- 카테고리:
MATCH_RECOGNIZE¶
행 세트에서 패턴 일치를 인식합니다. MATCH_RECOGNIZE 는 (테이블, 뷰, 하위 쿼리 또는 기타 소스에서) 행 세트를 입력으로 받아들이고, 이 세트 내에서 주어진 행 패턴에 대한 모든 일치 항목을 반환합니다. 패턴은 정규식과 유사하게 정의됩니다.
절은 다음 중 하나를 반환할 수 있습니다.
각 일치 항목에 속한 모든 행.
일치 항목당 하나의 요약 행.
MATCH_RECOGNIZE 는 일반적으로 시계열에서 이벤트를 감지하는 데 사용됩니다. 예를 들어, MATCH_RECOGNIZE 는 V (아래로 뒤에서 위로) 또는 W (아래로, 위로, 아래로, 위로)와 같은 모양에 대한 주가 기록 테이블을 검색할 수 있습니다.
MATCH_RECOGNIZE 는 FROM 절의 선택적 하위 절입니다.
참고
재귀 공통 테이블 식(CTE) 에서는 MATCH_RECOGNIZE 절을 사용할 수 없습니다.
- 참고 항목:
구문¶
필수 하위 절¶
DEFINE: 기호 정의¶
기호(“패턴 변수”라고도 함)는 패턴의 구성 요소입니다.
기호는 식으로 정의됩니다. 식이 행에 대해 true로 평가되면 해당 행에 기호가 할당됩니다. 행에 여러 기호를 할당할 수 있습니다.
DEFINE 절에서 정의되지 않았지만 패턴에서 사용되는 기호는 항상 모든 행에 할당됩니다. 암시적으로 다음 예와 동일합니다.
패턴은 기호와 연산자 를 기반으로 정의됩니다.
PATTERN: 일치시킬 패턴 지정¶
패턴은 일치를 나타내는 유효한 행 시퀀스를 정의합니다. 패턴은 정규식(regex)처럼 정의되며 기호, 연산자, 수량자로 구성됩니다.
예를 들어, 기호 S1 이 stock_price < 55 로 정의되고 기호 S2 가 stock price > 55 로 정의된다고 가정합니다. 다음 패턴은 주가가 55 미만에서 55 초과로 증가한 행 시퀀스를 지정합니다.
다음은 패턴 정의에 대한 더 복잡한 예입니다.
다음 섹션에서는 이 패턴의 개별 구성 요소에 대해 자세히 설명합니다.
참고
MATCH_RECOGNIZE는 역추적 을 사용하여 패턴을 일치시킵니다. 역추적을 사용하는 다른 정규식 엔진 의 경우와 마찬가지로, 일치시킬 패턴과 데이터의 일부 조합을 실행하는 데 시간이 오래 걸릴 수 있으므로 높은 계산 비용이 발생할 수 있습니다.
성능을 향상하려면 패턴을 다음과 같이 최대한 구체적으로 정의하십시오.
각 행은 기호 1개 또는 적은 수의 기호와만 일치해야 합니다.
모든 행과 일치하는 기호를 사용하지 마십시오(예:
DEFINE절에 없는 기호 또는 true로 정의된 기호).수량자의 상한을 정의하십시오(예:
{,10}대신*).
예를 들어, 다음 패턴은 일치하는 행이 없으면 비용이 증가할 수 있습니다.
일치시키려는 행 수에 상한이 있는 경우, 수량자에 해당 제한을 지정하여 성능을 향상시킬 수 있습니다. 또한, symbol1 다음에 오는 any_symbol 을 찾도록 지정하는 대신, symbol1 이 아닌 행(이 예에서는 not_symbol1)을 찾을 수 있습니다.
일반적으로, 쿼리 실행 시간을 모니터링하여 쿼리가 예상보다 오래 걸리지 않는지 확인하는 것이 좋습니다.
- 기호:
기호는 해당 기호가 할당된 행과 일치합니다. 다음 기호를 사용할 수 있습니다.
symbol. 예:S1, … ,S4이러한 기호는DEFINE하위 절에 정의된 기호이며 행별로 평가됩니다. (여기에는 정의되지 않고 모든 행에 자동으로 할당되는 기호도 포함될 수 있습니다.)^(파티션의 시작.) 이 기호는 파티션의 시작을 나타내는 가상 기호이며, 이와 연결된 행이 없습니다. 파티션 시작에서만 일치를 시작하도록 요구하는 데 사용할 수 있습니다.예를 보려면 파티션의 시작 또는 마지막과 관련된 일치 패턴 를 참조하십시오.
$(파티션의 끝.) 이 기호는 파티션의 끝을 나타내는 가상 기호이며, 이와 연결된 행이 없습니다. 파티션의 끝에서만 일치가 끝나도록 요구하는 데 사용할 수 있습니다.예를 보려면 파티션의 시작 또는 마지막과 관련된 일치 패턴 를 참조하십시오.
- 수량자:
기호 또는 연산 다음에 수량자를 배치할 수 있습니다. 수량자는 관련 기호 또는 연산의 최소 및 최대 발생 횟수를 나타냅니다. 다음 수량자를 사용할 수 있습니다.
수량자
의미
+1개 이상. 예:
( {- S3 -} S4 )+.
*0개 이상. 예:
S2*?.
?0 또는 1.
{n}정확히 n.
{n,}n 이상.
{,m}0에서 m.
{n, m}n에서 m. 예:
PERMUTE(S1, S2){1,2}.
기본적으로 수량자는 “탐욕 모드”에 있습니다. 즉, 수량자는 가능한 경우 최대 수량과 일치시키려고 합니다. 수량자를 “비탐욕(reluctant) 모드”(수량자는 가능한 경우 최소 수량과 일치하려고 함)로 설정하려면 수량자 뒤에 ? 를 배치하십시오(예: S2*?).
- 연산자:
연산자는 유효한 일치를 형성하기 위해 행 시퀀스에서 기호 또는 기타 연산이 발생해야 하는 순서를 지정합니다. 다음 연산자를 사용할 수 있습니다.
연산자
의미
... ...(공백)연결. 기호 또는 연산이 다른 기호 또는 연산을 따라야 함을 지정합니다. 예를 들어,
S1 S2는S2에 대해 정의된 조건이S1에 대해 정의된 조건 다음에 발생해야 함을 의미합니다.
{- ... -}제외. 출력에서 포함된 기호 또는 연산을 제외합니다. 예를 들어,
{- S3 -}은 출력에서 연산자S3을 제외합니다. 제외된 행은 출력에 나타나지 않지만,MEASURES식 평가에는 포함됩니다.
( ... )그룹화. 연산자의 우선 순위를 무시하거나, 그룹의 기호 또는 연산에 동일한 수량자를 적용하는 데 사용됩니다. 이 예에서 수량자
+는S4만이 아니라{- S3 -} S4시퀀스에 적용됩니다.
PERMUTE(..., ...)순열. 지정된 패턴의 모든 순열과 일치합니다. 예를 들어,
PERMUTE(S1, S2)는S1 S2또는S2 S1과 일치합니다.PERMUTE()는 무제한의 인자를 사용합니다.
... | ...대체. 첫 번째 기호나 연산 또는 다른 기호나 연산이 발생하도록 지정합니다. 예:
( S3 S4 ) | PERMUTE(S1, S2). 대체 연산자는 연결 연산자보다 우선합니다.
선택적 하위 절¶
ORDER BY: 일치시키기 전에 행 정렬¶
{}여기서:
윈도우 함수 에서와 같이 행의 순서를 정의하십시오. 이는 각 파티션의 개별 행이
MATCH_RECOGNIZE연산자에 전달되는 순서입니다.자세한 내용은 행 분할 및 정렬하기 섹션을 참조하십시오.
PARTITION BY: 행을 윈도우로 분할¶
{}윈도우 함수 에서와 같이 입력 행 세트를 분할합니다.
MATCH_RECOGNIZE는 각 결과 파티션에 대해 개별적으로 일치를 수행합니다.분할은 서로 관련된 행을 그룹화할 뿐만 아니라 Snowflake의 분산 데이터 처리 기능을 활용합니다. 별도의 파티션을 병렬로 처리할 수 있기 때문입니다.
분할에 대한 자세한 내용은 행 분할 및 정렬하기 을 참조하십시오.
MEASURES: 추가 출력 열 지정¶
“측정값”은 MATCH_RECOGNIZE 연산자의 출력에 추가되는 선택적 추가 열입니다. MEASURES 하위 절의 식은 DEFINE 하위 절의 식과 동일한 기능을 갖습니다. 자세한 내용은 기호 를 참조하십시오.
MEASURES 하위 절 내에서, MATCH_RECOGNIZE 와 관련된 다음 함수를 사용할 수 있습니다.
MATCH_NUMBER()일치 항목의 순차적 번호를 반환합니다. MATCH_NUMBER는 1부터 시작하여, 일치할 때마다 증가합니다.MATCH_SEQUENCE_NUMBER()일치 항목 내의 행 번호를 반환합니다. MATCH_SEQUENCE_NUMBER 는 순차적이며 1부터 시작합니다.CLASSIFIER()각 행과 일치하는 기호가 포함된 TEXT 값을 반환합니다. 예를 들어, 행이 기호GT75와 일치하면CLASSIFIER함수는 문자열 “GT75”를 반환합니다.
참고
측정값을 지정할 때 DEFINE 및 MEASURES 에서 사용되는 윈도우 함수에 대한 제한 사항 섹션에 언급된 제한 사항을 기억하십시오.
ROW(S) PER MATCH: 반환할 행 지정¶
성공적인 일치 항목에 대해 반환되는 행을 지정합니다. 이 하위 절은 선택 사항입니다.
ALL ROWS PER MATCH: 일치하는 모든 행을 반환합니다.ONE ROW PER MATCH: 일치하는 행 수와 관계없이 각 일치 항목에 대해 하나의 요약 행을 반환합니다. 이것이 기본값입니다.
다음과 같은 특별한 경우에 유의하십시오.
빈 일치 항목: 패턴이 0개의 행과 일치할 수 있는 경우 빈 일치 항목이 발생합니다. 예를 들어 패턴이
A*로 정의되고 일치 시도의 시작에 있는 첫 번째 행이 기호B에 할당된 경우, 해당 행만 포함하는 빈 일치 항목이 생성됩니다.A*패턴의*수량자가 0번의A가 일치 항목으로 처리되도록 허용하기 때문입니다.MEASURES식은 이 행에 대해 다르게 평가됩니다.CLASSIFIER 함수는 NULL을 반환합니다.
윈도우 함수는 NULL을 반환합니다.
COUNT 함수는 0을 반환합니다.
일치하지 않는 행: 행이 패턴과 일치하지 않는 경우, 이는 일치하지 않는 행이라고 합니다. 일치하지 않는 행도 반환하도록
MATCH_RECOGNIZE를 구성할 수 있습니다. 일치하지 않는 행의 경우,MEASURES하위 절의 식은 NULL을 반환합니다.
제외
패턴 정의의 제외 구문
({- ... -})을 사용하면 사용자가 출력에서 특정 행을 제외할 수 있습니다. 패턴에서 일치하는 모든 기호가 제외된 경우,ALL ROWS PER MATCH가 지정된 경우 해당 일치 항목에 대해 행이 생성되지 않습니다. MATCH_NUMBER는 관계없이 증가합니다. 제외된 행은 결과의 일부가 아니지만,MEASURES식 평가를 위해 포함됩니다.제외 구문을 사용할 때 ROWS PER MATCH 하위 절은 다음과 같이 지정할 수 있습니다.
ONE ROW PER MATCH(기본값)
각 성공적인 일치 항목에 대해 정확히 하나의 행을 반환합니다.
MEASURES하위 절의 윈도우 함수에 대한 기본 윈도우 함수 의미 체계는FINAL입니다.MATCH_RECOGNIZE연산자의 출력 열은PARTITION BY하위 절에 제공된 모든 식 및 모든MEASURES식입니다. 일치 항목의 모든 결과 행은 모든 측정값에 대해ANY_VALUE집계 함수를 사용하여,PARTITION BY하위 절에 제공된 식 및MATCH_NUMBER로 그룹화됩니다. 따라서 측정값이 동일한 일치 항목의 다른 행에 대해 다른 값으로 평가되는 경우, 출력은 비결정적입니다.PARTITION BY및MEASURES하위 절을 생략하는 경우, 결과에 열이 포함되지 않음을 나타내는 오류가 발생합니다.빈 일치 항목의 경우, 행이 생성됩니다. 일치하지 않는 행은 출력의 일부가 아닙니다.
ALL ROWS PER MATCH제외 하도록 표시된 패턴 부분과 일치하는 행을 제외하고, 일치 항목의 일부인 각 행에 대한 행을 반환합니다.
제외된 행은
MEASURES하위 절의 계산에서 여전히 고려됩니다.AFTER MATCH SKIP TO하위 절에 따라 일치 항목이 겹칠 수 있으므로 동일 행이 출력에 여러 번 나타날 수 있습니다.MEASURES하위 절의 윈도우 함수에 대한 기본 윈도우 함수 의미 체계는RUNNING입니다.MATCH_RECOGNIZE연산자의 출력 열은 입력되는 행 세트의 열, 그리고MEASURES하위 절에 정의된 열입니다.ALL ROWS PER MATCH에 대해 다음 옵션을 사용할 수 있습니다.SHOW EMPTY MATCHES (default)빈 일치 항목을 출력에 추가합니다. 일치하지 않는 행은 출력되지 않습니다.OMIT EMPTY MATCHES빈 일치 항목도, 일치하지 않는 행도 출력되지 않습니다. 그러나 MATCH_NUMBER는 여전히 빈 일치 항목만큼 증가합니다.WITH UNMATCHED ROWS빈 일치 항목 및 일치하지 않는 행을 출력에 추가합니다. 이 절이 사용되는 경우, 패턴에 제외가 포함되어서는 안 됩니다.
제외를 사용하여 무관련 출력을 줄이는 예는 비인접 행에서 패턴 검색 을 참조하십시오.
AFTER MATCH SKIP: 일치 후 계속할 위치 지정¶
이 하위 절은 긍정적인 일치 항목이 발견된 후 일치를 계속할 위치를 지정합니다.
PAST LAST ROW (default)현재 일치 항목의 마지막 행 이후에 일치를 계속합니다.
이렇게 할 경우, 겹치는 행을 포함하는 일치 항목이 방지됩니다. 예를 들어, 행에 3개의
V모양이 포함된 주식 패턴이 있는 경우,PAST LAST ROW는 2개가 아닌 1개의W패턴을 찾습니다.TO NEXT ROW현재 일치 항목의 첫 번째 행 이후에 일치를 계속합니다.
이렇게 할 경우, 겹치는 행을 포함하는 일치 항목이 허용됩니다. 예를 들어, 연속으로 3개의
V모양이 포함된 주식 패턴이 있는 경우,TO NEXT ROW는 두 개의W패턴을 찾습니다(첫 번째 패턴은 처음 두V모양을 기반으로 하고, 두 번째W모양은 두 번째 및 세 번째V모양을 기반으로 하므로 두 패턴 모두 동일한V를 포함함).TO [ { FIRST | LAST } ] <symbol>주어진 기호와 일치하는 첫 번째 또는 마지막(기본값) 행에서 일치를 계속합니다.
하나 이상의 행이 지정 기호에 매핑되어야 하며, 그렇지 않으면 오류가 발생합니다.
이것이 현재 일치 항목의 첫 번째 행을 지나치지 않는 경우, 오류가 발생합니다.
사용법 노트¶
DEFINE 및 MEASURES 절의 식¶
DEFINE 및 MEASURES 절은 식을 허용합니다. 이러한 식은 복잡할 수 있으며 윈도우 함수 및 특수 탐색 함수(윈도우 함수 유형)를 포함할 수 있습니다.
대부분의 경우, DEFINE 및 MEASURES 의 식은 Snowflake SQL 구문의 다른 식에 대한 규칙을 따릅니다. 그러나 몇 가지 차이점이 있으며 이는 아래에 설명되어 있습니다.
- 윈도우 함수:
-
PREV( expr [ , offset [, default ] ] )MEASURES 하위 절의 현재 일치 항목 내에서 이전 행으로 이동합니다.이 함수는 현재 DEFINE 하위 절에서 사용할 수 없습니다. 대신 현재 윈도우 프레임 내에서 이전 행으로 이동하는 LAG 를 사용할 수 있습니다.
NEXT( expr [ , offset [ , default ] ] )현재 윈도우 프레임 내에서 다음 행으로 이동합니다. 이 함수는 LEAD 와 동일합니다.FIRST( expr )MEASURES 하위 절에서 현재 일치 항목의 첫 번째 행으로 이동합니다.이 함수는 현재 DEFINE 하위 절에서 사용할 수 없습니다. 대신 현재 윈도우 프레임 의 첫 번째 행으로 이동하는 FIRST_VALUE 를 사용할 수 있습니다.
LAST( expr )현재 윈도우 프레임 의 마지막 행으로 이동합니다. 이 함수는 LAST_VALUE 와 유사하지만, LAST 의 경우 윈도우 프레임은 LAST 가 DEFINE 하위 절 내에서 사용될 때 현재 일치 시도의 현재 행으로 제한됩니다.
탐색 함수를 사용하는 예는 일치에 대한 정보 반환하기 을 참조하십시오.
일반적으로, 윈도우 함수가
MATCH_RECOGNIZE절 내에서 사용될 때 윈도우 함수는 자체OVER (PARTITION BY ... ORDER BY ...)절이 필요하지 않습니다. 윈도우는MATCH_RECOGNIZE절의PARTITION BY및ORDER BY에 의해 암시적으로 결정됩니다. (그러나 일부 예외에 대해서는 DEFINE 및 MEASURES 에서 사용되는 윈도우 함수에 대한 제한 사항 을 참조하십시오.)일반적으로, 윈도우 프레임 은 윈도우 함수가 사용되는 현재 컨텍스트에서도 암시적으로 파생됩니다. 프레임의 하한은 다음과 같이 정의됩니다.
DEFINE하위 절에서:프레임은
LAG,LEAD,FIRST_VALUE,LAST_VALUE를 사용하는 경우를 제외하고 현재 일치 시도의 시작에서 시작합니다.MEASURES하위 절에서:프레임은 발견된 일치 항목의 시작에서 시작됩니다.
윈도우 프레임의 가장자리는
RUNNING또는FINAL의미 체계를 사용하여 지정할 수 있습니다.RUNNING:일반적으로 프레임은 현재 행에서 끝납니다. 그러나 다음과 같은 예외가 있습니다.
DEFINE하위 절에서LAG,LEAD,FIRST_VALUE,LAST_VALUE,NEXT의 경우 프레임은 윈도우의 마지막 행에서 끝납니다.MEASURES하위 절에서PREV,NEXT,LAG,LEAD의 경우, 프레임은 윈도우의 마지막 행에서 끝납니다.
DEFINE하위 절에서RUNNING은 기본(그리고 유일하게 허용되는) 의미 체계입니다.MEASURES하위 절에서,ALL ROWS PER MATCH하위 절이 사용될 때RUNNING이 기본값입니다.FINAL:프레임은 일치 항목의 마지막 행에서 끝납니다.
FINAL은MEASURES하위 절에서만 허용됩니다.ONE ROW PER MATCH가 적용될 때 기본값입니다. - 기호 조건자:
DEFINE및MEASURES하위 절 내의 식은 기호를 열 참조에 대한 조건자로 허용합니다.<symbol>은 일치하는 행을 나타내고<column>은 해당 행 내의 특정 열을 식별합니다.조건부 열 참조는 주변 윈도우 함수가 지정 기호에 최종적으로 매핑된 행만 확인한다는 것을 의미합니다.
조건부 열 참조는 윈도우 함수 외부와 내부에서 사용할 수 있습니다. 윈도우 함수 외부에서 사용되는 경우,
<symbol>.<column>은LAST(<기호>.<열>)과 동일합니다. 윈도우 함수 내부에서 모든 열 참조는 동일 기호로 조건자가 지정되어야 하거나, 모두 조건자 지정이 되지 않아야 합니다.다음은 탐색 관련 함수가 조건부 열 참조와 함께 작동하는 방식을 설명합니다.
{}지정된<기호>에 마지막으로 매핑된 첫 번째 행에 대해 현재 행(또는FINAL의미 체계의 경우 마지막 행)을 포함하여 이로부터 시작해 윈도우 프레임을 역방향으로 검색한 다음,<오프셋>(기본값은 1) 행 뒤로 이동하고, 해당 행이 매핑된 기호를 무시합니다. 프레임의 검색된 부분이<symbol>에 매핑된 행을 포함하지 않거나, 검색이 프레임의 가장자리를 벗어나면 NULL이 반환됩니다.{}지정된<기호>에 마지막으로 매핑된 첫 번째 행에 대해 현재 행(또는FINAL의미 체계의 경우 마지막 행)을 포함하여 이로부터 시작해 윈도우 프레임을 역방향으로 검색한 다음,<오프셋>(기본값은 1) 행 앞으로 이동하고, 해당 행이 매핑된 기호를 무시합니다. 프레임의 검색된 부분이<symbol>에 매핑된 행을 포함하지 않거나, 검색이 프레임의 가장자리를 벗어나면 NULL이 반환됩니다.{}지정된<기호>에 마지막으로 매핑된 첫 번째 행에 대해 첫 번째 행을 포함하여 이로부터 시작해 현재 행(또는FINAL의미 체계의 경우 마지막 행)을 포함하여 여기까지 윈도우 프레임을 앞으로 검색합니다. 프레임의 검색된 부분이<symbol>에 매핑된 행을 포함하지 않으면 NULL이 반환됩니다.{}지정된<기호>에 마지막으로 매핑된 첫 번째 행에 대해 현재 행(또는FINAL의미 체계의 경우 마지막 행)을 포함하여 이로부터 시작해 윈도우 프레임을 역방향으로 검색합니다. 프레임의 검색된 부분이<symbol>에 매핑된 행을 포함하지 않으면 NULL이 반환됩니다.
참고
윈도우 함수에 대한 제한 사항은 DEFINE 및 MEASURES 에서 사용되는 윈도우 함수에 대한 제한 사항 섹션에 설명되어 있습니다.
DEFINE 및 MEASURES 에서 사용되는 윈도우 함수에 대한 제한 사항¶
DEFINE 및 MEASURES 하위 절의 식에는 윈도우 함수가 포함될 수 있습니다. 그러나 이러한 하위 절에서 윈도우 함수를 사용하는 데에는 몇 가지 제한 사항이 있습니다. 이러한 제한 사항은 아래 표에 나와 있습니다.
함수
DEFINE (실행 중) [column/symbol.column]
MEASURES (실행 중) [column/symbol.column]
MEASURES (최종) [column/symbol.column]
열
✔ / ❌
✔ / ❌
✔ / ✔
PREV(…)
❌ / ❌
✔ / ❌
✔ / ❌
NEXT(…)
✔ / ❌
✔ / ❌
✔ / ❌
FIRST(…)
❌ / ❌
✔ / ❌
✔ / ✔
LAST(…)
✔ / ❌
✔ / ❌
✔ / ✔
LAG()
✔ / ❌
✔ / ❌
✔ / ❌
LEAD()
✔ / ❌
✔ / ❌
✔ / ❌
FIRST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
LAST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
집계 [1]
✔ / ❌
✔ / ✔
✔ / ✔
기타 윈도우 함수 [1]
✔ / ❌
✔ / ❌
✔ / ❌
MATCH_RECOGNIZE 관련 함수 MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER(), CLASSIFIER() 는 현재 DEFINE 하위 절에서 사용할 수 없습니다.
문제 해결하기¶
오류 메시지: ONE ROW PER MATCH를 사용할 때 “열이 없는 SELECT”¶
ONE ROW PER MATCH 절을 사용할 때 PARTITION BY 및 MEASURES 하위 절의 열 및 식만 SELECT의 프로젝션 절에서 허용됩니다. PARTITION BY 또는 MEASURES 절 없이 MATCH_RECOGNIZE 를 사용하려고 하는 경우, SELECT with no columns 와 유사한 오류가 발생합니다.
ONE ROW PER MATCH vs. ALL ROWS PER MATCH 에 대한 자세한 내용은 각 일치에 대해 행 1개 생성하기 vs 각 일치에 대해 모든 행 생성하기 을 참조하십시오.
예¶
패턴과 일치하는 행의 시퀀스 찾기 항목에는 여기에 있는 대부분의 예보다 간단한 일부를 포함하여 많은 예가 있습니다. MATCH_RECOGNIZE 에 아직 익숙하지 않은 경우, 먼저 이러한 예를 읽어보는 것이 좋습니다.
아래의 일부 예에서는 다음 테이블과 데이터를 사용합니다.
다음 그래프는 곡선의 모양을 보여줍니다.
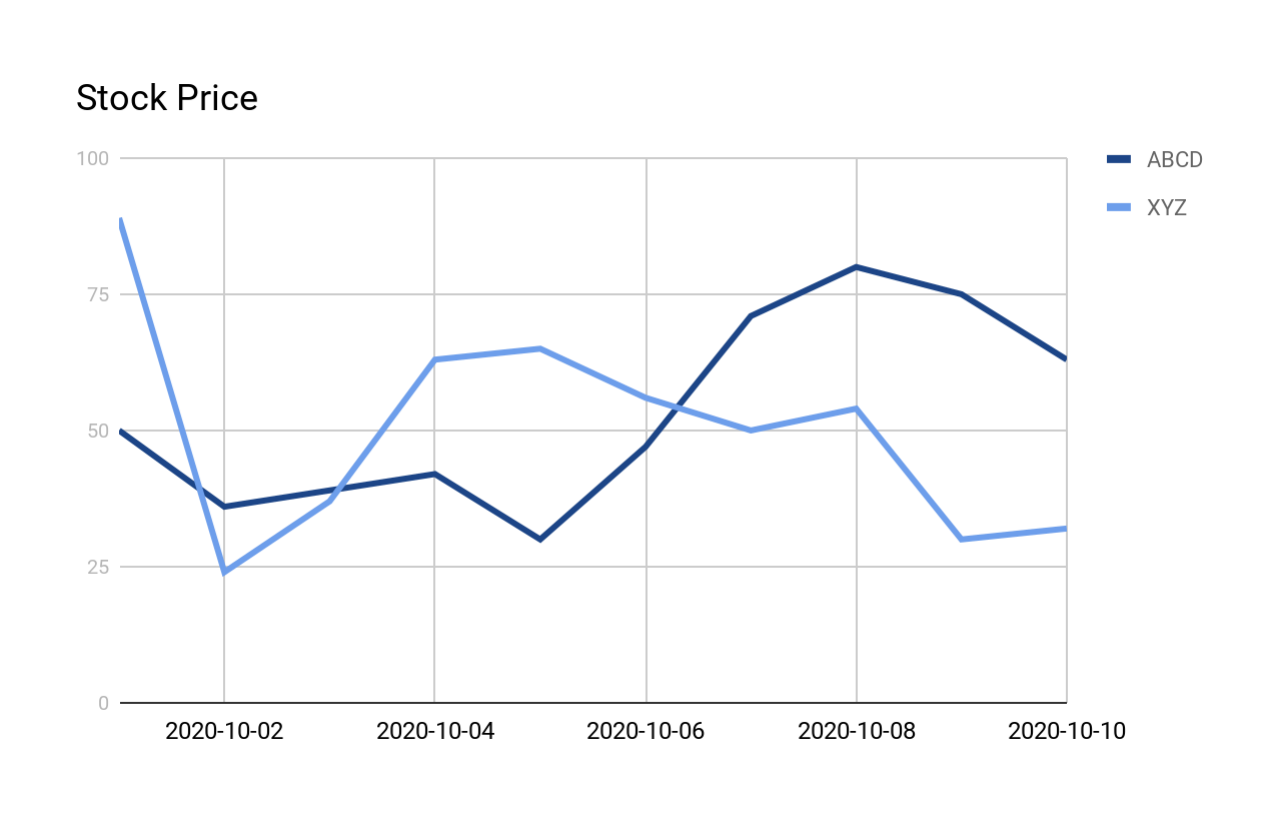
각 V 모양에 대해 하나의 요약 행 보고¶
다음 쿼리는 이전에 제시된 stock_price_history에서 모든 V 모양을 검색합니다. 출력은 쿼리 및 출력 이후에 자세히 설명됩니다.
출력에는 일치 항목당 하나의 행이 표시됩니다(일치 항목에 포함된 행 수와 관계없이 표시).
출력에는 다음 열이 포함됩니다.
COMPANY: 회사의 주식 기호입니다.
MATCH_NUMBER는 이 데이터 세트 내에서 일치 항목을 식별하는 순차적 번호입니다(예: 첫 번째 일치에는 MATCH_NUMBER 1, 두 번째 일치에는 MATCH_NUMBER 2 등). 데이터가 분할된 경우, MATCH_NUMBER는 (이 예의 경우, 각 회사/주식에 대한) 파티션 내의 순차적 번호입니다.
START_DATE: 이 패턴 발생이 시작되는 날짜입니다.
END_DATE: 이 패턴 발생이 끝나는 날짜입니다.
ROWS_IN_SEQUENCE: 이는 일치하는 행의 수입니다. 예를 들어, 첫 번째 일치 항목은 4일(10월 1일~10월 4일)에 측정된 가격을 기반으로 하므로 ROWS_IN_SEQUENCE는 4입니다.
NUM_DECREASES: 가격이 하락한 일수(일치 항목 내)입니다. 예를 들어, 첫 번째 일치 항목에서 가격이 1일간 하락한 후 2일간 상승했으므로 NUM_DECREASES는 1입니다.
NUM_INCREASES: 가격이 오른 일수(일치 항목 내)입니다. 예를 들어, 첫 번째 일치 항목에서 가격이 1일간 하락한 후 2일간 상승했으므로 NUM_INCREASES는 2입니다.
한 회사의 모든 일치 항목에 대해 모든 행 보고¶
이 예는 각 일치 항목 내의 모든 행을 반환합니다(일치 항목당 하나의 요약 행이 아님). 이 패턴은 ‘ABCD’ 회사의 가격 상승을 검색합니다.
빈 일치 항목 생략¶
이는 회사 전체 차트의 평균보다 높은 가격대를 검색합니다. 이 예에서는 빈 일치 항목을 생략합니다. 그러나 빈 일치 항목이라 하더라도 MATCH_NUMBER는 증가합니다.
WITH UNMATCHED ROWS 옵션 시연¶
이 예는 WITH UNMATCHED ROWS option 옵션을 보여줍니다. 위의 빈 일치 항목 생략 예와 같이, 이 예는 각 회사 차트의 평균 가격보다 높은 가격대를 검색합니다. 이 쿼리의 수량자는 + 이고, 이전 쿼리의 수량자는 * 입니다.
MEASURES 절에서 기호 조건자 표시¶
이 예는 기호 조건자와 함께 <symbol>.<column> 표기법의 사용을 보여줍니다.