Snowpipe Streaming¶
Snowpipe Streaming est le service de Snowflake pour le chargement continu et à faible latence de données en flux directement dans Snowflake. Il permet l’ingestion et l’analyse des données en temps quasi réel, ce qui est crucial pour obtenir des informations en temps opportun et des réponses opérationnelles immédiates. De grands volumes de données provenant de diverses sources de flux sont disponibles pour des requêtes et des analyses en quelques secondes.
Valeur ajoutée de Snowpipe Streaming¶
Disponibilité des données en temps réel : ingère les données au fur et à mesure de leur arrivée, contrairement aux méthodes traditionnelles de chargement par lot, ce qui permet d’afficher des tableaux de bord en direct, d’analyser en temps réel et de détecter les fraudes.
Charges de travail de flux efficaces : Utilise les SDKs Snowpipe Streaming pour écrire des lignes directement dans des tables, sans passer par la mise en zone de préparation des données dans un stockage Cloud intermédiaire. Cette approche directe réduit la latence et simplifie l’architecture d’ingestion.
Des pipelines de données simplifiés : propose une approche simplifiée pour les pipelines de données en continu à partir de sources telles que les événements d’application, les capteurs IoT, les flux de capture de données modifiées (CDC) et les files d’attente de messages (par exemple, Apache Kafka).
Sans serveur et évolutif : En tant qu’offre sans serveur, il met automatiquement à l’échelle les ressources de calcul en fonction de la charge d’ingestion.
Rentabilité pour les flux : La facturation est optimisée pour l’ingestion des flux, offrant potentiellement des solutions plus rentables pour les flux de données à haut volume et à faible latence.
Avec Snowpipe Streaming, vous pouvez créer des applications de données en temps réel sur le Snowflake Data Cloud, afin de prendre des décisions basées sur les données les plus fraîches disponibles.
Implémentations Snowpipe Streaming¶
Snowpipe Streaming propose deux implémentations distinctes pour répondre aux divers besoins d’ingestion de données et aux attentes en matière de performances : Snowpipe Streaming avec architecture hautes performances et Snowpipe Streaming avec architecture classique :
Snowpipe Streaming avec architecture hautes performances
Snowflake a mis en œuvre cette implémentation de nouvelle génération afin d’améliorer considérablement le débit, d’optimiser les performances de flux et de fournir un modèle de coût prévisible, ouvrant ainsi la voie à des capacités de flux de données avancées.
Caractéristiques clés :
SDK : Utilise le nouveau SDK snowpipe-streaming.
Tarification : des tarifs transparents, basés sur le débit (crédits par GB non compressé).
Gestion du flux de données : uilise l’objet PIPE pour gérer le flux de données et permettre des transformations légères au moment de l’ingestion. Les canaux sont ouverts sur cet objet PIPE.
Ingestion : offre une API REST pour l’ingestion directe et légère de données à travers le PIPE.
Validation du schéma : effectuée côté serveur lors de l’ingestion par rapport au schéma défini dans le PIPE.
Performance : conçu pour augmenter considérablement le débit et améliorer l’efficacité des requêtes sur les données ingérées.
Nous vous encourageons à explorer cette architecture avancée, en particulier pour les nouveaux projets de flux.
Snowpipe Streaming avec architecture classique
Il s’agit de la mise en œuvre originale, généralement disponible, qui fournit une solution fiable pour les pipelines de données établis.
Caractéristiques clés :
SDK : Utilise le snowflake-ingest-sdk.
Gestion des flux de données : N’utilise pas le concept d’objet PIPE pour l’ingestion des flux. Les canaux sont configurés et ouverts directement sur les tables cibles.
Tarification : basée sur une combinaison de ressources de calcul sans serveur utilisées pour l’ingestion et le nombre de connexions actives des clients.
Choix de votre implémentation¶
Tenez compte de vos besoins immédiats et de votre stratégie de données à long terme lorsque vous choisissez une implémentation :
Nouveaux projets de flux : Nous vous recommandons d’évaluer l’architecture hautes performances de Snowpipe Streaming pour sa conception innovante, ses meilleures performances, son évolutivité et sa prévisibilité des coûts.
Exigences en matière de performances : l’architecture haute performance est conçue pour maximiser le débit et optimiser les performances en temps réel.
Préférence en matière de tarification : l’architecture haute performance propose une tarification claire, basée sur le débit, tandis que l’architecture classique facture en fonction de l’utilisation du calcul sans serveur et des connexions des clients.
Configurations existantes : Les applications existantes utilisant l’architecture classique peuvent continuer à fonctionner. Pour les extensions ou les refontes futures, envisagez de migrer vers ou d’incorporer l’architecture hautes performances.
Définition et gestion des fonctionnalités : l’objet PIPE de l’architecture haute performance introduit des capacités de gestion et de transformation améliorées qui n’existent pas dans l’architecture classique.
Comparaison de Snowpipe Streaming et de Snowpipe¶
Snowpipe Streaming est destiné à compléter Snowpipe, et non à le remplacer. Utilisez l’API de Snowpipe Streaming dans des scénarios de streaming où les données sont transmises en flux avec des lignes (par exemple, des sujets Apache Kafka) au lieu d’être écrites dans des fichiers. Le API s’intègre dans un flux d’ingestion qui comprend une application Java personnalisée existante qui produit ou reçoit des enregistrements. WIth l’API, vous n’avez pas besoin de créer des fichiers pour charger les données dans les tables de Snowflake. L’API permet le chargement automatique et continu des flux de données dans Snowflake au fur et à mesure que les données sont disponibles.
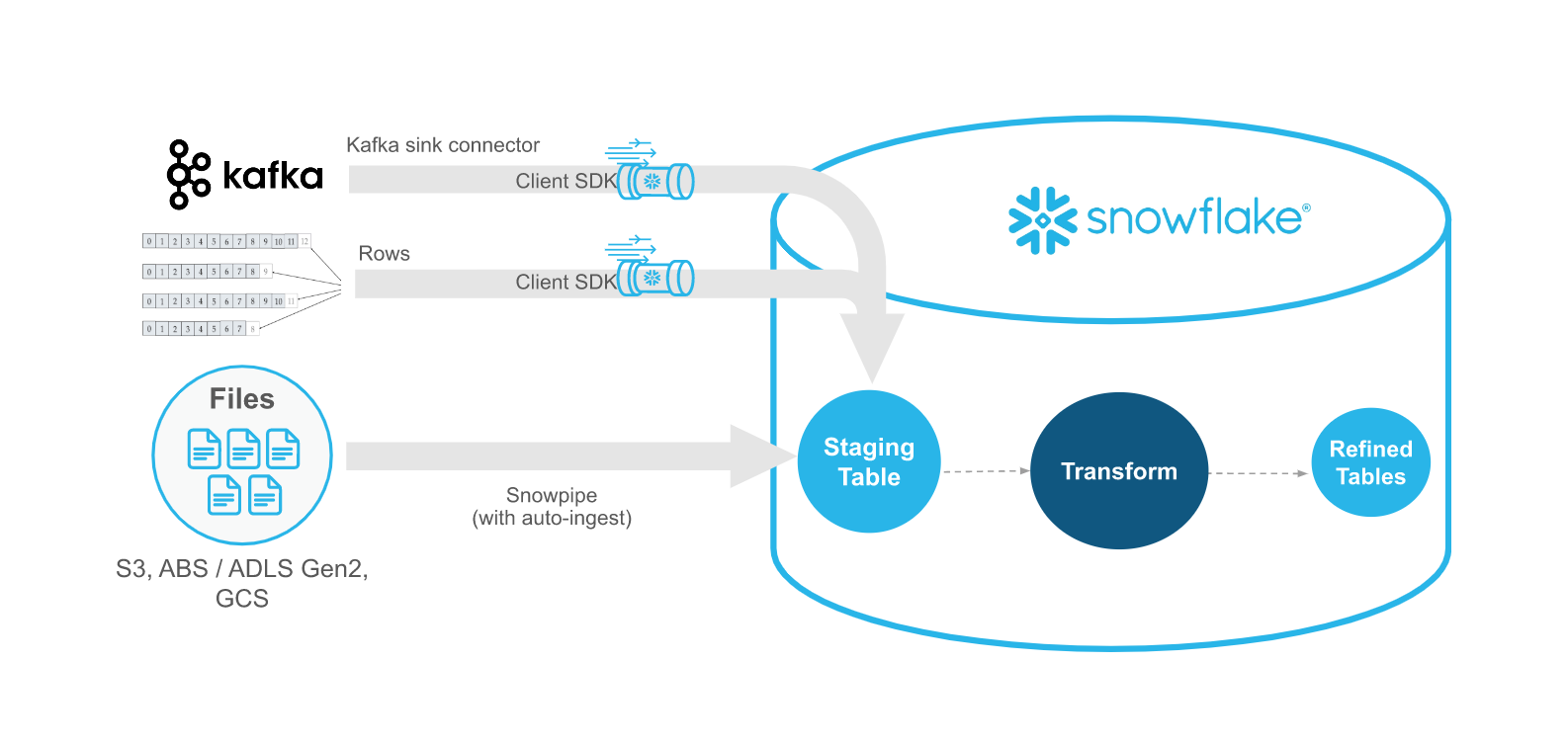
Le tableau suivant décrit les différences entre Snowpipe Streaming et Snowpipe :
Catégorie |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
Forme des données à charger |
Lignes |
Fichiers. Si votre pipeline de données existant génère des fichiers dans un stockage Blob, nous vous recommandons d’utiliser Snowpipe au lieu du API. |
Exigences relatives aux logiciels tiers |
Code d’application Java personnalisé pour le Snowflake Ingest SDK. |
Aucun(e) |
Commande de données |
Insertions ordonnées dans chaque canal. |
Non pris en charge. Snowpipe peut charger des données à partir de fichiers dans un ordre différent des horodatages de création des fichiers dans le stockage cloud. |
Historique de chargement |
Historique de chargement enregistré dans la vue SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY (Account Usage). |
Historique de chargement enregistré dans COPY_HISTORY (Account Usage) et la fonction COPY_HISTORY (Information Schema). |
Objet du canal |
L’architecture classique ne nécessite pas d’objet de type « Canal ». L’API écrit les enregistrements directement dans les tables cibles. L’architecture haute performance exige un objet de type « Canal ». |
Nécessite un objet Canal qui met en file d’attente et charge les données des fichiers en zone de préparation dans les tables cibles. |
Canaux¶
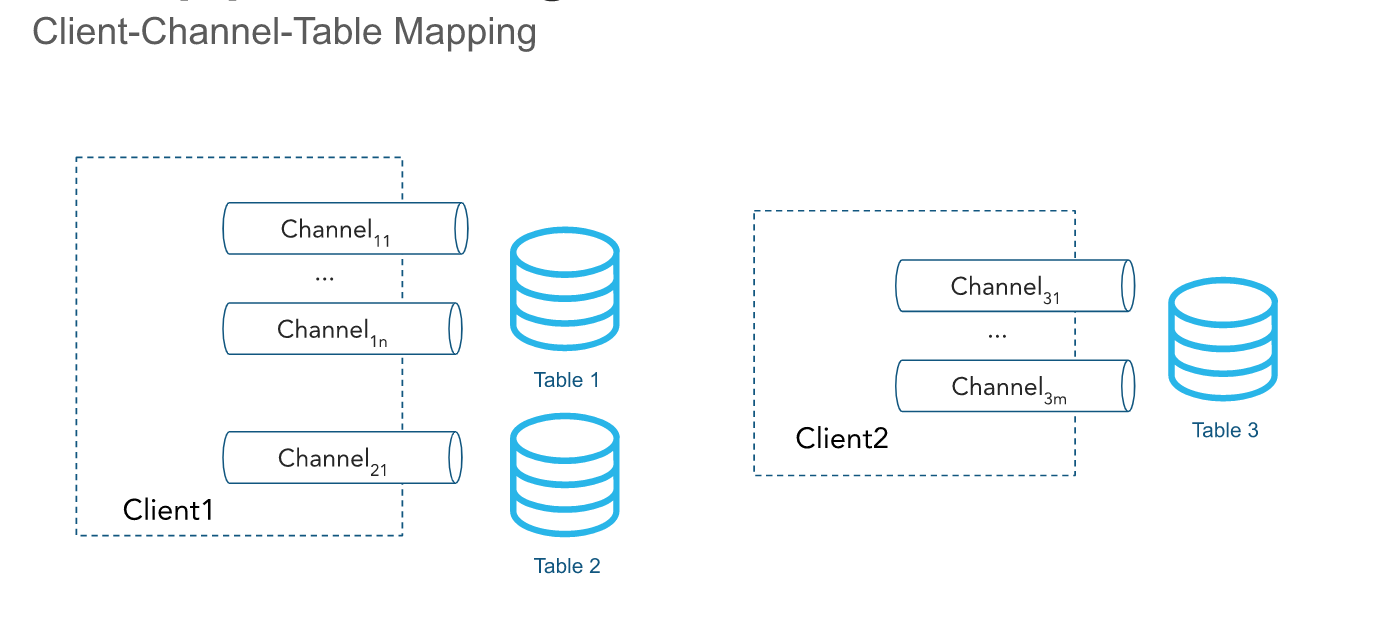
L’API ingère des lignes à travers un ou plusieurs canaux. Un canal représente une connexion de streaming logique et nommée avec Snowflake pour le chargement de données dans une table de manière ordonnée. L’ordre des lignes et les jetons de décalage correspondants sont préservés au sein d’un canal, mais pas entre les canaux qui pointent vers la même table.
Dans l’architecture classique, un seul canal correspond à exactement une seule table dans Snowflake, bien que plusieurs canaux puissent pointer vers la même table. Le client SDK a la possibilité d’ouvrir plusieurs canaux vers plusieurs tables ; cependant, le SDK ne peut pas ouvrir de canaux sur plusieurs comptes. Les canaux sont conçus pour durer longtemps lorsqu’un client insère activement des données, et ils doivent être réutilisés lors des redémarrages du processus client, car les informations de jeton de décalage sont conservées. Les données à l’intérieur du canal sont automatiquement effacées toutes les secondes, par défaut, et le canal n’a pas besoin d’être fermé. Pour plus d’informations, voir Recommandations en matière de latence.
Vous pouvez supprimer définitivement des canaux en utilisant DropChannelRequest l’API lorsque vous n’avez plus besoin du canal et des métadonnées de décalage associées. Il existe deux façons de supprimer un canal :
Suppression d’un canal à la fermeture. Les données à l’intérieur du canal sont automatiquement vidées avant la suppression du canal.
Suppression d’un canal à l’aveugle. Nous le recommandons pas, car la suppression d’un canal à l’aveugle supprime toutes les données en attente.
Vous pouvez lancer la commande SHOW CHANNELS pour obtenir la liste des chaînes pour lesquelles vous disposez de privilèges d’accès. Pour plus d’informations, consultez SHOW CHANNELS.
Note
Les canaux inactifs ainsi que leurs jetons de décalage sont automatiquement supprimés après 30 jours d’inactivité.
Jetons de décalage¶
Un jeton de décalage est une chaîne de caractères qu’un client peut inclure dans ses requêtes de méthode de soumission de ligne (par exemple, pour une ou plusieurs lignes) afin de suivre la progression de l’ingestion sur la base par canal. Les méthodes spécifiques utilisées sont insertRow ou insertRows pour l’architecture classique, et appendRow ou appendRows pour l’architecture haute performance. Le jeton est initialisé à la valeur NULL lors de la création du canal et est mis à jour lorsque les lignes avec un jeton de décalage fourni sont validées dans Snowflake par le biais d’un processus asynchrone. Les clients peuvent périodiquement faire des requêtes en utilisant la méthode getLatestCommittedOffsetToken afin d’obtenir le dernier jeton de décalage engagé pour un canal particulier et l’utiliser pour raisonner sur la progression de l’ingestion. Notez que ce jeton n’est pas utilisé par Snowflake pour effectuer la déduplication ; cependant, les clients peuvent utiliser ce jeton pour effectuer la déduplication en utilisant votre code personnalisé.
Lorsqu’un client rouvre un canal, le dernier jeton de décalage persistant est renvoyé. Le client peut réinitialiser sa position dans la source de données en utilisant le jeton pour éviter d’envoyer deux fois les mêmes données. Notez que lorsqu’un événement de réouverture d’un canal se produit, toutes les données non validées mises en mémoire tampon dans Snowflake sont écartées pour éviter de les engager.
Vous pouvez utiliser le dernier jeton de décalage engagé pour effectuer les opérations suivantes :
Suivre la progression de l’ingestion.
Vérifier si un décalage spécifique a été validé en le comparant au dernier jeton de décalage validé.
Avancer le décalage de la source et purger les données qui ont déjà été engagées.
Permettre la déduplication et assurer la livraison des données « exactly-once ».
Par exemple, le connecteur Kafka pourrait lire un jeton de décalage à partir d’un sujet tel que <partition>:<décalage>, ou simplement <décalage> si la partition est encodée dans le nom du canal. Prenons la requête suivante :
Le connecteur Kafka est en ligne et ouvre un canal correspondant à
Partition 1dans le sujet KafkaTavec le nom de canalT:P1.Le connecteur commence à lire les enregistrements de la partition Kafka.
Le connecteur appelle le API, en faisant une demande de méthode
insertRowsavec le décalage associé à l’enregistrement comme jeton de décalage.Par exemple, le jeton de décalage pourrait être
10, faisant référence au dixième enregistrement de la partition Kafka.Le connecteur effectue périodiquement des
getLatestCommittedOffsetTokendemandes de méthode pour déterminer la progression de l’ingestion.
Si le connecteur Kafka tombe en panne, la procédure suivante peut être complétée pour reprendre la lecture des enregistrements à partir du décalage correct pour la partition Kafka :
Le connecteur Kafka revient en ligne et rouvre le canal en utilisant le même nom que précédemment.
Le connecteur appelle le API, en faisant une demande de méthode
getLatestCommittedOffsetTokenpour obtenir le dernier décalage engagé pour la partition.Par exemple, supposons que le dernier jeton de décalage persistant est
20.Le connecteur utilise la lecture Kafka APIs pour réinitialiser un curseur correspondant au décalage plus 1 (
21dans cet exemple).Le connecteur reprend la lecture des enregistrements. Aucune donnée en double n’est récupérée après le repositionnement réussi du curseur de lecture.
Dans un autre exemple, une application lit les journaux d’un répertoire et utilise le client Snowpipe Streaming SDK pour exporter ces journaux vers Snowflake. Vous pouvez construire une application d’exportation de journaux qui fait ce qui suit :
Lister les fichiers dans le répertoire du journal.
Supposons que le framework de journalisation génère des fichiers journaux qui peuvent être ordonnés lexicographiquement et que les nouveaux fichiers journaux sont placés à la fin de cet ordre.
Lit un fichier journal ligne par ligne et appelle les requêtes de la méthode API, effectuant
insertRowsavec un jeton de décalage correspondant au nom du fichier journal et au nombre de lignes ou à la position des octets.Par exemple, un jeton de décalage pourrait être
messages_1.log:20, oùmessages_1.logest le nom du fichier journal et20est le numéro de ligne.
Si l’application tombe en panne ou doit être redémarrée, elle appelle alors le API, en faisant une demande de méthode getLatestCommittedOffsetToken pour récupérer un jeton de décalage qui correspond à au dernier fichier journal et à la dernière ligne exportés. En continuant avec l’exemple, cela pourrait être messages_1.log:20. L’application ouvrirait alors messages_1.log et chercherait la ligne 21 pour éviter que la même ligne de journal soit ingérée deux fois.
Note
Les informations relatives au jeton de décalage peuvent être perdues. Le jeton de décalage est lié à un objet de canal, et un canal est automatiquement effacé si aucune nouvelle ingestion n’est effectuée en utilisant le canal pendant une période de 30 jours. Pour éviter la perte du jeton de décalage, envisagez de maintenir un décalage séparé et de réinitialiser le jeton de décalage du canal si nécessaire.
Rôles de offsetToken et continuationToken¶
offsetToken et continuationToken sont tous deux utilisés pour garantir une livraison unique des données, mais ils répondent à des usages différents et sont gérés par des sous-systèmes différents. La principale distinction réside dans ce qui contrôle la valeur du jeton et dans la portée de son utilisation.
continuationToken(s’applique uniquement à l’architecture hautes performances et n’est utilisé que par des utilisateurs API REST directs) :Ce jeton est géré par Snowflake et est essentiel pour maintenir l’état d’une session de streaming unique et continue. Lorsqu’un client envoie des données à l’aide de l’API
Append Rows, Snowflake lui renvoie uncontinuationToken. Le client doit renvoyer ce jeton dans sa requête AppendRows suivante pour s’assurer que les données sont reçues par Snowflake dans le bon ordre et sans interruption. Snowflake utilise le jeton pour détecter et empêcher les doublons de données ou les données manquantes en cas de nouvelle tentative d’un SDK.offsetToken(s’applique à la fois aux architectures classiques et hautes performances) :Ce jeton est un identificateur défini par l’utilisateur qui permet une livraison unique à partir d’une source externe. Snowflake n’utilise pas ce jeton pour ses propres opérations internes ou pour empêcher la réingestion. Au lieu de cela, Snowflake stocke simplement cette valeur. Il est de la responsabilité du système externe (comme un connecteur Kafka) de lire le jeton de décalage de Snowflake et de l’utiliser pour suivre sa propre progression d’ingestion et éviter d’envoyer des doublons de données si le flux externe doit être rejoué.
Opérations à insertion uniquement¶
L” API est actuellement limité à l’insertion de lignes. Pour modifier, supprimer ou combiner des données, écrivez les enregistrements « bruts « dans une ou plusieurs tables mises en zone de préparation. Fusionnez, joignez ou transformez les données en utilisant des pipelines de données continus pour insérer les données modifiées dans les tableaux de reporting de destination.
Types de données Java pris en charge¶
Le tableau suivant résume les types de données Java pris en charge pour l’ingestion dans les colonnes Snowflake :
Type de colonne Snowflake |
Type de données Java autorisées |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Privilèges d’accès requis¶
L’appel de l’API de Snowpipe Streaming nécessite un rôle avec les privilèges suivants :
Objet |
Privilège |
|---|---|
Table |
OWNERSHIP ou au minimum INSERT et EVOLVE SCHEMA (uniquement requis lors de l’utilisation de l’évolution des schémas pour le connecteur Kafka avec Snowpipe Streaming) |
Base de données |
USAGE |
Schéma |
USAGE |
Canal |
OPERATE (nécessaire uniquement pour l’architecture hautes performances) |