Utilisation du connecteur Python¶
Ce chapitre fournit une série d’exemples illustrant comment utiliser le connecteur Snowflake pour effectuer des opérations Snowflake standard, telles que la connexion d’utilisateurs, la création de bases de données et de tables, la création d’entrepôts, l’insertion/le chargement de données et l’envoi de requêtes.
L’exemple de code à la fin de ce chapitre combine les exemples en un seul programme Python fonctionnel.
Note
Snowflake fournit maintenant des APIs Python de première classe pour gérer les ressources principales de Snowflake, y compris les bases de données, les schémas, les tables, les tâches et les entrepôts, sans utiliser SQL. Pour plus d’informations, voir Snowflake Python APIs : gestion des objets Snowflake avec Python.
Création d’une base de données, d’un schéma et d’un entrepôt¶
Après la connexion, créez une base de données, un schéma et un entrepôt, s’ils n’existent pas encore, en utilisant les commandes CREATE DATABASE, CREATE SCHEMA et CREATE WAREHOUSE.
L’exemple ci-dessous montre comment créer un entrepôt nommé tiny_warehouse, une base de données nommée testdb et un schéma nommé testschema. Notez que lorsque vous créez le schéma, vous devez spécifier le nom de la base de données dans laquelle créer le schéma ou vous devez déjà être connecté à la base de données dans laquelle créer le schéma. L’exemple ci-dessous exécute une commande USE DATABASE avant la commande CREATE SCHEMA pour s’assurer que le schéma est créé dans la base de données appropriée.
conn.cursor().execute("CREATE WAREHOUSE IF NOT EXISTS tiny_warehouse_mg") conn.cursor().execute("CREATE DATABASE IF NOT EXISTS testdb_mg") conn.cursor().execute("USE DATABASE testdb_mg") conn.cursor().execute("CREATE SCHEMA IF NOT EXISTS testschema_mg")
Utilisation de la base de données, du schéma et de l’entrepôt¶
Spécifiez la base de données et le schéma dans lesquels vous souhaitez créer les tables. Spécifiez également l’entrepôt qui fournira les ressources nécessaires à l’exécution des instructions et des requêtes DML.
Par exemple, pour utiliser la base de données testdb, le schéma testschema et l’entrepôt tiny_warehouse (créé dans la section précédente) :
conn.cursor().execute("USE WAREHOUSE tiny_warehouse_mg") conn.cursor().execute("USE DATABASE testdb_mg") conn.cursor().execute("USE SCHEMA testdb_mg.testschema_mg")
Création de tables et insertion de données¶
Utilisez la commande CREATE TABLE pour créer des tables et la commande INSERT pour remplir les tables avec des données.
Par exemple, créez une table nommée testtable et insérez deux lignes dans la table :
conn.cursor().execute( "CREATE OR REPLACE TABLE " "test_table(col1 integer, col2 string)") conn.cursor().execute( "INSERT INTO test_table(col1, col2) VALUES " + " (123, 'test string1'), " + " (456, 'test string2')")
Chargement des données¶
Au lieu d’insérer des données dans les tables à l’aide de commandes INSERT individuelles, vous pouvez charger en masse des données à partir de fichiers préparés dans un emplacement interne ou externe.
Copie de données à partir d’un emplacement interne¶
Pour charger des données de fichiers de votre machine hôte vers une table, utilisez d’abord la commande PUT pour placer le fichier dans un emplacement interne, puis utilisez la commande COPY INTO <table> pour copier les données des fichiers vers la table.
Par exemple :
# Putting Data con.cursor().execute("PUT file:///tmp/data/file* @%testtable") con.cursor().execute("COPY INTO testtable")Où vos données CSV sont stockées dans un répertoire local nommé
/tmp/datadans un environnement Linux ou macOS, et le répertoire contient des fichiers nommésfile0,file1, …file100.
Copie de données à partir d’un emplacement externe¶
Pour charger des données à partir de fichiers préparés dans un emplacement externe (c’est-à-dire votre propre compartiment S3) vers une table, utilisez la commande COPY INTO <table> .
Par exemple :
# Copying Data con.cursor().execute(""" COPY INTO testtable FROM s3://<s3_bucket>/data/ STORAGE_INTEGRATION = myint FILE_FORMAT=(field_delimiter=',') """.format( aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY))Où :
s3://<compartiment_s3>/data/spécifie le nom de votre compartiment S3Les fichiers dans le compartiment sont préfixés avec
data.Le compartiment est accessible à l’aide d’une intégration de stockage créée à l’aide de CREATE STORAGE INTEGRATION par un administrateur de compte (c’est-à-dire un utilisateur avec le rôle ACCOUNTADMIN) ou un rôle avec le privilège global CREATE INTEGRATION. Une intégration de stockage permet aux utilisateurs d’éviter de fournir des informations d’identification pour accéder à un emplacement de stockage privé.
Note
Cet exemple utilise la fonction format() pour composer l’instruction. Si votre environnement présente un risque d’attaques par injection SQL, vous pouvez, si vous le souhaitez, lier des valeurs plutôt que d’utiliser format().
Interrogation de données¶
Avec le connecteur Snowflake pour Python, vous pouvez soumettre :
une requête synchrone, qui renvoie le contrôle à votre application une fois la requête terminée.
une requête asynchrone, qui renvoie le contrôle à votre application avant la fin de la requête.
Une fois la requête terminée, vous utilisez l’objet Cursor pour récupérer les valeurs dans les résultats. Par défaut, le connecteur Snowflake pour Python convertit les valeurs des types de données Snowflake en types de données Python natifs. (Notez que vous pouvez choisir de renvoyer les valeurs sous forme de chaînes de caractères et d’effectuer les conversions de type dans votre application. Voir Amélioration des performances des requêtes en contournant la conversion des données.)
Note
Par défaut, les valeurs des colonnes NUMBER sont renvoyées sous forme de valeurs flottantes en double précision (float64). Pour les retourner sous forme de valeurs décimales (decimal.Decimal) dans les méthodes fetch_pandas_all() et fetch_pandas_batches() définissez le paramètre arrow_number_to_decimal de la méthode connect() sur True.
Exécution d’une requête synchrone¶
Pour effectuer une requête synchrone, appelez la méthode execute() dans l’objet Cursor. Par exemple :
conn = snowflake.connector.connect( ... )
cur = conn.cursor()
cur.execute('select * from products')
Utilisez l’objet Cursor pour récupérer les valeurs dans les résultats, comme expliqué dans Utilisation de cursor pour récupérer des valeurs.
Exécution d’une requête asynchrone¶
Le connecteur Snowflake pour Python prend en charge les requêtes asynchrones (c’est-à-dire les requêtes qui renvoient le contrôle à l’utilisateur avant la fin de la requête). Vous pouvez soumettre une requête asynchrone et utiliser l’interrogation pour déterminer quand la requête est terminée. Une fois la requête terminée, vous pouvez obtenir les résultats.
Note
Pour effectuer des requêtes asynchrones, vous devez vous assurer que le paramètre de configuration ABORT_DETACHED_QUERY est FALSE (valeur par défaut).
Si la connexion au client est perdue :
Pour les requêtes synchrones, toutes les requêtes synchrones en cours sont immédiatement abandonnées, quelle que soit la valeur du paramètre.
Pour les requêtes asynchrones :
Si ABORT_DETACHED_QUERY est réglé sur
FALSE, les requêtes asynchrones en cours continuent de s’exécuter jusqu’à ce qu’elles se terminent normalement.Si ABORT_DETACHED_QUERY est réglé sur
TRUE, Snowflake interrompt automatiquement toutes les requêtes asynchrones en cours lorsqu’une connexion client n’est pas rétablie après cinq minutes.Vous pouvez empêcher l’interruption de la requête asynchrone au bout de cinq minutes en appelant
cursor.query_result(queryId). Bien que cet appel ne permette pas de récupérer le résultat de la requête, puisque celle-ci est toujours en cours d’exécution, il empêche l’annulation de la requête. L’invocation dequery_resultest une opération synchrone, qui peut ou non convenir à votre cas d’utilisation particulier.
Grâce à cette fonction, vous pouvez soumettre plusieurs requêtes en parallèle sans attendre que chaque requête soit terminée. Vous pouvez également exécuter une combinaison de requêtes synchrones et asynchrones au cours de la même session.
Note
L’exécution de plusieurs instructions dans une seule requête nécessite qu’un entrepôt valide soit disponible dans une session.
Enfin, vous pouvez soumettre une requête asynchrone à partir d’une connexion et vérifier les résultats à partir d’une autre connexion. Par exemple, un utilisateur peut lancer une requête de longue durée à partir de votre application, quitter l’application et la relancer ultérieurement pour vérifier les résultats.
Pour mieux comprendre la hiérarchie de la logique métier des pilotes et l’interaction du paramètre ABORT_DETACHED_QUERY, consultez l’organigramme suivant :
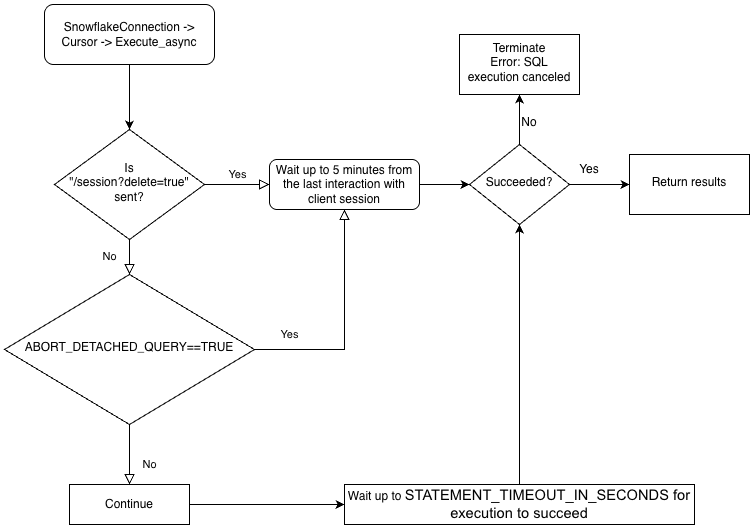
Soumission d’une requête asynchrone¶
Note
Les requêtes asynchrones ne prennent pas en charge les instructions PUT/GET.
Lorsque cursor.execute_async(query) est utilisé, le pilote Python de Snowflake conserve automatiquement le suivi des requêtes soumises de manière asynchrone. Lorsque la connexion est explicitement fermée avec connection.close() ou que le gestionnaire de contexte est utilisé avec connect()..., la liste des requêtes asynchrones est examinée et, si l’une d’entre elles est toujours en cours d’exécution, la session côté Snowflake n’est pas supprimée.
Si aucune requête asynchrone ne s’exécute dans la même connexion, la session Snowflake appartenant à la connexion est déconnectée lorsque connection.close() est appelé, ce qui annule implicitement toutes les autres requêtes exécutées dans la même session.
This behavior also depends on the SQL ABORT_DETACHED_QUERY parameter.
La meilleure pratique consiste à isoler toutes les tâches asynchrones de longue durée (en particulier celles destinées à se poursuivre après la fermeture de la connexion) dans une connexion séparée.
Vous pouvez utiliser le paramètre de connexion server_session_keep_alive (par défaut : False) pour remplacer ce comportement automatique. Par défaut, la session Snowflake est déconnectée lorsque connection.close() est appelé uniquement lorsqu’aucune requête asynchrone n’y est exécutée. Le comportement par défaut ne prend pas en compte ou ne suit pas les requêtes de synchronisation.
Lorsque server_session_keep_alive=True, connection.close() ne déconnectera pas la session Snowflake, quel que soit l’état des requêtes. Pour les connexions conçues pour émettre des requêtes asynchrones de longue durée, l’activation de ce paramètre peut réduire les frais généraux liés au CPU et accélérer le processus de fermeture de la connexion.
Important
L’activation de ce paramètre peut avoir des effets inattendus sur la facturation (par exemple, elle peut entraîner l’exécution de requêtes jusqu’à la valeur configurée de STATEMENT_TIMEOUT_IN_SECONDS). Snowflake vous recommande vivement de bien réfléchir avant de modifier la valeur par défaut de server_session_keep_alive et, si possible, de tester soigneusement cette modification dans les environnements hors production avant de la mettre en œuvre en production.
Pour soumettre une requête asynchrone, appelez la méthode execute_async() dans l’objet Cursor. Par exemple :
conn = snowflake.connector.connect( ... )
cur = conn.cursor()
# Submit an asynchronous query for execution.
cur.execute_async('select count(*) from table(generator(timeLimit => 25))')
Après avoir soumis la requête :
Pour déterminer si la requête est toujours en cours d’exécution, voir Vérification du statut d’une requête.
Pour récupérer les résultats de la requête, voir Utilisation de l’ID de requête pour récupérer les résultats d’une requête.
Pour des exemples d’exécution de requêtes asynchrones, voir Exemples de requêtes asynchrones.
Meilleures pratiques pour les requêtes asynchrones¶
Lorsque vous soumettez une requête asynchrone, suivez ces bonnes pratiques :
Assurez-vous de savoir quelles requêtes dépendent d’autres requêtes avant d’exécuter des requêtes en parallèle. Certaines requêtes sont interdépendantes et sensibles à l’ordre, et ne conviennent donc pas à la parallélisation. Par exemple, une instruction INSERT ne doit évidemment pas démarrer avant la fin de l’instruction CREATE TABLE correspondante.
Assurez-vous de ne pas exécuter trop de requêtes par rapport à la mémoire dont vous disposez. L’exécution de plusieurs requêtes en parallèle consomme généralement plus de mémoire, en particulier si plusieurs ensembles de résultats sont stockés en mémoire en même temps.
Lors de l’interrogation, gérez les rares cas où une requête échoue.
Assurez-vous que les instructions de contrôle des transactions (BEGIN, COMMIT et ROLLBACK) ne sont pas exécutées en parallèle avec d’autres instructions.
Sachez que les requêtes asynchrones ne sont pas garanties de renvoyer des résultats ordonnés, même si le SQL possède lui-même une clause ORDER BY. Par conséquent, la fonction
result_scanne garantit pas les résultats ordonnés.
Récupération des ID de requête Snowflake¶
Un ID de requête identifie chaque requête exécutée par Snowflake. Lorsque vous utilisez le connecteur Snowflake pour Python afin d’exécuter une requête, vous pouvez accéder à l’ID de requête grâce à l’attribut sfqid de l’objet Cursor :
# Retrieving a Snowflake Query ID cur = con.cursor() cur.execute("SELECT * FROM testtable") print(cur.sfqid)
Vous pouvez utiliser l’ID de requête pour :
Vérifier le statut de la requête dans l’interface Web.
Dans l’Snowsight, les IDs de requêtes sont affichés dans la page Query History. Voir Surveillance de l’activité des requêtes avec l’historique des requêtes.
Vérifier par programme le statut de la requête (par exemple, pour déterminer si une requête asynchrone a abouti).
Récupérer les résultats d’une requête asynchrone ou d’une requête synchrone précédemment soumise.
Voir Utilisation de l’ID de requête pour récupérer les résultats d’une requête.
Annuler une requête en cours d’exécution.
Vérification du statut d’une requête¶
Pour vérifier le statut d’une requête :
Obtenez l’ID de la requête à partir du champ
sfqidde l’objetCursor.Transmettez l’ID de requête à la méthode
get_query_status()de l’objetConnectionpour renvoyer la constante enumQueryStatusqui représente le statut de la requête.Par défaut,
get_query_status()ne signale pas d’erreur si la requête a abouti à une erreur. Si vous voulez qu’une erreur soit signalée, appelez plutôtget_query_status_throw_if_error().Utilisez la constante enum
QueryStatuspour vérifier le statut de la requête.Pour déterminer si la requête est toujours en cours d’exécution (par exemple, s’il s’agit d’une requête asynchrone), transmettez la constante à la méthode
is_still_running()de l’objetConnection.Pour déterminer si une erreur s’est produite, transmettez la constante à la méthode
is_an_error().
Pour la liste complète des constantes enum, voir
QueryStatus.
L’exemple suivant exécute une requête asynchrone et vérifie le statut de la requête :
import time
...
# Execute a long-running query asynchronously.
cur.execute_async('select count(*) from table(generator(timeLimit => 25))')
...
# Wait for the query to finish running.
query_id = cur.sfqid
while conn.is_still_running(conn.get_query_status(query_id)):
time.sleep(1)
L’exemple suivant signale une erreur si la requête a abouti à une erreur :
from snowflake.connector import ProgrammingError
import time
...
# Wait for the query to finish running and raise an error
# if a problem occurred with the execution of the query.
try:
query_id = cur.sfqid
while conn.is_still_running(conn.get_query_status_throw_if_error(query_id)):
time.sleep(1)
except ProgrammingError as err:
print('Programming Error: {0}'.format(err))
Utilisation de l’ID de requête pour récupérer les résultats d’une requête¶
Note
Si vous avez exécuté une requête synchrone en appelant la méthode execute() sur un objet Cursor vous n’avez pas besoin d’utiliser l’ID de requête pour récupérer les résultats. Vous pouvez simplement récupérer les valeurs à partir des résultats, comme expliqué dans Utilisation de cursor pour récupérer des valeurs.
Si vous souhaitez récupérer les résultats d’une requête asynchrone ou d’une requête synchrone précédemment soumise, suivez ces étapes :
Obtenez l’ID de la requête. Voir Récupération des ID de requête Snowflake.
Appelez la méthode
get_results_from_sfqid()dans l’objetCursorpour récupérer les résultats.Utilisez l’objet
Cursorpour récupérer les valeurs dans les résultats, comme expliqué dans Utilisation de cursor pour récupérer des valeurs.
Notez que si la requête est toujours en cours d’exécution, les méthodes de récupération (fetchone(), fetchmany(), fetchall(), etc.) attendront que la requête soit terminée.
Par exemple :
# Get the results from a query.
cur.get_results_from_sfqid(query_id)
results = cur.fetchall()
print(f'{results[0]}')
Utilisation de cursor pour récupérer des valeurs¶
Récupérez les valeurs d’une table à l’aide de la méthode d’itérateur d’objet curseur.
Par exemple, pour extraire des colonnes nommées « col1 » et « col2 » de la table nommée testtable créée précédemment (dans Création de tables et insertion de données), utilisez un code similaire à celui-ci :
cur = conn.cursor() try: cur.execute("SELECT col1, col2 FROM test_table ORDER BY col1") for (col1, col2) in cur: print('{0}, {1}'.format(col1, col2)) finally: cur.close()
Le connecteur Snowflake pour Python fournit un raccourci utile :
for (col1, col2) in con.cursor().execute("SELECT col1, col2 FROM testtable"): print('{0}, {1}'.format(col1, col2))
Si vous avez besoin d’obtenir un seul résultat (c’est-à-dire une seule ligne), utilisez la méthode fetchone :
col1, col2 = con.cursor().execute("SELECT col1, col2 FROM testtable").fetchone() print('{0}, {1}'.format(col1, col2))
Si vous avez besoin d’obtenir le nombre spécifié de lignes à un moment donné, utilisez la méthode fetchmany avec le nombre de lignes :
cur = con.cursor().execute("SELECT col1, col2 FROM testtable") ret = cur.fetchmany(3) print(ret) while len(ret) > 0: ret = cur.fetchmany(3) print(ret)Note
Utilisez
fetchoneoufetchmanysi le nombre de résultats est trop grand pour la mémoire.
Si vous avez besoin de tous les résultats en même temps :
results = con.cursor().execute("SELECT col1, col2 FROM testtable").fetchall() for rec in results: print('%s, %s' % (rec[0], rec[1]))
Pour définir un délai d’attente pour une requête, exécutez une commande « begin » et incluez un paramètre de délai d’attente dans la requête. Si la requête dépasse la longueur de la valeur du paramètre, une erreur se produit et un retour en arrière se produit.
Dans le code suivant, l’erreur 604 signifie que la requête a été annulée. Le paramètre de délai d’attente démarre Timer() et s’annule si la requête ne se termine pas dans le délai spécifié.
conn.cursor().execute("create or replace table testtbl(a int, b string)") conn.cursor().execute("begin") try: conn.cursor().execute("insert into testtbl(a,b) values(3, 'test3'), (4,'test4')", timeout=10) # long query except ProgrammingError as e: if e.errno == 604: print("timeout") conn.cursor().execute("rollback") else: raise e else: conn.cursor().execute("commit")
Utilisation de DictCursor pour récupérer des valeurs par nom de colonne¶
Si vous voulez récupérer une valeur par nom de colonne, créez un objet cursor de type DictCursor.
Par exemple :
# Querying data by DictCursor from snowflake.connector import DictCursor cur = con.cursor(DictCursor) try: cur.execute("SELECT col1, col2 FROM testtable") for rec in cur: print('{0}, {1}'.format(rec['COL1'], rec['COL2'])) finally: cur.close()
Exemples de requêtes asynchrones¶
Voici un exemple simple d’une requête asynchrone :
from snowflake.connector import ProgrammingError
import time
conn = snowflake.connector.connect( ... )
cur = conn.cursor()
# Submit an asynchronous query for execution.
cur.execute_async('select count(*) from table(generator(timeLimit => 25))')
# Retrieve the results.
cur.get_results_from_sfqid(query_id)
results = cur.fetchall()
print(f'{results[0]}')
L’exemple suivant soumet une requête asynchrone à partir d’une connexion et récupère les résultats à partir d’une autre connexion :
from snowflake.connector import ProgrammingError
import time
conn = snowflake.connector.connect( ... )
cur = conn.cursor()
# Submit an asynchronous query for execution.
cur.execute_async('select count(*) from table(generator(timeLimit => 25))')
# Get the query ID for the asynchronous query.
query_id = cur.sfqid
# Close the cursor and the connection.
cur.close()
conn.close()
# Open a new connection.
new_conn = snowflake.connector.connect( ... )
# Create a new cursor.
new_cur = new_conn.cursor()
# Retrieve the results.
new_cur.get_results_from_sfqid(query_id)
results = new_cur.fetchall()
print(f'{results[0]}')
Annulation d’une requête par ID de requête¶
Annulation d’une requête par ID de requête
cur = cn.cursor() try: cur.execute(r"SELECT SYSTEM$CANCEL_QUERY('queryID')") result = cur.fetchall() print(len(result)) print(result[0]) finally: cur.close()
Remplacez la chaîne « queryID » par l’ID de la requête. Pour obtenir l’ID d’une requête, voir Récupération des ID de requête Snowflake.
Amélioration des performances des requêtes en contournant la conversion des données¶
Pour améliorer les performances des requêtes, utilisez la classe SnowflakeNoConverterToPython du module snowflake.connector.converter_null pour contourner les conversions de données du type de données interne Snowflake vers le type de données Python natif. Exemple :
from snowflake.connector.converter_null import SnowflakeNoConverterToPython con = snowflake.connector.connect( ... converter_class=SnowflakeNoConverterToPython ) for rec in con.cursor().execute("SELECT * FROM large_table"): # rec includes raw Snowflake data
En conséquence, toutes les données sont représentées sous forme de chaîne, de sorte que l’application soit chargée de les convertir en types de données Python natifs. Par exemple, les données TIMESTAMP_NTZ et TIMESTAMP_LTZ sont l’heure d’époque représentée sous forme de chaîne, et les données TIMESTAMP_TZ correspondent à l’heure suivie d’un espace suivi du décalage par rapport à UTC en minutes, représentés sous forme de chaîne.
Aucun impact n’est fait sur les données de liaison ; les données natives Python peuvent toujours être liées aux mises à jour.
Téléchargement des résultats¶
Snowflake Connector pour Python version 3.14.0 a introduit le paramètre de connexion unsafe_file_write qui spécifie comment le connecteur doit définir les autorisations de fichiers lors du téléchargement de fichiers pour une zone de préparation Snowflake avec la commande GET. Ces fichiers appartiennent toujours à l’utilisateur qui exécute le processus Python.
Par défaut, le paramètre unsafe_file_write est False pour fournir une autorisation de fichier 600 plus sûre et plus stricte, ce qui signifie que seul le propriétaire dispose de l’autorisation de lecture et d’écriture sur les fichiers téléchargés. Les autres groupes et utilisateurs n’ont pas d’autorisations pour les fichiers téléchargés avec la commande GET.
Si votre organisation exige des autorisations moins restrictives pour les fichiers, vous pouvez définir le paramètre unsafe_file_write sur True. L’activation de ce paramètre définit les autorisations pour les fichiers téléchargés à partir d’une zone de préparation sur 644, ce qui permet au propriétaire de disposer des privilèges de lecture et d’écriture pour les fichiers, mais autorise les autres utilisateurs à les lire. Ce paramètre peut être nécessaire, par exemple, pour certains outils ETL qui s’exécutent sous un autre utilisateur du système qui doit pouvoir lire et traiter les fichiers téléchargés.
Si vous n’êtes pas sûr de la valeur à utiliser, consultez l’équipe responsable de la politique de sécurité applicable à votre organisation.
Données de liaison¶
Pour spécifier les valeurs à utiliser dans une instruction SQL, vous pouvez inclure des littéraux dans l’instruction ou lier des variables. Lorsque vous liez des variables, vous insérez un ou plusieurs espaces réservés dans le texte de l’instruction SQL, puis vous spécifiez la variable (la valeur à utiliser) pour chaque caractère de remplacement.
L’exemple suivant compare l’utilisation des littéraux et de la liaison :
Littéraux :
con.cursor().execute("INSERT INTO testtable(col1, col2) VALUES(789, 'test string3')")Liaison :
con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES(%s, %s)", ( 789, 'test string3' ))
Note
Il existe une limite supérieure à la taille des données que vous pouvez lier ou que vous pouvez combiner dans un lot. Pour plus de détails, voir Limites de la taille du texte de requête.
Snowflake prend en charge les types de liaisons suivants :
pyformatetformat, qui lient les données sur le client.qmarketnumeric, qui lient les données sur le serveur.
Chacun de ceux-ci est expliqué ci-dessous.
Liaison pyformat ou format¶
La liaison pyformat et la liaison format lient les données de liaison côté client plutôt que côté serveur.
Par défaut, le connecteur Snowflake pour Python prend en charge pyformat et format pour que vous puissiez utiliser %(name)s ou %s comme caractère de remplacement. Par exemple :
Utilisation de
%(name)scomme caractère de remplacement :conn.cursor().execute( "INSERT INTO test_table(col1, col2) " "VALUES(%(col1)s, %(col2)s)", { 'col1': 789, 'col2': 'test string3', })
Utilisation de
%scomme caractère de remplacement :con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES(%s, %s)", ( 789, 'test string3' ))
Avec pyformat et format, vous pouvez également utiliser un objet de liste pour lier des données de l’opérateur IN :
# Binding data for IN operator con.cursor().execute( "SELECT col1, col2 FROM testtable" " WHERE col2 IN (%s)", ( ['test string1', 'test string3'], ))
Le caractère pourcentage (« % ») est à la fois un caractère générique pour SQL LIKE et un caractère de liaison de format pour Python. Si vous utilisez la liaison de format et si votre commande SQL contient le caractère pourcentage, vous devrez peut-être échapper le caractère pourcentage. Par exemple, si votre instruction SQL est :
SELECT col1, col2 FROM test_table WHERE col2 ILIKE '%York' LIMIT 1; -- Find York, New York, etc.
votre code Python devrait ressembler à ceci (notez le signe de pourcentage supplémentaire pour échapper le signe de pourcentage d’origine) :
sql_command = "select col1, col2 from test_table " sql_command += " where col2 like '%%York' limit %(lim)s" parameter_dictionary = {'lim': 1 } cur.execute(sql_command, parameter_dictionary)
Liaison qmark ou numeric¶
La liaison qmark et la liaison numeric lient les données de liaison côté serveur plutôt que côté client :
Pour la liaison
qmarkutilisez un point d’interrogation (?) pour indiquer à quel emplacement dans la chaîne vous voulez insérer la valeur d’une variable.Pour la liaison
numericutilisez le signe deux-points (:) suivi d’un nombre pour indiquer la position de la variable que vous voulez substituer à cette position. Par exemple,:2indique la deuxième variable.Utilisez la liaison numérique pour lier la même valeur plus d’une fois dans la même requête. Par exemple, si vous avez une longue valeur VARCHAR ou BINARY ou semi-structurée que vous souhaitez utiliser plusieurs fois, alors la liaison
numericvous permet d’envoyer la valeur au serveur une fois et de l’utiliser plusieurs fois.
Les sections suivantes expliquent comment utiliser les liaisons qmark et numeric :
Utilisation de liaisons qmark ou numeric¶
Pour utiliser la liaison de style qmark ou numeric, vous pouvez soit exécuter l’une des opérations suivantes, soit définir paramstyle dans le cadre des paramètres de connexion lors de l’appel connect().
snowflake.connector.paramstyle='qmark'snowflake.connector.paramstyle='numeric'
Si vous définissez paramstyle sur qmark ou numeric, vous devez utiliser ? ou :N (où N est remplacé par un nombre) comme caractères de remplacement, respectivement.
Par exemple :
Utilisation de
?comme caractère de remplacement :from snowflake.connector import connect connection_parameters = { 'account': 'xxxxx', 'user': 'xxxx', 'password': 'xxxxxx', "host": "xxxxxx", "port": 443, 'protocol': 'https', 'warehouse': 'xxx', 'database': 'xxx', 'schema': 'xxx', 'paramstyle': 'qmark' # note paramstyle setting here at connection level } con = connect(**connection_parameters) con.cursor().execute( "INSERT INTO testtable2(col1,col2,col3) " "VALUES(?,?,?)", ( 987, 'test string4', ("TIMESTAMP_LTZ", datetime.now()) ) )
Utilisation de
:Ncomme caractère de remplacement :import snowflake.connector snowflake.connector.paramstyle='numeric' con = snowflake.connector.connect(...) con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES(:1, :2)", ( 789, 'test string3' ))
La requête suivante montre comment utiliser la liaison
numericpour réutiliser une variable :con.cursor().execute( "INSERT INTO testtable(complete_video, short_sample_of_video) " "VALUES(:1, SUBSTRING(:1, :2, :3))", ( binary_value_that_stores_video, # variable :1 starting_offset_in_bytes_of_video_clip, # variable :2 length_in_bytes_of_video_clip # variable :3 ))
Utilisation de liaisons qmark ou numeric avec des objets datetime¶
Lorsque vous utilisez la liaison qmark ou numeric pour lier des données à un type de données Snowflake TIMESTAMP, définissez la variable bind sur un tuple qui spécifie le type de données Snowflake timestamp (TIMESTAMP_LTZ ou TIMESTAMP_TZ) et la valeur. Par exemple :
import snowflake.connector snowflake.connector.paramstyle='qmark' con = snowflake.connector.connect(...) con.cursor().execute( "CREATE OR REPLACE TABLE testtable2 (" " col1 int, " " col2 string, " " col3 timestamp_ltz" ")" ) con.cursor().execute( "INSERT INTO testtable2(col1,col2,col3) " "VALUES(?,?,?)", ( 987, 'test string4', ("TIMESTAMP_LTZ", datetime.now()) ) )
Contrairement à la liaison côté client, la liaison côté serveur nécessite le type de données Snowflake pour la colonne. La plupart des types de données Python classiques font déjà l’objet de mappages implicites aux types de données Snowflake (par exemple, int est mappé à FIXED). Cependant, comme les données Python datetime peuvent être liées à l’un des multiples types de données Snowflake (TIMESTAMP_NTZ, TIMESTAMP_LTZ ou TIMESTAMP_TZ) et que le mappage par défaut est TIMESTAMP_NTZ, vous devez spécifier le type de données Snowflake à utiliser.
Utilisation de variables de liaison avec l’opérateur IN¶
qmark et numeric (liaison côté serveur) ne prennent pas en charge l’utilisation de variables de liaison avec l’opérateur IN.
Si vous devez utiliser des variables de liaison avec l’opérateur IN, utilisez la liaison côté client (pyformat ou format).
Liaison de paramètres aux variables pour les insertions par lots¶
Dans le code de votre application, vous pouvez insérer plusieurs lignes dans un seul lot. Pour ce faire, utilisez les paramètres comme valeurs dans une instruction INSERT. Par exemple, l’instruction suivante utilise des caractères de remplacement pour la qmark liaison dans une instruction INSERT :
insert into grocery (item, quantity) values (?, ?)
Ensuite, pour spécifier les données qui doivent être insérées, définissez une variable qui est une séquence de séquences (par exemple, une liste de tuples) :
rows_to_insert = [('milk', 2), ('apple', 3), ('egg', 2)]
Comme le montre l’exemple ci-dessus, chaque élément de la liste est un tuple qui contient les valeurs des colonnes d’une ligne à insérer.
Pour effectuer la liaison, appelez la méthode executemany(), en transmettant la variable comme deuxième argument. Par exemple :
conn = snowflake.connector.connect( ... ) rows_to_insert = [('milk', 2), ('apple', 3), ('egg', 2)] conn.cursor().executemany( "insert into grocery (item, quantity) values (?, ?)", rows_to_insert)
Si vous liez des données sur le serveur (c’est-à-dire en utilisant la liaison qmark ou numeric), le connecteur peut optimiser les performances des insertions par lots grâce à la liaison.
Lorsque vous utilisez cette technique pour insérer un grand nombre de valeurs, le pilote peut améliorer les performances en diffusant les données (sans créer de fichiers sur la machine locale) vers une zone de préparation temporaire pour l’acquisition. Le pilote le fait automatiquement lorsque le nombre de valeurs dépasse un seuil.
En outre, la base de données et le schéma actuels de la session doivent être définis. Si ceux-ci ne sont pas définis, la commande CREATE TEMPORARY STAGE exécutée par le pilote peut échouer avec l’erreur suivante :
CREATE TEMPORARY STAGE SYSTEM$BIND file_format=(type=csv field_optionally_enclosed_by='"')
Cannot perform CREATE STAGE. This session does not have a current schema. Call 'USE SCHEMA', or use a qualified name.
Note
Pour découvrir d’autres moyens de charger des données dans la base de données Snowflake (y compris le chargement en masse à l’aide de la commande COPY), consultez Charger des données dans Snowflake.
Eviter les attaques par injection SQL¶
Évitez la liaison de données à l’aide de la fonction de formatage Python, car vous générez un risque d’injection SQL. Par exemple :
# Binding data (UNSAFE EXAMPLE) con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES(%(col1)d, '%(col2)s')" % { 'col1': 789, 'col2': 'test string3' })# Binding data (UNSAFE EXAMPLE) con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES(%d, '%s')" % ( 789, 'test string3' ))# Binding data (UNSAFE EXAMPLE) con.cursor().execute( "INSERT INTO testtable(col1, col2) " "VALUES({col1}, '{col2}')".format( col1=789, col2='test string3') )
Au lieu de cela, stockez les valeurs dans des variables, puis liez ces variables en utilisant le style de liaison qmark ou numérique.
Récupération de métadonnées de colonne¶
Pour récupérer les métadonnées de chaque colonne dans le jeu de résultats (par exemple, le nom, le type, la précision, l’échelle, etc. de chaque colonne), utilisez l’une des approches suivantes :
Pour accéder aux métadonnées après avoir appelé la méthode
execute()pour exécuter la requête, utilisez l’attributdescriptionde l’objetCursor.Pour accéder aux métadonnées sans avoir à exécuter la requête, appelez la méthode
describe().La méthode
describeest disponible dans le connecteur Snowflake pour Python 2.4.6 et les versions plus récentes.
L’attribut description prend l’une des valeurs suivantes :
Version 2.4.5 et antérieure : une liste de tuples.
Version 2.4.6 et ultérieure : une liste d’objets ResultMetadata. (La méthode
describerenvoie également cette liste).
Chaque tuple et objet ResultMetadata contient les métadonnées d’une colonne (le nom de la colonne, le type de données, etc.). Vous pouvez accéder aux métadonnées par l’index ou, dans 2.4.6 et les versions ultérieures, par l’attribut ResultMetadata.
Les exemples suivants montrent comment accéder aux métadonnées à partir des tuples et des objets ResultMetadata retournés.
Exemple : récupérer les métadonnées du nom de la colonne par index (versions 2.4.5 et ultérieures) :
L’exemple suivant utilise l’attribut description pour récupérer la liste des noms de colonnes après avoir exécuté une requête. L’attribut est une liste de tuples, et l’exemple accède au nom de la colonne à partir de la première valeur de chaque tuple.
cur = conn.cursor() cur.execute("SELECT * FROM test_table") print(','.join([col[0] for col in cur.description]))
Exemple : récupérer les métadonnées du nom de la colonne par attribut (versions 2.4.6 et ultérieures) :
L’exemple suivant utilise l’attribut description pour récupérer la liste des noms de colonnes après avoir exécuté une requête. L’attribut est une liste d’objets ResultMetaData, et l’exemple accède au nom de la colonne à partir de l’attribut name de chaque objet ResultMetadata.
cur = conn.cursor() cur.execute("SELECT * FROM test_table") print(','.join([col.name for col in cur.description]))
Exemple : récupérer les métadonnées du nom de la colonne sans exécuter de requête (versions 2.4.6 et ultérieures) :
L’exemple suivant utilise la méthode describe pour récupérer la liste des noms de colonnes sans exécuter de requête. La méthode describe() renvoie une liste d’objets ResultMetaData, et l’exemple accède au nom de la colonne à partir de l’attribut name de chaque objet ResultMetadata.
cur = conn.cursor() result_metadata_list = cur.describe("SELECT * FROM test_table") print(','.join([col.name for col in result_metadata_list]))
Gestion des erreurs¶
L’application doit traiter correctement les exceptions soulevées par le connecteur Snowflake, et décider de continuer ou d’arrêter l’exécution du code.
# Catching the syntax error cur = con.cursor() try: cur.execute("SELECT * FROM testtable") except snowflake.connector.errors.ProgrammingError as e: # default error message print(e) # customer error message print('Error {0} ({1}): {2} ({3})'.format(e.errno, e.sqlstate, e.msg, e.sfqid)) finally: cur.close()
Utilisation de execute_stream pour exécuter des scripts SQL¶
La fonction execute_stream vous permet d’exécuter un ou plusieurs scripts SQL dans un flux :
from codecs import open with open(sqlfile, 'r', encoding='utf-8') as f: for cur in con.execute_stream(f): for ret in cur: print(ret)
Note
Une configuration supplémentaire peut être requise si sql_stream contient des commentaires. Voir Utilisation de execute_stream pour exécuter des scripts SQL.
Fermeture de la connexion¶
Nous vous recommandons de fermer la connexion en utilisant la méthode close :
connection.close()
Ceci permet de s’assurer que les métriques client collectées sont soumises au serveur et que la session est supprimée. De plus, les blocs try-finally permettent de s’assurer que la connexion est fermée même si une exception est levée au milieu :
# Connecting to Snowflake con = snowflake.connector.connect(...) try: # Running queries con.cursor().execute(...) ... finally: # Closing the connection con.close()
Prudence
De multiples connexions non fermées peuvent épuiser les ressources de votre système et éventuellement provoquer une panne de l’application.
Utilisation du gestionnaire de contexte pour connecter et contrôler les transactions¶
Le connecteur Snowflake pour Python prend en charge un gestionnaire de contexte attribuant et libérant des ressources au besoin. Le gestionnaire de contexte est utile pour valider ou annuler des transactions en fonction du statut de l’instruction lorsque autocommit est désactivé.
# Connecting to Snowflake using the context manager with snowflake.connector.connect( user=USER, password=PASSWORD, account=ACCOUNT, autocommit=False, ) as con: con.cursor().execute("INSERT INTO a VALUES(1, 'test1')") con.cursor().execute("INSERT INTO a VALUES(2, 'test2')") con.cursor().execute("INSERT INTO a VALUES(not numeric value, 'test3')") # fail
Dans l’exemple ci-dessus, lorsque la troisième instruction échoue, le gestionnaire de contexte annule les modifications apportées à la transaction et ferme la connexion. Si toutes les instructions étaient réussies, le gestionnaire de contexte validerait les modifications et fermerait la connexion.
Un code équivalent avec les blocs try et except est le suivant :
# Connecting to Snowflake using try and except blocks con = snowflake.connector.connect( user=USER, password=PASSWORD, account=ACCOUNT, autocommit=False) try: con.cursor().execute("INSERT INTO a VALUES(1, 'test1')") con.cursor().execute("INSERT INTO a VALUES(2, 'test2')") con.cursor().execute("INSERT INTO a VALUES(not numeric value, 'test3')") # fail con.commit() except Exception as e: con.rollback() raise e finally: con.close()
Utilisation du type de données VECTOR¶
La prise en charge du type de données VECTOR a été introduite dans la version 3.6.0 de Snowflake Python Connector. Vous pouvez utiliser le type de données VECTOR avec les fonctions de similarité vectorielle pour mettre en œuvre des applications basées sur la recherche vectorielle ou la génération augmentée de récupération (RAG).
L’exemple de code suivant montre comment utiliser le connecteur Python pour créer des tables avec des colonnes VECTOR et appeler la fonction VECTOR_INNER_PRODUCT :
import snowflake.connector
conn = ... # Set up connection
cur = conn.cursor()
# Create a table and insert some vectors
cur.execute("CREATE OR REPLACE TABLE vectors (a VECTOR(FLOAT, 3), b VECTOR(FLOAT, 3))")
values = [([1.1, 2.2, 3], [1, 1, 1]), ([1, 2.2, 3], [4, 6, 8])]
for row in values:
cur.execute(f"""
INSERT INTO vectors(a, b)
SELECT {row[0]}::VECTOR(FLOAT,3), {row[1]}::VECTOR(FLOAT,3)
""")
# Compute the pairwise inner product between columns a and b
cur.execute("SELECT VECTOR_INNER_PRODUCT(a, b) FROM vectors")
print(cur.fetchall())
[(6.30...,), (41.2...,)]
L’exemple de code suivant montre comment utiliser le connecteur Python pour appeler VECTOR_COSINE_SIMILARITY afin de trouver les vecteurs les plus proches de [1,2,3] :
cur.execute(f"""
SELECT a, VECTOR_COSINE_SIMILARITY(a, {[1,2,3]}::VECTOR(FLOAT, 3))
AS similarity
FROM vectors
ORDER BY similarity DESC
LIMIT 1;
""")
print(cur.fetchall())
[([1.0, 2.2..., 3.0], 0.9990...)]
Note
Les liaisons de variables ne sont pas prises en charge pour les types de données VECTOR.
Connexion¶
Le connecteur Snowflake pour Python utilise le module standard Python logging pour enregistrer le statut à intervalles réguliers afin que l’application puisse suivre son activité en arrière-plan. La façon la plus simple d’activer la journalisation est d’ouvrir logging.basicConfig() au début de l’application.
Par exemple, pour définir le niveau de journalisation sur INFO et stocker les journaux dans un fichier nommé /tmp/snowflake_python_connector.log :
logging.basicConfig( filename=file_name, level=logging.INFO)
Une journalisation plus complète peut être activée en réglant le niveau de journalisation sur DEBUG comme suit :
# Logging including the timestamp, thread and the source code location import logging for logger_name in ['snowflake.connector', 'botocore', 'boto3']: logger = logging.getLogger(logger_name) logger.setLevel(logging.DEBUG) ch = logging.FileHandler('/tmp/python_connector.log') ch.setLevel(logging.DEBUG) ch.setFormatter(logging.Formatter('%(asctime)s - %(threadName)s %(filename)s:%(lineno)d - %(funcName)s() - %(levelname)s - %(message)s')) logger.addHandler(ch)La classe de formateur SecretDetector facultative mais recommandée garantit qu’un certain ensemble d’informations sensibles connues est masqué avant d’être écrit dans les fichiers journaux de Snowflake Python Connector. Pour utiliser SecretDetector, utilisez un code similaire au suivant :
# Logging including the timestamp, thread and the source code location import logging from snowflake.connector.secret_detector import SecretDetector for logger_name in ['snowflake.connector', 'botocore', 'boto3']: logger = logging.getLogger(logger_name) logger.setLevel(logging.DEBUG) ch = logging.FileHandler('/tmp/python_connector.log') ch.setLevel(logging.DEBUG) ch.setFormatter(SecretDetector('%(asctime)s - %(threadName)s %(filename)s:%(lineno)d - %(funcName)s() - %(levelname)s - %(message)s')) logger.addHandler(ch)Note
botocoreetboto3sont disponibles via AWS (Amazon Web Services) SDK pour Python.
Fichier de configuration de journalisation¶
Sinon, vous pouvez facilement spécifier le niveau de journalisation et le répertoire dans lequel enregistrer les fichiers journaux dans le fichier de configuration config.toml. Pour plus d’informations sur ce fichier, voir Connexion à l’aide du fichier connections.toml.
Note
Cette fonction de configuration de la journalisation prend en charge les niveaux de journalisation définis dans le document Python sur la journalisation.
Pour plus d’informations sur les niveaux de journalisation, consultez le tutoriel Python sur la journalisation de base.
Ce fichier de configuration de la journalisation utilise toml pour définir les paramètres de journalisation save_logs, level, et path, comme suit :
[log]
save_logs = true
level = "INFO"
path = "<directory to store logs>"
où :
save_logsdétermine si les journaux doivent être sauvegardés.levelspécifie le niveau de journalisation. S’il n’est pas défini, le pilote utilise par défautINFO.pathidentifie le répertoire dans lequel les fichiers journaux doivent être enregistrés. S’il n’est pas défini, le pilote enregistre les journaux dans le répertoire par défaut$SNOWFLAKE_HOME/logs/.
Note
Si votre fichier config.toml ne contient pas de section [log], les messages de journal ne sont pas enregistrés.
Les messages du journal d’une seule journée sont ajoutés au fichier python-connector.log, qui est ensuite renommé python-connector.log.YYYY-MM-DD.
Exemple de programme¶
L’exemple de code suivant combine plusieurs exemples décrits dans les chapitres précédents en un programme Python fonctionnel : Cet exemple contient deux parties :
Une classe parente (« python_veritas_base ») contient le code de nombreuses opérations courantes, telles que la connexion au serveur.
Une classe enfant (« python_connector_example ») représente les parties personnalisées d’un client particulier, par exemple, l’interrogation d’une table.
Cet exemple de code est importé directement à partir de l’un de nos tests pour garantir qu’il a été exécuté sur une version récente du produit.
Étant donné que cela provient d’un test, il inclut une petite quantité de code pour définir un autre port et un autre protocole utilisés dans certains tests. Les utilisateurs ne doivent pas définir le protocole ou le numéro de port ; au lieu de cela, omettez-les et utilisez les valeurs par défaut.
Il contient également des marqueurs de section (parfois appelés « balises d’extrait ») pour identifier le code qui peut être importé indépendamment dans la documentation. Les marqueurs de section ressemblent généralement à :
# -- (> ---------------------- SECTION=import_connector ---------------------
...
# -- <) ---------------------------- END_SECTION ----------------------------
Ces marqueurs de section ne sont pas requis dans le code utilisateur.
La première partie de l’exemple de code contient les sous-routines courantes pour :
Lisez les arguments de ligne de commande (par exemple, « –warehouse MyWarehouse ») qui contiennent des informations de connexion.
Connectez-vous au serveur.
Créez et utilisez un entrepôt, une base de données et un schéma.
Détruisez le schéma, la base de données et l’entrepôt lorsque vous n’en avez plus besoin.
import logging
import os
import sys
# -- (> ---------------------- SECTION=import_connector ---------------------
import snowflake.connector
# -- <) ---------------------------- END_SECTION ----------------------------
class python_veritas_base:
"""
PURPOSE:
This is the Base/Parent class for programs that use the Snowflake
Connector for Python.
This class is intended primarily for:
* Sample programs, e.g. in the documentation.
* Tests.
"""
def __init__(self, p_log_file_name = None):
"""
PURPOSE:
This does any required initialization steps, which in this class is
basically just turning on logging.
"""
file_name = p_log_file_name
if file_name is None:
file_name = '/tmp/snowflake_python_connector.log'
# -- (> ---------- SECTION=begin_logging -----------------------------
logging.basicConfig(
filename=file_name,
level=logging.INFO)
# -- <) ---------- END_SECTION ---------------------------------------
# -- (> ---------------------------- SECTION=main ------------------------
def main(self, argv):
"""
PURPOSE:
Most tests follow the same basic pattern in this main() method:
* Create a connection.
* Set up, e.g. use (or create and use) the warehouse, database,
and schema.
* Run the queries (or do the other tasks, e.g. load data).
* Clean up. In this test/demo, we drop the warehouse, database,
and schema. In a customer scenario, you'd typically clean up
temporary tables, etc., but wouldn't drop your database.
* Close the connection.
"""
# Read the connection parameters (e.g. user ID) from the command line
# and environment variables, then connect to Snowflake.
connection = self.create_connection(argv)
# Set up anything we need (e.g. a separate schema for the test/demo).
self.set_up(connection)
# Do the "real work", for example, create a table, insert rows, SELECT
# from the table, etc.
self.do_the_real_work(connection)
# Clean up. In this case, we drop the temporary warehouse, database, and
# schema.
self.clean_up(connection)
print("\nClosing connection...")
# -- (> ------------------- SECTION=close_connection -----------------
connection.close()
# -- <) ---------------------------- END_SECTION ---------------------
# -- <) ---------------------------- END_SECTION=main --------------------
def args_to_properties(self, args):
"""
PURPOSE:
Read the command-line arguments and store them in a dictionary.
Command-line arguments should come in pairs, e.g.:
"--user MyUser"
INPUTS:
The command line arguments (sys.argv).
RETURNS:
Returns the dictionary.
DESIRABLE ENHANCEMENTS:
Improve error detection and handling.
"""
connection_parameters = {}
i = 1
while i < len(args) - 1:
property_name = args[i]
# Strip off the leading "--" from the tag, e.g. from "--user".
property_name = property_name[2:]
property_value = args[i + 1]
connection_parameters[property_name] = property_value
i += 2
return connection_parameters
def create_connection(self, argv):
"""
PURPOSE:
This gets account identifier and login information from the
environment variables and command-line parameters, connects to the
server, and returns the connection object.
INPUTS:
argv: This is usually sys.argv, which contains the command-line
parameters. It could be an equivalent substitute if you get
the parameter information from another source.
RETURNS:
A connection.
"""
# Get account identifier and login information from environment variables and command-line parameters.
# For information about account identifiers, see
# https://docs.snowflake.com/en/user-guide/admin-account-identifier.html .
# -- (> ----------------------- SECTION=set_login_info ---------------
# Get the password from an appropriate environment variable, if
# available.
PASSWORD = os.getenv('SNOWSQL_PWD')
# Get the other login info etc. from the command line.
if len(argv) < 11:
msg = "ERROR: Please pass the following command-line parameters:\n"
msg += "--warehouse <warehouse> --database <db> --schema <schema> "
msg += "--user <user> --account <account_identifier> "
print(msg)
sys.exit(-1)
else:
connection_parameters = self.args_to_properties(argv)
USER = connection_parameters["user"]
ACCOUNT = connection_parameters["account"]
WAREHOUSE = connection_parameters["warehouse"]
DATABASE = connection_parameters["database"]
SCHEMA = connection_parameters["schema"]
# Optional: for internal testing only.
try:
PORT = connection_parameters["port"]
except:
PORT = ""
try:
PROTOCOL = connection_parameters["protocol"]
except:
PROTOCOL = ""
# If the password is set by both command line and env var, the
# command-line value takes precedence over (is written over) the
# env var value.
# If the password wasn't set either in the environment var or on
# the command line...
if PASSWORD is None or PASSWORD == '':
print("ERROR: Set password, e.g. with SNOWSQL_PWD environment variable")
sys.exit(-2)
# -- <) ---------------------------- END_SECTION ---------------------
# Optional diagnostic:
#print("USER:", USER)
#print("ACCOUNT:", ACCOUNT)
#print("WAREHOUSE:", WAREHOUSE)
#print("DATABASE:", DATABASE)
#print("SCHEMA:", SCHEMA)
#print("PASSWORD:", PASSWORD)
#print("PROTOCOL:" "'" + PROTOCOL + "'")
#print("PORT:" + "'" + PORT + "'")
print("Connecting...")
# If the PORT is set but the protocol is not, we ignore the PORT (bug!!).
if PROTOCOL is None or PROTOCOL == "" or PORT is None or PORT == "":
# -- (> ------------------- SECTION=connect_to_snowflake ---------
conn = snowflake.connector.connect(
user=USER,
password=PASSWORD,
account=ACCOUNT,
warehouse=WAREHOUSE,
database=DATABASE,
schema=SCHEMA
)
# -- <) ---------------------------- END_SECTION -----------------
else:
conn = snowflake.connector.connect(
user=USER,
password=PASSWORD,
account=ACCOUNT,
warehouse=WAREHOUSE,
database=DATABASE,
schema=SCHEMA,
# Optional: for internal testing only.
protocol=PROTOCOL,
port=PORT
)
return conn
def set_up(self, connection):
"""
PURPOSE:
Set up to run a test. You can override this method with one
appropriate to your test/demo.
"""
# Create a temporary warehouse, database, and schema.
self.create_warehouse_database_and_schema(connection)
def do_the_real_work(self, conn):
"""
PURPOSE:
Your sub-class should override this to include the code required for
your documentation sample or your test case.
This default method does a very simple self-test that shows that the
connection was successful.
"""
# Create a cursor for this connection.
cursor1 = conn.cursor()
# This is an example of an SQL statement we might want to run.
command = "SELECT PI()"
# Run the statement.
cursor1.execute(command)
# Get the results (should be only one):
for row in cursor1:
print(row[0])
# Close this cursor.
cursor1.close()
def clean_up(self, connection):
"""
PURPOSE:
Clean up after a test. You can override this method with one
appropriate to your test/demo.
"""
# Create a temporary warehouse, database, and schema.
self.drop_warehouse_database_and_schema(connection)
def create_warehouse_database_and_schema(self, conn):
"""
PURPOSE:
Create the temporary schema, database, and warehouse that we use
for most tests/demos.
"""
# Create a database, schema, and warehouse if they don't already exist.
print("\nCreating warehouse, database, schema...")
# -- (> ------------- SECTION=create_warehouse_database_schema -------
conn.cursor().execute("CREATE WAREHOUSE IF NOT EXISTS tiny_warehouse_mg")
conn.cursor().execute("CREATE DATABASE IF NOT EXISTS testdb_mg")
conn.cursor().execute("USE DATABASE testdb_mg")
conn.cursor().execute("CREATE SCHEMA IF NOT EXISTS testschema_mg")
# -- <) ---------------------------- END_SECTION ---------------------
# -- (> --------------- SECTION=use_warehouse_database_schema --------
conn.cursor().execute("USE WAREHOUSE tiny_warehouse_mg")
conn.cursor().execute("USE DATABASE testdb_mg")
conn.cursor().execute("USE SCHEMA testdb_mg.testschema_mg")
# -- <) ---------------------------- END_SECTION ---------------------
def drop_warehouse_database_and_schema(self, conn):
"""
PURPOSE:
Drop the temporary schema, database, and warehouse that we create
for most tests/demos.
"""
# -- (> ------------- SECTION=drop_warehouse_database_schema ---------
conn.cursor().execute("DROP SCHEMA IF EXISTS testschema_mg")
conn.cursor().execute("DROP DATABASE IF EXISTS testdb_mg")
conn.cursor().execute("DROP WAREHOUSE IF EXISTS tiny_warehouse_mg")
# -- <) ---------------------------- END_SECTION ---------------------
# ----------------------------------------------------------------------------
if __name__ == '__main__':
pvb = python_veritas_base()
pvb.main(sys.argv)
La deuxième partie de l’exemple de code crée une table, y insère des lignes, etc. :
import sys
# -- (> ---------------------- SECTION=import_connector ---------------------
import snowflake.connector
# -- <) ---------------------------- END_SECTION ----------------------------
# Import the base class that contains methods used in many tests and code
# examples.
from python_veritas_base import python_veritas_base
class python_connector_example (python_veritas_base):
"""
PURPOSE:
This is a simple example program that shows how to use the Snowflake
Python Connector to create and query a table.
"""
def __init__(self):
pass
def do_the_real_work(self, conn):
"""
INPUTS:
conn is a Connection object returned from snowflake.connector.connect().
"""
print("\nCreating table test_table...")
# -- (> ----------------------- SECTION=create_table ---------------------
conn.cursor().execute(
"CREATE OR REPLACE TABLE "
"test_table(col1 integer, col2 string)")
conn.cursor().execute(
"INSERT INTO test_table(col1, col2) VALUES " +
" (123, 'test string1'), " +
" (456, 'test string2')")
# -- <) ---------------------------- END_SECTION -------------------------
print("\nSelecting from test_table...")
# -- (> ----------------------- SECTION=querying_data --------------------
cur = conn.cursor()
try:
cur.execute("SELECT col1, col2 FROM test_table ORDER BY col1")
for (col1, col2) in cur:
print('{0}, {1}'.format(col1, col2))
finally:
cur.close()
# -- <) ---------------------------- END_SECTION -------------------------
# ============================================================================
if __name__ == '__main__':
test_case = python_connector_example()
test_case.main(sys.argv)
Pour exécuter cet exemple, procédez comme suit :
Copiez le premier morceau de code dans un fichier nommé « python_veritas_base.py ».
Copiez le deuxième morceau de code dans un fichier nommé « python_connector_example.py »
Définissez la variable d’environnement SNOWSQL_PWD sur votre mot de passe, par exemple :
export SNOWSQL_PWD='MyPassword'Exécutez le programme à l’aide d’une ligne de commande similaire à la suivante (remplacez les informations d’utilisateur et de compte par vos propres informations d’utilisateur et de compte, bien sûr).
Avertissement
Cela supprime l’entrepôt, la base de données et le schéma à la fin du programme ! N’utilisez pas le nom d’une base de données existante, car vous la perdrez !
python3 python_connector_example.py --warehouse <unique_warehouse_name> --database <new_warehouse_zzz_test> --schema <new_schema_zzz_test> --account myorganization-myaccount --user MyUserName
Voici la sortie :
Connecting...
Creating warehouse, database, schema...
Creating table test_table...
Selecting from test_table...
123, test string1
456, test string2
Closing connection...
Voici un exemple plus long :
Note
Dans le chapitre où vous configurez votre compte et vos informations de connexion, assurez-vous de remplacer les variables au besoin pour les faire correspondre à vos informations de connexion Snowflake (nom, mot de passe, etc.).
Cet exemple utilise la fonction format() pour composer l’instruction. Si votre environnement présente un risque d’attaques par injection SQL, vous pouvez, si vous le souhaitez, lier des valeurs plutôt que d’utiliser format().
#!/usr/bin/env python
#
# Snowflake Connector for Python Sample Program
#
# Logging
import logging
logging.basicConfig(
filename='/tmp/snowflake_python_connector.log',
level=logging.INFO)
import snowflake.connector
# Set ACCOUNT to your account identifier.
# See https://docs.snowflake.com/en/user-guide/gen-conn-config.
ACCOUNT = '<my_organization>-<my_account>'
# Set your login information.
USER = '<login_name>'
PASSWORD = '<password>'
import os
# Only required if you copy data from your S3 bucket
AWS_ACCESS_KEY_ID = os.getenv('AWS_ACCESS_KEY_ID')
AWS_SECRET_ACCESS_KEY = os.getenv('AWS_SECRET_ACCESS_KEY')
# Connecting to Snowflake
con = snowflake.connector.connect(
user=USER,
password=PASSWORD,
account=ACCOUNT,
)
# Creating a database, schema, and warehouse if none exists
con.cursor().execute("CREATE WAREHOUSE IF NOT EXISTS tiny_warehouse")
con.cursor().execute("CREATE DATABASE IF NOT EXISTS testdb")
con.cursor().execute("USE DATABASE testdb")
con.cursor().execute("CREATE SCHEMA IF NOT EXISTS testschema")
# Using the database, schema and warehouse
con.cursor().execute("USE WAREHOUSE tiny_warehouse")
con.cursor().execute("USE SCHEMA testdb.testschema")
# Creating a table and inserting data
con.cursor().execute(
"CREATE OR REPLACE TABLE "
"testtable(col1 integer, col2 string)")
con.cursor().execute(
"INSERT INTO testtable(col1, col2) "
"VALUES(123, 'test string1'),(456, 'test string2')")
# Copying data from internal stage (for testtable table)
con.cursor().execute("PUT file:///tmp/data0/file* @%testtable")
con.cursor().execute("COPY INTO testtable")
# Copying data from external stage (S3 bucket -
# replace <s3_bucket> with the name of your bucket)
con.cursor().execute("""
COPY INTO testtable FROM s3://<s3_bucket>/data/
STORAGE_INTEGRATION = myint
FILE_FORMAT=(field_delimiter=',')
""".format(
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY))
# Querying data
cur = con.cursor()
try:
cur.execute("SELECT col1, col2 FROM testtable")
for (col1, col2) in cur:
print('{0}, {1}'.format(col1, col2))
finally:
cur.close()
# Binding data
con.cursor().execute(
"INSERT INTO testtable(col1, col2) "
"VALUES(%(col1)s, %(col2)s)", {
'col1': 789,
'col2': 'test string3',
})
# Retrieving column names
cur = con.cursor()
cur.execute("SELECT * FROM testtable")
print(','.join([col[0] for col in cur.description]))
# Catching syntax errors
cur = con.cursor()
try:
cur.execute("SELECT * FROM testtable")
except snowflake.connector.errors.ProgrammingError as e:
# default error message
print(e)
# user error message
print('Error {0} ({1}): {2} ({3})'.format(e.errno, e.sqlstate, e.msg, e.sfqid))
finally:
cur.close()
# Retrieving the Snowflake query ID
cur = con.cursor()
cur.execute("SELECT * FROM testtable")
print(cur.sfqid)
# Closing the connection
con.close()