- Categorias:
MATCH_RECOGNIZE¶
Reconhece correspondências de um padrão em um conjunto de linhas. MATCH_RECOGNIZE aceita um conjunto de linhas (de uma tabela, visualização, subconsulta ou outra fonte) como entrada, e retorna todas as correspondências de um determinado padrão de linha dentro deste conjunto. O padrão é definido de forma semelhante a uma expressão regular.
A cláusula também pode retornar:
Todas as linhas pertencentes a cada correspondência.
Uma linha de resumo por correspondência.
MATCH_RECOGNIZE é tipicamente usado para detectar eventos em séries temporais. Por exemplo, MATCH_RECOGNIZE pode pesquisar em uma tabela de histórico de preços de ações por formas como V (para baixo seguido de para cima) ou W (para baixo, para cima, para baixo, para cima).
MATCH_RECOGNIZE é uma subcláusula opcional da cláusula FROM.
Nota
Você não pode usar a cláusula MATCH_RECOGNIZE em uma expressão de tabela comum (CTE) **recursiva**.
Sintaxe¶
Subcláusulas obrigatórias¶
DEFINE: definição de símbolos¶
Os símbolos (também conhecidos como “variáveis de padrão”) são os blocos de construção do padrão.
Um símbolo é definido por uma expressão. Se a expressão for avaliada como verdadeira para uma linha, o símbolo é atribuído a essa linha. A uma linha podem ser atribuídos múltiplos símbolos.
Os símbolos que não estão definidos na cláusula DEFINE, mas que são usados no padrão, são sempre atribuídos a todas as linhas. Implicitamente, eles são equivalentes ao exemplo a seguir:
Os padrões são definidos com base em símbolos e operadores.
PATTERN: especificação do padrão a atender¶
O padrão define uma sequência válida de linhas que representa uma correspondência. O padrão é definido como uma expressão regular (regex) e é construído a partir de símbolos, operadores e quantificadores.
Por exemplo, suponha que o símbolo S1 seja definido como stock_price < 55, e o símbolo S2 seja definido como stock price > 55. O seguinte padrão especifica uma sequência de linhas nas quais o preço das ações aumentou de menos de 55 para obter mais de 55:
O seguinte é um exemplo mais complexo para uma definição de padrão:
A seção seguinte descreve em detalhes os componentes individuais deste padrão.
Nota
MATCH_RECOGNIZE usa rastreamento inverso para atender padrões. Como é o caso de outros mecanismos de expressão regular que usam rastreamento inverso, algumas combinações de padrões e dados para correspondência podem levar muito tempo para serem executadas, o que pode resultar em altos custos de computação.
Para melhorar o desempenho, defina um padrão que seja o mais específico possível:
Certifique-se de que cada linha corresponda apenas a um símbolo ou a um pequeno número de símbolos
Evite usar símbolos que façam correspondência a cada linha (por exemplo, símbolos que não estejam na cláusula
DEFINEou símbolos que sejam definidos como verdadeiro)Defina um limite superior para quantificadores (por exemplo,
{,10}em vez de*).
Por exemplo, o seguinte padrão pode resultar em aumento de custos se nenhuma linha corresponder:
Se houver um limite superior para o número de linhas que você deseja fazer a correspondência, você pode especificar esse limite nos quantificadores para melhorar o desempenho. Além disso, em vez de especificar que você deseja encontrar any_symbol depois de symbol1, você pode procurar uma linha que não seja symbol1 (not_symbol1, neste exemplo);
Em geral, você deve monitorar o tempo de execução da consulta para verificar se ela não está demorando mais do que o esperado.
- Símbolos:
Um símbolo corresponde a uma linha à qual esse símbolo foi atribuído. Os seguintes símbolos estão disponíveis:
symbol. Por exemplo,S1, … ,S4Estes são símbolos definidos na subcláusulaDEFINEe são avaliados por linha. (Eles também podem incluir símbolos que não foram definidos e são automaticamente atribuídos a todas as linhas).^(início da partição). Este é um símbolo virtual que denota o início de uma partição e não tem nenhuma linha associada a ela. Você pode usá-lo para exigir que uma correspondência comece apenas no início de uma partição.Para obter um exemplo, consulte Correspondência de padrões relativos ao início ou ao fim de uma partição.
$(fim da partição.) Este é um símbolo virtual que denota o fim de uma partição e não tem nenhuma linha associada a ela. Você pode usá-lo para exigir que uma correspondência termine apenas no fim de uma partição.Para obter um exemplo, consulte Correspondência de padrões relativos ao início ou ao fim de uma partição.
- Quantificadores:
Um quantificador pode ser colocado depois de um símbolo ou operação. Um quantificador denota o número mínimo e máximo de ocorrências do símbolo ou operação associada. Os seguintes quantificadores estão disponíveis:
Quantificador
Significado
+1 ou mais. Por exemplo,
( {- S3 -} S4 )+.
*0 ou mais. Por exemplo,
S2*?.
?0 ou 1.
{n}Exatamente n.
{n,}n ou mais.
{,m}0 a m.
{n, m}n a m. Por exemplo,
PERMUTE(S1, S2){1,2}.
Por padrão, os quantificadores estão em “modo ganancioso”, o que significa que eles tentam igualar a quantidade máxima, se possível. Para colocar um quantificador no “modo relutante”, no qual o quantificador tenta igualar a quantidade mínima, se possível, coloque um ? após o quantificador (por exemplo, S2*?).
- Operadores:
Os operadores especificam em que ordem os símbolos ou outras operações devem ocorrer na sequência de linhas para formar uma correspondência válida. Os seguintes operadores estão disponíveis:
Operador
Significado
... ...(espaço)Concatenação. Especifica que um símbolo ou operação deve seguir outro. Por exemplo,
S1 S2significa que a condição definida paraS2deve ocorrer após a condição definida paraS1.
{- ... -}Exclusão. Exclui da saída os símbolos ou operações contidos. Por exemplo,
{- S3 -}exclui o operadorS3da saída. As linhas excluídas não aparecerão na saída, mas serão incluídas na avaliação das expressõesMEASURES.
( ... )Agrupamento. Usado para anular a precedência de um operador ou para aplicar o mesmo quantificador para símbolos ou operações no grupo. Neste exemplo, o quantificador
+se aplica à sequência{- S3 -} S4, e não apenasS4.
PERMUTE(..., ...)Permutação. Corresponde a qualquer permutação dos padrões especificados. Por exemplo,
PERMUTE(S1, S2)corresponde aS1 S2ouS2 S1.PERMUTE()tem um número ilimitado de argumentos.
... | ...Alternativa. Especifica que ou o primeiro símbolo ou operação ou o outro deve ocorrer. Por exemplo,
( S3 S4 ) | PERMUTE(S1, S2). O operador alternativo tem precedência sobre o operador de concatenação.
Subcláusulas opcionais¶
ORDER BY: ordenação das linhas antes da correspondência¶
ORDER BY orderItem1 [ , orderItem2 ... ]Onde:
Defina a ordem das linhas como você faria para as funções de janela. Esta é a ordem em que as linhas individuais de cada partição são passadas ao operador
MATCH_RECOGNIZE.Para obter mais informações, consulte Partição e classificação das linhas.
PARTITION BY: particionamento das linhas em janelas¶
PARTITION BY <expr1> [ , <expr2> ... ]Particionar o conjunto de linhas de entrada como você faria para funções de janela.
MATCH_RECOGNIZEfaz a correspondência individualmente para cada partição resultante.A partição não apenas agrupa linhas que estão relacionadas entre si, mas também aumenta a capacidade de processamento de dados distribuídos do Snowflake, pois as partições separadas podem ser processadas em paralelo.
Para obter mais informações sobre partições, consulte Partição e classificação das linhas.
MEASURES: especificação de colunas de saída adicionais¶
As “Medidas” são colunas adicionais opcionais que são adicionadas à saída do operador MATCH_RECOGNIZE. As expressões na subcláusula MEASURES têm as mesmas capacidades que as expressões na subcláusula DEFINE. Para obter mais informações, consulte Símbolos.
Dentro da subcláusula MEASURES, estão disponíveis as seguintes funções específicas para MATCH_RECOGNIZE:
MATCH_NUMBER()retorna o número sequencial da correspondência. O MATCH_NUMBER começa de 1, e é incrementado para cada correspondência.MATCH_SEQUENCE_NUMBER()retorna o número da linha dentro de uma correspondência. O MATCH_SEQUENCE_NUMBER é sequencial e começa a partir de 1.CLASSIFIER()retorna um valor TEXT que contém o símbolo correspondido pela linha. Por exemplo, se uma linha corresponder ao símboloGT75, então a funçãoCLASSIFIERretorna a cadeia de caracteres “GT75”.
Nota
Ao especificar as medidas, lembre-se das restrições mencionadas na seção Limitações das funções de janela utilizadas em DEFINE e MEASURES.
ROW(S) PER MATCH: especificação das linhas a retornar¶
Especifica quais linhas são retornadas para uma correspondência bem sucedida. Esta subcláusula é opcional.
ALL ROWS PER MATCH: retorna todas as linhas na correspondência.ONE ROW PER MATCH: retorna uma linha de resumo para cada correspondência, independentemente de quantas linhas estejam na correspondência. Este é o padrão.
Tenha atenção aos seguintes casos especiais:
Correspondências vazias: uma correspondência vazia acontece se um padrão corresponder a zero linhas. Por exemplo, se o padrão for definido como
A*e a primeira linha no início de uma tentativa de correspondência for atribuída ao símboloB, então é gerada uma correspondência vazia incluindo apenas essa linha, pois o quantificador*no padrãoA*permite que 0 ocorrências deAsejam tratadas como uma correspondência. As expressõesMEASURESsão avaliadas de forma diferente para esta linha:A função CLASSIFIER retorna NULL.
As funções de janela retornam NULL.
A função COUNT retorna 0.
Linhas sem correspondência: se uma linha não corresponder ao padrão, ela é chamada de linha sem correspondência.
MATCH_RECOGNIZEtambém pode ser configurado para retornar linhas sem correspondência. Para linhas sem correspondência, as expressões na subcláusulaMEASURESretornam NULL.
Exclusões
A sintaxe de exclusão
({- ... -})na definição do padrão permite que os usuários excluam determinadas linhas da saída. Se todos os símbolos combinados no padrão foram excluídos, nenhuma linha é gerada para essa correspondência seALL ROWS PER MATCHfoi especificado. Note que MATCH_NUMBER é incrementado de qualquer forma. As linhas excluídas não fazem parte do resultado, mas estão incluídas para a avaliação das expressõesMEASURES.Ao utilizar a sintaxe de exclusão, a subcláusula ROWS PER MATCH pode ser especificada como segue:
ONE ROW PER MATCH (padrão)
Retorna exatamente uma linha para cada correspondência bem sucedida. A semântica padrão da função de janela para funções de janela na subcláusula
MEASURESéFINAL.As colunas de saída do operador
MATCH_RECOGNIZEsão todas as expressões dadas na subcláusulaPARTITION BYe todas as expressõesMEASURES. Todas as linhas resultantes de uma correspondência são agrupadas pelas expressões dadas na subcláusulaPARTITION BYeMATCH_NUMBERusando a função de agregaçãoANY_VALUEpara todas as medidas. Portanto, se as medidas são avaliadas como um valor diferente para linhas diferentes da mesma correspondência, então a saída é não determinística.Omitir as subcláusulas
PARTITION BYeMEASURESresulta em um erro indicando que o resultado não inclui nenhuma coluna.Para correspondências vazias, é gerada uma linha. Linhas sem correspondência não fazem parte da saída.
ALL ROWS PER MATCHRetorna uma linha para cada linha que faz parte da correspondência, exceto para as linhas que foram correspondidas com uma parte do padrão que foi marcada para exclusão.
Linhas excluídas ainda são levadas em conta nos cálculos da subcláusula
MEASURES.As correspondências podem se sobrepor com base na subcláusula
AFTER MATCH SKIP TO, de modo que a mesma linha pode aparecer várias vezes na saída.A semântica padrão da função de janela para funções de janela na subcláusula
MEASURESéRUNNING.As colunas de saída do operador
MATCH_RECOGNIZEsão as colunas do conjunto de linhas a serem entradas e as colunas definidas na subcláusulaMEASURES.As seguintes opções estão disponíveis para
ALL ROWS PER MATCH:SHOW EMPTY MATCHES (default)Adiciona correspondências vazias à saída. Linhas sem correspondência não fazem parte da saída.OMIT EMPTY MATCHESCorrespondências vazias ou linhas sem correspondência não fazem parte da saída. No entanto, o MATCH_NUMBER ainda é incrementado por uma correspondência vazia.WITH UNMATCHED ROWSAdiciona correspondências vazias e linhas sem correspondência à saída. Se esta cláusula for utilizada, então o padrão não deve conter exclusões.
Para um exemplo que utiliza a exclusão para reduzir a saída irrelevante, consulte Pesquisa de padrões em linhas não adjacentes.
AFTER MATCH SKIP: especificação de onde continuar após uma correspondência¶
Esta subcláusula especifica onde continuar a correspondência após ter sido encontrada uma correspondência positiva.
PAST LAST ROW (default)Continuar a correspondência após a última linha da correspondência atual.
Isso evita correspondências que tenham linhas sobrepostas. Por exemplo, se você tem um padrão de ação que contém 3
Vformas em uma linha, entãoPAST LAST ROWencontra um padrãoWe não dois.TO NEXT ROWContinuar a correspondência após a primeira linha da correspondência atual.
Isto permite combinações que contêm linhas sobrepostas. Por exemplo, se você tem um padrão de ação que contém 3 formas
Vem uma linha, entãoTO NEXT ROWencontra dois padrõesW(o primeiro padrão é baseado nas duas primeiras formasVe a segunda formaWé baseada nas segunda e terceira formasV; assim, ambos os padrões contêm o mesmoV).TO [ { FIRST | LAST } ] <símbolo>Continuar a correspondência na primeira ou última linha (padrão) que foi correspondida com o símbolo dado.
Pelo menos uma linha precisa ser mapeada para o símbolo dado ou um erro é acusado.
Se isso não passar da primeira linha da correspondência atual, então um erro é acusado.
Notas de uso¶
Expressões nas cláusulas DEFINE e MEASURES.¶
As cláusulas DEFINE e MEASURES permitem expressões. Essas expressões podem ser complexas e podem incluir funções de janela e funções especiais de navegação (que são um tipo de função de janela).
Na maioria dos aspectos, as expressões em DEFINE e MEASURES seguem as regras para expressões em outros lugares na sintaxe SQL do Snowflake. No entanto, existem algumas diferenças, que são descritas abaixo:
- Funções de janela:
-
PREV( expr [ , offset [, default ] ] )Navegar para a linha anterior na correspondência atual na subcláusula MEASURES.Esta função não está disponível atualmente na subcláusula DEFINE. Em vez disso, você pode usar LAG, que navega para a linha anterior no quadro da janela atual.
NEXT( expr [ , offset [ , default ] ] )Navegar para a próxima linha dentro do quadro da janela atual. Esta função é equivalente a LEAD.FIRST( expr )Navegar para a primeira linha da correspondência atual na subcláusula MEASURES.Esta função não está disponível atualmente na subcláusula DEFINE. Em vez disso, você pode usar FIRST_VALUE, que navega para a primeira linha do quadro da janela atual.
LAST( expr )Navegar para a última linha do quadro da janela atual. Esta função é semelhante a LAST_VALUE, mas para LAST o quadro da janela é limitado à linha atual da correspondência atual quando LAST é usado dentro da subcláusula DEFINE.
Para um exemplo que utiliza as funções de navegação, consulte Retorno de informações sobre a correspondência.
Em geral, quando uma função de janela é usada dentro de uma cláusula
MATCH_RECOGNIZE, a função de janela não requer sua própria cláusulaOVER (PARTITION BY ... ORDER BY ...). A janela é implicitamente determinada porPARTITION BYeORDER BYda cláusulaMATCH_RECOGNIZE. (No entanto, consulte Limitações das funções de janela utilizadas em DEFINE e MEASURES para algumas exceções).Em geral, o quadro da janela também é explicitamente derivado do contexto atual no qual a função de janela está sendo usada. O limite inferior do quadro é definido como descrito abaixo:
Na subcláusula
DEFINE:O quadro começa no início da tentativa de correspondência atual, exceto quando se usa
LAG,LEAD,FIRST_VALUEeLAST_VALUE.Na subcláusula
MEASURES:O quadro começa no início da correspondência que foi encontrada.
As bordas do quadro da janela podem ser especificadas usando a semântica
RUNNINGouFINAL.RUNNING:Em geral, o quadro termina na linha atual. No entanto, existem as seguintes exceções:
Na subcláusula
DEFINE, paraLAG,LEAD,FIRST_VALUE,LAST_VALUEeNEXT, o quadro termina na última linha da janela.Na subcláusula
MEASURES, paraPREV,NEXT,LAGeLEAD, o quadro termina na última linha da janela.
Na subcláusula
DEFINE,RUNNINGé a semântica padrão (e a única permitida).Na subcláusula
MEASURES, quando a subcláusulaALL ROWS PER MATCHé usada,RUNNINGé o padrão.FINAL:O quadro termina na última linha da correspondência.
FINALé permitido somente na subcláusulaMEASURES. É o padrão lá quandoONE ROW PER MATCHse aplica. - Predicados do símbolo:
Expressões dentro das subcláusulas
DEFINEeMEASURESpermitem símbolos como predicados para referências de colunas.O
<símbolo>indica uma linha que foi correspondida, e a<coluna>identifica uma coluna específica dentro dessa linha.Uma referência de coluna predicada significa que a função de janela ao redor só olha para linhas que foram finalmente mapeadas para o símbolo especificado.
As referências predicadas de colunas podem ser usadas fora e dentro de uma função de janela. Se usado fora de uma função de janela,
<symbol>.<column>é igual aLAST(<symbol>.<column>). Dentro de uma função de janela, todas as referências de colunas precisam ser predicadas com o mesmo símbolo ou são todas não predicadas.A seguir, explicamos como as funções relacionadas à navegação se comportam com referências de colunas predicadas:
PREV/LAG( ... <symbol>.<column> ... , <offset>)Procura o quadro da janela para trás começando de e incluindo a linha atual (ou última linha no caso de uma semânticaFINAL) para a primeira linha que foi finalmente mapeada para o<símbolo>especificado, e depois vai para trás linhas<offset>(o padrão é 1), ignorando o símbolo para o qual essas linhas foram mapeadas. Se a parte pesquisada do quadro não contiver uma linha mapeada para<símbolo>ou a pesquisa for além da borda do quadro, então NULL é retornado.NEXT/LEAD( ... <symbol>.<column> ... , <offset>)Procura o quadro da janela para trás começando de e incluindo a linha atual (ou última linha no caso de uma semânticaFINAL) para a primeira linha que foi finalmente mapeada para o<símbolo>especificado, e depois vai para frente linha<offset>(o padrão é 1), ignorando o símbolo para o qual essas linhas foram mapeadas. Se a parte pesquisada do quadro não contiver uma linha mapeada para<símbolo>ou a pesquisa for além da borda do quadro, então NULL é retornado.FIRST/FIRST_VALUE( ... <symbol>.<column> ... )Procura o quadro da janela para frente começando de e incluindo a primeira linha até e incluindo a linha atual (ou última linha no caso de uma semânticaFINAL) para a primeira linha que foi finalmente mapeada para o<símbolo>especificado. Se a parte pesquisada do quadro não contiver uma linha mapeada para<símbolo>, NULL é retornado.LAST/LAST_VALUE( ... <symbol>.<column> ... )Procura o quadro da janela para trás começando de e incluindo a linha atual (ou última linha no caso de uma semânticaFINAL) para a primeira linha que foi finalmente mapeada para o<símbolo>especificado. Se a parte pesquisada do quadro não contiver uma linha mapeada para<símbolo>, NULL é retornado.
Nota
As restrições nas funções de janela estão documentadas na seção Limitações das funções de janela utilizadas em DEFINE e MEASURES.
Limitações das funções de janela utilizadas em DEFINE e MEASURES¶
Expressões nas subcláusulas DEFINE e MEASURES podem incluir funções de janela. No entanto, há algumas limitações no uso de funções de janela nestas subcláusulas. Estas limitações são mostradas na tabela abaixo:
Função
DEFINE (Em execução) [coluna/símbolo.coluna]
MEASURES (Em execução) [coluna/símbolo.coluna]
MEASURES (Final) [coluna/símbolo.coluna]
Coluna
✔ / ❌
✔ / ❌
✔ / ✔
PREV(…)
❌ / ❌
✔ / ❌
✔ / ❌
NEXT(…)
✔ / ❌
✔ / ❌
✔ / ❌
FIRST(…)
❌ / ❌
✔ / ❌
✔ / ✔
LAST(…)
✔ / ❌
✔ / ❌
✔ / ✔
LAG()
✔ / ❌
✔ / ❌
✔ / ❌
LEAD()
✔ / ❌
✔ / ❌
✔ / ❌
FIRST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
LAST_VALUE()
✔ / ❌
✔ / ❌
✔ / ✔
Agregações [1]
✔ / ❌
✔ / ✔
✔ / ✔
Outras funções de janela [1]
✔ / ❌
✔ / ❌
✔ / ❌
As funções específicas de MATCH_RECOGNIZE MATCH_NUMBER(), MATCH_SEQUENCE_NUMBER() e CLASSIFIER() não estão atualmente disponíveis na subcláusula DEFINE.
Solução de problemas¶
Mensagem de erro: «SELECT sem colunas» ao usar ONE ROW PER MATCH¶
Quando você utiliza a cláusula ONE ROW PER MATCH, somente colunas e expressões das subcláusulas PARTITION BY e MEASURES são permitidas na cláusula de projeção de SELECT. Se você tentar usar MATCH_RECOGNIZE sem uma cláusula PARTITION BY ou MEASURES, você receberá um erro semelhante a SELECT with no columns.
Para obter mais informações sobre ONE ROW PER MATCH vs. ALL ROWS PER MATCH, consulte Geração de uma linha vs. geração de todas as linhas para cada correspondência.
Exemplos¶
O tópico Identificação de sequências de linhas que correspondem a um padrão contém muitos exemplos, incluindo alguns que são mais simples do que a maioria dos exemplos aqui apresentados. Se você ainda não estiver familiarizado com MATCH_RECOGNIZE, então talvez você queira ler esses exemplos primeiro.
Alguns dos exemplos abaixo utilizam a seguinte tabela e dados:
O gráfico a seguir mostra as formas das curvas:
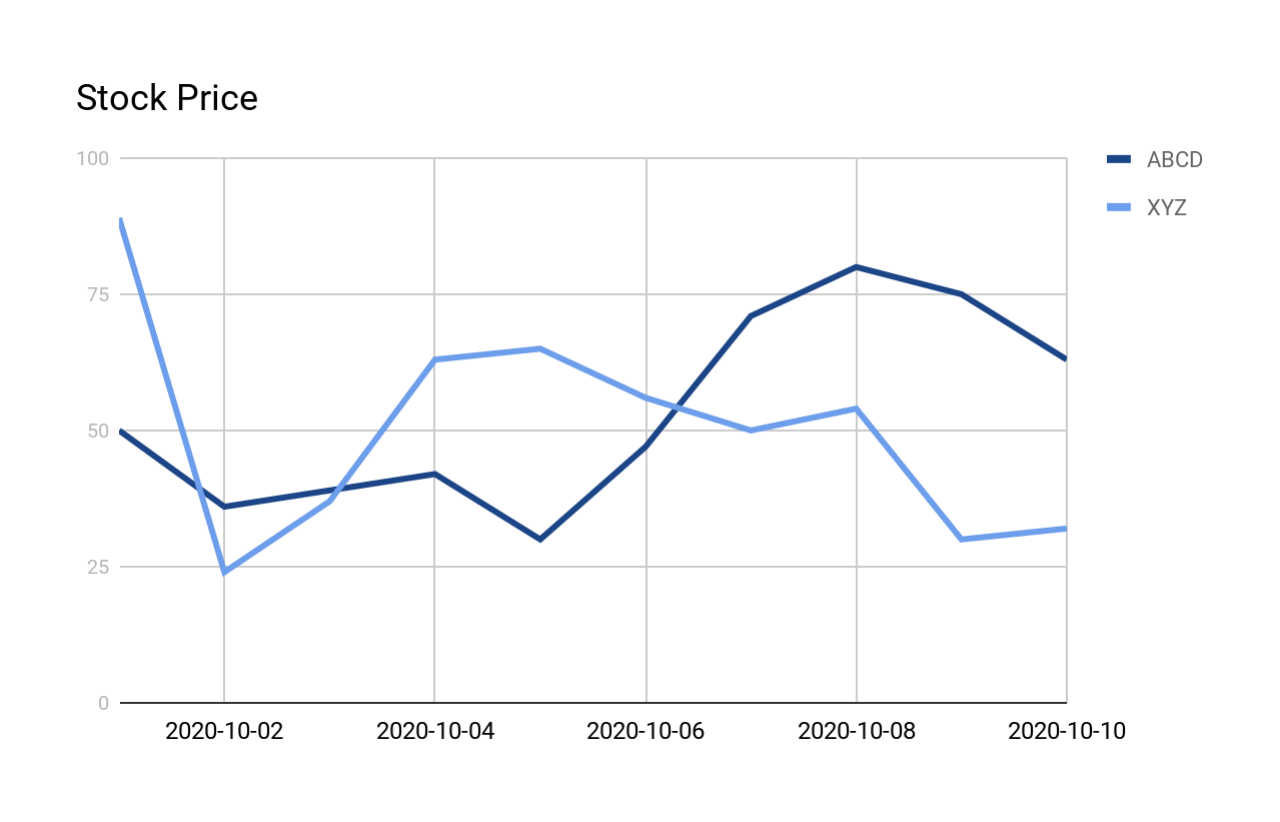
Relatório uma linha de resumo para cada forma V¶
A consulta a seguir busca todas as formas V no stock_price_history apresentado anteriormente. A saída é explicada com mais detalhes após a consulta e a saída.
A saída mostra uma linha por correspondência (independentemente de quantas linhas faziam parte da correspondência).
A saída inclui as seguintes colunas:
COMPANY: o símbolo das ações da empresa.
O MATCH_NUMBER é um número sequencial que identifica qual correspondência estava dentro deste conjunto de dados (por exemplo, a primeira correspondência tem MATCH_NUMBER 1, a segunda correspondência tem MATCH_NUMBER 2 etc.). Se os dados foram particionados, então o MATCH_NUMBER é o número sequencial dentro da partição (neste exemplo, para cada empresa/ação).
START_DATE: a data em que esta ocorrência do padrão começa.
END_DATE: a data em que esta ocorrência do padrão termina.
ROWS_IN_SEQUENCE: este é o número de linhas na correspondência. Por exemplo, a primeira correspondência é baseada nos preços medidos em 4 dias (1º de outubro até 4 de outubro), portanto ROWS_IN_SEQUENCE é 4.
NUM_DECREASES: este é o número de dias (dentro da correspondência) em que o preço caiu. Por exemplo, na primeira correspondência, o preço caiu por 1 dia e depois subiu por 2 dias, portanto NUM_DECREASES é 1.
NUM_INCREASES: este é o número de dias (dentro da correspondência) em que o preço subiu. Por exemplo, na primeira correspondência, o preço caiu por 1 dia e depois subiu por 2 dias, portanto NUM_INCREASES é 2.
Relatório de todas as linhas para todas as correspondências de uma empresa¶
Este exemplo retorna todas as linhas dentro de cada correspondência (não apenas uma linha de resumo por correspondência). Este padrão busca o aumento dos preços da empresa ‘ABCD’:
Omissão de correspondências vazias¶
Isso procura por faixas de preço acima da média de todo o gráfico de uma empresa. Este exemplo omite as correspondências vazias. Observe, no entanto, que as correspondências vazias aumentam o MATCH_NUMBER:
Demonstrar a opção WITH UNMATCHED ROWS¶
Este exemplo demonstra a WITH UNMATCHED ROWS option. Como o exemplo Omissão de correspondências vazias acima, este exemplo procura por faixas de preço acima do preço médio do gráfico de cada empresa. Observe que o quantificador nesta consulta é +, enquanto o quantificador na consulta anterior era *:
Demonstração dos predicados do símbolo na cláusula MEASURES¶
Este exemplo mostra o uso da notação <símbolo>.<coluna> com predicados do símbolos: