Intégrations vectorielles¶
Une intégration fait référence à la réduction de données à haute dimension, telles qu’un texte non structuré, en une représentation à moins de dimensions, telle qu’un vecteur. Les techniques modernes d’apprentissage profond peuvent créer des intégrations vectorielles, qui sont des représentations numériques structurées, à partir de données non structurées telles que du texte et des images, tout en préservant les notions sémantiques de similarité et de dissimilarité dans la géométrie des vecteurs qu’elles produisent.
L’illustration suivante est un exemple simplifié de l’intégration vectorielle et de la similarité géométrique d’un texte en langue naturelle. Dans la pratique, les réseaux neuronaux produisent des vecteurs d’intégration comportant des centaines, voire des milliers de dimensions, et non deux comme illustré ici, mais le concept est le même. Un texte sémantiquement similaire produit des vecteurs qui « pointent » dans la même direction générale.
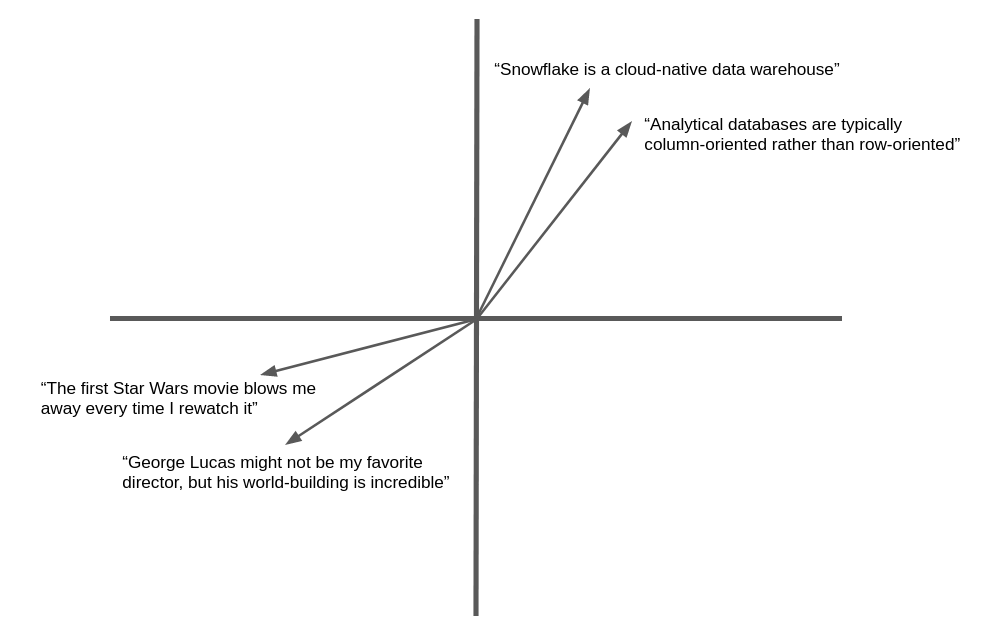
De nombreuses applications peuvent bénéficier de la possibilité de trouver du texte ou des images similaires à une cible. Par exemple, lorsqu’un nouveau ticket d’assistance est enregistré dans un service d’assistance, l’équipe d’assistance peut bénéficier de la possibilité de trouver des cas similaires qui ont déjà été résolus. L’avantage de l’utilisation des vecteurs d’intégration dans cette application est qu’elle va au-delà de la correspondance des mots clés pour s’intéresser à la similarité sémantique, de sorte que des enregistrements apparentés peuvent être trouvés même s’ils ne contiennent pas exactement les mêmes mots.
Snowflake Cortex propose les fonctions EMBED_TEXT_768 et EMBED_TEXT_1024, ainsi que plusieurs Fonctions vectorielles permettant de les comparer pour diverses applications.
Modèles de vectorisation de texte¶
Snowflake propose les modèles de vectorisation de texte suivants. Voir ci-dessous pour plus de détails.
Nom du modèle |
Dimensions de la sortie |
Fenêtre contextuelle |
Prise en charge des langages |
|---|---|---|---|
snowflake-arctic-embed-m-v1.5 |
768 |
512 |
Anglais uniquement |
snowflake-arctic-embed-m |
768 |
512 |
Anglais uniquement |
e5-base-v2 |
768 |
512 |
Anglais uniquement |
snowflake-arctic-embed-l-v2.0 |
1024 |
512 |
Multilingue |
voyage-multilingue-2 |
1024 |
32000 |
Multilingue (langues prises en charge) |
nv-embed-qa-4 |
1024 |
512 |
Anglais uniquement |
Les modèles pris en charge peuvent avoir des coûts différents.
À propos des fonctions de similarité vectorielle¶
La mesure de la similarité entre des vecteurs est une opération fondamentale de la comparaison sémantique. Snowflake Cortex fournit quatre fonctions de similarité vectorielle : VECTOR_INNER_PRODUCT VECTOR_L1_distance, VECTOR_L2_DISTANCE, et VECTOR_COSINE_SIMILARITY. Pour en savoir plus sur ces fonctions, consultez Fonctions vectorielles.
Pour plus de détails sur la syntaxe et l’utilisation, reportez-vous à la page de référence de chaque fonction :
Exemples¶
Les exemples suivants utilisent les fonctions de similarité vectorielle.
Cet exemple SQL utilise la fonction VECTOR_INNER_PRODUCT pour déterminer quels vecteurs de la table sont les plus proches les uns des autres entre les colonnes a et b :
Cet exemple SQL appelle la fonction VECTOR_COSINE_SIMILARITY pour trouver le vecteur le plus proche de [1,2,3] :
Snowflake Python Connector¶
Ces exemples montrent comment utiliser le type de données VECTOR et les fonctions de similarité vectorielle avec le connecteur Python.
Note
La prise en charge du type VECTOR a été introduite dans la version 3.6 du Snowflake Python Connector.
Snowpark Python¶
Ces exemples montrent comment utiliser le type de données VECTOR et les fonctions de similarité vectorielle avec la bibliothèque Snowpark Python.
Note
La prise en charge du type VECTOR a été introduite dans la version 1.11 de Snowpark Python.
La bibliothèque de Snowpark Python ne prend pas en charge la fonction VECTOR_COSINE_SIMILARITY.
Créez des intégrations vectorielles à partir d’un texte¶
Pour créer une représentation vectorielle à partir d’un morceau de texte, vous pouvez utiliser les fonctions EMBED_TEXT_768 (SNOWFLAKE.CORTEX) ou EMBED_TEXT_1024 (SNOWFLAKE.CORTEX), selon les dimensions de sortie du modèle. Cette fonction renvoie l’intégration vectorielle d’un texte anglais donné. Ce vecteur peut être utilisé avec les fonctions de comparaison de vecteurs pour déterminer la similarité sémantique de deux documents.
Astuce
Vous pouvez utiliser d’autres modèles d’intégration via Snowpark Container Services. Pour plus d’informations, voir Embed Text Container Service.
Important
EMBED_TEXT_768 et EMBED_TEXT_1024 sont des fonctions Cortex LLM. Leur utilisation est donc régie par les mêmes contrôles d’accès que les autres fonctions Cortex LLM. Pour savoir comment accéder à ces fonctions, consultez Privilèges requis pour les fonctions Cortex LLM.
Exemples de cas d’utilisation¶
Cette section montre comment utiliser les intégrations, les fonctions de similarité vectorielle et le type de données VECTOR pour mettre en œuvre des cas d’utilisation populaires tels que la recherche de similarité vectorielle et la génération augmentée de récupération (RAG).
Recherche de similitudes vectorielles¶
Pour mettre en œuvre une recherche de documents sémantiquement similaires, il faut d’abord stocker les intégrations des documents à rechercher. Maintenez les intégrations à jour lorsque des documents sont ajoutés ou modifiés.
Dans cet exemple, les documents sont des problèmes soumis au centre d’appel enregistrés par les représentants du service d’assistance. La question est stockée dans une colonne appelée issue_text dans la table issues. Le SQL suivant crée une nouvelle colonne de vecteurs pour contenir les intégrations des questions.
Pour effectuer une recherche, il faut créer une intégration du terme recherché ou du document cible, puis utiliser une fonction de similarité vectorielle pour localiser les documents dont les intégrations sont similaires. Utilisez les clauses ORDER BY et LIMIT pour sélectionner les documents k qui correspondent le mieux et utilisez éventuellement une condition WHERE pour spécifier une similarité minimale.
En règle générale, l’appel à la fonction de similarité vectorielle doit figurer dans la clause SELECT et non dans la clause WHERE. De cette façon, la fonction n’est appelée que pour les lignes spécifiées par la clause WHERE, qui peut restreindre la requête sur la base d’autres critères, au lieu d’opérer sur toutes les lignes de la table. Pour tester une valeur de similarité dans la clause WHERE, définissez un alias de colonne pour l’appel VECTOR_COSINE_SIMILARITY dans la clause SELECT et utilisez cet alias dans une condition de la clause WHERE.
Cet exemple permet de trouver jusqu’à cinq questions correspondant au terme de recherche au cours des 90 derniers jours, en supposant que la similarité en cosinus avec le terme de recherche est d’au moins 0,7.
Génération augmentée de récupération (RAG)¶
Dans la génération augmentée de récupération (RAG), la requête d’un utilisateur est utilisée pour trouver des documents similaires à l’aide du vecteur de similarité. Le document de tête est ensuite transmis à un grand modèle de langage (LLM) avec la requête de l’utilisateur, fournissant le contexte pour la réponse générative (achèvement). Cela peut améliorer considérablement la pertinence de la réponse.
Dans l’exemple suivant, wiki est une table avec une colonne de texte content, et query est une table à une seule ligne avec une colonne de texte text.
Considérations relatives aux clients¶
Les fonctions Snowflake Cortex, dont EMBED_TEXT_768 et EMBED_TEXT_1024LLM, ont un coût de calcul basé sur le nombre de jetons traités.
Note
Un jeton est la plus petite unité de texte traitée par les fonctions Snowflake Cortex LLM, correspondant approximativement à quatre caractères de texte. L’équivalence du texte brut d’entrée ou de sortie en jetons peut varier selon le modèle.
Pour les fonctions EMBED_TEXT_768 et EMBED_TEXT_1024, seuls les jetons d’entrée sont pris en compte dans le total facturable.
Les fonctions de similarité vectorielle n’entraînent pas de coûts liés aux jetons.
Pour plus d’informations sur la facturation des fonctions Cortex LLM, voir Considérations relatives aux coûts des fonctions Cortex LLM. Pour des informations générales sur les coûts de calcul, voir Comprendre le coût du calcul.