Récupération ponctuelle Snowflake Postgres¶
Vue d’ensemble¶
Snowflake Postgres supports creating forks of an instance using point-in-time recovery (PITR). A fork is a new instance that reflects the state of an existing instance at a specific time. A fork is similar to a CLONE operation in Snowflake. However, unlike the CLONE operation, a fork performs a full copy of all of the origin data.
Étant donné qu’un fork est isolé de l’instance d’origine, toutes les modifications que vous apportez au fork (schéma ou données) n’affectent pas l’instance d’origine.
La récupération ponctuelle est utile lorsque vous devez :
Récupérer des modifications accidentelles, telles que des tables supprimées ou des mises à jour de données incorrectes.
Inspecter l’état historique de vos données à des fins de débogage ou d’audit.
Tester les modifications de l’application par rapport à une copie réaliste des données de production sans impacter l’instance d’origine.
Les forks sont créés à partir de la sauvegarde de base la plus récente de l’instance d’origine qui existe avant un moment donné. Les enregistrements du journal d’écriture anticipée (WAL) de l’instance d’origine sont relus jusqu’au point sélectionné dans le temps afin que l’instance dérivée soit transactionnellement cohérente avec l’instance d’origine à ce moment précis.
Ce qui est copié dans le fork¶
Lorsque vous créez un fork, les caractéristiques suivantes sont copiées à partir de l’instance d’origine :
La version Postgres. La version est copiée pour la compatibilité binaire.
The high availability setting (enabled or disabled).
Les identifiants de connexion pour accéder à l’instance.
Vous pouvez personnaliser certaines propriétés pour la nouvelle instance lors de la création, telles que le stockage et la taille de l’instance (plan). La tarification du fork est basée sur la configuration du fork (plan, stockage et haute disponibilité), comme n’importe quelle autre instance.
Création d’un fork¶
Dans le menu de navigation, sélectionnez Postgres.
Sélectionnez l’instance que vous souhaitez dériver.
Sous Manage, sur la page Postgres Instance, sélectionnez l’élément Fork et saisissez les options de configuration.
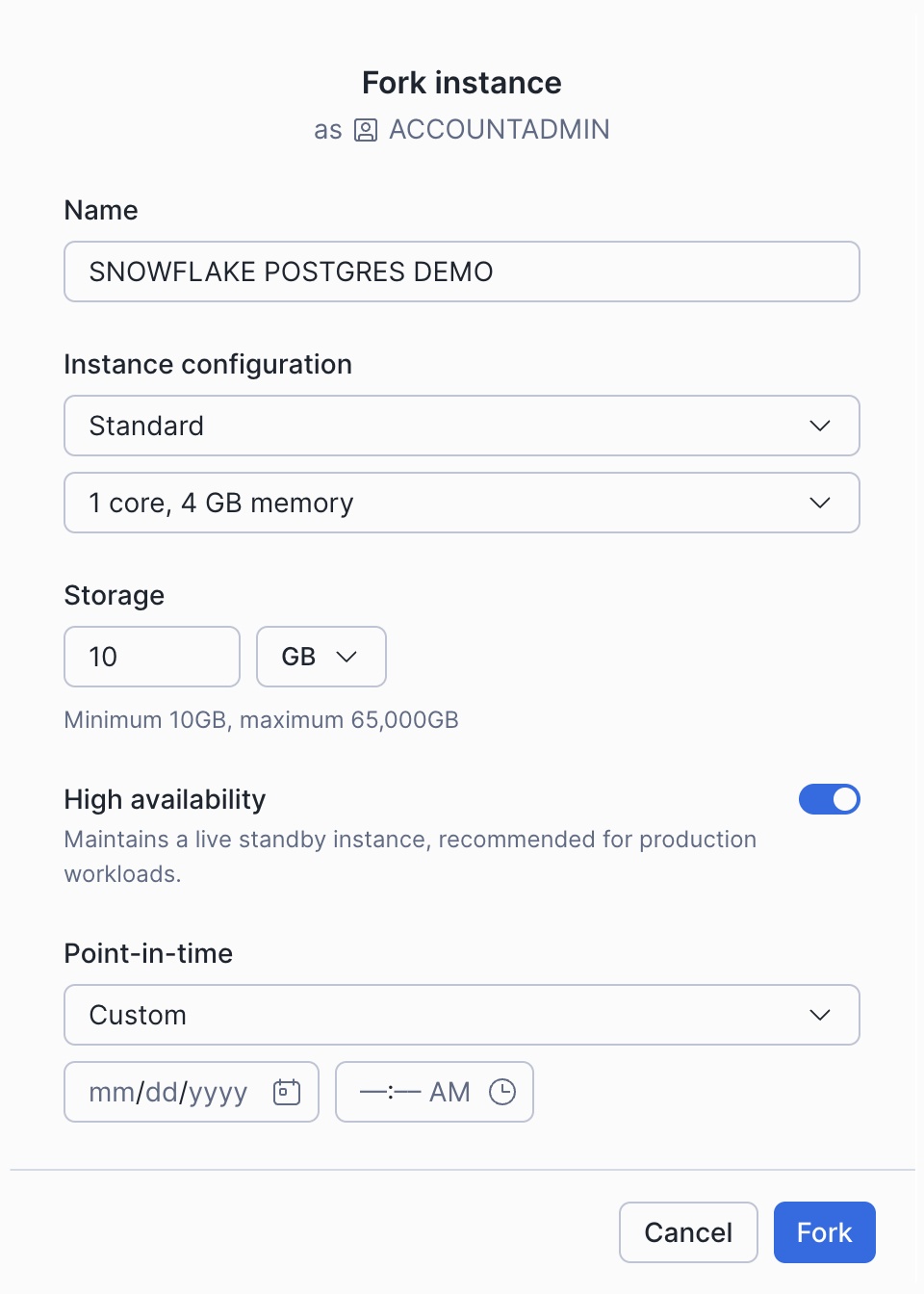
Sélectionnez Fork pour créer le fork.
Pour créer une instance Postgres en tant que fork d’une instance d’origine, exécutez la commande CREATE POSTGRES INSTANCE et spécifiez la clause FORK. La commande crée le fork à partir de l’instance d’origine au point spécifié par la clause AT ou BEFORE. Si vous omettez cette clause, le fork est basé sur l’instance d’origine au point actuel dans le temps.
Pour les paramètres de commande :
FORK orig_nameSpécifie l’origine du fork.
{ AT | BEFORE } ( { TIMESTAMP => timestamp | OFFSET => time_difference } )Specifies the point in time to fork from. The timestamp or offset must fall within the 10 day postgres data retention time.
Par défaut : Utilise l’heure actuelle.
La clause AT | BEFORE accepte l’un des paramètres suivants :
TIMESTAMP => timestampSpécifie une date et une heure exactes à utiliser pour Time Travel. La valeur doit être explicitement convertie en type de données TIMESTAMP, TIMESTAMP_LTZ, TIMESTAMP_NTZ ou TIMESTAMP_TZ.
Si aucune conversion explicite n’est spécifiée, l’horodatage dans la clause AT est traité comme un horodatage avec le fuseau horaire UTC (équivalent à TIMESTAMP_NTZ). Utiliser le type de données TIMESTAMP pour une conversion explicite peut également entraîner le traitement de la valeur comme une valeur TIMESTAMP_NTZ. Pour plus de détails, voir Types de données de date et heure.
OFFSET => time_differenceSpécifie la différence en secondes par rapport au temps actuel à utiliser pour Time Travel, sous la forme
-NoùNpeut être un entier ou une expression arithmétique (par exemple,-120correspond à 120 secondes,-30*60correspond à 1800 secondes ou 30 minutes).
Par défaut : Copié à partir de l’origine.
COMPUTE_FAMILY = compute_familySpécifie le nom d’une taille d’instance à partir des tables Tailles d’instance Snowflake Postgres.
Par défaut : Copié à partir de l’origine.
STORAGE_SIZE_GB = storage_gbSpécifie la taille de stockage en GB. Doit être comprise entre 10 et 65,535.
Par défaut : Copié à partir de l’origine.
HIGH_AVAILABILITY = { TRUE | FALSE }Spécifie le paramètre de haute disponibilité à utiliser pour le fork.
Par défaut : Copié à partir de l’origine.
POSTGRES_SETTINGS = 'json_string'Allows you to optionally set Postgres configuration parameters on your instance in JSON format. See Paramètres du serveur Snowflake Postgres for a list of available Postgres parameters.
Par défaut : Copié à partir de l’origine.
COMMENT = 'string_literal'Spécifie un commentaire pour l’utilisateur.
Par défaut :
NULL
TAG ( tag_name = 'tag_value' [ , tag_name = 'tag_value' , ... ] )Spécifie le nom de la balise et la valeur de la chaîne de la balise.
La valeur de la balise est toujours une chaîne de caractères et le nombre maximum de caractères pour la valeur de la balise est 256.
Pour plus d’informations sur la spécification des balises dans une instruction, voir Quotas de balises.
Une ligne avec les colonnes suivantes sera renvoyée :
statushost
Exemples SQL CREATE FORK
Créer un fork
my_forkà partir de l’instance d’originemy_origin_instanceà l’horodatage2025-01-01 12:00:00.Créer un fork
my_forkà partir de l’instance d’originemy_origin_instancetel qu’elle était il y a120secondes.Create a fork
my_forkfrom the origin instancemy_origin_instanceas of the current time, using theSTANDARD_Minstance size and no high availability.
When you create a fork, no credentials will be displayed. Credentials for the fork are the same as the origin instance. You can regenerate credentials later if needed.
Le temps nécessaire pour créer un fork dépend de la taille de l’instance d’origine.