlaufende Nummer der Übereinstimmung zurück. Die MATCH_NUMBER beginnt bei 1 und wird bei jeder Übereinstimmung erhöht.MATCH_SEQUENCE_NUMBER()gibt die Zeilennummer innerhalb einer Übereinstimmung zurück. Die MATCH_SEQUENCE_NUMBER ist sequenziell und beginnt mit 1.CLASSIFIER()gibt einen TEXT-Wert zurück, der das Symbol enthält, mit dem die jeweilige Zeile übereinstimmt. Wenn zum Beispiel eine Zeile mit dem SymbolGT75übereinstimmt, gibt die FunktionCLASSIFIERdie Zeichenfolge „GT75“ zurück.
Bemerkung
Beachten Sie beim Festlegen von Measures die im Abschnitt Einschränkungen für in DEFINE und MEASURES verwendete Fensterfunktionen genannten Einschränkungen.
ROW(S) PER MATCH: Festlegen der zurückzugebenden Zeilen¶
Gibt an, welche Zeilen bei einer erfolgreichen Übereinstimmung zurückgegeben werden. Diese Unterklausel ist optional.
ALL ROWS PER MATCH: Gibt alle Zeilen in der Übereinstimmung zurück.ONE ROW PER MATCH: Gibt genau eine Zusammenfassungszeile für jede Übereinstimmung zurück, unabhängig davon, wie viele Zeilen in der Übereinstimmung enthalten sind. Dies ist der Standard.
Beachten Sie die folgenden Sonderfälle:
Leere Übereinstimmungen: Eine leere Übereinstimmung liegt vor, wenn ein Muster mit null Zeilen übereinstimmen kann. Wenn das Muster z. B. als
A*definiert ist und die erste Zeile am Anfang eines Abgleichversuchs dem SymbolBzugewiesen ist, dann wird eine leere Übereinstimmung generiert, die nur diese Zeile enthält, weil der Quantifizierer*im MusterA*erlaubt, dass 0 Vorkommen vonAals Übereinstimmung behandelt werden. DieMEASURES-Ausdrücke werden für diese Zeile anders ausgewertet:Die Funktion CLASSIFIER gibt NULL zurück.
Fensterfunktionen geben NULL zurück.
Die Funktion COUNT gibt 0 zurück.
Nicht übereinstimmende Zeilen: Wenn eine Zeile nicht mit dem Muster übereinstimmt, wird sie als nicht übereinstimmende Zeile bezeichnet.
MATCH_RECOGNIZEkann so konfiguriert werden, dass auch nicht übereinstimmende Zeilen zurückgegeben werden. Für nicht übereinstimmende Zeilen geben Ausdrücke in derMEASURES-Unterklausel NULL zurück.
Ausschlüsse
Die Ausschlusssyntax
({- ... -})in der Musterdefinition ermöglicht es dem Benutzer, bestimmte Zeilen von der Ausgabe auszuschließen. Wenn alle übereinstimmenden Symbole im Muster ausgeschlossen wurden, wird bei Angabe vonALL ROWS PER MATCHkeine Zeile für diese Übereinstimmung generiert. Beachten Sie, dass die MATCH_NUMBER ohnehin inkrementiert wird. Ausgeschlossene Zeilen sind nicht Teil des Ergebnisses, werden aber bei der Auswertung vonMEASURES-Ausdrücken berücksichtigt.Bei Verwendung der Ausschlusssyntax kann die Unterklausel ROWS PER MATCH wie folgt angegeben werden:
ONE ROW PER MATCH (Standard)
Gibt für jede erfolgreiche Übereinstimmung genau eine Zeile zurück. Die Standard-Fensterfunktionssemantik für Fensterfunktionen in der
MEASURES-Unterklausel istFINAL.Die Ausgabespalten des
MATCH_RECOGNIZE-Operators sind alle in derPARTITION BY-Unterklausel angegebenen Ausdrücke und alleMEASURES-Ausdrücke. Alle resultierenden Zeilen einer Übereinstimmung werden durch die Ausdrücke in derPARTITION BY-Unterklausel und dieMATCH_NUMBERunter Verwendung derANY_VALUE-Aggregationsfunktion für alle Measures gruppiert. Wenn also Measures für verschiedene Zeilen derselben Übereinstimmung einen unterschiedlichen Wert ergeben, dann ist die Ausgabe nicht deterministisch.Das Weglassen der Unterklauseln
PARTITION BYundMEASURESführt zu einem Fehler, der anzeigt, dass das Ergebnis keine Spalten enthält.Bei leeren Übereinstimmungen wird eine Zeile generiert. Nicht übereinstimmende Zeilen sind nicht Teil der Ausgabe.
ALL ROWS PER MATCHGibt eine Zeile für jede Zeile zurück, die Teil der Übereinstimmung ist, mit Ausnahme von Zeilen, die mit einem Teil des Musters übereinstimmen, der für den Ausschluss markiert wurde.
Ausgeschlossene Zeilen werden bei Berechnungen in der
MEASURES-Unterklausel weiterhin berücksichtigt.Übereinstimmungen können sich aufgrund der
AFTER MATCH SKIP TO-Unterklausel überschneiden, sodass dieselbe Zeile möglicherweise mehrfach in der Ausgabe vorkommt.Die Standard-Fensterfunktionssemantik für Fensterfunktionen in der
MEASURES-Unterklausel istRUNNING.Die Ausgabespalten des
MATCH_RECOGNIZE-Operators sind die Spalten der eingegebenen Zeilenmenge und die in derMEASURES-Unterklausel definierten Spalten.Die folgenden Optionen sind für
ALL ROWS PER MATCHverfügbar:SHOW EMPTY MATCHES (default)fügt leere Übereinstimmungen zur Ausgabe hinzu. Nicht übereinstimmende Zeilen werden nicht ausgegeben.OMIT EMPTY MATCHESgibt weder leere Treffer noch nicht übereinstimmende Zeilen aus. Die MATCH_NUMBER wird jedoch weiterhin durch eine leere Übereinstimmung inkrementiert.WITH UNMATCHED ROWSfügt leere Übereinstimmungen und nicht übereinstimmende Zeilen zur Ausgabe hinzu. Wenn diese Klausel verwendet wird, dann darf das Muster keine Ausschlüsse enthalten.
Ein Beispiel, das den Ausschluss verwendet, um irrelevante Ausgaben zu reduzieren, finden Sie unter Suche nach Mustern in nicht benachbarten Zeilen.
AFTER MATCH SKIP: Festlegen, wo nach einer Übereinstimmung fortgefahren werden soll¶
Diese Unterklausel gibt an, wo der Abgleich fortgesetzt werden soll, nachdem eine positive Übereinstimmung gefunden wurde.
PAST LAST ROW (default)Den Abgleich nach der letzten Zeile der aktuellen Übereinstimmung fortsetzen.
Dies verhindert Übereinstimmungen, die sich überschneidende Zeilen enthalten. Wenn Sie z. B. ein Aktienmuster haben, das drei
V-Formen nacheinander enthält, dann findetPAST LAST ROWeinW-Muster, nicht zwei.TO NEXT ROWDen Abgleich nach der ersten Zeile der aktuellen Übereinstimmung fortsetzen.
Dies erlaubt Übereinstimmungen, die sich überschneidende Zeilen enthalten. Wenn Sie z. B. ein Aktienmuster haben, das drei
V-Formen nacheinander enthält, dann findetTO NEXT ROWzweiW-Muster (das erste Muster basiert auf den ersten beidenV-Formen, und die zweiteW-Form basiert auf der zweiten und drittenV-Form; beide Muster enthalten also dasselbeV).TO [ { FIRST | LAST } ] <Symbol>Setzt den Abgleich an der ersten oder letzten (Standard) Zeile fort, die mit dem gegebenen Symbol übereinstimmt.
Mindestens eine Zeile muss dem gegebenen Symbol zugeordnet werden, sonst wird ein Fehler ausgelöst.
Wenn dabei nicht über die erste Zeile der aktuellen Übereinstimmung hinausgesprungen wird, wird ein Fehler ausgelöst.
Nutzungshinweise¶
Ausdrücke in DEFINE- und MEASURES-Klauseln¶
In DEFINE- und MEASURES-Klauseln sind Ausdrücke zulässig. Diese Ausdrücke können komplex sein und können Fensterfunktionen und spezielle Navigationsfunktionen (die eine Art von Fensterfunktion sind) enthalten.
In den meisten Fällen folgen die Ausdrücke in DEFINE und MEASURES den Regeln für Ausdrücke, wie sie an anderen Stellen der Snowflake-SQL-Syntax beschrieben sind. Es gibt jedoch einige Unterschiede, die im Folgenden beschrieben werden:
- Fensterfunktionen:
-
PREV( expr [ , offset [, default ] ] )Navigiert zur vorherigen Zeile innerhalb der aktuellen Übereinstimmung in der Unterklausel MEASURES.Diese Funktion ist derzeit in der Unterklausel DEFINE nicht verfügbar. Stattdessen können Sie LAG verwenden, das zur vorherigen Zeile innerhalb des aktuellen Fensterrahmens navigiert.
NEXT( expr [ , offset [ , default ] ] )navigiert zur nächsten Zeile innerhalb des aktuellen Fensterrahmens. Diese Funktion ist äquivalent zu LEAD.FIRST( expr )Navigiert zur ersten Zeile der aktuellen Übereinstimmung in der Unterklausel MEASURES.Diese Funktion ist derzeit in der Unterklausel DEFINE nicht verfügbar. Stattdessen können Sie FIRST_VALUE verwenden, das zur ersten Zeile des aktuellen Fensterrahmens navigiert.
LAST( expr )Navigiert zur letzten Zeile des aktuellen Fensterrahmens. Diese Funktion ist ähnlich wie LAST_VALUE, aber für LAST wird der Fensterrahmen auf die aktuelle Zeile des aktuellen Anpassungsversuchs begrenzt, wenn LAST innerhalb der DEFINE-Unterklausel verwendet wird.
Ein Beispiel für die Verwendung der Navigationsfunktionen finden Sie unter Zurückgeben von Informationen zur Übereinstimmung.
Wenn eine Fensterfunktion innerhalb einer
MATCH_RECOGNIZE-Klausel verwendet wird, benötigt die Fensterfunktion im Allgemeinen keine eigeneOVER (PARTITION BY ... ORDER BY ...)-Klausel. Das Fenster wird implizit durchPARTITION BYundORDER BYin derMATCH_RECOGNIZE-Klausel bestimmt. (Einige Ausnahmen finden Sie unter Einschränkungen für in DEFINE und MEASURES verwendete Fensterfunktionen.)Im Allgemeinen wird der Fensterrahmen auch implizit aus dem aktuellen Kontext abgeleitet, in dem die Fensterfunktion verwendet wird. Die untere Begrenzung des Rahmens wird wie unten beschrieben definiert:
In der
DEFINE-Unterklausel:Der Rahmen beginnt am Anfang des aktuellen Abgleichversuchs, außer bei Verwendung von
LAG,LEAD,FIRST_VALUEundLAST_VALUE.In der
MEASURES-Unterklausel:Der Rahmen beginnt am Anfang der gefundenen Übereinstimmung.
Die Ränder des Fensterrahmens können entweder mit der Semantik
RUNNINGoderFINALangegeben werden.RUNNING:Im Allgemeinen endet der Rahmen mit der aktuellen Zeile. Es gibt jedoch die folgenden Ausnahmen:
In der
DEFINE-Unterklausel endet der Rahmen fürLAG,LEAD,FIRST_VALUE,LAST_VALUEundNEXTbei der letzten Zeile des Fensters.In der
MEASURES-Unterklausel endet der Rahmen fürPREV,NEXT,LAGundLEADbei der letzten Zeile des Fensters.
In der
DEFINE-Unterklausel istRUNNINGdie Standard-Semantik (und die einzig erlaubte).In der
MEASURES-Unterklausel ist bei Verwendung derALL ROWS PER MATCH-Unterklausel der StandardwertRUNNING.FINAL:Der Rahmen endet mit der letzten Zeile der Übereinstimmung.
FINAList nur in derMEASURES-Unterklausel erlaubt. Es ist dort der Standard, wennONE ROW PER MATCHgilt. - Symbolprädikate:
Ausdrücke innerhalb der Unterklauseln
DEFINEundMEASURESerlauben Symbole als Prädikate für Spaltenreferenzen.Das
<Symbol>kennzeichnet eine übereinstimmende Zeile, und die<Spalte>identifiziert eine bestimmte Spalte innerhalb dieser Zeile.Eine Spaltenreferenz mit Prädikat bedeutet, dass die umgebende Fensterfunktion nur die Zeilen betrachtet, die schließlich dem angegebenen Symbol zugeordnet wurden.
Spaltenreferenzen mit Prädikat können außerhalb und innerhalb einer Fensterfunktion verwendet werden. Bei Verwendung außerhalb einer Fensterfunktion ist
<symbol>.<column>dasselbe wieLAST(<Symbol>.<Spalte>). Innerhalb einer Fensterfunktion müssen alle Spaltenreferenzen entweder dasselbe Symbol als Prädikat verwenden oder kein Prädikat haben.Im Folgenden wird erläutert, wie sich navigationsbezogene Funktionen mit prädizierten Spaltenreferenzen verhalten:
{}: Durchsucht den Fensterrahmen rückwärts und einschließlich der aktuellen Zeile (oder der letzten Zeile im Falle einerFINAL-Semantik) nach der ersten Zeile, die schließlich dem angegebenen<Symbol>zugeordnet wurde, und geht dann<Offset>Zeilen (Standard ist 1) rückwärts, wobei das diesen Zeilen zugeordnete Symbol ignoriert wird. Wenn der durchsuchte Teil des Rahmens keine dem<Symbol>zugeordnete Zeilen enthält oder der Suchlauf den Rahmen verlassen wird, wird NULL zurückgegeben.{}: Durchsucht den Fensterrahmen rückwärts und einschließlich der aktuellen Zeile (oder der letzten Zeile im Falle einerFINAL-Semantik) nach der ersten Zeile, die schließlich dem angegebenen<Symbol>zugeordnet wurde, und geht<Offset>Zeilen (Standard ist 1) vorwärts, wobei das diesen Zeilen zugeordnete Symbol ignoriert wird. Wenn der durchsuchte Teil des Rahmens keine dem<Symbol>zugeordnete Zeilen enthält oder der Suchlauf den Rahmen verlassen wird, wird NULL zurückgegeben.{}: Durchsucht den Fensterrahmen vorwärts und einschließlich der ersten Zeile bis einschließlich der aktuellen Zeile (oder der letzten Zeile im Falle einerFINAL-Semantik) nach der ersten Zeile, die schließlich dem angegebenen<Symbol>zugeordnet wurde. Wenn der durchsuchte Teil des Rahmens keine dem<Symbol>zugeordnete Zeile enthält, wird NULL zurückgegeben.{}: Durchsucht den Fensterrahmen vorwärts ab und einschließlich der aktuellen Zeile (oder der letzten Zeile im Falle einerFINAL-Semantik) nach der ersten Zeile, die schließlich dem angegebenen<Symbol>zugeordnet wurde. Wenn der durchsuchte Teil des Rahmens keine dem<Symbol>zugeordnete Zeile enthält, wird NULL zurückgegeben.
Bemerkung
Beschränkungen für Fensterfunktionen sind im Abschnitt Einschränkungen für in DEFINE und MEASURES verwendete Fensterfunktionen dokumentiert.
Einschränkungen für in DEFINE und MEASURES verwendete Fensterfunktionen¶
Ausdrücke in den Unterklauseln DEFINE und MEASURES können Fensterfunktionen enthalten. Es gibt jedoch einige Begrenzungen bei der Verwendung von Fensterfunktionen in diesen Unterklauseln. Diese Begrenzungen sind in der folgenden Tabelle aufgeführt:
Funktion
DEFINE (In Ausführung) [Spalte/Symbol.Spalte]
MEASURES (In Ausführung) [Spalte/Symbol.Spalte]
MEASURES (Endgültig) [Spalte/Symbol.Spalte]
Spalte
✔ / ❌
✔ / ❌
✔ / ✔
PREV(…)
❌ / ❌
✔ / ❌
✔ / ❌
NEXT(…)
✔ / ❌
✔ / ❌
✔ / ❌
FIRST(…)
❌ / ❌
✔ / ❌
✔ / ✔
LAST(…)
✔ / ❌
✔ / ❌
✔ / ✔
LAG()
✔ / ❌
✔ / ❌
✔ / ❌
LEAD()
✔ / ❌
✔ / ❌
✔ / ❌
FIRST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
LAST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
Aggregationen [1]
✔ / ❌
✔ / ✔
✔ / ✔
Weitere Fensterfunktionen [1]
✔ / ❌
✔ / ❌
✔ / ❌
Die MATCH_RECOGNIZE-spezifischen Funktionen MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER() und CLASSIFIER() sind derzeit in der DEFINE-Unterklausel nicht verfügbar.
Problembehandlung¶
Fehlermeldung: „SELECT with no columns“ bei Verwendung von ONE ROW PER MATCH¶
Wenn Sie die ONE ROW PER MATCH-Klausel verwenden, sind nur Spalten und Ausdrücke aus den PARTITION BY- und MEASURES-Unterklauseln in der Projektionsklausel von SELECT erlaubt. Wenn Sie versuchen, MATCH_RECOGNIZE ohne eine PARTITION BY- oder MEASURES-Klausel zu verwenden, erhalten Sie eine Fehlermeldung ähnlich wie SELECT with no columns.
Weitere Informationen zu ONE ROW PER MATCH vs. ALL ROWS PER MATCH finden Sie unter Generieren einer Zeile für jede Übereinstimmung vs. Generieren aller Zeilen für jede Übereinstimmung.
Beispiele¶
Unter dem Thema Identifizieren von Sequenzen von Zeilen, die einem Muster entsprechen finden Sie zahlreiche Beispiele, darunter einige, die einfacher sind als die meisten der hier vorgestellten Beispiele. Wenn Sie mit MATCH_RECOGNIZE noch nicht vertraut sind, sollten Sie diese Beispiele zuerst lesen.
Einige der Beispiele unten verwenden folgende Tabelle und Daten:
Die folgende Grafik zeigt die Formen der Kurven:
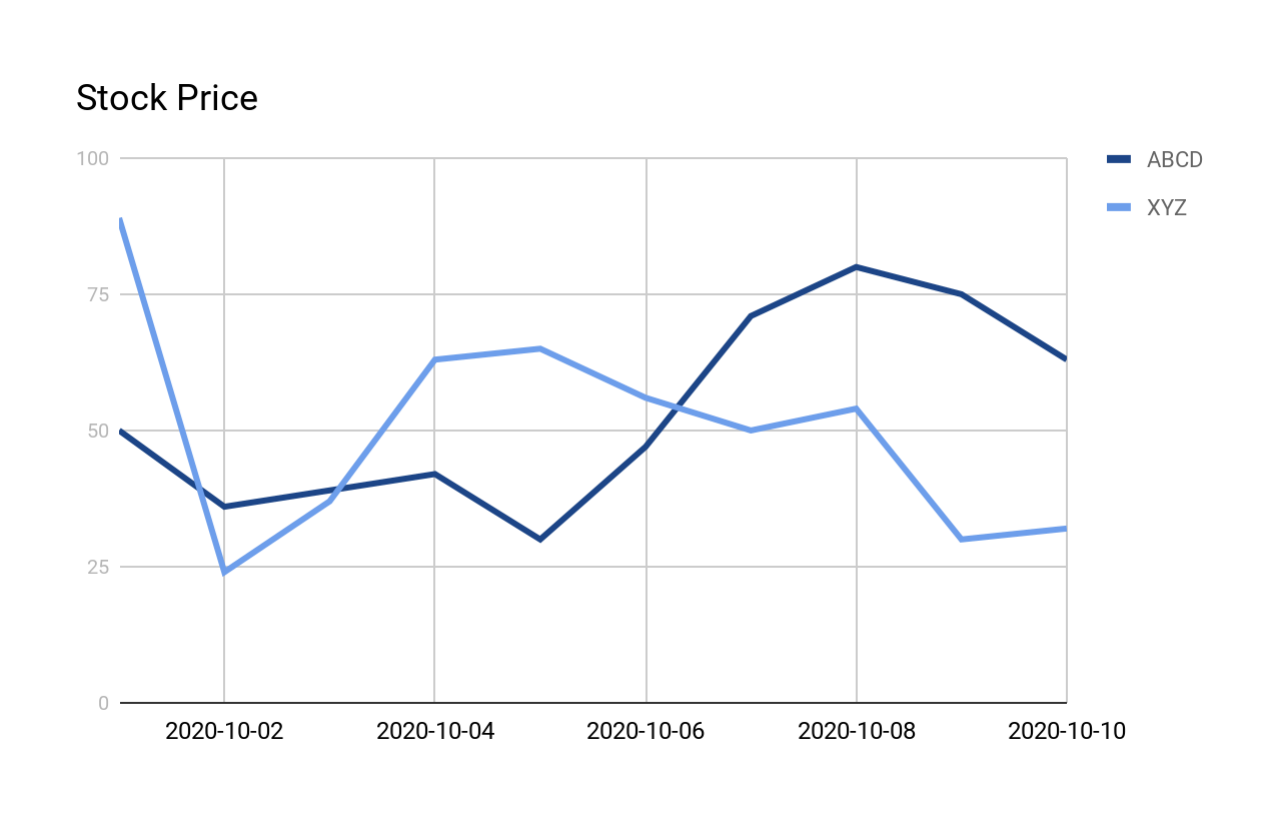
Eine Zusammenfassungszeile für jede V-Form zurückgeben¶
Die folgende Abfrage sucht nach allen V-Formen in der zuvor vorgestellten „stock_price_history“. Die Ausgabe wird im Anschluss an die Abfrage und Ausgabe näher erläutert.
Die Ausgabe zeigt eine Zeile pro Übereinstimmung (unabhängig davon, wie viele Zeilen Teil der Übereinstimmung waren).
Die Ausgabe enthält die folgenden Spalten:
COMPANY: Tickersymbol der Firma.
Die MATCH_NUMBER ist eine fortlaufende Nummer, die angibt, um welche Übereinstimmung es sich in diesem Dataset handelt (z. B. die erste Übereinstimmung hat MATCH_NUMBER 1, die zweite Übereinstimmung hat MATCH_NUMBER 2 usw.). Wenn die Daten partitioniert wurden, dann ist MATCH_NUMBER die fortlaufende Nummer innerhalb der Partition (in diesem Beispiel für jede Firma/Aktie).
START_DATE: Datum, an dem das Auftreten des Musters beginnt.
END_DATE: Datum, an dem das Auftreten des Musters endet.
ROWS_IN_SEQUENCE: Anzahl der Zeilen in der Übereinstimmung. Zum Beispiel basiert die erste Übereinstimmung auf den Kurs-Measure, der an 4 Tagen (1. Oktober bis 4. Oktober) gemessen wurden, also hat ROWS_IN_SEQUENCE den Wert 4.
NUM_DECREASES: Anzahl der Tage (innerhalb der Übereinstimmung), an denen der Kurs gesunken ist. So ist beispielsweise in der ersten Übereinstimmung der Kurs 1 Tag gefallen und dann 2 Tage gestiegen, also ist NUM_DECREASES 1.
NUM_INCREASES: Anzahl der Tage (innerhalb der Übereinstimmung), an denen der Kurs gestiegen ist. So ist beispielsweise in der ersten Übereinstimmung der Kurs 1 Tag gefallen und dann 2 Tage gestiegen, also ist NUM_INCREASES 2.
Alle Zeilen für alle Übereinstimmungen für eine Firma zurückgeben¶
Dieses Beispiel gibt alle Zeilen innerhalb jeder Übereinstimmung zurück (nicht nur eine Zusammenfassungszeile pro Übereinstimmung). Dieses Muster sucht nach steigenden Kursen der Firma ABCD:
Leere Übereinstimmungen auslassen¶
Dabei wird nach Kursbereichen gesucht, die über dem Durchschnitt des gesamten Charts eines Unternehmens liegen. In diesem Beispiel werden leere Übereinstimmungen ausgelassen. Beachten Sie, dass auch bei leeren Übereinstimmungen die MATCH_NUMBER inkrementiert wird:
Beispiel für WITH UNMATCHED ROWS-Option¶
In diesem Beispiel wird die Option WITH UNMATCHED ROWS option veranschaulicht: Wie im obigen Beispiel Leere Übereinstimmungen auslassen wird auch in diesem Beispiel nach Kursbereichen gesucht, die über dem Durchschnittskurs des Charts der jeweiligen Firma liegen. Beachten Sie, dass der Quantifizierer in dieser Abfrage + ist, während der Quantifizierer in der vorherigen Abfrage * war:
Auswirkung von Symbolprädikaten in der MEASURES-Klausel¶
Im folgende Beispiel wird die Verwendung der <Symbol>.<Spalte>-Notation mit Symbolprädikaten gezeigt: