L’objet PIPE¶
L’objet PIPE est la couche de traitement côté serveur pour Snowpipe Streaming. Chaque ingestion de flux passe par un canal, qui gère la validation du schéma, les transformations de données en cours facultatives et le pré-clustering facultatif avant la validation des données dans la table cible.
L’objet PIPE fournit les capacités suivantes :
Transformations en cours : Filtrez les lignes, réorganisez les colonnes, convertissez les types et appliquez les expressions lors de l’ingestion à l’aide de la syntaxe de transformation de commande COPY. Cela permet de nettoyer et de façonner les données au moment de l’ingestion, sans étape ETL obligatoire.
Pré-clustering : Triez les données lors de l’ingestion en fonction des clés de clustering de table pour optimiser les performances des requêtes.
Validation des schémas côté serveur : Validez les données entrantes par rapport au schéma défini dans le canal avant la validation.
Prise en charge des fonctionnalités de table : Effectuez l’ingestion dans des tables avec des clés de clustering définies, des colonnes de valeurs DEFAULT et des colonnes AUTOINCREMENT (ou IDENTITY).
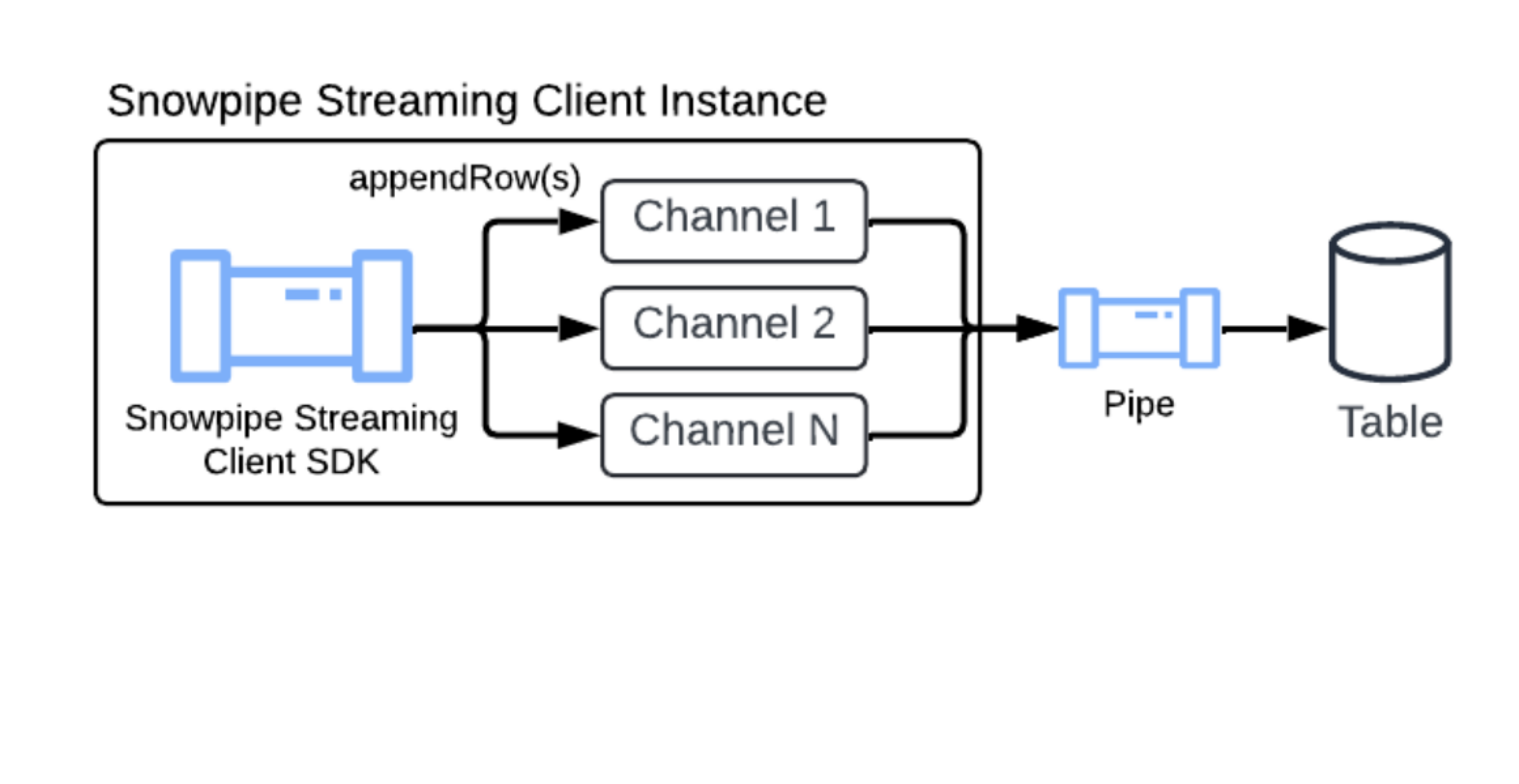
Pour une configuration rapide, Snowflake crée automatiquement un canal par défaut pour chaque table. Le canal par défaut gère l’ingestion sans DDL manuel requis. Pour les cas d’utilisation avancés qui nécessitent des transformations ou un pré-clustering, vous pouvez créer un canal nommé personnalisé. Pour plus d’informations, voir CREATE PIPE.
Canal par défaut¶
Snowflake fournit un canal par défaut pour chaque table cible. Le canal par défaut est créé à la demande après le premier appel d’infos de canal ou de canal ouvert réussi sur la table cible. Cela vous permet de commencer immédiatement la diffusion des données sans avoir besoin d’exécuter manuellement les instructions CREATE PIPE DDL.
Création à la demande : Vous pouvez uniquement voir ou décrire le canal (en utilisant SHOW PIPES ou DESCRIBE PIPE) après son instanciation par l’un de ces appels.
Convention de dénomination :
<TABLE_NAME>-STREAMING(par exemple,MY_TABLE-STREAMING)Entièrement géré par Snowflake : Vous ne pouvez pas exécuter CREATE, ALTER, ou DROP sur le canal par défaut.
Visibilité : Vous pouvez inspecter le canal par défaut en utilisant SHOWPIPES, DESCRIBEPIPE, et SHOWCHANNELS. Le canal par défaut est également inclus dans les vues ACCOUNT_USAGE. PIPES, ACCOUNT_USAGE .METERING_HISTORY, et ORGANIZATION_USAGE.PIPES.
Le canal par défaut présente les limitations suivantes :
Aucune transformation : Le canal par défaut utilise
MATCH_BY_COLUMN_NAMEdans l’instruction de copie sous-jacente. Il ne prend pas en charge les transformations de données spécifiques.Aucun pré-clustering : Le canal par défaut ne prend pas en charge le pré-clustering pour la table cible.
Si votre flux de travail nécessite des transformations ou un pré-clustering, créez votre propre canal nommé. Pour plus d’informations, voir CREATE PIPE.
Lorsque vous configurez le SDK ou l’API REST Snowpipe Streaming, vous pouvez faire référence au nom du canal par défaut dans la configuration de votre client pour commencer le streaming. Pour plus d’informations, voir Tutoriel : Premiers pas avec l’architecture hautes performances du SDK Snowpipe Streaming et Tutoriel : Premiers pas avec l’API REST Snowpipe Streaming utilisant cURL et un JWT.
Pré-clustering de données lors de l’ingestion¶
Snowpipe Streaming peut regrouper les données en vol pendant l’ingestion, ce qui améliore les performances des requêtes sur vos tables cibles. Cette fonctionnalité trie vos données directement lors de l’ingestion avant leur validation.
Pour tirer parti du pré-clustering, votre table cible doit comporter des clés de clustering définies. Vous pouvez ensuite activer cette fonctionnalité en définissant le paramètre CLUSTER_AT_INGEST_TIME sur TRUE dans votre instruction COPY INTO lors de la création ou du remplacement de votre canal Snowpipe Streaming.
Pour plus d’informations, voir CLUSTER_AT_INGEST_TIME.
Important
Lorsque vous utilisez la fonctionnalité de pré-clustering, assurez-vous de ne pas désactiver la fonctionnalité de clustering automatique sur la table de destination. La désactivation du clustering automatique peut entraîner une dégradation des performances des requêtes au fil du temps.