Snowpipe Streaming¶
Snowpipe Streamingは、ストリーミングデータを継続的かつ低レイテンシーでSnowflakeに直接読み込むためのSnowflakeのサービスです。ほぼリアルタイムのデータ取り込みと分析が可能になり、タイムリーな洞察と迅速な業務対応が可能になります。多様なストリームソースからの大量のデータを、数秒以内にクエリや分析に利用できるようにします。
Snowpipe Streamingの値¶
リアルタイムのデータ可用性: 従来のバッチ読み込み中とは異なり、データが到着した時点で取り込み、ライブダッシュボード、リアルタイムアナリティクス、不正検出などのユースケースをサポートします。
効率的なストリーミングワークロード:Snowpipe Streaming SDKs を利用して、中間のクラウドストレージにデータをステージングする必要なく、行をテーブルに直接書き込みます。この直接アプローチは、レイテンシを低減し、インジェスションアーキテクチャを簡素化します。
データパイプラインの簡素化:アプリケーションイベント、 IoT センサー、Change Data Capture (CDC) ストリーム、メッセージキュー (Apache Kafka など) などのソースからの継続的なデータパイプラインのための合理化されたアプローチを提供します。
サーバーレスでスケーラブル:サーバーレスサービスとして、インジェスションの負荷に基づいてコンピューティングリソースを自動的にスケーリングします。
ストリーミングの費用対効果が高い:請求はストリーミングインジェスション用に最適化されており、大量で低レイテンシのデータフィードにより費用対効果の高いソリューションを提供する可能性があります。
Snowpipe Streamingを使用すると、Snowflake Data Cloud上でリアルタイムのデータアプリケーションを構築できるため、可用性の高いデータに基づいて意思決定を行うことができます。
Snowpipe Streamingの実装¶
Snowpipe Streamingは、多様なデータインジェスションのニーズとパフォーマンスの期待に対応するために、2つの異なる実装を提供します。高性能アーキテクチャを使用したSnowpipe Streamingと、従来のアーキテクチャを使用したSnowpipe Streaming:
高性能アーキテクチャを使用した Snowpipe Streaming
Snowflakeは、スループットを大幅に向上させ、ストリーミングパフォーマンスを最適化し、予測可能なコストモデルを提供するために、この次世代実装を設計し、高度なデータストリーミング機能のステージを設定しました。
キーの特徴:
SDK:新しい `Snowpipe Streaming SDK<https://repo1.maven.org/maven2/com/snowflake/snowpipe-streaming/>`_ を利用します。
価格設定: 透明性のあるスループットベースの価格設定 (非圧縮 GB) あたりのクレジットが特徴です。
データフロー管理: PIPE オブジェクトを使用してデータフローを管理し、インジェスト時に軽量の変換を可能にします。チャンネルはこの PIPE オブジェクトに対して開かれます。
取り込み: PIPE を介した直接的で軽量なデータ取り込みのための REST API を提供します。
スキーマ検証: PIPE で定義されたスキーマに対して、インジェスト時にサーバー側で行われるパフォーマンス。
パフォーマンスインジェストされたデータのスループットを大幅に向上させ、クエリ効率を改善するように設計されています。
特に新しいストリーミング・プロジェクトでは、この先進的なアーキテクチャをぜひお試しください。
従来のアーキテクチャを使用したSnowpipe Streaming
これは一般的に利用可能なオリジナルの実装で、確立されたデータパイプラインに信頼性の高いソリューションを提供します。
キーの特徴:
SDK:`Snowflake-ingest-sdk <https://mvnrepository.com/artifact/net.snowflake/snowflake-ingest-sdk>`_を利用します。
データフロー管理:ストリーミングインジェスションの PIPE オブジェクト概念は使用しません。チャネルは構成され、ターゲットテーブルに対して直接開きます。
価格: インジェストに使用されるサーバーレスコンピュートリソースとアクティブクライアント接続数の組み合わせに基づきます。
実装の選択¶
実装を選択する際には、差し迫ったニーズと長期的なデータ戦略を考慮してください。
新しいストリーミングプロジェクト:Snowpipe Streaming高性能アーキテクチャについて、その将来を考慮した設計、より優れたパフォーマンス、スケーラビリティ、コスト予測可能性を評価することをお勧めします。
パフォーマンス要件高性能アーキテクチャは、スループットを最大化し、リアルタイムパフォーマンスを最適化するように構築されています。
価格設定の好み: ハイパフォーマンスアーキテクチャはスループットベースの明確な価格設定を提供し、クラシックアーキテクチャはサーバーレスのコンピュート使用量とクライアント接続に基づいて請求します。
既存の設定:従来のアーキテクチャを使用する既存のアプリケーションは、引き続き動作できます。将来の拡張または再設計のために、高性能アーキテクチャへの移行または組み込みを検討してください。
機能セットと管理:ハイパフォーマンスアーキテクチャの PIPE オブジェクトは、クラシックアーキテクチャにはない強化された管理機能と変換機能を導入しています。
Snowpipe Streaming 対 Snowpipe¶
SnowpipeストリームはSnowpipeを補完するものであり、Snowpipeの代わりではありません。Snowpipe Streaming API は、データをファイルに書き込むのではなく、行(Apache Kafkaトピックなど)でストリームするストリーミングシナリオで使用します。API は、記録を生成または受信する既存のカスタムJavaアプリケーションを含むインジェストワークフローに適合します。WIth API では、Snowflakeのテーブルにデータをロードするためのファイルを作成する必要はありません。API は、データが利用可能になると、Snowflakeにデータのストリームを自動的に継続的に読み込みます。
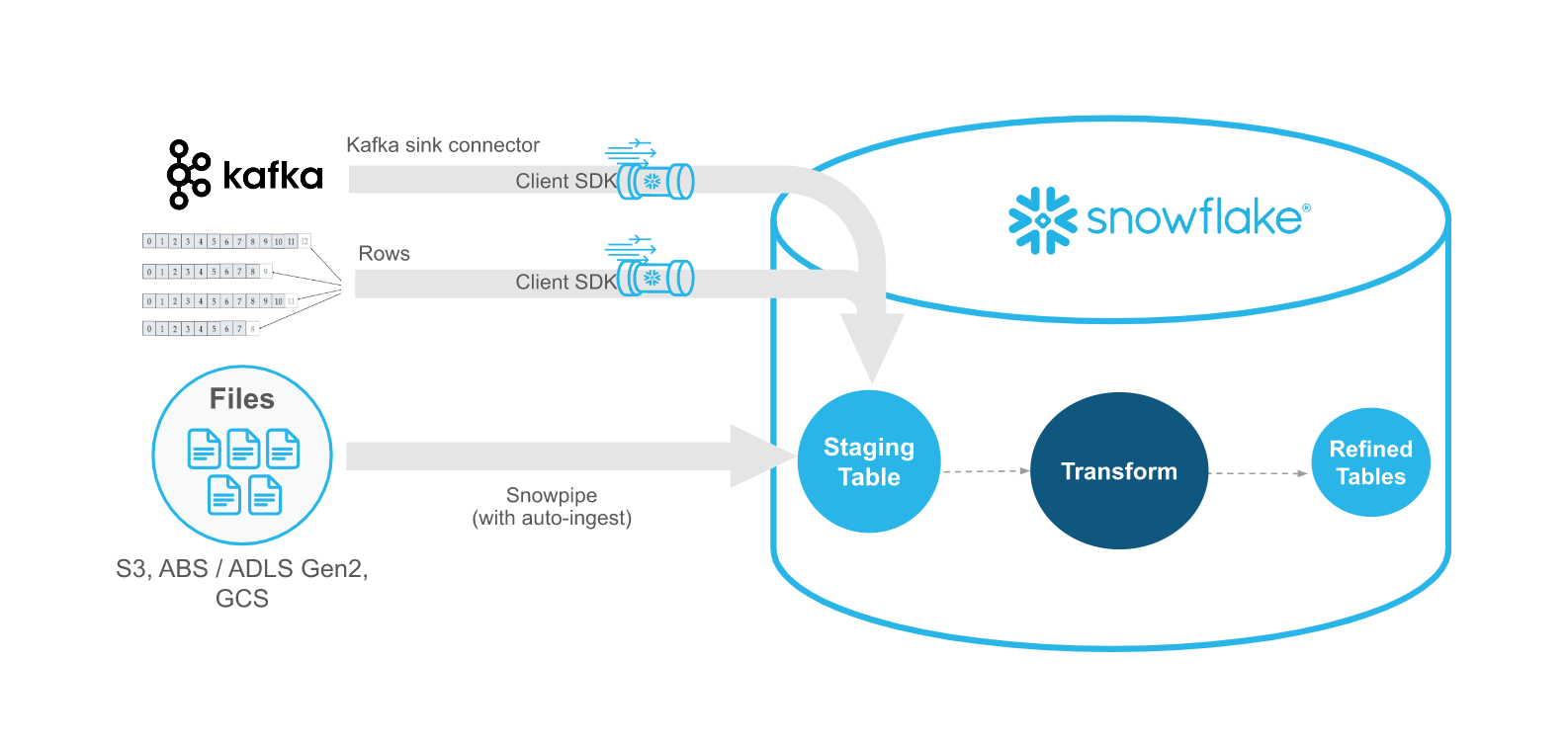
次のテーブルでは、Snowpipe StreamingとSnowpipeの違いについて説明します。
カテゴリ |
Snowpipe Streaming |
Snowpipe |
|---|---|---|
ロードするデータの形式 |
行 |
ファイル。既存のデータパイプラインがBLOBストレージにファイルを生成する場合は、 API の代わりにSnowpipeを使用することをお勧めします。 |
サードパーティのソフトウェア要件 |
Snowflake Ingest SDK 用のカスタムJavaアプリケーションのコードラッパー。 |
なし |
データの順序 |
各チャネル内の順序付き挿入 |
サポート対象外です。Snowpipeは、クラウドストレージのファイル作成タイムスタンプとは異なる順序でファイルからデータをロードできます。 |
ロード履歴 |
SNOWPIPE_STREAMING_FILE_MIGRATION_HISTORY ビュー (Account Usage) に記録されたロード履歴。 |
COPY_HISTORY (Account Usage) および COPY_HISTORY 関数 (Information Schema) に記録されたロード履歴。 |
パイプオブジェクト |
古典的なアーキテクチャではパイプオブジェクトは必要ありません。API はターゲットテーブルに直接記録を書き込みます。ハイパフォーマンスアーキテクチャにはパイプオブジェクトが必要です。 |
ステージングされたファイルデータをキューに入れ、ターゲットテーブルにロードするパイプオブジェクトが必要です。 |
チャネル¶
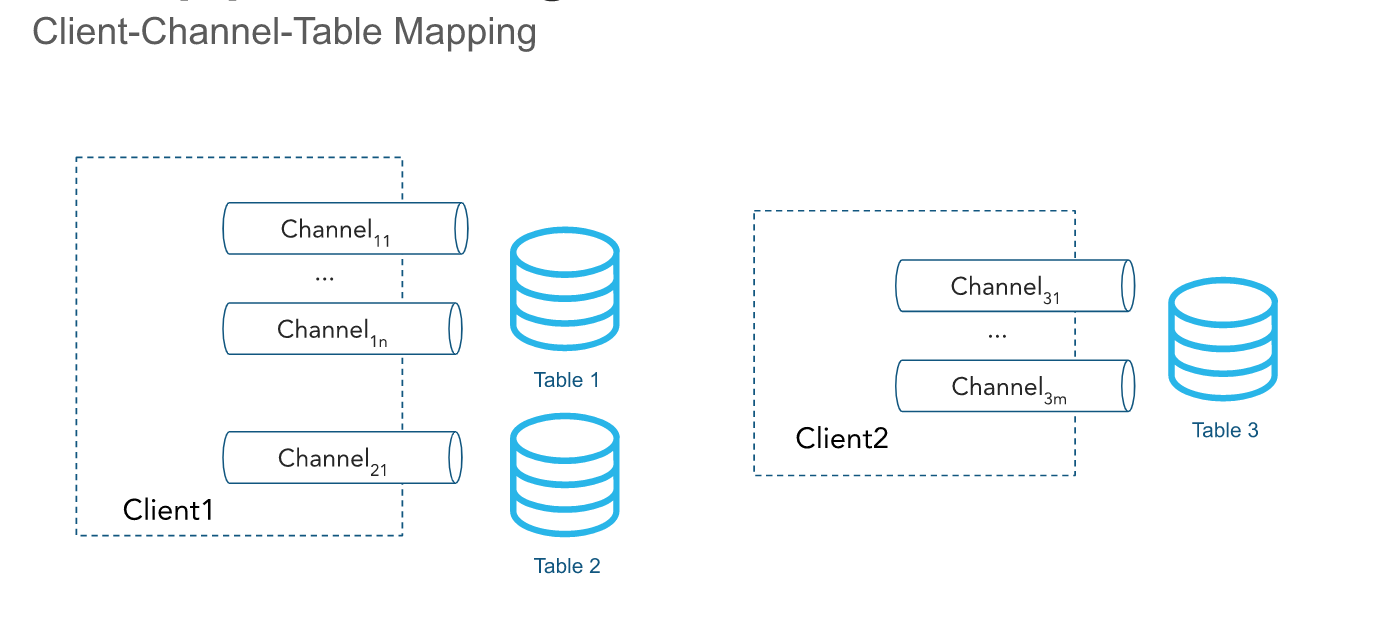
API は、1つ以上のチャネルを介して行をインジェストします。チャネルは、秩序ある方法でデータをテーブルにロードするための、Snowflakeとの論理的な名前付きストリーミング接続を表します。行の順序とそれに対応するオフセットトークンはチャネル内で保持されますが、同じテーブルをポイントするチャネル間では保持されません。
従来のアーキテクチャでは、単一のチャネルはSnowflakeの1つのテーブルに正確にマッピングされます。ただし、複数のチャネルが同じテーブルをポイントすることはできます。クライアント SDK は複数のチャネルを複数のテーブルに開くことができますが、 SDK はアカウント間でチャネルを開くことはできません。チャネルは、クライアントが活発にデータを挿入していると長い間維持され、オフセットトークン情報が保持されるため、クライアントプロセスの再起動に再利用されるべきです。チャネル内のデータはデフォルトで1秒ごとに自動的にフラッシュされます。チャネルを閉じる必要はありません。詳細については、 レイテンシの推奨事項 をご参照ください。
チャンネルと関連するオフセットメタデータが不要に なった場合、 DropChannelRequest API を使用して、 チャンネルを永久的に削除することができます。チャネルを削除するには2つの方法があります:
クロージングでチャネルを削除する。チャネル内のデータは、チャネルが削除される前に自動的にフラッシュされます。
やみくもにチャネルを削除する。やみくもにチャネルをドロップすると、保留中のデータがすべて破棄されるため、これは推奨しません。
SHOW CHANNELS コマンドを実行すると、アクセス権限のあるチャンネルをリストできます。詳細については、 SHOW CHANNELS をご参照ください。
注釈
非アクティブなチャネルとそのオフセットトークンは、30日を過ぎると自動的に削除されます。
オフセットトークン¶
オフセットトークン は、クライアントが行サブミッションメソッドリクエストに含めることができる文字列です(例えば、単一または複数の行の場合)。これにより、チャネル単位で取り込みの進捗を追跡することができます。具体的には、クラシック・アーキテクチャでは insertRow または insertRows、ハイパフォーマンス・アーキテクチャでは appendRow または appendRows が使用されます。トークンはチャネルの作成時に NULL に初期化され、提供されたオフセットトークンを持つ行が非同期プロセスを通じてSnowflakeにコミットされるときに更新されます。クライアントは、定期的に getLatestCommittedOffsetToken メソッドリクエストを行い、特定のチャネルの最新のコミット オフセット トークンを取得し、それを使用してインジェストの進捗状況を推論することができます。このトークンは、Snowflake が重複排除を実行するために使用するものでは ありません。ただし、クライアントはカスタムコードを使用して重複排除を実行するためにこのトークンを使用することができます。
クライアントがチャネルを再度開くと、最新の永続化されたオフセットトークンが返されます。クライアントは、トークンを使用してデータソース内の位置をリセットし、同じデータを2回送信することを回避できます。チャネルの再開イベントが発生すると、Snowflakeにバッファーされたコミットされていないデータは、コミットを回避するために破棄されることに注意してください。
最新のコミットされたオフセットトークンを使用して、次の一般的な使用例を実行できます。
インジェスチョンの進行状況の追跡
特定のオフセットがコミットされているかどうかを、最後にコミットされたオフセットトークンと比較することによって確認します。
ソースオフセットの提出と、すでにコミットされたデータのパージ
重複排除の有効化と、データを1回だけ配信することの保証
たとえば、Kafkaコネクタはトピックから <パーティション>:<オフセット> などのオフセットトークンを読み取ることができます。または、パーティションがチャネル名にエンコードされている場合は、単に <オフセット> を読み取ることができます。次のシナリオを検討してください。
Kafkaコネクタがオンラインになり、Kafkaトピック
TのPartition 1に対応するチャネルがT:P1というチャネル名で開きます。コネクタは、Kafkaパーティションからの記録の読み取りを開始します。
コネクタは API を呼び出し、記録に関連付けられたオフセットをオフセットトークンとして使用して
insertRowsメソッドリクエストを作成します。たとえば、オフセットトークンは
10で、Kafkaパーティションの10番目の記録を参照します。コネクタは定期的に
getLatestCommittedOffsetTokenメソッドリクエストを実行し、インジェストの進行状況を判断します。
Kafkaコネクタがクラッシュした場合は、次のプロシージャを完了して、Kafkaパーティションの正しいオフセットから記録の読み取りを再開できます。
Kafkaコネクタがオンラインに戻り、以前と同じ名前を使用してチャネルを再度開きます。
コネクタは API を呼び出し、
getLatestCommittedOffsetTokenメソッドリクエストを作成して、パーティションの最新のコミット済みオフセットを取得します。たとえば、最新の永続オフセットトークンが
20であるとします。コネクタは、Kafka読み取り APIs を使用して、オフセット+1 (この例では
21)に対応するカーソルをリセットします。コネクタは記録の読み取りを再開します。読み取りカーソルが正常に再配置されると、重複するデータは取得されません。
別の例では、アプリケーションはディレクトリからログを読み込み、Snowpipe Streaming Client SDK を使用してこれらのログをSnowflakeにエクスポートします。次を実行するログエクスポートアプリケーションをビルドできます。
ログディレクトリ内のファイルをリストする。
ログフレームワークが生成するログファイルは辞書順に並べることができ、新しいログファイルはこの順序の最後に配置されるとします。
ログファイルを1行ずつ読み取り、 API を呼び出して、ログファイル名と行数またはバイト位置に対応するオフセットトークンを使用して
insertRowsメソッドリクエストを作成する。たとえば、オフセットトークンは
messages_1.log:20のようになります。ここで、messages_1.logはログファイルの名前で、20は行番号です。
アプリケーションがクラッシュしたり、再起動が必要になったりすると、 API が呼び出され、最後にエクスポートされたログファイルと行に該当するオフセットトークンを取得する getLatestCommittedOffsetToken メソッドリクエストが作成されます。例を続けると、これは messages_1.log:20 になります。その後、アプリケーションは messages_1.log を開き、行 21 を検索して、同じログ行が2回インジェストされないようにします。
注釈
オフセットトークンの情報が失われる可能性があります。オフセットトークンはチャネルオブジェクトにリンクされており、チャネルを使用して新しいインジェスチョンが30日間実行されない場合、チャネルは自動的にクリアされます。オフセットトークンの損失を防ぐために、別のオフセットを維持し、必要に応じてチャネルのオフセットトークンをリセットすることを検討してください。
offsetToken および continuationToken のロール¶
offsetToken および continuationToken の両方とも1回だけのデータ配信を保証するために使用されますが、これらは異なる目的を果たし、異なるサブシステムによって管理されます。主な違いは、誰がトークンの値とその使用範囲を管理するかです。
:code:`continuationToken`(高性能アーキテクチャにのみ適用され、直接 RESTAPI ユーザーによってのみ使用されます):
このトークンはSnowflakeによって管理され、単一の継続的なストリーミングセッションの状態を維持するために不可欠です。クライアントが
Append RowsAPI を使用してデータを送信する場合、SnowflakeはcontinuationTokenを返します。クライアントは次の AppendRows リクエストでこのトークンを戻し、データが正しい順序でギャップなくSnowflakeに受信されるようにする必要があります。Snowflakeはトークンを使用して、SDK 再試行が発生した場合に重複データまたは不足データを検出し、防ぎます。:code:`offsetToken`(従来のアーキテクチャと高性能アーキテクチャの両方に適用):
このトークンは、外部ソースからの1回限りの配信を可能にするユーザー定義の識別子です。Snowflakeは、このトークンを独自の内部操作や再取り込みの防止に使用することはありません。代わりに、Snowflakeはこの値を単純に保存します。SnowflakeからOffsetTokenを読み取り、それを使用して自身の取り込みの進捗を追跡し、外部ストリームのリプレイが必要な場合に重複データの送信を回避するのは、外部システム(Kafkaコネクタなど)の責任です。
挿入のみの操作¶
API は現在、行の挿入に限られています。データを変更、削除、または結合するには、「生」記録を1つ以上のステージングされたテーブルに書き込みます。継続的なデータパイプライン を使用してデータをマージ、結合、または変換し、変更されたデータを宛先のレポートテーブルに挿入します。
サポートされているJavaデータ型¶
次のテーブルは、Snowflake列へのインジェスチョンでサポートされているJavaデータ型をまとめたものです。
Snowflake列型 |
許可されたJavaデータ型 |
|---|---|
|
|
|
|
|
|
|
|
|
ブール変換の詳細 をご参照ください。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
必要なアクセス権限¶
Snowpipe Streaming API を呼び出すには、次の権限を持つロールが必要です。
オブジェクト |
権限 |
|---|---|
テーブル |
OWNERSHIP または INSERT と EVOLVE SCHEMA の最小 (Snowpipe StreamingでKafkaコネクタのスキーマ進化を使用する場合にのみ必要) |
データベース |
USAGE |
スキーマ |
USAGE |
パイプ |
OPERATE(高性能アーキテクチャにのみ必要) |