動的テーブル¶
動的テーブルは、定義されたクエリとターゲットの鮮度に基づいて自動的に更新されるテーブルで、手動更新やカスタムスケジュールを必要とせず、データ変換とパイプライン管理を簡素化します。
動的テーブルを作成する際には、ベースオブジェクトからどのようにデータを変換するかを指定するクエリを定義します。Snowflakeは動的テーブルのリフレッシュスケジュールを処理し、クエリに基づいてベースオブジェクトに加えられた変更を反映するためにテーブルを自動的に更新します。
主な考慮事項と一般的なベストプラクティス¶
不変性制約:不変性制約を使用して、動的テーブルの更新を制御できるようにします。制約によって特定の行は静的な状態に保たれ、テーブルの残りの部分はインクリメンタルな更新が可能になります。マークされたデータへの不要な変更を防ぐ一方で、テーブルの他の部分には通常のリフレッシュが行われるようにします。詳しくは 不変性制約の理解 を参照してください。
主キー:Snowflakeは、信頼性の高い主キーを使用して、動的テーブルパイプラインの変更をより効率的に追跡します。動的テーブルにシステムから派生した主キーがある場合、上流のテーブルがフルリフレッシュモードを使用していても、下流のテーブルは増分リフレッシュを使用できます。詳細については、 動的テーブルの主キーを理解する をご参照ください。
パフォーマンスの考慮事項: 動的テーブルは、それをサポートするワークロードに対して増分処理を使用します。これは、テーブル全体を再計算する代わりに変更されたデータのみを処理することで、パフォーマンスを改善することができます。パフォーマンスは、クエリパターンとデータ組織に応じて異なります。動的テーブルのパフォーマンスの最適化に関するガイダンスについては、 動的テーブルのパフォーマンスおよび最適化 を参照してください。
複雑な動的テーブルを分割する: パフォーマンスを向上させ、トラブルシューティングを簡素化するために、パイプラインをより小さく、焦点を絞った動的テーブルに分割します。詳細については、 動的テーブル作成のベストプラクティス をご参照ください。
動的テーブルの仕組み¶
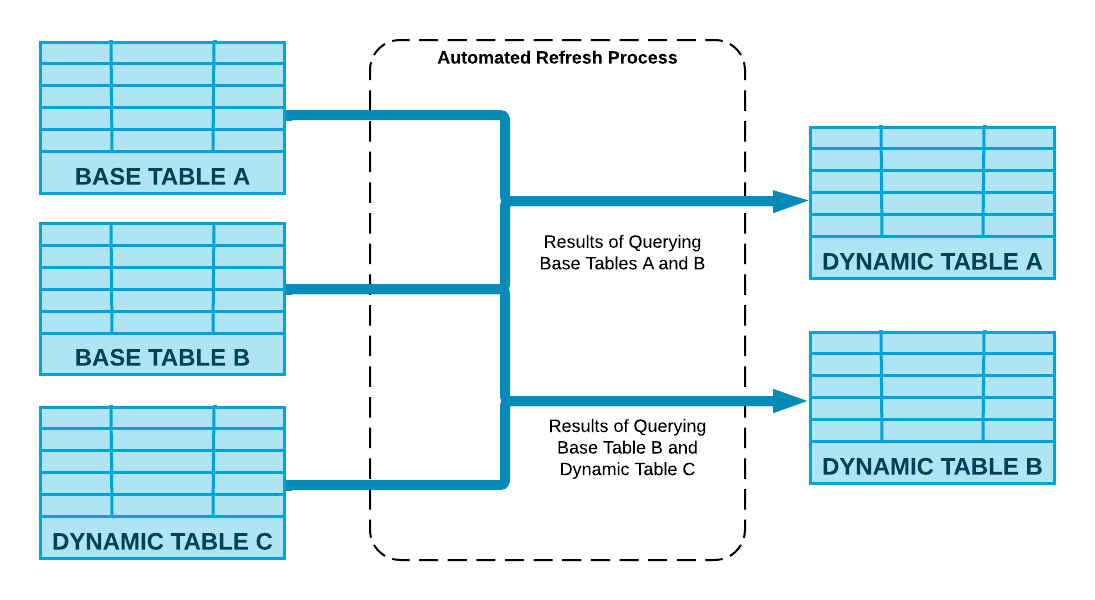
Snowflakeは CREATE DYNAMIC TABLE ステートメントで指定された定義クエリを実行し、動的テーブルは自動リフレッシュプロセスによって更新されます。
以下の図は、このプロセスがどのようにベースオブジェクトに加えられた変更を計算し、テーブルに関連付けられているコンピューティングリソースを使用して動的テーブルにマージするかを示しています。
ターゲットラグ¶
*ターゲットラグ*を使用して、データの鮮度を設定します。通常、テーブルデータの鮮度は、ベーステーブルデータの鮮度からそれほど遅れることはありません。ターゲットラグを使えば、テーブルのリフレッシュ頻度やデータの最新性をコントロールできます。ターゲットラグはリフレッシュ頻度とコンピューティングコストに影響します。
詳しくは、 動的テーブルのターゲット・ラグの理解 を参照してください。データの鮮度とパフォーマンスのバランスをとるためのガイダンスについては、 動的テーブルのパフォーマンスの最適化 を参照してください。
動的テーブルのリフレッシュ¶
動的テーブルは、指定したターゲットラグ内にリフレッシュすることを目的としています。たとえば、ターゲットラグを5分とすることで、動的テーブルのデータがベーステーブルのデータ更新から5分以上遅れないようにすることができます。リフレッシュモードはテーブル作成時に設定し、その後はスケジュールまたは手動でリフレッシュできます。
動的なテーブルの初期化とリフレッシュの理解 パラメーターで指定。詳細については、 動的なテーブルの初期化とリフレッシュの理解 および 動的テーブルの手動更新 をご参照ください。
動的テーブルを使用する場合¶
動的テーブルは次のようなシナリオに最適です。
カスタムコードを書かずにクエリ結果を実体化したい場合。
手動でデータの依存関係を追跡したり、リフレッシュスケジュールを管理したりすることは避けたいです。動的テーブルを使用すると、変換ステップを手動で管理することなく、パイプラインの結果を宣言的に定義できます。
データ変換のために複数のテーブルをパイプラインで連結したい場合。
リフレッシュスケジュールをきめ細かく制御する必要はなく、パイプラインのターゲット鮮度を指定するだけで済みます。Snowflakeは、ターゲットの鮮度要件に基づいて、スケジューリングと実行を含むデータリフレッシュのオーケストレーションを処理します。
使用例¶
ゆっくりと変化するディメンション (SCDs): 動的テーブルを使用して、変更ストリームから読み取り、変更タイムスタンプで並べ替えられた記録ごとのキーに対してウィンドウ関数を使用することで、タイプ 1 およびタイプ 2 SCDs を実装できます。このメソッドでは、挿入、削除、更新の順番が前後しても処理できるため、 SCDs の作成が簡単になります。詳細については、 動的テーブルを使用して、ゆっくりと変化するディメンションを実装する をご参照ください。
結合と集約: 高速なクエリを可能にするために、動的テーブルを使用して、遅い結合と集約を増分事前計算することができます。増分リフレッシュのためにこれらの演算子を最適化するためのガイダンスについては、 インクリメンタルリフレッシュ向けにクエリを最適化する を参照してください。
バッチからストリームへの遷移: 動的テーブルは、 ALTER DYNAMIC TABLE コマンドひとつでバッチからストリームへのシームレスな移行をサポートします。データ パイプ ラインの更新頻度を制御して、コストとデータの鮮度のバランスをとることができます。