Canaux et livraison unique¶
Cette rubrique explique comment Snowpipe Streaming ingère des données via des canaux avec des garanties de classement et comment les jetons de décalage permettent une livraison unique.
Principes fondamentaux d’ingestion de flux¶
Snowpipe Streaming s’articule autour de plusieurs principes fondamentaux d’ingestion de flux :
Ingestion continue : Les données circulent dans Snowflake au fur et à mesure de leur production, plutôt que d’être collectées en lots et chargées périodiquement. Les applications soumettent des lignes en continu par le biais de connexions de longue durée, et Snowflake valide automatiquement les données.
Livraison unique : Chaque enregistrement est ingéré une seule fois, même en cas d’échec du client ou d’interruption du réseau. Snowpipe Streaming y parvient grâce au suivi des jetons de décalage, qui permet aux clients de reprendre à partir de la dernière position validée sans dupliquer les données.
Ingestion ordonnée : Les lignes sont validées dans l’ordre où elles sont soumises dans un canal. Cela préserve la séquence des événements du système source, qui est essentielle pour les données de séries chronologiques, les pipelines CDC, et les pistes d’audit.
Faible latence : Les données sont disponibles pour la requête dès 5 secondes après leur ingestion. Cela permet d’effectuer des analyses en temps quasi réel, sans les délais inhérents au chargement par lots traditionnel.
Sans serveur : Snowflake gère toutes les ressources de calcul pour l’ingestion. Les ressources augmentent automatiquement en fonction du débit, sans infrastructure à provisionner ou à gérer par le client.
Comment les données circulent¶
Une application cliente se connecte à Snowflake à l’aide d’un SDK Snowpipe Streaming (Java ou Python) ou de l’API REST. Le client ouvre un ou plusieurs canaux sur un pipeline, puis soumet des lignes via ces canaux. Snowflake met en mémoire tampon et valide les données dans la table cible, les rendant disponibles pour une requête en quelques secondes.
Le flux de bout en bout :
L’application cliente soumet des lignes à l’aide du SDK (
appendRows) ou de l’API REST (point de terminaisonAppend Rows).Le canal reçoit les lignes dans l’ordre et associe chaque lot à un jeton de décalage pour le suivi de la progression.
Le pipeline traite les données côté serveur, en validant le schéma, en appliquant les transformations ou le pré-clustering configurés, puis en enregistrant les données dans la table cible.
La table cible reçoit les données enregistrées, qui deviennent immédiatement interrogeables.
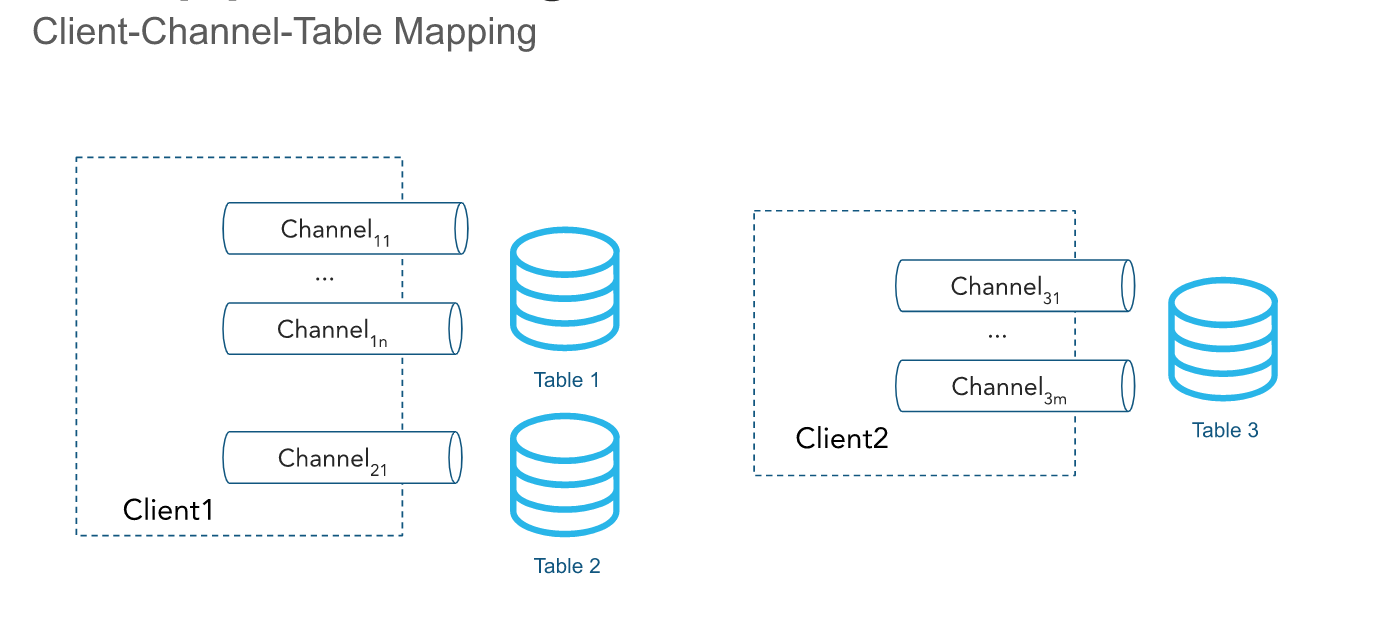
Canaux¶
Un canal est une connexion de flux logique et nommée avec Snowflake pour le chargement de données dans une table. Les canaux offrent deux garanties :
Ingestion ordonnée : L’ordre des lignes et des jetons de décalage correspondants est préservé au sein d’un canal.
Livraison unique : Les jetons de décalage permettent aux clients de suivre la progression validée et de rejouer à partir de la dernière position validée lors de la récupération.
L’ordre est préservé au sein d’un canal, mais pas entre les canaux qui pointent vers la même table.
Les canaux sont ouverts sur un pipeline. Le client SDK a la possibilité d’ouvrir plusieurs canaux vers plusieurs pipelines ; cependant, le SDK ne peut pas ouvrir de canaux sur plusieurs comptes. Les canaux sont conçus pour durer longtemps lorsqu’un client insère activement des données, et ils doivent être réutilisés lors des redémarrages du processus client, car les informations de jetons de décalage sont conservées.
Vous pouvez supprimer définitivement des canaux à l’aide de l’API DropChannelRequest lorsque vous n’avez plus besoin du canal et des métadonnées de décalage associées. Vous pouvez supprimer un canal de deux façons :
Suppression d’un canal à la fermeture. Les données à l’intérieur du canal sont automatiquement vidées avant la suppression du canal.
Suppression d’un canal à l’aveugle. Nous ne recommandons pas cette approche, car elle supprime toutes les données en attente.
Vous pouvez lancer la commande SHOW CHANNELS pour obtenir la liste des chaînes pour lesquelles vous disposez de privilèges d’accès. Pour plus d’informations, consultez SHOW CHANNELS.
Note
Les canaux inactifs ainsi que leurs jetons de décalage sont automatiquement supprimés après 30 jours d’inactivité.
Jetons de décalage et livraison unique¶
Astuce
Comment la livraison unique fonctionne dans Snowpipe Streaming : Votre application soumet des lignes avec un jeton de décalage (par exemple, un décalage de partition Kafka). Snowflake conserve le jeton lorsque les données sont validées. Lors de la récupération, votre application appelle getLatestCommittedOffsetToken pour trouver où il s’est arrêté, puis rejoue à partir de cette position. Aucune donnée en double n’est ingérée et aucune donnée n’est perdue.
Un jeton de décalage est une chaîne qu’un client inclut dans les demandes de soumission de lignes pour suivre la progression de l’ingestion pour chaque canal. Les méthodes spécifiques utilisées sont appendRow ou:code:appendRows pour le SDK et le point de terminaison Append Rows pour l’API REST.
Le jeton est initialisé à la valeur NULL lors de la création du canal et est mis à jour lorsque les lignes avec un jeton de décalage fourni sont validées dans Snowflake. Les clients peuvent appeler périodiquement getLatestCommittedOffsetToken pour obtenir le dernier jeton de décalage validé pour un canal et l’utiliser pour raisonner sur la progression de l’ingestion.
Lorsqu’un client rouvre un canal, le dernier jeton de décalage persistant est renvoyé. Le client peut réinitialiser sa position dans la source de données en utilisant le jeton pour éviter d’envoyer deux fois les mêmes données. Lorsqu’un événement de réouverture d’un canal se produit, toutes les données non validées mises en mémoire tampon dans Snowflake sont écartées pour éviter de les valider.
Vous pouvez utiliser le dernier jeton de décalage validé pour effectuer les opérations suivantes :
Suivre la progression de l’ingestion
Vérifier si un décalage spécifique a été validé en le comparant au dernier jeton de décalage validé
Avancer le décalage de la source et purger les données qui ont déjà été validées
Activer la déduplication et assurer la livraison unique des données
Exemple : Reprise en cas d’échec du connecteur Kafka
Le connecteur Kafka lit un jeton de décalage d’un sujet comme <partition>:<offset>. Prenons la requête suivante :
Le connecteur Kafka est en ligne et ouvre un canal correspondant à
Partition 1dans le sujet KafkaTavec le nom de canalT:P1.Le connecteur commence à lire les enregistrements de la partition Kafka.
Le connecteur appelle le API, en faisant une demande de méthode
appendRowsavec le décalage associé à l’enregistrement comme jeton de décalage.Par exemple, le jeton de décalage pourrait être
10, faisant référence au dixième enregistrement de la partition Kafka.Le connecteur effectue périodiquement des
getLatestCommittedOffsetTokendemandes de méthode pour déterminer la progression de l’ingestion.
Si le connecteur Kafka tombe en panne, la procédure suivante reprend la lecture des enregistrements à partir du décalage correct :
Le connecteur Kafka revient en ligne et rouvre le canal en utilisant le même nom que précédemment.
Le connecteur appelle
getLatestCommittedOffsetTokenpour obtenir le dernier décalage validé pour la partition.Par exemple, supposons que le dernier jeton de décalage persistant est
20.Le connecteur utilise la lecture Kafka APIs pour réinitialiser un curseur correspondant au décalage plus 1 (
21dans cet exemple).Le connecteur reprend la lecture des enregistrements. Aucune donnée en double n’est récupérée après le repositionnement réussi du curseur de lecture.
Exemple : Ingestion de fichiers de journalisation avec reprise après échec
Une application lit les journaux d’un répertoire et utilise le SDK Snowpipe Streaming pour exporter ces journaux vers Snowflake. L’application effectue les opérations suivantes :
Liste les fichiers dans le répertoire du journal.
Supposons que le framework de journalisation génère des fichiers journaux qui peuvent être ordonnés lexicographiquement et que les nouveaux fichiers journaux sont placés à la fin de cet ordre.
Lit un fichier journal ligne par ligne et appelle les requêtes de la méthode API, effectuant
appendRowsavec un jeton de décalage correspondant au nom du fichier journal et au nombre de lignes ou à la position des octets.Par exemple, un jeton de décalage pourrait être
messages_1.log:20, oùmessages_1.logest le nom du fichier journal et20est le numéro de ligne.
Si l’application tombe en panne ou doit être redémarrée, elle appelle getLatestCommittedOffsetToken pour récupérer le jeton de décalage qui correspond au dernier fichier de journalisation et à la dernière ligne exportés. En continuant avec l’exemple, cela pourrait être messages_1.log:20. L’application ouvre alors messages_1.log et cherche la ligne 21 pour éviter que la même ligne de journal soit ingérée deux fois.
Note
Les informations relatives au jeton de décalage peuvent être perdues. Le jeton de décalage est lié à un objet de canal, et un canal est automatiquement effacé si aucune nouvelle ingestion n’est effectuée en utilisant le canal pendant une période de 30 jours. Pour éviter la perte du jeton de décalage, envisagez de maintenir un décalage séparé et de réinitialiser le jeton de décalage du canal si nécessaire.
Rôles de offsetToken et continuationToken¶
offsetToken et continuationToken sont tous deux utilisés pour garantir une livraison unique des données, mais ils répondent à des usages différents et sont gérés par des sous-systèmes différents. La principale distinction réside dans ce qui contrôle la valeur du jeton et dans la portée de son utilisation.
continuationToken(uniquement utilisé par les utilisateurs directs de l’API REST) :Ce jeton est géré par Snowflake et est essentiel pour maintenir l’état d’une session de streaming unique et continue. Lorsqu’un client envoie des données à l’aide de l’API
Append Rows, Snowflake lui renvoie uncontinuationToken. Le client doit retransmettre ce jeton dans sa requête AppendRows suivante pour s’assurer que les données sont reçues par Snowflake dans le bon ordre et sans interruption. Snowflake utilise le jeton pour détecter et empêcher les doublons de données ou les données manquantes en cas de nouvelle tentative d’un SDK.offsetToken:Ce jeton est un identificateur défini par l’utilisateur qui permet une livraison unique à partir d’une source externe. Snowflake stocke cette valeur, mais ne l’utilise pas pour ses propres opérations internes ou pour empêcher la réingestion. Il est de la responsabilité du système externe, comme un connecteur Kafka, de lire le jeton de décalage de Snowflake et de l’utiliser pour suivre sa propre progression d’ingestion et éviter d’envoyer des données dupliquées si le flux externe doit être rejoué.